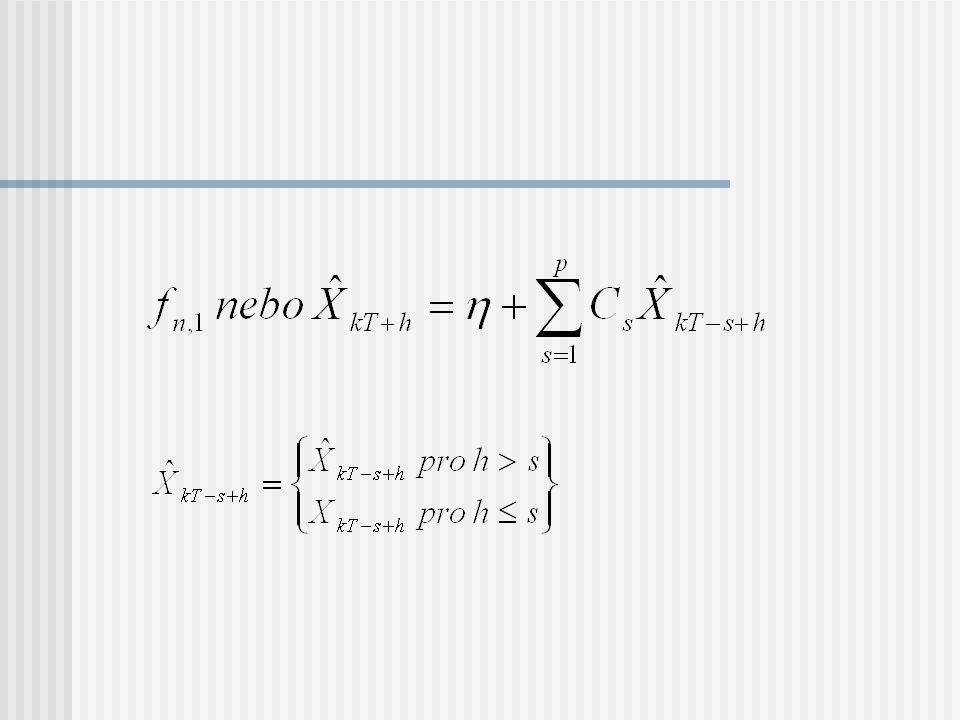Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Lukáš Čechura k.h.: čtvrtek 14:30-16:00
Prognostické metody Lukáš Čechura k.h.: čtvrtek 14:30-16:00

2
Obsah předmětu - Přednášky
Úvod do prognostiky, vymezení prognostiky a klasifikace prognóz; Typologie prognostických metod Vlastnosti časových řad, trendové funkce a prognózování; Prognózy z modelů časových řad – ARIMA modely Další vybrané problémy prognóz z časových řad Prognózy z ekonometrických modelů, specific to general modelování; Ověřování prognostických vlastností ekonometrického modelu; Odvození prognóz z komplexních ekonometrických modelů General to specific modelování – ADL modely Prognózy cenového vývoje – ADL model VAR model Kointegrační analýza, VECM model Leading indicators Simulační cílové a faktorové prognózy

3
Obsah předmětu - cvičení
Úvod, zadání projektu, datová základna Trendové funkce; ARIMA model ADL model VAR model Vyhodnocení prognóz; Závěr

4
Doporučená literatura
Granger, C.W.J.: Forecasting in business and economics, Academic Press New York, 1989 Green, W.H.: Econometric Analysis, Printice Hall, 2003 (5th edition) Cipra, T.: Finanční ekonometrie, Ekopress, 2008 Hušek, R.: Základy ekonometrické analýzy II. – Speciální postupy a techniky, VŠE Praha 1998 Tvrdoň J.: Ekonometrie, ČZU Praha 2000
 Cipra, T.: Finanční ekonometrie, Ekopress, Hušek, R.: Základy ekonometrické analýzy II. – Speciální postupy a techniky, VŠE Praha Tvrdoň J.: Ekonometrie, ČZU Praha")
5
Scénář vývoje 28. září 2010 bude úterý. Na pláži v La Jolla bude v 11:00 svítit sluníčko. Vlny budou 4 stopy vysoké se 14 sekundovým intervalem. Výška přílivu bude +2,3 stopy a teplota vody 20 oC. Navléknu si brýle se šnorchlem a začnu se potápět. Po nějaké chvíli najdu na dně půl dolaru, který zde ztratil před několika měsíci jiný potápěč. Použiji celý půl dolar na nákup „Evening Tribune“.

6
Rozbor scénáře Datum – 28. září 2010 pouze stanoví, kdy se daný scénář uskuteční. Den – tj. určení, že bude úterý není ve skutečnosti prognózou, jelikož lze určit podle kalendáře. Příliv – mechanismus, který zapříčiňuje příliv a odliv je velmi dobře znám a závisí na pohybu měsíce a dalších objektů sluneční soustavy. Proto tento pohyb může být prognózován s vysokou mírou přesnosti, i když jeho kalkulace nemusí být lehkou záležitostí. Chybu prognózy lze proto očekávat velmi malou, jež může být ovlivněna předchozími větrnými podmínkami. Jediným předpokladem, který je nutný při této prognóze přijmout, je neměnnost mechanismu, kterým je příliv a odliv generován.

7
Slunečné počasí, vlny a teplota vody – tato prognóza může být založena na sledování podmínek počasí v tomto období roku, tj. 28. září. Prognózou pak může být průměr hodnot z předchozích let. Tato prognóza však bude zatížena velkou chybou. Např. teplota oceánu se výrazně mění z roku na rok, jde o tzv. sezónní kolísání. Také počasí v daném místě lze velmi těžko předpovědět, jelikož závisí na budoucím pohybu vzdušných mas a na mechanismu, který jimi v atmosféře hýbe.

8
Moje chování – o mnohém z toho, co jsem pronesl, lze pochybovat
Moje chování – o mnohém z toho, co jsem pronesl, lze pochybovat. Ale za předpokladu splnění všech nutných podmínek, tj. že budu 28. září 2010 na pláži v La Jolla, dostatečně zdravý na potápění, atd., bude předpověď samovyplňující. Nalezení půl dolaru – není prognózou, ale přáním.

9
Koupě „Evening Tribune“ za nalezený půl dolar – v dané oblasti vychází večerník „Evening Tribune“, který po nedávném zdražení z 15 centů stojí 25 centů. Sledováním minulého cenového vývoje v celé ekonomice lze prognózovat, že co dnes stojí 25 centů bude v roce 2010 stát 50 centů. Mechanismus prognózy je založen na minulém vývoji, tj. cena je extrapolována.

10
Z uvedeného jednoduchého scénáře plyne následující:
Prognózy se od sebe liší stupněm své prognózovatelnosti, tj. některé proměnné lze prognózovat s vysokou mírou přesnosti a naopak některé jsou téměř neprognózovatelné. Metoda použitá k odvození prognózy závisí na disponibilních datech, kvalitě disponibilních modelů a předpokladech, vedle jiného.

11
Oblasti prognózování Např. v USA je ročně vynaloženo na zpracování prognóz mnoho milionů dolarů. Hlavní zájemci o prognózy jsou vláda, centrální banka, ost. státní úřady a management ve všech oblastech podnikání. Jedná se např. o následující typy prognóz: Podnik musí prognózovat velikost prodeje každého ze svých produktů, aby výše jeho produkce a zásob byla ekonomicky efektivní, a zároveň zajišťovala kontrolu pravděpodobnosti neuspokojení poptávky.

12
Investice – rozhodnutí o realizaci investičního záměru závisí na výši budoucích příjmů, které investice generuje. Prognóza těchto příjmu zásadně ovlivňuje rozhodovací proces. Nový produkt firmy – prognóza prodeje a vliv na jiné produkty firmy Prognóza vývoje nezaměstnanosti pro vládní účely Prognóza vývoje HDP pro účely sestavování SR

13
Vymezení prognostiky Prognostika je v širším slova smyslu část teorie poznání vztahující se k budoucnosti Ekonomické procesy mají objektivní charakter Prognóza x predikce x hypotéza

14
Klasifikace prognóz Dle délky prognostického horizontu
Dle předmětu prognózování Dle typu prognóz: Event outcome forecasts Event timing forecasts Time series forecasts

15
Event outcome forecasts
Narodí se chlapec či dívka? Kdo vyhraje volby? Jakou známku dostanu z prognostických metod? … Dostanu ji? …

16
Event timing forecasts
Kdy budou v ČR volby? Kdy nastane zlomový bod v ekonomice? (leading indicator) Kdy ČNB změní sazby? Kdy se bratr ožení? ….
 Kdy ČNB změní sazby Kdy se bratr ožení ….")
17
Time series forecasts Časová řada je sekvence hodnot dané proměnné, jež je zaznamenávána (obvykle) v pravidelných intervalech. Proměnná – xt, kde t=1,…,n Jaké bude nabývat hodnoty v čase n+h? h reprezentuje počet period (období) prognostického horizontu. xt je sekvence náhodných proměnných, stejně tak i xn+h
 prognostického horizontu. xt je sekvence náhodných proměnných, stejně tak i xn+h.")
18
Proměnná xt může být popsána pravděpodobnostními charakteristikami
Distribuční funkce; funkce hustoty pravděpodobnosti; Průměr a rozptyl Rozdělení pravděpodobnosti podmíněně na disponibilních informacích v čase n. Intervalová prognóza x bodová prognóza Trace forecast

19
Informační (datová) základna
Informační základna (In): In: xn-j , j>=0 In: xn-j, yn-j, zn-j, etc., j>=0 Misspecification Under-parameterisation Over-parameterisation Informační základna: Vhodná – minulá a současná data Nevhodná – suboptimální (podmíněná) prognóza Numerická data Informace nenumerického charakteru
: In: xn-j , j>=0. In: xn-j, yn-j, zn-j, etc., j>=0. Misspecification. Under-parameterisation. Over-parameterisation. Informační základna: Vhodná – minulá a současná data. Nevhodná – suboptimální (podmíněná) prognóza. Numerická data. Informace nenumerického charakteru.")
20
Nákladová funkce prognóz
Kritérium výběru nejlepší prognózy C(e) = Ae2 Kritérium = min C(e)
 = Ae2. Kritérium = min C(e)")
21
Členění prognostických metod
Prognostické metody Orientačně, podle míry subjektivity, lez klasifikovat prognostické metody na subjektivní, objektivní a systémové modely. Charakteristika prognostických metod v tomto pojetí ale neznamená předurčení prognóz sestavených převážně na základě subjektivních metod na prognózy méně kvalitní ve srovnání s prognózami, které využívají ve větší míře objektivní metody. Jak objektivní tak subjektivní metody mají své přednosti a nedostatky a jde spíše o využívání předností obou prognostických směrů. Určitou syntézu subjektivních a objektivních metod představují systémové modely. Subjektivní metody Metoda srovnávací (analogických úsudků) spočívá v nalezení analogie ve vývoji systémů obdobných jak z hlediska obsahové struktury, tak časových a místních podmínek. V ekonomických prognózách se používá zejména historické analogie, která při dodržení podmínky odpovídající srovnatelnosti může poskytnout v krátké době a s nízkými náklady na jednotku informace požadované prognostické poznatky.
 spočívá v nalezení analogie ve vývoji systémů obdobných jak z hlediska obsahové struktury, tak časových a místních podmínek. V ekonomických prognózách se používá zejména historické analogie, která při dodržení podmínky odpovídající srovnatelnosti může poskytnout v krátké době a s nízkými náklady na jednotku informace požadované prognostické poznatky.")
22
Analýza dokumentů se vztahuje jak k textovým, tak k elementárním statistickým podkladům, které poskytují informace o objektu prognózy. Pokud jsou informace úplné, metoda umožňuje získat komplexní přehled o daném problému. Plnému využití této metody brání mnohdy značná nesourodost podkladových materiálů s vysokými nároky na stanovení skutečných vývojových tendencí. Při normativní metodě se využívá prognóz sestavených pro hlavní výrobky. Na základě příslušných normativů se odvozuje prognóza pro výrobky, které jsou v závislosti na hlavním výrobku – buť jako výrobky sdružené, nebo které tvoří doplněk, příslušenství nebo náhradní díl výrobku hlavního. Přesnost takto odvozených prognóz zcela závisí na kvalitě působení prognózy. Normativní metoda je obdobou analogické metody.

23
Podstatou metody dotazování je zjištění názoru odborníků na vývoj předmětu prognózy. Dotazy jsou kladeny ústní nebo písemnou formou. Předností písemných dotazů je menší časová náročnost na shromáždění příslušných informací a stejný systém kladení otázek, který není při ústním dotazování zcela zaručen. Způsob organizace a zpracování dotazování je podrobně popsáno v tzv. delfské metodě. Jedná se o etapové zjištění názoru odborníků, při němž se dotazy formulují nejdříve obecně, pak se postupně zpřesňují a konkretizují směrem od obecného ke zvláštnímu. Dotazy jsou formulovány tak, aby bylo možné statistické zpracování ve formě zjištění mediánů a kvartilů, zmenšení kvartilových intervalů a korelace mezi hodnotami časových horizontů objevu při dvou pravděpodobnostech 0,5 a 0,9, mezi nimiž se předpokládá psychologická souvislost. Předností metody je dosažení konkrétního závěru ještě v etapě dotazování.

24
Obdobou delfské metody je tzv
Obdobou delfské metody je tzv. brainstorming - burza nápadů, při němž jsou dotazy kladeny ústní formou kolektivu odborníků různých profesí, případně neodborníků, mezi nimiž nejsou žádné zábrany pro vyjádření jakýchkoliv námětů a idejí. Nenucená a otevřená forma diskuse je podmínkou úspěchu této metody. Na rozdíl od delfské metody diskuse nemusí vyústit v konkrétní závěr. Zhodnocení utříděných námětů vzešlých z diskuse, která se zaznamenává, představuje závěrečnou etapu brainstormingové metody. Charakteristickým rysem metody dotazování v jejích různých variantách je přenesení řešení prognostického úkolu z větší části na dotazované - není to jistě jediný důvod značného rozšíření těchto metod. Soubor dotazovaných pak vlastně představuje prognostický tým a na jeho složení do značné míry závisí kvalita prognózy.

25
Objektivní metody Objektivní metody používané v prognostické činnosti vycházejí z poznatků statistiky a aplikované matematiky, nebo jsou jejich kombinací. Ze statistických metod se jedná zejména o zkoumání založené na analýze trendových funkcí, modelů časových řad a regresních modelů. Analýzu trendových funkcí lze rozdělit do dvou navazujících etap. První etapou je stanovení trendové funkce. V ekonomických prognózách se jedná zpravidla o neperiodické časové řady s náhodným kolísáním. K jejich vyrovnání se používá řady funkcí, z nichž největšího rozšíření doznaly funkce lineární, mocninná (dvojlogaritmická), semilogaritmická, exponenciální, kvadratická, hyperbolická a logistická (tzv. S-funkce).
, semilogaritmická, exponenciální, kvadratická, hyperbolická a logistická (tzv. S-funkce).")
26
Modely časových řad – ARIMA modely
Mezi objektivní metody patří dále prognostické postupy, které využívají poznatků aplikované matematiky. Jedná se zejména o strukturální analýzu, matematické programování a síťovou analýzu. Značného rozšíření v prognostických pracích doznala zejména strukturální analýza, která vychází z klasického Leontěvova modelu. Input-output analysis of the Economy of USA. Umožňuje vyčíslit výslednou spotřebu při požadované hrubé produkci, úroveň hrubé produkce při požadované spotřebě, nebo řešení smíšeného úkolu. Kromě těchto základních propočtů lze vyjádřit vliv ekonomických nástrojů řízení, včetně cenových, na reprodukční proces a jeho výsledky.

27
Strukturální analýza patří k metodám, které v prognostické činnosti respektují normativně cílový postup formulace prognóz. Obdobně je tomu v případě modelů matematického programování. Bilanční modely lze v kombinaci se simplexovými modely považovat za další obohacení prognostických nástrojů. Ve srovnání s ostatními prognostickými metodami předností modelů matematického programování je možnost formulace účelové funkce. Ostatní metody operační analýzy ve větším měřítku nebyly pro sestavení prognóz využívány. Za zmínku stojí metody síťové analýzy, které lze využít k prognóze časových úseků, v nichž vývoj předmětu prognózy dosáhne předem definovaného stadia nebo požadovaného stavu.

28
Systémové modely Mezi nejslibnější metody prognostické činnosti patří systémové modely. Prognostické systémové modely využívají jak objektivních, tak subjektivních metod pro vyjádření budoucnosti jako struktury, v níž jsou všechny dílčí prvky ve vzájemných souvislostech a interakcích. Systémový přístup je způsob chápání reality, který nemění základní metodologické nástroje prognózování. Systémový přístup při sestavování prognóz představuje účinný pořádací princip, který přispívá k dosažení souladu prognózy a skutečného vývoje.

29
Vlastnosti časových řad, modely časových řad
Časová řada – věcně a prostorově srovnatelná pozorování (dat), která jsou jednoznačně uspořádána z hlediska času ve směru minulost – přítomnost. Analýza časových řad – soubor metod, které slouží k popisu těchto řad a případně k předpovídání jejich budoucího chování.
, která jsou jednoznačně uspořádána z hlediska času ve směru minulost – přítomnost. Analýza časových řad – soubor metod, které slouží k popisu těchto řad a případně k předpovídání jejich budoucího chování.")
30
Elementární charakteristiky časových řad
Obvykle prvním úkolem při analýze časové řady je získat rychlou a orientační představu o charakteru procesu, který tato řada reprezentuje. Vizuální analýza Grafy Elementární charakteristiky (diference různého řádu, tempa a průměrná tempa růstu, průměr časové řady aj.)
")
31
Přístupy k modelování časových řad
Výchozím principem je jednorozměrný model: Yt=f(t;u) k němuž se v zásadě přistupuje trojím způsobem
 k němuž se v zásadě přistupuje trojím způsobem.")
32
A) Klasický (formální) model
Dekompozice časové řady na 4 složky Y = T + S + C + u

33
B) Box-Jenkinsova metodologie
Tento přístup považuje za základní prvek časové řady náhodnou složku a snaží se ji modelovat. Těžiště postupu se klade na korelační analýzu více či méně závislých pozorování, uspořádaných do tvaru časové řady.

34
C) Spektrální analýza V tomto přístupu se časová řada považuje za „směs“ sinusovek a kosinusovek o rozličných amplitudách a frekvencích. Tato koncepce umožňuje provést explicitní popis periodického chování časové řady a především vystopovat ty významné složky periodicity, které se podílejí na věcných vlastnostech zkoumaného procesu. V tomto přístupu tedy není stěžejním faktorem časová proměnná, ale právě faktor frekvenční.

35
Vlastnosti stochastických časových řad
Stochastický proces lze označit jako nekonečnou posloupnost náhodných veličin uspořádaných v čase. Možnost realizace každého pozorování je dána funkcí rozdělení pravděpodobnosti f(Yt). Modelování konkrétního stochastického procesu proto vyžaduje, co nejpřesněji popsat povahu náhodnosti. Skutečná povaha zpravidla neznámá. Aproximativně pomocí zjednodušeného modelu časové řady. Čím přesněji popisuje stochastický model časové řady charakteristiky skutečného rozdělení pravděpodobnosti, tím lepší je jeho schopnost predikce.
. Modelování konkrétního stochastického procesu proto vyžaduje, co nejpřesněji popsat povahu náhodnosti. Skutečná povaha zpravidla neznámá. Aproximativně pomocí zjednodušeného modelu časové řady. Čím přesněji popisuje stochastický model časové řady charakteristiky skutečného rozdělení pravděpodobnosti, tím lepší je jeho schopnost predikce.")
36
Stacionarita a nestacionarita časových řad
Popis stochastického procesu – společné (simultánní) rozdělení pravděpodobnosti hodnot náhodné veličiny Yt, tj. (yR+1, yR+2, …, yR+T). Komplikované Používá se 1. a 2. moment realizovaných hodnot
 rozdělení pravděpodobnosti hodnot náhodné veličiny Yt, tj. (yR+1, yR+2, …, yR+T). Komplikované. Používá se 1. a 2. moment realizovaných hodnot.")
37
Stacionarita Definice: časová řada yt je stacionární, jestliže její rozdělení pravděpodobnosti je v čase neměnné, tj. společné (rozdělení) pravděpodobnosti (yR+1,=, yR+2, …, yR+T) není závislé na R. Striktní stacionarita Slabě stacionární proces (2. řádu) – průměr a rozptyl je konstantní, přičemž kovariance libovolných dvou pozorování časové řada závisejí pouze na velikosti zpoždění, tj. na délce časového posunu mezi nimi, nikoliv na hodnotě R.
 pravděpodobnosti (yR+1,=, yR+2, …, yR+T) není závislé na R. Striktní stacionarita. Slabě stacionární proces (2. řádu) – průměr a rozptyl je konstantní, přičemž kovariance libovolných dvou pozorování časové řada závisejí pouze na velikosti zpoždění, tj. na délce časového posunu mezi nimi, nikoliv na hodnotě R.")
38
Nestacionární časové řady
Trend Sezónnost Strukturální šoky v ekonomice Zjišťování nestastacionarity ACF Testy jednotkového kořene

39
Modely časových řad ARIMA modely
Použití ke krátkodobé predikci a to v situaci, kdy nejsou k dispozici adekvátní data vysvětlujících proměnných, resp. když při odhadu a verifikaci LRM nebo MSR dospějeme k závěru, že odhadnuté parametry jsou z hlediska ekonomických, statistických i ekonometrických kritérií nepoužitelné. Nebo má-li model špatné prognostické vlastnosti.

40
Modely náhodných procházek
Jednoduchý stochastický proces Proces je nestacionární, neboť průměr a rozptyl nejsou konstantní I(1) Použije-li se proces tohoto typu k popisu dynamického chování, např. cen akcií nebo spotřebitelských cen , jde o nestacionární model časových řad. Avšak časové řady cenových změn jsou již generovány stacionárním ryze náhodným procesem, nazývaným také jako bílý šum. Pro krátkodobou předpověď na základě modelu náhodné procházky platí y´t+1=yt + E(ut+1) = yt
 Použije-li se proces tohoto typu k popisu dynamického chování, např. cen akcií nebo spotřebitelských cen , jde o nestacionární model časových řad. Avšak časové řady cenových změn jsou již generovány stacionárním ryze náhodným procesem, nazývaným také jako bílý šum. Pro krátkodobou předpověď na základě modelu náhodné procházky platí. y´t+1=yt + E(ut+1) = yt.")
41
Modely klouzavých průměrů (MA)
Jedna z možností modelování dynamiky stacionárních časových řad Např. analýza vývoje změn cen akcií, kdy tato posloupnost změn cen s nulovým průměrem a konstantním rozptylem lze zapsat: Yt = ut ut jsou identicky rozdělené náhodné složky, sériově nezkorelované. Odrážejí působení neočekávaných vlivů na cenu akcií např. informace o finanční situaci podniku. Lze předpokládat, že všechny nové informace nejsou trhem absorbovány během 1 dne, proto změnu pro příští den lze vyjádřit jako:

42
yt+1 = ut+1 + aut Přičemž ut+1 reprezentuje vliv nové informace (inovace), která vešla ve známost v průběhu dne t+1, zatímco výraz aut odráží doznívající působení informace z předešlého dne. Vzhledem k tomu, že procesem MA(1) generovaná pozorování yt jsou zkorelována pouze se sousedními pozorováními, tj. yt-1 a yt+1, říkáme, že proces MA(1) má paměť pouze jedno období, tj. zapomíná vše, co se událo se zpožděním větším než jedno období.
, která vešla ve známost v průběhu dne t+1, zatímco výraz aut odráží doznívající působení informace z předešlého dne. Vzhledem k tomu, že procesem MA(1) generovaná pozorování yt jsou zkorelována pouze se sousedními pozorováními, tj. yt-1 a yt+1, říkáme, že proces MA(1) má paměť pouze jedno období, tj. zapomíná vše, co se událo se zpožděním větším než jedno období.")
43
Autoregresní modely (AR)
Jiný přístup k modelování časové struktury stacionárních časových řad. Vyjádření yt jako funkce několika předcházejících pozorování.

44
Autoregresní modely klouzavých průměrů - ARMA
V praxi při modelování čas. řad se setkáváme s případy, kdy stacionární náhodný proces, generující jejich jednotlivá pozorování, nevyhovují zcela předpokladům MA, resp. AR, modelů. V této situaci je adekvátní taková specifikace modelu časové řady, jejíž složky vycházejí z principu kombinace AR a MA procesů. Smíšený model čas. řady, se nazývá ARMA (p,q) model, přičemž p výrazů je autoregresního typu a q reprezentuje zpožděné klouzavé průměry.
 model, přičemž p výrazů je autoregresního typu a q reprezentuje zpožděné klouzavé průměry.")
45
Autoregresní integrované modely klouzavých průměrů - ARIMA
Kromě stacionárních stochastických procesů se používají při specifikaci modelů časových i nestacionární procesy. I(d)
")
46
Nejsou-li stacionární časové řady smíšeného typu, takže jejich pozorování jsou generována pouze buď AR, resp. MA, procesem, pak Yt mají charakter integrovaného autoregresního procesu řádu (p,d), značeného jako ARI (p,d,0) nebo integrovaného procesu klouzavých průměrů řádu (d,q), který se značí IMA (0,d,q). Zvláštním případem procesu ARIMA, kterým lze generovat časové řady vykazující trend, je proces SARIMA, používaný k modelování čas. řad multiplikativně sezónního typu, tj. zatížených stochastickou sezónností (opět možné modifikace na SAR, SMA, resp. SARMA).
.")
47
Specifikace Modelu ARIMA (p,d,q)
1. fáze – linearizace časové řady 2. fáze – určení řádu integrace (homogenity) časové řady Stacionární časová řada = integrovaná řádu 0 Nestacionární č. ř. = integrovaná řádu d 3. fáze – nalezení hodnot p a q, tj. délky zpoždění AR a MA 4. fáze – odhad modelu 5. fáze – verifikace modelu 6. fáze – aplikace - prognózy
 časové řady. Stacionární časová řada = integrovaná řádu 0. Nestacionární č. ř. = integrovaná řádu d. 3. fáze – nalezení hodnot p a q, tj. délky zpoždění AR a MA. 4. fáze – odhad modelu. 5. fáze – verifikace modelu. 6. fáze – aplikace - prognózy.")
48
2. fáze - Autokorelační funkce (ACF)
Autokorelační funkce k-tého řádu ρk = γk/γ0 γk = cov(yt,yt+k) γ0 = σytσyt+k = σ2y V praktické aplikaci neznáme teoretickou ACF, odhadujeme pomocí výběrové ACF k-tého řádu Grafickým znázorněním pro různé hodnoty k je tzv. výběrový korelogram. Korelogram Stacionární čas. řada – s rostoucím k hodnota ACF klesá Nestacionární čas. řada – s rostoucím k hodnota ACF neklesá
 γ0 = σytσyt+k = σ2y. V praktické aplikaci neznáme teoretickou ACF, odhadujeme pomocí výběrové ACF k-tého řádu. Grafickým znázorněním pro různé hodnoty k je tzv. výběrový korelogram. Korelogram. Stacionární čas. řada – s rostoucím k hodnota ACF klesá. Nestacionární čas. řada – s rostoucím k hodnota ACF neklesá.")
49
3. fáze – nalezení hodnot p a q
ACF AIC, SIC Korigované R2

50
4. fáze – odhad modelu AR – pomocí BMNČ
MA – speciální techniky (interativního charakteru)
")
51
5. fáze – verifikace modelu
Aplikace různých kritérií za účelem ověření správnosti zvolené specifikace modelu Nejlépe provést verifikaci shody s předpověďmi ex post. Testování autokorelace reziduí Výběrový korelogram reziduí

52
6. fáze – odvození prognózy
Předpověď s modelem MA(1) Předpověď s modelem AR(1) Předpověď s modelem ARMA(1,1)
 Předpověď s modelem AR(1) Předpověď s modelem ARMA(1,1)")
53
Metody s nízkými náklady
Celý proces analýzy časových řad je někdy příliš zdlouhavý a nákladný. Proto byly některé části modelování z automatizovány. Identifikace modelu, tj. nalezení hodnot p a q, je zpravidla ponechána na analytikovi. Jednou z metod, která ulehčuje proces volby správného tvaru modelu, je stepwise AR model.

54
EWMA – exponentially weighted mowing average methods
Prognóza s nízkými náklady Metoda je založena na odlišném přístupu ve srovnání s metodami předchozími. Tento přístup pokládá za nejdůležitější aspekt časové řady její průměr. Prognóza je pak založena na odhadu průměru časové řady.

55
EWMA

56
Vylepšení EWMA

57
Kterou z metod použít ARIMA Stepwise AR model EWMA model
Rozhodnutí záleží na: Času Penězích Disponibilních datech

58
Vlastnosti optimální prognózy
Chyby prognózy et,h na h období prognostického horizontu by měly mít podobu MA(h-1) modelu. Zvláště pak chyba prognózy na jedno období dopředu et,1 by měla mít charakter bílého šumu. Rozptyl et,h je rostoucí s rostoucím h. S dostatečně velkým h by se měl blížit rozptylu xt.
 modelu. Zvláště pak chyba prognózy na jedno období dopředu et,1 by měla mít charakter bílého šumu. Rozptyl et,h je rostoucí s rostoucím h. S dostatečně velkým h by se měl blížit rozptylu xt.")
59
General to specific modelování
General to specific modelování zahrnuje formulaci neomezeného dynamického modelu (proto general), který je následně testován, transformován a redukován ve velikosti pomocí řady různých statistických testů. Tento specifický model ve své povaze odpovídá obecnému modelu, jelikož je z něho odvozen, avšak obsahuje pouze podstatné (signifikantní) vztahy mezi proměnnými modelovaného vztahu.
, který je následně testován, transformován a redukován ve velikosti pomocí řady různých statistických testů. Tento specifický model ve své povaze odpovídá obecnému modelu, jelikož je z něho odvozen, avšak obsahuje pouze podstatné (signifikantní) vztahy mezi proměnnými modelovaného vztahu.")
60
ADL model Neomezený dynamický model (jednorovnicový) je zpravidla formulován, resp. definován ve formě ADL (autoregressive distributed lag) modelu. ADL (Autoregressive distributed lag) model je model, který obsahuje n zpožděných hodnot závisle proměnné (proto označení „autoregrissive“) a p zpožděných hodnot nezávisle proměnné (proto „distributed lag“).
 model je model, který obsahuje n zpožděných hodnot závisle proměnné (proto označení „autoregrissive ) a p zpožděných hodnot nezávisle proměnné (proto „distributed lag ).")
61
ADL (n,p) model yt = β0 + β1yt-1 + β2yt-2 +…+ βnyt-n + γ10x1t + γ11x1t-1 + … + γ1px1t-p + ut kde β0, …, βn a γ10, …, γ1p jsou neznámé parametry pro n zpožděných hodnot endogenní proměnné a p zpoždění exogenní proměnné a ut je náhodná složka s nulovým podmíněným průměrem, tj. E(ut|yt-1, …, yt-n, xt, xt-1, …, xt-p) = 0.
 = 0.")
62
ADL (n,p) model s k proměnnými
yt = β0 + β1yt-1 + β2yt-2 +…+ βnyt-n + γ10x1t + γ11x1t-1 + … + γ1px1t-p +…+ γk0xkt + γk1xkt-1 + … + γkpxkt-p + ut kde β0, …, βn a γ10, …, γ1p, γk1, …, γkp jsou neznámé parametry pro n zpožděných hodnot endogenní proměnné a p zpoždění k exogenních proměnných a ut je náhodná složka s nulovým podmíněným průměrem, tj. E(ut|yt-1, …, yt-n, xt, xt-1, …, xt-p) = 0.
 = 0.")
63
DL model a význam jeho parametrů
Dílčí multiplikátory řádu i (Partial multipliers of order i) – vyjadřují mezní efekt proměnné xt-i na yt . Jinými slovy lze říci, že tyto multiplikátory ukazují vliv jednotkové změny proměnné Xt v období t-i, tj. i období před běžným obdobím (obdobím t), na E(yt) (ceteris paribus). Krátkodobý multiplikátor (Short-run, or impact multiplier) – je dílčí multiplikátor řádu i = 0, tj. je roven γ0. Tento multiplikátor ukazuje, jaký má vliv jednotkový růst v xt na E(yt) v běžném období (ve stejném období).
 – vyjadřují mezní efekt proměnné xt-i na yt . Jinými slovy lze říci, že tyto multiplikátory ukazují vliv jednotkové změny proměnné Xt v období t-i, tj. i období před běžným obdobím (obdobím t), na E(yt) (ceteris paribus). Krátkodobý multiplikátor (Short-run, or impact multiplier) – je dílčí multiplikátor řádu i = 0, tj. je roven γ0. Tento multiplikátor ukazuje, jaký má vliv jednotkový růst v xt na E(yt) v běžném období (ve stejném období).")
64
Střednědobé multiplikátory řádu i (Interim, or intermediate, multipliers of order i) – představují sumu prvních i dílčích multiplikátorů, tzn., že jsou rovny součtu γ0+γ1+γ2+…+γi. Tyto multiplikátory ukazují vliv jednotkové změny v xt na E(yt) za i období vzhledem k období t, tj. za i období předcházející období t. Dlouhodobý (celkový, rovnovážný) multiplikátor – je sumou všech dílčích multiplikátorů DL modelu. Tento multiplikátor vyjadřuje vliv jednotkové změny v xt na E(yt) za všechna období.
 multiplikátor – je sumou všech dílčích multiplikátorů DL modelu. Tento multiplikátor vyjadřuje vliv jednotkové změny v xt na E(yt) za všechna období.")
65
ADL model a význam jeho parametrů
Dílčí multiplikátory řádu i – nabývají stejného významu jako v případě DL modelu. Krátkodobý multiplikátor (Short-run, or impact multiplier) – je opět shodný s krátkodobým multiplikátorem u DL modelu, tj. je roven γ0. Střednědobé multiplikátory řádu I - jsou multiplikátory, které ukazují vliv jednotkové změny v xt na E(yt) za I období vzhledem k období t, tj. za I období předcházející období t. Vzhledem k tomu, že na pravé straně rovnice se vyskytují zpožděné hodnoty závisle proměnné, je nutné zohlednit jejich vliv.
 – je opět shodný s krátkodobým multiplikátorem u DL modelu, tj. je roven γ0. Střednědobé multiplikátory řádu I - jsou multiplikátory, které ukazují vliv jednotkové změny v xt na E(yt) za I období vzhledem k období t, tj. za I období předcházející období t. Vzhledem k tomu, že na pravé straně rovnice se vyskytují zpožděné hodnoty závisle proměnné, je nutné zohlednit jejich vliv.")
66
Střednědobý multiplikátor řádu I

67
Dlouhodobý multiplikátor ADL modelu
Dlouhodobý (celkový, rovnovážný) multiplikátor – je multiplikátor, který vyjadřuje vliv jednotkové změny v xt na E(yt) za všechna období a je totožný se střednědobým multiplikátorem za předpokladu, že I=(p=n).
 multiplikátor – je multiplikátor, který vyjadřuje vliv jednotkové změny v xt na E(yt) za všechna období a je totožný se střednědobým multiplikátorem za předpokladu, že I=(p=n).")
68
ADL model a kointegrační analýza

69
Model ADL(1,1) β1 = γ1 = 0 γ0 = γ1 = 0 β1 = γ0 = 0
Existuje nejméně deset ekonomicky smysluplných specifických modelů, které mohou být odvozeny z výše uvedeného obecného modelu při uvalení restrikcí na parametry β1, γ0 a γ1. β1 = γ1 = 0 Při uvalení nulových restrikcí na parametry β1 a γ1 se model zjednoduší na statickou regresi. γ0 = γ1 = 0 Za předpokladu nulových parametrů γ je specifický model autoregresním modelem prvního řádu, tj. AR(1). β1 = γ0 = 0 Specifický model se zpožděnou exogenní proměnnou se nazývá modelem předbíhajícího indikátoru, tj. leading indicator equation.
. β1 = γ0 = 0. Specifický model se zpožděnou exogenní proměnnou se nazývá modelem předbíhajícího indikátoru, tj. leading indicator equation.")
70
β1 = 1, γ0 = –γ1 Při takovýchto hodnotách parametrů se jedná o rovnici v prvních diferencích. β1 = 0 Model bez zpožděné endogenní proměnné se nazývá konečný distributed lag model prvního řádu, tj. DL(1) (viz předchozí výklad významu parametrů DL modelu). γ1 = 0 Za předpokladu nulové restrikce na parametr γ1 je model nazýván modelem částečného přizpůsobení. γ0 = 0 V situaci uvalení nulové restrikce na parametr γ0 se jedná o tzv. „dead-start“ model se zpožděnou informací.
 (viz předchozí výklad významu parametrů DL modelu). γ1 = 0. Za předpokladu nulové restrikce na parametr γ1 je model nazýván modelem částečného přizpůsobení. γ0 = 0. V situaci uvalení nulové restrikce na parametr γ0 se jedná o tzv. „dead-start model se zpožděnou informací.")
71
γ1 = –β1 Model, ve kterém parametr γ1 = –β1 je označován jako model proporcionální odezvy a vysvětlujícími proměnnými jsou xt a (yt-1 – xt-1). β1 – 1 = –(γ0 + γ1) Případ 9, tj. model, kde β1 – 1 = –(γ0 + γ1), je poněkud složitější v odvození. Pro získání jeho tvaru je nutné vyjádřit model ADL(1,1) v prvních diferencích s kointegračním vektorem, tj. s error-correction mechanismem. Je tudíž třeba od obou stran rovnice ADL(1,1) odečíst yt-1 a přičíst a odečíst γ0xt-1 k pravé straně rovnice. Po určitém zjednodušení lze dospět ke vztahu:
 Případ 9, tj. model, kde β1 – 1 = –(γ0 + γ1), je poněkud složitější v odvození. Pro získání jeho tvaru je nutné vyjádřit model ADL(1,1) v prvních diferencích s kointegračním vektorem, tj. s error-correction mechanismem. Je tudíž třeba od obou stran rovnice ADL(1,1) odečíst yt-1 a přičíst a odečíst γ0xt-1 k pravé straně rovnice. Po určitém zjednodušení lze dospět ke vztahu:")
72
Tato rovnice obsahuje error-correction mechanismus typu (yt-1 – xt-1), jestliže je splněna podmínka β1 – 1 = –(γ0 + γ1).
, jestliže je splněna podmínka β1 – 1 = –(γ0 + γ1).")
73
γ1 = –β1 γ0 Restrikce 10 je nazývána common factor nebo též COMFAC restrikce.

74
Předpoklady modelu ADL
E(ut|yt-1, …, yt-n, x1t, x1t-1, …, x1t-p, …., xkt, xkt-1, …, xkt-p) = 0; (a) náhodné proměnné (yt, x1t, … , xkt) jsou stacionární; (b) (yt, x1t, … , xkt) a (yt-j, x1t-j, … , xkt-j) jsou nezávislé s dostatečně velkým j; x1t, … , xkt a yt mají nenulové a konečné první čtyři momenty; nepřítomnost perfektní multikolinearity.
 = 0; (a) náhodné proměnné (yt, x1t, … , xkt) jsou stacionární; (b) (yt, x1t, … , xkt) a (yt-j, x1t-j, … , xkt-j) jsou nezávislé s dostatečně velkým j; x1t, … , xkt a yt mají nenulové a konečné první čtyři momenty; nepřítomnost perfektní multikolinearity.")
75
Volba délky zpoždění ADL (n,p) modelu
F-test Maximalizace korigovaného R2 Minimalizace Akaikeho informačního kritéria Minimalizace Bayesova (nebo také Schwarzova) informačního kritéria
 informačního kritéria.")
77
Ačkoliv jsou informační kritéria založena na stejném principu, tj
Ačkoliv jsou informační kritéria založena na stejném principu, tj. ohodnocení efektů a nákladů zahrnutí dodatečných zpožděných proměnných, mohou poskytovat vzhledem k různému ocenění těchto efektů či nákladů různé výsledky. Volba správné délky zpoždění pak závisí na postojích a preferencích autora modelu.

78
Přechod od obecného modelu ke specifickému
Testování významnosti i-tého zpoždění F-test Grangerova kauzalita Test Grangerovy kauzality Statistika Grangerovy kauzality – F-test

79
Odvození prognózy z ADL (n,p) modelu
Krátkodobá prognóza fn,1 nebo ŷt+1 = b0 + b1yt + c1xt fn,1 nebo ŷt+1 = b0 + b1yt + b2yt-1 +…+ bnyt-n+1 + c11x1t +…+ c1px1t-p+1 +…+ ck1xkt +…+ ckpxkt-p+1 Situace je o něco složitější obsahuje-li ADL (n,p) model vysvětlující proměnnou x, resp. proměnné x1, ..., xk v běžném období t.
 model vysvětlující proměnnou x, resp. proměnné x1, ..., xk v běžném období t.")
80
Odvození prognózy z ADL (n,p) modelu
Střednědobá a dlouhodobá prognóza fn,2 nebo ŷt+2 = b0 + b1 ŷt+1 + b2yt +…+ bnyt-n+2 + c10x´1t+2 + c11x´1t+1 +…+ c1px1t-p+2 +…+ ck0x´kt+2 + ck1x´kt+1 + …+ ckpxkt-p+2 fn,h nebo ŷt+h = b0 + b1 ŷt+h-1 + b2yt+h-2 +…+ bnyt-n+h + c10x´1t+h + c11x´1t+h-1 +…+ c1px1t-p+h +…+ ck0x´kt+h + ck1x´kt+h-1 + …+ ckpxkt-p+h

81
Chyba prognózy Chyba prognózy se skládá ze dvou komponentů. Prvním je nejistota plynoucí z odhadu regresních koeficientů, jež má pravděpodobnostní charakter, a to i přesto, že je při splnění všech předpokladů nejlepším (lineárním), konzistentním a nestranným odhadem. Druhým komponentem je nejistota spojená s budoucí neznámou hodnotou náhodné složky – ut. Velikost typické chyby vzniklé použitím prognostického modelu lze vyjádřit pomocí RMSFE (Root Mean Squared Forecast). RMSFE je vypočtena jako odmocnina průměru čtverce chyby prognózy.
, konzistentním a nestranným odhadem. Druhým komponentem je nejistota spojená s budoucí neznámou hodnotou náhodné složky – ut. Velikost typické chyby vzniklé použitím prognostického modelu lze vyjádřit pomocí RMSFE (Root Mean Squared Forecast). RMSFE je vypočtena jako odmocnina průměru čtverce chyby prognózy.")
82
RMFSE

83
Interval prognózy Za předpokladu normálního rozdělení náhodné složky je interval spolehlivosti prognózy dán vztahem:

84
Ex-post prognóza Ex-post prognóza je využívána k ověření prognostických vlastností modelu, k odhadu RMSFE a k porovnání prognostických modelů mezi sebou.

85
ADL model (aplikace) – Prognóza cen zemědělských výrobců
QSZt = f(CZVt-h| MCt-h,…); h = 1, …, n CZVt = f(QSZt – QDZt) QDZt = f(MRt-h – CZVt-h = 0| …) Substitucí funkcí nabídky a poptávky ve vztahu CZVt = f(QSZt – QDZt) lze dospět k redukované formě modelu cenové transmise, tj. CZVt = f(CZVt-h, CPVt-h| ….)
; h = 1, …, n. CZVt = f(QSZt – QDZt) QDZt = f(MRt-h – CZVt-h = 0| …) Substitucí funkcí nabídky a poptávky ve vztahu CZVt = f(QSZt – QDZt) lze dospět k redukované formě modelu cenové transmise, tj. CZVt = f(CZVt-h, CPVt-h| ….)")
86
Obecný model CZVt = β0 + β1CZVt-1 +…+ βnCZVt-n + γ11CPV1t-1 + … + γ1pCPV1t-p + ut kde β0, …, βn a γ10, …, γ1p jsou neznámé parametry pro n zpožděných hodnot endogenní proměnné a p zpoždění exogenní proměnné a ut je náhodná složka s nulovým podmíněným průměrem, tj. E(ut|yt-1, …, yt-n, xt, xt-1, …, xt-p) = 0.
 = 0.")
87
DATA Časové řady cen zemědělských výrobců a cen potravinářských výrobců jsou získány z databáze ARAD ČNB. Časové řady mají měsíční periodicitu a reprezentují období ledna 1995 až července 2005, tj. 127 pozorování.

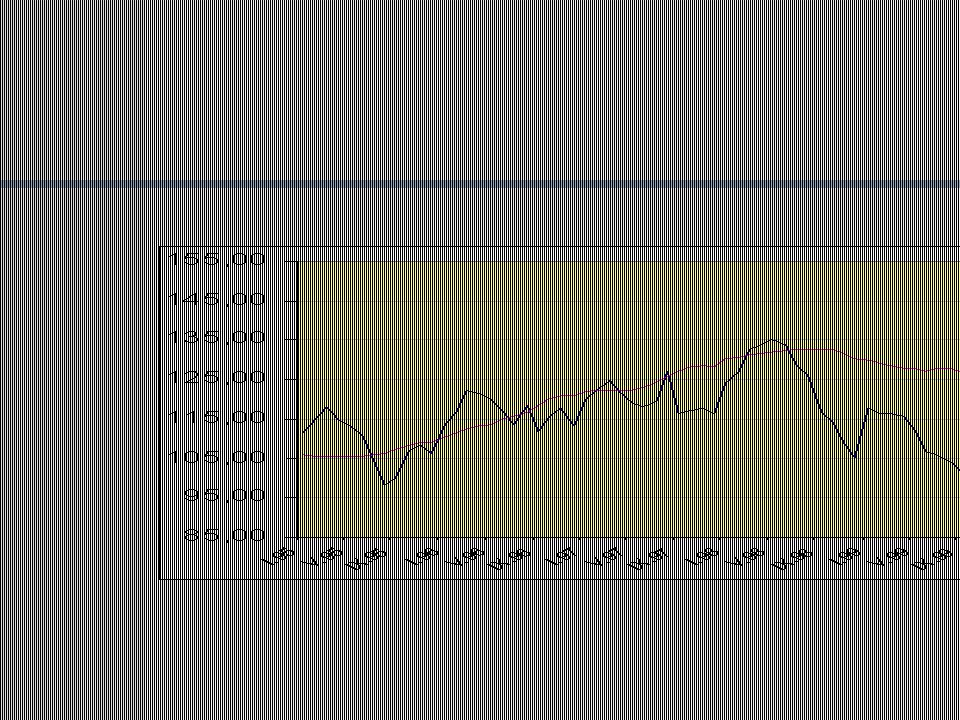
91
Transformace dat Ceny zemědělských výrobců (CZV) a ceny průmyslových výrobců (CPV) – meziroční změny
 a ceny průmyslových výrobců (CPV) – meziroční změny.")
92
Postupné diference CZV (dCZV) a CPV (dCPV) - z dat meziročních změn
 a CPV (dCPV) - z dat meziročních změn")
93
Ceny zemědělských výrobců (CZV) a ceny průmyslových výrobců (CPV) – sezónně očištěné
 a ceny průmyslových výrobců (CPV) – sezónně očištěné")
94
Postupné diference CZV-sezónně oč., CPV a CPV-sezónně oč

95
Autokorelační koeficienty
Zpoždění Indexy cen průměr 1994=100 Meziroční změny cen Index cen průměr 1994=100 – sezónně očištěno CZV CPV dCZV dCPV CZVo CPVo dCZVo dCPVo 1 0,929 0,983 0,320 0,629 0,851 0,998 0,119 0,543 0,920 0,997 0,241 0,206 2 0,810 0,944 -0,058 0,479 0,666 0,994 0,077 0,411 0,799 0,992 -0,083 0,146 3 0,696 0,890 -0,078 0,384 0,461 0,989 0,070 0,426 0,692 0,986 -0,079 0,133 4 0,587 0,823 -0,015 0,370 0,232 0,982 -0,225 0,331 0,594 0,979 0,092 5 0,477 0,742 -0,044 0,321 0,974 -0,197 0,287 0,496 0,972 -0,070 0,316 6 0,372 0,651 -0,003 0,257 -0,036 0,965 -0,322 0,277 0,408 0,962 0,087 7 0,275 0,554 0,069 0,150 -0,051 0,954 -0,172 0,182 0,325 0,951 -0,023 0,261 8 0,178 0,458 0,122 0,072 0,942 -0,194 0,138 0,242 0,938 0,135 -0,010 9 0,066 0,362 0,166 -0,011 0,108 0,157 0,140 0,924 0,115 -0,018 10 -0,080 0,267 0,026 -0,098 0,914 0,111 0,014 0,020 0,910 11 -0,231 0,175 -0,100 -0,245 0,164 0,899 0,028 -0,086 -0,095 0,896 -0,017 -0,134 12 -0,362 0,094 -0,383 -0,491 0,189 0,884 0,632 0,010 -0,205 0,883 0,455 13 -0,431 0,032 -0,307 -0,353 0,033 0,867 -0,054 -0,149 -0,314 0,864

96
Dependent variable: dCZV
ADL z meziročních změn Total observations: 127 Usable observations: 114 (1996:02 to 2005:07) Dependent variable: dCZV R2: 0,275 SEE: 3,2654 DW-test: 2,0108 SSR: 1164,418 Variable Coefficient P-value dCZV (1) 0,179827 0,0463 dCZV (12) -0,306588 0,0011 dCPV (1) 0, 0,0730 dCPV (12) -0,774379 0,0741 Specification tests T-Stat. Significance level A: Tests for Autocorrelation LM(1) 0,03689 0,84768 LM(4) 9,32449 0,05348 B: Tests for Heteroscedasticity Breusch-Pagan test 6,7595 0,07997 C: Functional Form Tests RESET test with quadratic 0,00216 0,96299 RESET test with quadratic and cubic 0,0063 0,99372 D: Tests for Normality BJ test 8,31716 0,01563 E: Structural Stability Tests Chow test 0,87207 0,45809
 Dependent variable: dCZV. R2: 0,275. SEE: 3,2654. DW-test: 2,0108. SSR: 1164,418. Variable. Coefficient. P-value. dCZV (1) 0, ,0463. dCZV (12) -0, ,0011. dCPV (1) 0, ,0730. dCPV (12) -0, ,0741. Specification tests. T-Stat. Significance level. A: Tests for Autocorrelation. LM(1) 0, , LM(4) 9, , B: Tests for Heteroscedasticity. Breusch-Pagan test. 6, , C: Functional Form Tests. RESET test with quadratic. 0, , RESET test with quadratic and cubic. 0, , D: Tests for Normality. BJ test. 8, , E: Structural Stability Tests. Chow test. 0, ,")
97
Odvození prognózy CZV Období Prognóza dCZV Prognóza CZV
Skutečné hodnoty CZV Chyba prognózy VIII.05 1,6811 90,6811 91,50 0,8189 IX.05 2,5747 93,2558 93,30 0,0442 X.05 0,8152 94,0711 93,70 -0,3711 XI.05 -0,7437 93,3274 94,00 0,6726 XII.05 1,5110 94,8385 94,80 -0,0385

98
Dependent variable: dCZV
ADL z indexu 1994=100 Total observations: 127 Usable observations: 113 (1996:03 to 2005:07) Dependent variable: dCZV R2: 0,1909 SEE: 2,9941 DW-test: 2,0886 SSR: 959,19 Variable Coefficient P-value dCZV (1) 0,2169 0,0265 dCZV (2) -0,2057 0,0311 dCZV (13) -0,2132 0,0215 dCPV (1) 0,6562 0,0871 dCPV (2) 0,2492 0,3956 dCPV (13) -0,6835 0,0580 Specification tests T-Stat. Significance level A: Tests for Autocorrelation LM(1) 2,06817 0,1504 LM(4) 7,94291 0,0937 B: Tests for Heteroscedasticity Breusch-Pagan test 9,36495 0,0248 C: Functional Form Tests RESET test with quadratic 5,72859 0,0184 RESET test with quadratic and cubic 3,3175 0,0401 D: Tests for Normality BJ test 8,20156 0,0166 E: Structural Stability Tests Chow test 1,21043 0,3098
 Dependent variable: dCZV. R2: 0,1909. SEE: 2,9941. DW-test: 2,0886. SSR: 959,19. Variable. Coefficient. P-value. dCZV (1) 0, ,0265. dCZV (2) -0, ,0311. dCZV (13) -0, ,0215. dCPV (1) 0, ,0871. dCPV (2) 0, ,3956. dCPV (13) -0, ,0580. Specification tests. T-Stat. Significance level. A: Tests for Autocorrelation. LM(1) 2, ,1504. LM(4) 7, ,0937. B: Tests for Heteroscedasticity. Breusch-Pagan test. 9, ,0248. C: Functional Form Tests. RESET test with quadratic. 5, ,0184. RESET test with quadratic and cubic. 3, ,0401. D: Tests for Normality. BJ test. 8, ,0166. E: Structural Stability Tests. Chow test. 1, ,3098.")
99
Odvození prognózy CZV Období Prognóza dCZVso Prognóza CZVso
Skutečné hodnoty CZV Chyba prognózy VIII.05 -1,8622 -5,8387 110,3251 108,2929 -2,0321 IX.05 0,7092 -5,1295 105,8980 103,1604 -2,7376 X.05 1,9833 -3,1463 110,3234 106,8399 -3,4835 XI.05 0,5819 -2,5644 110,5036 108,0690 -2,4346 XII.05 -0,3093 -2,8737 106,6251 103,8608 -2,7643

100
Porovnání prognóz Období Prognóza dCZV Prognóza CZV
Skutečné hodnoty CZV Chyba prognózy VIII.05 1,6811 90,6811 91,50 0,8189 IX.05 2,5747 93,2558 93,30 0,0442 X.05 0,8152 94,0711 93,70 -0,3711 XI.05 -0,7437 93,3274 94,00 0,6726 XII.05 1,5110 94,8385 94,80 -0,0385 Období Prognóza dCZVso Prognóza CZVso Prognóza CZV Skutečné hodnoty CZV Chyba prognózy VIII.05 -1,8622 -5,8387 110,3251 108,2929 -2,0321 IX.05 0,7092 -5,1295 105,8980 103,1604 -2,7376 X.05 1,9833 -3,1463 110,3234 106,8399 -3,4835 XI.05 0,5819 -2,5644 110,5036 108,0690 -2,4346 XII.05 -0,3093 -2,8737 106,6251 103,8608 -2,7643

101
VAR model modelovaný vztah cenové transmise s použitím ADL modelu opomíjí jeden důležitý ekonomický aspekt vztahů v zemědělsko-potravinářské vertikále, a to že tyto vztahy zřejmě mají simultánní povahu. V případě, že simultánní vztahy ve vertikále existují, což lze předpokládat (viz následující hypotéza), jejich opomenutím se dopouštíme chyby specifikace, která v lepším případě má za důsledek, že ztrácíme důležitou informaci o modelovaném vztahu.
, jejich opomenutím se dopouštíme chyby specifikace, která v lepším případě má za důsledek, že ztrácíme důležitou informaci o modelovaném vztahu.")
102
Rozšíření ekonomického modelu

104
Charakteristika VAR modelování
Vektorové autoregresní modely vycházejí z myšlenky, že všechny proměnné využité pro analýzu zvolené závislosti jsou náhodné a simultánně závislé. To znamená, že modelová struktura obsahuje pouze endogenní proměnné, přičemž jejich maximální délka zpoždění je stejná. Další charakteristikou je, že VAR model (jeho obecná forma) nevychází striktně z ekonomické teorii.
 nevychází striktně z ekonomické teorii.")
105
VAR model VAR(p) modely jsou zobecněním AR modelů na časové řady více proměnných a jejich předností je relativně jednoduchý odhad parametrů metodou nejmenších čtverců. Konstrukce modelů VAR se zpravidla rozpadá do následujících kroků: transformace dat na stacionární časové řady (testy jednotkových kořenů), volba proměnných modelu a maximální délky zpoždění, zjednodušení modelu redukcí maximálního zpoždění a ortogonalizace reziduí.
 modely jsou zobecněním AR modelů na časové řady více proměnných a jejich předností je relativně jednoduchý odhad parametrů metodou nejmenších čtverců. Konstrukce modelů VAR se zpravidla rozpadá do následujících kroků: transformace dat na stacionární časové řady (testy jednotkových kořenů), volba proměnných modelu a maximální délky zpoždění, zjednodušení modelu redukcí maximálního zpoždění a. ortogonalizace reziduí.")
106
VAR model Model VAR(p) lze zapsat ve formě, přičemž se předpokládá, že CS = 0 pro s > p: . kde Xt reprezentuje k proměnných modelu, tj. v případě dvou proměnných je

107
Volba počtu proměnných a délky zpoždění ve VAR modelu, tj
Volba počtu proměnných a délky zpoždění ve VAR modelu, tj. počet k a velikost p, je v praxi často spojena s nutností uvalení nulových restrikcí, a to v závislosti na délce disponibilních časových řad. Například při zahrnutí tří proměnných do VAR modelu a při délce zpoždění 5 období je v každé rovnici odhadováno nejméně 15 parametrů (tj. v případě, že model neobsahuje deterministickou složku).
.")
108
Volbu délky zpoždění ve VAR modelu lze založit stejně jako u ADL modelu na informačních kritériích (viz AIC, SIC, aj.). Velmi důležitým ale též často přehlíženým rysem VAR modelu je, že náhodné složky výše uvedeného vztahu mají nenulové kovariance. Tento významný rys umožňuje odvození „strukturální“ alternativy ke klasickým ekonometrickým modelům, která je konzistentní s danou ekonomickou teorií a umožňuje aplikaci modelu v ekonomické analýze.

109
Ortogonalizace reziduí
Odvození „strukturální“ alternativy spočívá v transformaci VAR modelu do formy mající „ortogonální inovace“ (ortogonalní rezidua). Jinak řečeno model je transformován tak, aby neobsahoval korelované náhodné složky. Postup ortogonalizace reziduí lze názorně demonstrovat na příkladu jednoduchého VAR modelu obsahujícího dvě proměnné xt a yt a majícího dvě zpoždění ve VAR prostoru.
. Jinak řečeno model je transformován tak, aby neobsahoval korelované náhodné složky. Postup ortogonalizace reziduí lze názorně demonstrovat na příkladu jednoduchého VAR modelu obsahujícího dvě proměnné xt a yt a majícího dvě zpoždění ve VAR prostoru.")
110
kde náhodné složky jsou souběžně korelovány, tj:

111
Pro získání modelu, ve kterém nebudou náhodné složky souběžně korelovány, lze první řádek vztahu vynásobit a výsledek odečíst od druhého řádku.

112
kde Souběžnou nezkorelovanost náhodných složek lze dokázat následovně:

113
Hodnoty σij jsou zpravidla neznámé a musí být odhadnuty
Hodnoty σij jsou zpravidla neznámé a musí být odhadnuty. Myšlenka ortogonalizace reziduí spočívá v možnosti využití jednotlivých rovnic VAR modelu odděleně v ekonomické analýze. V tomto smyslu lze ekonomickou analýzu chápat jako analýzu, která se zabývá vlivem známého šoku nebo též „ortogonální inovace“ na zkoumaný systém (vztah)
")
114
Impulse-response analýza
Výše uvedený proces ortogonalizace reziduí lze využít v dynamické simulaci, ve které zkoumáme reakce proměnných na jednotlivé exogenní šoky (inovace) v čase t. Jinými slovy se zajímáme o to, jak se bude měnit proměnná y při jednotkové změně x. V případě dvourovnicového VAR(1) modelu lze takovouto změnu zkoumat tak, že se o jednotku bude měnit náhodná složka u1t rovnice x, která bude determinovat y. Výsledný efekt je stejný jako, když by se měnila o jednotku proměnná x.
 v čase t. Jinými slovy se zajímáme o to, jak se bude měnit proměnná y při jednotkové změně x. V případě dvourovnicového VAR(1) modelu lze takovouto změnu zkoumat tak, že se o jednotku bude měnit náhodná složka u1t rovnice x, která bude determinovat y. Výsledný efekt je stejný jako, když by se měnila o jednotku proměnná x.")
115
Impulse-response funkce
kde

116
Význam elementů v I-R funkci
Význam pro jednotlivá i lze vymezit následovně: reprezentuje očekávaný okamžitý vliv jednotkové změny v u1t na yt . je očekávaná reakce v prvním období na jednotkovou změnu v u1t na yt .

117
Odvození prognózy z VAR modelu
VAR modely poskytují dvě velké výhody při jejich aplikaci v prognostické činnosti. Jednak nemusíme věnovat takovou pozornost ekonomické teorii při specifikaci modelu, a to vzhledem k tomu, že zde nerozlišujeme mezi endogenními a exogenními proměnnými a dále zde nejsou uvalovány žádné nulové restrikce. Druhou a důležitější výhodou je, že se nemusí přijímat žádné předpoklady o hodnotách exogenních proměnných v prognostickém horizontu ve srovnání se standardními ekonometrickými prognózami, které jsou podmíněné na znalostech hodnot exogenních proměnných.

118
Je-li abstrahováno od korelace mezi rezidui jednotlivých rovnic, lze prognózu z VAR modelu odvodit mechanicky. V prvním období je způsob analogický odvození prognózy z ADL modelu, tj. dosazením známých hodnot zahrnutých proměnných v modelovaném vztahu. Pro další období prognostického horizontu se prognóza odvodí rekurzivně podmíněně na prognózách v obdobích, pro které skutečné hodnoty nejsou známy. To lze přehledně zapsat následovně:

120
Dependent variable: dCZV Dependent variable: dCPV
VAR model - příklad Total observations: Monthly Data From: 1995:01 To 2005:07 Usable observations: 113 (1996:03 to 2005:07) Degrees of Freedom: 105 Dependent variable: dCZV Dependent variable: dCPV R2: 31,93 SEE: 3,2258 R2: 0,62 SEE: 0,4969 DW-test: 2,0629 SSR: 1092,6035 DW-test: 2,0752 SSR: 25,9261 Variable Coefficient p-value dCZV (1) 0,16025 0,1066 dCPV (1) 0,4388 0,0000 dCZV (2) -0,2094 0,2800 dCPV (2) 0,1854 0,0227 dCZV (12) -0,2741 0,0046 dCPV (12) -0,5397 dCZV (13) -0,1641 0,1161 dCPV (13) 0,0019 1,0272 0,0930 0,0312 0,0423 0,4898 0,3488 0,0146 0,3164 -0,5021 0,3669 0,0315 0,0330 0,0990 0,8626 0,0011 0,9428 F-Test F-statistic dCZV 5,5941 0,0004 dCPV 29,6004 2,9671 0,0229 2,7889 0,0301
 Degrees of Freedom: 105. Dependent variable: dCZV. Dependent variable: dCPV. R2: 31,93. SEE: 3,2258. R2: 0,62. SEE: 0,4969. DW-test: 2,0629. SSR: 1092,6035. DW-test: 2,0752. SSR: 25,9261. Variable. Coefficient. p-value. dCZV (1) 0, ,1066. dCPV (1) 0, ,0000. dCZV (2) -0, ,2800. dCPV (2) 0, ,0227. dCZV (12) -0, ,0046. dCPV (12) -0,5397. dCZV (13) -0, ,1161. dCPV (13) 0, , , , , , , , , , , , , , , , ,9428. F-Test. F-statistic. dCZV. 5, ,0004. dCPV. 29, , , , ,0301.")
121
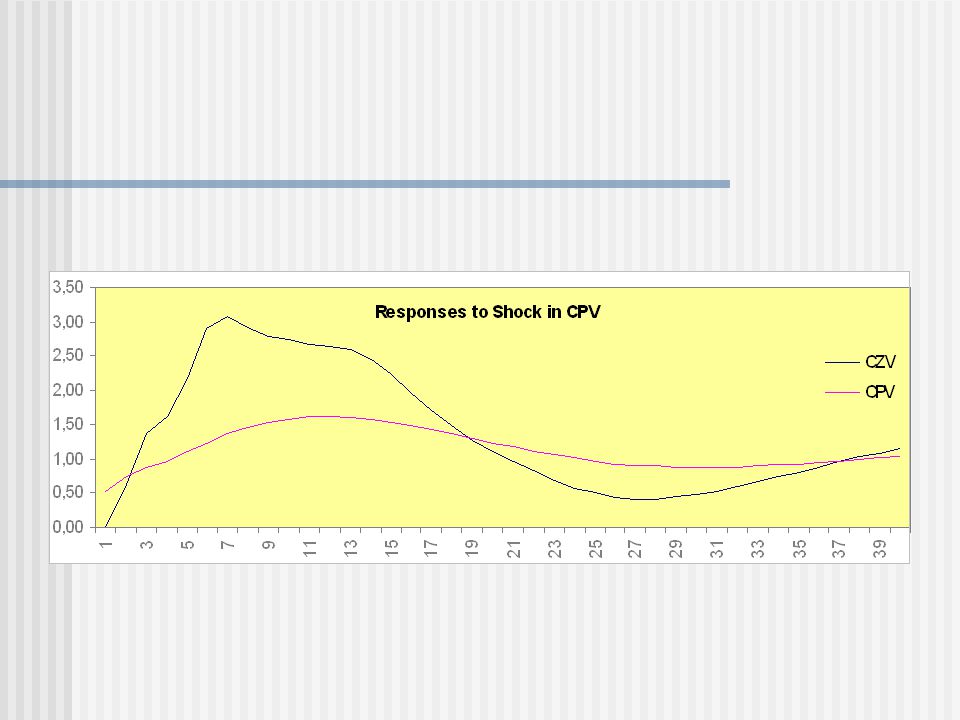
Impulse-response analýza

123
Dekompozice rozptylu dCZV
Decomposition of Variance for Series dCZV Step Std Error dCZV dCPV 1 3, 100,000 0,000 2 3, 97,880 2,120 3 3, 95,574 4,426 4 3, 94,916 5,084 5 3, 94,679 5,321 6 3, 94,479 5,521 7 3, 94,334 5,660 8 3, 94,253 5,747 9 3, 94,210 5,790 10 3, 94,183 5,817 11 3, 94,167 5,833 12 3, 94,157 5,843 13 3, 94,239 5,761 14 3, 93,073 6,927 15 3, 91,261 8,739 16 3, 90,402 9,598 17 3, 90,010 9,990 18 3, 89,721 10,279

124
Dekompozice rozptylu dCPV
Decomposition of Variance for Series dCPV Step Std Error dCZV dCPV 1 0, 9,679 90,324 2 0, 16,417 83,583 3 0, 21,141 78,859 4 0, 22,173 77,827 5 0, 22,498 77,502 6 0, 22,776 77,224 7 0, 22,971 77,029 8 0, 23,074 76,926 9 0, 23,129 76,871 10 0, 23,163 76,837 11 0, 23,184 76,816 12 0, 23,196 76,804 13 0, 20,758 79,242 14 0, 20,754 79,246 15 0, 21,811 78,189 16 0, 22,182 77,818 17 0, 22,177 77,823 18 0, 22,236 77,764

125
Odvození prognózy Prognóza dCZV Prognóza dCPV Prognóza CZV
Prognóza CPV Chyba prognózy CZV Chyba prognózy CPV -0,7008 -0,1025 88,299 97,897 3,201 0,103 2,8115 0,0310 94,312 98,031 -1,012 -0,331 1,5479 0,0856 94,848 97,786 -1,148 -0,386 -1,1313 0,3575 92,569 97,757 1,431 -0,557 0,5294 0,5901 94,529 97,790 0,271 -1,290

126
Kointegrační analýza Transformací, tzn. převodem nestacionárních časových řad na stacionární (např. diferencováním u řad majících stochastický trend) ztrácí časové řady z ekonomického hlediska velmi důležitou informaci o jejich dlouhodobých vztazích. Kointegrační analýza umožňuje řešit rozpor vzniklý mezi statistickými požadavky a ekonomickými potřebami.
 ztrácí časové řady z ekonomického hlediska velmi důležitou informaci o jejich dlouhodobých vztazích. Kointegrační analýza umožňuje řešit rozpor vzniklý mezi statistickými požadavky a ekonomickými potřebami.")
127
Nyní mohou nastat 3 situace:
Předpokládejme, že proměnné Yt a Xt jsou integrované stejného řádu a vyjádřeme jejich vztah v jednoduchém statickém modelu: Yt = γXt + ut Nyní mohou nastat 3 situace: proces ut má charakter bílého šumu, tj. je typu I(0), proces ut je stacionární a autokorelovaný a je rovněž typu I(0), proces ut je typu I(1), tj. je integrován řádem jedna.
, proces ut je stacionární a autokorelovaný a je rovněž typu I(0), proces ut je typu I(1), tj. je integrován řádem jedna.")
128
V prvním případě jsou proměnné kointegrovány, tzn
V prvním případě jsou proměnné kointegrovány, tzn. je mezi nimi dlouhodobý vztah (směřují k rovnovážnému stavu). Dlouhodobým multiplikátorem je regresní parametr γ. V druhém případě jsou proměnné taktéž kointegrovány. V této situaci lze psát ut = βut-1 + t , kde t je proces bílého šumu, pak model lze přepsat do tvaru ADL (1,1), tj.: Yt = βYt-1 + γXt - βXt-1 + t Dlouhodobý multiplikátor () vyjadřující dlouhodobý vztah má v tomto případě podobu: = γ (1+β)/(1-β) Poslední případ neobsahuje kointegrované časové řady a tudíž neobsahuje dlouhodobý multiplikátor.
. Dlouhodobým multiplikátorem je regresní parametr γ. V druhém případě jsou proměnné taktéž kointegrovány. V této situaci lze psát ut = βut-1 + t , kde t je proces bílého šumu, pak model lze přepsat do tvaru ADL (1,1), tj.: Yt = βYt-1 + γXt - βXt-1 + t. Dlouhodobý multiplikátor () vyjadřující dlouhodobý vztah má v tomto případě podobu: = γ (1+β)/(1-β) Poslední případ neobsahuje kointegrované časové řady a tudíž neobsahuje dlouhodobý multiplikátor.")
129
Myšlenka kointegrační analýzy
Myšlenka kointegrační analýzy je založena na vztahu, který mají ekonomické proměnné mezi sebou v dlouhém období. Takovýto vztah může být konvergující k rovnovážnému stavu v dlouhém období nebo naopak divergující. Jestliže ekonomické proměnné od sebe v krátkém období divergují a tato divergence nemá hranice, pak mezi proměnnými rovnovážný stav není. Je-li ovšem divergence od rovnovážného vztahu v určitých mezích, resp. stochastická, a po určitém čase se vytrácí, pak lze proměnné označit za kointegrované, jelikož v dlouhém období směřují k rovnovážnému vztahu.

130
Definice kointegrace Engle a Granger (1987) definují kointegraci mezi dvěma proměnnými následovně: Definice: časové řady xt a yt jsou kointegrovány řádu d, b, kde d>=b>=0 , v zápisu jako xt, yt ~ CI(d,b) , jestliže: obě časové řady jsou integrovány řádu d, existuje lineární kombinace těchto časových řad (proměnných), tj. α1xt + α2yt, která je integrována řádu d – b. Vektor [α1 , α2] se nazývá kointegrační vektor.
 , jestliže: obě časové řady jsou integrovány řádu d, existuje lineární kombinace těchto časových řad (proměnných), tj. α1xt + α2yt, která je integrována řádu d – b. Vektor [α1 , α2] se nazývá kointegrační vektor.")
131
V praktické aplikaci je nejzajímavější případ, kdy se časové řady při použití kointegračního vektoru stávají stacionárními, tj. kde d = b. V takovém případě obsahuje kointegrační vektor parametry dlouhodobého vztahu mezi proměnnými. Ekonomické časové řady jsou zpravidla integrovány řádu 1. Máme-li proměnné integrovány řádu 1 potom, aby byly kointegrovány musí splňovat: x´t . α ~ CI(1 , 1).
.")
132
Důležitost kointegrační analýzy
Důležitost kointegrační analýzy v modelování nestacionárních časových řad lze vymezit dle Banerjee A., et al. (2003) v následujících třech bodech: Jestliže existuje rovnovážný vztah mezi proměnnými, tj. je-li lineární kombinace proměnných stacionární, pak lze počítat s tím, že tato lineární kombinace se vrací ke svému průměru (zpravidla nulovému). Ekonometrický model, který obsahuje nestacionární proměnné má smysl tehdy a jen tehdy, jsou-li proměnné kointegrovány. V opačném případě se jedná o tzv. zdánlivou regresi (spurious regression). Jestliže jsou proměnné kointegrovány, lze sestavit error-correction model, který obsahuje jak dlouhodobý vztah mezi proměnnými (tj. kointegrační vektor), tak odchylku proměnných od rovnovážného vztahu.
 v následujících třech bodech: Jestliže existuje rovnovážný vztah mezi proměnnými, tj. je-li lineární kombinace proměnných stacionární, pak lze počítat s tím, že tato lineární kombinace se vrací ke svému průměru (zpravidla nulovému). Ekonometrický model, který obsahuje nestacionární proměnné má smysl tehdy a jen tehdy, jsou-li proměnné kointegrovány. V opačném případě se jedná o tzv. zdánlivou regresi (spurious regression). Jestliže jsou proměnné kointegrovány, lze sestavit error-correction model, který obsahuje jak dlouhodobý vztah mezi proměnnými (tj. kointegrační vektor), tak odchylku proměnných od rovnovážného vztahu.")
133
VECM VECM lze formálně zapsat ve formě:
kde CS = 0 pro s > p, Xt je k x 1 vektor proměnných integrovaných řádu 1, tj. I(1), u1, …,ut jsou nid (0,Σ) a П je matice dlouhodobého vztahu.
, u1, …,ut jsou nid (0,Σ) a П je matice dlouhodobého vztahu.")
134
Konstrukce modelů VECM
Konstrukce modelů VECM se podobně jako konstrukce VAR modelu skládá z následujících kroků: testy jednotkových kořenů, určení (odhad) kointegračního vektoru, volba proměnných modelu a maximální délky zpoždění, odhad modelu, zjednodušení modelu redukcí maximálního zpoždění a ortogonalizace reziduí.
 kointegračního vektoru, volba proměnných modelu a maximální délky zpoždění, odhad modelu, zjednodušení modelu redukcí maximálního zpoždění a ortogonalizace reziduí.")
135
Dependent variable: dCZV Dependent variable: dCPV
VECM - příklad Total observations: Monthly Data From: 1995:01 To 2005:07 Usable observations: 121 (1995:07 to 2005:07) Degrees of Freedom: 95 Dependent variable: dCZV Dependent variable: dCPV R2: 0,3387 SEE: 3,2482 R2: 0,4816 SEE: 0,5960 DW-test: 1,9907 SSR: 1160,5650 DW-test: 2,0148 SSR: 39,0746 Variable Coefficient (p-value) Coefficient (value) dCZV (1) 0,3473 (0,0004) dCPV (1) 0,3942 (0,0002) dCZV (2) -0,1365 (0,1925) dCPV (2) 0,0401 (0,7071) dCZV (3) -0,0159 (0,8767) dCPV (3) -0,0804 (0,9408) dCZV (4) -0,0084(0,9311) dCPV (4) 0,0795 (0,4677) dCZV (5) -0,1443 (0,1362) dCPV (5) 0,0382 (0,6925) 0,9239 (0,0943) 0,0512 (0,0045) 0,5499 (0,3451) 0,0133 (0,4862) -0,0569 (0,9231) 0,0374 (0,0482) 1,0637 (0,0764) 0,0123 (0,4930) 0,9094 (0,0862) 0,0368 (0,0393) EC1 (1) -0,2526 (0,0001) -0,0196 (0,0796)
 Degrees of Freedom: 95. Dependent variable: dCZV. Dependent variable: dCPV. R2: 0,3387. SEE: 3,2482. R2: 0,4816. SEE: 0,5960. DW-test: 1,9907. SSR: 1160,5650. DW-test: 2,0148. SSR: 39,0746. Variable. Coefficient (p-value) Coefficient (value) dCZV (1) 0,3473 (0,0004) dCPV (1) 0,3942 (0,0002) dCZV (2) -0,1365 (0,1925) dCPV (2) 0,0401 (0,7071) dCZV (3) -0,0159 (0,8767) dCPV (3) -0,0804 (0,9408) dCZV (4) -0,0084(0,9311) dCPV (4) 0,0795 (0,4677) dCZV (5) -0,1443 (0,1362) dCPV (5) 0,0382 (0,6925) 0,9239 (0,0943) 0,0512 (0,0045) 0,5499 (0,3451) 0,0133 (0,4862) -0,0569 (0,9231) 0,0374 (0,0482) 1,0637 (0,0764) 0,0123 (0,4930) 0,9094 (0,0862) 0,0368 (0,0393) EC1 (1) -0,2526 (0,0001) -0,0196 (0,0796)")
136
Impulse-response analýza

138
Dekompozice rozptylu CZV
Decomposition of Variance for Series CZV Step Std Error CZV CPV 1 3, 100,000 0,000 2 4, 98,344 1,656 3 5, 93,312 6,688 4 6, 87,838 12,162 5 6, 80,082 19,918 6 7, 69,460 30,540 7 8, 61,130 38,870 8 9, 56,119 43,881 9 9, 52,636 47,364 10 10, 49,634 50,366 11 10, 46,930 53,070 12 10, 44,333 55,667 13 11, 41,952 58,048 14 11, 40,024 59,976 15 11, 38,581 61,419 16 11, 37,543 62,457 17 11, 36,847 63,153 18 12, 36,426 63,574

139
Dekompozice rozptylu CPV
Decomposition of Variance for Series CPV Step Std Error CZV CPV 1 0, 13,964 86,036 2 1, 19,645 80,355 3 1, 21,357 78,643 4 1, 22,642 77,358 5 2, 22,522 77,478 6 2, 22,585 77,415 7 3, 21,697 78,303 8 3, 20,127 79,873 9 3, 18,354 81,646 10 4, 16,694 83,306 11 4, 15,189 84,811 12 4, 13,871 86,129 13 5, 12,721 87,279 14 5, 11,713 88,287 15 5, 10,383 89,162 16 5, 10,102 89,898 17 5, 9,506 90,494 18 6, 9,045 90,955

140
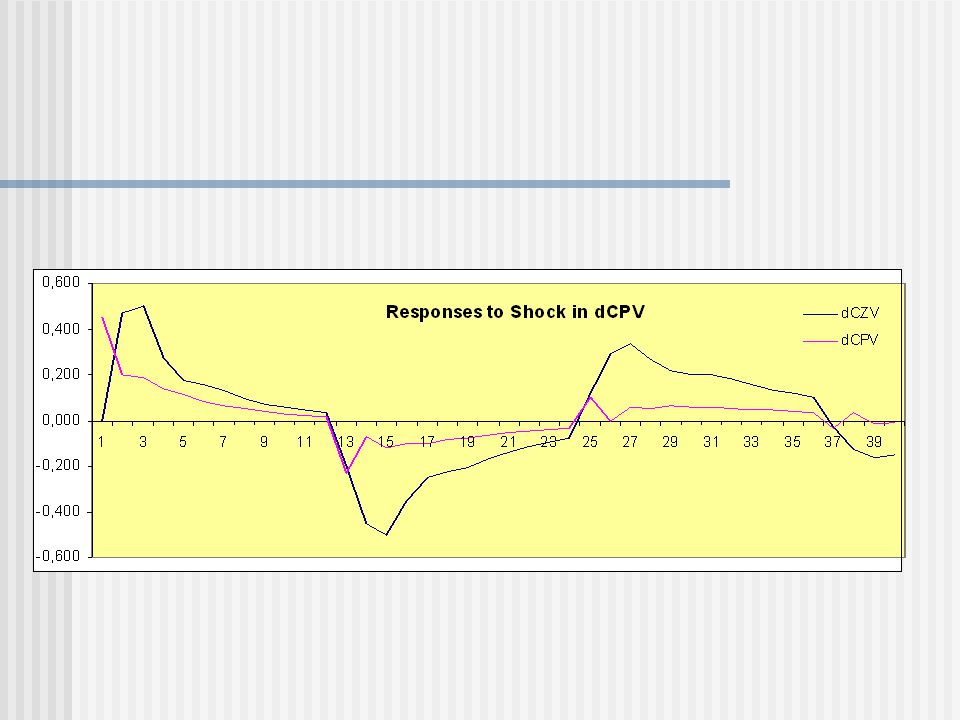
Odvození prognózy z VECM
Období Prognóza dCZV Prognóza dCPV Prognóza CZV Prognóza CPV Chyba prognózy CZV Chyba prognózy CPV VIII.05 -0,1191 -0,5608 88,881 97,439 2,619 0,561 IX.05 -0,3177 -0,3195 91,182 97,680 2,118 0,020 X.05 -1,3773 -0,1638 91,923 97,536 1,777 -0,136 XI.05 -1,9033 -0,0610 91,797 97,339 2,203 -0,139 XII.05 -0,9422 -0,3420 93,058 96,858 1,742 -0,358

141
Specific to general modeling
Specific-Genaral přístup je ekonometrickým přístupem, který reprezentuje tradiční ekonometrické modelování. Toto modelování je založeno na přesně definovaném vztahu (rovnici), který vychází z ekonomické teorie. Model je vystavěn na předpokladu nulového průměru náhodné složky, nepřítomnosti autokorelace a heteroskedasticity náhodné složky, specifikačních předpokladech a neexistenci perfektní multikolinearity. Z toho plyne, že za předpokladu stability prostředí nejčastěji používaná metoda nejmenších čtverců poskytuje nejlepší a nezkreslené lineární odhady.
, který vychází z ekonomické teorie. Model je vystavěn na předpokladu nulového průměru náhodné složky, nepřítomnosti autokorelace a heteroskedasticity náhodné složky, specifikačních předpokladech a neexistenci perfektní multikolinearity. Z toho plyne, že za předpokladu stability prostředí nejčastěji používaná metoda nejmenších čtverců poskytuje nejlepší a nezkreslené lineární odhady.")
142
Nevýhody tradičního přístupu
Testy statistických a ekonometrických vlastností modelu nemají stanovené pořadí. Vzhledem k neomezenému počtu diagnostických testů není zřejmé, zda-li byl odhadnut nejlepší model. Podmíněný charakter testů rovněž neumožňuje určit skutečnou hladinu významnosti aplikovaných testů, jelikož není známo skutečné rozdělení pravděpodobnosti.

143
Fáze ekonometrického modelování
Ekonomická teorie – studium dokumentu Tvorba ekonomického modelu Tvorba ekonometrického modelu Sběr, zpracování a analýza vstupních dat Odhad parametrů ekonometrického modelu Ekonomické ověření modelu – interpretovatelnost Statistické a ekonometrické ověření Aplikace ekonometrického modelu nebo jeho zamítnutí, které vrací postup k bodu (1)
")
144
„Základem každé vědy je soubor jistých znalostí
„Základem každé vědy je soubor jistých znalostí. To, co z těchto izolovaných poznatků dělá skutečnou vědu je, že tyto poznatky logicky uspořádáme, vytvoříme z nich systém. A k tomu slouží logika. Pomocí logického myšlení, logickým odvozováním získáváme z daných faktů nová fakta nebo hypotézy (poslední opět konfrontujeme s experimentem, neboť by se mohlo stát, že výchozí poznatky nezobrazují skutečnost správně)…“ (Kopáček, 2004).
… (Kopáček, 2004).")
145
P. Hebák ve své publikaci „Texty k bayesovské statistice“ (viz Hebák, 1999) uvádí následující: “Deduktivní úsudky – Logický důkaz se nazývá dedukcí. Závěr je získán jeho dedukováním z jiných tvrzení, které jsou označeny jako premisy (předpoklady) argumentu (závěru, důsledku). Jsou-li předpoklady správné, musí být správné i závěry z nich vyplývající. … Deduktivní úsudky však nemohou samy o sobě být dostatečným základem úsudků v ekonomii. Deduktivní úsudek zná pouze tři možnosti důkaz, vyvrácení a neprůkaznost. …“ a „Induktivní úsudky – Základním problémem vědeckého pokroku i každodenních rozhodnutí je schopnost využít zkušenosti. Znalost získaná tímto způsobem je částečně pouhým popisem pozorované skutečnosti a částečně předpovědí budoucí zkušenosti na základě minulé zkušenosti. Tato činnost, která spočívá v zobecnění, může být považována za induktivní úsudek. … Zjednodušený a nesprávný je názor, že indukce spočívá jen v empirickém ověřování existujících teorií a nepřináší nové myšlenky. Správné je považovat i zobecnění za část induktivního procesu.“
 uvádí následující: Deduktivní úsudky – Logický důkaz se nazývá dedukcí. Závěr je získán jeho dedukováním z jiných tvrzení, které jsou označeny jako premisy (předpoklady) argumentu (závěru, důsledku). Jsou-li předpoklady správné, musí být správné i závěry z nich vyplývající. … Deduktivní úsudky však nemohou samy o sobě být dostatečným základem úsudků v ekonomii. Deduktivní úsudek zná pouze tři možnosti důkaz, vyvrácení a neprůkaznost. … a „Induktivní úsudky – Základním problémem vědeckého pokroku i každodenních rozhodnutí je schopnost využít zkušenosti. Znalost získaná tímto způsobem je částečně pouhým popisem pozorované skutečnosti a částečně předpovědí budoucí zkušenosti na základě minulé zkušenosti. Tato činnost, která spočívá v zobecnění, může být považována za induktivní úsudek. … Zjednodušený a nesprávný je názor, že indukce spočívá jen v empirickém ověřování existujících teorií a nepřináší nové myšlenky. Správné je považovat i zobecnění za část induktivního procesu. .")
146
„…Bylo rozpoznáno, že vědci obecně uplatňují proces indukce, který zahrnuje (a) měření a popis a (b) použití zobecnění nebo teorie k vysvětlení, prognózování a přijímání rozhodnutí. …, pokusy o srovnávání vědy, obzvláště ekonomických věd, s dedukcí je fundamentální chybou, jelikož v dedukci jsou možné mezní tvrzení o důkazu, důkazu o opaku a neznalosti. Vědci potřebují a užívají tvrzení odrážející stupeň důvěry ve výroky a zevšeobecňování, což nemůže být analyzováno použitím pouze deduktivních metod.“(Zellner, 2004).
..")
147
Při odvození ekonomického modelu je třeba respektovat některé důležité aspekty tohoto kroku. Tinbergen (1951; in Charemza et al. (2003)) v této souvislosti říká, že: „první věcí, kterou je třeba udělat v důkladné aplikaci, je rozhodnout o správné ekonomické analýze zkoumaných vztahů … Dvou věcí si musíme být neustále vědomi: i) je nezbytné vědět, o jaký vztah se přesně zajímáme, a ii) znát faktory vstupující do tohoto vztahu“.
) v této souvislosti říká, že: „první věcí, kterou je třeba udělat v důkladné aplikaci, je rozhodnout o správné ekonomické analýze zkoumaných vztahů … Dvou věcí si musíme být neustále vědomi: i) je nezbytné vědět, o jaký vztah se přesně zajímáme, a ii) znát faktory vstupující do tohoto vztahu ..")
148
Znalost daného vztahu a faktorů, které ho determinují, je nezbytná pro odvození ekonomického modelu. Jinými slovy ekonomický model musí splňovat specifikační předpoklady. V této souvislosti se jedná o předpoklad zahrnutí podstatných proměnných do modelu, volby správné funkční formy, stability parametrů a předpoklad neexistence simultánního vztahu mezi endogenní proměnnou a exogenní, resp. exogenními proměnnými.

149
Předpoklady EM Specifikační předpoklady ekonometrického modelu
Neopomenutí podstatné vysvětlující proměnné; Vypuštění irelevantních vysvětlujících proměnných; Volba správné funkční formy modelu; Stabilní odhadnuté parametry, časová invariantnost; Respektování simultánnosti vztahů mezi proměnnými;

150
Předpoklad nulového průměru
Předpoklad homoskedasticity Předpoklad nepřítomnosti autokorelace reziduí Nezávisle proměnné jsou nenáhodné a fixní v opakujících se souborech Neexistence perfektní multikolinearity Normální rozdělení náhodné složky

151
Důsledky nedodržení předpokladů EM
Při výskytu autokorelace reziduí získané odhady běžnou metodou nejmenších čtverců jsou nezkreslené, ale nejsou nejlepší. Existují tedy jiné metody odhadu, které poskytují lepší výsledky, jako např. GLS (Generalized Least Squares). Při výskytu autokorelace metoda nejmenších čtverců podhodnocuje standardní chyby odhadu. To znamená, že t-hodnoty, R2 a F-testy jsou vysoce nespolehlivé.
. Při výskytu autokorelace metoda nejmenších čtverců podhodnocuje standardní chyby odhadu. To znamená, že t-hodnoty, R2 a F-testy jsou vysoce nespolehlivé.")
152
Přítomnost heteroskedasticity způsobuje, že odhadnuté parametry ekonometrického modelu jsou nezkreslené, ale nejsou nejlepší. Parametry mají velké chyby odhadu. Lepších odhadů může být dosaženo opět při použití GLS. Chyby parametrů získané BMNČ jsou zkreslené. Směr zkreslení závisí na vztahu mezi rozptylem náhodné složky a hodnotou nezávisle proměnné, která heteroskedasticitu způsobuje.

153
Při výskytu vysoké multikolinearity není možné separovat vlivy jednotlivých vysvětlujících proměnných na vysvětlovanou proměnou, jelikož proměnné se v čase pohybují obdobně, a to v závislosti na výši multikolinearity. Důsledkem vysoké multikolinearity je získání velkých chyb parametrů.

154
Dodržení předpokladu normálního rozdělení náhodné složky je důležité z toho důvodu, aby odhady parametrů pomocí běžné metody nejmenších čtverců měly taktéž normální rozdělení a testy statistických předpokladů měly t, F a χ2 rozdělení, tj. nebyly zavádějící.

Podobné prezentace