Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Jak najít potřebné informace
Rešeršní činnost aneb Jak najít potřebné informace

2
Univerzitní knihovna ZČU URL: http://www.knihovna.zcu.cz
Mgr. Miluše Mírková Univerzitní knihovna ZČU URL: Kompendium tel

3
Obsah Rešeršní činnost Typologie rešerší Postup rešerše
Závěr rešeršní činnosti Vyhledávání na internetu

4
Rešeršní činnost Motto: "Když jsem chtěl něco vynalézat, začal jsem studovat vše, co se v dané otázce udělalo v minulosti." (Thomas Alva Edison, , americký vynálezce a podnikatel)
")
5
Rešeršní činnost ve 2. polovině minulého století byla nastolena cesta k informační společnosti: ročně vychází kolem 70 tis. odborných vědeckých časopisů denně je publikováno 6-7 tis. vědeckých článků ročně vychází asi 300 tis. odborných monografií (knih celkem přes 800 tis. titulů) denně se přihlašuje asi 1000 patentů v současnosti žije 80-90% z celkového počtu vědců v dějinách lidstva 90% všech nových informací je obsaženo v pouhých 5% celkově publikovaných prací
 denně se přihlašuje asi 1000 patentů. v současnosti žije 80-90% z celkového počtu vědců v dějinách lidstva. 90% všech nových informací je obsaženo v pouhých 5% celkově publikovaných prací.")
6
Rešeršní činnost základní součástí informační přípravy jako výchozího bodu řešení úkolů je rešerše význam termínu rešerše: odvozuje se od francouzského „recherche“, což znamená hledání, vyhledávání, pátrání šetření, vyšetřování výzkum, průzkum, bádání, rešerše rešerší se nazývá vyhledávání informací z dostupných zdrojů (z katalogů, z databází, z internetu apod.) rešerše je: proces vyhledávání produkt vyhledávání
 rešerše je: proces vyhledávání. produkt vyhledávání.")
7
Základy vyhledávání rešeršní logika: logické postupy používané při rešeršní činnosti, zejména ve fázi sestavení rešeršního dotazu a jeho úprav rešeršní logika je základem rešeršní techniky, slouží správnému vyjádření dotazu

8
Základy vyhledávání základem rešeršní logiky jsou booleovské operátory (logické operátory) základem jsou booleovské operátory vyjadřují logické vztahy pomocí Vennových diagramů znázorněné množiny představující použití operátorů (tmavá barva zobrazuje vyhledanou množinu) logický součin logický součet logická negace
 logický součin logický součet logická negace.")
9
Základy vyhledávání operátor AND zužuje dotaz logický součin
operátor AND – univerzita AND Plzeň operátor AND zužuje dotaz univerzita Plzeň

10
Základy vyhledávání operátor OR dotaz rozšiřuje logický součet
operátor OR – vysoká škola OR univerzita operátor OR dotaz rozšiřuje vysoká škola univerzita

11
Základy vyhledávání operátor NOT odstraňuje nežádoucí dokumenty
logická negace operátor NOT – univerzita NOT Plzeň univerzita Plzeň operátor NOT odstraňuje nežádoucí dokumenty

12
Základy vyhledávání distanční operátory (proximitní operátory, operátory kontextové nebo operátory blízkosti) specifikují posloupnost a vzdálenost mezi dvěma vyhledávacími výrazy near - blízký adjacent (ADJ) - sousední followed by
 - sousední. followed by.")
13
Základy vyhledávání krácení podle slovních kořenů (truncation, stemming) hvězdička: * (asterisk) otazník: ? aj. může nahrazovat předpony zakončení slov například knihovn* současné vyhledání různých tvarů slov - krácení podle slovních kořenů (truncation, někdy také stemming) vynechávání počátečních nebo koncových částí slov a jejich nahrazení znakem hvězdička: * (asterisk) (nebo jiné znaky) lze nahradit předpony i zakončení slov například místo několika výrazů knihovna, knihovny, knihovník a knihovnictví je možné použít v dotazu pouze výraz knihovn* a systém vyhledá všechna slova tímto výrazem začínající tento způsob zjednodušuje a usnadňuje formulaci dotazu, jinak by se musely všechny tvary hledaných slov spojit v dotazu operátorem OR knihovna OR knihovny OR knihovník OR knihovnictví
 vynechávání počátečních nebo koncových částí slov a jejich nahrazení znakem hvězdička: * (asterisk) (nebo jiné znaky) lze nahradit předpony i zakončení slov. například místo několika výrazů knihovna, knihovny, knihovník a knihovnictví je možné použít v dotazu pouze výraz knihovn* a systém vyhledá všechna slova tímto výrazem začínající. tento způsob zjednodušuje a usnadňuje formulaci dotazu, jinak by se musely všechny tvary hledaných slov spojit v dotazu operátorem OR. knihovna OR knihovny OR knihovník OR knihovnictví.")
14
Základy vyhledávání používání zástupných znaků pro maskování (wild cards) hvězdička: * otazník: ? aj. může nahrazovat znaky uprostřed slova například filo?ofie velká a malá písmena – většina vyhledávačů je nerozlišuje způsob používání zástupných znaků pro maskování je u jednotlivých systémů poněkud odlišný - zjistit v nápovědě nahrazení písmen (jednoho nebo více) uprostřed slov například filo?ofie - vyhledá se filosofie i filozofie
 uprostřed slov. například filo ofie - vyhledá se filosofie i filozofie.")
15
Typologie rešerší rešerše lze členit podle různých hledisek do mnoha typů příklady používaných třídicích hledisek: hledisko úplnosti zahrnutých dokumentů: úplné rešerše (zachycují všechny zdroje) výběrové rešerše (zachycují zdroje výběrově podle zadaných kritérií)
 výběrové rešerše (zachycují zdroje výběrově podle zadaných kritérií)")
16
Typologie rešerší hledisko časové: jednorázové rešerše
doplňkové rešerše (doplněk k dříve uskutečněné rešerši) průběžné rešerše (prováděné s určenou periodicitou – případně i s jednorázovou retrospektivou) hledisko typu zahrnutých informací: dokumentografické (obsahují záznamy dokumentů) faktografické (obsahují přímo informace – fakta – například statistické údaje)
 průběžné rešerše (prováděné s určenou periodicitou – případně i s jednorázovou retrospektivou) hledisko typu zahrnutých informací: dokumentografické (obsahují záznamy dokumentů) faktografické (obsahují přímo informace – fakta – například statistické údaje)")
17
Postup rešerše základní etapy rešerše: příprava rešerše
informační průzkum nebo-li vyhledávání zpracování rešerše v podmínkách dialogových technologií se ostré hranice mezi těmito etapami ztrácejí a v průběhu provádění rešerše se plynule přechází z jedné do druhé a to i opakovaně např. část přípravných prací lze provádět až v průběhu vyhledávání a zpracování může být nedílnou součástí vyhledávání Internet vzhledem k dynamickému a distribuovanému charakteru vyžaduje poněkud jiné rešeršní strategie a techniky než komerční databázová centra. úspěšné vyhledávání v internetu předpokládá kromě jiného znalost, jak jít přímo ke zdroji informace, správně odhadnou URL adresu, mít cit pro to, kdy použít jaké vyhledávací stroje, jaké nástroje jsou vhodné pro určitý typ požadavku

18
Příprava rešerše příprava rešerše formulace rešeršního požadavku,
analýza rešeršního požadavku volba zdroje či zdrojů informací volba rešeršní strategie vyjádření pojmů rešeršního požadavku v selekčních jazycích zvolených informačních souborů formulace rešeršního dotazu

19
Formulace rešeršního požadavku
vyjádření tématu, ke kterému je zapotřebí vyhledat informace formulování rešeršního tématu v optimální podobě analýza informačního požadavku a informační potřeby - vymezení problematiky, která nás zajímá, vymezení časového horizontu a charakteru informace (kdo je uživatelem → populárně naučná informace, vědecká apod.) správné pochopení informačního požadavku je základem volby správné rešeršní strategie a úspěšného vyhledávání
 správné pochopení informačního požadavku je základem volby správné rešeršní strategie a úspěšného vyhledávání.")
20
Analýza rešeršního požadavku
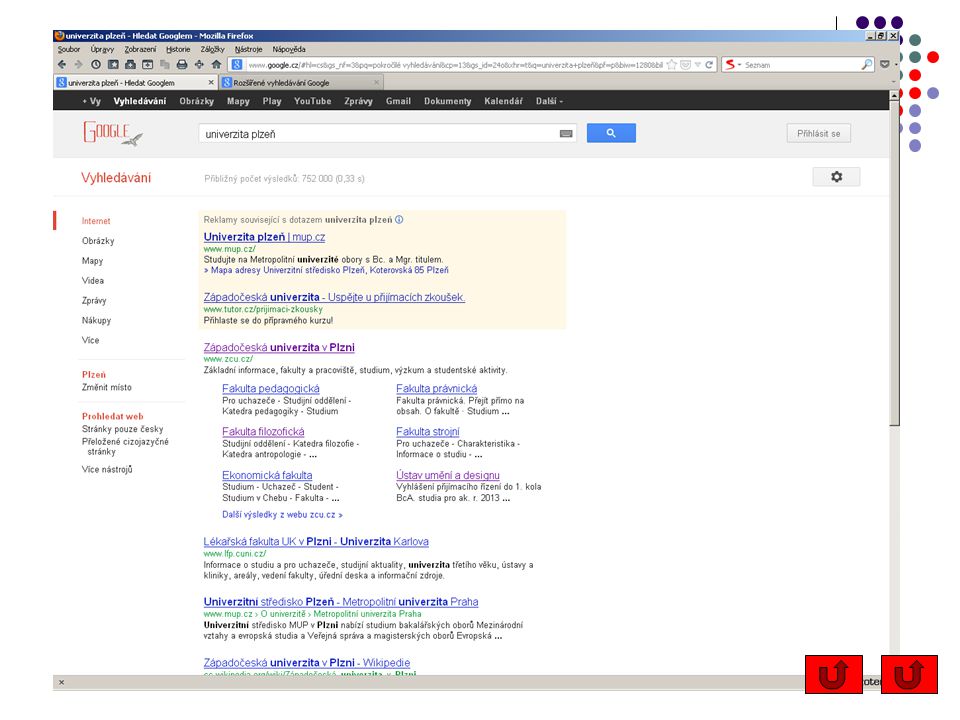
identifikace klíčových pojmů rešeršního požadavku stanovení jejich vzájemných vztahů příklad: téma: informace o vysokých školách v Plzni klíčové pojmy: vysoká škola, univerzita (synonymum) Plzeň vzájemné vztahy: vysoká škola nebo univerzita a zároveň Plzeň analýza informačního požadavku a informační potřeby - vymezení problematiky, která nás zajímá, vymezení časového horizontu a charakteru informace (kdo je uživatelem → populárně naučná informace, vědecká apod.) správné pochopení informačního požadavku je základem volby správné rešeršní strategie a úspěšného vyhledávání
 Plzeň. vzájemné vztahy: vysoká škola nebo univerzita a zároveň Plzeň. analýza informačního požadavku a informační potřeby - vymezení problematiky, která nás zajímá, vymezení časového horizontu a charakteru informace (kdo je uživatelem → populárně naučná informace, vědecká apod.) správné pochopení informačního požadavku je základem volby správné rešeršní strategie a úspěšného vyhledávání.")
21
Problémy v etapě přípravy rešerše
pozor na jazykové problémy jazykové problémy transliterace jmen např. v angličtině Shcherbinin (v češtině Ščerbinin), Leontiev (Leontěv), Minaev (Minajev), Khalimullin (Chalimulin), Shimanskii (Šimanskij), Chembartsev (Čembarcev), Derevschikov (Děrevščikov) apod. odlišná terminologie pravopisné rozdíly v terminologii (např. defectoscopy x flaw detection) př. computerised x computerized modelling x modeling nelatinková písma bývají transliterována - pravidla pro transliteraci (např. cyrilice) jsou v anglicky mluvících zemích poněkud odlišná od našich zvyklostí problémy při hledání ruských autorů nebo ruských zdrojů (názvy ruských časopisů apod.) příklady jmen ruských autorů převzaté ze záznamů v bázích dat – rozdílnost transliterace při hledání jmen autorů, názvů jejich pracovišť nebo názvů časopisů, které nejsou anglického původu nespokojit se jen s jedním negativním výsledkem hledání, zkusit dotaz přeformulovat nepoužívat diakritická znaménka
, Leontiev (Leontěv), Minaev (Minajev), Khalimullin (Chalimulin), Shimanskii (Šimanskij), Chembartsev (Čembarcev), Derevschikov (Děrevščikov) apod. odlišná terminologie. pravopisné rozdíly v terminologii (např. defectoscopy x flaw detection) př. computerised x computerized. modelling x modeling. nelatinková písma bývají transliterována - pravidla pro transliteraci (např. cyrilice) jsou v anglicky mluvících zemích poněkud odlišná od našich zvyklostí. problémy při hledání ruských autorů nebo ruských zdrojů (názvy ruských časopisů apod.) příklady jmen ruských autorů převzaté ze záznamů v bázích dat – rozdílnost transliterace. při hledání jmen autorů, názvů jejich pracovišť nebo názvů časopisů, které nejsou anglického původu nespokojit se jen s jedním negativním výsledkem hledání, zkusit dotaz přeformulovat. nepoužívat diakritická znaménka.")
22
Volba zdroje informací
volíme jeden osvědčený zdroj nebo vhodnou kombinaci několika zdrojů (databáze, katalogy, internet apod.) je vhodné seznámit se s obsahem zdrojů, které máme k dispozici (šetříme čas, vliv na výsledek rešerše) pomocná dokumentace – nápověda příslušných zdrojů, informace na serverech producentů informačních zdrojů, články na internetu i v časopisech apod.)
 je vhodné seznámit se s obsahem zdrojů, které máme k dispozici (šetříme čas, vliv na výsledek rešerše) pomocná dokumentace – nápověda příslušných zdrojů, informace na serverech producentů informačních zdrojů, články na internetu i v časopisech apod.)")
23
Volba rešeršní strategie
rešeršní strategie = postup rešerše, způsob, jak efektivně získat co možná nejpřesn ohlas relevantních dokumentů základní strategie strategie stavebních kamenů strategie rostoucí perly strategie osekávání strategie vyhledávání nejdříve podle nejužší fasety strategie vyhledávání nejdříve podle nejmenší četnosti výskytu rešeršní strategie = postup rešerše, způsob, jak efektivně získat přesný ohlas relevantních dokumentů podle Charlese Bourna (*1931-, Stanford Research Institute, zabýval se knihovnickou analýzou, automatizací, metodami vyhodnocováním apod.) a jeho spolupracovníků lze rozlišovat 5 typů přístupu
 a jeho spolupracovníků lze rozlišovat 5 typů přístupu.")
24
Volba rešeršní strategie
strategie stavebních kamenů přeformulování dotazu do několika dotazů dílčích průběh rešerše se rozpadá do několika dílčích rešerší příklad: aplikace autorského zákona v oblasti elektronických dokumentů a kopírování klíčové pojmy: autorský zákon kopírování elektronické dokumenty dotazy: autorský zákon AND kopírování autorský zákon AND elektronické dokumenty konečný výsledek: spojení výsledků jednotlivých vyhledávání založena na zjednodušeném přeformulování dotazu do několika dotazů dílčích průběh rešerše se rozpadá do několika dílčích, které se ve finále spojí v jeden soubor

25
Volba rešeršní strategie
strategie rostoucí perly začíná vyhledáváním záznamu k nejužšímu možnému pojmu v požadavku s cílem nalézt alespoň jeden relevantní záznam příklad: aplikace autorského zákona v oblasti elektronických dokumentů a kopírování klíčové pojmy: aplikace autorského zákona kopírování elektronické dokumenty dotaz: aplikace autorského zákona AND kopírování AND elektronické dokumenty pokud málo dokumentů – rozšíření tématu: autorský zákon AND kopírování AND (elektronické dokumenty OR elektronické knihy OR elektronické časopisy) případně můžeme začít jménem odborníka z dané oblasti a postupně dotaz rozšiřovat Začíná vyhledáváním záznamu k nejužšímu možnému pojmu v požadavku s cílem nalézt alespoň jeden relevantní záznam. Někdy se také nazývá nepřímým průzkumem. Může představovat i takový postup, kdy známe jméno určitého zásadního autora působícího v oboru a nejprve se soustředíme na vyhledání jeho prací a postupně rešerši rozšiřujeme. Používá se zejména v případech, kdy je téma formulováno příliš složitě, ale je udáno jméno odborníka. Na základě výsledků tohoto prvotního vyhledávání, pak můžeme postupovat k dalším záznamům buď podle jmen dalších odborníků nebo podle upřesněné tematiky.
 případně můžeme začít jménem odborníka z dané oblasti a postupně dotaz rozšiřovat. Začíná vyhledáváním záznamu k nejužšímu možnému pojmu v požadavku s cílem nalézt alespoň jeden relevantní záznam. Někdy se také nazývá nepřímým průzkumem. Může představovat i takový postup, kdy známe jméno určitého zásadního autora působícího v oboru a nejprve se soustředíme na vyhledání jeho prací a postupně rešerši rozšiřujeme. Používá se zejména v případech, kdy je téma formulováno příliš složitě, ale je udáno jméno odborníka. Na základě výsledků tohoto prvotního vyhledávání, pak můžeme postupovat k dalším záznamům buď podle jmen dalších odborníků nebo podle upřesněné tematiky.")
26
Volba rešeršní strategie
strategie osekávání postupné omezování dotazu aplikace autorského zákona AND kopírování AND elektronické dokumenty pokud mnoho dokumentů, pak omezíme například pomocí vyloučení určitého druhu dokumentů: (aplikace autorského zákona AND kopírování AND elektronické dokumenty) NOT knihy další způsoby omezení – použitím proximitních operátorů, časově, jazykově apod. v případě, že očekáváme velké množství vyhledaných záznamů taktiky: - omezit vyhledávání na určité pole záznamu - například pouze na předmět - použijeme proximitní operátory pro klíčová slova - místo „library AND (books OR journals)" použijeme „library NEAR (books OR journals)" - část vyhledaných záznamů vyloučíme operátorem not - „library NEAR (books OR journals) AND NOT (electronic books OR electronic journals)" - omezíme vyhledávání na určitý typ nebo druh dokumentu - například pouze články z časopisů - vyhledávání omezíme jazykově- například pouze angličtina - vymezíme časové období apod.
 NOT knihy. další způsoby omezení – použitím proximitních operátorů, časově, jazykově apod. v případě, že očekáváme velké množství vyhledaných záznamů. taktiky: - omezit vyhledávání na určité pole záznamu - například pouze na předmět. - použijeme proximitní operátory pro klíčová slova - místo „library AND (books OR journals) použijeme „library NEAR (books OR journals) - část vyhledaných záznamů vyloučíme operátorem not - „library NEAR (books OR journals) AND NOT (electronic books OR electronic journals) - omezíme vyhledávání na určitý typ nebo druh dokumentu - například pouze články z časopisů. - vyhledávání omezíme jazykově- například pouze angličtina. - vymezíme časové období apod.")
27
Závěr přípravy rešerše
vyjádření pojmů rešeršního požadavku v selekčních jazycích zvolených informačních souborů formulace rešeršního dotazu dotaz: („vysoká škola“ OR univerzita) AND Plzeň
 AND Plzeň.")
28
Informační průzkum strojově (prostřednictvím počítače)
ručně (v katalogu, v kartotéce)
")
29
Zpracování výsledků vyhledané záznamy o informačních zdrojích je třeba upravit do podoby dokumentu, který představuje písemný výsledek rešerše struktura a formální úprava rešerše dříve norma ČSN Formální úprava rešerší byla zrušena, má pouze informativní význam ČSN Formální úprava rešerší. Praha: Vydavatelství Úřadu pro normalizaci a měření, s. Účinnost od Zrušená norma (bez náhrady). Platnost ukončena v březnu 2002.
. Platnost ukončena v březnu")
30
Zpracování výsledků povinné části rešerše podle normy ČSN 01 0198
titulní list analytický list základní část příklad rešerše (pozor – citace v ukázce jsou podle již neplatné normy – dnes se řídí ČSN ISO 690:2011)
")
31
Zpracování výsledků základní část rešerše
zahrnuje textovou část, kterou tvoří soupis záznamů dokumentů nebo jejich částí pravidla platná pro tvorbu základní části lze aplikovat na úpravu seznamů literatury jako součásti různých studentských prací, bakalářských, diplomových aj. záznamy zpracovat podle normy ČSN ISO 690:2011

32
Zpracování výsledků příklady citací: kniha
MEŠKO, Dušan aj. Akademická příručka. Martin: Osveta, © s. ISBN článek z tištěného periodika VAŘEKA, Pavel. Příspěvek ke studiu žijících vsí středověkého původu. Pozůstatky zástavby z pozdního středověku na parcele č.p. 121 v Mikulčicích. Přehled výzkumů, 2010, 51(1-2), ISSN článek z elektronického periodika BITUŠÍKOVÁ, Alexandra a LUTHER, Daniel. Sustainable diversity and public space in the city of Bratislava, Slovakia. Anthropological Notebooks [online]. Ljubljana (Slovenia): Slovene Anthropological Society, 2010, 16(2) [cit ]. ISSN X. Dostupné z: Anthropological _Notebooks_XVI_2_Bitusikova.pdf
, ISSN článek z elektronického periodika. BITUŠÍKOVÁ, Alexandra a LUTHER, Daniel. Sustainable diversity and public space in the city of Bratislava, Slovakia. Anthropological Notebooks [online]. Ljubljana (Slovenia): Slovene Anthropological Society, 2010, 16(2) [cit ]. ISSN X. Dostupné z: Anthropological _Notebooks_XVI_2_Bitusikova.pdf.")
33
Závěr rešeršní činnosti
vyhodnocení rešerše na základě toho, kolik dokumentů systém nalezl, posoudíme, zda je třeba dotaz upravit velké množství – příliš obecný dotaz žádný výsledek – špatná klíčová slova nebo příliš komplikovaný dotaz relevance informací pertinence informací hodnocení je důležitou součástí rešerše hlavní kritéria hodnocení: počet vyhledaných záznamů podíl pertinentních, popř. relevantních záznamů z počtu záznamů vyhledaných relevance informací znamená, že vyhledané informace odpovídají zadanému dotazu a jsou vhodné k řešení daného informačního problému pertinence znamená, že vyhledané informace přesně odpovídají konkrétní potřebě uživatele

34
Závěr rešeršní činnosti
negativní rešerše případ, kdy vyčerpáme všechny zdroje a nedostaneme žádné výsledky i negativní rešerše může přinést závažnou informaci - že nebylo o dané problematice nic publikováno

35
Závěr rešeršní činnosti
zásady pro dosažení optimálního počtu záznamů chceme-li získat více záznamů: co nejméně zpřesňovat dotaz používat jen nezbytná pole a nejdůležitější termíny neomezovat vyhledávání časově apod. nepoužívat logický operátor NOT ověřit správnost pravopisu použít zástupné znaky (pokud to vyhledávací nástroj umožňuje) použít synonyma a příbuzná slova – spojit operátorem OR
 použít synonyma a příbuzná slova – spojit operátorem OR.")
36
Závěr rešeršní činnosti
chceme-li dotaz zpřesnit (zmenšit vyhledanou množinu): používat více slov vyjadřujících hledané téma spojených logickým operátorem AND nepoužívat obecné nebo abstraktní výrazy používat jen významová slova využít další nabídky vyhledávacího nástroje, například omezit prohledávání časově nebo jazykově
: používat více slov vyjadřujících hledané téma spojených logickým operátorem AND. nepoužívat obecné nebo abstraktní výrazy používat jen významová slova. využít další nabídky vyhledávacího nástroje, například omezit prohledávání časově nebo jazykově.")
37
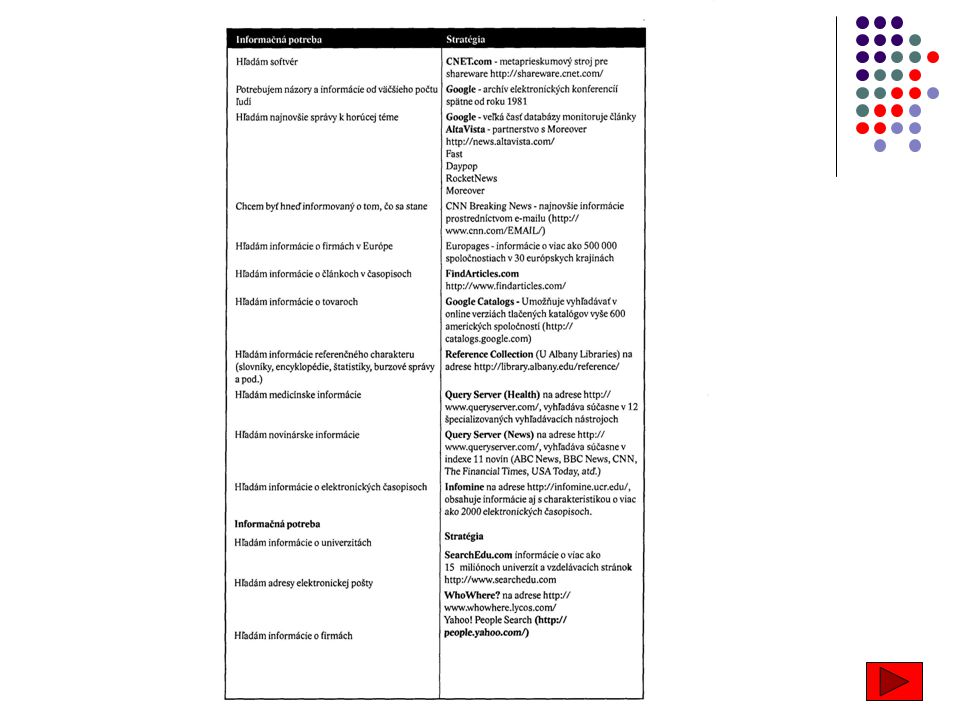
Vyhledávání na internetu
internet - nepostradatelný zdroj informací nejen z oblasti zábavy, praktických záležitostí života, ale i odborných informací poskytuje nepřeberné množství nástrojů pro vyhledávání informací pro úspěšné vyhledávání informací je třeba porozumět internetu a jeho možnostem poskytuje nepřeberné množství nástrojů pro vyhledávání informací, které používají některé odlišné vyhledávací prostředky, zaměřují se na různé oblasti internetu a přinášejí výsledky v různých formách abychom se dokázali dostat k potřebným informacím, musíme porozumět internetu a jeho možnostem

38
Vyhledávání na internetu
uvádí se, že na internetu 1 bilion stran obsahu v tištěné podobě vychází jen 0,003% celého obsahu publikovaného ve světě velikost internetu se údajně každých 5 let zdvojnásobuje využívání internetu další statistiky V angl. textu ( uvedeno 1 trilion (1018) = v češtině 1 bilion (1012)
 uvedeno 1 trilion (1018) = v češtině 1 bilion (1012)")
39
Vyhledávání na internetu
zdroje na internetu z hlediska přístupnosti: veřejné neveřejné (např. komerční databáze, periodika apod.) Zdroje informací na internetu: -veřejné; -neveřejné (většinou placené služby) - patří mezi ně často právě ty informace, které jsou lidé tradičně zvyklí hledat v knihovnách – noviny, časopisy, knihy, bibliografické databáze…
 Zdroje informací na internetu: -veřejné; -neveřejné (většinou placené služby) - patří mezi ně často právě ty informace, které jsou lidé tradičně zvyklí hledat v knihovnách – noviny, časopisy, knihy, bibliografické databáze…")
40
Vyhledávání na internetu
internet x komerční zdroje informací internet distribuovaný (bez centrální autority) – otázka kvality a důvěryhodnosti informací dynamický (neustálá aktualizace) – rozdílná aktuálnost stránek komerční zdroje (bibliografické databáze apod.) propracovanější vyhledávací nástroje (pracují se strukturovanou databází – exaktnější vyhledávání) hlavní důraz ne na množství, ale kvalitu zdrojů zařazovaných do databází (recenzované zdroje, autoritativní zdroje atd.) komerční – tedy placené
 – otázka kvality a důvěryhodnosti informací. dynamický (neustálá aktualizace) – rozdílná aktuálnost stránek. komerční zdroje (bibliografické databáze apod.) propracovanější vyhledávací nástroje (pracují se strukturovanou databází – exaktnější vyhledávání) hlavní důraz ne na množství, ale kvalitu zdrojů zařazovaných do databází (recenzované zdroje, autoritativní zdroje atd.) komerční – tedy placené.")
41
Vyhledávání na internetu
zásady pro vyhledávání na internetu uvědomit si, že internet není knihovna (v knihovně jsou zdroje zpracovány a organizovány) – internet je neuspořádaný a chaotický dokázat odhadnout, co má smysl hledat na internetu vybrat správná místa, kde s hledáním začít osvojit si práci s vyhledávacími nástroji přečíst si nápovědu správně formulovat dotaz použít synonyma a příbuzné výrazy zkontrolovat pravopis nenechat se odradit počátečním neúspěchem nespokojit se jen s jedním hledáním správně formulovat dotaz ujasnit si, co chci nalézt, uvědomit si hierarchii v odborné terminologii - jaký je obecnější i speciálnější pojem k termínu zvolenému pro vyhledávání (pro případ, že po zadání zvoleného termínu bude vyhledáno příliš mnoho nebo příliš málo dokumentů)
 – internet je neuspořádaný a chaotický. dokázat odhadnout, co má smysl hledat na internetu. vybrat správná místa, kde s hledáním začít. osvojit si práci s vyhledávacími nástroji. přečíst si nápovědu. správně formulovat dotaz. použít synonyma a příbuzné výrazy. zkontrolovat pravopis. nenechat se odradit počátečním neúspěchem. nespokojit se jen s jedním hledáním. správně formulovat dotaz. ujasnit si, co chci nalézt, uvědomit si hierarchii v odborné terminologii - jaký je obecnější i speciálnější pojem k termínu zvolenému pro vyhledávání (pro případ, že po zadání zvoleného termínu bude vyhledáno příliš mnoho nebo příliš málo dokumentů)")
42
Vyhledávání na internetu
faktory, které mají vliv na uspořádání výsledků četnost výskytu slov počet výrazů v dotazu, jež se shodují s nalezeným dokumentem váha podle pole blízkost slov výskyt příbuzných slov a různých pravopisných variant pořadí slov v dotazu uživatele apod. Abychom rozuměli výsledkům vyhledávání, je třeba vědět, jak je systémy řadí. V první fázi systém vyhledá dokumenty, jež obsahují klíčová slova v požadovaném vztahu. Systém setřídí výsledky tak, aby odkazy zobrazené ve výsledcích na prvních místech, co nejvíce odpovídaly položenému dotazu. Program se tedy snaží odhadnout, které dokumenty jsou nejvhodnější.

43
Vyhledávání na internetu
problém kvality zdrojů snadnost zveřejňování dokumentů → velké množství informací informační zdroje nejsou odborně editovány → otázka kvality autoři často zůstávají v anonymitě chybějí data zveřejnění je těžké určit, jedná-li se o informaci původní obtížné rozlišování skutečných seriózních informací od reklamních textů Hodnocení důležité při využívání informací pro odbornou, profesionální práci a studium. -WWW prostředí a snadnost zveřejňování dokumentů a informací na internetu - internet je demokratický a svobodný komunikační a informační nástroj -autoři často zůstávají v anonymitě, je-li uvedeno autorovo jméno, jen zřídka je připojena informace o jeho odborné způsobilosti; je velmi složité vystopovat cíle, které autora vedly ke zveřejnění informace; - často chybějí data zveřejnění, ani v případě, že text časový údaj obsahuje, není vyhráno - může jít o datum vytvoření původního textu, prvního zveřejnění na internetu nebo poslední revize; -je těžké určit, jedná-li se o informaci původní (primární) nebo převzatou (sekundární); -
 nebo převzatou (sekundární); -")
44
Vyhledávání na internetu
zásady pro hodnocení dokumentů kvalifikace autora: v které instituci autor pracuje – lze to poznat i z URL, zda se jeho jméno vyskytuje v tištěných zdrojích, v Science Citation Indexu (Web of Science), ve Scopusu struktura informačního zdroje: respektuje stránka nejnovější doporučení pro tvorbu WWW jsou na stránce odkazy a další citace je způsob navigace na stránce srozumitelný je stránka registrovaná ve vyhledávacích nástrojích internetu, adresářích a virtuálních knihovnách
, ve Scopusu. struktura informačního zdroje: respektuje stránka nejnovější doporučení pro tvorbu WWW. jsou na stránce odkazy a další citace. je způsob navigace na stránce srozumitelný. je stránka registrovaná ve vyhledávacích nástrojích internetu, adresářích a virtuálních knihovnách.")
45
Vyhledávání na internetu
zásady pro hodnocení dokumentů – pokračování jaký je obsah informačního zdroje: kdo je cílovou skupinou stránky jaká je hodnota stránky v porovnáním s dalšími zdroji relevantními k tématu úroveň pokrytí dané problematiky srozumitelnost a přehlednost textu objektivita předkládaných informací aktuálnost předkládaných informací byla stránka recenzovaní nebo hodnocená

46
Vyhledávání na internetu
zásady pro hodnocení dokumentů – pokračování datum vydání stránky: kdy byla vytvořena kdy byla naposledy aktualizována jsou odkazy aktuální apod.

47
Vyhledávání na internetu
booleovská logika se v současných vyhledávacích nástrojích používá třemi způsoby úplné booleovské vyhledávání s použitím logických operátorů implicitní booleovské vyhledávání předdefinovaná terminologie ve formulářích

48
Vyhledávací nástroje vyhledávání na internetu umožňují různé druhy vyhledávacích nástrojů volba vyhledávacího nástroje použít několik vyhledávačů – každý z nich může nalézt unikátní dokumenty strategie volby zdroje odhad webové adresy použití předmětového adresáře (klasifikace zdrojů podle předmětových kategorií) použití internetového vyhledávače (vyhledávácí služby nepostihují celý obsah webu – tzv. neviditelný web mnohdy nedokážou běžné nástroje prohledat) odhad webové adresy: Použití jména nebo zkratky názvu organizace (nkp, skoda) mezi www a koncovkou Přidání vhodné koncovky, v ČR nejčastěji .cz, u zahraničních – zejména amerických zdrojů .com Nejobvyklejší zakončení: com for commercial edu for educational org for other organizations gov for U.S. federal government mil for U.S. military net for Internet service providers and networks
 použití internetového vyhledávače (vyhledávácí služby nepostihují celý obsah webu – tzv. neviditelný web mnohdy nedokážou běžné nástroje prohledat) odhad webové adresy: Použití jména nebo zkratky názvu organizace (nkp, skoda) mezi www a koncovkou. Přidání vhodné koncovky, v ČR nejčastěji .cz, u zahraničních – zejména amerických zdrojů .com. Nejobvyklejší zakončení: com for commercial edu for educational org for other organizations gov for U.S. federal government mil for U.S. military net for Internet service providers and networks.")
49
základní zásady výběru vyhledávacího nástroje
Vyhledávací nástroje základní zásady výběru vyhledávacího nástroje vyčerpávající průzkum → nástroj s velkou databází nejznámější a nejvíce navštěvované zdroje → nástroj budovaný na základě ručního sběru dat máme jasnou představu o hledaném tématu → vyhledávací stroj výběr se bude lišit i podle toho, zda chceme vyhledávat nebo prohledávat příklad - budeme-li chtít prohledávat klíčovými slovy např. české zdroje, použijeme raději Google – kvalitnější výsledky než třeba český Seznam (Google – větší databáze) - budeme-li chtít použít pro hledání českých zdrojů předmětový katalog, obrátíme se na Centrum.cz, nikoliv třeba na službu Yahoo!.
 - budeme-li chtít použít pro hledání českých zdrojů předmětový katalog, obrátíme se na Centrum.cz, nikoliv třeba na službu Yahoo!.")
50
Vyhledávací nástroje druhy:
internetové vyhledávače, služby typu „search engines“, vyhledávací systémy předmětové adresáře a virtuální knihovny internetové vyhledávače obvykle disponují vyhledáváním i předmětovými adresáři metavyhledávací nástroje

51
Internetové vyhledávače
internetový vyhledávač, vyhledávací stroj, search engine, fultextový vyhledávač systém, který na základě klíčového slova formulovaného uživatelem hledá v databázi nebo v indexu a oznámí uživateli výsledek

52
Internetové vyhledávače
základní rozdíly mezi vyhledávacími stroji: - jaký prostor internetu nástroj prohledává (jen WWW nebo také Usenet (o něm), Gopher (o něm), FTP – Archie, Snoopie (o FTP) aj.) - velikost indexu (seznam slov a jim odpovídajících dokumentů ve kterých se dané slovo vyskytuje ) - způsob indexování webových stránek frekvence výskytu, počet termínů vyhovujících požadavku, váha podle polí, proximita, pořadí slov v dotazu apod. - způsob řazení výsledků - možnosti vyhledávání - jaké typy dokumentů pokrývá vyhledávací nástroj - uživatelská podpora a přívětivost - možnost personalizace Usenet je systém elektronických diskusních skupin, distribuovaný prostřednictvím internetu po celém světě. Uživatelé čtou a posílají veřejné příspěvky (články, zprávy nebo příspěvky, souhrnně zvané „newsy“) do kategorií zvaných skupiny. Diskuze v jednotlivých skupinách se dělí na vlákna. Příspěvky jsou na serveru uloženy chronologicky. Gopher - prostředek pro navigaci a vyhledávání potřebných dat v síti, funguje na principu klient-server, proto musí být na počítači, na kterém pracujete, nainstalován vhodný klient Služba Gopher byla vyvinuta v USA, na univerzitě v Minnesotě, o něco málo dříve než World Wide Web. Poté spolu obě služby soupeřily, s tím že zpočátku měl navrch (co do počtu serverů) Gopher. Kolem roku 1995 bylo celosvětově v provozu přes 6000 serverů této služby. S postupem času se ale jazýček vah začal obracet a Web začal převládat. Gopher nakonec prohrál na celé čáře. Více na FTP (anglicky File Transfer Protocol) je v informatice protokol aplikační vrstvy z rodiny TCP/IP. Je určen pro přenos souborů mezi počítači, na kterých mohou běžet rozdílné operační systémy (je platformně nezávislý).
, Gopher (o něm), FTP – Archie, Snoopie. (o FTP) aj.) - velikost indexu (seznam slov a jim odpovídajících dokumentů ve kterých se dané slovo vyskytuje ) - způsob indexování webových stránek. frekvence výskytu, počet termínů vyhovujících požadavku, váha podle polí, proximita, pořadí slov v dotazu apod. - způsob řazení výsledků. - možnosti vyhledávání. - jaké typy dokumentů pokrývá vyhledávací nástroj. - uživatelská podpora a přívětivost. - možnost personalizace. Usenet je systém elektronických diskusních skupin, distribuovaný prostřednictvím internetu po celém světě. Uživatelé čtou a posílají veřejné příspěvky (články, zprávy nebo příspěvky, souhrnně zvané „newsy ) do kategorií zvaných skupiny. Diskuze v jednotlivých skupinách se dělí na vlákna. Příspěvky jsou na serveru uloženy chronologicky. Gopher - prostředek pro navigaci a vyhledávání potřebných dat v síti, funguje na principu klient-server, proto musí být na počítači, na kterém pracujete, nainstalován vhodný klient. Služba Gopher byla vyvinuta v USA, na univerzitě v Minnesotě, o něco málo dříve než World Wide Web. Poté spolu obě služby soupeřily, s tím že zpočátku měl navrch (co do počtu serverů) Gopher. Kolem roku 1995 bylo celosvětově v provozu přes 6000 serverů této služby. S postupem času se ale jazýček vah začal obracet a Web začal převládat. Gopher nakonec prohrál na celé čáře. Více na FTP (anglicky File Transfer Protocol) je v informatice protokol aplikační vrstvy z rodiny TCP/IP. Je určen pro přenos souborů mezi počítači, na kterých mohou běžet rozdílné operační systémy (je platformně nezávislý).")
53
Internetové vyhledávače
při výběru vyhledávacího nástroje bereme v úvahu velikost jeho indexu způsob indexování aktuálnost informací (update) žádný internetový vyhledávač neumí prohledat celý internet žádný vyhledávač není ideální jak pracuje robot nejčastější metodou objevování stránek je využívání hypertextových spojení jakmile robot najde určitou stránku, vybere všechny hypertextové odkazy z této stránky a zařadí je do pořadí pro prozkoumání nalezenou stránku robot indexuje a uloží ji do invertovaného indexu invertovaný index je abecední index klíčových slov – u každého klíčového slova jsou dokumenty, kde se dané klíčové slovo nalézá využívání slovníku stop slov metodika indexování u jednotlivých robotů se liší a není veřejně známa některé vynechávají nevýznamová slova, některé slova s příliš velkou frekvencí vysokou váhu mají slova z názvů a metaprvky mohou být naprogramovány na širší záběr webu nebo do větší hloubky Na širší záběr – indexují především hlavní stránky Na hlubší záběr – indexují nejen hlavní stránky, ale i další v daném webovém sídle
 žádný internetový vyhledávač neumí prohledat celý internet. žádný vyhledávač není ideální. jak pracuje robot. nejčastější metodou objevování stránek je využívání hypertextových spojení. jakmile robot najde určitou stránku, vybere všechny hypertextové odkazy z této stránky a zařadí je do pořadí pro prozkoumání. nalezenou stránku robot indexuje a uloží ji do invertovaného indexu. invertovaný index je abecední index klíčových slov – u každého klíčového slova jsou dokumenty, kde se dané klíčové slovo nalézá. využívání slovníku stop slov. metodika indexování u jednotlivých robotů se liší a není veřejně známa. některé vynechávají nevýznamová slova, některé slova s příliš velkou frekvencí. vysokou váhu mají slova z názvů a metaprvky. mohou být naprogramovány na širší záběr webu nebo do větší hloubky. Na širší záběr – indexují především hlavní stránky. Na hlubší záběr – indexují nejen hlavní stránky, ale i další v daném webovém sídle.")
54
Internetové vyhledávače
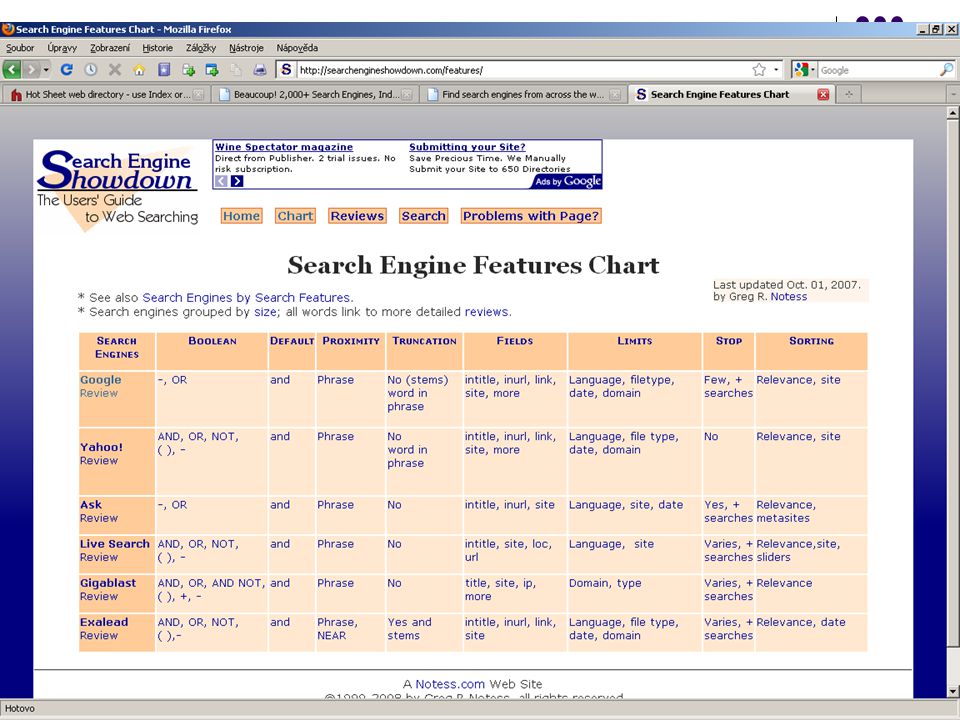
katalogy a rozcestníky internetových vyhledávačů: Hotsheet – tematicky uspořádané, velké množství kategorií Beaucoup - tematicky uspořádané SearchengineCollossus - seznam vyhledávačů uspořádaný teritoriálně

55
Internetové vyhledávače
informace o internetových vyhledávačích : například SearchengineShowDown -

58
Světové internetové vyhledávače
Google založ. v r. 1998 jeden z nejpopulárnějších a největších vyhledávacích nástrojů poskytuje řadu dalších služeb systém denně aktualizuje 260 zaměstnanců z nichž více než 50 má titul PhD. Jeden z nejpopulárnějších nástrojů, řada ocenění Systém denně aktualizuje 260 zaměstnanců z nichž více než 50 má titul PhD.

59
Světové internetové vyhledávače
Google výhody: veliká databáze možnost nastavení jazyka podle volby uživatele hledané termíny jsou zvýrazněné lišta nástrojů s mnoha funkcemi propracované vyhledávání v mnoha speciálních zdrojích zobrazuje stránky, které už zanikly, ale jsou v paměti (archiv/ cached) - s udáním data, kdy byly indexovány
 - s udáním data, kdy byly indexovány.")
60
Světové internetové vyhledávače

61
Světové internetové vyhledávače

62
Světové internetové vyhledávače
Google nevýhody: indexuje pouze prvních 101 KB u webových stránek a 120 KB u pdf souborů nepoužívá rozšíření v jednoduchém vyhledávání neumožňuje plné použití booleovských operátorů (např. NOT) neumožňuje použití závorek k seskupování klíčových slov v dotazu (v obou uvedených případech - stejný výsledek) např. pizza AND (žampiony OR šunka) AND olivy nebo (pizza AND žampiony) OR (šunka AND olivy) pizza AND (žampiony OR šunka) AND olivy - chceme pizzu s olivami, ale je jedno, zda tam budou žampiony nebo šunka nebo (pizza AND žampiony) OR (šunka AND olivy) – chceme pizzu se žampiony nebo jiné jídlo se šunkou a olivami V Googlu v obou případech stejný výsledek
 neumožňuje použití závorek k seskupování klíčových slov v dotazu (v obou uvedených případech - stejný výsledek) např. pizza AND (žampiony OR šunka) AND olivy. nebo. (pizza AND žampiony) OR (šunka AND olivy) pizza AND (žampiony OR šunka) AND olivy - chceme pizzu s olivami, ale je jedno, zda tam budou žampiony nebo šunka. nebo. (pizza AND žampiony) OR (šunka AND olivy) – chceme pizzu se žampiony nebo jiné jídlo se šunkou a olivami. V Googlu v obou případech stejný výsledek.")
63
Světové internetové vyhledávače
způsoby vyhledávání jednoduché vyhledávání implicitně AND vyhledávání podle polí „Zkusím štěstí“ zobrazí první vyhledaný výsledek rozšířené vyhledávání předdefinovaný formulář

64
Světové internetové vyhledávače
prohledávání podle polí příklady allintitle:text allinurl:text allintext:text vyhledávání podle obrázků (ikona fotoaparátu) zkratky pro vyhledávání define:library a řada dalších Vyhledání obrázku - book
 zkratky pro vyhledávání. define:library. a řada dalších. Vyhledání obrázku - book.")
65
Světové internetové vyhledávače
fráze uvozovky rozšíření hledá automaticky jednotné a množné číslo maskování možné uvnitř frází – např. „pizza se šunkou a *“

66
Světové internetové vyhledávače
nerozlišuje malá a velká písmena př. Brno – totéž co brno vyhledání synonym pomocí ~ př. šumava ~cesty najde i trasy apod.

67
Světové internetové vyhledávače
řada dalších služeb přehled dalších možností co všechno Google umí

68
Světové internetové vyhledávače
nejhledanější slova na Googlu 2011 nejvyhledavanejsi-slova-v-roce 2012

69
Světové internetové vyhledávače
specializované služby Googlu Scholar Books (Knihy)
")
70
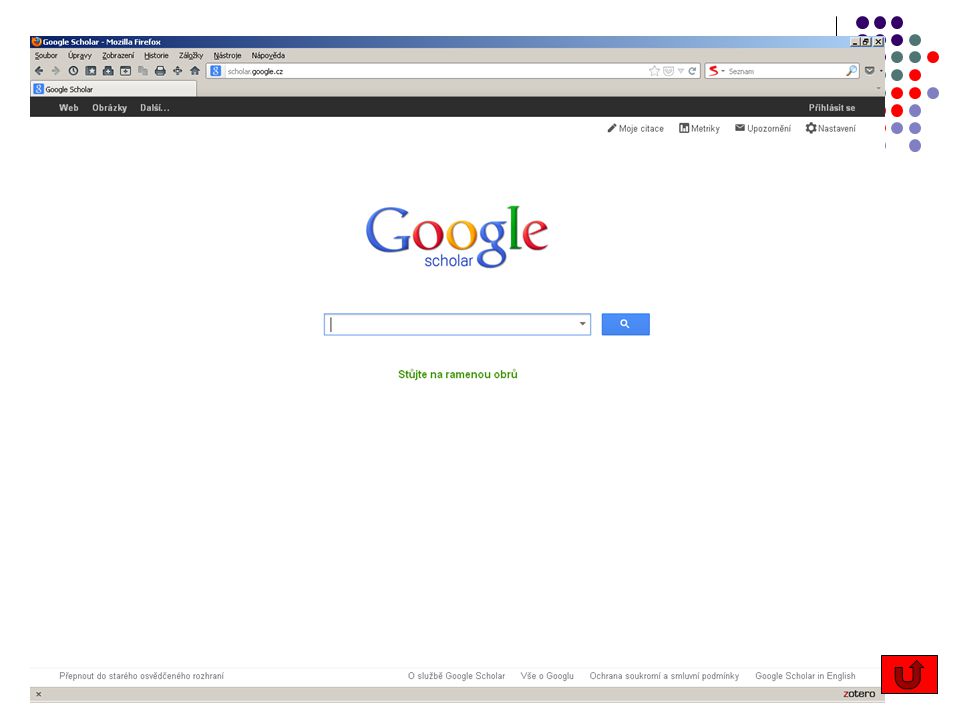
Světové internetové vyhledávače
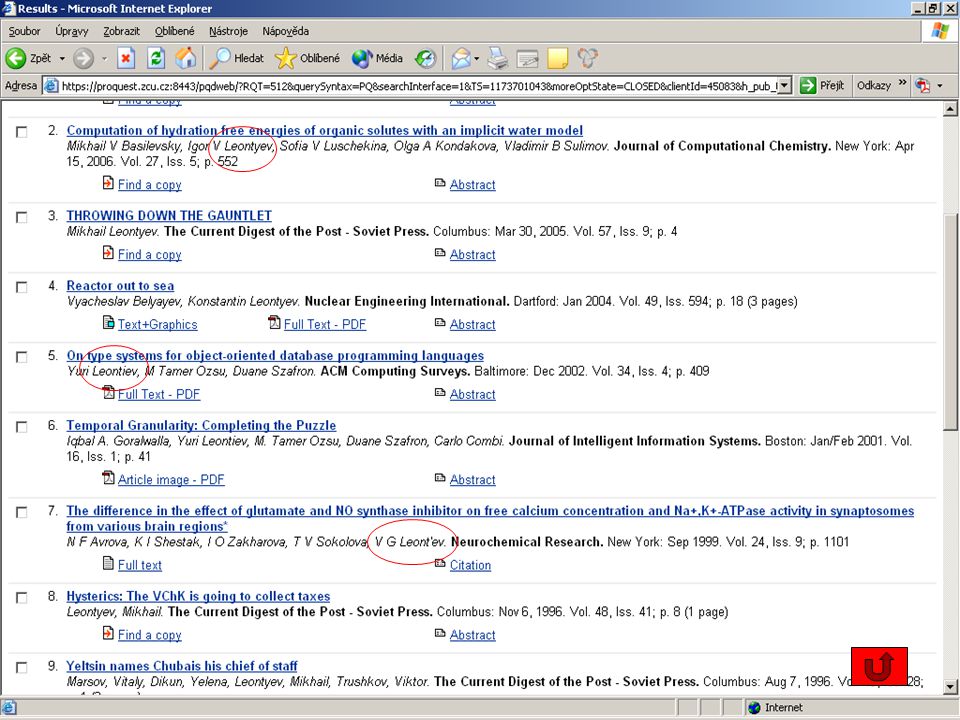
Google Scholar specializovaný vyhledávač vědeckých informací - recenzovaných článků, disertací, knih, preprintů, abstrakt, technických zpráv ze všech oborů výzkumu, vysokoškolských kvalifikačních prácí umožňuje vyhledání dokumentu zobrazení abstraktu vyhledání citací dokumentu

71
Světové internetové vyhledávače
řazení článků podle relevance (hodnocení textu, váha autora, reputace zdroje, ve kterém je zveřejněn) hledání podle autora (př. einstein - pokud mnoho výsledků lze zúžit – autor:einstein)
 hledání podle autora. (př. einstein - pokud mnoho výsledků lze zúžit – autor:einstein)")
72
Světové internetové vyhledávače
struktura záznamu název začátek textu citace podobné články různé verze článku příklad:

73
Světové internetové vyhledávače
Google knihy nabízí ke stažení ve formátu pdf některé knihy, které již nejsou chráněné autorským zákonem původní plán – převést na internet 4 mil. knih z vybraných amerických univerzitních a veřejných knihoven, z knihovny britské Oxfordské univerzity a z Bavorské státní knihovny nový plán - převést všechny existující knihy u knih které jsou chráněny copyrightem zobrazuje pouze základní bibliografické údaje, eventuálně krátké ukázky textu plné texty řady knih, které jsou již veřejným majetkem a nejsou chráněny autorskými právy (70 let po smrti autora) u ostatních jen základní bibliografické údaje, případně obálky, obsahy, náhledy některých stránek, rejstříky apod. odkaz, kde lze knihu získat (knihovna, knihkupectví…)
 u ostatních jen základní bibliografické údaje, případně obálky, obsahy, náhledy některých stránek, rejstříky apod. odkaz, kde lze knihu získat (knihovna, knihkupectví…)")
74
Světové internetové vyhledávače
jednoduché vyhledávání pokročilé vyhledávání možno různých upřesnění příklad: Sokrates

75
Světové internetové vyhledávače
služby Google knihy příklad: odkazy na stránce: Najít v knihovně Všichni prodejci

76
Světové internetové vyhledávače
Altavista vyhledávač vytvořen v r. 1995 dnes ve vlastnictví Yahoo! – používá jeho databázi a předmětový katalog indexuje všechna slova dokumentu (kromě poznámek), využívá i slova z URL, ze jmen obrázků, metaprvky při posuzování relevance stránek se bere v úvahu řada faktorů např. kde se nachází termín – největší váhu má titul, frekvence výskytu, popularita stránky aj.
, využívá i slova z URL, ze jmen obrázků, metaprvky. při posuzování relevance stránek se bere v úvahu řada faktorů. např. kde se nachází termín – největší váhu má titul, frekvence. výskytu, popularita stránky aj.")
77
Světové internetové vyhledávače
Altavista Silné stránky velká škála funkcí velká databáze hledané termíny jsou zvýrazněné používá proximitní operátory

78
Světové internetové vyhledávače
způsoby vyhledávání jednoduché vyhledávání implicitně AND vyhledávání podle polí rozšířené vyhledávání předdefinovaný formulář

79
Světové internetové vyhledávače
booleovské operátory (musí být velkými písmeny) AND implicitně OR NOT distanční operátory NEAR, ADJACENT (ADJ), FOLLOWED BY např. Karel NEAR Borovský
 AND implicitně. OR. NOT. distanční operátory NEAR, ADJACENT (ADJ), FOLLOWED BY. např. Karel NEAR Borovský.")
80
Světové internetové vyhledávače
fráze uvozovky vyloučení nežádoucích termínů pomocí – zabránění vyloučení obecných slov pomocí +

81
Světové internetové vyhledávače
prohledávání podle polí domain:domainame domain:cz +knihovna +katalog like:URLtext like: title:text inurl:text

82
Světové internetové vyhledávače
další možnosti vyhledávání obrázky videa mapy news a řada dalších služeb

83
Světové internetové vyhledávače
omezení vyhledávače v zájmu rychlého vyhledávání Altavista zastaví vyhledávací proces po určitém časovém limitu, takže v závislosti na momentální rychlosti zpracování úlohy můžeme při opakovaném vyhledávání dostat rozdílný počet výsledků

84
Světové internetové vyhledávače
Lycos velmi rychlé vyhledávání, personalizace HotBot jednoduché, komfortní a rychlé vyhledávání s pozoruhodnými výsledky Lycos jednodušší vyhledávací techniky (jen podle slov, nikoliv frázi), ale také nižší účinnost; značné zatížení reklamou vadí při vyhledávání; HotBot jednoduché, komfortní, rychlé a velmi sofistikované rešeršní techniky (slova i fráze + hledání v polích) s pozoruhodnými výsledky
, ale také nižší účinnost; značné zatížení reklamou vadí při vyhledávání; HotBot. jednoduché, komfortní, rychlé a velmi sofistikované rešeršní techniky (slova i fráze + hledání v polích) s pozoruhodnými výsledky.")
85
Světové internetové vyhledávače
Ask nabízí podobná vyhledávání odpovědi na otázky uživatelů již nejen strojově dohledávány na základě existujících webových zdrojů v nové veřejné betaverzi vyhledávače Ask.com se dostává ke slovu uživatelská komunita (Q&A Community) na otázky uživatelů odpovídají jiní vybraní uživatelé na základě svých znalostí a zkušeností odpovědi rovněž indexovány, zobrazí se při dalším výskytu stejného nebo podobného dotazu
 na otázky uživatelů odpovídají jiní vybraní uživatelé na základě svých znalostí a zkušeností. odpovědi rovněž indexovány, zobrazí se při dalším výskytu stejného nebo podobného dotazu.")
86
České internetové vyhledávače
Seznam Atlas Centrum vyhledavace.unas.cz nebo

87
Předmětové adresáře předmětový adresář – služba odkazující na zdroje, které do ní dodali tvůrci webových stánek nebo informační pracovníci předmětový adresář je organizovaný do předmětových kategorií, podkategorií apod. (příklad) do předmětových vyhledávačů řadíme i digitální knihovny, které jsou sestavené profesionály, zdroje jsou často anotované, hodnocené z více hledisek digitální knihovna - spravovaná sbírka informací, spolu se službami informace jsou v digitální podobě a dostupné prostřednictvím sítě
 do předmětových vyhledávačů řadíme i digitální knihovny, které jsou sestavené profesionály, zdroje jsou často anotované, hodnocené z více hledisek. digitální knihovna - spravovaná sbírka informací, spolu se službami. informace jsou v digitální podobě a dostupné prostřednictvím sítě.")
88
Předmětové adresáře výhody předmětových vyhledávačů
anotování a hodnocení zdrojů nevýhody použití různých klasifikačních schémat méně častá aktualizace subjektivita hodnocení daná lidským faktorem

89
Předmětové adresáře kdy použijeme předmětový adresář
okruh vyhledávaného tématu je příliš široký chceme-li získat relevantnější obsah než prostřednictvím vyhledávačů chceme-li získat přehled webových sídel, které doporučili experti většina adresářů používá způsob prohlížení i vyhledávání podle klíčových slov vyhledávání neprobíhá na celém webu jako u vyhledávačů, ale jen v záznamech adresáře

90
Předmětové adresáře druhy adresářů akademické a profesionální
jsou vytvořeny experty na danou problematiku, využívají se hlavně pro výzkumné účely komerční portály určeny nejširší veřejnosti, cílem je co největší návštěvnost

91
Předmětové adresáře Yahoo! výhody
jeden z prvních systémů, 1994 – univerzita ve Stanfordu jeden z největších adresářů denně aktualizovaný automatické spojení na Altavistu a Google hledaná slova jsou zvýrazněna podobně jako Google ukládá do paměti starší verze stránek – Casched

92
Předmětové adresáře Yahoo! nevýhody - vyhledávání
nedostatek pokročilých vyhledávacích možností – např. rozšíření minimální využití booleovských operátorů indexuje pouze prvních 500 Kb z webové stránky

93
Předmětové adresáře česká verze kategorie má editora
dmoz vznikl 1998 představuje nový přístup k organizování informací na internetu využívá princip externích redaktorů, kteří se starají o určitou tematickou oblast přispívat může každý, kdo má zájem na každé stránce je uveden zodpovědný redaktor nebo výzva „tato kategorie potřebuje redaktora“ česká verze kategorie má editora kategorie hledá editora

94
Předmětové adresáře (viz Neviditelný web)
příklady virtuálních knihoven Infomine ipl2 (viz Neviditelný web)
")
95
Světové metavyhledávače
umožňují současné vyhledávání ve více než jednom vyhledávacím nástroji nebo adresáři zastřešují vybrané vyhledávače a jejich prostřednictvím získávají výsledky

96
Světové metavyhledávače
výhody vyhledávání z jednoho místa pouze jednou zadáváme rešeršní dotaz výsledkem rešerše je jednotný seznam záznamů nevýhody většinou limitují počet záznamů z jednoho zdroje (zpravidla 10) nevyužívají všechny možnosti formulování rešeršního požadavku
 nevyužívají všechny možnosti formulování rešeršního požadavku.")
97
Světové metavyhledávače
Federated Query Server (Open Text Corporation) výkonný metavyhledávač od firmy Open Text Yippy! seskupování výsledků do klastrů Metacrawler DogPile Excite funguje od r. 1996, přináší poměrně kvalitní výsledky Metacrawler špičkový "metavyhledávací systém (University of Washington, Seattle, USA) pro rešerše využívá individuálních rešeršních systémů (Alta Vista, Lycos, Open Text atd.), eliminuje duplicity a vyhodnocuje výsledky vyhledávání a seskupuje DogPile využívá nejznámější vyhledávací stroje jako Google, Yahoo, Ask Jeeves, About, Teoma, FindWhat, LookSmart a další seskupuje výsledky stejně jako Metacrawler
 výkonný metavyhledávač od firmy Open Text. Yippy! seskupování výsledků do klastrů. Metacrawler. DogPile. Excite. funguje od r. 1996, přináší poměrně kvalitní výsledky. Metacrawler. špičkový metavyhledávací systém (University of Washington, Seattle, USA) pro rešerše využívá individuálních rešeršních systémů (Alta Vista, Lycos, Open Text atd.), eliminuje duplicity a vyhodnocuje výsledky vyhledávání a seskupuje. DogPile. využívá nejznámější vyhledávací stroje jako Google, Yahoo, Ask Jeeves, About, Teoma, FindWhat, LookSmart a další. seskupuje výsledky stejně jako Metacrawler.")
98
Neviditelný web neviditelný web, skrytý web, hlubinný web
invisible web, hidden web, deep web kolem r. 1999, se zjistilo, že vyhledávací stroje neindexují stále více webovského prostoru některé vyhledavače mohou najít pouze zlomek informací z webové stránky nebo vstupní bránu k databázi, ale další obsah již nemohou prohledat proto jsou takové stránky označována jako stránky neviditelné

99
Neviditelný web Michael K. Bergman

100
Neviditelný web Michael K. Bergman

101
Neviditelný web Obsah neviditelného webu podle tematických oblastí

102
Neviditelný web důvody
vyhledávací stroje nedokážou vyhledávat v databázích vyhledávací stroje nedokážou indexovat dynamicky se měnící stránky (informace se generují z databáze) omezená přístupová práva (na některé stránky je přístup chráněn heslem - katalogy knihoven, databáze apod.) – stránky s neveřejným obsahem pro mnoho vyhledávačů jsou jiné typy souborů než html nečitelné k řadě stránek nevedou odkazy z jiných stránek – odpojené stránky (až 22% webu) mnoho vyhledávacích strojů má omezení na počet indexovaných stránek z určité domény apod. Běžné vyhledávací nástroje (vyhledávací stroje, angl. search engines) nemohou podobný typ informací ve svých databázích registrovat, buď pro technická omezení, nebo proto, že je jejich robotům (programům, které získávají informace z webových serverů) vstup do těchto zdrojů zakázán. dynamicky generované stránky Některé stránky vytvářejí svůj obsah teprve na základě požadavku uživatele. Tyto tzv. dynamické stránky jsou psány různými programovými a skriptovacími jazyky, které na základě vložených dat stránku vytvářejí. Každá takto vytvořená stránka je unikátní a již pravděpodobně nedojde k dalšímu zobrazení stránky ve stejné podobě. Typickým příkladem jsou různé databáze (dotazy v databázích), výpisy z ceníků nebo různé kalkulátory (konverze měn, výpočet tělesného tuku atd.). Takto generované stránky mají navíc ještě dynamicky generovanou adresu- naapř. .../cv.asp?PID=25152&UI, která je platná pouze pro tuto operaci a dále nebude platná. omezená přístupová práva ke stránkám Každá stránka může vyhledavači zakázat aby ji zaindexoval (zaregistroval). Pokud budou tyto pokyny zápsány v hlavičce stránky, každý vyhledavač, který na stránku narazí, nebude stránku zapisovat a ihned ji opustí. Tato možnost byla vytvořena pro stránky, které nemají veřejný charakter a tvůrce nemá zájem na jejich zveřejnění. Další překážkou pro vyhledavače mohou být kódované stránky, kde je pro přístup vyžadováno heslo. Obsah, který se tak skrývá pod zakódovanými stránkami nemůže být prohledán anebo prohledán a zaindexován je, ale uživatel k němu nemá přístup. zvláštní typy dokumentů, které vyhledavače neumí prohledávat Formáty jiného formátu než HTML jsou pro většinu vyhledavačů nečitelné. Některé formáty (PDF, Postscript) některé vyhledavače sice umí prohledávat (např. AltaVista -PDF, Google - PDF, PS) ale jiné jsou zatím velmi tvrdým oříškem (formáty Macromedia Flash, skriptovací jazyky apod.). Za tohoto stavu není možné získat úplné informace, které se na stránkách vyskytují. tzv. "samotáři" - stránky, které nemají odkazy na jiné a na které také není odkaz Dnes se již tento problém vyskytuje méně často, ale pořád přetrvává. Na některé stránky neexistují odkazy z jiných stránek, které by je umožňovaly nalézt. To se týká i celých prezentací. Vyhledavač zpravidla sleduje různé odkazy ze stránek a tak nacházejí další stránky, které pak registrují ve své databázi. Stránky, na které nejsou odkazy, pak mohou být (ale také nemusí) nalezeny vyhledavačem.
 omezená přístupová práva (na některé stránky je přístup chráněn heslem - katalogy knihoven, databáze apod.) – stránky s neveřejným obsahem. pro mnoho vyhledávačů jsou jiné typy souborů než html nečitelné. k řadě stránek nevedou odkazy z jiných stránek – odpojené stránky (až 22% webu) mnoho vyhledávacích strojů má omezení na počet indexovaných stránek z určité domény. apod. Běžné vyhledávací nástroje (vyhledávací stroje, angl. search engines) nemohou podobný typ informací ve svých databázích registrovat, buď pro technická omezení, nebo proto, že je jejich robotům (programům, které získávají informace z webových serverů) vstup do těchto zdrojů zakázán. dynamicky generované stránky Některé stránky vytvářejí svůj obsah teprve na základě požadavku uživatele. Tyto tzv. dynamické stránky jsou psány různými programovými a skriptovacími jazyky, které na základě vložených dat stránku vytvářejí. Každá takto vytvořená stránka je unikátní a již pravděpodobně nedojde k dalšímu zobrazení stránky ve stejné podobě. Typickým příkladem jsou různé databáze (dotazy v databázích), výpisy z ceníků nebo různé kalkulátory (konverze měn, výpočet tělesného tuku atd.). Takto generované stránky mají navíc ještě dynamicky generovanou adresu- naapř. .../cv.asp PID=25152&UI, která je platná pouze pro tuto operaci a dále nebude platná. omezená přístupová práva ke stránkám Každá stránka může vyhledavači zakázat aby ji zaindexoval (zaregistroval). Pokud budou tyto pokyny zápsány v hlavičce stránky, každý vyhledavač, který na stránku narazí, nebude stránku zapisovat a ihned ji opustí. Tato možnost byla vytvořena pro stránky, které nemají veřejný charakter a tvůrce nemá zájem na jejich zveřejnění. Další překážkou pro vyhledavače mohou být kódované stránky, kde je pro přístup vyžadováno heslo. Obsah, který se tak skrývá pod zakódovanými stránkami nemůže být prohledán anebo prohledán a zaindexován je, ale uživatel k němu nemá přístup. zvláštní typy dokumentů, které vyhledavače neumí prohledávat Formáty jiného formátu než HTML jsou pro většinu vyhledavačů nečitelné. Některé formáty (PDF, Postscript) některé vyhledavače sice umí prohledávat (např. AltaVista -PDF, Google - PDF, PS) ale jiné jsou zatím velmi tvrdým oříškem (formáty Macromedia Flash, skriptovací jazyky apod.). Za tohoto stavu není možné získat úplné informace, které se na stránkách vyskytují. tzv. samotáři - stránky, které nemají odkazy na jiné a na které také není odkaz Dnes se již tento problém vyskytuje méně často, ale pořád přetrvává. Na některé stránky neexistují odkazy z jiných stránek, které by je umožňovaly nalézt. To se týká i celých prezentací. Vyhledavač zpravidla sleduje různé odkazy ze stránek a tak nacházejí další stránky, které pak registrují ve své databázi. Stránky, na které nejsou odkazy, pak mohou být (ale také nemusí) nalezeny vyhledavačem.")
103
Neviditelný web neviditelný web je až 500krát větší než tzv. povrchový web obsahuje kvalitní dokumenty (1000 až 2000krát kvalitnější než v povrchovém webu) je to nejrychleji rostoucí část webu až 95% informací v neviditelném webu patří k veřejně přístupným informacím, které jsou přístupné bez poplatků
 je to nejrychleji rostoucí část webu. až 95% informací v neviditelném webu patří k veřejně přístupným informacím, které jsou přístupné bez poplatků.")
104
Neviditelný web jak funguje běžný vyhledávací stroj
na základě klíčového slova hledá ve své databázi nebo indexu důležitou součástí je robot jestli-že na některé stránky nevedou spojení, robot je nenajde „odpojené“ stránky představují až 22% současného internetu a tvoří tzv. skutečně neviditelný web běžné vyhledávací stroje - zpravidla optimalizované na textové dokumenty nevyhledávají v databázích na základě klíčového slova hledá v databázi nebo indexu a oznámí uživateli výsledek důležitou součástí je robot - prohledává web s cílem najít dokument a zároveň všechny dokumenty, které tento dokument cituje jestli-že na některé stránky nevedou spojení, robot je nenajde - „odpojené“ stránky představují až 22% současného internetu - tzv. skutečně neviditelný web vyhledávací stroje jsou zpravidla optimalizované na textové dokumenty, většina strojů neindexuje ani formáty pdf, postscript apod. Nelze zadat dotaz typu: najdi obraz podobný Moně Lise apod. nevyhledávají v db, dostanou se jen k rozhraní

105
Neviditelný web Možnosti vyhledávacích strojů se stále zdokonalují
typy obsahu v neviditelném webu a důvody neviditelnosti odpojené stránky robot nemůže sledovat spojení na stránku stránka obsahuje hlavně obrázky, video, audio nedostatek textu, aby robot porozuměl obsahu stránka obsahuje hlavně soubory pdf, postscript, flash apod. stránka se většinou neindexuje z ekonomických důvodů obsah v relačních databázích roboty nedokážou vyplnit požadovaná pole v interaktivních formulářích obsah se mění v reálném čase obrovské množství dat, které se neustále mění Možnosti vyhledávacích strojů se stále zdokonalují Vyhledávací stroj je systém, který na základě klíčového slova hledá v databázi nebo indexu a oznámí uživateli výsledek Důležitou součástí je robot, který prohledává web s cílem najít dokument a všechny dokumenty, na které nalezený dokument odkazuje

106
Neviditelný web příklad rozdílu mezi „viditelným“ a „neviditelným“ webem viditelný: iCivil Engineering - neviditelný: Civil Engineering database -

107
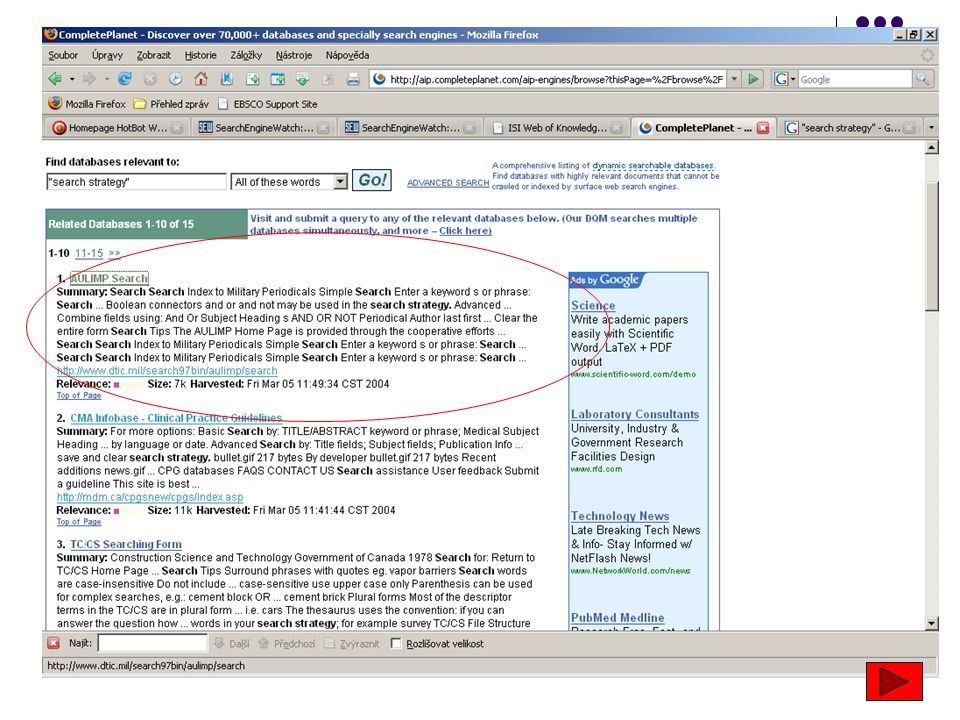
Neviditelný web brány pro neviditelný web Complete Planet
umožňuje vyhledávání ve více než databází a specializovaných vyhledávacích nástrojích - zdarma vyhledávání nebo prohlížení využití booleovských operátorů u záznamů je uvedená míra relevance Turbo10 – metasearch engine, která poskytuje interface k vyhledávačům Turbo10 posílá dotaz také do některých speciálních vyhledávačů (celkový uváděný počet se blíží číslu 800). Nabízí i část www prostoru, který nazýváme hlubokým či neviditelným webem (deep/invisible web).
. Nabízí i část www prostoru, který nazýváme hlubokým či neviditelným webem (deep/invisible web).")
108
Neviditelný web brány pro neviditelný web Scirus – www.scirus.com
vyhledávací stroj Elsevieru – vyhledává ve viditelném i neviditelném webu specifický vyhledávací nástroj pro odborné informace (záměrná filtrace nevědeckých obsahů, hluboká indexace www, vědeckých databází)
")
109
Neviditelný web ipl2 – dříve Librarians‘ Index to the Internet
digitální knihovna, ale zahrnuje zdroje ze skrytého webu předmětový anotovaný adresář s více než 8000 internetových zdrojů vybrali a anotovali odborníci z oblasti organizace vědění systém udržuje přes 100 specialistů každodenní aktualizace

110
Neviditelný web Infomine
digitální knihovna, ale zahrnuje zdroje ze skrytého webu od r jako systém University of California vytvářejí ho informační profesionálové přístup k více než databází zdroj především pro akademickou komunitu propracované možnosti vyhledávání u každého záznamu seznam předmětových hesel a klíčových slov (More info… )
")
111
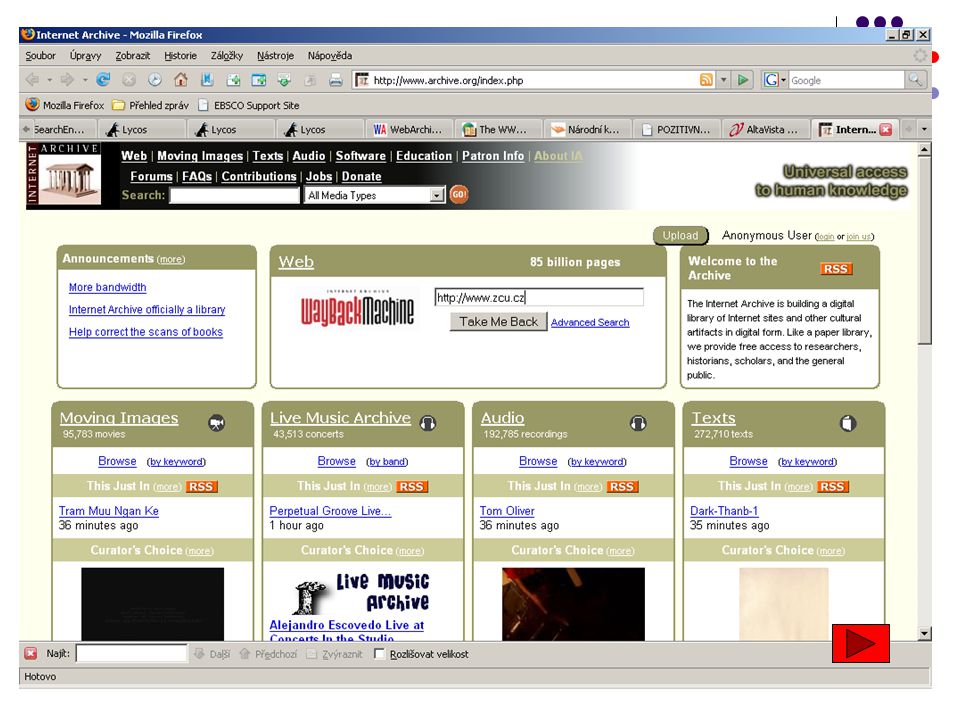
Archiv webu Internet Archive Wayback Machine http://www.archive.org
asi 10 miliard stránek v rozsahu 1Pbyte (7/2004) snaha o zpracování, uchovávání a zpřístupnění webových zdrojů jako specifické kategorie elektronických dokumentů první svého druhu, je Internet Archive cíl: budování archivu celého volně přístupného webu na konci října 2001 uvedena do provozu služba Wayback Machine, která je bránou k tomuto archivu nabízí všem uživatelům unikátní příležitost prohlížet vybrané webové zdroje v podobě, jakou měly před pěti lety nebo minulý měsíc, a to na základě zadaného URL - vyhledávání je možné omezit na určité období hodnotu tohoto systému zvyšuje fakt, že některé z webových zdrojů nemusí vůbec existovat nebo jsou přesunuty na neznámou adresu Problémy:odezva systému na rešeršní požadavek je nezřídka poměrně pomalá zdaleka ne všechny stránky jsou kompletně "zrekonstruovány" - chybějí na nich obrázky, odkazy nejsou funkční a konečně archiv není úplný (podobně jako v případě běžných webových vyhledávacích služeb nelze zaručit, že jejich robot se dostane na všechny stránky)
 snaha o zpracování, uchovávání a zpřístupnění webových zdrojů jako specifické kategorie elektronických dokumentů. první svého druhu, je Internet Archive. cíl: budování archivu celého volně přístupného webu. na konci října 2001 uvedena do provozu služba Wayback Machine, která je bránou k tomuto archivu. nabízí všem uživatelům unikátní příležitost prohlížet vybrané webové zdroje v podobě, jakou měly před pěti lety nebo minulý měsíc, a to na základě zadaného URL - vyhledávání je možné omezit na určité období. hodnotu tohoto systému zvyšuje fakt, že některé z webových zdrojů nemusí vůbec existovat nebo jsou přesunuty na neznámou adresu. Problémy:odezva systému na rešeršní požadavek je nezřídka poměrně pomalá. zdaleka ne všechny stránky jsou kompletně zrekonstruovány - chybějí na nich obrázky, odkazy nejsou funkční a konečně archiv není úplný (podobně jako v případě běžných webových vyhledávacích služeb nelze zaručit, že jejich robot se dostane na všechny stránky)")
112
Archiv webu WebArchiv - archiv českého webu
uchování digitálních dokumentů volně dostupných na webu co lze nalézt ve WebArchivu: publikace odborného, uměleckého a zpravodajsko- publicistického zaměření periodika, monografie, konferenční příspěvky, výzkumné a jiné zprávy, akademické práce textové a do jisté míry i obrazové a zvukové dokumenty existující pouze v digitální podobě

113
Problémy současného internetu
neustálý nárůst hostitelských počítačů nové typy dokumentů, které nejsou dostatečně indexované množství vyhledávacích nástrojů různé kvality žádný nástroj nepokrývá celý web obsah a lokalizace dokumentů se často mění málo vyhledávacích nástrojů hodnotí dokumenty současná verze html neumožňuje dostatečně popisovat obsah dokumentu (podává informaci o grafickém uspořádání dokumentu) – o postižení obsahu dokumentu se snaží tzv. „sémantický web“ sémantický web využívá jazyka XML u klasických webových stránek je pro počítač odstavec textu jen shlukem znaků pokud stránka bude doplněna o sémantiku (neboli význam), bude počítač vědět, že ten odstavec se týká např. loňských finančních výsledků firmy lepší relevantnost ve vyhledávačích, počítač bude moci zpracovávat data logicky (dle významu) a ne jen mechanicky (dle filtrů) atd. Základním krokem k vytvoření sémantického webu je konceptualizace dat dostupných na Internetu, jejíž klíčovým nástrojem jsou ontologie, aneb formalizované reprezentace znalostí určené k jejich sdílení a znovupoužití. Sémantický web je dále založen na standardizovaném popisu webových zdrojů (vše, dosažitelné pomocí WWW, tedy textové dokumenty, obrázky, videosekvence, zvukové soubory apod.). Každý zdroj by byl vybaven stejnými charakteristikami údaji (autor, typ zdroje, klíčová slova atd.), což by umožnilo uživatelům Internetu pracovat se sítí WWW jako s relační databází a dotazovat se na její obsah prostřednictvím jazyků podobných SQL. Důraz by se kladl na vysokou přesnost a relevanci odpovědi na vyhledávací dotaz.
 – o postižení obsahu dokumentu se snaží tzv. „sémantický web sémantický web využívá jazyka XML. u klasických webových stránek je pro počítač odstavec textu jen shlukem znaků. pokud stránka bude doplněna o sémantiku (neboli význam), bude počítač vědět, že ten odstavec se týká např. loňských finančních výsledků firmy. lepší relevantnost ve vyhledávačích, počítač bude moci zpracovávat data logicky (dle významu) a ne jen mechanicky (dle filtrů) atd. Základním krokem k vytvoření sémantického webu je konceptualizace dat dostupných na Internetu, jejíž klíčovým nástrojem jsou ontologie, aneb formalizované reprezentace znalostí určené k jejich sdílení a znovupoužití. Sémantický web je dále založen na standardizovaném popisu webových zdrojů (vše, dosažitelné pomocí WWW, tedy textové dokumenty, obrázky, videosekvence, zvukové soubory apod.). Každý zdroj by byl vybaven stejnými charakteristikami údaji (autor, typ zdroje, klíčová slova atd.), což by umožnilo uživatelům Internetu pracovat se sítí WWW jako s relační databází a dotazovat se na její obsah prostřednictvím jazyků podobných SQL. Důraz by se kladl na vysokou přesnost a relevanci odpovědi na vyhledávací dotaz.")
114
Závěr Kompendium Literatura:
MAKULOVÁ, SOŇA Vyhľadávanie informácií v internete : problémy, východiská, postupy. Bratislava : EL&T, 2002. BOLDIŠ, PETR. Jak oddělit zrno od plev: Ověřování informací v prostředí internetu [online] [citováno ]. < >. BOLDIŠ, PETR. Vyhledávání na internetu [online] [citováno ]. < Kompendium

115
Těšíme se na shledanou v knihovně

135
Počet webových stránek v miliónech

150
Command How Supported By Or OR
AltaVista, AOL Search, Excite, Google, Inktomi (HotBot, MSN), Lycos, Northern Light None AllTheWeb, Direct Hit, LookSmart, Not yet updated, but may be still correct: Yahoo And AND AltaVista, AOL Search, Excite, Inktomi (HotBot, MSN) Lycos, Northern Light AllTheWeb, Direct Hit, Google, LookSmart Not yet updated, but may be still correct: Yahoo Not NOT AOL Search, Excite, Inktomi (HotBot), Lycos, Northern Light AND NOT AltaVista, Inktomi (MSN) Not yet updated, but may be still correct: Netscape AllTheWeb, Direct Hit, Google, LookSmart, Not yet updated, but may be still correct: Yahoo Nesting ( ) AltaVista, AOL Search, Excite, Inktomi (MSN), Northern Light AllTheWeb, Direct Hit, Google, Inktomi (HotBot), LookSmart, Lycos Not yet updated, but may be still correct: Yahoo Near NEAR AltaVista (10 words), AOL Search (specify number), Lycos (25 words) AllTheWeb, Direct Hit, Google, Inktomi (HotBot, MSN), LookSmart Notes At AltaVista, Boolean only works on advanced search page. At Excite, Google & MSN, Boolean commands must be in UPPERCASE At Inktomi-powered services, set menu to "Boolean"
, Lycos, Northern Light. None. AllTheWeb, Direct Hit, LookSmart, Not yet updated, but may be still correct: Yahoo. And. AND. AltaVista, AOL Search, Excite, Inktomi (HotBot, MSN) Lycos, Northern Light. AllTheWeb, Direct Hit, Google, LookSmart Not yet updated, but may be still correct: Yahoo. Not. NOT. AOL Search, Excite, Inktomi (HotBot), Lycos, Northern Light. AND NOT. AltaVista, Inktomi (MSN) Not yet updated, but may be still correct: Netscape. AllTheWeb, Direct Hit, Google, LookSmart, Not yet updated, but may be still correct: Yahoo. Nesting. ( ) AltaVista, AOL Search, Excite, Inktomi (MSN), Northern Light. AllTheWeb, Direct Hit, Google, Inktomi (HotBot), LookSmart, Lycos Not yet updated, but may be still correct: Yahoo. Near. NEAR. AltaVista (10 words), AOL Search (specify number), Lycos (25 words) AllTheWeb, Direct Hit, Google, Inktomi (HotBot, MSN), LookSmart. Notes At AltaVista, Boolean only works on advanced search page. At Excite, Google & MSN, Boolean commands must be in UPPERCASE At Inktomi-powered services, set menu to Boolean")
160
Makulová

163
Vyhledávání na internetu
existuje mnoho definic internetu příklady: zdůraznění technické stránky komplexní globální síť skládající se z dalších nezávislých sítí soubor norem nebo protokolů TCP/IP, které umožňují komunikaci mezi počítačovými sítěmi nejrůznějších druhů zdůraznění sociálně-komunikační stránky informační médium, kde najdeme množství nejaktuálnějších informací a služeb komunikační médium umožňující miliónům lidí být v neustálém kontaktu v reálném čase TCP/IP – Transfer Control Protocol/Internet Protocol Internet jako: Informační médium Komunikační médium Reklamní a marketingové médium Obchodní médium Zábavní médium atd.

164
Úvod technické aspekty neexistuje centrální regulační orgán HyperText Transfer Protocol (HTTP) World Wide Web - založený na hypertextu HyperText Markup Language (HTML) prohlížeč, např. MS Explorer, Firefox, Opera URL - Uniform Resource Locator URL – Uniform Resource Locator = jedinečná adresa dokumentu na webu
 prohlížeč, např. MS Explorer, Firefox, Opera. URL - Uniform Resource Locator. URL – Uniform Resource Locator = jedinečná adresa dokumentu na webu.")
165
Úvod historie 1969 - ARPANET vybudování sítě bez centrálního uzlu
dojde-li ke zničení některé z linek, informace putuje jinou trasou Základní data z historie internetu 60. léta Americká armáda hledá způsob, jak zajistit, aby armádní počítače rozmístěné po celém území USA spolu bez problému komunikovaly a to i ve chvíli, kdy část sítě je vyřazena z provozu; návrh na vybudování sítě bez centrálního uzlu (dojde-li ke zničení některé z linek, informace putuje jinou trasou); 1969: první komunikace po síti složené ze čtyř uzlů: University of California (UCLA) v Los Angeles, Stanford Research Institute, UC Santa Barbara a University of Utah v Salt Lake City, tj. vzniká ARPANET; časem se přidávají další instituce, především z akademického prostředí; síť je nekomerční záležitostí, na jejíž provozování přispívá ze svých zdrojů americká armáda a vládní agentury;
; 1969: první komunikace po síti složené ze čtyř uzlů: University of California (UCLA) v Los Angeles, Stanford Research Institute, UC Santa Barbara a University of Utah v Salt Lake City, tj. vzniká ARPANET; časem se přidávají další instituce, především z akademického prostředí; síť je nekomerční záležitostí, na jejíž provozování přispívá ze svých zdrojů americká armáda a vládní agentury;")
166
Úvod historie - pokračování HTML - HyperText Markup Language
vznik www World Wide Web (W3 nebo WWW) Tim Berners-Lee – CERN – Ženeva 1991 distribuovaný multimediální hypertextový systém v rámci www navrhl: HTML - HyperText Markup Language HTTP - HyperText Transfer Protocol URL - Universal Resource Locator Tim Berners-Lee CERN – Laboratory for Particle Physics (fyzika elementárních částic) V r programátoři Tim Berners-Lee a Robert Cailliau v CERN v Ženevě vyvinuli www. V říjnu 1990 začali práci na prvním webovém klientovi, který by umožnil vytváření, editování a prohlížení webových stránek. V souvislosti s tím vytvořil jazyk html. Všechny dokumenty napsané v tomto jazyce se zobrazovaly identicky na různých platformách počítačů kdekoliv na světě. Dále vytvořil HTTP – HyperText Transfer Protocol – jako soubor pravidel, které využívaly počítače v internetu. Podobně Tim Berners-Lee navrhl i URL – Universal Resource Locator – jako standard, který umožnil přidělení jedinečné adresy každému dokumentu v internetu. Tak už v prosinci byly položeny základy toho, čemu říkáme Worl Wide Web. Pro přenos souborů na internetu používá HyperText Transfer Protocol (HTTP). Pohyb uvnitř samotného dokumentu usnadňují hypertextové odkazy (hyperlinky), jejichž prostřednictvím je možné přejít na jinou část dokumentu či jiný dokument umístěný v podstatě na libovolném místě na internetu. Pro práci s WWW je nezbytný browser (prohlížeč). Základním prostředkem pro tvorbu WWW dokumentů je HyperText Markup Language (HTML).
 Tim Berners-Lee – CERN – Ženeva distribuovaný multimediální hypertextový systém. v rámci www navrhl: HTML - HyperText Markup Language. HTTP - HyperText Transfer Protocol. URL - Universal Resource Locator. Tim Berners-Lee CERN – Laboratory for Particle Physics (fyzika elementárních částic) V r programátoři Tim Berners-Lee a Robert Cailliau v CERN v Ženevě vyvinuli www. V říjnu 1990 začali práci na prvním webovém klientovi, který by umožnil vytváření, editování a prohlížení webových stránek. V souvislosti s tím vytvořil jazyk html. Všechny dokumenty napsané v tomto jazyce se zobrazovaly identicky na různých platformách počítačů kdekoliv na světě. Dále vytvořil HTTP – HyperText Transfer Protocol – jako soubor pravidel, které využívaly počítače v internetu. Podobně Tim Berners-Lee navrhl i URL – Universal Resource Locator – jako standard, který umožnil přidělení jedinečné adresy každému dokumentu v internetu. Tak už v prosinci byly položeny základy toho, čemu říkáme Worl Wide Web. Pro přenos souborů na internetu používá HyperText Transfer Protocol (HTTP). Pohyb uvnitř samotného dokumentu usnadňují hypertextové odkazy (hyperlinky), jejichž prostřednictvím je možné přejít na jinou část dokumentu či jiný dokument umístěný v podstatě na libovolném místě na internetu. Pro práci s WWW je nezbytný browser (prohlížeč). Základním prostředkem pro tvorbu WWW dokumentů je HyperText Markup Language (HTML).")
167
Úvod historie - pokračování
Základní charakteristiky www: distribuovaný informace se může nacházet v počítačovém systému na libovolném místě multimediální text, grafika, zvuk, video hypertextový objekty jsou navzájem propojené pomocí linků www = interface k internetu

168
Úvod historie - pokračování v ČR
úspěšné pokusy ČVUT při propojení Prahy a Lince únor oficiální datum připojení ČR k internetu první připojenou vysokou školou je ČVUT

169
Úvod počítače 1992 něco přes 1 milión 2007 přes 600 miliónů uživatelé
rychlý nárůst hostitelských počítačů a uživatelů počítače 1992 něco přes 1 milión 2007 přes 600 miliónů uživatelé počet obyvatelstva celkem více než 6,5 mld. uživatelé internetu 2007 asi 1,25mld (=18,9 %) v Evropě převládá skupina lidí od 21 do 30 let Hostitelský počítač – počítač, který přímo poskytuje služby uživateli
 v Evropě převládá skupina lidí od 21 do 30 let. Hostitelský počítač – počítač, který přímo poskytuje služby uživateli.")
170
Úvod netiquette neomezovat ostatní uživatele
nevstupovat do souborů, které jsou majetkem jiných osob nešířit fámy nekopírovat programy, za které jste nezaplatili hlídat si svoje heslo Netiquette S prudkým nárůstem počtu uživatelů internetu, kteří již nepřicházeli pouze z řad technicky vzdělaných "síťových" odborníků, bylo nutné formulovat soubor pravidel, jak se v síti chovat. Spojením dvou anglických slov "net" a "etiquette" vznikla "netiquette" – síťová etiketa. Jde o soubor doporučení, která je třeba dodržovat, abychom mohli bez problémů Internet používat ke spokojenosti všech ostatních.

171
Jak na rešerši Makulová

Podobné prezentace














>")
















. Slouží ke komunikaci.>")
