Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Bibliografická a rešeršní činnost
Specifika vyhledávání informací na internetu

2
Mgr. Miluše Mírková Univerzitní knihovna ZČU URL: tel URL:

3
Obsah Internet jako informační médium Vyhledávací nástroje internetu
Internetové vyhledávače Světové internetové vyhledávače České internetové vyhledávače Předmětové adresáře Světové metavyhledávače Neviditelný web Archiv webu Závěr

4
Internet jako informační médium
informační exploze denně vychází na světě přes 2 tisíce nových titulů tištěných knih + elektronické knihy (ročně celkem více než 800 tisíc titulů) 6 až 7 tisíc vědeckých článků na internetu jsou stovky miliard dokumentů v tištěné podobě vychází jen 0,003% celého obsahu publikované ve světě zdroje na internetu z hlediska přístupnosti: veřejné neveřejné (např. komerční databáze, periodika apod.) Zdroje informací na internetu: -veřejné; -neveřejné (většinou placené služby) - patří mezi ně často právě ty informace, které jsou lidé tradičně zvyklí hledat v knihovnách – noviny, časopisy, knihy, bibliografické databáze… Graf : GG – Google, AV – Altavista, INK – Inktomi, TMA – Theoma?, ATW - All The Web – v miliardách
 6 až 7 tisíc vědeckých článků. na internetu jsou stovky miliard dokumentů. v tištěné podobě vychází jen 0,003% celého obsahu publikované ve světě. zdroje na internetu z hlediska přístupnosti: veřejné. neveřejné (např. komerční databáze, periodika apod.) Zdroje informací na internetu: -veřejné; -neveřejné (většinou placené služby) - patří mezi ně často právě ty informace, které jsou lidé tradičně zvyklí hledat v knihovnách – noviny, časopisy, knihy, bibliografické databáze… Graf : GG – Google, AV – Altavista, INK – Inktomi, TMA – Theoma , ATW - All The Web – v miliardách.")
5
Internet jako informační médium
internet x komerční zdroje informací internet dynamický (neustálá aktualizace) distribuovaný (bez centrální autority) – otázka kvality a důvěryhodnosti informací komerční zdroje (bibliografické databáze apod.) propracovanější vyhledávací nástroje (pracují se strukturovanou databází – exaktnější vyhledávání) hlavní důraz ne na množství, ale kvalitu zdrojů zařazovaných do databází (recenzované zdroje, autoritativní zdroje atd.) komerční – tedy placené
 distribuovaný (bez centrální autority) – otázka kvality a důvěryhodnosti informací. komerční zdroje (bibliografické databáze apod.) propracovanější vyhledávací nástroje (pracují se strukturovanou databází – exaktnější vyhledávání) hlavní důraz ne na množství, ale kvalitu zdrojů zařazovaných do databází (recenzované zdroje, autoritativní zdroje atd.) komerční – tedy placené.")
6
Internet jako informační médium
zásady pro vyhledávání na internetu uvědomit si, že internet není knihovna (v knihovně jsou zdroje zpracovány a organizovány) – internet je neuspořádaný a chaotický dokázat odhadnout, co má smysl hledat na internetu vybrat správná místa, kde s hledáním začít osvojit si práci s vyhledávacími nástroji přečíst si nápovědu správně formulovat dotaz použít synonyma a příbuzné výrazy zkontrolovat pravopis nenechat se odradit počátečním neúspěchem a nespokojit se jen s jedním hledáním Obrovské množství webových dokumentů – obsah webu není a nemůže být zpracován pomocí standardizovaného jazyka Při práci s Internetem mají velký význam i znalosti z tradičního prostředí. Poučený a zkušený uživatel snáze najde a rozpozná kvalitní a užitečné informační zdroje, nežli ten, kdo jen spoléhá na náhodu nebo využívá stále jedinou vyhledávací službu a ještě ke všemu tím nejjednodušším způsobem.
 – internet je neuspořádaný a chaotický. dokázat odhadnout, co má smysl hledat na internetu. vybrat správná místa, kde s hledáním začít. osvojit si práci s vyhledávacími nástroji. přečíst si nápovědu. správně formulovat dotaz. použít synonyma a příbuzné výrazy. zkontrolovat pravopis. nenechat se odradit počátečním neúspěchem a nespokojit se jen s jedním hledáním. Obrovské množství webových dokumentů – obsah webu není a nemůže být zpracován pomocí standardizovaného jazyka. Při práci s Internetem mají velký význam i znalosti z tradičního prostředí. Poučený a zkušený uživatel snáze najde a rozpozná kvalitní a užitečné informační zdroje, nežli ten, kdo jen spoléhá na náhodu nebo využívá stále jedinou vyhledávací službu a ještě ke všemu tím nejjednodušším způsobem.")
7
Internet jako informační médium
zobrazení výsledků možnost nastavení počtu záznamů na stránce zobrazení stručných anotací nebo shrnutí vyznačení vyhledávaných termínů faktory, které mají vliv na uspořádání výsledků četnost výskytu slov počet výrazů v dotazu, jež se shodují s nalezeným dokumentem váha podle pole blízkost slov výskyt příbuzných slov a různých pravopisných variant pořadí slov v dotazu uživatele apod.

8
Internet jako informační médium
problém kvality zdrojů snadnost zveřejňování dokumentů přinesla publikační explozi informační zdroje nejsou odborně editovány autoři často zůstávají v anonymitě chybějí data zveřejnění je těžké určit, jedná-li se o informaci původní obtížné rozlišování skutečných seriózních informací od reklamních textů

9
Internet jako informační médium
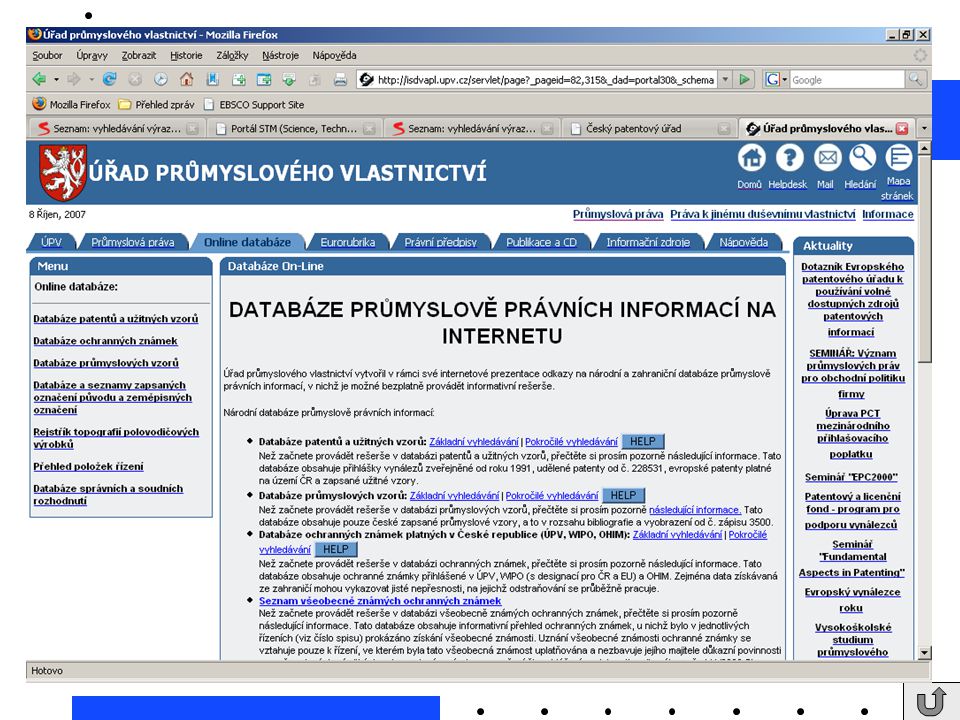
zásady pro hodnocení dokumentů kvalifikace autora: v které instituci autor pracuje – lze to poznat i z URL, zda se jeho jméno vyskytuje v tištěných zdrojích, v Science Citation Indexu (Web of Science), zda je na něj uveden kontakt struktura informačního zdroje: zda respektuje stránka nejnovější doporučení pro tvorbu WWW jestli jsou na stránce odkazy a další citace je-li způsob navigace na stránce srozumitelný zda je stránka registrovaná ve vyhledávacích nástrojích internetu, adresářích a digitálních (virtuálních) knihovnách Tvorba webových dokumentů souvisí velmi úzce s problematikou jejich hledání a nalézání. Každý dokument, který je součástí webového sídla (angl. website), by měl mít vlastní název Názvy odkazů patří totiž mezi ty části dokumentu, jež se načítají do databází vyhledávacích služeb. Z tohoto pohledu je zřejmé, jak nesmyslné jsou odkazy typu „klikněte zde“, „jděte tudy“ apod. Takovéto výrazy mají pro hledání informací, ke kterým odkaz vede, nulovou hodnotu. Názvy odkazů by samozřejmě měly být výstižné a stručné
, zda je na něj uveden kontakt. struktura informačního zdroje: zda respektuje stránka nejnovější doporučení pro tvorbu WWW. jestli jsou na stránce odkazy a další citace. je-li způsob navigace na stránce srozumitelný. zda je stránka registrovaná ve vyhledávacích nástrojích internetu, adresářích a digitálních (virtuálních) knihovnách. Tvorba webových dokumentů souvisí velmi úzce s problematikou jejich hledání a nalézání. Každý dokument, který je součástí webového sídla (angl. website), by měl mít vlastní název. Názvy odkazů patří totiž mezi ty části dokumentu, jež se načítají do databází vyhledávacích služeb. Z tohoto pohledu je zřejmé, jak nesmyslné jsou odkazy typu „klikněte zde , „jděte tudy apod. Takovéto výrazy mají pro hledání informací, ke kterým odkaz vede, nulovou hodnotu. Názvy odkazů by samozřejmě měly být výstižné a stručné.")
10
Internet jako informační médium
zásady pro hodnocení dokumentů – pokračování obsah informačního zdroje: kdo je cílovou skupinou stránky jaká je hodnota stránky v porovnáním s dalšími zdroji relevantními k tématu jaká je úroveň pokrytí dané problematiky zda je text srozumitelný, přehledný a bez chyb jestli jsou předkládané informace objektivní jestli jsou informace aktuální zda uvádí autor důkazy pro svá tvrzení a odkazy na použité zdroje jestli byla stránka recenzovaná nebo hodnocená

11
Internet jako informační médium
zásady pro hodnocení dokumentů – pokračování datum vydání stránky – problém rozeznat: kdy byla vytvořena kdy byla naposledy aktualizována jsou odkazy aktuální apod.

12
Vyhledávací nástroje internetu
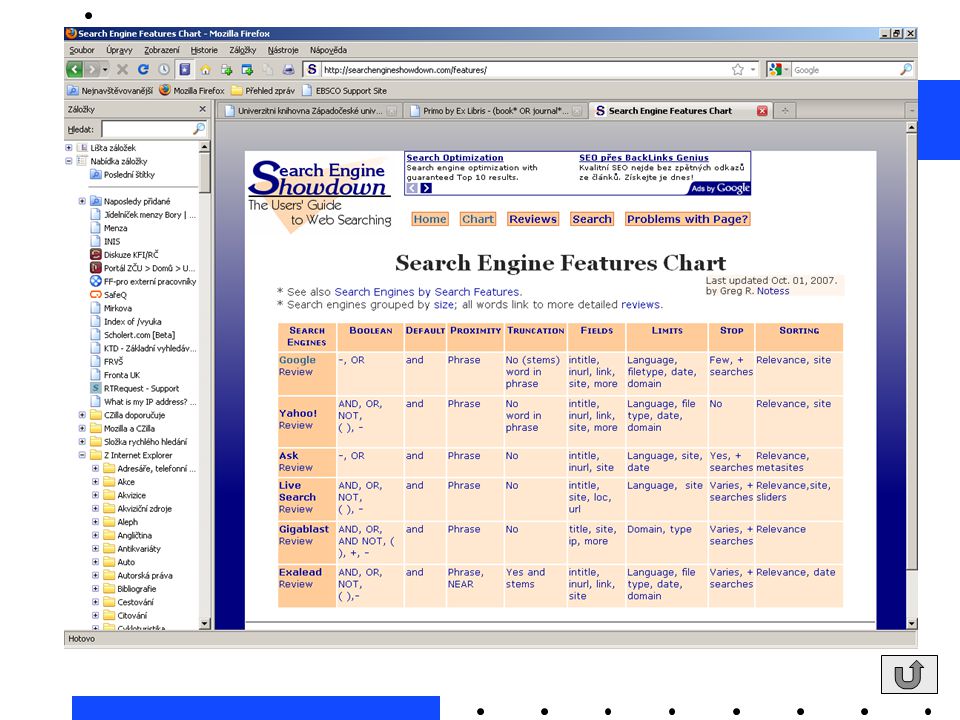
booleovská logika se v současných vyhledávacích nástrojích používá třemi způsoby úplné booleovské vyhledávání s použitím logických operátorů implicitní booleovské vyhledávání předdefinovaná terminologie ve formulářích

13
Vyhledávací nástroje internetu
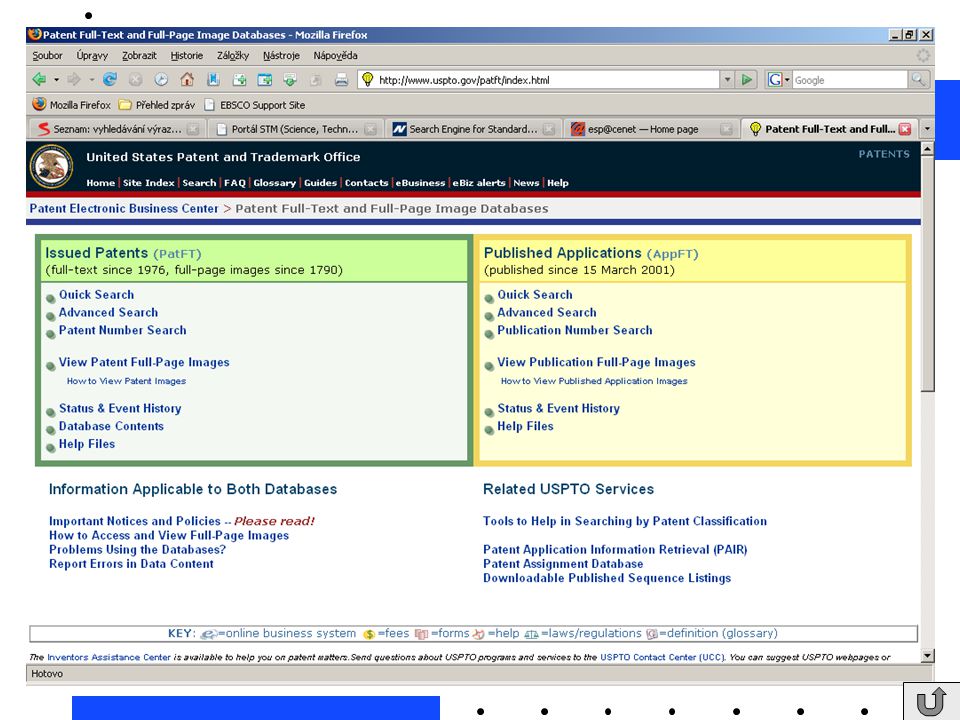
volba vyhledávacího nástroje odhad webové adresy použití předmětového adresáře (klasifikace zdrojů podle předmětových kategorií) použití internetového vyhledávače (vyhledávácí služby nepostihují celý obsah webu – tzv. neviditelný web mnohdy nedokážou běžné nástroje prohledat) použít několik vyhledávačů – každý z nich může nalézt unikátní dokumenty Odhad URL adresy: nebo nebo apod. zkratky názvu instituce „oříznutí“ adresy známého dokumentu („Oříznutí“ adresy dokumentu nebo pokus o její modifikaci bohužel často končívá nezdarem. Jedním z důvodů, proč podobný postup nefunguje vždy, jsou nevhodné postupy tvůrců webových dokumentů. Absence určitých znalostí se projevuje i tím, jakým způsobem strukturují své internetové informace. To se pak odráží také v názvech souborů a cestách k informacím na některých serverech. Jde samozřejmě o složitější problém související s provozem serverů obecně, s informační architekturou webových sídel, obsahem i designem webových dokumentů a služeb. Přesto můžete podobný způsob pohybu po Webu a objevování nových informací – někdy – s úspěchem vyzkoušet.) Přidání vhodné koncovky, v ČR nejčastěji .cz, u zahraničních – zejména amerických zdrojů .com Nejobvyklejší zakončení: com for commercial edu for educational org for other organizations gov for U.S. federal government mil for U.S. military net for Internet service providers and networks Zeměpisné domény korespondují s dvoumístnými kódy zemí podle normy ISO. Můžete si je v tištěné podobě zjistit v normě ČSN EN ISO Kódy pro názvy zemí a jejich částí – Část 1: Kódy zemí. Kompletní seznam najdeme na adrese: nebo
 použití internetového vyhledávače (vyhledávácí služby nepostihují celý obsah webu – tzv. neviditelný web mnohdy nedokážou běžné nástroje prohledat) použít několik vyhledávačů – každý z nich může nalézt unikátní dokumenty. Odhad URL adresy: nebo nebo apod. zkratky názvu instituce. „oříznutí adresy známého dokumentu. („Oříznutí adresy dokumentu nebo pokus o její modifikaci bohužel často končívá nezdarem. Jedním z důvodů, proč podobný postup nefunguje vždy, jsou nevhodné postupy tvůrců webových dokumentů. Absence určitých znalostí se projevuje i tím, jakým způsobem strukturují své internetové informace. To se pak odráží také v názvech souborů a cestách k informacím na některých serverech. Jde samozřejmě o složitější problém související s provozem serverů obecně, s informační architekturou webových sídel, obsahem i designem webových dokumentů a služeb. Přesto můžete podobný způsob pohybu po Webu a objevování nových informací – někdy – s úspěchem vyzkoušet.) Přidání vhodné koncovky, v ČR nejčastěji .cz, u zahraničních – zejména amerických zdrojů .com. Nejobvyklejší zakončení: com for commercial edu for educational org for other organizations gov for U.S. federal government mil for U.S. military net for Internet service providers and networks. Zeměpisné domény korespondují s dvoumístnými kódy zemí podle normy ISO. Můžete si je v tištěné podobě zjistit v normě ČSN EN ISO Kódy pro názvy zemí a jejich částí – Část 1: Kódy zemí. Kompletní seznam najdeme na adrese: nebo")
14
Vyhledávací nástroje internetu
internetové vyhledávače, služby typu „search engines“, vyhledávací stroje, vyhledávací systémy předmětové adresáře a digitální (virtuální) knihovny (prohlížení) většina velkých vyhledávacích služeb nabízí - dvě základní možnosti prohledávání své databáze: postupným procházením hierarchicky uspořádaného systému menu příkazem/dotazem tvořeným klíčovými slovy vyjadřujícími hledané téma metavyhledávací nástroje Většina velkých vyhledávacích služeb nabízí uživateli dvě základní možnosti prohledávání své databáze: postupným procházením hierarchicky uspořádaného systému menu, příkazem/dotazem tvořeným klíčovými slovy vyjadřujícími hledané téma. Služby primárně založené na automatizovaném sběru dat a zpětném vyhledávání prostřednictvím klíčových slov, tj. vyhledávací stroje, proto doplnily svoji nabídku o přístup k vybraným zdrojům procházením hierarchicky uspořádaných předmětových skupin. Zpravidla pro tento účel využívají jiných služeb přizpůsobených vlastním potřebám. Například služba Google pro tento účel používá poněkud modifikovanou podobu Open Directory. Naopak služby, u nichž je prvotní funkcí zpřístupnění odkazů na informační zdroje prostřednictvím hierarchicky uspořádaných předmětových skupin, nabízejí uživatelům také možnost prohledávání své vlastní databáze klíčovými slovy. Obsah databáze je shodný s daty zpřístupňovanými předmětově, jejich rozsah je tedy (ve srovnání s databázemi vyhledávacích strojů) poměrně omezený. Proto také v případě, že se hledané zdroje v jejich databázi nenajdou, nabízejí tyto služby uživatelům i možnost vyhledat zadaný dotaz zvoleným vyhledávacím strojem nebo alespoň odkazy na řadu dalších vyhledávacích služeb, které můžete také pro vyhledávání použít. Některé služby provedou vyhledání v jiném zdroji automaticky (např. Yahoo!).
 knihovny (prohlížení) většina velkých vyhledávacích služeb nabízí - dvě základní možnosti prohledávání své databáze: postupným procházením hierarchicky uspořádaného systému menu. příkazem/dotazem tvořeným klíčovými slovy vyjadřujícími hledané téma. metavyhledávací nástroje. Většina velkých vyhledávacích služeb nabízí uživateli dvě základní možnosti prohledávání své databáze: postupným procházením hierarchicky uspořádaného systému menu, příkazem/dotazem tvořeným klíčovými slovy vyjadřujícími hledané téma. Služby primárně založené na automatizovaném sběru dat a zpětném vyhledávání prostřednictvím klíčových slov, tj. vyhledávací stroje, proto doplnily svoji nabídku o přístup k vybraným zdrojům procházením hierarchicky uspořádaných předmětových skupin. Zpravidla pro tento účel využívají jiných služeb přizpůsobených vlastním potřebám. Například služba Google pro tento účel používá poněkud modifikovanou podobu Open Directory. Naopak služby, u nichž je prvotní funkcí zpřístupnění odkazů na informační zdroje prostřednictvím hierarchicky uspořádaných předmětových skupin, nabízejí uživatelům také možnost prohledávání své vlastní databáze klíčovými slovy. Obsah databáze je shodný s daty zpřístupňovanými předmětově, jejich rozsah je tedy (ve srovnání s databázemi vyhledávacích strojů) poměrně omezený. Proto také v případě, že se hledané zdroje v jejich databázi nenajdou, nabízejí tyto služby uživatelům i možnost vyhledat zadaný dotaz zvoleným vyhledávacím strojem nebo alespoň odkazy na řadu dalších vyhledávacích služeb, které můžete také pro vyhledávání použít. Některé služby provedou vyhledání v jiném zdroji automaticky (např. Yahoo!).")
15
Vyhledávací nástroje internetu
hlavní odlišnosti jednotlivých typů vyhledávacích nástrojů: internetové vyhledávače – založené na automatizovaném sběru dat prostřednictvím robotů primárně určeny pro vyhledávání předmětové adresáře – vytvářeny ručně, zdroje jsou do nich zařazovány výběrově - specializace dva druhy: digitální (virtuální) knihovny soupisy zdrojů internetu určeny pro prohlížení metavyhledávací nástroje – zastřešují jednotlivé vyhledávače – jednotné vyhledávací prostředí pro více vyhledávačů vyhledávací stroje Tyto vyhledávací služby disponují nejrozsáhlejšími databázemi -sběr dat - tzv. roboti, též bot, spider, crawler nebo worm. Některé roboty mají dokonce vlastní jména, například program používaný pro sběr dat AltaVistou se jmenuje „Scooter“. Předmětové adresáře vznikají ručně, zdroje jsou do nich zařazovány výběrově Buď tyto informace poskytují vyhledávacím službám sami producenti internetových zdrojů vyplněním formuláře, který je součástí nabídky každé z vyhledávacích služeb (najdete je pod odkazy přidej stránku, add URL, submit URL apod.) nebo jsou informace o nových zdrojích zjišťovány pracovníky nebo spolupracovníky vyhledávacích služeb vlastním průzkumem Internetu.
 knihovny. soupisy zdrojů internetu. určeny pro prohlížení. metavyhledávací nástroje – zastřešují jednotlivé vyhledávače – jednotné vyhledávací prostředí pro více vyhledávačů. vyhledávací stroje. Tyto vyhledávací služby disponují nejrozsáhlejšími databázemi -sběr dat - tzv. roboti, též bot, spider, crawler nebo worm. Některé roboty mají dokonce vlastní jména, například program používaný pro sběr dat AltaVistou se jmenuje „Scooter . Předmětové adresáře. vznikají ručně, zdroje jsou do nich zařazovány výběrově. Buď tyto informace poskytují vyhledávacím službám sami producenti internetových zdrojů vyplněním formuláře, který je součástí nabídky každé z vyhledávacích služeb (najdete je pod odkazy přidej stránku, add URL, submit URL apod.) nebo jsou informace o nových zdrojích zjišťovány pracovníky nebo spolupracovníky vyhledávacích služeb vlastním průzkumem Internetu.")
16
Vyhledávací nástroje internetu
základní zásady výběru vyhledávacího nástroje vyčerpávající průzkum → nástroj s velkou databází nejznámější a nejvíce navštěvované zdroje → nástroj budovaný na základě ručního sběru dat máme jasnou představu o hledaném tématu → vyhledávací stroj příklad - budeme-li chtít prohledávat klíčovými slovy např. české zdroje, použijeme raději Google – kvalitnější výsledky než třeba český Seznam (Google – větší databáze) - budeme-li chtít použít pro hledání českých zdrojů předmětový katalog, obrátíme se na Centrum.cz, nikoliv třeba na službu Yahoo!.
 - budeme-li chtít použít pro hledání českých zdrojů předmětový katalog, obrátíme se na Centrum.cz, nikoliv třeba na službu Yahoo!.")
17
Internetové vyhledávače
internetový vyhledávač, vyhledávací stroj, search engine, fultextový vyhledávač systém, který na základě klíčového slova formulovaného uživatelem hledá v databázi a předá uživateli výsledek je tvořen robotem, indexačním programem, vyhledávacím programem a grafickým rozhraním databáze vyhledávače používáme, chceme-li provést vyčerpávající průzkum webu, při hledání velmi specializovaných informací většina vyhledávacích služeb poskytuje řadu dalších služeb: aktuální zpravodajství, obchodní a ekonomické informace, turistické informace, počasí, bezplatný atd.

18
Internetové vyhledávače
základní rozdíly mezi vyhledávacími stroji: - jaký prostor internetu nástroj prohledává (celý svět nebo jen zdroje v určitém regionu, jen WWWeb nebo také Usenet (o něm), Gopher (o něm), FTP – Archie, Snoopie (o FTP) aj.) - velikost databáze – vzniká automatizovaně nebo ručně? - způsob indexování webových stránek frekvence výskytu, počet termínů vyhovujících požadavku, váha podle polí, proximita, pořadí slov v dotazu apod. zda zařazuje do své databáze jen názvy dokumentů, názvy hypertextových odkazů, vybrané prvky z dokumentů, části textů nebo úplné texty dokumentů Každý vyhledávací stroj slouží trochu jinému účelu, proto se liší i nabídkou vyhledávacích prostředků Usenet je systém elektronických diskusních skupin, distribuovaný prostřednictvím internetu po celém světě. Uživatelé čtou a posílají veřejné příspěvky (články, zprávy nebo příspěvky, souhrnně zvané „newsy“) do kategorií zvaných skupiny. Diskuze v jednotlivých skupinách se dělí na vlákna. Příspěvky jsou na serveru uloženy chronologicky. Gopher - prostředek pro navigaci a vyhledávání potřebných dat v síti, funguje na principu klient-server, proto musí být na počítači, na kterém pracujete, nainstalován vhodný klient Služba Gopher byla vyvinuta v USA, na univerzitě v Minnesotě, o něco málo dříve než World Wide Web. Poté spolu obě služby soupeřily, s tím že zpočátku měl navrch (co do počtu serverů) Gopher. Kolem roku 1995 bylo celosvětově v provozu přes 6000 serverů této služby. S postupem času se ale jazýček vah začal obracet a Web začal převládat. Gopher nakonec prohrál na celé čáře. Více na FTP (anglicky File Transfer Protocol) je v informatice protokol aplikační vrstvy z rodiny TCP/IP. Je určen pro přenos souborů mezi počítači, na kterých mohou běžet rozdílné operační systémy (je platformně nezávislý).
, Gopher (o něm), FTP – Archie, Snoopie (o FTP) aj.) - velikost databáze – vzniká automatizovaně nebo ručně - způsob indexování webových stránek. frekvence výskytu, počet termínů vyhovujících požadavku, váha podle polí, proximita, pořadí slov v dotazu apod. zda zařazuje do své databáze jen názvy dokumentů, názvy hypertextových odkazů, vybrané prvky z dokumentů, části textů nebo úplné texty dokumentů. Každý vyhledávací stroj slouží trochu jinému účelu, proto se liší i nabídkou vyhledávacích prostředků. Usenet je systém elektronických diskusních skupin, distribuovaný prostřednictvím internetu po celém světě. Uživatelé čtou a posílají veřejné příspěvky (články, zprávy nebo příspěvky, souhrnně zvané „newsy ) do kategorií zvaných skupiny. Diskuze v jednotlivých skupinách se dělí na vlákna. Příspěvky jsou na serveru uloženy chronologicky. Gopher - prostředek pro navigaci a vyhledávání potřebných dat v síti, funguje na principu klient-server, proto musí být na počítači, na kterém pracujete, nainstalován vhodný klient. Služba Gopher byla vyvinuta v USA, na univerzitě v Minnesotě, o něco málo dříve než World Wide Web. Poté spolu obě služby soupeřily, s tím že zpočátku měl navrch (co do počtu serverů) Gopher. Kolem roku 1995 bylo celosvětově v provozu přes 6000 serverů této služby. S postupem času se ale jazýček vah začal obracet a Web začal převládat. Gopher nakonec prohrál na celé čáře. Více na FTP (anglicky File Transfer Protocol) je v informatice protokol aplikační vrstvy z rodiny TCP/IP. Je určen pro přenos souborů mezi počítači, na kterých mohou běžet rozdílné operační systémy (je platformně nezávislý).")
19
Internetové vyhledávače
základní rozdíly mezi vyhledávacími stroji: - způsob řazení výsledků - možnosti vyhledávání (jednoduché, pokročilé, pozor na odlišné fungování shodných nebo podobných příkazů) - jaké typy dokumentů pokrývá vyhledávací nástroj (html, pdf, postscript, obrázky, zvukové dokumenty apod.) - uživatelská podpora a přívětivost možnost personalizace žádný internetový vyhledávač neumí prohledat celý internet žádný vyhledávač není ideální Na prvních místech v dotazu uveďte slova, jež mají pro výsledek hledání největší význam. Některé vyhledávací služby totiž přikládají slovům na začátku dotazu větší váhu při hodnocení výsledků vyhledávání. Pokud je to nutné, použijte v dotazu synonyma a příbuzné výrazy, ale ne ve velkém množství, neboť to může vést ke zkreslení výsledků hledání. Raději proveďte několik samostatných hledání, je-li to nezbytné. Rozhraní pro jednoduché hledání je standardní nabídkou nejen u všech vyhledávacích strojů, ale také u předmětově orientovaných vyhledávacích služeb. Proto je také najdete vždy na jejich vstupní stránce. Interakce mezi uživatelem a vyhledávacím nástrojem se děje prostřednictvím „příkazového řádku“, který je v tomto případě představován velmi jednoduchým formulářem. Do okénka formuláře lze vepsat jednoduchý dotaz tvořený několika klíčovými slovy, které je možné spojit do vzájemných vztahů pomocí znamének plus a minus nebo uvozovkami. zpravidla dovede k velmi dobrému výsledku Pokročilé vyhledávání – větší kontrola uživatele nad vyhledáváním
 - jaké typy dokumentů pokrývá vyhledávací nástroj (html, pdf, postscript, obrázky, zvukové dokumenty apod.) - uživatelská podpora a přívětivost. možnost personalizace. žádný internetový vyhledávač neumí prohledat celý internet. žádný vyhledávač není ideální. Na prvních místech v dotazu uveďte slova, jež mají pro výsledek hledání největší význam. Některé vyhledávací služby totiž přikládají slovům na začátku dotazu větší váhu při hodnocení výsledků vyhledávání. Pokud je to nutné, použijte v dotazu synonyma a příbuzné výrazy, ale ne ve velkém množství, neboť to může vést ke zkreslení výsledků hledání. Raději proveďte několik samostatných hledání, je-li to nezbytné. Rozhraní pro jednoduché hledání je standardní nabídkou nejen u všech vyhledávacích strojů, ale také u předmětově orientovaných vyhledávacích služeb. Proto je také najdete vždy na jejich vstupní stránce. Interakce mezi uživatelem a vyhledávacím nástrojem se děje prostřednictvím „příkazového řádku , který je v tomto případě představován velmi jednoduchým formulářem. Do okénka formuláře lze vepsat jednoduchý dotaz tvořený několika klíčovými slovy, které je možné spojit do vzájemných vztahů pomocí znamének plus a minus nebo uvozovkami. zpravidla dovede k velmi dobrému výsledku. Pokročilé vyhledávání – větší kontrola uživatele nad vyhledáváním.")
20
Internetové vyhledávače
použití booleovských operátorů ve vyhledávacích službách použití operátorů v jednoduchém rozhraní většina vyhledávačů nepodporuje zpočátku používala většina vyhledávacích nástrojů implicitně operátor OR, v současnosti však již převládá nastavení na operátor AND použití implicitního operátoru OR – hodnocení relevance - na prvních místech odkazy na dokumenty s nejvyšším výskytem, na nižších místech některá z použitých klíčových slov chybí Použití booleovských operátorů AND, OR a NOT nebo distančního operátoru NEAR v rozhraní pro jednoduchém hledání většina vyhledávacích nástrojů neumožňuje nebo nepovažuje za nutné, zvláště tehdy, je-li jejich standardním operátorem AND. Použijete-li např. při hledání prostřednictvím Google v dotazu operátor AND, odpoví vám systém – kromě toho, že vám nabídne vyhledané odkazy – takto: „The "AND" operator is unnecessary -- we include all search terms by default.“ („Operátor AND je zbytečný – zahrnujeme standardně všechny vyhledávací výrazy.“) Nejste-li si jisti, jaký standardní operátor vyhledávací služba používá, můžete si to rychle zjistit sami i bez nápovědy (zde se zpravidla tyto informace ani nedozvíte). Stačí zadat jednoduchý dotaz se dvěma klíčovými slovy, z nichž jedno je nesmyslné, například: dogs xhjfglllmnopk. Nebo česky: psi xhjfglllmnopk. Pokud vám systém odpoví, že nic nenalezl, jde o nástroj se standardním operátorem AND. Pokud vám služba vyhledá odkazy na zdroje, ve kterých najdete zmínku o psech, pak jde o službu se skrytým operátorem OR. Při prezentaci výsledků se vám může zdát – zvlášť při použití obecných výrazů nebo při hledání nějakého frekventovaného tématu, že systém vámi zadané výrazy spojil operátorem AND, tedy tak, jak jste si to nejspíš přáli. Vzhledem k tomu, že všechny vyhledávací služby umožňují použít alespoň znaménka plus nebo minus jako podmínku pro výskyt nebo vyloučení slov z hledání, a také dvojitých uvozovek pro vyhledání fráze, můžete tedy jejich pomocí částečně „obejít“ nežádoucí standardní operátor
 Nejste-li si jisti, jaký standardní operátor vyhledávací služba používá, můžete si to rychle zjistit sami i bez nápovědy (zde se zpravidla tyto informace ani nedozvíte). Stačí zadat jednoduchý dotaz se dvěma klíčovými slovy, z nichž jedno je nesmyslné, například: dogs xhjfglllmnopk. Nebo česky: psi xhjfglllmnopk. Pokud vám systém odpoví, že nic nenalezl, jde o nástroj se standardním operátorem AND. Pokud vám služba vyhledá odkazy na zdroje, ve kterých najdete zmínku o psech, pak jde o službu se skrytým operátorem OR. Při prezentaci výsledků se vám může zdát – zvlášť při použití obecných výrazů nebo při hledání nějakého frekventovaného tématu, že systém vámi zadané výrazy spojil operátorem AND, tedy tak, jak jste si to nejspíš přáli. Vzhledem k tomu, že všechny vyhledávací služby umožňují použít alespoň znaménka plus nebo minus jako podmínku pro výskyt nebo vyloučení slov z hledání, a také dvojitých uvozovek pro vyhledání fráze, můžete tedy jejich pomocí částečně „obejít nežádoucí standardní operátor.")
21
Internetové vyhledávače
katalogy a rozcestníky internetových vyhledávačů: Hotsheet – tematicky uspořádané, velké množství kategorií Beaucoup - tematicky uspořádané SearchengineCollossus - seznam vyhledávačů uspořádaný teritoriálně

22
Internetové vyhledávače
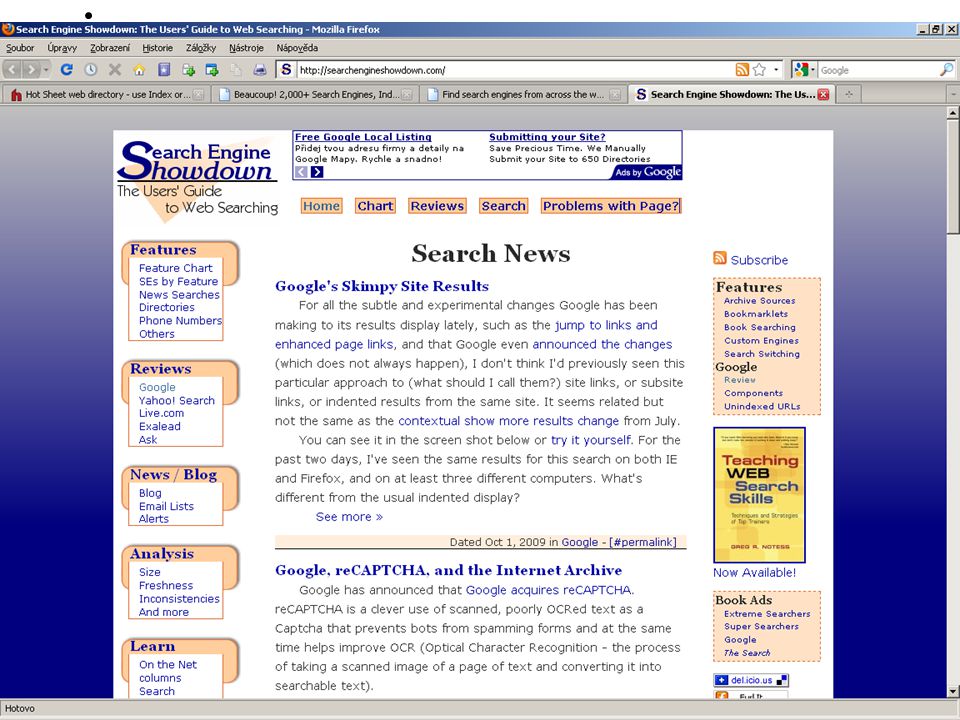
informace o internetových vyhledávačích : například SearchengineShowDown -

25
Světové internetové vyhledávače
Google založ. v r. 1998 jeden z nejpopulárnějších a největších vyhledávacích nástrojů poskytuje řadu dalších služeb systém denně aktualizuje 260 zaměstnanců z nichž více než 50 má titul PhD.

26
Světové internetové vyhledávače
Google výhody: veliká databáze - indexuje miliardy webových stránek z povrchového webu včetně pdf, doc, ps, xls, txt, ppt, rtf aj. souborů neustálá inovace vyhledávacích služeb při posuzování relevance stránek se berou v úvahu odbornost i popularita stránky možnost nastavení jazyka podle volby uživatele hledané termíny jsou zvýrazněné propracované vyhledávání v mnoha speciálních zdrojích zobrazuje stránky, které už zanikly, ale jsou v paměti (cached) s udáním data, kdy byly indexovány
 s udáním data, kdy byly indexovány.")
27
Světové internetové vyhledávače

28
Světové internetové vyhledávače

29
Světové internetové vyhledávače
Google nevýhody: indexuje pouze prvních 101 KB u webových stránek a 120 KB u pdf souborů nepoužívá možnost rozšíření slov pomocí * či jiného znaku v jednoduchém vyhledávání neumožňuje plné použití booleovských operátorů (např. NOT) neumožňuje použití závorek k seskupování klíčových slov v dotazu např. pizza AND (žampiony OR šunka) AND olivy nebo (pizza AND žampiony) OR (šunka AND olivy) v obou případech stejný výsledek
 neumožňuje použití závorek k seskupování klíčových slov v dotazu. např. pizza AND (žampiony OR šunka) AND olivy. nebo. (pizza AND žampiony) OR (šunka AND olivy) v obou případech stejný výsledek.")
30
Světové internetové vyhledávače
způsoby vyhledávání jednoduché vyhledávání defaultně AND vyhledávání podle polí „Zkusím štěstí“ zobrazí první vyhledaný výsledek rozšířené vyhledávání předdefinovaný formulář

31
Světové internetové vyhledávače
vyhledávací možnosti prohledávání podle polí příklady allintitle:text allinurl:text allintext:text

32
Světové internetové vyhledávače
fráze uvozovky rozšíření hledá automaticky jednotné a množné číslo maskování možné uvnitř frází – např. „pizza se šunkou a *“ vyloučení nežádoucích termínů pomocí - př. univerzita -fakulta zabránění vyloučení obecných slov pomocí + př. sparta +a slavia nerozlišuje malá a velká písmena př. Brno – totéž co brno vyhledání synonym pomocí ~ př. šumava ~cesty najde i trasy apod. Znaménka plus a minus však nepotlačí standardní operátor. Je-li standardním operátorem OR, pak to neznamená, že znaménko plus změní tuto standardní funkci na operátor AND. Použití znaménka však ovlivní způsob setřídění výsledků vyhledávání.

33
Světové internetové vyhledávače
řada dalších služeb přehled dalších možností překladač

34
Světové internetové vyhledávače
nejhledanější slova na Googlu 2007 idnes 2009 2010

35
Světové internetové vyhledávače
specializované služby Googlu Scholar Books (Knihy)
")
36
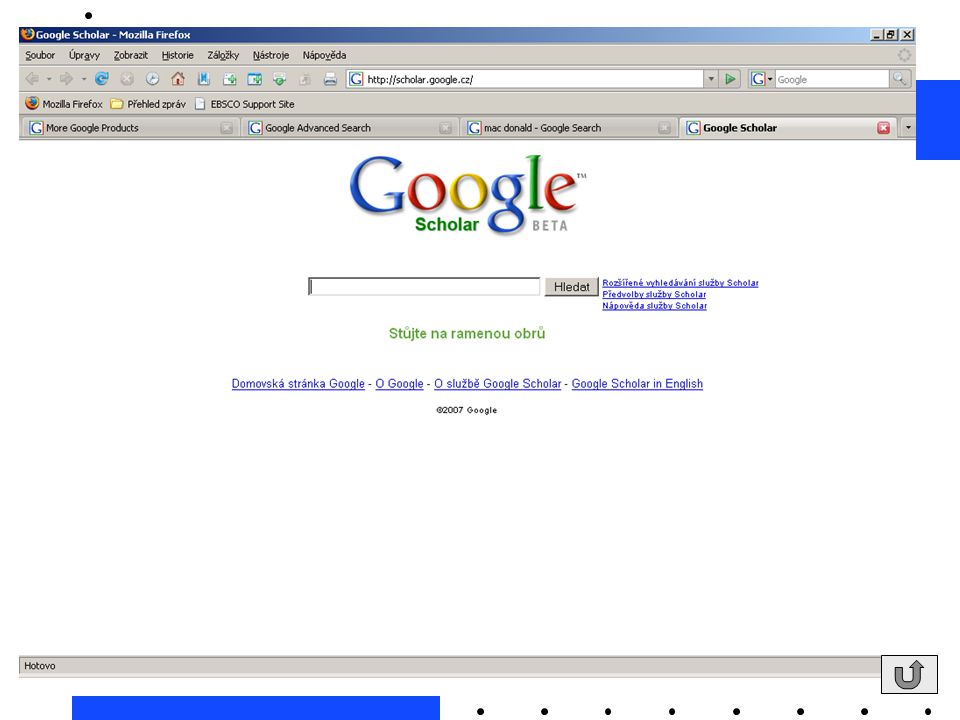
Světové internetové vyhledávače
Google Scholar specializovaný vyhledávač vědeckých informací - recenzovaných článků, disertací, knih, preprintů, abstrakt, technických zpráv ze všech oborů výzkumu, vysokoškolských kvalifikačních prácí umožňuje vyhledání dokumentu zobrazení abstraktu vyhledání citací dokumentu Příklad GIS

37
Světové internetové vyhledávače
řazení článků podle relevance (hodnocení textu, váha autora, reputace zdroje, ve kterém je zveřejněn) hledání podle autora (př. einstein - pokud mnoho výsledků lze zúžit – autor: „a einstein“)
 hledání podle autora. (př. einstein - pokud mnoho výsledků lze zúžit – autor: „a einstein )")
38
Světové internetové vyhledávače
struktura záznamu název citace „Související články “ další verze článku „Archiv“ (v angličtině Cached) příklad: „vyhledávání informací“
 příklad: „vyhledávání informací")
39
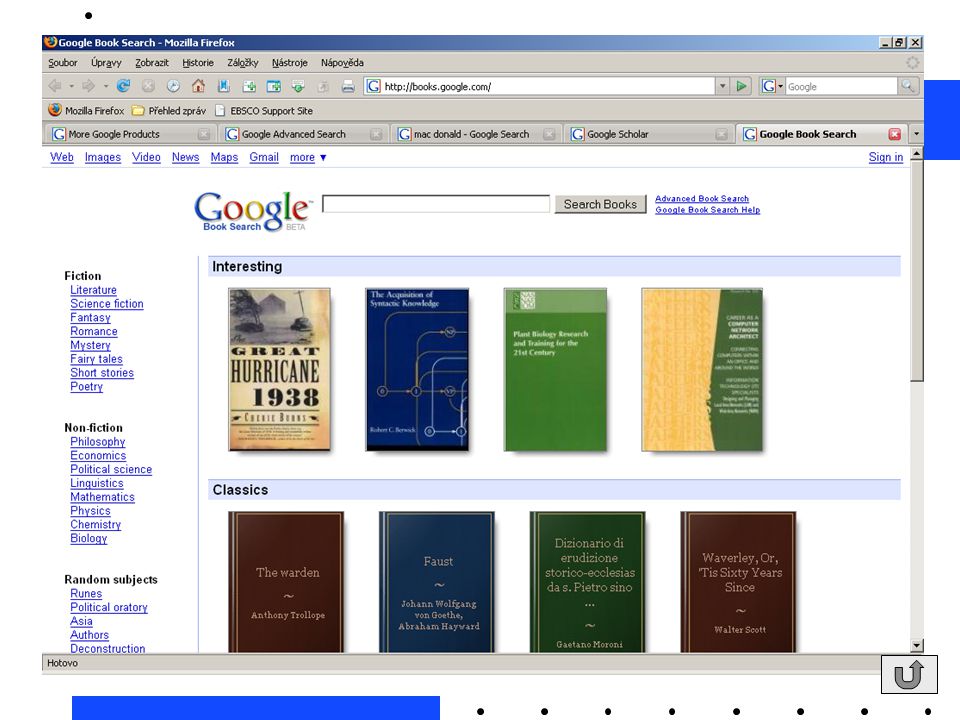
Světové internetové vyhledávače
Google knihy nabízí ke stažení ve formátu pdf některé knihy, které již nejsou chráněné autorským zákonem původní plán – převést na internet 4 mil. knih z vybraných amerických univerzitních a veřejných knihoven, z knihovny britské Oxfordské univerzity a z Bavorské státní knihovny nový plán - převést všechny existující knihy u knih které jsou chráněny copyrightem zobrazuje pouze základní bibliografické údaje, eventuálně krátké ukázky textu plné texty řady knih, které jsou již veřejným majetkem a nejsou chráněny autorskými právy (70 let po smrti autora) u ostatních jen základní bibliografické údaje, případně obálky, obsahy, náhledy některých stránek, rejstříky apod. odkaz, kde lze knihu získat (knihovna, knihkupectví…)
 u ostatních jen základní bibliografické údaje, případně obálky, obsahy, náhledy některých stránek, rejstříky apod. odkaz, kde lze knihu získat (knihovna, knihkupectví…)")
40
Světové internetové vyhledávače
jednoduché vyhledávání rozšířené vyhledávání možno vyhledávat všechny knihy omezený náhled a úplné zobrazení pouze úplné zobrazení pouze volná díla a další možnosti příklad: oliver twist dickens (příklad: oliver twist dickens)
")
41
Světové internetové vyhledávače
služby Google knihy příklad: odkazy na stránce: Najít v knihovně (vyhledává v katalogu WorldCat) Přidat do mé knihovny (potřeba přihlásit se) Další vydání
 Přidat do mé knihovny (potřeba přihlásit se) Další vydání.")
42
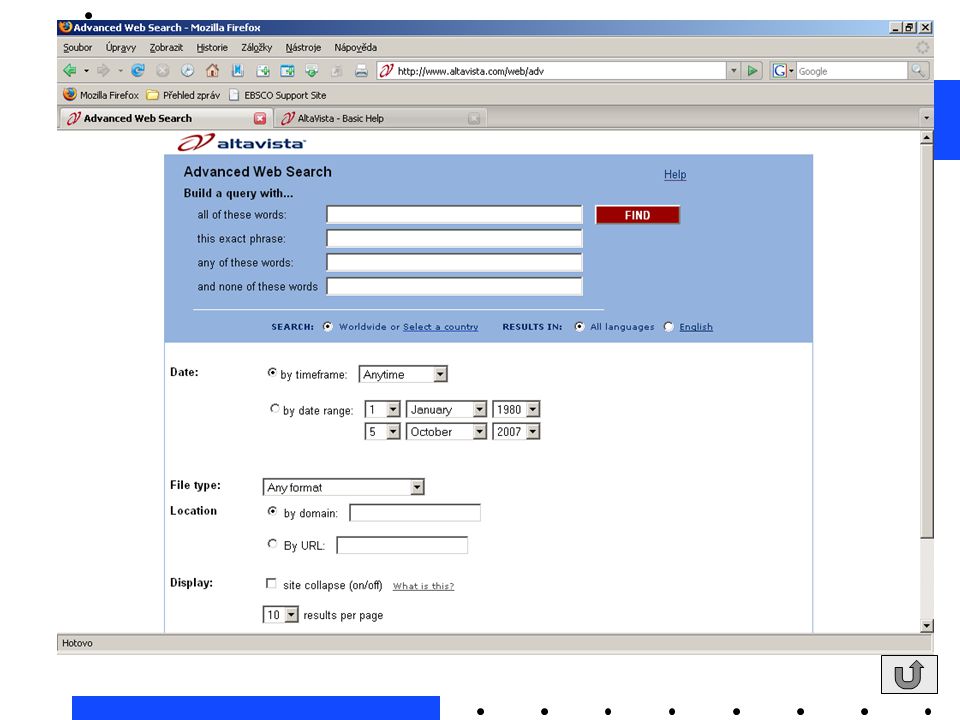
Světové internetové vyhledávače
Altavista vyhledávač vytvořen v r. 1995 dnes ve vlastnictví Yahoo! – používá jeho databázi a předmětový katalog odlišuje se od Googlu některými vyhledávacími prostředky a dalšími možnostmi

43
Světové internetové vyhledávače
booleovské operátory (musí být velkými písmeny) AND implicitně OR NOT distanční operátory NEAR, ADJACENT (ADJ), FOLLOWED BY např. Karel NEAR Borovsky v Altavistě nastavena vzdálenost na 10 slov
 AND implicitně. OR. NOT. distanční operátory. NEAR, ADJACENT (ADJ), FOLLOWED BY. např. Karel NEAR Borovsky. v Altavistě nastavena vzdálenost na 10 slov.")
44
Světové internetové vyhledávače
prohledávání podle polí domain:domainame domain:cz +knihovna +katalog title:text inurl:text Babel Fish Translation překladač – možnost vložit blok textu nebo adresu webové stránky Správně vytvořené (X)HTML dokumenty jsou strukturované dokumenty, toto hledání můžeme kombinovat s klíčovými slovy do složitějšího dotazu – příklad: domain:cz +knihovna +katalog
HTML dokumenty jsou strukturované dokumenty, toto hledání můžeme kombinovat s klíčovými slovy do složitějšího dotazu – příklad: domain:cz +knihovna +katalog.")
45
Světové internetové vyhledávače
omezení vyhledávače v zájmu rychlého vyhledávání Altavista zastaví vyhledávací proces po určitém časovém limitu, takže v závislosti na momentální rychlosti zpracování úlohy můžeme při opakovaném vyhledávání dostat rozdílný počet výsledků

46
Světové internetové vyhledávače
AllTheWeb prohledává web, multimédia, FTP filtr pro odstranění stránek s nevhodným obsahem nemá adresář Lycos velmi rychlé vyhledávání, jedoduché vyhledávací techniky (jen slova – ne fráze), personalizace, ale velké množství reklam HotBot jednoduché, komfortní a rychlé vyhledávání s pozoruhodnými výsledky Ask nabízí vyhledávací historii
, personalizace, ale velké množství reklam. HotBot. jednoduché, komfortní a rychlé vyhledávání s pozoruhodnými výsledky. Ask. nabízí vyhledávací historii.")
47
České internetové vyhledávače
Seznam Atlas Centrum vyhledavace.unas.cz nebo vyhledavace.net aj.

48
Předmětové adresáře předmětový adresář – služba odkazující na zdroje, které do ní dodali tvůrci webových stánek nebo informační pracovníci předmětový adresář je organizovaný do předmětových kategorií, podkategorií apod. poměrně malá databáze při vyhledávání se prohledává pouze databáze předmětového adresáře

49
Předmětové adresáře digitální (virtuální) knihovny
do předmětových vyhledávačů řadíme i digitální knihovny, které jsou sestavené profesionály, zdroje jsou často anotované, hodnocené z více hledisek digitální knihovna je spravovaná sbírka informací, spolu se službami informace jsou v digitální podobě a dostupné prostřednictvím sítě tematicky uspořádané odkazy na zdroje - kvalitní pořádací systém - kvalitní zdroje X - obtížnější údržba - lidský faktor - subjektivita Informační zdroje ve virtuálních knihovnách jsou zpravidla organizovány logicky Kromě kvalitního pořádacího systému nabízejí tyto služby uživatelům Internetu také odkazy na kvalitní informační zdroje. Virtuální knihovny poskytují informace na základě hierarchicky uspořádaných předmětových skupin, původně pouze pro prohlížení (angl. browsing). V současnosti většina z nich nabízí i rozhraní umožňující hledání prostřednictvím klíčových slov. Použití virtuálních knihoven je vhodné zvláště tehdy, hledáte-li kvalitní zdroje na určité téma. Hledání nejvhodnějších zdrojů vám přitom mohou usnadnit recenze, jimiž bývají odkazy na informační zdroje zpravidla doplňovány. Lidský faktor znamená na druhé straně omezení. Jednak je obtížná údržba a aktualizace zdrojů, jednak je to omezující prvek, pokud jde o množství a úplnost zdrojů ve virtuálních knihovnách registrovaných. A to nejen ve vztahu k celému Internetu, tam je to zřejmé na první pohled, ale i s ohledem na praktickou nemožnost – vzhledem k tomu, jakým způsobem jsou budovány – podchytit opravdu všechny kvalitní zdroje věnující se danému tématu.
. V současnosti většina z nich nabízí i rozhraní umožňující hledání prostřednictvím klíčových slov. Použití virtuálních knihoven je vhodné zvláště tehdy, hledáte-li kvalitní zdroje na určité téma. Hledání nejvhodnějších zdrojů vám přitom mohou usnadnit recenze, jimiž bývají odkazy na informační zdroje zpravidla doplňovány. Lidský faktor znamená na druhé straně omezení. Jednak je obtížná údržba a aktualizace zdrojů, jednak je to omezující prvek, pokud jde o množství a úplnost zdrojů ve virtuálních knihovnách registrovaných. A to nejen ve vztahu k celému Internetu, tam je to zřejmé na první pohled, ale i s ohledem na praktickou nemožnost – vzhledem k tomu, jakým způsobem jsou budovány – podchytit opravdu všechny kvalitní zdroje věnující se danému tématu.")
50
Předmětové adresáře výhody předmětových vyhledávačů
anotování a hodnocení zdrojů nevýhody použití různých klasifikačních schémat tematická struktura přijatá na začátku nemusí vyhovovat v průběhu vývoje méně častá aktualizace subjektivita hodnocení daná lidským faktorem vyhledávání probíhá jen v názvech dokumentů, v anotacích a adresách dokumentů – nejedná se o plnotextové vyhledávání

51
Předmětové adresáře kdy použijeme předmětový adresář
okruh vyhledávaného tématu je příliš široký a nejsme si jisti, jak dotaz správně formulovat chceme-li získat relevantnější obsah než prostřednictvím vyhledávačů chceme-li získat přehled webových sídel, které doporučili experti dostaneme-li při vyhledávání pomocí vyhledávače příliš mnoho výsledků většina adresářů používá způsob prohlížení i vyhledávání podle klíčových slov vyhledávání neprobíhá na celém webu jako u vyhledávačů, ale jen v záznamech adresáře

52
Předmětové adresáře Yahoo! výhody
jeden z prvních systémů, 1994 – univerzita ve Stanfordu jeden z největších adresářů denně aktualizovaný automatické spojení na Altavistu a Google hledaná slova jsou zvýrazněna podobně jako Google ukládá do paměti starší verze stránek – Casched

53
Předmětové adresáře Yahoo! nevýhody
nedostatek pokročilých vyhledávacích možností – např. rozšíření minimální využití booleovských operátorů indexuje pouze prvních 500 Kb z webové stránky

54
Předmětové adresáře Open Directory Project vznikl 1998
představuje nový přístup k organizování informací na internetu využívá princip externích redaktorů, kteří se starají o určitou tematickou oblast přispívat může každý, kdo má zájem na každé stránce je uveden zodpovědný redaktor nebo výzva „tato kategorie potřebuje redaktora“

55
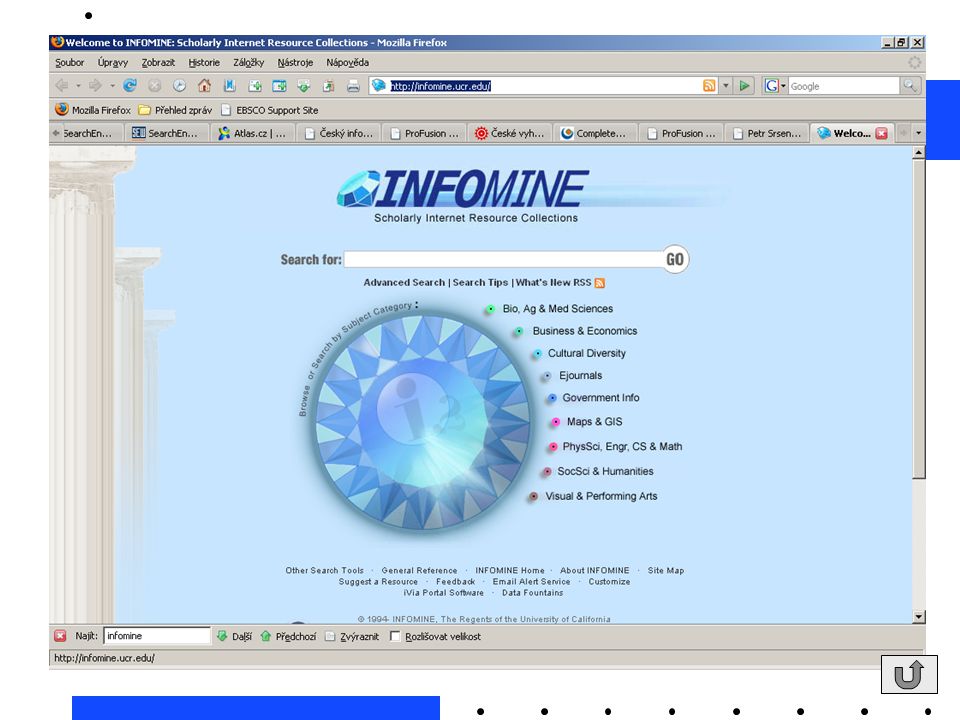
Předmětové adresáře příklady digitálních knihoven Infomine
kolekce internetových zdrojů pro akademickou sféru, vytvořena americkými univerzitními knihovníky ipl2 na vytváření se podílejí studenti, knihovníci a specialisté z oblasti informační vědy

56
Světové metavyhledávače
umožňují současné vyhledávání ve více než jednom vyhledávacím nástroji nebo adresáři zastřešují vybrané vyhledávače a jejich prostřednictvím získávají výsledky

57
Světové metavyhledávače
výhody vyhledávání z jednoho místa pouze jednou zadáváme rešeršní dotaz výsledkem rešerše je jednotný seznam záznamů nevýhody většinou limitují počet záznamů z jednoho zdroje (zpravidla 10) nevyužívají všechny možnosti formulování rešeršního požadavku
 nevyužívají všechny možnosti formulování rešeršního požadavku.")
58
Světové metavyhledávače
Federated Query Server (Open Text Corporation) výkonný metavyhledávač od firmy Open Text Yippy! seskupování výsledků do klastrů Metacrawler kvalitní systém, eliminuje duplicity a vyhodnocuje výsledky a seskupuje je DogPile seskupuje výsledky stejně jako Metacrawler Excite funguje od r. 1996, přináší poměrně kvalitní výsledky
 výkonný metavyhledávač od firmy Open Text. Yippy! seskupování výsledků do klastrů. Metacrawler. kvalitní systém, eliminuje duplicity a vyhodnocuje výsledky. a seskupuje je. DogPile. seskupuje výsledky stejně jako Metacrawler. Excite. funguje od r. 1996, přináší poměrně kvalitní výsledky.")
59
Neviditelný web neviditelný web, skrytý web, hlubinný web invisible web, hidden web, deep web kolem r. 1999, se zjistilo, že vyhledávací stroje neindexují stále více webovského prostoru některé vyhledavače mohou najít pouze zlomek informací z webové stránky nebo vstupní bránu k databázi, ale další obsah již nemohou prohledat proto jsou takové stránky označována jako stránky neviditelné

60
Neviditelný web Michael K. Bergman

61
Neviditelný web Michael K. Bergman

62
Neviditelný web Obsah neviditelného webu podle tematických oblastí

63
Neviditelný web důvody
vyhledávací stroje nedokážou indexovat dynamicky se měnící stránky (informace se generují z databáze) omezená přístupová práva (na některé stránky je přístup chráněn heslem - katalogy knihoven, databáze apod.) – stránky s neveřejným obsahem pro mnoho vyhledávačů jsou jiné typy souborů než html nečitelné k řadě stránek nevedou odkazy z jiných stránek – odpojené stránky mnoho vyhledávacích strojů má omezení na počet indexovaných stránek z určité domény apod. dynamicky generované stránky Některé stránky vytvářejí svůj obsah teprve na základě požadavku uživatele. Tyto tzv. dynamické stránky jsou psány různými programovými a skriptovacími jazyky, které na základě vložených dat stránku vytvářejí. Každá takto vytvořená stránka je unikátní a již pravděpodobně nedojde k dalšímu zobrazení stránky ve stejné podobě. Typickým příkladem jsou různé databáze (dotazy v databázích), výpisy z ceníků nebo různé kalkulátory (konverze měn, výpočet tělesného tuku atd.). Takto generované stránky mají navíc ještě dynamicky generovanou adresu- naapř. .../cv.asp?PID=25152&UI, která je platná pouze pro tuto operaci a dále nebude platná. omezená přístupová práva ke stránkám Každá stránka může vyhledavači zakázat aby ji zaindexoval (zaregistroval). Pokud budou tyto pokyny zápsány v hlavičce stránky, každý vyhledavač, který na stránku narazí, nebude stránku zapisovat a ihned ji opustí. Tato možnost byla vytvořena pro stránky, které nemají veřejný charakter a tvůrce nemá zájem na jejich zveřejnění. Další překážkou pro vyhledavače mohou být kódované stránky, kde je pro přístup vyžadováno heslo. Obsah, který se tak skrývá pod zakódovanými stránkami nemůže být prohledán anebo prohledán a zaindexován je, ale uživatel k němu nemá přístup. zvláštní typy dokumentů, které vyhledavače neumí prohledávat Formáty jiného formátu než HTML jsou pro většinu vyhledavačů nečitelné. Některé formáty (PDF, Postscript) některé vyhledavače sice umí prohledávat (např. AltaVista -PDF, Google - PDF, PS) ale jiné jsou zatím velmi tvrdým oříškem (formáty Macromedia Flash, skriptovací jazyky apod.). Za tohoto stavu není možné získat úplné informace, které se na stránkách vyskytují. tzv. "samotáři" - stránky, které nemají odkazy na jiné a na které také není odkaz Dnes se již tento problém vyskytuje méně často, ale pořád přetrvává. Na některé stránky neexistují odkazy z jiných stránek, které by je umožňovaly nalézt. To se týká i celých prezentací. Vyhledavač zpravidla sleduje různé odkazy ze stránek a tak nacházejí další stránky, které pak registrují ve své databázi. Stránky, na které nejsou odkazy, pak mohou být (ale také nemusí) nalezeny vyhledavačem.
 omezená přístupová práva (na některé stránky je přístup chráněn heslem - katalogy knihoven, databáze apod.) – stránky s neveřejným obsahem. pro mnoho vyhledávačů jsou jiné typy souborů než html nečitelné. k řadě stránek nevedou odkazy z jiných stránek – odpojené stránky. mnoho vyhledávacích strojů má omezení na počet indexovaných stránek z určité domény. apod. dynamicky generované stránky Některé stránky vytvářejí svůj obsah teprve na základě požadavku uživatele. Tyto tzv. dynamické stránky jsou psány různými programovými a skriptovacími jazyky, které na základě vložených dat stránku vytvářejí. Každá takto vytvořená stránka je unikátní a již pravděpodobně nedojde k dalšímu zobrazení stránky ve stejné podobě. Typickým příkladem jsou různé databáze (dotazy v databázích), výpisy z ceníků nebo různé kalkulátory (konverze měn, výpočet tělesného tuku atd.). Takto generované stránky mají navíc ještě dynamicky generovanou adresu- naapř. .../cv.asp PID=25152&UI, která je platná pouze pro tuto operaci a dále nebude platná. omezená přístupová práva ke stránkám Každá stránka může vyhledavači zakázat aby ji zaindexoval (zaregistroval). Pokud budou tyto pokyny zápsány v hlavičce stránky, každý vyhledavač, který na stránku narazí, nebude stránku zapisovat a ihned ji opustí. Tato možnost byla vytvořena pro stránky, které nemají veřejný charakter a tvůrce nemá zájem na jejich zveřejnění. Další překážkou pro vyhledavače mohou být kódované stránky, kde je pro přístup vyžadováno heslo. Obsah, který se tak skrývá pod zakódovanými stránkami nemůže být prohledán anebo prohledán a zaindexován je, ale uživatel k němu nemá přístup. zvláštní typy dokumentů, které vyhledavače neumí prohledávat Formáty jiného formátu než HTML jsou pro většinu vyhledavačů nečitelné. Některé formáty (PDF, Postscript) některé vyhledavače sice umí prohledávat (např. AltaVista -PDF, Google - PDF, PS) ale jiné jsou zatím velmi tvrdým oříškem (formáty Macromedia Flash, skriptovací jazyky apod.). Za tohoto stavu není možné získat úplné informace, které se na stránkách vyskytují. tzv. samotáři - stránky, které nemají odkazy na jiné a na které také není odkaz Dnes se již tento problém vyskytuje méně často, ale pořád přetrvává. Na některé stránky neexistují odkazy z jiných stránek, které by je umožňovaly nalézt. To se týká i celých prezentací. Vyhledavač zpravidla sleduje různé odkazy ze stránek a tak nacházejí další stránky, které pak registrují ve své databázi. Stránky, na které nejsou odkazy, pak mohou být (ale také nemusí) nalezeny vyhledavačem.")
64
Neviditelný web neviditelný web je až 500krát větší než tzv. povrchový web obsahuje kvalitní dokumenty (1000 až 2000krát kvalitnější než v povrchovém webu) je to nejrychleji rostoucí část webu až 95% informací v neviditelném webu patří k veřejně přístupným informacím, které jsou přístupné bez poplatků
 je to nejrychleji rostoucí část webu. až 95% informací v neviditelném webu patří k veřejně přístupným informacím, které jsou přístupné bez poplatků.")
65
Neviditelný web příklad rozdílu mezi „viditelným“ a „neviditelným“ webem viditelný: iCivil Engineering - neviditelný: Civil Engineering database - nebo Educator's Reference Desk - Eric (databáze) -
 -")
66
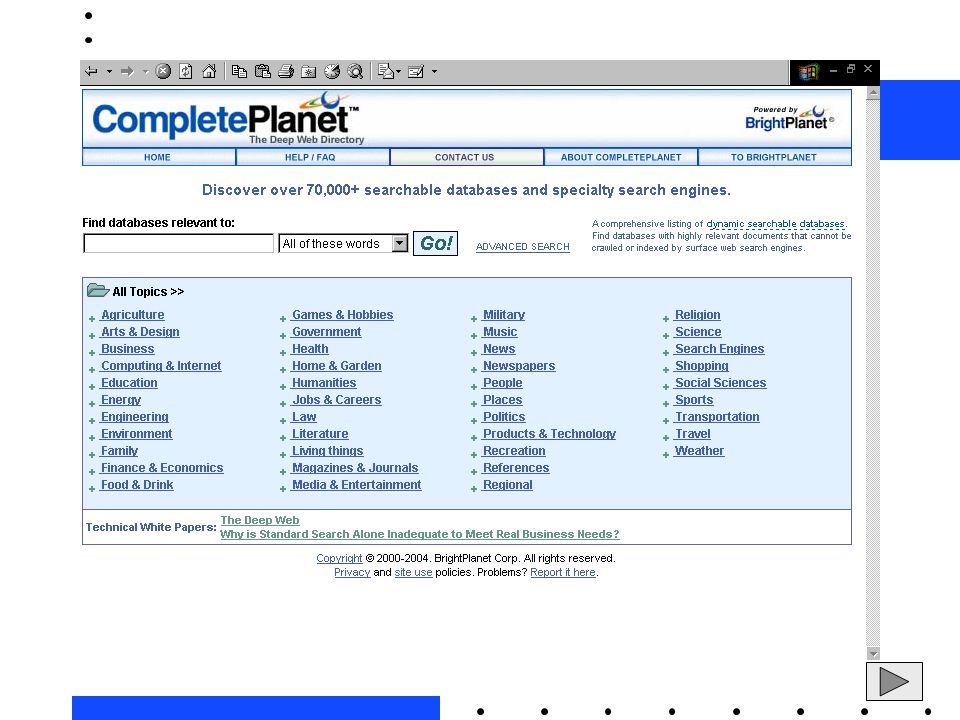
Neviditelný web brány pro neviditelný web Complete Planet
umožňuje vyhledávání ve více než databází a specializovaných vyhledávacích nástrojích vyhledávání nebo prohlížení využití booleovských operátorů u záznamů je uvedená míra relevance Turbo10 - metavyhledávač i pro neviditelný web Turbo10 – metasearch engine, která poskytuje interface k vyhledávačům Turbo10 posílá dotaz také do některých speciálních vyhledávačů (celkový uváděný počet se blíží číslu 800). Nabízí i část www prostoru, který nazýváme hlubokým či neviditelným webem (deep/invisible web).
. Nabízí i část www prostoru, který nazýváme hlubokým či neviditelným webem (deep/invisible web).")
67
Neviditelný web brány pro neviditelný web Scirus – www.scirus.com
vyhledávací stroj Elsevieru – vyhledává ve viditelném i neviditelném webu specifický vyhledávací nástroj pro odborné informace (záměrná filtrace nevědeckých obsahů, hluboká indexace www, vědeckých databází)
")
68
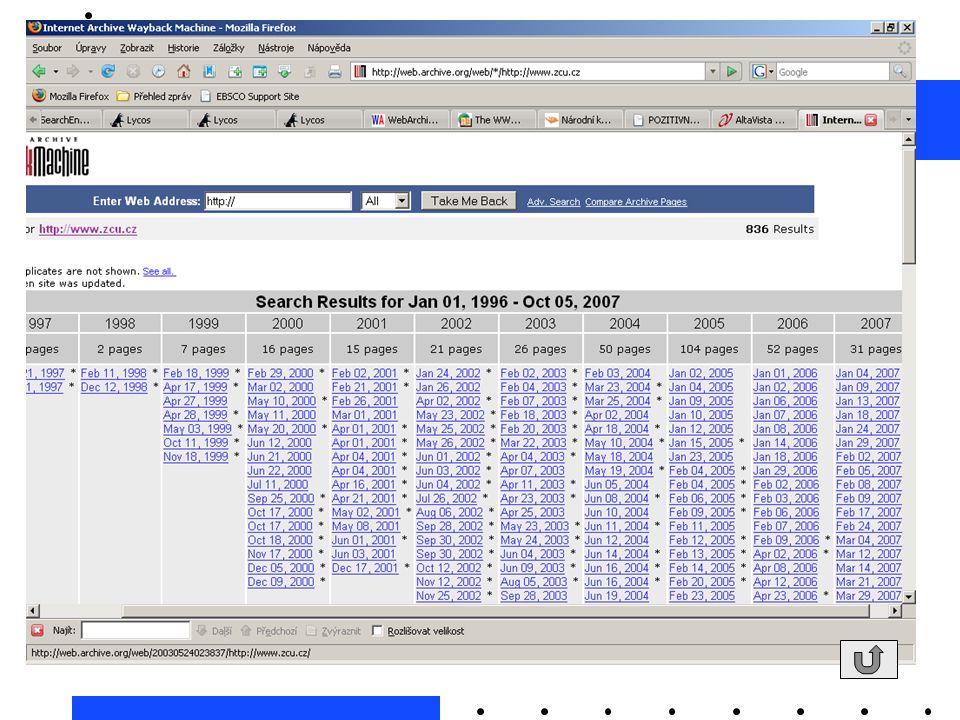
Archiv webu Internet Archive Wayback Machine http://www.archive.org
nová BETA verze - asi 10 miliard stránek v rozsahu 1Pbyte (7/2004) snaha o zpracování, uchovávání a zpřístupnění webových zdrojů jako specifické kategorie elektronických dokumentů první svého druhu, je Internet Archive cíl: budování archivu celého volně přístupného webu na konci října 2001 uvedena do provozu služba Wayback Machine, která je bránou k tomuto archivu nabízí všem uživatelům unikátní příležitost prohlížet vybrané webové zdroje v podobě, jakou měly před pěti lety nebo minulý měsíc, a to na základě zadaného URL - vyhledávání je možné omezit na určité období hodnotu tohoto systému zvyšuje fakt, že některé z webových zdrojů nemusí vůbec existovat nebo jsou přesunuty na neznámou adresu Problémy:odezva systému na rešeršní požadavek je nezřídka poměrně pomalá zdaleka ne všechny stránky jsou kompletně "zrekonstruovány" - chybějí na nich obrázky, odkazy nejsou funkční a konečně archiv není úplný (podobně jako v případě běžných webových vyhledávacích služeb nelze zaručit, že jejich robot se dostane na všechny stránky)
 snaha o zpracování, uchovávání a zpřístupnění webových zdrojů jako specifické kategorie elektronických dokumentů. první svého druhu, je Internet Archive. cíl: budování archivu celého volně přístupného webu. na konci října 2001 uvedena do provozu služba Wayback Machine, která je bránou k tomuto archivu. nabízí všem uživatelům unikátní příležitost prohlížet vybrané webové zdroje v podobě, jakou měly před pěti lety nebo minulý měsíc, a to na základě zadaného URL - vyhledávání je možné omezit na určité období. hodnotu tohoto systému zvyšuje fakt, že některé z webových zdrojů nemusí vůbec existovat nebo jsou přesunuty na neznámou adresu. Problémy:odezva systému na rešeršní požadavek je nezřídka poměrně pomalá. zdaleka ne všechny stránky jsou kompletně zrekonstruovány - chybějí na nich obrázky, odkazy nejsou funkční a konečně archiv není úplný (podobně jako v případě běžných webových vyhledávacích služeb nelze zaručit, že jejich robot se dostane na všechny stránky)")
69
Archiv webu WebArchiv - archiv českého webu
uchování digitálních dokumentů volně dostupných na webu co lze nalézt ve WebArchivu: publikace odborného, uměleckého a zpravodajsko- publicistického zaměření textové a do jisté míry i obrazové a zvukové dokumenty existující pouze v digitální podobě

70
Závěr problémy současného internetu
neustálý nárůst hostitelských počítačů nové typy dokumentů, které nejsou dostatečně indexované množství vyhledávacích nástrojů různé kvality žádný nástroj nepokrývá celý web obsah a lokalizace dokumentů se často mění málo vyhledávacích nástrojů hodnotí dokumenty současná verze html neumožňuje dostatečně popisovat obsah dokumentu (podává informaci o grafickém uspořádání dokumentu) – o postižení obsahu dokumentu se snaží tzv. „sémantický web“ sémantický web využívá jazyka XML u klasických webových stránek je pro počítač odstavec textu jen shlukem znaků pokud stránka bude doplněna o sémantiku (neboli význam), bude počítač vědět, že ten odstavec se týká např. loňských finančních výsledků firmy lepší relevantnost ve vyhledávačích, počítač bude moci zpracovávat data logicky (dle významu) a ne jen mechanicky (dle filtrů) atd. Základním krokem k vytvoření sémantického webu je konceptualizace dat dostupných na Internetu, jejíž klíčovým nástrojem jsou ontologie, aneb formalizované reprezentace znalostí určené k jejich sdílení a znovupoužití. Sémantický web je dále založen na standardizovaném popisu webových zdrojů (vše, dosažitelné pomocí WWW, tedy textové dokumenty, obrázky, videosekvence, zvukové soubory apod.). Každý zdroj by byl vybaven stejnými charakteristikami údaji (autor, typ zdroje, klíčová slova atd.), což by umožnilo uživatelům Internetu pracovat se sítí WWW jako s relační databází a dotazovat se na její obsah prostřednictvím jazyků podobných SQL. Důraz by se kladl na vysokou přesnost a relevanci odpovědi na vyhledávací dotaz.
 – o postižení obsahu dokumentu se snaží tzv. „sémantický web sémantický web využívá jazyka XML. u klasických webových stránek je pro počítač odstavec textu jen shlukem znaků. pokud stránka bude doplněna o sémantiku (neboli význam), bude počítač vědět, že ten odstavec se týká např. loňských finančních výsledků firmy. lepší relevantnost ve vyhledávačích, počítač bude moci zpracovávat data logicky (dle významu) a ne jen mechanicky (dle filtrů) atd. Základním krokem k vytvoření sémantického webu je konceptualizace dat dostupných na Internetu, jejíž klíčovým nástrojem jsou ontologie, aneb formalizované reprezentace znalostí určené k jejich sdílení a znovupoužití. Sémantický web je dále založen na standardizovaném popisu webových zdrojů (vše, dosažitelné pomocí WWW, tedy textové dokumenty, obrázky, videosekvence, zvukové soubory apod.). Každý zdroj by byl vybaven stejnými charakteristikami údaji (autor, typ zdroje, klíčová slova atd.), což by umožnilo uživatelům Internetu pracovat se sítí WWW jako s relační databází a dotazovat se na její obsah prostřednictvím jazyků podobných SQL. Důraz by se kladl na vysokou přesnost a relevanci odpovědi na vyhledávací dotaz.")
71
Závěr Další literatura:
MAKULOVÁ, SOŇA Vyhľadávanie informácií v internete : problémy, východiská, postupy. Bratislava : EL&T, 2002. BOLDIŠ, PETR. Jak oddělit zrno od plev: Ověřování informací v prostředí internetu [online] [citováno ]. < >. BOLDIŠ, PETR. Vyhledávání na internetu [online] [citováno ]. <

72
Děkuji za pozornost

92
Billions Of Textual Documents Indexed December 1995-September 2003
GG – Google, ATW – All The Web, INK – Inktomi, TMA – Teoma, AV - Altavista

116
Makulová

Podobné prezentace













>")




>")










 komunikace.>")


 Pro předmět Jazykový projev (2014/15) připravila Eva Cerniňáková Jabok - Vyšší odborná škola sociálně.>")