Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Praktikum elementární analýzy dat Třídění 2. a 3. stupně 30.5.2012 UK FHS Řízení a supervize (LS 2012) Jiří Šafr jiri.safr(zavináč)seznam.cz poslední aktualizace 30. 5. 2012
 Jiří Šafr jiri.safr(zavináč)seznam.cz poslední aktualizace")
2
Struktura – plán práce Opakování třídění 1. stupně (průměr, směr.odchylka, procenta) „Orientační mapa“ analýzy vztahu 2 proměnných: –Spojitá × spojitá –Spojitá (závislá) × kategoriální (nezávislá) –Kategoriální × kategoriální Kontingenční tabulky Třídění 3. stupně (dtto) Procvičování na datech FHS Knihy&TV Tvorba součtových indexů (data Práce se seniory) Na co s dát pozor (výběrová data vs. census) Jak to má vypadat – úprava tabulek a dalších výstupů
 „Orientační mapa analýzy vztahu 2 proměnných: –Spojitá × spojitá –Spojitá (závislá) × kategoriální (nezávislá) –Kategoriální × kategoriální Kontingenční tabulky Třídění 3. stupně (dtto) Procvičování na datech FHS Knihy&TV Tvorba součtových indexů (data Práce se seniory) Na co s dát pozor (výběrová data vs. census) Jak to má vypadat – úprava tabulek a dalších výstupů.")
3
„Orientační mapa“ analýzy 2 proměnných Hlavním cílem výzkumu je testovat hypotézy 2.řádu = vztah dvou (a více) proměnných. (Jak) souvisí spolu hodnoty jedné a druhé proměnné? Např. Proměnné existují ve 2 základních typech: kategoriální (nominální a ordinální) spojité – kardinální (číselné) → různé varianty jejich kombinací při analýze
 souvisí spolu hodnoty jedné a druhé proměnné. Např. Proměnné existují ve 2 základních typech: kategoriální (nominální a ordinální) spojité – kardinální (číselné) → různé varianty jejich kombinací při analýze.")
4
„Orientační mapa“ analýzy dvou proměnných – přehled analytických nástrojů Spojitá × spojitá, např. počet přečtených knih a věk → korelační koeficient (Pearsonův), bodový X-Y graf Spojitá (závislá) × kategoriální (nezávislá) např. např. počet přečtených knih a obor studia → průměry v podskupinách, koeficient Eta, graf průměrů v podskupinách (Barchart pro mean, Line-multiple nebo Boxplot, Errorbar) Kategoriální × kategoriální např. oblíbené literární žánry a obor studia → kontingenční tabulka, sloupcový graf (Barchart) pro % koeficient kontingence (CC), Phi, Gama …
, bodový X-Y graf Spojitá (závislá) × kategoriální (nezávislá) např. např. počet přečtených knih a obor studia → průměry v podskupinách, koeficient Eta, graf průměrů v podskupinách (Barchart pro mean, Line-multiple nebo Boxplot, Errorbar) Kategoriální × kategoriální např. oblíbené literární žánry a obor studia → kontingenční tabulka, sloupcový graf (Barchart) pro % koeficient kontingence (CC), Phi, Gama ….")
5
Spojitá × spojitá Číselná proměnná → ideální situace: nejlepší způsob měření, nejsofistikovanější analýzy, možnost převodu na kategoriální Korelace (a nebo) X-Y graf CORRELATIONS knihy_celk WITH TV. GRAPH /SCATTERPLOT(BIVAR) =knihy_celk WITH TV. ALE! Korelace měří lineární vztah (přímou úměru) a předpokládá „normální“ rozložení proměnných. Závislosti mohou mít i jinou než lineární povahu, proto si raději udělejte i X-Y (Scatter plot) → souvislosti jsou vizuálně vidět Pozor na Outliery – extrémní hodnoty znaků (a jejich kombinace) R - korelační koeficient R 2 - koeficient determinace R = √R 2 a R2 = R × R zde √0,066 = 0,257
 =knihy_celk WITH TV. ALE. Korelace měří lineární vztah (přímou úměru) a předpokládá „normální rozložení proměnných. Závislosti mohou mít i jinou než lineární povahu, proto si raději udělejte i X-Y (Scatter plot) → souvislosti jsou vizuálně vidět Pozor na Outliery – extrémní hodnoty znaků (a jejich kombinace) R - korelační koeficient R 2 - koeficient determinace R = √R 2 a R2 = R × R zde √0,066 = 0,257.")
6
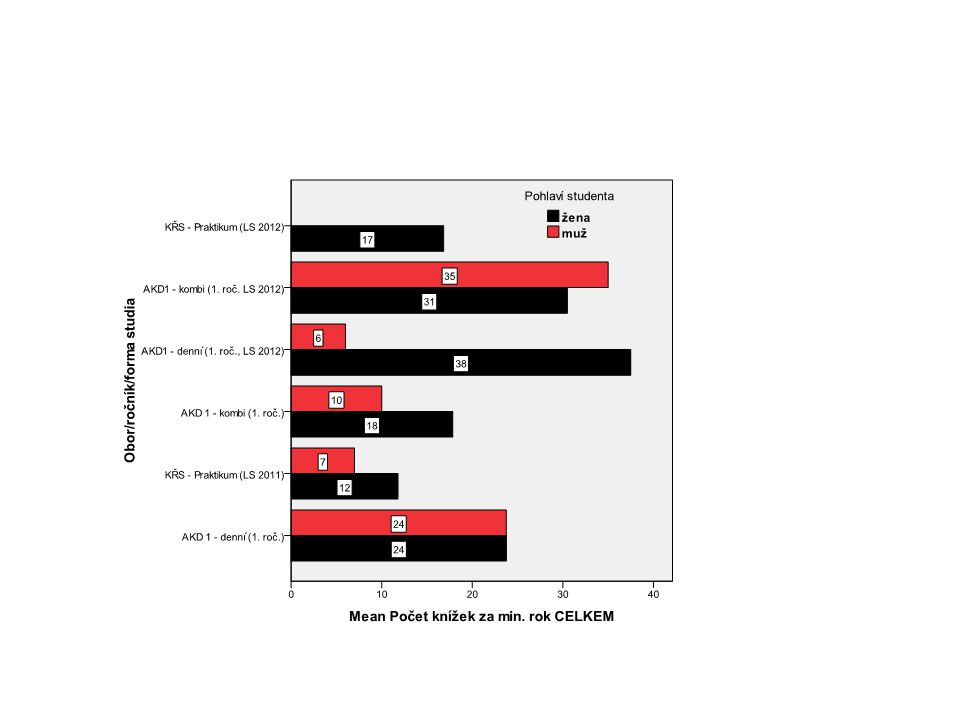
Spojitá (závislá) × kategoriální (nezávislá) V principu porovnáváme průměry závislé - spojité v kategoriích nezávislé proměnné + kontrola rozptylu (směrodatné odchylky StD ve skupinách) missing values studium (5 6). MEANS knihy_celk BY studium. GRAPH /BAR(SIMPLE)=MEAN(knihy_celk) BY studium. *pro výběrová data = vzorek z populace) Intervalový odhad průměru s konfidenčním int.:. GRAPH ERRORBAR (CI) knihy_celk BY studium.
=MEAN(knihy_celk) BY studium. *pro výběrová data = vzorek z populace) Intervalový odhad průměru s konfidenčním int.:. GRAPH ERRORBAR (CI) knihy_celk BY studium..")
7
Kategoriální × kategoriální Kontingenční tabulka: hledáme souvislosti pomocí spoluvýskytu v relativních četnostech (%) Odchylky od očekávané=teoretické četnosti (→ znaménkové schéma) Pro ordinální znaky sledujeme krajní kategorie a kupení na diagonále. Vidíme i vztahy spoluvýskytu, které nejsou lineární (pro nominální znaky) CROSSTABS knihy_celk3t BY TV3t. CROSSTABS knihy_celk3t BY TV3t /cel = col. CROSSTABS knihy_celk3t BY TV3t /cel = col count. *+ test homogenity; míry asociace / korelace. CROSSTABS knihy_celk3t BY TV3t /cel = col / STATISTICS CC CORREL LAMBDA. Vždy kontrolujeme počet absolutních četností! Pod cca 5 → problém (→ nespolehlivé závěry) → sloučit kategorie.
 CROSSTABS knihy_celk3t BY TV3t. CROSSTABS knihy_celk3t BY TV3t /cel = col. CROSSTABS knihy_celk3t BY TV3t /cel = col count. *+ test homogenity; míry asociace / korelace. CROSSTABS knihy_celk3t BY TV3t /cel = col / STATISTICS CC CORREL LAMBDA. Vždy kontrolujeme počet absolutních četností. Pod cca 5 → problém (→ nespolehlivé závěry) → sloučit kategorie..")
8
Třídění 3. stupně

11
Na co s dát pozor

12
Výběrová data vs. census Máme-li data z náhodného (dobrého kvótního) výběru z populace (tj. vzorek), pak k testování hypotéz můžeme (měli bychom) přistoupit pomocí principů statistické inference (statistické testy; intervalové odhady → viz AKDII. http://metodykv.wz.cz/index.htm#analyza2 ) http://metodykv.wz.cz/index.htm#analyza2 A naopak máme-li kompletní populaci (census) statistické testy nedávají smysl.
, pak k testování hypotéz můžeme (měli bychom) přistoupit pomocí principů statistické inference (statistické testy; intervalové odhady → viz AKDII. ) A naopak máme-li kompletní populaci (census) statistické testy nedávají smysl..")
13
Pozor na … Nízké četnosti zejména při spoluvýskytu některých kategorií v kontingenčních tabulkách → sloučit (překódovat) Outliery = extrémní hodnoty → rekódovat na „nižší ale smysluplnou“ hodnotu (nebo případně označit jako chybějící hodnoty)
 Outliery = extrémní hodnoty → rekódovat na „nižší ale smysluplnou hodnotu (nebo případně označit jako chybějící hodnoty)")
Podobné prezentace



seznam.cz>")
seznam.cz vytvořeno 29. 6. 2009, poslední aktualizace 14. 2. 2012 UK FHS Historická.>")


seznam.cz>")



 0. Poučení z minulých ročníků a novinky od ZS 2013 (2011) poslední aktualizace 1.10.2014 Jiří Šafr jiri.safr(at)seznam.cz.>")



 Jiří Šafr jiri.safr(AT)seznam.cz Poslední aktualizace 23/5/2012 UK FHS Historická.>")
 Jiří Šafr jiri.safr(zavináč)seznam.cz poslední aktualizace.>")

 / Praktikum LS 2011,>")

