Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Zarovnávání biologických sekvencí
Úvod do medicínské informatiky pro Bc. studium Zarovnávání biologických sekvencí 9. přednáška

2
Zarovnávání biologických sekvencí
Úvod do medicínské informatiky pro Bc. studium Zarovnávání biologických sekvencí Pravděpodobnost a pravděpodobnostní modely Zarovnávání Významnost skóre v hodnocení modelu Nastavení parametrů modelů

3
Pravděpodobnost a pravděpodobnostní modely
Úvod do medicínské informatiky pro Bc. studium Pravděpodobnost a pravděpodobnostní modely Model je systém simulující objekt za určitých podmínek. Pravděpodobnostní model je systém poskytující různé výstupy s různými pravděpodobnostmi, a může simulovat třídu objektů.

4
Maximální pravděpodobnost
Úvod do medicínské informatiky pro Bc. studium Maximální pravděpodobnost Parametry modelu jsou odhadovány z velké množiny "správných" příkladů (trénovací množina). Příklad: Pravděpodobnost qa pro aminokyselinu a může být odhadnuta jako pozorovaná četnost výskytů reziduí v databázi známých proteinových sekvencí, např. SWISS-PROT.
. Příklad: Pravděpodobnost qa pro aminokyselinu a může být odhadnuta jako pozorovaná četnost výskytů reziduí v databázi známých proteinových sekvencí, např. SWISS-PROT.")
5
Maximální pravděpodobnost
Úvod do medicínské informatiky pro Bc. studium Maximální pravděpodobnost Tento způsob odhadu se nazývá metoda maximální pravděpodobnosti. Obecně: Je dán model s parametry θ a množina dat D, potom odhad maximální pravděpodobnosti pro θ je taková hodnota, která maximalizuje P(D|θ).
.")
6
Pravděpodobnosti Podmíněná pravděpodobnost Vzájemná pravděpodobnost
Úvod do medicínské informatiky pro Bc. studium Pravděpodobnosti Podmíněná pravděpodobnost Vzájemná pravděpodobnost Marginální pravděpodobnost Příklad: Máme dvě kostky D1 a D2. Pravděpodobnost, že padne i při hodu kostkou D1 je podmíněná pravděpodobnost P(i|D1).
.")
7
Úvod do medicínské informatiky pro Bc. studium
Pravděpodobnosti Vybereme-li náhodně kostku Dj s p. P(Dj), j=1, 2, p. výběru kostky Dj a hození i je součinem dvou p. a nazývá se vzájemnou pravděpodobností P(i,Dj)=P(Dj).P(i|Dj). Rovnice P(X,Y)= P(X|Y).P(Y) platí obecně pro jakékoliv jevy X a Y. Jestliže jsou podmíněná i vzájemná p. známy, můžeme vypočítat marginální pravděpodobnost P(X)=SYP(X,Y)=SYP(X|Y).P(Y)
, j=1, 2, p. výběru kostky Dj a hození i je součinem dvou p. a nazývá se vzájemnou pravděpodobností P(i,Dj)=P(Dj).P(i|Dj). Rovnice P(X,Y)= P(X|Y).P(Y) platí obecně pro jakékoliv jevy X a Y. Jestliže jsou podmíněná i vzájemná p. známy, můžeme vypočítat marginální pravděpodobnost P(X)=SYP(X,Y)=SYP(X|Y).P(Y)")
8
Úvod do medicínské informatiky pro Bc. studium
Párování Základní úlohou sekvenční analýzy je otázka, zda jsou dvě sekvence v relaci (zda spolu souvisí, zda mají společného předka). Úloha má dvě části: párování (zarovnání sekvencí nebo jejich částí), posouzení, zda se párování zdařilo díky relaci sekvencí nebo náhodou, za pomoci ohodnocení.
. Úloha má dvě části: párování (zarovnání sekvencí nebo jejich částí), posouzení, zda se párování zdařilo. díky relaci sekvencí nebo. náhodou, za pomoci ohodnocení.")
9
Příklady relací sekvencí
Úvod do medicínské informatiky pro Bc. studium Příklady relací sekvencí Hemoglobin subunit alpha versus Hemoglobin subunit beta

10
Úvod do medicínské informatiky pro Bc. studium

11
Úvod do medicínské informatiky pro Bc. studium

12
Úvod do medicínské informatiky pro Bc. studium

13
Úvod do medicínské informatiky pro Bc. studium

14
Příklady relací sekvencí
Úvod do medicínské informatiky pro Bc. studium Příklady relací sekvencí Lidský alfa globin: HBA_HUMAN GSAQVKGHGKKVADALTNAVAHVD G+ +VK+HGKKV A+++++AH+D HBB_HUMAN GNPKVKAHGKKVLGAFSDGLAHLD Jasná podobnost lidskému beta globinu. H+ KV + +A ++ LGB2_LUPLU NNPELQAHAGKVFKLVYEAAIQLQ Strukturálně přijatelné srovnání s leghemoglobinem. Písmeno – identická pozice, + - 'podobná pozice'

15
Úvod do medicínské informatiky pro Bc. studium
Model ohodnocení Při porovnávání sekvencí hledáme důkaz divergence ze společného předka, která mohla nastat procesem mutace, a selekce. Základní mutační procesy jsou substituce (změna rezidua), a inserce a delece (přidání a vypuštění rezidua). Inserce a delece jsou vztaženy k mezerám.
, a. inserce a delece (přidání a vypuštění rezidua). Inserce a delece jsou vztaženy k mezerám.")
16
Modely (ne)příbuznosti
Úvod do medicínské informatiky pro Bc. studium Modely (ne)příbuznosti Dvojice sekvencí x a y délky n a m. xi je i-tý symbol x, yj je j-tý symbol y. Symboly jsou z abecedy A. A ={A, G, C, T} pro DNA, A ={20 aminokyselin} pro proteiny. Dvojici sekvencí přiřadíme skóre párování, které představuje p., že sekvence jsou příbuzné (jako opak nepříbuznosti).
příbuznosti. Dvojice sekvencí x a y délky n a m. xi je i-tý symbol x, yj je j-tý symbol y. Symboly jsou z abecedy A. A ={A, G, C, T} pro DNA, A ={20 aminokyselin} pro proteiny. Dvojici sekvencí přiřadíme skóre párování, které představuje p., že sekvence jsou příbuzné (jako opak nepříbuznosti).")
17
Úvod do medicínské informatiky pro Bc. studium
Model nepříbuznosti Nepříbuzný (náhodný) model R předpokládá, že symbol a se objevuje nezávisle s četností qa. P. dvou sekvencí je potom pouze součinem p. sekvencí:
 model R předpokládá, že symbol a se objevuje nezávisle s četností qa. P. dvou sekvencí je potom pouze součinem p. sekvencí:")
18
Úvod do medicínské informatiky pro Bc. studium
Model příbuznosti V modelu příbuznosti M se zarovnané páry reziduí objevují se vzájemnou p. pab. pab může být chápána jako p. toho, že rezidua a a b byla nezávisle odvozena z neznámého rezidua c ve společném předkovi. c může být totožné s a nebo b.

19
Pravděpodobnostní poměr
Úvod do medicínské informatiky pro Bc. studium Pravděpodobnostní poměr Pravděpodobnostní poměr je dán poměrem p. obou modelů:

20
Logaritmický pravděpodobnostní poměr
Úvod do medicínské informatiky pro Bc. studium Logaritmický pravděpodobnostní poměr Obvykle se využívá aditivního skórovacího systému. Tomu odpovídá logaritmický pravděpodobnostní poměr: kde s(xi,yi) je individuální skóre
 je individuální skóre.")
21
Úvod do medicínské informatiky pro Bc. studium
Substituční matice Log p. poměr je sumou individuálních skóre s(a,b) pro každý zarovnaný pár reziduí. Skóre s(a,b) bývají vyjádřena substituční maticí (maticí skóre). Např. pro proteiny tvoří matici 20x20 s s(ai,aj) na pozicích i, j, kde ai, aj jsou i-tá a j-tá aminokyselina
 pro každý zarovnaný pár reziduí. Skóre s(a,b) bývají vyjádřena substituční maticí (maticí skóre). Např. pro proteiny tvoří matici 20x20 s s(ai,aj) na pozicích i, j, kde ai, aj jsou i-tá a j-tá aminokyselina.")
22
Příklad substituční matice
Úvod do medicínské informatiky pro Bc. studium A R N D C Q E G H I L K M F P S T W Y V 5 -2 -1 -3 1 7 -4 2 8 13 6 10 15 Matice BLOSUM50

23
Úvod do medicínské informatiky pro Bc. studium
Penalizace mezer Kromě substitucí je nutné ohodnotit také inserce a delece. Standardní cena mezery délky g je Alternativou je afinní skóre kde d je standarní cena a e<d je rozšiřující cena pro menší penalizaci dlouhých insercí a delecí.

24
Zarovnávací algoritmy
Úvod do medicínské informatiky pro Bc. studium Zarovnávací algoritmy Zarovnávací algoritmy slouží k nalezení optimálního zarovnání dvojice sekvencí. Jsou-li sekvence stejně dlouhé, existuje jediné možné (globální) zarovnání kompletních sekvencí. Uvážíme-li také mezery, existuje možných globálních zarovnání. n=10: 1,9.105 n=100:
 zarovnání kompletních sekvencí. Uvážíme-li také mezery, existuje. možných globálních zarovnání. n=10: 1, n=100:")
25
Globální v. lokální zarovnávání
Úvod do medicínské informatiky pro Bc. studium Globální v. lokální zarovnávání Při globálním zarovnávání hledáme optimální vzájemnou polohu dvou sekvencí od jednoho konce k druhému. Častější situací je zarovnávání subsekvencí v tzv. lokálním zarovnávání.

26
Dynamické programování
Úvod do medicínské informatiky pro Bc. studium Dynamické programování Optimální zarovnání se v analýze biologických sekvencí řeší dynamickým programováním: Needlemanův-Wunschův algoritmus, Gotohův a., Smithův-Watermanův a.. a další.

27
Dynamické programování
Úvod do medicínské informatiky pro Bc. studium Dynamické programování Dynamické programování (DP) zaručuje nalezení optimálního zarovnání. Existují rychlejší – heuristické – algoritmy, které ale vyžadují apriorní informaci a nemusí vždy nalézt globální optimum. DP využívá v analýze biologických sekvencí logaritmický pravděpodobnostní poměr půjde o nalezení maxima.
 zaručuje nalezení optimálního zarovnání. Existují rychlejší – heuristické – algoritmy, které ale vyžadují apriorní informaci a nemusí vždy nalézt globální optimum. DP využívá v analýze biologických sekvencí logaritmický pravděpodobnostní poměr půjde o nalezení maxima.")
28
Needlemanův-Wunschův a.
Úvod do medicínské informatiky pro Bc. studium Needlemanův-Wunschův a. Myšlenka: globální zarovnání využije předchozí lokální zarovnání kratších subsekvencí. Vytváří se matice F (indexovaná i a j pro jednotlivé sekvence). F(i,j) je skóre nejlepšího zarovnání mezi počátečním segmentem x1..i sekvence x do xi a počátečním segmentem y1..j sekvence y do yj.
. F(i,j) je skóre nejlepšího zarovnání mezi počátečním segmentem x1..i sekvence x do xi a počátečním segmentem y1..j sekvence y do yj.")
29
Konstrukce N.-W. a. Existují 3 možné cesty k nejlepšímu skóre F(i,j).
Úvod do medicínské informatiky pro Bc. studium Konstrukce N.-W. a. Existují 3 možné cesty k nejlepšímu skóre F(i,j). I G A xi A I G A xi G A xi - - L G V yj G V yj S L G V yj xi je zarovnáno k yj, pak F(i,j)= F(i-1,j-1)+s(xi,yj), xi je zarovnáno k mezeře, pak F(i,j)= F(i-1,j)-d, yj je zarovnáno k mezeře, pak F(i,j)= F(i,j-1)-d,.
. I G A xi A I G A xi G A xi - - L G V yj G V yj - - S L G V yj. xi je zarovnáno k yj, pak F(i,j)= F(i-1,j-1)+s(xi,yj), xi je zarovnáno k mezeře, pak F(i,j)= F(i-1,j)-d, yj je zarovnáno k mezeře, pak F(i,j)= F(i,j-1)-d,.")
30
Needlemanův-Wunschův a.
Úvod do medicínské informatiky pro Bc. studium Needlemanův-Wunschův a. F(i,j) je konstruována rekurzivně. Inicializace je F(i,j)=0. Po té se matice plní shora zleva směrem dolů doprava:
 je konstruována rekurzivně. Inicializace je F(i,j)=0. Po té se matice plní shora zleva směrem dolů doprava:")
31
Needlemanův-Wunschův a.
Úvod do medicínské informatiky pro Bc. studium Needlemanův-Wunschův a. Matice je naplněna takto: Během plnění je uchována informace o cestě (index buňky, která byla zdrojem hodnoty). F(i-1,j-1) F(i,j-1) F(i-1,j) F(i,j) -d s(xi,yj)
. F(i-1,j-1) F(i,j-1) F(i-1,j) F(i,j) -d. s(xi,yj)")
32
sekvence 1: HEAGAWGHEE sekvence 2: PAWHEAE N.–W. a. - příklad
Úvod do medicínské informatiky pro Bc. studium N.–W. a. - příklad sekvence 1: HEAGAWGHEE sekvence 2: PAWHEAE

33
Penalizační skóre Hodnoty z matice BLOSUM50 pro sekvence z příkladu.
Úvod do medicínské informatiky pro Bc. studium Penalizační skóre Hodnoty z matice BLOSUM50 pro sekvence z příkladu. H E A G W P -2 -1 -4 5 -3 15 10 6 Penalizace mezer d=-8.

34
N. –W. a. - příklad HEAGAWGHEE PAWHEAE H E A G A W G H E E P A W H E A
Úvod do medicínské informatiky pro Bc. studium N. –W. a. - příklad H E A G A W G H E E -48 -56 -40 -32 -24 -16 -8 -80 -72 -64 P 2 -5 -15 -12 -11 -3 -16 -30 1 -9 -14 -6 -24 -38 3 -7 -8 -22 -19 -13 -18 -37 -29 -21 -60 -52 -44 -36 -28 -20 -73 -65 -57 -49 -42 -33 -2 -9 -17 -25 A -10 -3 -4 -12 W H H E A G W P -2 -1 -4 5 -3 15 10 6 E A E HEAGAWGHEE PAWHEAE

35
N. –W. a. - příklad Optimální zarovnání: HEAGAWGHE-E
Úvod do medicínské informatiky pro Bc. studium N. –W. a. - příklad H E A G A W G H E E -8 -16 -24 -32 -40 -48 -56 -64 -72 -80 P -8 -2 -9 -17 -25 -33 -42 -49 -57 -65 -73 A -16 -10 -3 -4 -12 -20 -28 -36 -44 -52 -60 W -24 -18 -11 -6 -7 -15 -5 -13 -21 -29 -37 H -32 -14 -18 -13 -8 -9 -13 -7 -3 -11 -19 E -40 -22 -8 -16 -16 -9 -12 -15 -7 3 -5 A -48 -30 -16 -3 -11 -11 -12 -12 -15 -5 2 E -56 -38 -24 -11 -6 -12 -14 -15 -12 -9 1 Optimální zarovnání: HEAGAWGHE-E (celkové skóre = 1) --P-AW-HEAE
 --P-AW-HEAE.")
36
N.–W. a. – výsledek příkladu
Úvod do medicínské informatiky pro Bc. studium N.–W. a. – výsledek příkladu sekvence 1: HEAGAWGHE-E sekvence 2: --P-AW-HEAE

37
Úvod do medicínské informatiky pro Bc. studium
Zpětné trasování Z pravého dolního rohu (n,m) matice F můžeme zakreslit optimální cestu. Optimální cesta je výstupem dynamického programování a odpovídá optimálnímu globálnímu zarovnání (s nejvyšším možným celkovým skóre). Cesta končí v levém horním rohu (0,0), kde se nachází hodnota F(0,0)=0.
 matice F můžeme zakreslit optimální cestu. Optimální cesta je výstupem dynamického programování a odpovídá optimálnímu globálnímu zarovnání (s nejvyšším možným celkovým skóre). Cesta končí v levém horním rohu (0,0), kde se nachází hodnota F(0,0)=0.")
38
Úvod do medicínské informatiky pro Bc. studium
Inicializace N.–W. a. V horním řádku pro j=0 nejsou definovány hodnoty F(i,j-1) a F(i-1,j-1). F(i,0) reprezentuje zarovnání prefixu x ke všem mezerám v y. Definujeme F(i,0)=-id. Podobně pro levý sloupec pro i=0 je F(0,j)=-jd.
 a F(i-1,j-1). F(i,0) reprezentuje zarovnání prefixu x ke všem mezerám v y. Definujeme F(i,0)=-id. Podobně pro levý sloupec pro i=0 je F(0,j)=-jd.")
39
Náročnost Needlemanova-Wunschova algoritmu
Úvod do medicínské informatiky pro Bc. studium Náročnost Needlemanova-Wunschova algoritmu Výpočetní a paměťové nároky jsou v analýze biologických dat vždy kritické. V N.-W. a. potřebujeme (m+1).(n+1) paměťových míst, pro každé číslo vypočítat 3 součty a 1 maximum. Celková časová náročnost je O(nm) – časová náročnost a protože obvykle n m, pak náročnost je O(n2)
.(n+1) paměťových míst, pro každé číslo vypočítat 3 součty a 1 maximum. Celková časová náročnost je. O(nm) – časová náročnost. a protože obvykle n m, pak náročnost je O(n2)")
40
Úvod do medicínské informatiky pro Bc. studium
Smithův-Watermanův a. Obecně algoritmy (dynamického programování) pro lokální zarovnávání vycházejí z principu globálního zarovnávání. Dva rozdíly: U každého prvku matice F je přidána další možnost stanovit F(i,j)=0 v případě, že ostatní varianty jsou <0. Zarovnávání může skončit kdekoliv uvnitř matice F, nikoliv nutně v pravém dolním rohu.
 pro lokální zarovnávání vycházejí z principu globálního zarovnávání. Dva rozdíly: U každého prvku matice F je přidána další možnost stanovit F(i,j)=0 v případě, že ostatní varianty jsou <0. Zarovnávání může skončit kdekoliv uvnitř matice F, nikoliv nutně v pravém dolním rohu.")
41
Smithův-Watermanův a. ad Rozdíl 1:
Úvod do medicínské informatiky pro Bc. studium Smithův-Watermanův a. ad Rozdíl 1: Volba hodnoty 0 odpovídá "nastartování" nového zarovnávání.

42
sekvence 1: HEAGAWGHEE sekvence 2: PAWHEAE S.–W. a. - příklad
Úvod do medicínské informatiky pro Bc. studium S.–W. a. - příklad sekvence 1: HEAGAWGHEE sekvence 2: PAWHEAE (Jde o stejné sekvence jako v příkladu pro globální zarovnání.)
")
43
S. –W. a. - příklad Optimální zarovnání: AWGHE
Úvod do medicínské informatiky pro Bc. studium S. –W. a. - příklad H E A G W P 5 2 20 12 4 10 18 22 14 6 16 8 28 21 13 27 26 Optimální zarovnání: AWGHE (celkové skóre = 28) AW-HE
 AW-HE.")
44
S.–W. a. – výsledek příkladu
Úvod do medicínské informatiky pro Bc. studium S.–W. a. – výsledek příkladu sekvence 1: HEAGAWGHE-E sekvence 2: --P-AW-HEAE V příkladu je nalezeno lokální zarovnání jako podmnožina globálního zarovnání. To však nemusí vždy nutně nastat.

45
Úvod do medicínské informatiky pro Bc. studium
Inicializace S.-W. a. V horním řádku pro j=0 nejsou definovány hodnoty F(i,j-1) a F(i-1,j-1). Použití 0 v algoritmu vynucuje změnu inicializace F. Definujeme F(i,0)=0. Podobně pro levý sloupec pro i=0 je F(0,j)=0.
 a F(i-1,j-1). Použití 0 v algoritmu vynucuje změnu inicializace F. Definujeme F(i,0)=0. Podobně pro levý sloupec pro i=0 je F(0,j)=0.")
46
Úvod do medicínské informatiky pro Bc. studium
Zpětné trasování Při zpětném trasování nemusíme vycházet z prvku F(n,m), ale z prvku Trasování opět končí ve chvíli, kdy dosáhneme prvku F(i,j)=0. To nemusí být nutně v bodě (0,0).
, ale z prvku. Trasování opět končí ve chvíli, kdy dosáhneme prvku F(i,j)=0. To nemusí být nutně v bodě (0,0).")
47
Úvod do medicínské informatiky pro Bc. studium
Opakované shody V případě dlouhých sekvencí je pravděpodobné nalezení mnoha lokálních zarovnání s vysokým skóre. Existují překrývající se a nepřekrývající se části (motivy). Existují symetrické a asymetrické metody: asymetrické – hledá se opakující se část z jedné sekvence v druhé (ale už ne naopak).
. Existují symetrické a asymetrické metody: asymetrické – hledá se opakující se část z jedné sekvence v druhé (ale už ne naopak).")
48
Asymetrická metoda pro nepřekrývající se části
Úvod do medicínské informatiky pro Bc. studium Asymetrická metoda pro nepřekrývající se části Zavádí se práh skóre T pro zanedbání krátkých lokálních zarovnání. y – sekvence obsahující část (motiv). x – sekvence, v níž vyhledáváme opakované části. Matice F je použita tak, že x je rozděleno na části, které souhlasí s částmi v y v lokálních zarovnáních s mezerami, nesouhlasí s ničím.
. x – sekvence, v níž vyhledáváme opakované části. Matice F je použita tak, že x je rozděleno na části, které. souhlasí s částmi v y v lokálních zarovnáních s mezerami, nesouhlasí s ničím.")
49
Asymetrická metoda pro nepřekrývající se části
Úvod do medicínské informatiky pro Bc. studium Asymetrická metoda pro nepřekrývající se části F(i,j) je konstruována rekurzivně. Inicializace je F(i,j)=0. Po té se matice plní podle:
 je konstruována rekurzivně. Inicializace je F(i,j)=0. Po té se matice plní podle:")
50
Asymetrická metoda pro nepřekrývající se části
Úvod do medicínské informatiky pro Bc. studium Asymetrická metoda pro nepřekrývající se části Vztah pro F(i,0) zajišťuje nesouhlasící oblasti a konce zarovnání (v případě, že skóre převýší práh T). Vztah pro F(i,j) zajišťuje začátky zarovnání a prodloužení.
 zajišťuje nesouhlasící oblasti a konce zarovnání (v případě, že skóre převýší práh T). Vztah pro F(i,j) zajišťuje začátky zarovnání a prodloužení.")
51
Opakované shody - příklad
Úvod do medicínské informatiky pro Bc. studium Opakované shody - příklad H E A G W 1 3 9 P 5 6 2 21 13 10 19 23 15 16 8 11 29 28 18 12 4 17 27 9 Optimální zarovnání: HEAGAWGHEE (celkové skóre = 9, T=20) HEA.AW-HE.
 HEA.AW-HE.")
52
Asymetrická metoda pro překrývající se části
Úvod do medicínské informatiky pro Bc. studium Asymetrická metoda pro překrývající se části Pří zarovnání se mohou některé části překrývat v různých konfiguracích. x y x y x y x y

53
Asymetrická metoda pro překrývající se části
Úvod do medicínské informatiky pro Bc. studium Asymetrická metoda pro překrývající se části Požadujeme globální zarovnání, ale bez penalizace přesahujících konců. Zarovnání má začínat na horním nebo levém okraji a končit na spodním nebo pravém okraji. F(i,j) je konstruována rekurzivně. Inicializace je F(i,0)=0 pro i=1,...,n a F(0,j)=0 pro j=1,...,m.
 je konstruována rekurzivně. Inicializace je F(i,0)=0 pro i=1,...,n a F(0,j)=0 pro j=1,...,m.")
54
Asymetrická metoda pro překrývající se části
Úvod do medicínské informatiky pro Bc. studium Asymetrická metoda pro překrývající se části Po té se matice plní podle vztahu pro globální zarovnání (Needlemanův-Wunschův a.):
:")
55
Opakované shody - příklad
Úvod do medicínské informatiky pro Bc. studium Opakované shody - příklad H E A G W P -2 -1 -4 4 3 -3 -5 1 18 10 2 6 -6 16 20 12 8 7 26 21 13 5 25 14 24 Optimální zarovnání: GAWGHEE (celkové skóre = 25) PAW-HEA
 PAW-HEA.")
56
Použití složitějších modelů v dynamickém programování
Úvod do medicínské informatiky pro Bc. studium Použití složitějších modelů v dynamickém programování Doposud jsme uvažovali nejjednodušší modely s mezerami, kde mezerové skóre g(g) je pouze násobek délky. To není ideální pro biologické sekvence, protože penalizují další mezery stejně jako první, přičemž mezery jsou obvykle delší než reziduum.
 je pouze násobek délky. To není ideální pro biologické sekvence, protože. penalizují další mezery stejně jako první, přičemž mezery jsou obvykle delší než reziduum.")
57
Použití složitějších modelů
Úvod do medicínské informatiky pro Bc. studium Použití složitějších modelů Pokud máme obecnou funkci g(g), můžeme stále použít všechny předešlé modely podle vzoru:
, můžeme stále použít všechny předešlé modely podle vzoru:")
58
Použití modelů s obecnou funkcí g(g)
Úvod do medicínské informatiky pro Bc. studium Použití modelů s obecnou funkcí g(g) Takový model ale vyžaduje O(n3) operací. Modely s lineární mezerovou penalizační funkcí vyžadují jen O(n2) operací. Důvodem je, že pro každou buňku (i,j) se musíme dívat na i+j+1 potenciálních prekurzorů (nikoliv jen na 3).
 Takový model ale vyžaduje O(n3) operací. Modely s lineární mezerovou penalizační funkcí vyžadují jen O(n2) operací. Důvodem je, že pro každou buňku (i,j) se musíme dívat na i+j+1 potenciálních prekurzorů (nikoliv jen na 3).")
59
Zarovnání s afinní penalizací mezer
Úvod do medicínské informatiky pro Bc. studium Zarovnání s afinní penalizací mezer Existují 3 možné cesty k nejlepšímu skóre F(i,j). I G A xi A I G A xi G A xi - - L G V yj G V yj S L G V yj xi je zarovnáno k yj, pak M(i,j) je nejlepší skóre až do (i,j), xi je zarovnáno k mezeře, pak Ix(i,j) je nejlepší skóre při inserci xi, yj je zarovnáno k mezeře, pak Iy(i,j) je nejlepší skóre při inserci yj.
. I G A xi A I G A xi G A xi - - L G V yj G V yj - - S L G V yj. xi je zarovnáno k yj, pak M(i,j) je nejlepší skóre až do (i,j), xi je zarovnáno k mezeře, pak Ix(i,j) je nejlepší skóre při inserci xi, yj je zarovnáno k mezeře, pak Iy(i,j) je nejlepší skóre při inserci yj.")
60
Zarovnání s afinní penalizací mezer
Úvod do medicínské informatiky pro Bc. studium Zarovnání s afinní penalizací mezer Rekurentní relace jsou teď

61
Relace mezi stavy pro afinní penalizaci mezer
Úvod do medicínské informatiky pro Bc. studium Relace mezi stavy pro afinní penalizaci mezer s(xi,yj) M (+1,+1) Iy (+0,+1) Ix (+1,+0) -d -e
 M (+1,+1) Iy (+0,+1) Ix (+1,+0) -d. -e.")
62
Významnost skóre Jsou známy metody nalezení optimálního zarovnání.
Úvod do medicínské informatiky pro Bc. studium Významnost skóre Jsou známy metody nalezení optimálního zarovnání. Jak posoudit významnost jejich skóre? Jak rozhodneme, zda se jedná o nejlepší biologicky smysluplné zarovnání, nebo o nejlepší zarovnání mezi dvěma zcela nesouvisejícími sekvencemi?

63
Posouzení významnosti skóre
Úvod do medicínské informatiky pro Bc. studium Posouzení významnosti skóre V zásadě existují dva přístupy: Bayesovský (založený na porovnání různých modelů), tradiční statistický (založený na vyčíslení pravděpodobnosti, že skóre bude vyšší než pozorovaná hodnota za předpokladu použití nulového modelu, který odpovídá hypotéze, že sekvence jsou nesouvisející).
, tradiční statistický (založený na vyčíslení pravděpodobnosti, že skóre bude vyšší než pozorovaná hodnota za předpokladu použití nulového modelu, který odpovídá hypotéze, že sekvence jsou nesouvisející).")
64
Úvod do medicínské informatiky pro Bc. studium
Bayesovský přístup Byl definován logaritmický pravděpodobnostní poměr založený na modelu příbuznosti. Model příbuznosti využívá pravděpodobnosti P(x,y|M). Není lepší použít pravděpodobnost toho, že sekvence jsou související - P(M|x,y) - jako opaku, že nesouvisejí? Lze vypočítat podle Bayesova vzorce, známe-li některé další předpoklady.
. Není lepší použít pravděpodobnost toho, že sekvence jsou související - P(M|x,y) - jako opaku, že nesouvisejí Lze vypočítat podle Bayesova vzorce, známe-li některé další předpoklady.")
65
Úvod do medicínské informatiky pro Bc. studium
Bayesovský přístup Je nutné znát apriorní pravděpodobnosti obou modelů, P(R) a P(M). To bude odrážet naše očekávání, že sekvence souvisí, před tím, než je budeme analyzovat. Potom P(R)=1-P(M).
 a P(M). To bude odrážet naše očekávání, že sekvence souvisí, před tím, než je budeme analyzovat. Potom P(R)=1-P(M).")
66
Úvod do medicínské informatiky pro Bc. studium
Bayesovský přístup Aposteriorní pravděpodobnost toho, že model zarovnání je správný, je:

67
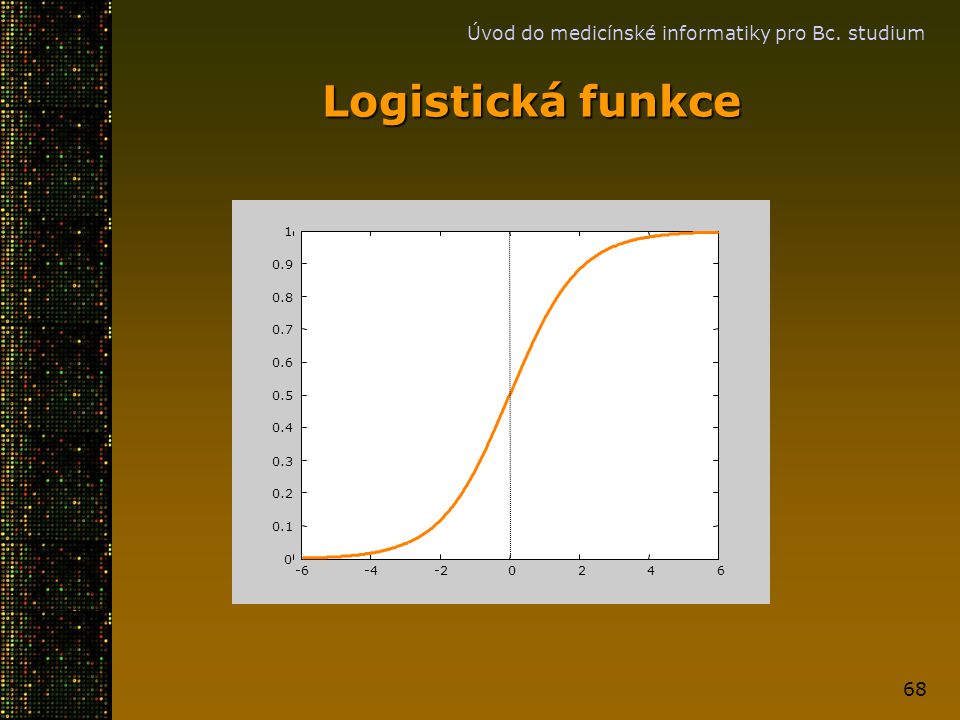
Bayesovský přístup Definujme kde Potom kde je logistická funkce.
Úvod do medicínské informatiky pro Bc. studium Bayesovský přístup Definujme kde Potom kde je logistická funkce.

68
Logistická funkce Úvod do medicínské informatiky pro Bc. studium -6 -4
-2 2 4 6 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
69
Úvod do medicínské informatiky pro Bc. studium
Bayesovský přístup V logaritmickém vztahu pro S byl přidán člen log(P(M)/P(R)). To odpovídá vynásobení P(M|x,y) členem P(M)/P(R). Celý přístup spočívá v porovnání výsledné hodnoty s hodnotou 0. Tak je vyjádřena příbuznost sekvencí.
/P(R)). To odpovídá vynásobení P(M|x,y) členem P(M)/P(R). Celý přístup spočívá v porovnání výsledné hodnoty s hodnotou 0. Tak je vyjádřena příbuznost sekvencí.")
70
Úvod do medicínské informatiky pro Bc. studium
Parametry pro modely Pro použití modelů je třeba stanovit (nastavit) některé parametry: substituční skóre, penalizace mezer, pravděpodobnosti. Odhad pravděpodobností lze provést zjištěním četností zarovnaných párů reziduí a mezer v potvrzených zarovnáních.
 některé parametry: substituční skóre, penalizace mezer, pravděpodobnosti. Odhad pravděpodobností lze provést zjištěním četností. zarovnaných párů reziduí a. mezer. v potvrzených zarovnáních.")
71
Podrobně o skórovacích maticích
Úvod do medicínské informatiky pro Bc. studium Podrobně o skórovacích maticích Slouží k celkovému ohodnocení úspěšnosti zarovnání. Jejich obsah je obvykle vytvořen intuitivně/experimentálně na základě těchto znalostí fyzikálních, chemických, genetických. Sestavení je kompromisem – podobnostní matice.

72
Skórovací podobnostní matice pro sekvence DNA
Úvod do medicínské informatiky pro Bc. studium Skórovací podobnostní matice pro sekvence DNA A T C G 1 A T C G 5 -4 Matice identity Matice BLAST A T C G 1 -5 -1 Tranzitní transverzní matice

73
Matice PAM PAM – Point Accepted Mutation
Úvod do medicínské informatiky pro Bc. studium Matice PAM PAM – Point Accepted Mutation Matice vznikají na základě skutečného výskytu substitucí v přírodě. Sledují se substituce v zarovnaných sekvencích podobných analyzovaným sekvencím.

74
Konstrukce matic BLOSUM
Úvod do medicínské informatiky pro Bc. studium Konstrukce matic BLOSUM Matice jsou odvozeny z množiny zarovnaných bezmezerových regionů z rodin proteinů nazývaných Databáze BLOCKS. Sekvence podstoupily shlukování. Dvě sekvence spadají do stejného shluku v případě, že procento identických reziduí přesáhne jistou úroveň L%.

75
Konstrukce matic BLOSUM
Úvod do medicínské informatiky pro Bc. studium Konstrukce matic BLOSUM Po té jsou vypočítány četnosti Aab pozorování rezidua a v jednom shluku zarovnanného s reziduem b v jiném shluku. Výpočet četnosti je korigován na velikost shluku váhováním každého výskytu hodnotou 1/(n1n2), kde n1 a n2 jsou velikosti příslušných shluků.
, kde n1 a n2 jsou velikosti příslušných shluků.")
76
Konstrukce matic BLOSUM
Úvod do medicínské informatiky pro Bc. studium Konstrukce matic BLOSUM Z četností Aab jsou odhadnuty qa a pab. pro výpočet individuálních skóre: Individuální skóre jsou pak

Podobné prezentace



















