Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Mluvené korpusy: přednosti a limity
Lucie Benešová Ústav Českého národního korpusu

2
osnova – dosavadní zveřejněné korpusy mluveného jazyka v rámci ÚČNK (PMK, BMK, ORAL2006, ORAL2008) – způsob sběru a zpracování dat pro nový chystaný mluvený korpus řady ORAL (×ORAL2006, ORAL2008) – co je možné v mluvených korpusech najít (doklady) – nový stávající sběr dat – vyhledávání v mluvených korpusech
 – co je možné v mluvených korpusech najít (doklady) – nový stávající sběr dat. – vyhledávání v mluvených korpusech.")
3
Pražský mluvený korpus (PMK)
– první korpus mluvené češtiny – zachycuje mluvenou češtinu z oblasti Prahy a jejího okolí – 304 magnetofonových nahrávek z let 1988–1996, velikost slov – zachycuje ve vyvážených proporcích čtyři sociolingvistické proměnné všechny pro jednoduchost dělené pouze binárně (na dvě hodnoty): pohlaví – M/Z – muži/ženy věk – I/V – mladší/starší (spodní hranicí je 20 let, předělem 35 let) vzdělání – A/B – nižší (ZŠ, SŠ)/vyšší (VŠ) vzdělání typ promluvy – F/N – formální/neformální formální promluva – monolog odpovědí na otázky kladené nahrávajícím (pro zamezení ovlivnění odpovědí, ať už kódem spisovným či nespisovným, měly smíšenou povahu nespisovně-spisovnou), týkaly se širokých témat jako škola, mládež, zaměstnání atp., přepisovány ani nahrávány nebyly neformální promluva – spontánní dialog dvou mluvčích
: pohlaví – M/Z – muži/ženy. věk – I/V – mladší/starší (spodní hranicí je 20 let, předělem 35 let) vzdělání – A/B – nižší (ZŠ, SŠ)/vyšší (VŠ) vzdělání. typ promluvy – F/N – formální/neformální. formální promluva – monolog odpovědí na otázky kladené nahrávajícím (pro zamezení ovlivnění odpovědí, ať už kódem spisovným či nespisovným, měly smíšenou povahu nespisovně-spisovnou), týkaly se širokých témat jako škola, mládež, zaměstnání atp., přepisovány ani nahrávány nebyly. neformální promluva – spontánní dialog dvou mluvčích.")
4
Brněnský mluvený korpus (BMK)
– v rámci ČNK první korpus mluvené češtiny z oblasti Moravy – zachycuje autentickou mluvu města Brna – autory jsou pedagogové z FF MU v Brně – 250 magnetofonových nahrávek z let 1994–1999, velikost slov – byl pořizován v souladu se zásadami PMK (stejné sociolingvistické proměnné) – formální otázky byly kladeny ve spisovném kódu (×PMK) – pravidla přepisu odpovídají v základních rysech pravidlům užívaným v PMK × pauzová interpunkce, zachycení simultánnosti dialogických promluv – např. uvedena skutečná výslovnost pod atributem pron, např. česko-moravský rozdíl ve znělosti sme-zme
 – formální otázky byly kladeny ve spisovném kódu (×PMK) – pravidla přepisu odpovídají v základních rysech pravidlům užívaným v PMK × pauzová interpunkce, zachycení simultánnosti dialogických promluv. – např. uvedena skutečná výslovnost pod atributem pron, např. česko-moravský rozdíl ve znělosti sme-zme.")
5
korpus mluveného jazyka ORAL2006
– zachycuje spontánní mluvený jazyk ve výhradně neformálních komunikačních situacích, pouze na území Čech – přepis 221 nahrávek z let 2002–2006, velikost 1 milion slov – charakteristika mluvčích je stejná jako v koncepci PMK, BMK (× informace, v které oblasti mluvčí prožil většinu dětství, cca do 15 let) – nahrávky jsou přepsány tzv. folkloristickou transkripcí – tradiční interpunkce – nezachycuje se suprasegmentální rovina, tj. např. intonace ani další fonetické jevy (např. koncová ztráta znělosti atp.) – přepis se co nejvíc drží běžného standardního zápisu, ale systémové věci se zachycují: – např. sem (=jsem), pudu, já si to vemu (=vezmu), kerej atp. + nářeční jevy typu muskej, zrouna) – k přepisu není zveřejněn zvuk (nezbývá než „trust the text“) – není lemmatizovaný ani morfologicky označkovaný
 – nahrávky jsou přepsány tzv. folkloristickou transkripcí. – tradiční interpunkce. – nezachycuje se suprasegmentální rovina, tj. např. intonace ani další fonetické jevy (např. koncová ztráta znělosti atp.) – přepis se co nejvíc drží běžného standardního zápisu, ale systémové věci se zachycují: – např. sem (=jsem), pudu, já si to vemu (=vezmu), kerej atp. + nářeční jevy typu muskej, zrouna) – k přepisu není zveřejněn zvuk (nezbývá než „trust the text ) – není lemmatizovaný ani morfologicky označkovaný.")
6
korpus mluveného jazyka ORAL2008
– zachycuje opět spontánní mluvený jazyk ve výhradně neformálních komunikačních situacích, pouze na území Čech – 1. mluvený korpus v rámci ÚČNK, který je plně vyvážený v jednotlivých základních sociolingvistických charakteristikách mluvčích – přepis 297 nahrávek z let 2002–2007, velikost 1 milion slov – koncepčně korpus ORAL2008 navazuje na ORAL2006 (tj. např. stejný způsob a pravidla transkripce, stejné dělení na oblasti podle tradičního nářečního členění J. Běliče atp.) – k přepisu rovněž není zveřejněn zvuk – není lemmatizovaný ani morfologicky označkovaný
 – k přepisu rovněž není zveřejněn zvuk. – není lemmatizovaný ani morfologicky označkovaný.")
7
spontánní mluvený jazyk
v návaznosti na práci J. Millera a R. Weinert(ové): Spontaneous spoken language (1998) spontánní mluvená produkce vzniká v reálném čase, bezprostředně, bez možnosti do výsledného produktu zpětně zasahovat mluvčím nepřipravená je limitovaná kapacitou krátkodobé paměti mluvčího i posluchače prototypicky vzniká při bezprostřední interakci s komunikačním partnerem (face-to-face) a v konkrétním situačním kontextu je neoddělitelná od vlastností, jako je přízvuk, rytmus, intonace a další zvukové charakteristiky doprovázena gestikou, mimikou, očním kontaktem, proxémikou a dalšími nonverbálními kódy
: Spontaneous spoken language (1998) spontánní mluvená produkce. vzniká v reálném čase, bezprostředně, bez možnosti do výsledného produktu zpětně zasahovat. mluvčím nepřipravená. je limitovaná kapacitou krátkodobé paměti mluvčího i posluchače. prototypicky vzniká při bezprostřední interakci s komunikačním partnerem (face-to-face) a v konkrétním situačním kontextu. je neoddělitelná od vlastností, jako je přízvuk, rytmus, intonace a další zvukové charakteristiky. doprovázena gestikou, mimikou, očním kontaktem, proxémikou a dalšími nonverbálními kódy.")
8
způsob sběru a zpracování dat pro nový chystaný mluvený korpus ORAL2013
Na jaký typ jazykového materiálu se zaměřujeme: spontánní mluvený jazyk v neformálních komunikačních situacích (tj. ne poloformální, ne formální) nepřipravenost, nepromyšlenost projevu (tj. zcela přirozená běžná spontánní improvizovaná konverzace) dialogičnost (tj. rozhovor dvou a více osob) blízký vzájemný vztah mluvčích – přátelskost/známost bezprostřední kontakt (tj. fyzická přítomnost jednotlivých mluvčích, ne telefonní hovory, hovory přes skype atp.) k charakteristice mluvčích – pouze dospělí (věková hranice min 18 let, tj. žádné děti, ani mládež) – pouze rodilí mluvčí (tj. žádní cizinci) nahráváme mluvčí z celé České republiky (tj. i Moravu, i Slezsko x ORAL2006, ORAL2008)
 nepřipravenost, nepromyšlenost projevu (tj. zcela přirozená běžná spontánní improvizovaná konverzace) dialogičnost (tj. rozhovor dvou a více osob) blízký vzájemný vztah mluvčích – přátelskost/známost. bezprostřední kontakt (tj. fyzická přítomnost jednotlivých mluvčích, ne telefonní hovory, hovory přes skype atp.) k charakteristice mluvčích – pouze dospělí (věková hranice min 18 let, tj. žádné děti, ani mládež) – pouze rodilí mluvčí (tj. žádní cizinci) nahráváme mluvčí z celé České republiky (tj. i Moravu, i Slezsko x ORAL2006, ORAL2008)")
9
organizace a způsob sběru dat
hlavní koordinační centrum a hlavní sběrná oblast pro Prahu – mluvená sekce ÚČNK FF UK v Praze spolupráce s řadou jiných univerzit, kde máme tzv. oblastní koordinátory (Univerzita Hradec Králové, Masarykova univerzita v Brně, Západočeská univerzita v Plzni, nově spolupráce s Univerzitou Palackého v Olomouci a Slezskou univerzitou v Opavě) nahrávající/přepisující = editor koordinátor (vybírá a zaučuje studenty, kontroluje přepisy, příp. vrací, příp. opraví a odevzdá, posílá smlouvy, nese odpovědnost za data z dané sběrné oblasti) koordinátor ÚČNK = superadmin (znovu kontrola, pokud je v pořádku, vyplatíme odměnu, pokud ne, vracíme zpět koordinátorovi)
 nahrávající/přepisující = editor koordinátor (vybírá a zaučuje studenty, kontroluje přepisy, příp. vrací, příp. opraví a odevzdá, posílá smlouvy, nese odpovědnost za data z dané sběrné oblasti) koordinátor ÚČNK = superadmin (znovu kontrola, pokud je v pořádku, vyplatíme odměnu, pokud ne, vracíme zpět koordinátorovi)")
10
maximální možná míra spontaneity
- nejlépe metodou skrytého nahrávání (tzv. clandestine microphone recordings) - aby skutečnost nahrávání neovlivňovala jednotlivé mluvčí (ve výběru jazykových prostředků, ve volbě témat atp.) - mluvčí nejsou PŘEDEM o nahrávání informováni, jsou ale informováni ZPĚTNĚ - tj. tato skutečnost jim musí být sdělena bezprostředně po skončení nahrávání - nutný souhlas mluvčích s použitím pro účely ÚČNK
 - aby skutečnost nahrávání neovlivňovala jednotlivé mluvčí (ve výběru jazykových prostředků, ve volbě témat atp.) - mluvčí nejsou PŘEDEM o nahrávání informováni, jsou ale informováni ZPĚTNĚ - tj. tato skutečnost jim musí být sdělena bezprostředně po skončení nahrávání - nutný souhlas mluvčích s použitím pro účely ÚČNK")
11
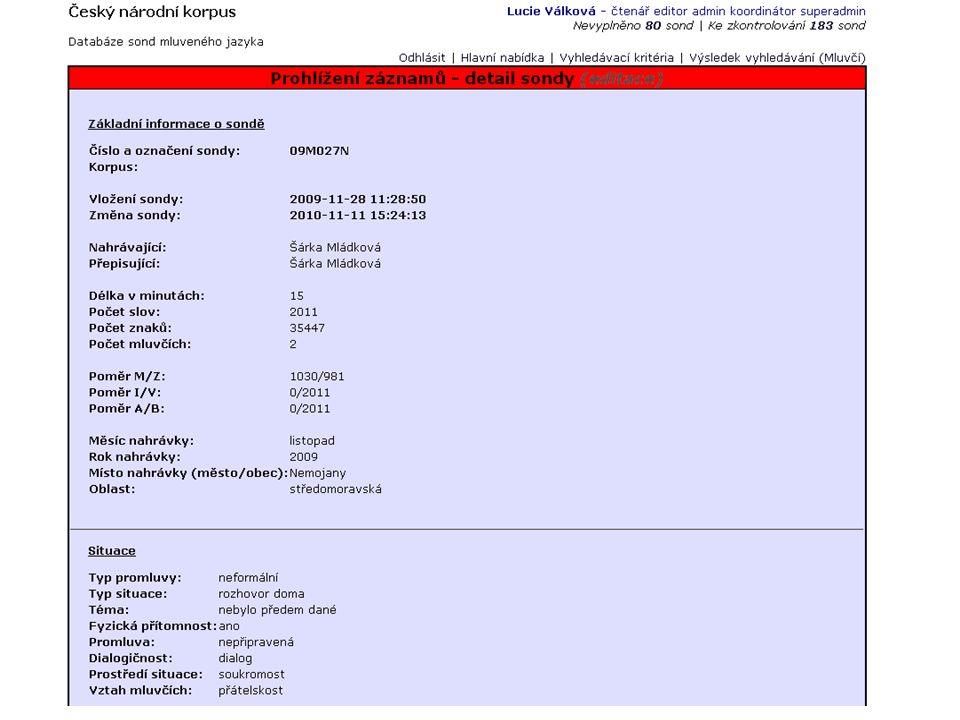
databáze sond mluveného jazyka (Mluvka)
– interní databáze (není veřejně přístupná!) – používá se sice už od r. 2004, ale v nedávné době prošla řadou inovačních procesů – původně byla navržena pro ukládání klíčových informací o komunikační situaci, o jednotlivých mluvčích, pro vkládání nahrávek a přepisů, teď ale poskytuje spoustu užitečných údajů a funkcí navíc – student, který nahraje a následně přepíše rozhovor, zanáší do databáze všechny potřebné údaje o nahrávání a o mluvčích
 – používá se sice už od r. 2004, ale v nedávné době prošla řadou inovačních procesů – původně byla navržena pro ukládání klíčových informací o komunikační situaci, o jednotlivých mluvčích, pro vkládání nahrávek a přepisů, teď ale poskytuje spoustu užitečných údajů a funkcí navíc – student, který nahraje a následně přepíše rozhovor, zanáší do databáze všechny potřebné údaje o nahrávání a o mluvčích")
14
informace k jednotlivým mluvčím
– číselné označení (číslo sondy + číslo mluvčího, 0 vždy označuje nahrávajícího, 1, 2 atd. další mluvčí) – kód mluvčího (automaticky přiřazuje databáze na základě jednotlivých údajů) – pohlaví – věk – vzdělání – místo narození, oblast narození, pobyt v dětství, současný pobyt – zaměstnání (skupiny podle českého statistického úřadu)
 – kód mluvčího (automaticky přiřazuje databáze na základě jednotlivých údajů) – pohlaví. – věk. – vzdělání. – místo narození, oblast narození, pobyt v dětství, současný pobyt. – zaměstnání (skupiny podle českého statistického úřadu)")
15
shodní mluvčí a jejich proznačování
– problém opakování mluvčích, proto jsme omezili max. počet slov na jednoho mluvčího napříč sondami na slov – abychom zabránili chybám a „podvádění“, vyznačujeme je pouze my, a to na základě shody údajů o mluvčím – skript, který vyhledá potenciální shody a navrhne, které mluvčí spojit, pak nutné projít ručně (kontrola poslechem) a vyhodnotit, co je skutečná shoda (přesto někdy velmi obtížné) – bude tedy možné sledovat jazykové jevy v rámci idiolektu jednoho mluvčí
 a vyhodnotit, co je skutečná shoda (přesto někdy velmi obtížné) – bude tedy možné sledovat jazykové jevy v rámci idiolektu jednoho mluvčí")
16
různé fáze rozpracovanosti jednotlivých sond

17
vyhledávácí formulář

18
hlídání vyváženosti jazykového materiálu (na základě sociolingvistických charakteristik mluvčích)
– při vyhledání skupiny sond (podle oblasti, podle roku atp.) databáze zobrazí celkový počet sond, celkový počet slov ve všech vyhledaných sondách, počty slov napříč jednotlivými sociolingvistickými charakteristikami (poměr muži/ženy, mladí/starší, poměr vzdělání nižší/vyšší), věk rozepíše detailněji po dekádách, zastoupení jednotlivých oblastí – to nám umožňuje vyvažovat materiál a ovlivňovat jednotlivé požadavky sbíraného materiálu
 databáze zobrazí celkový počet sond, celkový počet slov ve všech vyhledaných sondách, počty slov napříč jednotlivými sociolingvistickými charakteristikami (poměr muži/ženy, mladí/starší, poměr vzdělání nižší/vyšší), věk rozepíše detailněji po dekádách, zastoupení jednotlivých oblastí – to nám umožňuje vyvažovat materiál a ovlivňovat jednotlivé požadavky sbíraného materiálu")
19
Transcriber pauzová interpunkce v naší koncepci:
speciální přepisovací program, který používáme od r. 2008 umožňuje propojit pořízený zápis se zvukovou stopou četné výhody (opakovaný poslech segmentu, snadná orientace ve zvuku i v přepise, ovládání pomocí klávesových zkratek) částečně řeší i problém, kdy mluvčí mluví přes sebe (umožňuje zachytit dva navzájem se překrývající mluvčí) přepisovací pravidla (největší změny x ORAL2006 a ORAL2008: pauzová interpunkce, zachycení simultánnosti dialogických promluv) pauzová interpunkce v naší koncepci: – krátká pauza je v přepise signalizována jednou tečkou – delší pauza (jako je např. zaváhání, hledání vhodného výrazu, přemýšlení, změna tématu apod.) je v přepise signalizována dvěma tečkami – dlouhá pauza je signalizována poznámkou v závorkách (odmlčení) – pojetí sice velmi subjektivní, ale nelze brát podle absolutní délky v sekundách, resp. zlomcích sekund – každý mluvčí má své individuální mluvní tempo a střední pauza je střední jen vzhledem k rychlosti jeho řeči
 částečně řeší i problém, kdy mluvčí mluví přes sebe (umožňuje zachytit dva navzájem se překrývající mluvčí) přepisovací pravidla (největší změny x ORAL2006 a ORAL2008: pauzová interpunkce, zachycení simultánnosti dialogických promluv) pauzová interpunkce v naší koncepci: – krátká pauza je v přepise signalizována jednou tečkou. – delší pauza (jako je např. zaváhání, hledání vhodného výrazu, přemýšlení, změna tématu apod.) je v přepise signalizována dvěma tečkami. – dlouhá pauza je signalizována poznámkou v závorkách (odmlčení) – pojetí sice velmi subjektivní, ale nelze brát podle absolutní délky v sekundách, resp. zlomcích sekund. – každý mluvčí má své individuální mluvní tempo a střední pauza je střední jen vzhledem k rychlosti jeho řeči.")
20
data pro korpus ORAL2013 sběr probíhal v letech 2008-2011
celkem textových slov 940 nahrávek představující 324 hodin ještě mnoho práce: všechny přepisy se musí spolu se zvukem znovu manuálně projít a opravit ačkoli je materiál „základně“ vyvážený, musí projít náročnějším vyvažovacím procesem

21
co je možné v mluvených korpusech hledat a najít
– všechny dostupné korpusy mluveného jazyka v rámci ÚČNK nejsou morfologicky označkované ani lemmatizované – tj. hledá se v „čistých textech“ – základním výstupem je proto především zadaná konkordance s hledaným tvarem nebo kombinací tvarů slova, omezené použití regulárních výrazů – přesto lze najít v mluvených korpusech spoustu zajímavých jazykových jevů – přepisy korpusů ORAL2006, ORAL2008 velmi dobře reflektují především specifika spontánního autentického mluveného jazyka (ve srovnání s jazykem psaným)
")
22
specifika spontánního mluveného jazyka
– neuspořádanost, menší míra organizovanosti, fragmentárnost, myšlenková a formulační roztříštěnost – kontextualizace (silná vazba ke komunikační situaci a kontextu) – konkrétnost, subjektivnost, emocionalita (souvisí s bezprostředním situačním kontextem mluvčích) – implicitnost, vyšší míra neurčitosti
 – konkrétnost, subjektivnost, emocionalita (souvisí s bezprostředním situačním kontextem mluvčích) – implicitnost, vyšší míra neurčitosti")
23
fragmentárnost, implicitnost, neurčitost
– mluvčí nemůže najít vhodný výraz, užívá spoustu vágních (prázdných) výrazů, pomáhá si deiktickými prostředky (poukazy k situaci, kontextu) – nadměrné používání ukazovacích zájmen (spíše než jako prostředek určitosti, názornosti je výrazem nejistoty a formulačních potíží mluvčího, např. no víš takovej ten...) – významově neurčité výrazy typu ňák, ňákej, takovej, jako – prostřednictvím výrazů a tak, nebo tak, tak ňák vyznívají formulace často do ztracena – častá frekvence neplnovýznamových výrazů (různé částice, citoslovce, konektory, významově vyprázdněné a v kontextu nadbytečné a, no, jo, že jo, no jo no, tak, taky) – vycpávková slova, které jsou typické pro konkrétní idiolekt: prostě, jaksi, vlastně, jako, teda, takže, třeba – opakování výrazů i rozsáhlejších textových úseků, různé opravy, rektifikace, mluvčí se pokouší o jinou a výstižnější formulaci, neustálé doplňování informací
 výrazů, pomáhá si deiktickými prostředky (poukazy k situaci, kontextu) – nadměrné používání ukazovacích zájmen (spíše než jako prostředek určitosti, názornosti je výrazem nejistoty a formulačních potíží mluvčího, např. no víš takovej ten...) – významově neurčité výrazy typu ňák, ňákej, takovej, jako – prostřednictvím výrazů a tak, nebo tak, tak ňák vyznívají formulace často do ztracena – častá frekvence neplnovýznamových výrazů (různé částice, citoslovce, konektory, významově vyprázdněné a v kontextu nadbytečné a, no, jo, že jo, no jo no, tak, taky) – vycpávková slova, které jsou typické pro konkrétní idiolekt: prostě, jaksi, vlastně, jako, teda, takže, třeba – opakování výrazů i rozsáhlejších textových úseků, různé opravy, rektifikace, mluvčí se pokouší o jinou a výstižnější formulaci, neustálé doplňování informací")
24
vybrané doklady DEIXE:
– je to takový n* tady to mám třeba uplně holý jo že to nemám takový vole tady takle takle mi to čouhá – já nejsem ňákej takovej . eee . prtože hele divej se já sem .. takovej už jako .. v tomdletom konzervativec já už nechcu úlet . nebo úlety nějaký jo . i když prostě ně* obrovská škála deiktických výrazů: takovýdlenc, takovejdle, tenhlecten, tadydlecten, tadydlencten, támhlencten atp. SILNÁ NEKOHERENTNOST, ROZTŘÍŠTĚNOST – a takže prostě no .. prostě a to . jo? to je takový .. taková .. pocta OPAKOVÁNÍ VÝRAZŮ – a chtěj . chtěj si hrát . chtěj si hrát a .. – jo normálně na tebe .. to bylo to bylo krásný to bylo .. – bylo to . bylo to prostě .. bylo to špatný no

25
lexikum: frazémy, přirovnání atp.
– to si nepamatuje asi vona byla nadrbaná jak sysel – no hotovo já sem přijel domů eště nakulenej jak sysel .. – no a . takže já sem přijel eště semka v nedělu vole z vopicou na zádech jako kráva .. – my si dáme jednu štyryadvacítku vole a máme kocovinu eště d* vole . krkáme havrany eště třetí tejden vole jo .. – sme šli v sedum ráno spat vole . budíček vole v devět hodin .. já sem nevodevřel málem hubu vole já sem měl v hubě jak v brašně na zmije to bylo šílený – no ale zmatlali sme se tam jak carský důstojníci

26
– akorát teda ty Řekyně mě na nich mrzí to že mají jako chlupatý ruce jak řidič autobusu vole – ale přestaňte honit machry protože prdíte v kině vole .. ve třetí řadě zleva já vám to říkám . hoši poďte na štamprdlu vole . – pak si jich nikdo nevšimne oni si myslí že sou zajímaví vole .. a sou přitom trapní vole jak žížala v oceánu vole .. – v tom plavání ne mě srala ta čepica měl sem to prostě já sem v tom vypadal jak žalud – to když sem slyšel poprvý . to je hochu to je jak když chčiješ na plech – chodíš chcát jak koroptev – mrdlý až na půdu / sou připosraní až na půdu / ta NP mě tam sere uplně až na půdu strašně – má svoje zpětný račí chody – toho mám v paži vole – nechci valit klíny jo ale určitě to tak prostě bude – já už melu hovna

27
obecná čeština a nářeční jazykové jevy
– obecná čeština (např. kerej, vodvážný, takovýdle voči, chtěj, von řek atp.) – řada nářečních jazykových jevů (ORALy reflektují jen Čechy!) morfonologická rovina: – např. muskej, zrouna , k pánoj, ulicej, perkýnko, vo našom, tátovo boty – v chystaném ORALu bude zahrnuta i Morava – např. zešit, žaba, kúsek chleba, čepica, větr, chcu, záda z toho bolijou, jen se ztrapňujú lexikální rovina: – např. rožnout, stolař, květina (x kytka), kokino, bobino, poklúzat, deska (x prkno), sdělat (x sundat), vlézt se (x vejít se), zavazet (x překážet) syntaktická rovina: – např. jít tam to nešel, vidět to jsem viděla, má 17 (x je mu 17)
 – řada nářečních jazykových jevů (ORALy reflektují jen Čechy!) morfonologická rovina: – např. muskej, zrouna , k pánoj, ulicej, perkýnko, vo našom, tátovo boty. – v chystaném ORALu bude zahrnuta i Morava. – např. zešit, žaba, kúsek chleba, čepica, větr, chcu, záda z toho bolijou, jen se ztrapňujú. lexikální rovina: – např. rožnout, stolař, květina (x kytka), kokino, bobino, poklúzat, deska (x prkno), sdělat (x sundat), vlézt se (x vejít se), zavazet (x překážet) syntaktická rovina: – např. jít tam to nešel, vidět to jsem viděla, má 17 (x je mu 17)")
28
stávající sběr dat mluveného jazyka
– zahájen v červenci 2012 (zatím tzv. zkušební sběr) – přepisuje se v jiném přepisovacím programu – ELAN – přepisuje se dvě roviny: ortografická a fonologická – nová přesnější a detailnější přepisovací pravidla – speciální stopy pro metatextové komentáře – špatně srozumitelný úsek – nesrozumitelný úsek – přerušení repliky – anonymizace výhledy: – zachycení suprasegmentálních rysů (intonace, prozodie atp.) – lemmatizace a morfologické značkování
 – přepisuje se v jiném přepisovacím programu – ELAN. – přepisuje se dvě roviny: ortografická a fonologická. – nová přesnější a detailnější přepisovací pravidla. – speciální stopy pro metatextové komentáře. – špatně srozumitelný úsek. – nesrozumitelný úsek. – přerušení repliky. – anonymizace. výhledy: – zachycení suprasegmentálních rysů (intonace, prozodie atp.) – lemmatizace a morfologické značkování.")
30
vyhledávání – konkrétní tvar slova – pomocí regulárních výrazů protetické v – vo.* × o.* (zajímavé příklady typu vochcávka, voser atp.) deminutiva – .*ičk.* „sprostá slova“– prd.* debl.* mrd.* jeb.* šuk.* kurev.* posr.* zasr.* ... .*ojc děsn.* strašn.* hrozn.* takov.* .*zej.* (negativní filtr zejtra) vocaď, votud, odtaď, odtud, votaď, vodsaď
 deminutiva – .*ičk.* „sprostá slova – prd.* debl.* mrd.* jeb.* šuk.* kurev.* posr.* zasr.* ... .*ojc děsn.* strašn.* hrozn.* takov.* .*zej.* (negativní filtr zejtra) vocaď, votud, odtaď, odtud, votaď, vodsaď")
Podobné prezentace














 1999. Tralvex Yeap. All Rights Reserved.>")






