Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Základy informatiky přednášky Bezpečnostní kódy

2
ZÁKLADY INFORMATIKY – Bezpečnostní kódy
Vznik a vývoj teorie informace Matematický aparát v teorii informace Základy teorie pravděpodobnosti – Náhodné veličiny Číselné soustavy Informace Základní pojmy – jednotka a zobrazení informace, informační hodnota Entropie – vlastnosti entropie Zdroje zpráv – spojité zdroje zpráv, diskrétní zdroje zpráv Přenos informace – vlastnosti přenosu kanálů, poruchy a šumy přenosu, způsoby boje proti šumu Kódování Elementární teorie kódování Rovnoměrné kódy – telegrafní kód Nerovnoměrné kódy – Morseova abeceda, konstrukce nerovnoměrných kódů Efektivní kódy – Shannonova – Fanova metoda, Hoffmanova metoda Bezpečností kódy Zabezpečující schopnosti kódů, Systematické kódy, Nesystematické kódy

3
V reálném životě často dochází při přenosu zakódovaných informací k chybám způsobeným šumem prostředí (přenosového kanálu). V každé oblasti přenosu a zpracovaní diskrétních informací se proto postupně stabilizuje používání určitých kódů, které se ukazují jako nejvýhodnější z hlediska kompromisu mezi: a) stupněm zabezpečení proti chybám b) jednoduchostí (efektivností) c) cenou realizace příslušných zařízení Snažíme se tedy najít kód, který má co nejkratší délku a přitom opravuje co největší počet chyb.
 stupněm zabezpečení proti chybám. b) jednoduchostí (efektivností) c) cenou realizace příslušných zařízení. Snažíme se tedy najít kód, který má co nejkratší délku a přitom opravuje co největší počet chyb.")
4
Každé kódové slovo představuje bod v signálním prostoru
Každé kódové slovo představuje bod v signálním prostoru. V důsledku rušivých vlivů se tento bod vysune do jiné polohy. Při náhodném charakteru rušivých vlivů se poloha tohoto bodu neustále mění – tvoří soustavu bodů kolem původního místa. Rozložení náhodných poruch - GAUSSOVO rozdělení. Z předchozího vyplývá –> pravděpodobnost chybného přenosu zprávy se zmenší vzdálením jednotlivých symbolů množiny signálů. To lze zajistit tak, že vyjádříme signálové symboly nějakým kódem a pak je vzdálíme od sebe vložením dalších míst do každého kódového slova.

5
bezpečnostní kódování (kódové zabezpečení)
Opatření, která provádíme pro zvýšení odolnosti kódových slov proti vlivům poruch bezpečnostní kódování (kódové zabezpečení) Snížení výskytu chyb při přenosu dat je možné zabezpečit několika způsoby: Bez zabezpečovacích zařízení - tj. úpravou zprávy, velice účinný způsob ochrany, nevyžaduje žádná přídavná zařízení S pomocí zabezpečovacích zařízení tj.bezpečnostní kódy – systematické, nesystematické kódy Kontrolou kvality signálu - tj. při vybočení sledovaného parametru signálu z tolerance se žádá o opakované zaslání posledního bloku dat
 Snížení výskytu chyb při přenosu dat je možné zabezpečit několika způsoby: Bez zabezpečovacích zařízení - tj. úpravou zprávy, velice účinný způsob ochrany, nevyžaduje žádná přídavná zařízení. S pomocí zabezpečovacích zařízení tj.bezpečnostní kódy – systematické, nesystematické kódy. Kontrolou kvality signálu - tj. při vybočení sledovaného parametru signálu z tolerance se žádá o opakované zaslání posledního bloku dat.")
6
Ad 1) Bez zabezpečovacích zařízení
Nejjednodušším způsobem snížení chybnosti je zvýšení redundance (nadbytečnosti) zprávy = opakování každého kódového slova. Příklad: Pro přenesení binárního kódového slova 10 použijeme opakování třikrát za sebou. Vysíláme tedy kódové slovo (při takovém přenosu je možné opravit jednu chybu) Maximální délka kódu při šestimístném kódovém slově je dána L=26=64. Informaci však nesou pouze 2 místa a další čtyři jsou zabezpečující, tzn. LZ=22=4. Poměr zkrácené a maximální délky kódu = v y u ž i t í k ó d u
 zprávy = opakování každého kódového slova. Příklad: Pro přenesení binárního kódového slova 10 použijeme opakování třikrát za sebou. Vysíláme tedy kódové slovo (při takovém přenosu je možné opravit jednu chybu) Maximální délka kódu při šestimístném kódovém slově je dána L=26=64. Informaci však nesou pouze 2 místa a další čtyři jsou zabezpečující, tzn. LZ=22=4. Poměr zkrácené a maximální délky kódu = v y u ž i t í k ó d u.")
7
5 4 3 2 1 5 U číselných položek se používá úprava kontrolním součtem.
Příklad: Chceme-li přenést číslo sečteme =15, poslední číslici přidáme k původnímu číslu a pak přenášíme číslo Maximální délka kódu při šestimístném kódovém slově je dána L=106. Informaci nese prvních 5 míst a poslední místo je zabezpečující, tzn. LZ=105.

8
Příklad: Přeneste dvoumístné kódové slovo vyjádřené desítkovou číselnou soustavou. Použijte přenesení se zabezpečením pomocí dvojnásobného opakování. Jaké je využití tohoto kódu. Řešení: Maximální délka kódu pro čtyřmístné dekadické kódové slovo je dána L=104. Informaci však nesou pouze 2 místa a další 2 jsou zabezpečující, tzn. LZ=102. Poměr zkrácené a maximální délky kódu = v y u ž i t í k ó d u

9
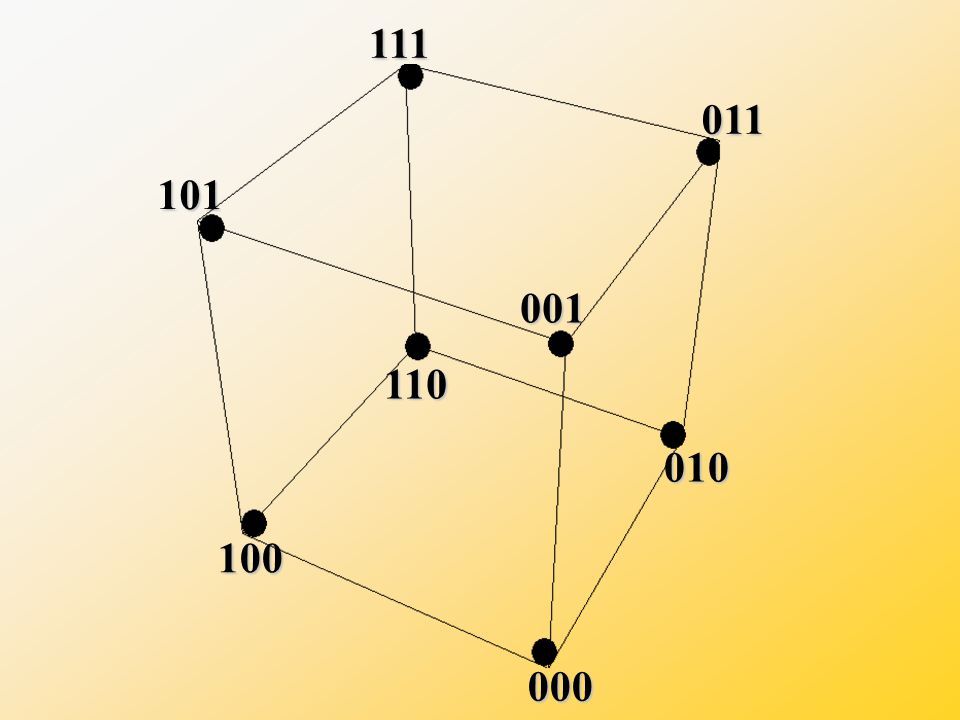
Geometrický model kódu
je výhodný pro odvození zabezpečujících vlastností kódu umožňuje názorné odvození vzdálenosti kódových slov, která je rozhodující pro určení počtu chyb, které je možno objevit popř. opravit m-místný binární kód (2m kódových slov) lze znázornit pomocí m-rozměrné krychle - HAMMING nejvýhodnější je představa pro 3-místný binární kód (délka kódu je 23=8) KRYCHLE HAMMINGOVA KOSTKA
 lze znázornit pomocí m-rozměrné krychle - HAMMING. nejvýhodnější je představa pro 3-místný binární kód (délka kódu je 23=8) KRYCHLE. HAMMINGOVA KOSTKA.")
10
111 011 101 001 110 010 100 000
11
Vzdálenost kódových slov
můžeme názorně odvodit z geometrického modelu kódu je dána počtem hran, které spojují jednotlivá kódová slova je rovna počtu znaků, ve kterých se dvě kódová slova liší Je označována jako tzv. Hammingova vzdálenost - d Geometrická interpretace viz následující obrázky

12
Hammingova vzdálenost d = 1
111 011 101 001 délka hrany krychle a = 1 poloměr opsané koule r = 1 kombinační číslo počet vrcholů ležících na opsané kouli 110 010 100 000

13
Hammingova vzdálenost d = 2
111 011 101 001 délka hrany krychle a = 1 poloměr opsané koule r = kombinační číslo počet vrcholů ležících na opsané kouli 110 010 100 000

14
Hammingova vzdálenost d = 3
111 011 101 001 délka hrany krychle a = 1 poloměr opsané koule r = kombinační číslo počet vrcholů ležících na opsané kouli 110 010 100 000

15
Detekční a korekční schopnosti kódu
Příklad: Mějme dvojkový 3-místný kód. Sledujte jaký vliv na zabezpečující vlastnosti kódu má velikost Hammingovy vzdálenosti. Maximální délka dvojkového 3-místného kódu – L = 23 = 8 (viz Hammingova kostka) kód využijeme celý (každé kódové slovo nese informaci d=1) – takový kód neumožňuje registrovat chybu využijeme jen kódová slova o d=2 (např. 000, 101, 110, 011) – takový kód umožňuje detekovat chybu využijeme jen kódová slova o d=3 (např. 000, 111) – takový kód umožňuje detekovat i opravit chybu Demonstrace viz předchozí obrázky
 kód využijeme celý (každé kódové slovo nese informaci d=1) – takový kód neumožňuje registrovat chybu. využijeme jen kódová slova o d=2 (např. 000, 101, 110, 011) – takový kód umožňuje detekovat chybu. využijeme jen kódová slova o d=3 (např. 000, 111) – takový kód umožňuje detekovat i opravit chybu. Demonstrace viz předchozí obrázky.")
16
Pod detekčními schopnostmi kódu rozumíme schopnost kódu objevovat - detekovat chyby vzniklé při přenosu informací. Z předchozího příkladu vyplývá, že kód objevuje (detekuje) -násobné chyby, když platí: Pod pojmem korekční schopnosti kódu rozumíme schopnost kódu chyby objevené při přenosu i opravit - korigovat. Z předchozího příkladu vyplývá, abychom mohli opravit (korigovat) -násobnou chybu, musí platit:
 -násobné chyby, když platí: Pod pojmem korekční schopnosti kódu rozumíme schopnost kódu chyby objevené při přenosu i opravit - korigovat. Z předchozího příkladu vyplývá, abychom mohli opravit (korigovat) -násobnou chybu, musí platit:")
17
Příklad: Jaké jsou detekční a korekční schopnosti kódu s minimální Hammingovou vzdáleností d = 3.

18
(můžeme objevit 4 chyby a dvě chyby můžeme opravit)
Příklad: Uvažujte opakovací kód. Sledujte detekční a korekční schopnosti tohoto kódu. Opakovací kód - přenášený znak se vyšle vícekrát (lichý počet krát - např. 5). Pro dekódování se pak uplatňuje většinové zastoupení (větší počet stejných znaků je uznán jako přijatý znak). kódování přenos dekódování 1 11111 10101 1 Zdrojové slovo Kódové slovo Přijaté slovo znak šum d= → = 4 = 2 (můžeme objevit 4 chyby a dvě chyby můžeme opravit)
. Pro dekódování se pak uplatňuje většinové zastoupení (větší počet stejných znaků je uznán jako přijatý znak). kódování. přenos. dekódování Zdrojové slovo. Kódové slovo. Přijaté slovo. znak. šum. d=5 → = 4 = 2. (můžeme objevit 4 chyby a dvě chyby můžeme opravit)")
19
Hammingova váha kódového slova
Je definována jako součet nenulových míst dvojkové posloupnosti tvořící kódové slovo. Lze jí tedy zapsat ve tvaru: Příklad: Uvažujte kódové slovo ve tvaru Ck = Jaká je Hammingova váha takového kódového slova.

20
Distribuce chybových míst v kódovém slově
Máme-li m-místné kódové slovo a z toho je k míst zasaženo rušením (je chybných) pak existuje právě N možností výskytu chybových míst v kódovém slově. Celkový počet možností nulové až m-násobné chyby můžeme vyjádřit vztahem:
 pak existuje právě N možností výskytu chybových míst v kódovém slově. Celkový počet možností nulové až m-násobné chyby můžeme vyjádřit vztahem:")
21
Nechť pro výskyt chyby platí pravděpodobnost p a pravděpodobnost (1-p) pro ostatní místa složky. Pak pravděpodobnost, že na k místech kódové složky se vyskytne chyba, a na (m - k) místech nikoli, bude: Protože však počet možností výskytu k-násobné chyby je dáno kombinačním číslem m nad k, platí pro pravděpodobnost výskytu k-násobné chyby: Označíme-li pravděpodobnost vzniku chyby na jednom místě kódového slova pch1, pravděpodobnost vzniku chyby na dvou místech pch2 a analogicky pravděpodobnost vzniku chyby na n místech pchn pak platí nerovnost pch1 > pch2 > ...> pchn

22
Příklad: Mějme pětimístné kódové slovo (m=5) a sledujme pravděpodobnost vzniku dvoumístné chyby (k=2). Výskyt chyby je dán pravděpodobností p a pravděpodobností (1 - p) je dán správný přenos ostatních míst. Řešení: Počet všech kombinací pro dvě chyby je dán kombinačním číslem: Pravděpodobnost výskytu dvojnásobné chyby je pak dána:
 a sledujme pravděpodobnost vzniku dvoumístné chyby (k=2). Výskyt chyby je dán pravděpodobností p a pravděpodobností (1 - p) je dán správný přenos ostatních míst. Řešení: Počet všech kombinací pro dvě chyby je dán kombinačním číslem: Pravděpodobnost výskytu dvojnásobné chyby je pak dána:")
23
Příklad: Stanovte pravděpodobnost bezchybného přenosu a dále pravděpodobnost výskytu 1, 2, 3, 4-násobné chyby v čtyřmístém kódovém slově. Pravděpodobnost chyby je dána p=0.2 a tedy (l - p) = 0.8 Pozn: Pravděpodobnost přechodu z nuly na jedničku a naopak (tedy pravděpodobnost chyby) může mít různou hodnotu (v příkladu jsme volili p = 0.2), musí však platit 0 < p < 0.5. (Pro hodnotu p = 0.5 klesá kapacita kanálu C na nulu)
 může mít různou hodnotu (v příkladu jsme volili p = 0.2), musí však platit 0 < p < 0.5. (Pro hodnotu p = 0.5 klesá kapacita kanálu C na nulu)")
Podobné prezentace


![Komplexní čísla. Komplexní číslo je uspořádaná dvojice [x, y], kde číslo x představuje reálnou část a číslo y imaginární část. Pokud je reálná část nulová,](/7/1931417/big_thumb.jpg "Komplexní čísla. Komplexní číslo je uspořádaná dvojice [x, y], kde číslo x představuje reálnou část a číslo y imaginární část. Pokud je reálná část nulová,>")

 o informacích, tj. o zápisu (kódování (angl.)), přenosu (transfer (angl.)), zpracování (procesování (angl.)) informací.>")














