Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Měření asociací v epidemiologických studiích
Marek Malý

2
Individuální a skupinová data
Klinický přístup (=individuální) Lékař vždy léčí konkrétního pacienta, ale každý pacient se podstatným způsobem v mnoha rysech liší od jiných pacientů Skupinový přístup Vzhledem k velké variabilitě biologického materiálu nevyplývá z jednoho pozorování žádná obecná informace. Nutno popsat a porovnat rozložení dat u skupin osob.
 Lékař vždy léčí konkrétního pacienta, ale každý pacient se podstatným způsobem v mnoha rysech liší od jiných pacientů. Skupinový přístup. Vzhledem k velké variabilitě biologického materiálu nevyplývá z jednoho pozorování žádná obecná informace. Nutno popsat a porovnat rozložení dat u skupin osob.")
3
Epidemiologie Zabývá se studiem a kvantifikací výskytu nemocí ve skupinách lidí. Soustřeďuje se na vyhodnocování hypotéz o příčinách nemocí a hledá souvislosti mezi výskytem nemoci a charakteristikami osob a jejich životního prostředí.

4
Kroky při realizaci studie
Formulace teoretického problému Formulace pracovních hypotéz Stanovení primárních a sekundárních cílů studie Rozhodnutí o cílové a studované populaci, opora výběru Plán studie, rozsah výběru Rozhodnutí o technice sběru informací Konstrukce nástrojů pro tento sběr (dotazníky, …) Pilotní studie / Předvýzkum Sběr dat Vkládání dat do počítače, kontrola chyb Vlastní analýza dat Interpretace, závěry, případné zobecnění
 Pilotní studie / Předvýzkum. Sběr dat. Vkládání dat do počítače, kontrola chyb. Vlastní analýza dat. Interpretace, závěry, případné zobecnění.")
5
Typy epidemiologických studií
OBSERVAČNÍ (POZOROVACÍ) [DESKRIPTIVNÍ, ANALYTICKÉ] popisy jednotlivých případů či série případů ekologické studie průřezové studie studie případů a kontrol kohortové studie INTERVENČNÍ (EXPERIMENTÁLNÍ) klinické studie terénní intervenční studie
 [DESKRIPTIVNÍ, ANALYTICKÉ] popisy jednotlivých případů či série případů. ekologické studie. průřezové studie. studie případů a kontrol. kohortové studie. INTERVENČNÍ (EXPERIMENTÁLNÍ) klinické studie. terénní intervenční studie.")
6
Typy jevů a proměnných Kvantitativní (numerické)
diskrétní (zpravidla celočíselné - počty) spojité (jakákoli hodnota v určitém rozsahu je možná; omezení dáno jen přesností měření) Kvalitativní (kategoriální) binární (dvě kategorie; ano-ne) nominální (několik kategorií bez uspořádání) ordinální (několik kategorií s uspořádáním)
 spojité (jakákoli hodnota v určitém rozsahu je možná; omezení dáno jen přesností měření) Kvalitativní (kategoriální) binární (dvě kategorie; ano-ne) nominální (několik kategorií bez uspořádání) ordinální (několik kategorií s uspořádáním)")
7
Základní cíle observačních studií
Popis frekvence výskytu onemocnění: incidence, prevalence Zkoumání vztahu mezi dvěma proměnnými Expozice (rizik. faktor): ano x ne, příp. ordinální či spojitá vel. Následek (onemocnění): ano x ne, příp. ordinální veličina Ukazatele asociace (síly vztahu): RR, OR, AR, SMR Testy hypotéz o síle asociace Otázky o kauzalitě Faktory ovlivňující správnou interpretaci zjištěné asociace zkreslení (bias) zavádějící faktor (confounder) – „třetí proměnná“ náhoda (chance)
: ano x ne, příp. ordinální či spojitá vel. Následek (onemocnění): ano x ne, příp. ordinální veličina. Ukazatele asociace (síly vztahu): RR, OR, AR, SMR. Testy hypotéz o síle asociace. Otázky o kauzalitě. Faktory ovlivňující správnou interpretaci zjištěné asociace. zkreslení (bias) zavádějící faktor (confounder) – „třetí proměnná náhoda (chance)")
8
Podíl, měra, míra Podíl, proporce, rel. četnost (proportion)
bezrozměrný podíl, v němž čitatel je součástí jmenovatele, odhaduje riziko podíl počtu chlapců v celk. počtu narozených dětí Poměr (ratio) čitatel není součástí jmenovatele; má rozměr poměr počtu narozených dívek k počtu narozených chlapců Míra (rate) speciální forma podílu zahrnující specifikaci času počet úmrtí na součet osobočasů v riziku
 čitatel není součástí jmenovatele; má rozměr. poměr počtu narozených dívek k počtu narozených chlapců. Míra (rate) speciální forma podílu zahrnující specifikaci času. počet úmrtí na součet osobočasů v riziku.")
9
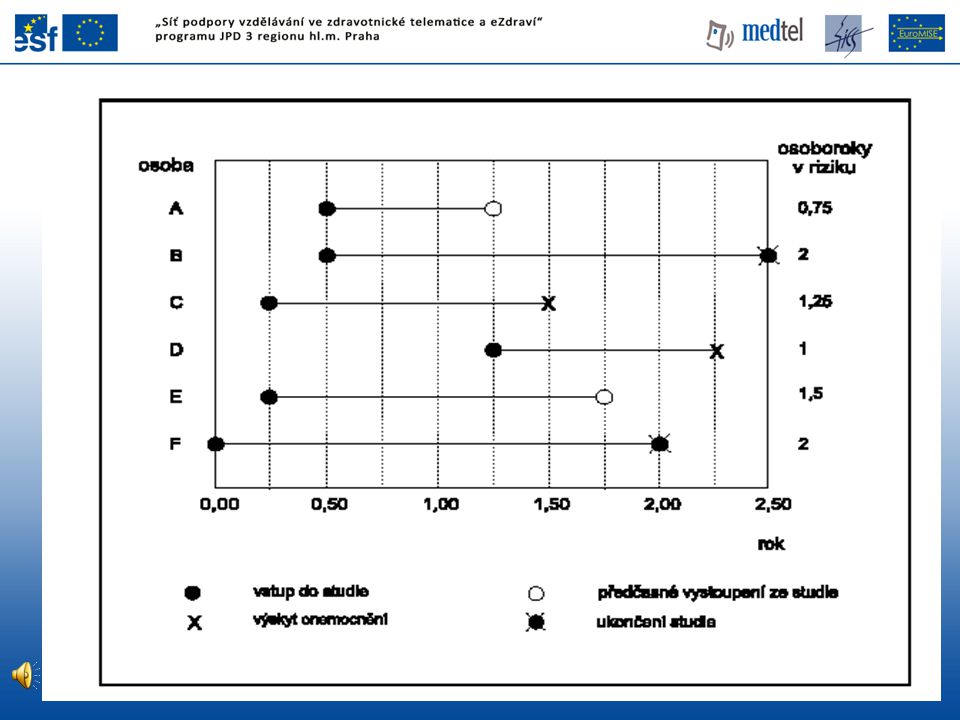
Koncepce osoba-čas (Person-years)
za každou osobu se do ukazatele přičte příspěvek odpovídající délce jejího sledování – „době strávené v riziku“ (ve dnech, v rocích) 12 osob sledovaných po dobu 1 měsíce přispívá stejně jako 1 osoba sledovaná 1 rok u velké populace zhruba stejné jako: průměrná velikost populace x délka sledování významná úloha ve jmenovateli, kde mají být jen osoby „v riziku“
 12 osob sledovaných po dobu 1 měsíce přispívá stejně jako 1 osoba sledovaná 1 rok. u velké populace zhruba stejné jako: průměrná velikost populace x délka sledování. významná úloha ve jmenovateli, kde mají být jen osoby „v riziku")
11
Měření frekvence nemoci
požadavek kvantifikace výskytu nemoci je v epidemiologickém sledování klíčový je třeba znát absolutní počet nemocných velikost populace, z níž nemocní pocházejí časové období, ve kterém byly údaje shromážděny ukazatelé četnosti (frekvence) nemoci - tzv. ukazatelé nemocnosti - jsou tedy mírou množství nemoci v určitém místě a čase; zpravidla se vyjadřují jako procento či na 1000, resp obyvatel
 nemoci - tzv. ukazatelé nemocnosti - jsou tedy mírou množství nemoci v určitém místě a čase; zpravidla se vyjadřují jako procento či na 1000, resp obyvatel.")
12
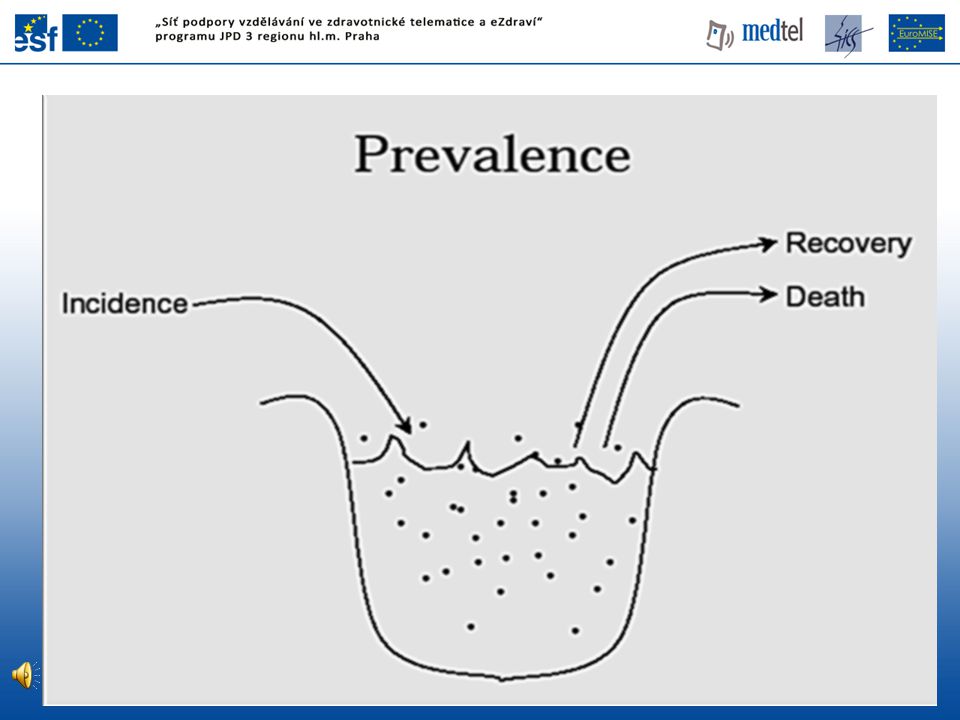
Prevalence a incidence
Incidence charakterizuje, kolik nových případů se objevilo v populaci v daném časovém intervalu (často roce); vlastně je ukazatelem dynamiky onemocnění, rychlosti nárůstu Prevalence informuje o úrovni nemocnosti v určitém okamžiku, popisuje podíl případů nemoci existujících např. v daném dni (okamžitá), případně měsíci atp. (intervalová) Ukazatele se vztahují na počet exponovaných osob, resp. na součet období, po která byly osoby sledovány (osobočas)
; vlastně je ukazatelem dynamiky onemocnění, rychlosti nárůstu. Prevalence informuje o úrovni nemocnosti v určitém okamžiku, popisuje podíl případů nemoci existujících např. v daném dni (okamžitá), případně měsíci atp. (intervalová) Ukazatele se vztahují na počet exponovaných osob, resp. na součet období, po která byly osoby sledovány (osobočas)")
13
Prevalence a incidence
počet všech osob se zkoumaným onemocněním ve studované populaci v daném okamžiku (Okamžitá) prevalence = počet osob v populaci ve stejném okamžiku počet případů onemocnění, které se vyskytly ve studované populaci v daném časovém intervalu Intervalová prevalence = součet osobočasů v populaci ve stejném časovém intervalu počet nově zjištěných případů onemocnění Incidence = střední stav studované populace
 prevalence = počet osob v populaci ve stejném okamžiku. počet případů onemocnění, které se vyskytly. ve studované populaci v daném časovém intervalu. Intervalová prevalence = součet osobočasů v populaci ve stejném. časovém intervalu. počet nově zjištěných případů onemocnění. Incidence = střední stav studované populace.")
15
Incidence a prevalence
Změna incidence odráží změnu v etiologických faktorech (rizikových, protektivních) Změna prevalence odráží změnu v incidenci, v délce trvání onemocnění či v obojím Úroveň prevalence závisí na zakončení nemoci (uzdravení, úmrtí) Pokud jsou prevalence, incidence i délka stabilní a prevalence < 10 %, platí přibližně prevalence incidence prům. délka onemocnění
 Změna prevalence odráží změnu v incidenci, v délce trvání onemocnění či v obojím. Úroveň prevalence závisí na zakončení nemoci (uzdravení, úmrtí) Pokud jsou prevalence, incidence i délka stabilní a prevalence < 10 %, platí přibližně. prevalence incidence prům. délka onemocnění.")
16
Průřezová studie

17
Průřezová studie Výběr jedinců do studie probíhá k jednomu časovému okamžiku - obecně bez znalosti expozice a nemoci Může zjišťovat prevalenci jak expozice tak nemoci Vhodné zejména pro nemoci, které nejsou rychle fatální, nevhodné pro vzácné nemoci či expozice Relativně snadný sběr dat, relativně levné Citlivé vzhledem ke zkreslení (bias) Nelze stanovit, zda byla dříve expozice či nemoc (kauzalita)
 Nelze stanovit, zda byla dříve expozice či nemoc (kauzalita)")
18
Průřezová studie - příklady
NHANES (National Health and Nutrition Examination Survey) MONICA
 MONICA.")
19
Kohortová studie

20
Kohortová studie PRINCIP: Vytvoření skupin na základě údaje o expozici a kompletní dlouhodobé sledování všech skupin (follow-up) stejným způsobem; možno sledovat (v podobě incidence) celé spektrum následků jedné expozice (více nemocí) Na začátku zařazeny jen osoby bez onemocnění Organizace studie: prospektivní, retrospektivní (historická) Nejúplnější a flexibilní popis vývoje od expozice k nemoci Může objasnit časové souvislosti mezi expozicí a nemocí, zachytit dynamiku vzniku zkoumané závislosti Vhodné pro vzácně se vyskytující expozice (příčiny) Odolnost vůči výběrovému zkreslení Naprosto nevhodná pro nemoci se vzácným výskytem Velké finanční a časové nároky Validitu narušují ztráty jedinců ze sledování
 stejným způsobem; možno sledovat (v podobě incidence) celé spektrum následků jedné expozice (více nemocí) Na začátku zařazeny jen osoby bez onemocnění. Organizace studie: prospektivní, retrospektivní (historická) Nejúplnější a flexibilní popis vývoje od expozice k nemoci. Může objasnit časové souvislosti mezi expozicí a nemocí, zachytit dynamiku vzniku zkoumané závislosti. Vhodné pro vzácně se vyskytující expozice (příčiny) Odolnost vůči výběrovému zkreslení. Naprosto nevhodná pro nemoci se vzácným výskytem. Velké finanční a časové nároky. Validitu narušují ztráty jedinců ze sledování.")
21
Kohortová studie Nemoc Expozice ano ne Celkem a b a+b c d c+d a+c b+d
n=a+b+c+d

22
Kohortová studie Nemoc Expozice ano ne Osobočas a - PY1 c PY0 Celkem
a+c T=PY1+PY0

23
Kohortová studie - příklady
Studie britských lékařů Studie horníků uranových dolů Framinghamská studie

24
Studie případů a kontrol

25
Studie případů a kontrol
PRINCIP: porovnání podílu osob exponovaných zkoumanému (rizikovému) faktoru ve skupině nemocných (PŘÍPADY) a zdravých (KONTROLY) Vhodné pro studium incidence nemocí vzácných a s dlouhou latencí Lze studovat více potenciálních příčin nemoci Založeno na popisu expozice v minulosti – potenciálně nepřesné záznamy či vzpomínky - zkreslení Neúplná kontrola vlivu dalších proměnných Často obtížná volba kontrolní skupiny, ta přitom podstatně ovlivňuje validitu Nelze přímo popsat incidenci mezi exponovanými a neexponovanými
 faktoru ve skupině nemocných (PŘÍPADY) a zdravých (KONTROLY) Vhodné pro studium incidence nemocí vzácných a s dlouhou latencí. Lze studovat více potenciálních příčin nemoci. Založeno na popisu expozice v minulosti – potenciálně nepřesné záznamy či vzpomínky - zkreslení. Neúplná kontrola vlivu dalších proměnných. Často obtížná volba kontrolní skupiny, ta přitom podstatně ovlivňuje validitu. Nelze přímo popsat incidenci mezi exponovanými a neexponovanými.")
26
Studie případů a kontrol
n=a+b+c+d b+d a+c Celkem c+d d c ne a+b b a ano KONTROLA PŘÍPAD Expozice Status

27
Studie případů a kontrol - příklady
Kouření a rakovina plic (Doll, Hill, BMJ 1950) Alkohol a rakovina jícnu (viz Breslow, Day I, 1980) Hormonální antikoncepce a infarkt myokardu (Rosenberg, Am. J. Epidemiol. 1980) Konzumace kávy a rakovina slinivky břišní (MacMahon, NEJM, 1981)
 Alkohol a rakovina jícnu (viz Breslow, Day I, 1980) Hormonální antikoncepce a infarkt myokardu (Rosenberg, Am. J. Epidemiol. 1980) Konzumace kávy a rakovina slinivky břišní (MacMahon, NEJM, 1981)")
28
Vztah kohortové studie ke studii případů a kontrol
Studie případů a kontrol často slouží k prvnímu prověření hypotézy a z nich vycházejí podrobnější a přesnější kohortové studie. V tzv. vnořené studii případů a kontrol (nested case-control study) jsou případy a kontroly vybírány z již existující kohorty, a je pro ně proto k dispozici základní informace o expozici rizikovým faktorům. Detaily se pak dohledávají jen pro menší počet jedinců zařazených ve vnořené studii (zejména se redukuje počet zdravých), což je výhodné zvláště tehdy, když je dohledání nákladné. Studie případů v kohortě (case-cohort study) je založena na analýze dat osob ze subkohorty (vybrané v úvodu kohortové studie) a všech případů onemocnění.
 jsou případy a kontroly vybírány z již existující kohorty, a je pro ně proto k dispozici základní informace o expozici rizikovým faktorům. Detaily se pak dohledávají jen pro menší počet jedinců zařazených ve vnořené studii (zejména se redukuje počet zdravých), což je výhodné zvláště tehdy, když je dohledání nákladné. Studie případů v kohortě (case-cohort study) je založena na analýze dat osob ze subkohorty (vybrané v úvodu kohortové studie) a všech případů onemocnění.")
29
UKAZATELE ASOCIACE Relativní riziko Poměr šancí Atributivní riziko
Standardizovaný úmrtnostní index (SMR)
")
30
(ABSOLUTNÍ) RIZIKO RIZIKO (RISK) - pravděpodobnost výskytu sledovaného jevu; odhadujeme ji pomocí relativní četnosti (počet nemocných ku počtu všech osob ve skupině); mezi 0 a 1 V exponované skupině: R1=a/(a+b) V neexponované skupině: R2=c/(c+d)
 - pravděpodobnost výskytu sledovaného jevu; odhadujeme ji pomocí relativní četnosti (počet nemocných ku počtu všech osob ve skupině); mezi 0 a 1. V exponované skupině: R1=a/(a+b) V neexponované skupině: R2=c/(c+d)")
31
Bakteriální infekce močových cest
Kohortová studie Bakteriální infekce močových cest Orální antikoncepce ano ne Celkem 27 455 482 77 1831 1908 104 2286 2390 R1 = 27 / 482 = 0,056 R2 = 77 / 1908 = 0,040 RR = R1 / R2 = 1,39 95% CI: (0,91; 2,13) χ2 = 2,27; p=0,132
 χ2 = 2,27; p=0,132.")
32
Interpretace intervalu spolehlivosti
Interval spolehlivosti pro RR lze použít při testování významnosti: testuje se H0: RR=1 (hodnota 1 odpovídá tomu, že není žádný rozdíl v riziku onemocnění mezi exponovanou a neexponovanou populací). Pokud hodnota 1 není pokryta 100(1-α)% intervalem spolehlivosti, nulovou hypotézu lze zamítnout na hladině α [např. 95% CI, α=0,05], v opačném případě H0 nezamítáme. Oproti p-hodnotě získáme navíc představu o přesnosti odhadu parametru a o tom, zda rozsah výběru byl dostatečně veliký.
. Pokud hodnota 1 není pokryta 100(1-α)% intervalem spolehlivosti, nulovou hypotézu lze zamítnout na hladině α [např. 95% CI, α=0,05], v opačném případě H0 nezamítáme. Oproti p-hodnotě získáme navíc představu o přesnosti odhadu parametru a o tom, zda rozsah výběru byl dostatečně veliký.")
33
Relativní riziko poměr rizika onemocnění v exponované a v neexponované populaci ukazatel asociace odhadující sílu vazby mezi expozicí a nemocí vyjadřuje, kolikrát je větší riziko následku u exponovaných v porovnání s neexponovanými RR může nabývat hodnot mezi 0 a nekonečnem RR=1 .. není vztah mezi expozicí a následkem RR>1 .. pozitivní vztah RR<1 .. inverzní vztah (expozice chrání před následkem)
")
34
Relativní riziko RR

35
Šance (ODDS) ŠANCE (ODDS) - poměr pravděpodobnosti, že ke sledovanému jevu došlo, vzhledem k pravděpodobnosti, že k tomuto jevu nedošlo (počet nemocných ku počtu zdravých); mezi 0 a nekonečnem V exponované skupině: [a/(a+b)] / [b/(a+b)]=a/b V neexponované skupině: [c/(c+d)] / [d/(c+d)]=c/d
 - poměr pravděpodobnosti, že ke sledovanému jevu došlo, vzhledem k pravděpodobnosti, že k tomuto jevu nedošlo (počet nemocných ku počtu zdravých); mezi 0 a nekonečnem. V exponované skupině: [a/(a+b)] / [b/(a+b)]=a/b. V neexponované skupině: [c/(c+d)] / [d/(c+d)]=c/d.")
36
Studie případů a kontrol
Infarkt myokardu Orální antikoncepce ano (případ) ne (kontrola) Celkem 23 304 327 ne 133 2816 2949 156 3120 3276 OR = O1 / O2 = 1,60 95% CI: (0,99; 2,58) χ2 = 4,13; p=0,042 O1 = 23 / = 0,076 O2 = 133 / 2816 = 0,047
 ne (kontrola) Celkem ne OR = O1 / O2 = 1,60. 95% CI: (0,99; 2,58) χ2 = 4,13; p=0,042. O1 = 23 / 304 = 0,076. O2 = 133 / 2816 = 0,047.")
37
ODDS RATIO – poměr šancí OR
Interpretace OR je podobná jako u RR, ovšem s použitím šance místo rizika OR může nabývat hodnot mezi 0 a nekonečnem OR je jediná možnost charakterizace velikosti asociace ve studii případů a kontrol OR je dobrým odhadem relativního rizika, pokud je výskyt onemocnění v populaci relativně nízký U onemocnění s častým výskytem (vysokou prevalencí) je nutno RR a OR považovat za dva různé ukazatele
 je nutno RR a OR považovat za dva různé ukazatele.")
38
ODDS RATIO – poměr šancí OR

39
ODDS RATIO – poměr šancí OR
Disease odds ratio Exposure odds ratio ve studii případů a kontrol se zpravidla z populace nevybírá stejný podíl nemocných a zdravých odhad relativního rizika by byl zkreslený, lze odhadovat jen podíly exponovaných mezi zdravými a mezi nemocnými

40
Vztah mezi šancí a pravděpodobností
Sledovaný faktor Úmrtí ano ne Celkem přítomen 2 98 100 nepřítomen 1 99 3 197 200 Pravděpodobnost 1/3 šance 1/2; pravděpodobnost 1/100 šance 1/99 Úmrtí: RR=(2/100)/(1/100) = 2; OR=(2/98)/(1/99) 2 Přežití: RR=(98/100)/(99/100) 1; OR=(98/2)/(99/1) 0,5
/(1/100) = 2; OR=(2/98)/(1/99) 2. Přežití: RR=(98/100)/(99/100) 1; OR=(98/2)/(99/1) 0,5.")
41
P-hodnota (P-VALUE) pravděpodobnost, že za platnosti nulové hypotézy H0 nastane právě takový výsledek, jaký byl pozorován, nebo ještě extrémnější (tj. vzdálenější od H0) malá p-hodnota svědčí proti platnosti H0 význam slova „malá“ určuje předem zvolená hladina významnosti α, na níže se testování provádí (typicky α=0.05) kdybychom zvolili hladinu významnosti právě rovnou p-hodnotě, byl by výsledek přesně na hranici statistické významnosti
 malá p-hodnota svědčí proti platnosti H0. význam slova „malá určuje předem zvolená hladina významnosti α, na níže se testování provádí (typicky α=0.05) kdybychom zvolili hladinu významnosti právě rovnou p-hodnotě, byl by výsledek přesně na hranici statistické významnosti.")
42
Intervaly spolehlivosti

43
Síla asociace, kauzalita
Čistě statistickými postupy nelze prokázat, zda vztah mezi veličinami je či není kauzální – testuje se, zda existuje asociace/vazba Čím větší je RR nebo OR, tím lze spíše očekávat, že vztah mezi expozicí a následkem je kauzální, i když tomu tak nemusí být ani u velmi silné vazby Pro úvahy o kauzalitě nutno dále posoudit: časový sled, specificitu (příčiny a následku), soulad s dosud známými fakty, biologickou plausibilitu, konzistenci závěrů různých studií Pro interpretaci je kromě vlastní hodnoty RR (OR) vždy nutná znalost intervalu spolehlivosti a rozsahu výběru
, soulad s dosud známými fakty, biologickou plausibilitu, konzistenci závěrů různých studií. Pro interpretaci je kromě vlastní hodnoty RR (OR) vždy nutná znalost intervalu spolehlivosti a rozsahu výběru.")
44
Síla asociace Jaký je rozdíl ve výpovědi o síle asociace v následujících situacích? OR #1: OR = % CI = ( ) OR #2: OR = % CI = ( ) OR #3: OR = % CI = ( ) OR #4: OR = % CI = ( )
 OR #3: OR = % CI = ( ) OR #4: OR = % CI = ( )")
45
Kohortová studie – horníci českých uranových dolů, expozice radonu a jeho dceřiným produktům
Příčina úmrtí Pozorovaná úmrtí (O) Očekávaná úmrtí (E) SMR (O/E) (95% int. spol.) Ca plic 704 138,6 5,08 (4,71-5,47) Ca jater 22 13,2 1,67 (1,04-2,52) Ca žlučníku 12 5,3 2,26 (1,16-3,94) SMR – standardizovaný úmrtnostní index E – počet případů, který by se v kohortě vyskytl, kdyby v ní platily stejné věkově specifické úmrtnosti jako v obecné populaci ČR
 Očekávaná úmrtí (E) SMR (O/E) (95% int. spol.) Ca plic ,6. 5,08 (4,71-5,47) Ca jater ,2. 1,67 (1,04-2,52) Ca žlučníku ,3. 2,26 (1,16-3,94) SMR – standardizovaný úmrtnostní index. E – počet případů, který by se v kohortě vyskytl, kdyby v ní platily stejné věkově specifické úmrtnosti jako v obecné populaci ČR.")
46
Atributivní riziko AR Ukazatel AR udává, za jakou část případů nemoci je zodpovědná expozice (za předpokladu příčinného vztahu mezi zkoumanou expozicí a následkem). Takto můžeme popsat počet případů nemoci mezi exponovanými, které by se nevyskytly, kdybychom dokázali zcela eliminovat expozici. Z praktického hlediska je takto dáno maximální snížení nemocnosti u exponovaných osob, kterého lze dosáhnout odstraněním rizikového faktoru. Na rozdíl od relativního rizika, které měří sílu asociace mezi expozicí a následkem, atributivní riziko je mírou dopadu této asociace v kontextu studia veřejného zdraví. V porovnání s RR se však ze zjištěné hodnoty AR rizika jen velmi těžko vyvozují zobecnění na jiné populace, neboť AR silně závisí na incidenci/prevalenci v neexponované skupině.
. Takto můžeme popsat počet případů nemoci mezi exponovanými, které by se nevyskytly, kdybychom dokázali zcela eliminovat expozici. Z praktického hlediska je takto dáno maximální snížení nemocnosti u exponovaných osob, kterého lze dosáhnout odstraněním rizikového faktoru. Na rozdíl od relativního rizika, které měří sílu asociace mezi expozicí a následkem, atributivní riziko je mírou dopadu této asociace v kontextu studia veřejného zdraví. V porovnání s RR se však ze zjištěné hodnoty AR rizika jen velmi těžko vyvozují zobecnění na jiné populace, neboť AR silně závisí na incidenci/prevalenci v neexponované skupině.")
47
Rozdíl rizik (atributivní riziko)
")
48
Potřebný počet léčených (Number needed to treat)
Převrácená hodnota rozdílu rizik, NNT=1/RD, je speciální měrou počtu osob, které připadají na každý další případ nemoci, resp. které by bylo třeba ošetřit, aby se předešlo vzniku jednoho případu.

49
Atributivní frakce Odhad podílu nemocných mezi exponovanými, který jde na vrub expozice, „AR v procentech“

50
Kohortová studie s osoboroky – horníci českých uranových dolů
Incidence leukémie IE = 9 / 38,65 na IĒ = 18 / 7,37 na RR = 38,65 / 7,37 = 5,24 95% CI: (1,93; 10,96) [relativní riziko] RD = 38,65 - 7,37 31,28 na 95% CI: (17,77; 44,78) [rozdíl rizik] AF=(38,65 - 7,37) / 38,65 80,9 % 95% CI: (57,54; 91,43) [atributivní frakce]
 [relativní riziko] RD = 38,65 - 7,37 31,28 na % CI: (17,77; 44,78) [rozdíl rizik] AF=(38,65 - 7,37) / 38,65 80,9 % 95% CI: (57,54; 91,43) [atributivní frakce]")
51
Hypotetická kohortová studie – protektivní účinky antikoncepce vzhledem k rakovině vaječníků
Ca vaječníků Osoboroky Rizika (rates) na Někdy 29 345000 8,4 Nikdy 45 321429 14,0 RR (rate ratio) = 8,4 / 14,0 = 0,60 RD (risk reduction) = 8,4 na – 14,0 na = 5,6 na PF (prevented fraction) = 1-RR = 5,6 / 14,0 na = 0,40 na 40 % (zabráněná frakce)
 na Někdy ,4. Nikdy ,0. RR (rate ratio) = 8,4 / 14,0 = 0,60. RD (risk reduction) = 8,4 na – 14,0 na = 5,6 na PF (prevented fraction) = 1-RR = 5,6 / 14,0 na = 0,40 na 40 % (zabráněná frakce)")
52
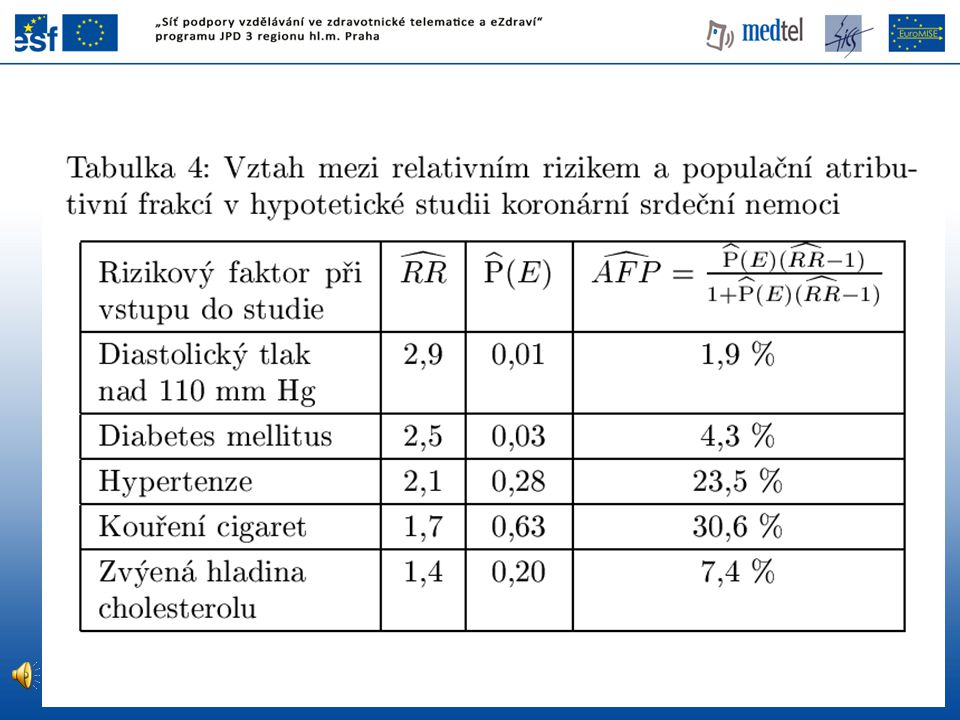
Populační atributivní frakce
Podíl onemocnění v celé studované populaci exponovaných i neexponovaných, kterým by se předešlo eliminací expozice PE ... odhad podílu exponovaných v populaci pomocí podílu exponovaných v kontrolní skupině

54
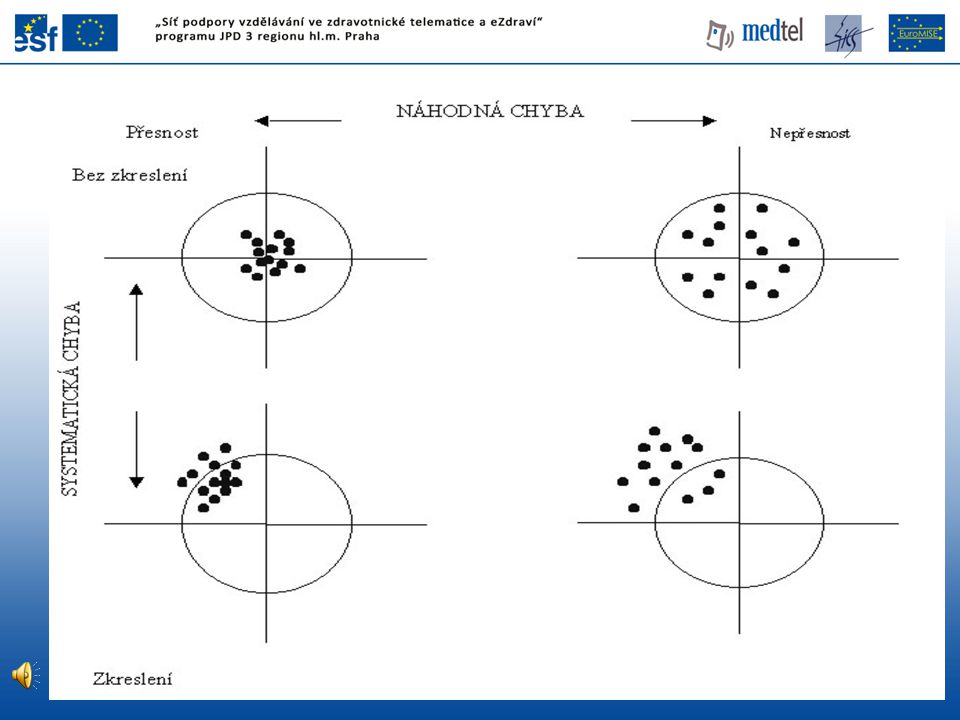
Interpretace studií Úloha náhodné chyby (kontrolována na hladině významnosti) Systematická chyba bias (zkreslení) confounding (zavádějící, matoucí, rušivý faktor) ztráty ze sledování
 confounding (zavádějící, matoucí, rušivý faktor) ztráty ze sledování.")
55
Zkreslení (bias) Jakákoli systematická chyba, která vznikne při sběru dat, jejich analýze, interpretaci, publikaci či kontrole a která vede k závěrům systematicky se lišícím od skutečnosti. Výběrové zkreslení Informační zkreslení Publikační zkreslení

57
Zavádějící faktor (Confounding factor)
EXPOZICE (konzumace alkoholu) NÁSLEDEK (rakovina plic) CONFOUNDING (kouření cigaret)
 NÁSLEDEK. (rakovina plic) CONFOUNDING. (kouření cigaret)")
58
Koncept confounding Confounding je zkreslení ukazatelů asociace (např. RR nebo OR), které může vzniknout proto, že jsme nekontrolovali další proměnné, které jsou rizikovým faktorem pro studovaný jev (nemoc) Ignorování účinku zavádějícího faktoru vede k chybným odhadům velikosti účinku (které jsou zatíženy zkreslením/bias) Bez možnosti korekce (adjustace) pozorovaného výsledku vzhledem k účinkům zavádějících faktorů není možné odlišit jejich účinek od účinku expozice Adjustace vzhledem k faktoru, který je způsoben zčásti expozicí a je korelován s výsledkem, může do studie zanést bias
, které může vzniknout proto, že jsme nekontrolovali další proměnné, které jsou rizikovým faktorem pro studovaný jev (nemoc) Ignorování účinku zavádějícího faktoru vede k chybným odhadům velikosti účinku (které jsou zatíženy zkreslením/bias) Bez možnosti korekce (adjustace) pozorovaného výsledku vzhledem k účinkům zavádějících faktorů není možné odlišit jejich účinek od účinku expozice. Adjustace vzhledem k faktoru, který je způsoben zčásti expozicí a je korelován s výsledkem, může do studie zanést bias.")
59
Zavádějící faktor – definiční kritéria
Musí být ve vztahu (přímém nebo nepřímém) k následku (rizikový faktor pro výskyt jevu) Faktor musí být skutečnou příčinou nemoci (jinou než studovaná expozice) nebo alespoň indikátorem, markerem rizika Asociace není sekundární (zprostředkovaná pouhou asociací faktoru s expozicí, která je příčinou nemoci) Musí být (v cílové populaci) asociován se studovanou expozicí Faktor musí být asociován se studovanou expozicí ve zdrojové populaci (populaci v riziku, v které vznikly studované případy) Nesmí být pouze mezikrokem v řetězci kauzálních dějů od expozice k výskytu studovaného jevu/ následku Mechanismem účinku se liší od expozice
 k následku (rizikový faktor pro výskyt jevu) Faktor musí být skutečnou příčinou nemoci (jinou než studovaná expozice) nebo alespoň indikátorem, markerem rizika. Asociace není sekundární (zprostředkovaná pouhou asociací faktoru s expozicí, která je příčinou nemoci) Musí být (v cílové populaci) asociován se studovanou expozicí. Faktor musí být asociován se studovanou expozicí ve zdrojové populaci (populaci v riziku, v které vznikly studované případy) Nesmí být pouze mezikrokem v řetězci kauzálních dějů od expozice k výskytu studovaného jevu/ následku. Mechanismem účinku se liší od expozice.")
60
Kontrola vlivu zavádějících faktorů
PŘI PLÁNOVÁNÍ STUDIE restrikce strukturální vyvažování (matching) randomizace PŘI ANALÝZE STUDIE (potenciální zavádějící faktory musí být identifikovány již při plánování studie a zaznamenány / změřeny při sběru dat) standardizace stratifikace (Mantelova-Haenszelova technika) logistická regrese složitější modely (analýza rozptylu, Coxův model)
 randomizace. PŘI ANALÝZE STUDIE. (potenciální zavádějící faktory musí být identifikovány již při plánování studie a zaznamenány / změřeny při sběru dat) standardizace. stratifikace (Mantelova-Haenszelova technika) logistická regrese. složitější modely (analýza rozptylu, Coxův model)")
61
Ukazatele zdravotnické statistiky
Hrubé Specifické Standardizované (přímá a nepřímá standardizace)
")
62
Přímá standardizace Chceme-li porovnávat určité ukazatele, např. úmrtnosti mezi oblastmi, nebo v delším časovém období, nelze používat absolutní ani relativní počty zemřelých (hrubou úmrtnost), a to kvůli závislosti takových ukazatelů na věkovém složení oblasti a skladbě obyvatel podle pohlaví. Metoda přímé standardizace provede přepočet všech údajů, které se mají porovnat, na jednu stejnou pevnou populaci (např. evropský standard - populace 100 000 osob, která má zastoupení jednotlivých věkových skupin zhruba na úrovni průměrného evropského státu v sedmdesátých letech). Standardizovaná úmrtnost je hypotetický ukazatel, který říká, jaká by byla úmrtnost ve fiktivní standardní populaci, pokud by tam platily stejné zákonitosti umírání jako v dané sledované populaci v daném čase. Sama o sobě nemá příliš velký smysl, ale je nezastupitelná pro účely srovnávání
, a to kvůli závislosti takových ukazatelů na věkovém složení oblasti a skladbě obyvatel podle pohlaví. Metoda přímé standardizace provede přepočet všech údajů, které se mají porovnat, na jednu stejnou pevnou populaci (např. evropský standard - populace osob, která má zastoupení jednotlivých věkových skupin zhruba na úrovni průměrného evropského státu v sedmdesátých letech). Standardizovaná úmrtnost je hypotetický ukazatel, který říká, jaká by byla úmrtnost ve fiktivní standardní populaci, pokud by tam platily stejné zákonitosti umírání jako v dané sledované populaci v daném čase. Sama o sobě nemá příliš velký smysl, ale je nezastupitelná pro účely srovnávání.")
63
Přímá standardizace

64
Stratifikace Základní princip: vytvořit podle hodnot kategoriální „třetí proměnné“ tzv. strata, vrstvy a hodnotit nejprve asociaci v každém stratu zvlášť – pomocí RR, OR, AR Pokud to je vhodné, vytvořit celkový odhad asociace adjustovaný vzhledem k stratifikující proměnné Ne vždy však představuje uvažovaná další proměnná další zavádějící faktor, může mít i jiné postavení

65
Stratifikace při posuzování asociace mezi expozicí a onemocněním může vystupovat „třetí proměnná“ v několika pozicích zavádějící faktor (confounder) faktor modifikující účinek (dochází k interakci) mezikrok v řetězci kauzálních dějů bez efektu Zavádějící faktor způsobuje zkreslení Faktor modifikující účinek poskytuje důležitou informaci
 faktor modifikující účinek (dochází k interakci) mezikrok v řetězci kauzálních dějů. bez efektu. Zavádějící faktor způsobuje zkreslení. Faktor modifikující účinek poskytuje důležitou informaci.")
66
Možné postavení „třetí proměnné“ při posuzování asociace mezi expozicí (E) a onemocněním (D)
bez efektu Mezikrok v příčinné posloupnosti + C M Faktor modi- fikující účinek _ Interakce: ÚČINEK EXPOZICE SE LIŠÍ V ZÁVISLOSTI NA HODNOTÁCH TŘETÍ PROMĚNNÉ D Confounding: ALTERNATIVNÍ VYSVĚTLENÍ VZNIKU ONEMOCNĚNÍ

67
Kohortová studie – i-té stratum
Nemoc Expozice ano ne Celkem ai bi ai+bi ci di ci+di ai+ci bi+di ni

68
Zavádějící faktor Hrubá (crude) analýza nebere
Následek Expozice Ano Ne Celkem Ano Ne Celkem Odds ratio: 2,3 Následek Následek Expozice Ano Ne Celkem Expozice Ano Ne Celkem Ano Ano Ne Ne Celkem Celkem Odds ratio: 1, Odds ratio: 1,0 Hrubá (crude) analýza nebere v úvahu žádnou další proměnnou Odhady velikosti relativního rizika specifické pro jednotlivá strata neindikují žádnou asociaci mezi expozicí a následkem
 analýza nebere. v úvahu žádnou další proměnnou. Odhady velikosti relativního rizika. specifické pro jednotlivá strata. neindikují žádnou asociaci mezi. expozicí a následkem.")
69
Ošetření vlivu zavádějícího faktoru
Zkonstruovat souhrnný ukazatel asociace jako vážený průměr ukazatelů z jednotlivých strat, např. (wiORi) / wi ; tím se vezme v úvahu informace každého strata a jejich rozdílnosti z pohledu ukazatele asociace různé možnosti volby vah, závisí na typu ukazatel (OR, RR, AR) i povaze dat Woolf (1955) Mantel-Haenszel (1959) Pokud je vliv zavádějícího faktoru podstatný (hrubý a stratifikovaný ukazatel se podstatně liší), nemá hrubý ukazatel smysl podstatná odlišnost: často se bere 10 %, ale nutno postupovat s ohledem na povahu problému
 / wi ; tím se vezme v úvahu informace každého strata a jejich rozdílnosti z pohledu ukazatele asociace. různé možnosti volby vah, závisí na typu ukazatel (OR, RR, AR) i povaze dat. Woolf (1955) Mantel-Haenszel (1959) Pokud je vliv zavádějícího faktoru podstatný (hrubý a stratifikovaný ukazatel se podstatně liší), nemá hrubý ukazatel smysl. podstatná odlišnost: často se bere 10 %, ale nutno postupovat s ohledem na povahu problému.")
70
Mantelova-Haenzelova statistika 2
Zobecnění 2 statistiky pro test nezávislosti v jedné čtyřpolní tabulce zde jde o test nezávislosti při současné kontrole vlivu zavádějícího faktoru Testuje nulovou hypotézu, že v žádném ze strat neexistuje asociace mezi expozicí a onemocněním Testová statistika se (bez ohledu na počet strat) porovnává s kritickou hodnotou 2 rozložení o 1 stupni volnosti Na tento test lze také nahlížet jako na test hypotézy ORMH=1; lze ovšem také testovat pomocí intervalu spolehlivosti Pozor: výsledek MH 2 testu může být statisticky nevýznamný nejen, když celkově asociace skutečně neexistuje, ale také tehdy, když ukazatele v dílčích tabulkách, které dominují, nebudou homogenní, či budou dokonce protichůdné
 porovnává s kritickou hodnotou 2 rozložení o 1 stupni volnosti. Na tento test lze také nahlížet jako na test hypotézy ORMH=1; lze ovšem také testovat pomocí intervalu spolehlivosti. Pozor: výsledek MH 2 testu může být statisticky nevýznamný nejen, když celkově asociace skutečně neexistuje, ale také tehdy, když ukazatele v dílčích tabulkách, které dominují, nebudou homogenní, či budou dokonce protichůdné.")
71
Asociace mezi expozicí asbestu a mesoteliomem pleury u horníků
Expozice (asbest) případ kontrola Celkem Rel. četnost exponovaných ano 197 237 434 mezi případy 71,64/100 ne 78 294 372 mezi kontrolami 44,63/100 275 531 806 Poměr šancí: ,13; % CI: (2,29; 4,28) Atributivní frakce: 68,1 %; 95% CI: (56,3; 76,7) 2=53,16; P<0,001
 případ. kontrola. Celkem. Rel. četnost exponovaných. ano mezi případy. 71,64/100. ne mezi kontrolami. 44,63/ Poměr šancí: 3,13; 95% CI: (2,29; 4,28) Atributivní frakce: 68,1 %; 95% CI: (56,3; 76,7) 2=53,16; P<0,001.")
72
Stratifikovaná studie případů a kontrol
KUŘÁCI Nemoc (mesoteliom) Expozice (asbest) ano ne Celkem 169 167 336 66 214 280 235 381 616 OR = 3,28; 95% CI: (2,31; 4,65) NEKUŘÁCI Nemoc (mesoteliom) Expozice (asbest) ano ne Celkem 27 70 97 12 80 92 39 150 189 OR = 2,67; 95% CI: (1,26; 5,64) Poměr šancí (hrubý): ,13; 95% CI: (2,29; 4,28) Poměr šancí (Mantel-Haenszel): 3,16; 95% CI: (2,32; 4,31) 2 (Mantel-Haenszel): 52,74; P<0,001
 Expozice (asbest) ano. ne. Celkem OR = 3,28; 95% CI: (2,31; 4,65) NEKUŘÁCI. Nemoc (mesoteliom) Expozice (asbest) ano. ne. Celkem OR = 2,67; 95% CI: (1,26; 5,64) Poměr šancí (hrubý): 3,13; 95% CI: (2,29; 4,28) Poměr šancí (Mantel-Haenszel): 3,16; 95% CI: (2,32; 4,31) 2 (Mantel-Haenszel): 52,74; P<0,001.")
73
Modifikace efektu Odlišné ukazatele asociace v jednotlivých stratech (třeba v závislosti na kouření) Např.vztah mezi užíváním orální antikoncepce a infarktem myokardu je modifikován kouřením – je jiný pro kuřačky a jiný pro nekuřačky Homogenitu strat z pohledu míry asociace je možno formálně testovat pomocí speciálních 2 testů Woolf Breslow-Day Tyto testy fungují dobře až při větších rozsazích výběrů, někdy jsou pak ale až příliš citlivé nutno doplnit expertním posouzením

74
Modifikace efektu OR ve stratech se diametrálně liší
Následek Expozice Ano Ne Celkem Ano Ne Celkem Odds ratio: 2,3 Následek Následek Expozice Ano Ne Celkem Expozice Ano Ne Celkem Ano Ano Ne Ne Celkem Celkem Odds ratio: 4, Odds ratio: 1,2 OR ve stratech se diametrálně liší Hrubý ani vážený/adjustovaný odhad nemá smysl Nutno publikovat OR pro všechna strata

75
Postup posouzení postavení „třetí proměnné“
Mezikrok v příčinné posloupnosti (expertní posouzení)? uvádět hrubé odhady ne ano Faktor modifikující účinek? ne ano uvádět stratum-specifické odhady, nikoli sumární Zavádějící faktor? Bez efektu: uvádět hrubé odhady uvádět “adjustované” sumární odhady (Mantel-Haenszel) ne ano
 uvádět hrubé odhady. ne. ano. Faktor modifikující účinek ne. ano. uvádět stratum-specifické odhady, nikoli sumární. Zavádějící faktor Bez efektu: uvádět hrubé odhady. uvádět adjustované sumární odhady (Mantel-Haenszel) ne. ano.")
76
Logistická regrese Modeluje vztah (asociaci) mezi jednou či více vysvětlujícími proměnnými xi, které mohou být dichotomické (ano/ne) kategoriální (socio-ekonomický status, ... ) spojité (věk, ...) a dichotomickou (binární) proměnnou Y Charakterizace „následku“ dichotomickou proměnnou je nejběžnější situací vyskytující se v biologii a epidemiologii Kódování Y 1=pozitivní odpověď / přítomnost určité charakteristiky (výskyt znaku / onemocnění či naopak přežití) 0=negativní odpověď / nepřítomnost charakteristiky
 kategoriální (socio-ekonomický status, ... ) spojité (věk, ...) a. dichotomickou (binární) proměnnou Y. Charakterizace „následku dichotomickou proměnnou je nejběžnější situací vyskytující se v biologii a epidemiologii. Kódování Y. 1=pozitivní odpověď / přítomnost určité charakteristiky (výskyt znaku / onemocnění či naopak přežití) 0=negativní odpověď / nepřítomnost charakteristiky.")
77
Logistická regrese Průměr binární veličiny si lze představovat jako pravděpodobnost, pak se bude zkoumat, jak je např. pravděpodobnost ICHS závislá na věku (a případně i na dalších proměnných, třeba kuřáckých návycích) Značení y .. ICHS (1=ano, 0=ne) P .. pravděpodobnost ICHS x .. věk Snaha použít místo zde nevhodného modelu lineární regrese y=α + βx model P=α + βx, ale P je pravděpodobnost a má být mezi 0 a 1 Proto se modeluje ln[P/(1-P)]= α + βx, tzv. logit(P) Změna v pravděpodobnosti není úměrná změně v x lineárně, závisí na hodnotě x nelineární model (logistická funkce) P/(1-P) je šance (odds) odpovědi „ano“ při dané hodnotě x
 Značení. y .. ICHS (1=ano, 0=ne) P .. pravděpodobnost ICHS. x .. věk. Snaha použít místo zde nevhodného modelu lineární regrese y=α + βx model P=α + βx, ale P je pravděpodobnost a má být mezi 0 a 1. Proto se modeluje ln[P/(1-P)]= α + βx, tzv. logit(P) Změna v pravděpodobnosti není úměrná změně v x lineárně, závisí na hodnotě x nelineární model (logistická funkce) P/(1-P) je šance (odds) odpovědi „ano při dané hodnotě x.")
78
Logistická regrese Pravdě-podobnost onemocnění x

79
Interpretace koeficientu β
Poměr šancí eb říká, kolikrát se změní šance (odds) na pozitivní výsledek při změně x z 0 na 1 (v případě dichotomické veličiny) při změně x o 1 jednotku (obecně, u spojité veličiny) b = změna logaritmu poměru šancí (OR) při jednotkové změně v x
 na pozitivní výsledek. při změně x z 0 na 1 (v případě dichotomické veličiny) při změně x o 1 jednotku (obecně, u spojité veličiny) b = změna logaritmu poměru šancí (OR) při jednotkové změně v x.")
80
Interpretace koeficientu β
b = 0 (eb=1) pravděpodobnost výskytu znaku je stejná na všech úrovních x, není asociace mezi x a y b > 0 (eb>1) pravděpodobnost výskytu znaku se s rostoucím x zvyšuje b < 0 (eb <1) pravděpodobnost výskytu znaku se s rostoucím x snižuje Lze testovat nulovou hypotézu H0: b=0 proti H1: b0 (Waldův test)
 pravděpodobnost výskytu znaku je stejná na všech úrovních x, není asociace mezi x a y. b > 0 (eb>1) pravděpodobnost výskytu znaku se s rostoucím x zvyšuje. b < 0 (eb <1) pravděpodobnost výskytu znaku se s rostoucím x snižuje. Lze testovat nulovou hypotézu H0: b=0 proti H1: b0 (Waldův test)")
81
Vícenásobná logistická regrese
Obecně lze do modelu zařadit více nezávisle proměnných (xi) různých typů Dichotomická, ordinální, nominální, spojitá … logit(P)=ln[P/(1-P)]= α + β1x1 + β2x βkxk P/(1-P) je šance odpovědi „ano“ při hodnotách x1 až xk Interpretace bi změna logaritmu poměru šancí (OR) při jednotkové změně v jedné konkrétní nezávisle proměnné xj při stejných (nezměněných) hodnotách všech ostatních xi, ij Míra asociace mezi xj a logaritmem poměru šancí adjustovaná vzhledem k vlivu všech ostatních xi zahrnutých v modelu eβi lze opět interpretovat jako poměr šancí
 různých typů. Dichotomická, ordinální, nominální, spojitá … logit(P)=ln[P/(1-P)]= α + β1x1 + β2x βkxk. P/(1-P) je šance odpovědi „ano při hodnotách x1 až xk. Interpretace bi. změna logaritmu poměru šancí (OR) při jednotkové změně v jedné konkrétní nezávisle proměnné xj při stejných (nezměněných) hodnotách všech ostatních xi, ij. Míra asociace mezi xj a logaritmem poměru šancí adjustovaná vzhledem k vlivu všech ostatních xi zahrnutých v modelu. eβi lze opět interpretovat jako poměr šancí.")
82
Logistická regrese Sledováno přežívání v závislosti na věku a pohlaví
logit(P)= α + β1AGE + β2FEMALE Odhady (SPSS) b S.E. Wald DF Sig. (P-value) OR= Exp(b) 95% CI for Exp(b) Lower Upper AGE -0.078 0.037 4.399 1 0.036 0.925 0.860 0.995 FEMALE 1.597 0.756 4.470 0.034 4.940 1.124 21.716 Constant 1.633 1.110 2.164 0.141 5.120 logit(P)= 1,633 –0,078AGE + 1,597FEMALE logit(P)= 1,633 –0,078AGE muži logit(P)= 3,230 –0,078AGE ženy
= α + β1AGE + β2FEMALE. Odhady (SPSS) b. S.E. Wald. DF. Sig. (P-value) OR= Exp(b) 95% CI for Exp(b) Lower. Upper. AGE FEMALE Constant logit(P)= 1,633 –0,078AGE + 1,597FEMALE. logit(P)= 1,633 –0,078AGE ... muži. logit(P)= 3,230 –0,078AGE ... ženy.")
83
Logistická regrese Interpretace
Pro jakýkoli daný věk je šance přežití pro ženy 4,9 krát větší než pro muže (e1,597=4,94); 95% CI: (1,1; 21,6) Šance přežití 40letého vzhledem k 20letému Odhad β1 je –0.078; e-0.078=0.925 je poměr šancí pro jednotkovou změnu věku e-0,078*20=0,21 je poměr šancí pro změnu o 20 let
; 95% CI: (1,1; 21,6) Šance přežití 40letého vzhledem k 20letému. Odhad β1 je –0.078; e-0.078=0.925 je poměr šancí pro jednotkovou změnu věku. e-0,078*20=0,21 je poměr šancí pro změnu o 20 let.")
84
Příklad - predikce 10-leté riziko úmrtí pro kardiovaskulární příčiny
pro 62letého muže, nediabetika, který kouří 20 cigaret denně, má BMI 25 kg/m2, STK 140 mm Hg, cholesterol 245 mg/100 ml a puls 80/min je riziko 26.8 % pro nekuřáka (s ostatními parametry stejnými) je riziko 18.8%
 je riziko 18.8%")
85
Logistická regrese Umožňuje současně adjustovat na vliv více proměnných, které mohou být binární, kategoriální i spojité Závisle proměnná musí být binární Zobecnění na kategoriální závisle proměnnou model poměrných šancí (proportional odds model)
")
86
Další možnosti Expozice ve více kategoriích Test trendu (Armitage)
")
87
TEST TRENDU konzumace alkoholu a rakovina jícnu
Alkohol (g/den) Případy Kontroly CELKEM RR Podíl 0-39 29 386 415 1,00 6,99 40-79 75 280 355 3,57 21,13 80-119 51 87 138 7,80 36,96 120+ 45 22 67 27,23 67,16 200 775 975 χ2 nezávislost: 158,8; DF=3 χ2 linearita: 6,9; DF=2 χ2 trend: 151,9; DF=1 ; P<0,001 (Breslow, Day: Statistical Methods in Cancer Research I, 1980)
 Případy. Kontroly. CELKEM. RR. Podíl ,00. 6, ,57. 21, ,80. 36, ,23. 67, χ2 nezávislost: 158,8; DF=3. χ2 linearita: 6,9; DF=2. χ2 trend: 151,9; DF=1 ; P<0,001. (Breslow, Day: Statistical Methods in Cancer Research I, 1980)")
88
Hypotézy Nulová hypotéza H0 („nic se neděje“)
Alternativní hypotéza HA (co se děje, když H0 neplatí) Statistický test říká, zda zamítneme H0 nebo nezamítneme Nezamítnutí není totéž, co přijetí hypotézy
 Statistický test říká, zda zamítneme H0 nebo nezamítneme. Nezamítnutí není totéž, co přijetí hypotézy.")
89
MOŽNÉ VÝSLEDKY STATISTICKÉHO TESTU A TYPY CHYB
Skutečnost Rozhodnutí na základě výběru Nezamítáme H0 Zamítáme H0 (statist. významný výsledek) H0 platí Správné rozhodnutí P=1-α (hladina spolehlivosti) Chyba I. druhu P= α (hladina významnosti) H0 neplatí, platí HA Chyba II. druhu P=β P=1- β (síla testu)
 H0 platí. Správné rozhodnutí. P=1-α (hladina spolehlivosti) Chyba I. druhu. P= α (hladina významnosti) H0 neplatí, platí HA. Chyba II. druhu. P=β. P=1- β (síla testu)")
90
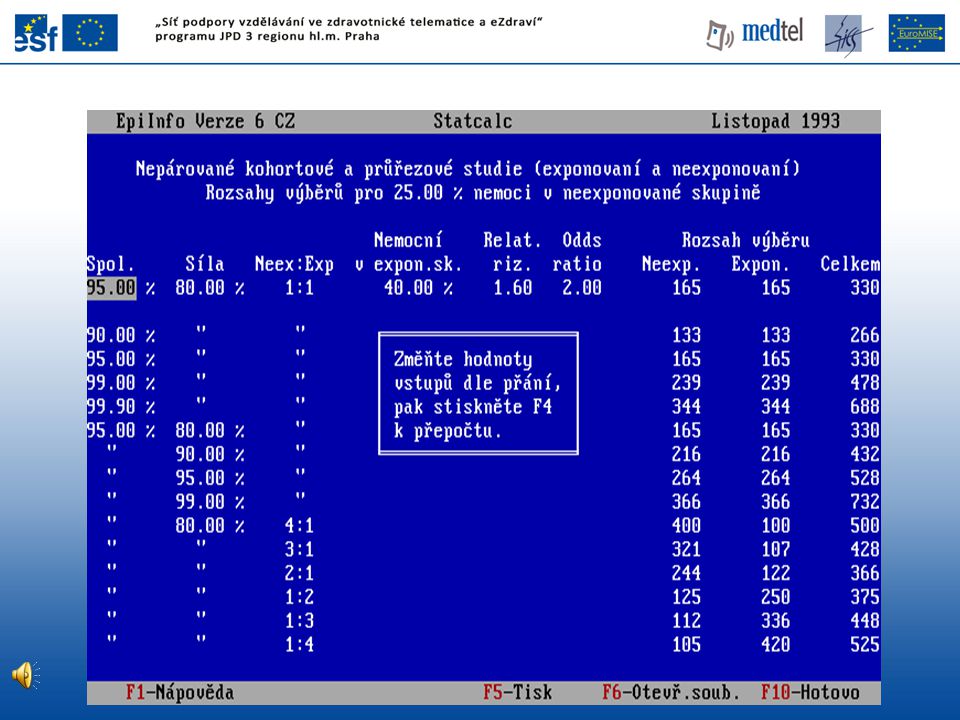
ROZSAH VÝBĚRU (DLE POŽADAVKU NA OR)
")
92
Literatura Armitage P., Berry G.: Statistical Methods in Medical Research. 2nd ed., Blackwell Scientific Publications, Oxford, 1991 Armitage P., Colton T., eds.: Encyclopedia of Biostatistics. Wiley, Chichester, 1998 Breslow N.E., Day N.E.: Statistical Methods in Cancer Research. Vol. 1 - The analysis of case-control studies. IARC Scientific Publications No. 32. International Agency for Research on Cancer, Lyon, 1980 Breslow N.E., Day N.E.: Statistical Methods in Cancer Research. Vol. 2 - The Design and Analysis of Cohort Studies. IARC Scientific Publications No. 82. International Agency for Research on Cancer, Lyon, 1987 Henneckens C.H., Buring J.: Epidemiology in Medicine. Little, Brown and Company, Boston, 1987 Jewell, N.P.: Statistics for Epidemiology. Chapman&Hall/CRC, Boca Raton, 2004 Newman, S.C.: Biostatistical Methods in Epidemiology. Wiley, New York, 2001 Rothman, K., Greenland, S.: Modern Epidemiology. 2nd ed. Lippincott-Raven, Philadelphia, 1998 Sachs, L.: Applied Statistics. A Handbook of Techniques. Springer-Verlag, New York, 1982 dos Santos Silva I.: Cancer Epidemiology: Principles and Methods. International Agency for Research on Cancer, Lyon, 1999 Woodward, M.: Epidemiology. Study Design and Data Analysis. 2nd ed. Chapman&Hall/CRC, Boca Raton, 2005 Zvárová, J., Malý, M. (ed.): Biomedicínská statistika III. Statistické metody v epidemiologii, svazek 1 a 2. Karolinum, Praha, 2003
: Biomedicínská statistika III. Statistické metody v epidemiologii, svazek 1 a 2. Karolinum, Praha,")
Podobné prezentace