Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Porovnání průměrů více než dvou normálních rozdělení
Analýza rozptylu Porovnání průměrů více než dvou normálních rozdělení

2
Analýza rozptylu (ANOVA) se v technické praxi používá buď jako samostatná technika nebo jako postup umožňující analýzu zdrojů variability v lineárních statistických modelech. Ze statistického hlediska lze analýzu rozptylu chápat jako speciální případ regresní analýzy, kdy vysvětlující proměnné mohou mít kvantitativní i kvalitativní charakter. Podstatou analýzy rozptylu je rozklad celkového rozptylu dat na složky objasněné (známé zdroje variability) a složku neobjasněnou, o níž se předpokládá, že je náhodná. Následně se testují hypotézy o významnosti jednotlivých zdrojů variability.
 a složku neobjasněnou, o níž se předpokládá, že je náhodná. Následně se testují hypotézy o významnosti jednotlivých zdrojů variability.")
3
Základní myšlenka analýzy rozptylu spočívá v tom, že celkový rozptyl rozložíme na rozptyly dílčí náležející příslušným jednotlivým vlivům, podle nichž jsou empirické údaje roztříděny. Kromě těchto dílčích rozptylů je jednou složkou celkového rozptylu tzv. reziduální rozptyl, který je způsoben dalšími vlivy, které v rámci analýzy nepostihujeme. Porovnáním složek rozptylu zkoumaného kvantitativního znaku pak určíme ty vlivy, které významně ovlivňují úroveň tohoto znaku.

4
Analýzu rozptylu používáme tehdy, sledujeme-li vliv jednoho nebo několika faktorů na zkoumaný statistický znak. Předpokládejme, že sledovaný znak je ovlivňován pouze jediným faktorem, který budeme sledovat na několika jeho úrovních. Úrovní faktoru se zde rozumí určitá hodnota kvantitativního znaku nebo určitá varianta kvalitativního znaku. Získané hodnoty uspořádáme podle jednoho třídícího kritéria (hlediska), tzn. podle úrovní sledovaného faktoru do tolika tříd, na kolika úrovních tento faktor sledujeme. Tento model, kdy sledujeme úroveň jednoho faktoru, se potom nazývá analýza rozptylu při jednoduchém třídění.
, tzn. podle úrovní sledovaného faktoru do tolika tříd, na kolika úrovních tento faktor sledujeme. Tento model, kdy sledujeme úroveň jednoho faktoru, se potom nazývá analýza rozptylu při jednoduchém třídění.")
5
Úrovně sledovaných faktorů mohou mít různý charakter.
V některých případech úrovně faktoru představují pevné typy určitého kvalitativního faktoru nebo pevná množství určitého kvantitativního faktoru. Účelem experimentu je vyšetřit a porovnat efekty těchto pevných úrovní faktoru. Jsou-li úrovně faktoru přesně fixovány, nazýváme odpovídající model analýzy rozptylu model s pevnými efekty (model I). Model s náhodnými efekty (model II) – úrovně faktoru mohou být náhodně vybrány z velkého počtu možných úrovní. Při náhodně vybraných úrovních (tzn. má-li výběr úrovní náhodný charakter) je efekt úrovně náhodnou veličinou.
. Model s náhodnými efekty (model II) – úrovně faktoru mohou být náhodně vybrány z velkého počtu možných úrovní. Při náhodně vybraných úrovních (tzn. má-li výběr úrovní náhodný charakter) je efekt úrovně náhodnou veličinou.")
6
Představme si, že sledujeme vliv tří způsobů mletí vzorku v zařízeních Z1, Z2 a Z3 na výsledek chemické analýzy. Na každém mlecím zařízení byly připraveny tři vzorky, pro které byly určeny výsledky chemické analýzy xij, (i = 1, 2, 3 a j = 1, 2, 3), kde xij označuje výsledek pro i-tý způsob mletí a j-tý vzorek. Způsob mletí je označován jako kvalitativní faktor. Vyskytují se však také faktory kvantitativní, jako je například průměrná velikost částic mletého vzorku či další fyzikální a chemické veličiny. Pokud nás zajímají pouze rozdíly mezi danými úrovněmi (způsoby mletí), jde o modely s pevnými efekty. Pokud jsou jednotlivé úrovně pouze výběrem z konečného či nekonečného souboru, jde o modely s náhodnými efekty.
, kde xij označuje výsledek pro i-tý způsob mletí a j-tý vzorek. Způsob mletí je označován jako kvalitativní faktor. Vyskytují se však také faktory kvantitativní, jako je například průměrná velikost částic mletého vzorku či další fyzikální a chemické veličiny. Pokud nás zajímají pouze rozdíly mezi danými úrovněmi (způsoby mletí), jde o modely s pevnými efekty. Pokud jsou jednotlivé úrovně pouze výběrem z konečného či nekonečného souboru, jde o modely s náhodnými efekty.")
7
Výběr mezi pevnými a náhodnými efekty závisí na vlastním záměru analýzy rozptylu a může se podle něho měnit. V rámci uvedeného příkladu uvažujme, že místo tří mlecích zařízení vybereme faktor „průměrná jemnost mletí“. O model s pevnými efekty půjde tehdy, budeme-li uvažovat, že třem mlecím zařízením odpovídají tři úrovně jemnosti mletí. Naším záměrem je vyšetřit, zda mletí na jednotlivých mlecích zařízeních výrazně ovlivní výsledek chemické analýzy. O model s náhodnými efekty jde tehdy, když zjišťujeme, zda má průměrná velikost částic vzorku vliv na výsledek analýzy. Ze všech možných velikostí částic náhodně vybereme tři, které lze shodou okolností realizovat na třech mlecích zařízeních. Zajímá nás tedy původní soubor, tj. všechny velikosti částic, a nikoliv vlastní výběr, tj. konkrétní tři velikosti částic.

8
Předpokládejme, že sledovaný faktor má m úrovní a že počet pozorování v jednotlivých třídách (tzn. na každé úrovni sledovaného faktoru) je roven n. Pro přehlednost uspořádání údajů je možné využít následujícího schématu:

9
Pro vlastní zpracování modelů analýzy rozptylu je důležité, zda je při všech kombinacích faktorů realizován stejný počet měření (opakování) či nikoliv. Pro stejný počet opakování se modely označují jako vyvážené (ortogonální), kdy n1 = n2 = … = nm. Nevyvážený (neortogonální) model rozsahy ni (i = 1, 2, …, m) jednotlivých tříd jsou různé. Podmínky použitelnosti analýzy rozptylu: normalita rozdělení, statistická nezávislost náhodných chyb eij, shodné rozptyly náhodných chyb eij.
, kdy n1 = n2 = … = nm. Nevyvážený (neortogonální) model rozsahy ni (i = 1, 2, …, m) jednotlivých tříd jsou různé. Podmínky použitelnosti analýzy rozptylu: normalita rozdělení, statistická nezávislost náhodných chyb eij, shodné rozptyly náhodných chyb eij.")
10
Analýza rozptylu při jednoduchém třídění hodnotí diference průměrů sledované závisle proměnné mezi skupinami, které jsou určeny jednou nezávisle proměnnou (jedním faktorem). Zkoumá se, zda skupiny vytvořené tímto faktorem jsou podobné, nebo zda jednotlivé průměry tvoří nějaké identifikovatelné shluky. Máme k dispozici m 2 nezávislých výběrů z rozdělení kde 1, 2, …, m a 2 jsou neznámé parametry ZS.

11
Nulová hypotéza má tvar: H0: 1 = 2 = … = m , m 2
Předpokládáme, že jednotlivé rozptyly ZS jsou shodné, tzn (není však nutno, aby jejich hodnota byla známa). Nulová hypotéza má tvar: H0: 1 = 2 = … = m , m 2 Alternativní hypotéza pak tvrdí, že existuje alespoň jedna dvojice průměrů, která se sobě nerovná. Předpokládáme, že jednotlivá měření vyhovují modelu xij = + ai + eij, i = 1, 2, …, m, j = 1, 2, …, n, kde xij označuje i-té měření v j-tém výběru, je společná část průměru a eij jsou nezávislé náhodné veličiny s rozdělením N(0; 2).
. Nulová hypotéza má tvar: H0: 1 = 2 = … = m , m 2. Alternativní hypotéza pak tvrdí, že existuje alespoň jedna dvojice průměrů, která se sobě nerovná. Předpokládáme, že jednotlivá měření vyhovují modelu. xij = + ai + eij, i = 1, 2, …, m, j = 1, 2, …, n, kde xij označuje i-té měření v j-tém výběru, je společná část průměru a eij jsou nezávislé náhodné veličiny s rozdělením N(0; 2).")
12
Hodnotu je možno interpretovat jako průměrný teoretický výsledek na uvažovaných úrovních faktoru A (obecná střední hodnota), ai (i = 1, 2, …, m) představuje efekt (účinek) i-té úrovně faktoru A (efekt ai zvyšuje nebo snižuje teoretickou střední hodnotu o účinek i-té úrovně faktoru A). Efekt skupiny ai způsobuje, že průměry i sledované proměnné si nemusí být rovny. Náhodné veličiny eij lze chápat jako náhodné chyby, jimiž je každé měření zatíženo.

13
Pro posouzení, zda daný faktor A skutečně ovlivňuje zkoumaný statistický znak X, je třeba testovat nulovou hypotézu H0: 1 = 2 = … = m, kterou je možno ekvivalentně zapsat též takto: H0: a1 = a2 = … = am = 0. Slovně vyjádřeno: efekty jednotlivých úrovní sledovaného faktoru A jsou zanedbatelné (faktor neovlivňuje závisle proměnnou X). Alternativní hypotézou je hypotéza
. Alternativní hypotézou je hypotéza.")
14
Pro přehlednější vyjádření vzorců užívaných v analýze rozptylu se používá tzv. tečkový způsob zápisu součtů a průměrů pozorovaných hodnot. Součet, resp. průměr hodnot, zjištěných v i-tém výběrovém souboru (tzn. součet, resp. průměr hodnot v i-tém řádku schématu) lze označit následujícím způsobem: Součet Průměr
 lze označit následujícím způsobem: Součet Průměr.")
15
Celkový součet označíme X•• , tzn.
a celkový průměr pak lze vyjádřit jako:

16
Ve složitějších modelech analýzy rozptylu budeme pracovat i se sloupcovými součty, resp. sloupcovými průměry: Tečka vždy nahrazuje indexy, přes které sčítáme.

17
Test H0 je založen na skutečnosti, že za platnosti H0 lze ze zjištěných výběrových hodnot xij provést odhad neznámého rozptylu 2 dvěma na sobě zcela nezávislými způsoby. 1. způsob odhadu 2 Každý z výběrových rozptylů ( je rozptyl hodnot zjištěných v i-tém výběrovém souboru) poskytuje odhad rozptylu 2. Jestliže z těchto výběrových rozptylů utvoříme aritmetický průměr, získáme opět odhad rozptylu 2, který je však lepší než kterýkoliv z odhadů .
 poskytuje odhad rozptylu 2. Jestliže z těchto výběrových rozptylů utvoříme aritmetický průměr, získáme opět odhad rozptylu 2, který je však lepší než kterýkoliv z odhadů .")
18
Tento odhad se nazývá rozptyl uvnitř tříd (reziduální rozptyl).
2. způsob odhadu 2 V teorii odhadu se dokazuje, že pro rozptyl výběrového průměru platí vztah Odtud pro rozptyl 2 dostáváme vyjádření

19
Rozptyl sice neznáme, můžeme ho ale odhadnout pomocí výběrových průměrů, vypočtených z pozorovaných hodnot xij: Následně tedy dostáváme vztah pro odhad 2: Tento odhad se nazývá rozptyl mezi třídami.

20
Test hypotézy H0: a1 = a2 = … = am = 0 je tedy ekvivalentní testu hypotézy
kde představuje rozptyl mezi třídami a rozptyl uvnitř tříd (reziduální). Významnost rozdílu mezi uvedenými rozptyly pak posoudíme F-testem, kdy testové kritérium bude mít tvar:
. Významnost rozdílu mezi uvedenými rozptyly pak posoudíme F-testem, kdy testové kritérium bude mít tvar:")
21
Statistika F má za platnosti H0 F-rozdělení o (m-1) a m(n-1) stupních volnosti.
Pokud F > F, pak zamítáme hypotézu o statisticky nevýznamném rozdílu obou rozptylů, což bude znamenat i zamítnutí hypotézy o shodě průměrů ZS. Pro provedení testu je třeba určit hodnoty srovnávaných rozptylů, které získáme pomocí tzv. součtů čtverců. Celkový součet čtverců, tzn. součet čtverců odchylek pozorovaných hodnot xij od celkového průměru lze upravit takto:

22
Označme: Výše uvedené lze stručně přepsat takto: S = S1 + Sr.

23
Celkovou variabilitu, reprezentovanou celkovým součtem čtverců S, lze rozložit na dvě aditivní složky: S1 – součet čtverců mezi třídami, Sr – součet čtverců uvnitř tříd (reziduální) Složka S1 charakterizuje vliv faktoru A na sledovaný statistický znak S, Složka Sr charakterizuje působení pouze náhodných příčin. Při praktických úlohách určujeme Sr jako rozdíl součtů S a S1, tzn. Sr = S – S1.
 Složka S1 charakterizuje vliv faktoru A na sledovaný statistický znak S, Složka Sr charakterizuje působení pouze náhodných příčin. Při praktických úlohách určujeme Sr jako rozdíl součtů S a S1, tzn. Sr = S – S1.")
24
Tvary součtů čtverců je možné upravit do výpočetně jednodušších výrazů, kdy dostáváme následující tzv. výpočetní tvary veličin S, S1 a Sr: kde

25
Jestliže F F [(m-1); m(n-1)] , zamítáme H0.
Výpočty pro analýzu rozptylu obvykle uspořádáváme do tzv. tabulky analýzy rozptylu. Variabilita Součet čtverců Stupně volnosti Rozptyl Testovací kritérium Mezi třídami m - 1 Uvnitř tříd (reziduální) m(n-1) Celková mn-1 Jestliže F F [(m-1); m(n-1)] , zamítáme H0.
![Jestliže F F [(m-1); m(n-1)] , zamítáme H0.](http://slideplayer.cz/slide/2691183/10/images/25/Jestli%C5%BEe+F+%EF%80%BE+F%EF%81%A1+%5B%28m-1%29%3B+m%28n-1%29%5D+%2C+zam%C3%ADt%C3%A1me+H0..jpg "Výpočty pro analýzu rozptylu obvykle uspořádáváme do tzv. tabulky analýzy rozptylu. Variabilita. Součet čtverců. Stupně volnosti. Rozptyl. Testovací kritérium. Mezi třídami. m - 1. Uvnitř tříd (reziduální) m(n-1) Celková. mn-1. Jestliže F F [(m-1); m(n-1)] , zamítáme H0.")
26
Analýza rozptylu při jednoduchém třídění s nestejným počtem opakování
Pokud jednotlivé třídy ve schématu nemají stejný počet pozorování, hovoříme o tzv. nevyváženém modelu analýzy rozptylu. Předpokládejme, že jednotlivé třídy mají rozsahy ni , i = 1, 2, …, m. Vzorce pro součty čtverců se odvodí zcela analogicky jako u vyváženého modelu a budou mít tento tvar (pravé strany výrazů pak představují výpočetní tvary součtů čtverců):
:")
28
Jestliže F F [(m-1); ( ni – m)] , zamítáme H0.
Pokud se týká stupňů volnosti, jsou u nevyváženého modelu stanoveny takto: f1 = m – 1, f2 = ni – m. Další postup je již stejný jako v případě třídění se stejným počtem pozorování (tzn. jako u vyváženého modelu). Jestliže F F [(m-1); ( ni – m)] , zamítáme H0.
![Jestliže F F [(m-1); ( ni – m)] , zamítáme H0.](http://slideplayer.cz/slide/2691183/10/images/28/Jestli%C5%BEe+F+%EF%80%BE+F%EF%81%A1+%5B%28m-1%29%3B+%28%EF%81%93+ni+%E2%80%93+m%29%5D+%2C+zam%C3%ADt%C3%A1me+H0..jpg "Pokud se týká stupňů volnosti, jsou u nevyváženého modelu stanoveny takto: f1 = m – 1, f2 = ni – m. Další postup je již stejný jako v případě třídění se stejným počtem pozorování (tzn. jako u vyváženého modelu). Jestliže F F [(m-1); ( ni – m)] , zamítáme H0.")
29
Podrobnější hodnocení výsledků analýzy rozptylu (metody mnohonásobného srovnávání)
Jestliže se F-testem zamítne H0, je závěr, že ne všechny průměry ZS jsou shodné, příliš neurčitý. Porovnáváme-li m výběrových průměrů, lze mezi nimi vytvořit m(m-1)/2 diferencí. F-test v analýze rozptylu však sám o sobě nepodává informaci, kolik a které z těchto diferencí jsou statisticky významné. Z tohoto důvodu je v případě zamítnutí H0 nezbytné, aby se výsledky analýzy rozptylu doplnily podrobnějším hodnocením, jímž bychom zjistili, které z dvojic výběrových průměrů se liší statisticky významně, a které pouze náhodně.
/2 diferencí. F-test v analýze rozptylu však sám o sobě nepodává informaci, kolik a které z těchto diferencí jsou statisticky významné. Z tohoto důvodu je v případě zamítnutí H0 nezbytné, aby se výsledky analýzy rozptylu doplnily podrobnějším hodnocením, jímž bychom zjistili, které z dvojic výběrových průměrů se liší statisticky významně, a které pouze náhodně.")
30
Metody mnohonásobného srovnávání umožňují detailní rozlišení jednotlivých průměrů.
Je možné použít postupy: Duncanova metoda Kramerova metoda Scheffého metoda (S – metoda) Tukeyova metoda (T – metoda) Newmann – Kelsův test Dunnettův test Fisherův LSD test apod.
 Tukeyova metoda (T – metoda) Newmann – Kelsův test. Dunnettův test. Fisherův LSD test apod.")
31
Scheffého metoda (S-metoda)
univerzálně použitelná, tzn. jak pro model vyvážený, tak nevyvážený. Hypotéza i =j (i, j = 1, 2, …, m; i j) se zamítá tehdy, jestliže – reziduální rozptyl, ni a nj – rozsahy srovnávaných souborů, F – tabulková hodnota F–rozdělení.
 se zamítá tehdy, jestliže. – reziduální rozptyl, ni a nj – rozsahy srovnávaných souborů, F – tabulková hodnota F–rozdělení.")
32
Tukeyova metoda (T-metoda)
použitelná pouze pro vyvážený model je citlivější na rozdíly mezi středními hodnotami Jestliže kde liší se výběrové průměry statisticky významně (ve smyslu T – metody). q (m; n-m) – tabelované hodnoty studentizovaného rozpětí q
. q (m; n-m) – tabelované hodnoty studentizovaného. rozpětí q.")
33
q, fr , m – tabulková hodnota studentizovaného rozpětí q pro:
U T – metody se lze setkat s označením dmin , kdy q, fr , m – tabulková hodnota studentizovaného rozpětí q pro: – hladinu významnosti, fr – stupňů volnosti reziduálního rozptylu, m – počet srovnávaných průměrů, n – počet opakování ve třídách (rozsah srovnávaných souborů).
.")
34
Duncanova metoda použitelná pouze pro vyvážený model
pro tuto metodu je potřeba vypočtené výběrové průměry seřadit vzestupně podle velikosti Rozptyl výběrových průměrů je možné odhadnout pomocí reziduálního rozptylu Pro další výpočty budeme potřebovat směrodatnou odchylku tohoto rozptylu, tzn.

35
Duncanova metoda uspořádávání průměrů
Kritická hodnota diferencí .. …

36
Kramerova metoda Rp; (f); – pomocné hodnoty pro Duncanův test, kdy
– hladina významnosti, f – stupně volnosti reziduálního rozptylu . Kramerova metoda Používá se v případě, kdy jednotlivé výběry mají nestejné rozsahy. Výběrové průměry vypočtené z výběrů o rozsazích ni a nj , kde ni nj , se liší statisticky významně, jestliže

37
Příklad Tří různých vyučovacích metod bylo použito na malých skupinách žáků. Na základě závěrečného zkoušení (v bodech), které jsou uvedeny v tabulce, posuďte, zda existuje statisticky významný rozdíl mezi uvedenými metodami.
, které jsou uvedeny v tabulce, posuďte, zda existuje statisticky významný rozdíl mezi uvedenými metodami.")
38
Použitím výpočtových tvarů dostaneme následující hodnoty součtů čtverců:

40
Následuje podrobnější vyhodnocení analýzy rozptylu. T-metoda
Metoda B 13,2 Metoda C 14,4 Metoda A 11 2,2 3,4 1,2 Statisticky významný rozdíl byl zjištěn mezi metodou A a B a metodou A a C.

41
S-metoda Metoda B 13,2 Metoda C 14,4 Metoda A 11 2,2 3,4 1,2 Podle S – metody byl statisticky významný rozdíl zjištěn mezi metodou A a metodou C.

42
R3; 42; 0,05 = 3,01 R2; 42; 0,05 = 2,86 Duncanova metoda
Kritická hodnota diferencí Metoda C 14,4 Metoda B 13,2 Metoda A 11,0 3,01 · 0,645 = 1,94 C – A 3,4 -- 2,86 · 0,645 = 1,84 C – B 1,2 B – A 2,2 R3; 42; 0,05 = 3,01 R2; 42; 0,05 = 2,86 Statisticky významný rozdíl byl zjištěn mezi metodou A a B a metodou A a C.

Podobné prezentace
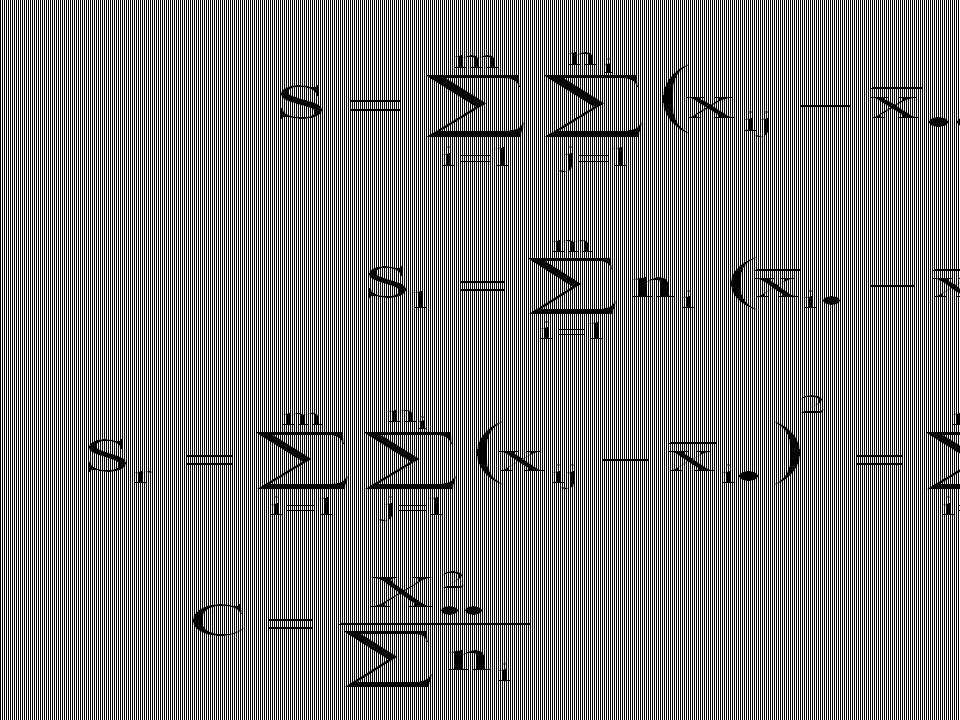
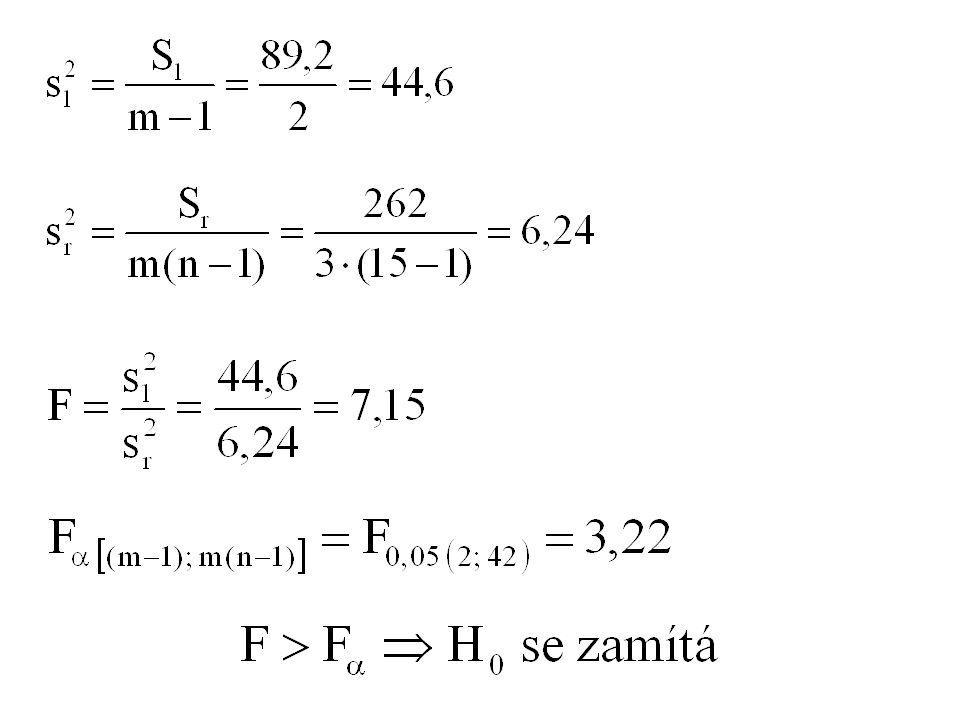











>")





 závislosti dvou náhodných veličin: korelace symetrický vztah obou veličin neslouží k předpovědi způsob (tvar) závislosti.>")

