Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
ELLA–CS Producer of medical devices

6
…durability !!!!!

8
Ronald Aylmer Fisher (17. února 1890, Londýn, Spojené království – 29
Ronald Aylmer Fisher (17. února 1890, Londýn, Spojené království – 29. července 1962, Adelaide, Austrálie) byl anglický statistik, evoluční biolog, eugenik a genetik. Zakladatel moderní matematické statistiky.
 byl anglický statistik, evoluční biolog, eugenik a genetik. Zakladatel moderní matematické statistiky.")
9
Srovnání – pro posouzení efektu intervence je třeba porovnat objekty vystavené této intervenci a objekty, které jí vystaveny nebyly (tzv. kontrolní skupina). Randomizace (znáhodnění) – výběr jednotek, které budou pozorovány, vystaveny různým druhům intervence resp. budou zařazeny do kontrolní skupiny, se musí dít na základě pravděpodobnostního výběru. Replikace (opakování) – vícenásobné opakování měření umožní posoudit náhodnou variabilitu měřených veličin, a tím i určit přesnost měření. Citováno z „
 – výběr jednotek, které budou pozorovány, vystaveny různým druhům intervence resp. budou zařazeny do kontrolní skupiny, se musí dít na základě pravděpodobnostního výběru. Replikace (opakování) – vícenásobné opakování měření umožní posoudit náhodnou variabilitu měřených veličin, a tím i určit přesnost měření. Citováno z „")
10
Blokový design, stratifikace – rozdělení experimentálních jednotek do bloků či strat, které vykazují podobné vlastnosti, umožní redukovat vliv zdrojů variability, které nejsou předmětem zkoumání. Faktoriální uspořádání – experiment může zkoumat vliv několika faktorů (různých intervencí) naráz, včetně jejich synergických efektů. Ortogonalita – faktoriální experiment má být navržen tak, aby umožňoval posoudit nezávisle vliv každého jednotlivého faktoru. Citováno z „
 naráz, včetně jejich synergických efektů. Ortogonalita – faktoriální experiment má být navržen tak, aby umožňoval posoudit nezávisle vliv každého jednotlivého faktoru. Citováno z „")
11
Deskriptivní statistika
PGS 2010 Presentace ELLA-CS, Brno, 2010, schváleno doc.ing.Josef Hanuš, CSc, přednosta Ústavu lékařské biofyziky, LFUK Hradec Králové

12
Biostatistika, Lékařská statistika
Proč: variabilita dat To není běžné v přírodních vědách (chemie, fyzika) změna barvy lakmusového papírku závisí na pH roztoku, při ponoření do kyseliny ve 100 % zčervená a nikdo nečeká, že bude jen 95 případech ze 100. Dáme-li 100 pacientům s bolestí hlavy paracetamol, neočekáváme, že všichni ucítí úlevu Budeme-li stejné osobě měřit krevní tlak za stejných podmínek s rozlišením 1 mmHg několik dní za sebou, pravděpodobnost, že dostaneme stejnou hodnotu je méně než 50 % Překrývá skutečné rozdíly nebo souvislosti Přijetí či zamítnutí předem formulované hypotézy na předem zvolené hladině pravděpodobnosti
 změna barvy lakmusového papírku závisí na pH roztoku, při ponoření do kyseliny ve 100 % zčervená a nikdo nečeká, že bude jen 95 případech ze 100. Dáme-li 100 pacientům s bolestí hlavy paracetamol, neočekáváme, že všichni ucítí úlevu. Budeme-li stejné osobě měřit krevní tlak za stejných podmínek s rozlišením 1 mmHg několik dní za sebou, pravděpodobnost, že dostaneme stejnou hodnotu je méně než 50 % Překrývá skutečné rozdíly nebo souvislosti. Přijetí či zamítnutí předem formulované hypotézy na předem zvolené hladině pravděpodobnosti.")
13
Biostatistika, Lékařská statistika
Generalizace pozorování spolehlivost zobecnění jevu pozorovaného na vybraných jedincích na definovanou populaci výběr musí být representativní náhodný každý jedinec musí mít stejnou šanci dostat se do daného výběru dostatečně velký závisí na variabilitě zkoumaných veličin a přesnosti s jakou je můžeme měřit

14
Statistika Deskriptivní (popisná) Inferenční (induktivní)
charakteristiky (statistiky) polohy, variability, presentace dat (tabulky, grafy) úplné soubory dat Inferenční (induktivní) závěry, rozhodnutí o populaci na základě pozorování vybraných jedinců populace, základní soubor, všichni jedinci, kteří splňují podmínku výskytu určujícího znaku (ů) rozsah konečný, nekonečný
 polohy, variability, presentace dat (tabulky, grafy) úplné soubory dat. Inferenční (induktivní) závěry, rozhodnutí o populaci na základě pozorování vybraných jedinců. populace, základní soubor, všichni jedinci, kteří splňují podmínku výskytu určujícího znaku (ů) rozsah konečný, nekonečný.")
15
Měrné stupnice Zkoumané znaky - proměnné veličiny, jejich hodnoty jsou data nominální - různé kategorie bez možnosti srovnání velikosti (pořadí): krevní skupiny, národnost, diagnosa; binární (pohlaví) ordinální - různé kategorie, jež lze seřadit podle velikosti (vyléčen, zlepšen, nezlepšen, zhoršen, zemřel), ale nemá cenu určovat rozdíl intervalová - rozdíl má reálný význam (teplota), nula stupnice je náhodná poměrová - reálná nula (hmotnost)
: krevní skupiny, národnost, diagnosa; binární (pohlaví) ordinální - různé kategorie, jež lze seřadit podle velikosti (vyléčen, zlepšen, nezlepšen, zhoršen, zemřel), ale nemá cenu určovat rozdíl. intervalová - rozdíl má reálný význam (teplota), nula stupnice je náhodná. poměrová - reálná nula (hmotnost)")
16
Typy dat kvalitativní - nominální
kvantitativní - intervalová a poměrová nespojitá, diskrétní - pouze celá čísla spojitá - libovolná hodnota (v určitém intervalu) vzhledem k přesnosti měření mají často charakter diskrétních (TK měřený tonometrem) ordinální - mezi i kvantitativní na ně transformujeme - mikrocyt, normocyt, makrocyt
 vzhledem k přesnosti měření mají často charakter diskrétních (TK měřený tonometrem) ordinální - mezi. i kvantitativní na ně transformujeme - mikrocyt, normocyt, makrocyt.")
17
Variabilita dat Zdroje biologická proměnlivost chyby měření
(jiný význam než v běžné mluvě – error × mistake) rozdíl hodnoty naměřené a hodnoty správné nebo populačního průměru, hrubé systematické, jednostranné metody přístroje osobní náhodné, oboustranné elementární, stejně velké, stejně pravděpodobné kladné i záporné, menší pravděpodobnější než větší, binomické rozložení, přecházející v rozdělení Gaussovo (normální)
 rozdíl hodnoty naměřené a hodnoty správné nebo populačního průměru, hrubé. systematické, jednostranné. metody. přístroje. osobní. náhodné, oboustranné. elementární, stejně velké, stejně pravděpodobné kladné i záporné, menší pravděpodobnější než větší, binomické rozložení, přecházející v rozdělení Gaussovo (normální)")
18
Výsledek měření Přesnost měření precision přesnost accuracy správnost
resolution rozlišení

19
Zápis dat 3 platné cifry - 0,1 % nejmenší zjistitelný rozdíl
TK 5 mm Hg podíl - implikuje velikost souboru platná cifra (desítky procent) platné cifry (jednotky procent) dětí - P = 0,5143
 platné cifry (jednotky procent) dětí - P = 0,5143.")
20
Charakteristiky polohy a variability
Míry polohy aritmetický průměr - populační a výběrový medián modus kvantily Míry variability variační rozpětí rozptyl, směrodatná odchylka - populační a výběrové kvantilová rozpětí

21
Míry polohy znaku Aritmetický průměr Medián Modus
může se stát, že se najde více hodnot, které se v datech vyskytují se stejnou četností rozložení bimodální, trimodální, multimodální Nejsem si jist, zda vzoreček má smysl. Asi by stačilo říci, že kvartily dělí setříděná data na 4 stejně velké (co do počtu pozorování) části, decily na 10 a percentily na 100 Excel – první hodnotu, kterou najde v případě, že rozložení je multimodální Kategorická data binární (0, 1) – ar. průměr – četnost výskytu 1 21
 části, decily na 10 a percentily na 100. Excel – první hodnotu, kterou najde v případě, že rozložení je multimodální. Kategorická data. binární (0, 1) – ar. průměr – četnost výskytu")
22
Míry polohy znaku 2 Kvantily – vzestupně setříděná data
k udává pořadové číslo (index) naměřené hodnoty q – daný kvantil, n – počet pozorování kvartily (Q = 4), decily (Q = 10), percentily (Q = 100) 15 čísel: 1. kvartil = (1 15)/4 = 3,75 1. decil = (1 15)/10 = 1,5 x4 x2 Jestliže zlomek není celé číslo, je k nejbližší vyšší celé číslo Nejsem si jist, zda vzoreček má smysl. Asi by stačilo říci, že kvartily dělí setříděná data na 4 stejně velké (co do počtu pozorování) části, decily na 10 a percentily na 100 Varianta EDF v souboru Percentile-type.doc v KIS 22
 naměřené hodnoty. q – daný kvantil, n – počet pozorování. kvartily (Q = 4), decily (Q = 10), percentily (Q = 100) 15 čísel: 1. kvartil = (1 15)/4 = 3, decil = (1 15)/10 = 1,5. x4. x2. Jestliže zlomek není celé číslo, je k nejbližší vyšší celé číslo. Nejsem si jist, zda vzoreček má smysl. Asi by stačilo říci, že kvartily dělí setříděná data na 4 stejně velké (co do počtu pozorování) části, decily na 10 a percentily na 100. Varianta EDF v souboru Percentile-type.doc v KIS. 22.")
23
Míry proměnlivosti znaku
Odchylka Populační rozptyl Výběrový rozptyl Směrodatné odchylky , s Variační koeficient Standardní chyba (aritmetického) průměru rozpětí - variační (inter)kvartilové (inter)decilové
 průměru. rozpětí - variační. (inter)kvartilové. (inter)decilové.")
24
Gaussovo rozdělení Normální, Gaussovo rozdělění dat
teoretické populační rozdělení, charakterizované populačním aritmetickým průměrem populační směrodatnou odchylkou hustota pravděpodobnosti výskytu dané hodnoty - zvonový tvar (bell shaped curve) nejčastější naměřená hodnota (nulová chyba) v intervalu ± leží 68 % všech naměřených dat v intervalu ± 1,96 × leží 95 % všech naměřených dat v intervalu ± 2,58 × leží 99 % všech naměřených dat
 nejčastější naměřená hodnota (nulová chyba) v intervalu ± leží 68 % všech naměřených dat. v intervalu ± 1,96 × leží 95 % všech naměřených dat. v intervalu ± 2,58 × leží 99 % všech naměřených dat.")
25
z transformace Vzhledem k používání z a t skóru v kostní densitometrii asi zmínit z skór 25

26
Standardizovaná Gaussova křivka
Spíš jen zmínit proč se dělá standardisace, na vzoreček ať zapomenou 26

27
Distribuční funkce

28
Hustotní funkce

29
Vlastnosti Nejčastěji používanými charakteristikami polohy a variability jsou průměr a směrodatná odchylka oprávněné pouze tehdy, jestliže můžeme předpokládat Gaussovo rozložení dat spojitá veličina, ležící v intervalu –, + biologické veličiny toto rozdělení v podstatě mít nemohou. V příznivém případě nemůžeme prokázat, že se od něj významně liší nejedná-li se o tyto případy, lepšími (správnějšími) charakteristikami polohy a variability jsou medián, modus a (různá) rozpětí
 charakteristikami polohy a variability jsou medián, modus a (různá) rozpětí.")
30
Unimodální sešikmená rozložení

31
Symetrická, ale též odchýlená
Špičatost (kurtosis) plošší - platykurtická užší - leptokurtická d’Agostinův Omnibus test
 plošší - platykurtická. užší - leptokurtická. d’Agostinův Omnibus test.")
32
Bimodální rozložení

33
lepto- a platy- kurtické rozdělení

34
t-rozdělení,Studentovo
tvar závisí na počtu stupňů volnosti df (degrees of freedom)
")
35
Meze spolehlivosti bodový x intervalový odhad
95% interval spolehlivosti aritmetického průměru

36
Tabulka s popisnou statistikou
Proměnná n min max AP DMS HMS M distr věk 26 52 84 71 67 75 70 NG vizus 0,01 0,40 0,20 0,16 0,24 0,15 0,25 G n – počet pacientů, min – minimální hodnota, max – maximální hodnota, AP – aritmetický průměr, DMS, HMS – 95% dolní a horní interval spolehlivosti, M – medián, distr – rozložení G – Gaussovo, NG – negaussovské Zvláštní pozornost je třeba věnovat počtu platných cifer jednotlivých veličin a v celé tabulce tento počet zachovávat

37
Testování hypotéz PGS 2010

38
Testování hypotéz Odpověď na otázku (tou by měl každý projekt začít):
Je chirurgická léčba (Parkinsonovy choroby) lepší (úspěšnější) než léčba medikamentózní? Je nový lék účinnější než starý? Má méně vedlejších účinků? Existuje spojitost (asociace) mezi dávkou léku a velikostí odezvy (poklesem krevního tlaku)? Je výsledek daného vyšetření u nemocných s danou chorobou jiný (častější, méně častý) než u zdravých jedinců?
 lepší (úspěšnější) než léčba medikamentózní Je nový lék účinnější než starý Má méně vedlejších účinků Existuje spojitost (asociace) mezi dávkou léku a velikostí odezvy (poklesem krevního tlaku) Je výsledek daného vyšetření u nemocných s danou chorobou jiný (častější, méně častý) než u zdravých jedinců")
39
Testování hypotéz vědecká, výzkumná hypotéza
prokázat s přiměřenou mírou spolehlivosti, za rámec rozumných pochybností, zda tuto hypotézu můžeme přijmout či zamítnout to je většinou nemožné všechny čínské děti jsou černovlasé i když uděláme velký výběr (103, 106) a všichni jsou skutečně černovlasí, ještě to naši hypotézu nedokazuje najdeme-li jediného blonďáka, tak můžeme (musíme) hypotézu zamítnout logicky jednodušší je tedy formulovat hypotézu zamítající určitou hypotézu než hypotézu potvrzující to je základem statistických hypotéz
 a všichni jsou skutečně černovlasí, ještě to naši hypotézu nedokazuje. najdeme-li jediného blonďáka, tak můžeme (musíme) hypotézu zamítnout. logicky jednodušší je tedy formulovat hypotézu zamítající určitou hypotézu než hypotézu potvrzující. to je základem statistických hypotéz.")
40
Testování hypotéz statistická hypotéza
chirurgická léčba není lepší než léčba medikamentózní nový lék není účinnější než starý, nemá méně vedlejších účinků neexistuje spojitost mezi dávkou léku a velikostí odezvy výsledek daného vyšetření není jiný než u zdravých jedinců kvantifikuje spolehlivost, pochybnost. Určuje pravděpodobnost skutečnosti, že správná (platná) hypotéza bude zamítnuta nebo špatná (neplatná) přijata
 hypotéza bude zamítnuta nebo špatná (neplatná) přijata.")
41
Testování hypotéz – příklad
chceme srovnat účinnost dvou léků na hypertenzi ze skupiny 100 hypertoniků jich 50 náhodně zařadíme do skupiny léčené lékem A a druhých 50 budeme léčit lékem B za rozumnou míru účinnosti obou preparátů můžeme považovat hodnotu TK, zjištěnou v obou skupinách po třech měsících za předpokladu gaussovského rozložení dat v obou souborech, výsledek vyjádříme pomocí průměrů a směrodatných odchylek TK v obou skupinách

42
Testování hypotéz – příklad, pokračování
za předpokladu gaussovského rozložení dat v obou souborech, výsledek vyjádříme pomocí průměrů a směrodatných odchylek TK v obou skupinách statistickou hypotézu formulujeme tak, že není rozdíl mezi µA a µB, tj., že µA = µB neboli, že µA - µB = 0

43
Testování hypotéz – příklad
problém je, že populační průměry neznáme a k výpočtu musíme použít charakteristiky výběrové (průměry a standardní chyby průměrů) statistika dává návod k odhadu pravděpodobnosti, že µA - µB = 0
 statistika dává návod k odhadu pravděpodobnosti, že µA - µB = 0.")
44
Nulová (null) hypotéza - H0
srovnávané parametry (statistické charakteristiky) jsou stejné jejich rozdíl je roven nule nemůžeme-li ji zamítnout, plyne z toho, že se v provedeném experimentu nepodařilo na zvolené hladině významnosti prokázat rozdíl srovnávaných charakteristik předem zvolená hladina významnosti (nulové hypotézy) se označuje α obvykle se volí 0,05 (5 %), 0,01 (1 %) není to však důkaz, že srovnávané charakteristiky jsou shodné takže formulace zní: nezamítáme nulovou hypotézu ne vždy nežádoucí: Ovlivňuje provoz jaderné elektrárny délku života v okolí do vzdálenosti x km?
 jsou stejné jejich rozdíl je roven nule. nemůžeme-li ji zamítnout, plyne z toho, že se v provedeném experimentu nepodařilo na zvolené hladině významnosti prokázat rozdíl srovnávaných charakteristik. předem zvolená hladina významnosti (nulové hypotézy) se označuje α. obvykle se volí 0,05 (5 %), 0,01 (1 %) není to však důkaz, že srovnávané charakteristiky jsou shodné. takže formulace zní: nezamítáme nulovou hypotézu. ne vždy nežádoucí: Ovlivňuje provoz jaderné elektrárny délku života v okolí do vzdálenosti x km")
45
Hypotéza alternativní - HA, H1
přijímáme ji, můžeme-li zamítnout hypotézu nulovou oboustranná - srovnávané charakteristiky jsou různé jednostranná - a) první je větší než druhá b) první je menší než druhá mělo by být stanoveno před tím, než je výsledek testu znám a měl by existovat racionální důvod pro její formulaci (někteří statistici principiálně použití jednostranné alternativní hypotézy odmítají) Statistický test počítá tzv. testové kritérium T, jehož hodnota je hodnota kvantilu rozdělení nějaké veličiny (nejčastěji Studentova, t).
 první je větší než druhá b) první je menší než druhá. mělo by být stanoveno před tím, než je výsledek testu znám a měl by existovat racionální důvod pro její formulaci (někteří statistici principiálně použití jednostranné alternativní hypotézy odmítají) Statistický test počítá tzv. testové kritérium T, jehož hodnota je hodnota kvantilu rozdělení nějaké veličiny (nejčastěji Studentova, t).")
46
Hypotéza alternativní - HA, H1
Výsledek srovnáváme v případě oboustranné alternativní hypotézy s hodnotou kvantilu pro pravděpodobnost 1 – α/2 v případě jednostranné alternativní hypotézy s hodnotou kvantilu pro pravděpodobnost 1 – α jestliže T ≥ hodnotě korespondujícího kvantilu, říkáme, že T leží mimo obor přijetí nulové hypotézy a zamítáme ji pravděpodobnost, příslušející k hodnotě T se nazývá p-hodnota jestliže p-hodnota ≤ α nulovou hypotézu zamítáme při zamítnutí nulové hypotézy se uvede její hladina významnosti α v podstatě to znamená, že alternativní hypotéza je přijata na hladině významnosti 1 − α Rozdíl mezi α a p je v tom, že první pravděpodobnost se určuje před začátkem testování, zatímco druhá je výsledkem výpočtu testového kritéria

47
Parametrické testy srovnávájí různé statistické charakteristiky dat majících Gaussovo rozdělení nemůžeme zamítnout nulovou hypotézu, že data pocházejí z populace, která má Gaussovo rozdělení na začátku je proto nutné otestovat normalitu dat ve výběru D‘Agostino Omnibus výběrový průměr (zjištěnou hodnotu) s populačním jednovýběrový test hypotézy o průměru dva (nebo více) výběrových průměrů nepárový t-test, ANOVA rozdíly hodnot stejné veličiny (hladiny léku v krvi) zjištěné za různých podmínek (za 4 a 8 h po podání, různou metodou) u stejných jedinců párový t-test výběrové rozptyly F-test koeficienty modelů (regrese, korelace)
 s populačním. jednovýběrový test hypotézy o průměru. dva (nebo více) výběrových průměrů. nepárový t-test, ANOVA. rozdíly hodnot stejné veličiny (hladiny léku v krvi) zjištěné za různých podmínek (za 4 a 8 h po podání, různou metodou) u stejných jedinců. párový t-test. výběrové rozptyly. F-test. koeficienty modelů (regrese, korelace)")
48
Testování hypotéz Hladina významnosti
pravděpodobnost, že zamítneme H0 i když je platná chyba I. druhu, 0,05 = 5% = *, 0,01 = 1% = **, 0,001 = 1‰ = ***

49
Testování hypotéz srovnáváme hodnotu testového kritéria s hodnotou příslušného kvantilu odpovídajícího rozdělení v uvedeném příkladu s rozdělením Gaussovým = 0,05 0, ,001 pro jednostrannou alternativní hypotézu (1 - ) 0, , ,999 1, , ,09 pro oboustrannou alternativní hypotézu (1 - /2) , , ,9995 1, , ,29
 0,95 0,99 0,999. 1,64 2,33 3,09. pro oboustrannou alternativní hypotézu (1 - /2) 0,975 0,995 0, ,96 2,58 3,29.")
50
Testování hypotéz pravděpodobnost, že přijmeme nulovou hypotézu i když je neplatná chyba II. druhu, (1 - ) je tzv. síla (power) testu. Je mírou jeho robustnosti, tj. citlivosti na splnění předpokladů Např. jaký bude výsledek testu, když testovaná veličina je diskrétní a ne spojitá, data nemají normální rozdělení ap. je spojena se zvolenou hodnotou hladiny významnosti. Čím je hladiny významnosti menší ( je větší), tím je též síla testu menší J. Knížek, P. Stránský: Příspěvek k nápravě opomíjení významu síly testů ve studiích z experimentální medicíny, ČLČ, 144, 2005, č. 2, s.: 56 – 58. Skutečný stav Výsledek testu H0 je platná H0 je neplatná Přijmi H0 správně chyba Zamítni H0 chyba správně
 je tzv. síla (power) testu. Je mírou jeho robustnosti, tj. citlivosti na splnění předpokladů. Např. jaký bude výsledek testu, když testovaná veličina je diskrétní a ne spojitá, data nemají normální rozdělení ap. je spojena se zvolenou hodnotou hladiny významnosti. Čím je hladiny významnosti menší ( je větší), tím je též síla testu menší. J. Knížek, P. Stránský: Příspěvek k nápravě opomíjení významu síly testů ve studiích z experimentální medicíny, ČLČ, 144, 2005, č. 2, s.: 56 – 58. Skutečný stav. Výsledek testu H0 je platná H0 je neplatná. Přijmi H0 správně chyba Zamítni H0 chyba správně.")
51
Testování hypotéz Presumpce neviny Věřím svědkům?
Jsou důkazy ve shodě s presumpcí neviny? Nejsou-li, zamítni předpoklad neviny a oznam obžalovanému, že je vinen chyba - odsouzení nevinného chyba - osvobození viníka Platí H0 Jsou data v pořádku? Vypočti testové kritérium Je-li jeho hodnota větší nebo rovna hodnotě kritické, zamítni H0 a přijmi HA

52
Jednovýběrový t-test hypotézy o průměru
df = n - 1 T – testové kritérium kritická hodnota t()
")
53
Párový t-test H0 – rozdíly mezi údaji ze dvou srovnávaných měření se rovnají 0 test normality se provádí pro rozdíly; původní data nemusejí mít Gaussovo rozložení df = n - 1

54
Nepárový (dvouvýběrový) t-test
Srovnání dvou výběrových průměrů df = n1 + n2 - 2 H0: průměry jsou stejné; jejich rozdíl je roven 0 HA oboustranná – průměry nejsou stejné HA jednostranná průměr prvního výběru je menší než průměr druhého výběru průměr prvního výběru je větší než průměr druhého výběru Test shody rozptylů – F test oboustranná alternativní hypotéza podle výsledku zvolíme druh nepárového t-test v případě neshody rozptylů (zamítneme H0 v F testu) je počet stupňů volnosti menší než n1 + n2 – 2 a většinou to není celé číslo
 je počet stupňů volnosti menší než n1 + n2 – 2 a většinou to není celé číslo.")
55
Korelace a regrese Vztah (závislost, asociace) dvou a více veličin
závisle proměnná - (vysvětlovaná), y nezávisle proměnná(é) - (vysvětlující), xi hladina alkoholu v krvi - množství vypitého alkoholu, pravděpodobnost infarktu - STK, BMI, cholesterolemie, množství vykouřených cigaret korelace - síla závislosti - positivní, negativní regrese - typ závislosti, určení hodnoty závisle proměnné, známe-li velikost nezávisle proměnné 55
, y. nezávisle proměnná(é) - (vysvětlující), xi. hladina alkoholu v krvi - množství vypitého alkoholu, pravděpodobnost infarktu - STK, BMI, cholesterolemie, množství vykouřených cigaret. korelace - síla závislosti - positivní, negativní. regrese - typ závislosti, určení hodnoty závisle proměnné, známe-li velikost nezávisle proměnné. 55.")
56
Korelace určení, která proměnná je závislá a která je nezávislá je z matematického hlediska nepodstatné, nerozlišitelné. Z logického je to často konvence (výška, hmotnost - věk, hmotnost - věk, tlak - objem) míra vazby mezi dvěma veličinami (za předpokladu linearity daného vztahu) je dána kovariancí (průměr součtu součinů odchylek obou proměnných) - formální obdoba rozptylu, má však jiný (fyzikální) rozměr 56
 míra vazby mezi dvěma veličinami (za předpokladu linearity daného vztahu) je dána kovariancí (průměr součtu součinů odchylek obou proměnných) - formální obdoba rozptylu, má však jiný (fyzikální) rozměr. 56.")
57
Jsou-li veličiny x a y nezávislé pak r = 0
Korelace normalisovanou (standardisovanou) mírou síly, těsnosti vztahu je Pearsonův korelační koeficient r () kovariance dělená –1, +1 ABS (r) = 1 - funkční, deterministický vztah Jsou-li veličiny x a y nezávislé pak r = 0 57
 mírou síly, těsnosti vztahu je. Pearsonův korelační koeficient r () kovariance dělená. –1, +1 ABS (r) = 1 - funkční, deterministický vztah. Jsou-li veličiny x a y nezávislé pak r =")
58
Korelace problém je, že neplatí opačná implikace
není obecně pravda, že je-li r = 0, že x a y jsou nezávislé [y = ABS (x)] x y 58
] x y")
59
Korelace ve speciálních případech (obě proměnné mají Gaussovo rozložení) to však platí je-li r = 0, pak x a y jsou nezávislé 0 < r < 0,1 - nezávislé 0,1 < r < 0,3 - slabá 0, 3 < r < 0,6 - střední 0,6 < r < 0,9 - silná r > 0,9 - velmi silná 59

60
Korelace 60

61
Pozitivní a negativní 61

62
62

63
Korelace Obě veličiny mají Gaussovo rozložení
H0 - r = 0; veličiny jsou nezávislé HA - r 0; veličiny jsou závislé p ≤ 0,05 - přijímáme alternativní hypotézu, neznamená to však, že jde o příčinný vztah. Závisí silně na velikosti souboru Obě veličiny mají Gaussovo rozložení Závislost mezi proměnnými je lineární 63

64
Regrese nalezení vhodného funkčního vztahu (vzorce, rovnice), popisujícího závislost mezi proměnnými jednoduchá (jedna nezávislá), vícenásobná lineární (y = x + ), nelineární jednorovnicová (jedna závislá), vícerovnicová Jednoduchá lineární regrese yi = xi + + i i – náhodná chyba yi – naměřěná hodnota – – vypočtená hodnota 64
, vícenásobná. lineární (y = x + ), nelineární. jednorovnicová (jedna závislá), vícerovnicová. Jednoduchá lineární regrese. yi = xi + + i. i – náhodná chyba. yi – naměřěná hodnota. – – vypočtená hodnota. 64.")
65
Regrese ri = yi - – residuum
používá se při rozhodování jak se vypočtou koeficienty regresní rovnice (, ) = min - metoda nejmenších čtverců, MNČ ABS ri = min - méně citlivé na extrémní hodnoty odhady koeficientů , se nazývají parametry regresní přímky b – regresní koeficient – směrnice regresní přímky (tg ) a – absolutní člen – hodnota y pro x = 0 (někdy se i tento člen nazývá regresním koeficientem) 65
 = min - metoda nejmenších čtverců, MNČ. ABS ri = min - méně citlivé na extrémní hodnoty. odhady koeficientů , se nazývají parametry regresní přímky. b – regresní koeficient – směrnice regresní přímky (tg ) a – absolutní člen – hodnota y pro x = 0. (někdy se i tento člen nazývá regresním koeficientem) 65.")
66
Regrese koeficient determinace - r2 (r square) - vysvětluje jaká část variability závisle proměnné (y) je způsobena nezávisle proměnnou vynásoben 100 udává % rozptylu vysvětlené regresí. Zbytek do 100 % je způsoben chybou znaménko korelačního koeficientu - SQRT (r2) je shodné se znaménkem regresního koeficientu b H0 – b = 0; ekvivalentní r = 0 HA – b 0 H0 – a = 0; regresní přímka prochází počátkem. Víme-li to předem, je nutné zadat při výpočtu 66
 je shodné se znaménkem regresního koeficientu b. H0 – b = 0; ekvivalentní r = 0. HA – b 0. H0 – a = 0; regresní přímka prochází počátkem. Víme-li to předem, je nutné zadat při výpočtu. 66.")
67
67

68
Regrese Předpoklady chyby mají Gaussovo rozdělení chyby mají stejný rozptyl (homoskedascita) vysvětlující (nezávislá) proměnná je nenáhodná (experimentátor může její hodnotu zvolit) pro predikci hodnot lze použít hodnoty nezávisle proměnné pouze z intervalu, ve kterém se nacházely hodnoty, ze kterých byly parametry regresní přímky počítány Lineární kalibrace - z hodnoty závisle proměnné se určuje nezávisle proměnná 68
 proměnná je nenáhodná (experimentátor může její hodnotu zvolit) pro predikci hodnot lze použít hodnoty nezávisle proměnné pouze z intervalu, ve kterém se nacházely hodnoty, ze kterých byly parametry regresní přímky počítány. Lineární kalibrace - z hodnoty závisle proměnné se určuje nezávisle proměnná. 68.")
69
69

70
Regrese Bodový graf (scattergram) Transformace y‘ = SQRT y y‘ = log y
nelinearita heteroskedascita y‘ = SQRT y y‘ = log y y‘ = 1/y x‘ = SQRT x x‘ = log x x‘ = 1/x 70

71
Biostatistika a e-learning na Lékařské fakultě UK v Hradci Králové
Univerzita Karlova v Praze Lékařská fakulta v Hradci Králové Ústav lékařské biofyziky Biostatistika a e-learning na Lékařské fakultě UK v Hradci Králové Josef Hanuš, Josef Bukač, Iva Selke-Krulichová, Pravoslav Stránský, Jiří Záhora MEFANET 2009 centralizovaný rozvojový projekt MŠMT c15/2009

72
Biostatistika - kdy, koho a jak
magisterské studium 1. ročník, zimní semestr Biofyzika a biostatistika 41/69 Zk teorie (přednášky a semináře) 4/12 praktika na PC učebně (excel) 3+3 statistické zpracování laboratorních výsledků – 5 úloh doktorské studium společná povinná výuka 1. ročník týdenní intenzivní kurz přednášky 10 h praktika na PC učebně (excel) – navíc nepovinné 3 h
 4/12. praktika na PC učebně (excel) 3+3. statistické zpracování laboratorních výsledků – 5 úloh. doktorské studium. společná povinná výuka 1. ročník. týdenní intenzivní kurz. přednášky 10 h. praktika na PC učebně (excel) – navíc nepovinné 3 h.")
73
Analýza stavu - dotazníky
magisterské studium téměř nulové vstupní znalosti malá hodinová dotace bez možnosti navýšení rozdílná počítačová gramotnost (excel) doktorské studium rozdílné vstupní znalosti malá hodinová dotace bez možnosti navýšení rozdílná počítačová gramotnost (excel) rozdílné výstupní požadavky
 doktorské studium. rozdílné vstupní znalosti. malá hodinová dotace bez možnosti navýšení. rozdílná počítačová gramotnost (excel) rozdílné výstupní požadavky.")
74
Nová koncepce výuky statistiky (2009-10)
srovnání vstupních znalostí a dovedností individuální víceúrovňová forma výuky podpora e-learning kurzy magisterské studium „náročná témata“ – klasická seminární výuka, studenty preferována „jednodušší témata“ – řízené prezenční samostudium s využitím e-learning kurzů PC učebna v rámci rozvrhu, prezence on-line komunikace s učitelem (spolužáky) interaktivní přístup, řešení úkolů „pomocná témata“ (počítačová gramotnost) – neřízené prezenční či distanční samostudium, e-learning kurzy doktorské studium dvouúrovňová forma výuky (1. úroveň je prerekvizitou pro 2. úroveň) 1. úroveň – srovnání vstupních znalostí neřízené distanční samostudium zadaných témat s využitím e-learning kurzů témata – základní pojmy, přesnost a chyby měření, popisná statistika, pravděpodobnost ověření znalostí závěrečným testem (prakticky zaměřeno) 2. úroveň – klasická výuka v rámci týdenního soustředění 10 h přednášky (induktivní statistika) praktické počítání vzorových zadání na PC učebně (excel) praktická ústní zkouška
 interaktivní přístup, řešení úkolů. „pomocná témata (počítačová gramotnost) – neřízené prezenční či distanční samostudium, e-learning kurzy. doktorské studium. dvouúrovňová forma výuky (1. úroveň je prerekvizitou pro 2. úroveň) 1. úroveň – srovnání vstupních znalostí. neřízené distanční samostudium zadaných témat s využitím e-learning kurzů. témata – základní pojmy, přesnost a chyby měření, popisná statistika, pravděpodobnost. ověření znalostí závěrečným testem (prakticky zaměřeno) 2. úroveň – klasická výuka v rámci týdenního soustředění 10 h. přednášky (induktivní statistika) praktické počítání vzorových zadání na PC učebně (excel) praktická ústní zkouška.")
75
Forma a obsah e-learning kurzů statistiky
předpoklady nulové vstupní znalosti statistiky využití pouze středoškolské matematiky (důkazy, odvození, …) využití možností prostředí LMS Moodle, každý kurz se skládá ze „studijních materiálů“ a „činností“ struktura kurzu kurz = kapitola ze statistiky jednotná struktura kurzů, členění na bloky tříúrovňový jednotné členění bloků – souhrn – výklad - příklady forma a obsah bloků kurzu souhrn – „studijní materiál“ webovská stránka obsah tématu stručně a jasně na jednu stránku určeno pro opakování, osvěžení znalostí výklad – „studijní materiál“ kniha (tisk) ucelený rozsáhlý výklad tématu vzorce, důkazy, odvození, ilustrativní úlohy a řešení příklady – „činnost“ přednáška (interaktivní komunikace, kontrola, řízení, …) jednotná interaktivní struktura příkladů výběr ze seznamu příkladů volba „vzorové řešení“ – ukázka správného výpočtu volba „zkusím to sám“ - libovolná forma nabídky řešení a analýza odpovědí appendix kurzu test – „činnost“ test, kontrola znalostí z daného kurzu otázky mnohočetného výběru přiřazování dlouhá a krátká tvořená odpověď numerická úloha pravda/nepravda slovník – „činnost“ slovník, definice pojmů, synonyma, anglický (německý) ekvivalent chat – „činnost“ chat, komunikace účastníků kurzu
 využití možností prostředí LMS Moodle, každý kurz se skládá ze „studijních materiálů a „činností struktura kurzu. kurz = kapitola ze statistiky. jednotná struktura kurzů, členění na bloky. tříúrovňový jednotné členění bloků – souhrn – výklad - příklady. forma a obsah bloků kurzu. souhrn – „studijní materiál webovská stránka. obsah tématu stručně a jasně na jednu stránku. určeno pro opakování, osvěžení znalostí. výklad – „studijní materiál kniha (tisk) ucelený rozsáhlý výklad tématu. vzorce, důkazy, odvození, ilustrativní úlohy a řešení. příklady – „činnost přednáška (interaktivní komunikace, kontrola, řízení, …) jednotná interaktivní struktura příkladů. výběr ze seznamu příkladů. volba „vzorové řešení – ukázka správného výpočtu. volba „zkusím to sám - libovolná forma nabídky řešení a analýza odpovědí. appendix kurzu. test – „činnost test, kontrola znalostí z daného kurzu. otázky mnohočetného výběru. přiřazování. dlouhá a krátká tvořená odpověď. numerická úloha. pravda/nepravda. slovník – „činnost slovník, definice pojmů, synonyma, anglický (německý) ekvivalent. chat – „činnost chat, komunikace účastníků kurzu.")
76
Seznam kurzů biostatistiky
základní kurzy K1 – Základní statistické pojmy K5 – Vlastnosti, přesnost a chyby měření K3 – Popisná statistika K4 – Pravděpodobnost K5 – Induktivní statistika doplňkové kurzy K0 - Co tu najdete a jak na to idea kurzů a zásady jejich používání, podrobná osnova K7 - Statistické programy návod jak řešit příklady kurzů pomocí statistických programů související kurzy a studijní materiály v Moodle Základy efektivního používání počítače Úvod do MS Excel 2003 Excel – statistika Přednášky

77
Programové a technické zabezpečení, přístup
LMS Moodle 3 PC učebny – celkem cca 60 ks počítačů 2 PC učebny - plánovány do rozvrhu, volný přístup mimo rozvrh 1 PC učebna – volný přístup 6,00 až 24,00 kde kurzy najdete: - česká verze - anglická verze (v přípravě) klíč: „stat“
 klíč: „stat")
78
Ukázky z kurzů (off line)
bloky souhrn výklad příklady

79
Ukázky z kurzů

80
Ukázky z kurzů - příklady

81
Presentace poskytnuta se svolením doc. Ing. J.Hanuše, CSc, 2010
Co dál? analýza zkušeností, zpětná vazba dokončení, nová témata případové studie on-line počítání „přinesených“ dat hledání spolupráce otevřený systém Presentace poskytnuta se svolením doc. Ing. J.Hanuše, CSc, 2010

Podobné prezentace

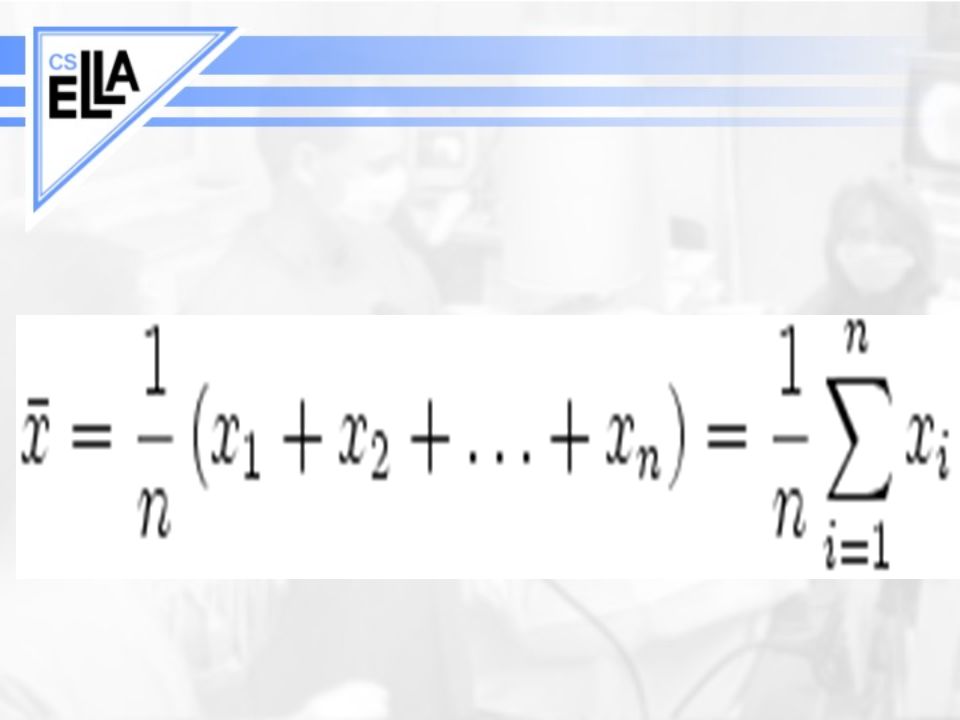
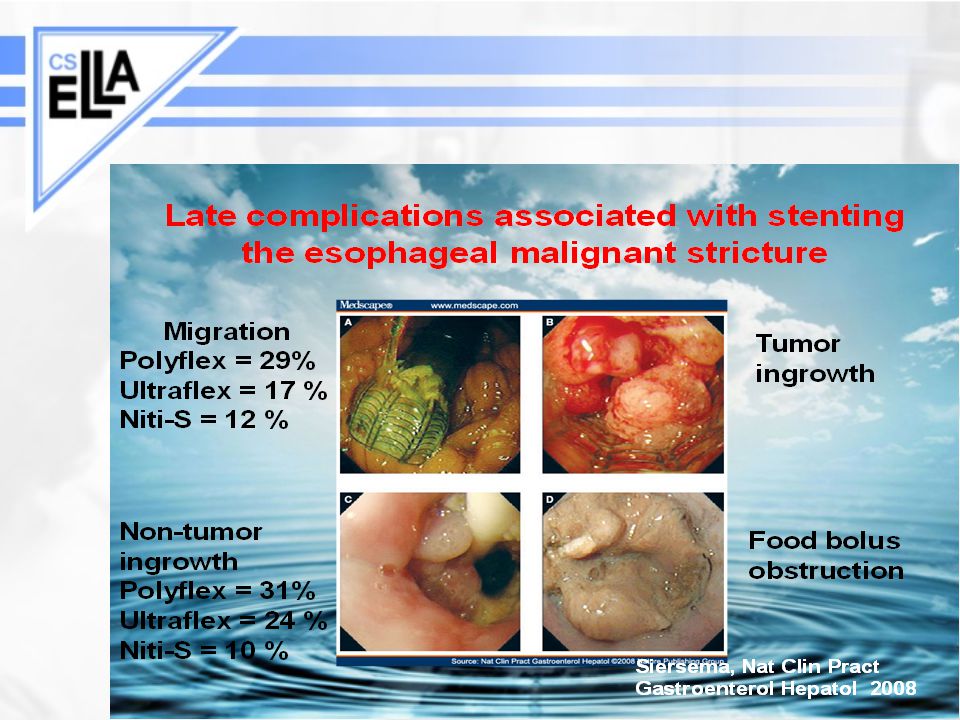











>")

 závislosti dvou náhodných veličin: korelace symetrický vztah obou veličin neslouží k předpovědi způsob (tvar) závislosti.>")



>")



