Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Kódy

2
Základní používané pojmy a názvosloví Abychom mohli vůbec hovořit o kodérech, je nutno probrat nejpoužívanější kódy, o jejich tvorbě, vlastnostech a použití. Nejprve si musíme definovat nebo objasnit základní pojmy, které se budou v následující kapitole používat. Kód je soubor znaků a pravidel k zaznamenávání informací, nebo-li soubor pravidel podle kterých se tvoří značky nebo sestava převodních vztahů mezi dvěmi abecedami. Kódování je převod informací do formalizovaného tvaru. Nejčastěji je tím míněno převádění desítkových čísel na jejich dvojkové ekvivalenty. Dekódování je převod informace z formalizovaného do původního tvaru Kodér je zařízení pro kódování Dekodér je zařízení pro dekódování

3
Znak je písmeno, číslice, interpunkční nebo rozdělovací znaménko obsažené ve zprávě. Kromě těchto znaků mohou existovat znaky pro speciální povely a některé řídící funkce. Značka je abstraktní nebo fyzikální obraz znaku složený z prvků. Abeceda je dohodnutá množina znaků nebo značek. Kapacita kódu je maximální počet značek, které lze v tom kterém kódu vytvořit. Zpráva je sestava prvků nebo znaků nesoucí ucelenou informaci. Bezpečnostní kód je souhrnné označení pro detekční a korekční kód. Je to kód umožňující zvýšit pravděpodobnost správnosti přenosu a vyhodnocení číslicového signálu na základě informační nadbytečnosti.

4
Detekční kód je nadbytečný kód umožňující zjistit určité chyby. Korekční kód je nadbytečný kód umožňující zjistit a opravit určité chyby. Nadbytečný kód je n prvkový kód, u něhož se využívá méně, než je jeho kapacita (počet symbolů je menší než maximálně možný počet značek pro daný počet bitů). Systematický kód je bezpečnostní kód, u kterého lze rozpoznat zabezpečovací značky (v jeho značkách lze rozlišit informační a zabezpečovací prvky). Nesystematický kód je bezpečnostní kód u kterého nelze rozpoznat zabezpečovací prvky (bity). Informační prvek je signálový prvek závislý jen na původní přenášené informaci.
. Systematický kód je bezpečnostní kód, u kterého lze rozpoznat zabezpečovací značky (v jeho značkách lze rozlišit informační a zabezpečovací prvky). Nesystematický kód je bezpečnostní kód u kterého nelze rozpoznat zabezpečovací prvky (bity). Informační prvek je signálový prvek závislý jen na původní přenášené informaci..")
5
Chybný prvek je signálový nebo kódový prvek, jehož přijatá hodnota nesouhlasí s výslednou. Chybná značka je blok informací obsahující alespoň jeden chybný prvek. Shluk chyb je skupina chybných bitů oddělená méně než 10ti dobrými bity.

6
Kódy Kódy používané v současné době byly vyvinuty proto, aby se odstranilo nebo alespoň zmenšilo nebezpečí rušení při přenosech informací, či pomocí kódu je umožněna komunikace například s počítačem. Jiné kódy se používají pro zamezení úniku informací a podobně. Kódy se dělí na : běžné nezabezpečené: desítkové binární BCD 3N+2 N+3 Aikenův kód 5421

7
74-2-1 další reflexní zabezpečovací detekční primitivní s jednoduchou paritou inerační polynomické kód N z M korekční cyklický

8
Hammingův speciální ASCII ostatní standardní transparentní

9
Kódy nezabezpečené

10
Desítkové kódy Binární kód Jedním z hlavních kódů je přímý dvojkový kód (binární), v němž je desítkové číslo vyjádřeno ve dvojkové soustavě. číslo 12 10 = 1100 2 Je to kód, který jednoznačně přiřazuje k dané informaci (např. číslici) kombinaci pouze 2 různých znaků 0 a 1 nebo dvouhodnotový signál. Tato kombinace má libovolný počet těchto elementárních znaků 0 a 1. Binární kód se používá velmi často v číslicových obvodech k vyjádření dekadických čísel (např. BCD kód). Informace, k níž přiřazujeme kombinaci binárních znaků může být : - číslice - písmeno - libovolný znak nebo jiná dohodnutá informace. Tento kód byl vlastně již vysvětlen při výkladu převodu čísel z dekadické soustavy do soustavy binární.
 kombinaci pouze 2 různých znaků 0 a 1 nebo dvouhodnotový signál. Tato kombinace má libovolný počet těchto elementárních znaků 0 a 1. Binární kód se používá velmi často v číslicových obvodech k vyjádření dekadických čísel (např. BCD kód). Informace, k níž přiřazujeme kombinaci binárních znaků může být : - číslice - písmeno - libovolný znak nebo jiná dohodnutá informace. Tento kód byl vlastně již vysvětlen při výkladu převodu čísel z dekadické soustavy do soustavy binární..")
11
Příklad: V čísle 10111001(2) se 1 nachází na pozici s váhou 27, potom 25, 24, 23 a pak až 20. Výsledné desítkové číslo tedy dostaneme sečtením těchto vah : 10111001 (2) = 27 + 25 + 24 + 23 + 20 = 128 + 32 +16 + 8 + 1 = 185 (10)
 = = = 185 (10).")
12
Kód BCD Z desítkových kódů je to nejjednodušší kód. Je to binární váhový kód, u něhož se využívá prvních 10ti stavů a ostatních 6 se vynechává. Je výhodný pro různé aplikace, ale nevýhodný například pro sčítání. Při sčítání je totiž nezbytná korekce při překročení čísla 9 a je obtížné určit, kdy korekci použít. Označení BCD je zkratka anglického názvu Binary Coded Decimal - neboli binárně kódovaná desítková čísla. Tento kód spojuje dobré vlastnosti jak dvojkového kódu (používá pouze 2 znaků - 0 a 1), tak desítkového (počítá se s ním jako s desítkovým, na který jsme zvyklí). Z těchto důvodů je BCD kód jeden z nejčastěji používaných kódů a budeme se s ním ještě mnohokrát setkávat i při praktických aplikacích.
, tak desítkového (počítá se s ním jako s desítkovým, na který jsme zvyklí). Z těchto důvodů je BCD kód jeden z nejčastěji používaných kódů a budeme se s ním ještě mnohokrát setkávat i při praktických aplikacích..")
13
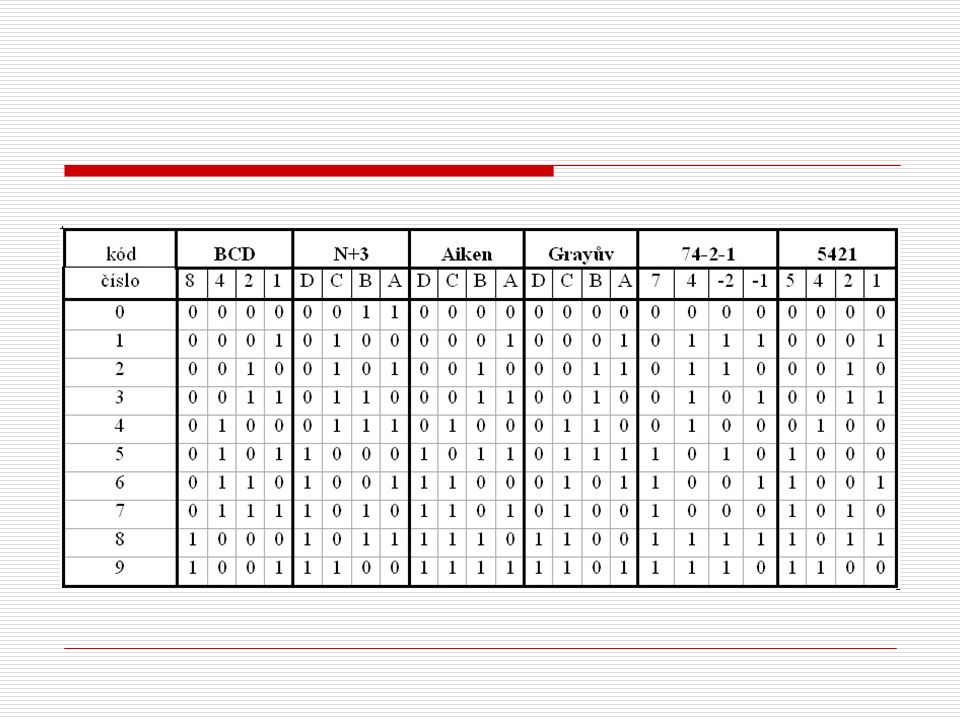
BCD kód spočívá v tom, že se každé dekadické číslici 0 až 9 přiřadí čtyřmístná kombinace dvojkových znaků 0 a 1 s váhami: 8 - 4 - 2 - 1 to znamená, že každou jednotlivou číslici vyjádříme v čistém dvojkovém kódu. Celý BCD kód je v tabulce 4.1. Mezi každou 4bitovou skupinou je vynecháno místo, abychom se vyhnuli záměně kódu BCD s čistě dvojkovým kódem.Největší výhoda tohoto kódu je ta, že se těchto 10 kombinací kódu BCD dá snadno zapamatovat, takže po krátké době s ním můžeme pracovat tak, jako jsme zvyklí na práci s čísly dekadické soustavy.

14
Příklad: Číslo 1234567890 je zapsáno následovně: číslo v dekadickém kódu 1 2 3 4 5 6 7 8 9 0 0001 0010 0011 0100 0101 0110 0111 1000 1001 0000 číslo v kódu BCD

16
Kód 3N+2 Jedná se o 5bitový kód pro zobrazení desítkových čísel. Číslici n (0, 1,..9) je přiřazeno číslo 3n+2 a toto číslo je vyjádřeno dvojkově. Používá u některých číslicových počítačů. Příklad: Číslo 7 se vyjádří v kódu 3n+2 takto : (7 x 3) + 2 = 23 => 10111
 je přiřazeno číslo 3n+2 a toto číslo je vyjádřeno dvojkově. Používá u některých číslicových počítačů. Příklad: Číslo 7 se vyjádří v kódu 3n+2 takto : (7 x 3) + 2 = 23 =>")
17
Kód N+3 Kód N+3 je samokomplementární neváhový kód (samokomplementární kód je takový kód u něhož se se změnou všech bitů čísla získá devítkový doplněk odpovídajícího čísla), jehož binární číslice B = D + 3, kde D je dekadická číslice, která je spolu s číslem 3 v binární formě. Využívá se u něho 10 ze 16ti stavů. V porovnání s binárním kódem vynechává na počátku a na konci vždy 3 stavy. Jinak binární kód sleduje. Pro sčítání je vhodnější než kód 8421, nicméně i tento kód potřebuje korekce.

18
Aikenův kód Aikenův kód, nebo též kód 2421 je samokomplementární váhový kód využívající prvních a posledních 5 stavů binárního kódu. Je velmi vhodný pro sčítání, protože dává přímo výsledek i přenos. Z tabulky 4.1 vyplývá, že vždy čísla 0 a 9, 1 a 8 atd. vyjádřená v tomto kódu jsou komplementární. Další často používané váhové kódy Další často používané váhové kódy používají váhové systémy na příklad 5421, 74(-2)(-1) atd.
(-1) atd..")
19
Reflexní kódy Reflexní kódy jsou takové kódy, u nichž při přechodu z jednoho čísla se sousední číslo mění jen o 1 bit. Grayův kód Takovým typickým často používaným kódem je kód Grayův. Je to binární dekadický kód. Nazývá se také kód cyklický (permutovaný), zrcadlový nebo symetrický se změnou v jednom řádu (viz tab. 4.1.) eventuelně reflexívní. Používá se na zmenšení rizika hazardů. Konstrukce Grayova kódu pro 3 bity je následující :
, zrcadlový nebo symetrický se změnou v jednom řádu (viz tab. 4.1.) eventuelně reflexívní. Používá se na zmenšení rizika hazardů. Konstrukce Grayova kódu pro 3 bity je následující :.")
21
Zabezpečovací kódy Zabezpečovací kódy lze roztřídit podle obrázku

22
Detekční kódy Nejjednodušší možnost zabezpečení přenosu umožňují tzv. primitivní bezpečnostní kódy. Primitivní bezpečnostní kódy opakovaný - každá značka se vysílá 2x za sebou negativní - každá značka se vysílá v obrácené verzi (nuly se zamění za jedničky) zrcadlově symetrický - každá značka se vyšle ještě jednou, ale v obráceném pořadí bitů
 zrcadlově symetrický - každá značka se vyšle ještě jednou, ale v obráceném pořadí bitů.")
23
Zabezpečení jednoduchou paritou Zabezpečovací kódy, které budou probírány v této pasáži paritní, iterační a polynomické jsou kódy systematické. Zabezpečení paritním bitem spočívá v tom, že se k přenášenému slovu přiřadí ještě jeden bit a to zabezpečovací bit obsahující informaci o počtu logických 1 v zabezpečovaném slově. Tento bit se přenese spolu se zabezpečovaným slovem a na přijímací straně se znovu vygeneruje paritní bit z přijatého slova. Tyto bity se porovnají a jsou-li stejné, považujeme přijaté slovo za správné. Rozdílnost paritních bitů indikuje chybu při přenosu. Používají se 2 typy parit : sudá - logická 1 se generuje tehdy, obsahuje-li zabezpečované slovo lichý počet binárních 1 lichá - logická 1 se generuje tehdy, obsahuje-li zabezpečované slovo sudý počet binárních 1

24
Příklad sudá parita PB lichá parita PB 10110101 1 10110101 0 10011100 0 10011100 1 Z předešlého jasně vyplývá, že sudá a lichá parita nikdy nenabývají stejných hodnot a jsou vzájemně inverzní. Běžnější způsob je zabezpečení pomocí liché parity. Jednoduchý paritní bit zabezpečuje proti jednoduchým chybám, trojnásobným chybám atd (lichému počtu chybných bitů). Sudý počet chybných bitů neodhalí. Jednoduché chyby tvoří cca 50 - 60% z vyskytujících se chyb (3násobné chyby cca 3 - 10%). Z tohoto důvodu je tento způsob zabezpečení velmi častý a používá se všude tam, kde nejsou velké nároky na bezpečnost.
. Sudý počet chybných bitů neodhalí. Jednoduché chyby tvoří cca % z vyskytujících se chyb (3násobné chyby cca %). Z tohoto důvodu je tento způsob zabezpečení velmi častý a používá se všude tam, kde nejsou velké nároky na bezpečnost..")
25
Iterační kódy V praxi však vidíme, že se chyby při přenosu nevyskytují osamoceně, ale většinou ve shlucích (dvoj a vícenásobné chyby). K odstranění těchto chyb slouží tak zvané iterační kódy. Jsou to kódy u nichž se zabezpečuje celý blok informací (značek). Nejjednodušší způsob je, použije-li se pasivní zabezpečení na určitý informační blok několikrát. Pro důležité přenosy dat se používá jako nejvýznamnější zabezpečení bloku několika značkami. Vedle zajištění každé značky jednoduchým paritním bitem, které se nazývá příčná parita nebo též značková parita se používá zabezpečení bloku značek (případně celé zprávy) přidáním celé značky tvořené paritními bity. Toto zabezpečení se nazývá svislá parita nebo též bloková parita. Paritní značka je vytvořena z jednoduchých paritních bitů všech značkových bitů stejné polohy v bloku, tedy i bitů parity.
. Nejjednodušší způsob je, použije-li se pasivní zabezpečení na určitý informační blok několikrát. Pro důležité přenosy dat se používá jako nejvýznamnější zabezpečení bloku několika značkami. Vedle zajištění každé značky jednoduchým paritním bitem, které se nazývá příčná parita nebo též značková parita se používá zabezpečení bloku značek (případně celé zprávy) přidáním celé značky tvořené paritními bity. Toto zabezpečení se nazývá svislá parita nebo též bloková parita. Paritní značka je vytvořena z jednoduchých paritních bitů všech značkových bitů stejné polohy v bloku, tedy i bitů parity..")
26
Mimo 2násobné iterace (příčná a svislá parita) se používá i 3násobná iterace s vytvářením spirálové parity. Příklad zajištění zprávy trojnásobnou iterací (příčné, svislé i spirálové) je na obrázku.
 je na obrázku..")
27
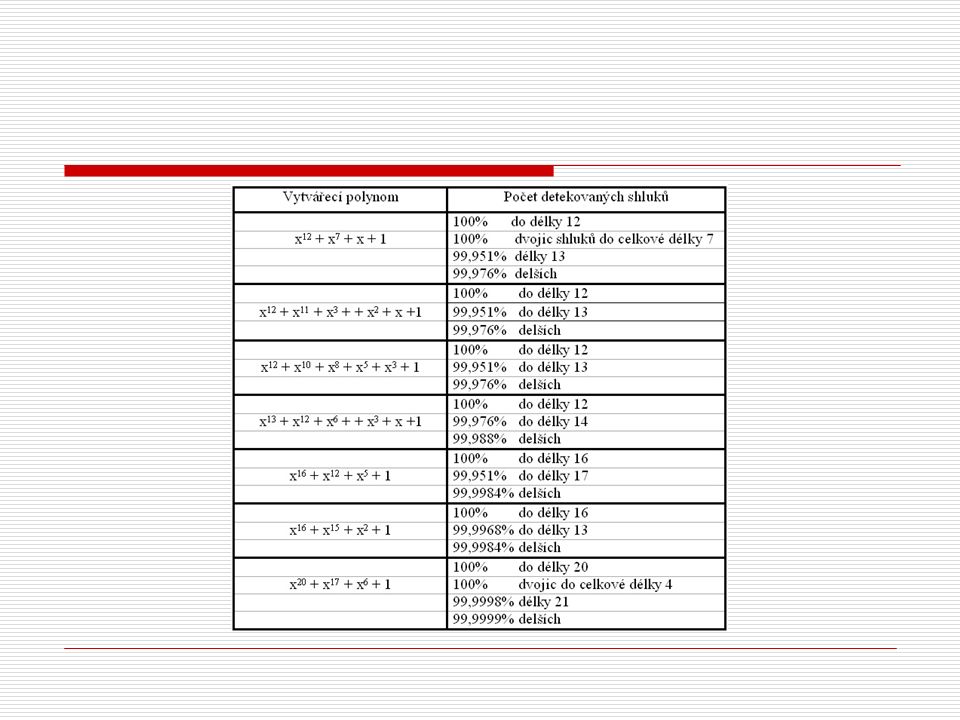
Polynomické (cyklické) kódy Polynomické kódy a jejich detekční schopnosti je možné popsat pomocí algebry mnohočlenů. Zabezpečení u těchto kódů se provádí pomocí zbytků po provedeném dělení. Operace nad čísly musí odpovídat operacím nad zbytky po dělení - na příklad po součtu dvou čísel musí součet zbytků těchto čísel být roven zbytku součtu. V opačném případě došlo k chybě. Cyklické kódy umožňují velmi dobré zajištění přenosu a jsou snadno technicky realizovatelné. Používají se k zabezpečení zprávy tvořící blok dat, sestávající z většího počtu značek.

28
Princip těchto kódů spočívá v tom, že se blok dat dělí tzv. vytvářecím polynomem (mnohočlenem). Tento mnohočlen představuje vysílanou zprávu a je beze zbytku dělitelný vytvářecím mnohočlenem. Této vlastnosti se využívá ke zjišťování chyb. Na přijímací straně se přijatý blok dat opět vydělí vytvářecím mnohočlenem a zjišťuje se zbytek. Při zbytku různém od nuly došlo při přenosu k chybě, při nulovém zbytku k chybě nedošlo, nebo není zjistitelná.
. Tento mnohočlen představuje vysílanou zprávu a je beze zbytku dělitelný vytvářecím mnohočlenem. Této vlastnosti se využívá ke zjišťování chyb. Na přijímací straně se přijatý blok dat opět vydělí vytvářecím mnohočlenem a zjišťuje se zbytek. Při zbytku různém od nuly došlo při přenosu k chybě, při nulovém zbytku k chybě nedošlo, nebo není zjistitelná..")
29
Kódování a dekódování těchto kódů se běžně realizuje buď posuvnými registry a sčítačkami modulo 2 nebo pomocí počítačů. Počet míst posuvného registru musí být roven stupni dělitele - t.j. vytvářecího mnohočlenu. Počet sčítaček modulo 2 se rovná počtu jedničkových bitů v děliteli. Po ukončení dělení zůstane v pomocném registru zbytek, který se připojí za přenášenou zprávu. Nevýhodou je zpoždění mezi posledním bitem zprávy, který vstupuje do registru a připraveností zabezpečovacích bitů k připojení. Při zabezpečení zpráv cyklickým kódem mohou mít zprávy proměnnou délku. Kratší zprávy jsou lépe zabezpečeny než zprávy delší. U kratších zpráv je však menší přenosový výkon, neboť zabezpečovací prvky kódu tvoří relativně větší část prvků celé zprávy.

30
Kód N z M Kód N z M je příkladem nesystematického detekčního kódu. Jedná se zde o Nprvkový kód, u kterého jsou kódové skupiny použité v určité abecedě vytvářeny tak, že všechny mají stejný počet a to M jedničkových prvků. Součet jedničkových prvků v kódové skupině se nazývá vahou kódové skupiny. Tyto kódy se proto také nazývají kódy s konstantní váhou. Při daném počtu prvků kódu N a při váze kódu M využívá kód M z N z kapacity Nprvkového kódu pouze N! N M!(N - M)! M je kombinací - z 2N možných kombinací pro N-prvkový kód.
. M je kombinací - z 2N možných kombinací pro N-prvkový kód..")
31
Zabezpečení tímto kódem tedy spočívá v tom, že všechny vysílané značky mají stejný počet jedniček a to M. Na přijímací straně se pak kontroluje, zda přijatá značka obsahuje tento počet jedniček. Jakákoliv změna v počtu jedniček než M signalizuje chybu. Účinnost zabezpečení tohoto kódu je snížena skutečností, že rušení při přenosu se projevuje nejen změnou hodnoty prvku 0 a 1, ale současně i 1 na 0, která často následuje vzápětí po prvé změně a tím dochází k nezjistitelnosti těchto chyb. Ostatní 2násobné shluky chyb a samozřejmě všechny jednoduché chyby tento kód detekuje.

32
Nejpoužívanějším kódem tohoto typu je kód 4 z 8. To znamená, že se jedná o 8prvkový kód, kdy jednu polovinu bitů tvoří jedničky a druhou polovinu nuly. Jakákoliv změna jejich rovnováhy pak signalizuje chybu. Tento kód umožňuje vytvořit 140 kombinací, což vyplývá z následujícího výpočtu :

33
Další známý kód je kód 3 ze 7 požívaný jako Mezinárodní telegrafní abeceda MTA 3. Je určena pro radiové mnohonásobné systémy, které signalizují a případně automaticky vyžádají opakování chybně přijaté kódové složky. Tato abeceda se skládá z 35 značek. Využívá vlastně celou abecedu MTA 2 a zbývající 3 jsou využity k zabezpečení přenosu.

35
Korekční kódy Jak již bylo uvedeno, korekční kódy dokáží chyby nejenom detekovat, ale i opravit. Po přijetí značky neodpovídající kódovému předpisu dojde nejprve ke zjištění nejpravděpodobnější chyby, která se pak automaticky opraví. Kód, který může detekovat dvojnásobné chyby může korigovat jen jednoduché chyby, podobně kód detekující 4násobné chyby bude korigovat chyby 2násobné atd. Ať je korekční kód konstruován jakkoliv, vždycky existuje určitá pravděpodobnost nesprávné korekce. Někdy dojde ke změně správného bitu na chybný proto, že sled chyb má jinou strukturu, než pro kterou byl kód navržen. Kdyby chybné bity byly rozloženy náhodným způsobem, nevznikl by žádný problém.

36
Náhodné rozložení chyb je ale velmi málo pravděpodobné, chyby se nevyskytují náhodně, ale ve shlucích, které mohou mít prakticky libovolnou strukturu. Kódy umožňující korigovat chyby mají velký význam pro zabezpečení záznamů na magnetických médiích (páskách, discích aj.), kdy není originál dostupný.
, kdy není originál dostupný..")
37
Korekční cyklický (polynomický) kód Cyklický kód lze využít ke korekci zjištěné chyby. Na přijímací straně se po detekci chyby (v případě, kdy vytvářecí mnohočlen není dělitelný vytvářecím mnohočlenem beze zbytku) se musí nalézt mnohočlen (polynom), který po dělení vytvářecím mnohočlenem má stejný zbytek, jako vydělení přijaté zprávy vytvářecím mnohočlenem. Nalezením tohoto mnohočlenu lze přijatou zprávu i opravit.
 se musí nalézt mnohočlen (polynom), který po dělení vytvářecím mnohočlenem má stejný zbytek, jako vydělení přijaté zprávy vytvářecím mnohočlenem. Nalezením tohoto mnohočlenu lze přijatou zprávu i opravit..")
38
Hammingův kód Základní princip tohoto kódu lze světlit pomocí tzv. Hammingovy krychle. Uvažujeme tedy 3místný binární kód, pomocí něhož můžeme vyjádřit celkem 2n = 23,což je 8 znaků. Tyto znaky přiřadíme jednotlivým vrcholům Hammingovy krychle. Každá hrana této krychle představuje tzv. Jednotkovou Hammingovu vzdálenost. Jestliže všechny znaky mají různé informační významy, pak změnou jediného elementu znaku dostáváme jiný informační význam. Chyba v jediném elementu znamená tedy přechod na jiný znak. Takový kód pak není bezpečnostním kódem.

39
Chceme-li vytvořit bezpečnostní kód, využijeme kapacitu tohoto trojmístného kódu jen částečně a významové znaky vybereme tak, aby jejich vzájemná Hammingova vzdálenost byla rovna 2. Znamená to, že zvolíme určitý vrchol a další vrcholy musí být vzdáleny přes dvě hrany (vrcholy stěnové úhlopříčky). Potom změna jednoho elementu každého významového znaku (pohyb přes jednu hranu) neznamená přechod na jiný významový znak, ale přechod na tzv. chybový znak. Říkáme, že jsme vytvořili bezpečnostní kód s detekcí 1 chyby (se zabezpečením na 1 chybu).
. Potom změna jednoho elementu každého významového znaku (pohyb přes jednu hranu) neznamená přechod na jiný významový znak, ale přechod na tzv. chybový znak. Říkáme, že jsme vytvořili bezpečnostní kód s detekcí 1 chyby (se zabezpečením na 1 chybu)..")
40
Pokud se redukuje počet významových znaků na 2, lze vybrat takové, které mají už Hammingovu vzdálenost 3 (přechod přes 3 hrany - vrcholy jedné tělesové úhlopříčky). To umožní vytvořit bezpečnostní kód s detekcí 2 chyb. V tomto případě lze vytvořit i kód korekční. Za předpokladu změny jednoho elementu významového znaku lze automaticky vyhodnotit nejen chybu, ale i pravděpodobně správný znak. Dostali jsme tedy korekční kód s korekcí 1 chyby.

41
Korekční kód využívající vícenásobné parity Tento korekční kód využívá toho, že přidáním více paritních bitů lze dostatečně přesně identifikovat místo chybného bitu a umožňuje ho opravit. Protože polohy parit jsou určeny, je snadné při výskytu chyby rozpoznat chybné parity a tím vymezit oblasti, ve kterých chyba leží. Správné parity a jim příslušné oblasti pak vymezí oblast chyby s přesností na 1 bit. Příklad Jako příklad uveďme způsob, podle kterého se přisoudí jednotlivým skupinám bitů kódového slova dílčí parity. Způsob určení chybového bitu je následující:

42
Kódové slovo určené k přezkoumání je např. (při liché paritě) 0010110. první 4 bity jsou datové (0010) zbylé tři jsou paritní (110), přičemž každý se vztahuje k různým třem bitů podle tabulky 4.3. 1. paritní bit se vztahuje k bitům s vahou 8, 2 a 1 2. paritní bit k bitům s vahou 8, 4 a 1 3. paritní bit se vztahuje k bitům s vahou 8, 4 a 2.
 zbylé tři jsou paritní (110), přičemž každý se vztahuje k různým třem bitů podle tabulky paritní bit se vztahuje k bitům s vahou 8, 2 a 1 2. paritní bit k bitům s vahou 8, 4 a 1 3. paritní bit se vztahuje k bitům s vahou 8, 4 a 2..")
43
Při správném přenosu by paritní bity museli tedy být 101. Nevyhovuje tedy parita P2 a P3. Chybný bit tedy musí ležet současně v oblasti P2 i P3 P2 - 8, 4, 1 P3 - 8, 4, 2 Chyba je tedy někde v bitech 8 a 4. Vzhledem k tomu, že oblast P1 je bez chyby, nemůže být chybný bit v oblasti P1 : 8, 2, 1. Chybný bit je tedy 4 a po jeho opravě vypadá kódové slovo takto : 0110110.

44
Speciální kódy Pro potřeby kódování datových zdrojů byla vyvinuta celá řada speciálních kódů, ale zde probereme jen ty nejznámější, ostatní pak překračují rámec publikace. S růstem požadavků na objemy přenášených dat a zvláště pak s růstem počtu terminálů schopných navazovat spojení s jinými terminály ve veřejné síti roste také potřeba standardizace kódů pro přenos dat. Mezinárodní organizace CCITT (The International Telegraph and Telephone Consultative Committee), ISO (International Organization for Standardization) a národní ASA (The American Standards Association) hrály v tomto úsilí největší roli. Volba standardů je vždy obtížná, neboť je třeba vyhovět mnoha zcela odlišným požadavkům různých uživatelů. Výsledkem normalizačních snah bylo vytvoření standardního kódu CCITT5/ISO7, který je v podstatě totožný s kódem ASCII, ze kterého byl odvozen.
, ISO (International Organization for Standardization) a národní ASA (The American Standards Association) hrály v tomto úsilí největší roli. Volba standardů je vždy obtížná, neboť je třeba vyhovět mnoha zcela odlišným požadavkům různých uživatelů. Výsledkem normalizačních snah bylo vytvoření standardního kódu CCITT5/ISO7, který je v podstatě totožný s kódem ASCII, ze kterého byl odvozen..")
45
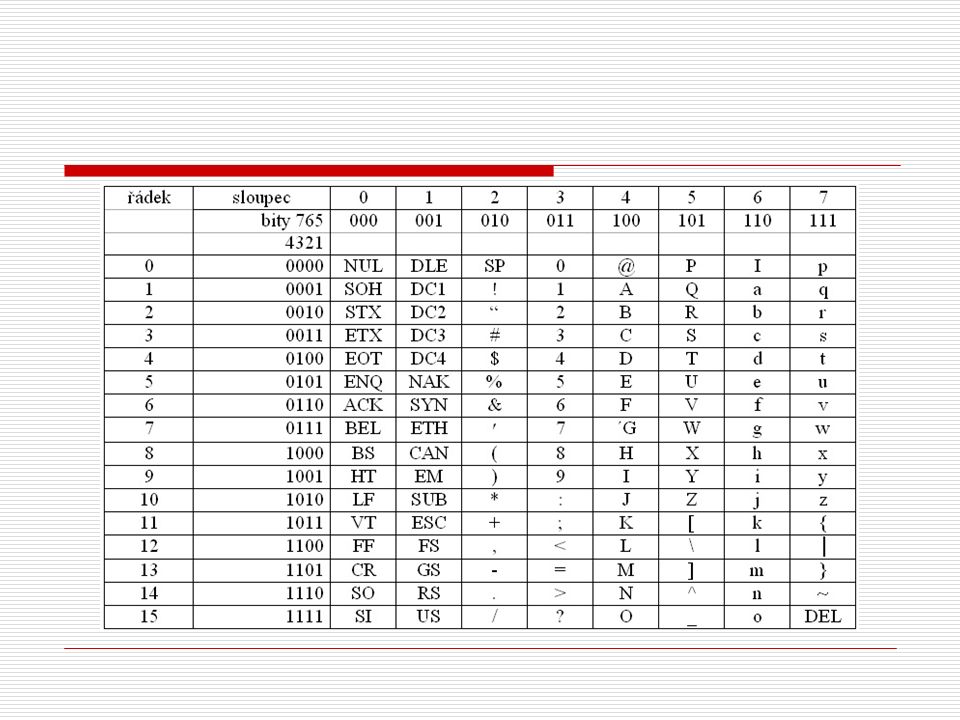
Kód ASCII Kód ASCII (American Standard Code for Informatiom Interchange) je standardní sedmiprvkový kód používaný jak v číslicových počítačích, tak i pro přenos dat (i po radiových a telefonních linkách). Se 7 bity můžeme znázornit 2n = 27 = 128 znaků. Osmiprvkový kód se používá mimo obvyklých znaků i pro znaky národní. Kód ASCII je používán ke znázorňování : číslic 0 – 9 písmen abecedy speciálních znaků

46
Speciálních znaků se používá pro řízení různých zařízení, například periferních zařízení pro počítače a pro komunikační obvody. Celý kód ASCII je v tabulce 4.4. Tento kód je pro každé číslo, písmeno nebo řídící znak sestaven ze 4bitových a 3bitových skupin. Následující tabulka znázorňuje uspořádání těchto dvou skupin a pořadí.

48
kde : NUL - nula SP – mezera SOH - začátek záhlaví DLE - výstupní kód pro ovládání STX - začátek textu DC1 ETX - konec textu DC2 - řízená zařízení EOT - konec přenosu DC3 ENQ - dotaz DC4 ACK - potvrzení NAK - negativní potvrzení BEL - zvonek SYN - synchronní nevyužitost BS - zpětný krok ETB - konec přenosu bloku HT - přeskok děrného štítku CAN - zrušení LF - řádkování EM - konec média VT - vertikální tabelace SUB - náhrada FF - posuv formuláře ESC - přepnutí CR - návrat vozíku FS - oddělovač souborů SO - posun ven GS - oddělovač skupin SI - posun dovnitř RS - oddělovač záznamů DEL - výmaz US - jednotkový oddělovač

49
Příklad Vyjádřete v kódu ASCII slovo Ano a dále číslo v hexadecimálním kódu 5F. Jednotlivá písmena tohoto slova najdeme v tabulce. V tabulce najdeme skupiny, které odpovídají řádku a sloupci, v němž jsme tento údaj lokalizovali. pro písmeno A - sloupec 4, řádka 1 : 100 0001 n - sloupec 6, řádka 14 : 110 1110 o - sloupec 6, řádka 15 : 110 1111 pro číslici 5 - sloupec 3, řádka 5 : 001 0101 pro písmeno F - sloupec 4, řádka 6 : 100 0110

50
Ostatní standardní kódy Používají se jak 6ti tak i 8bitové kódy. Jejich význam je bývá buď speciální nebo lokální. Příkladem speciálního kódu určeného pro periferní operace a operace spojené s přenosem dat je 8bitový kód EBCDIC (Extended Binary Coded Decimal Interchange Code nebo-li „Rozšířený výměnný kód pro dvojkové kódování“ desítkových čísel) používaný firmou IBM. Další příklad může být 6ti prvkový kód UNIVAC XS-3.
 používaný firmou IBM. Další příklad může být 6ti prvkový kód UNIVAC XS-3..")
51
Transparentní kódy Často se stává, že kapacita kódu je malá a nestačí pro přenos všech znaků (jak informačních tak i řídících) a zvětšení počtu bitů není buď možné, nebo žádoucí například z důvodu přenosového výkonu. Řešení většinou spočívá v tom, že se pro účely řízení použije dvou znaků na místo jednoho. Například u kódu ASCII se na prvém místě dvojice použije znak DLE (Data Link Escape), který informuje přijímač o tom, že druhý znak je nezbytné interpretovat jako znak řídící. V tomto případě není znak DLE považován za součást dat. Aby znak DLE mohl být považován za součást dat, respektive za znak DLE, musí mu předcházet jiný znak DLE. Takovému kódu se někdy říká transparentní kód a odpovídajícímu přenosu transparentní přenos.
, který informuje přijímač o tom, že druhý znak je nezbytné interpretovat jako znak řídící. V tomto případě není znak DLE považován za součást dat. Aby znak DLE mohl být považován za součást dat, respektive za znak DLE, musí mu předcházet jiný znak DLE. Takovému kódu se někdy říká transparentní kód a odpovídajícímu přenosu transparentní přenos..")
52
Některé terminály mohou přecházet z jednoho způsobu přenosu na druhý. K tomu stačí pouze vyslat určité posloupnosti znaků jako : DLE STX - začátek transparentního přenosu DLE ETB - konec transparentního přenosu DLE ITB - konec transparentního přenosu, pokračování v normálním přenosu Jiný způsob řešení problému spočívá v označení začátku a konce vysílaných bloků dat zvláštními bitovými sledy, které se uvnitř bloků dat nemohou vyskytnout (například, že sledem bude posloupnost 6 jedniček – 111111).
..")
53
Výskyt takového sledu jedniček v bloku dat se dá potlačit speciálním logickým obvodem, který kontroluje neustále vysílaná data a při zjištění posloupnosti pěti jedniček automaticky vloží nulový bit. V přijímači je obdobný logický obvod, který neustále sleduje výskyt kombinace 111110 a který při výskytu této kombinace potlačuje 0. Tímto způsobem lze vyslat každou kombinaci bitů bez nebezpečí, že by některá obsahovala sled 6ti jedniček. Pro vyznačení začátku a konce bloku se může potom použít sled 01111110 a pro přenos dat jakákoliv kombinace.

54
Kritéria pro volbu kódu Výsledný účinek každého opatření pro zabezpečení datového přenosu závisí na těchto faktorech: účinnosti zabezpečení - kolik chyb zůstane nedetekováno snížení průchodnosti spoje - přidáním zabezpečovacích bitů případně opakováním chybných zpráv se snižuje průchodnost spoje. nákladech na realizaci - výsledný účinek každého opatření je možné měnit volbou způsobu kódování. Tam, kde je hlavní bezpečnost přenosu (v bankovnictví při peněžních transakcích, v obraně a podobně), je hledisko průchodnosti spojů a nákladů na realizaci až druhotné. Toto jsou však výjimečné případy se kterými se často nesetkáváme. Většinou pracují systémy s takovým stupněm zabezpečení, který se dá zdůvodnit a k jehož dosažení nejsou nutné příliš velké finanční náklady.
, je hledisko průchodnosti spojů a nákladů na realizaci až druhotné. Toto jsou však výjimečné případy se kterými se často nesetkáváme. Většinou pracují systémy s takovým stupněm zabezpečení, který se dá zdůvodnit a k jehož dosažení nejsou nutné příliš velké finanční náklady..")
55
Na počátku rozvoje výpočetní techniky bylo zabezpečení přenosu velmi drahou záležitostí - proto volbu kódu ovlivňovaly náklady. Technologie LSI a VLSI (vysoká a velmi vysoká integrace) podstatně snížila cenu realizace složitých koncových zařízení (kodérů a dekodérů), takže vliv jejich ceny na volbu kódu stále klesá. Výjimku tvoří systémy s velkým počtem terminálů, kde je jejich cena a s tím spojené hledisko volby kódu rozhodujícím faktorem.
 podstatně snížila cenu realizace složitých koncových zařízení (kodérů a dekodérů), takže vliv jejich ceny na volbu kódu stále klesá. Výjimku tvoří systémy s velkým počtem terminálů, kde je jejich cena a s tím spojené hledisko volby kódu rozhodujícím faktorem..")
56
Přehled vlastností různých způsobů zabezpečení

Podobné prezentace


















>")

