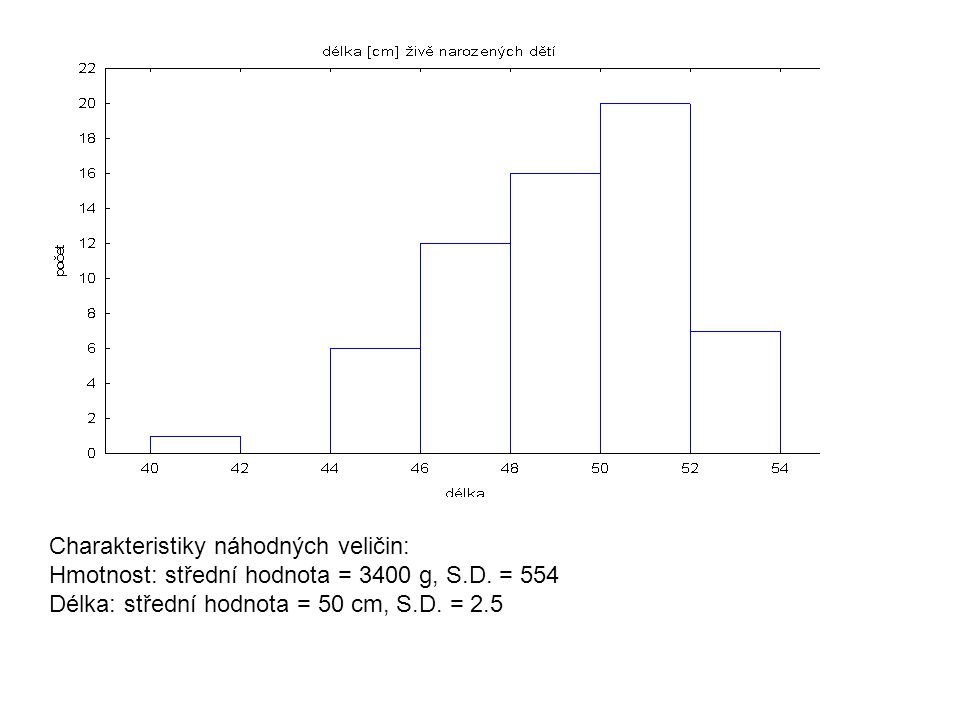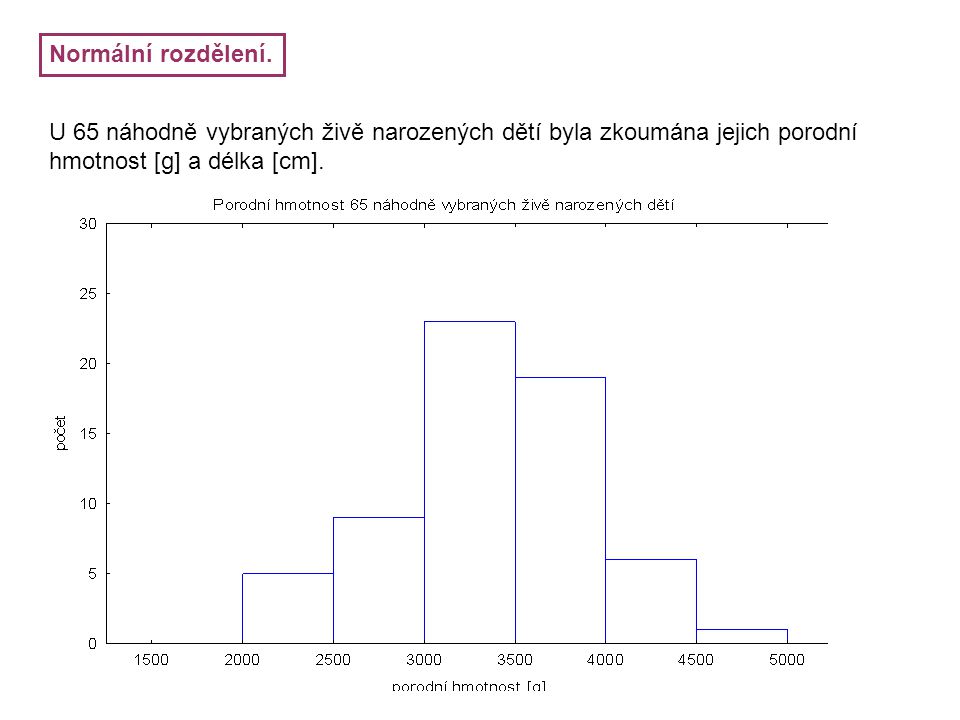
Normální rozdělení. U 65 náhodně vybraných živě narozených dětí byla zkoumána jejich porodní hmotnost [g] a délka [cm].
Charakteristiky náhodných veličin: Hmotnost: střední hodnota = 3400 g, S.D. = 554 Délka: střední hodnota = 50 cm, S.D. = 2.5
(očekávané (relativní) četnosti) sledované (relativní) četnosti k je počet tříd (počet sloupců v histogramu)
Normální rozdělení: je předpokladem použití mnoha statistických metod zachovává se vzhledem k některým (lineární) transformacím je definována pouze 2 parametry je symetrická (šikmost = 0) Ověřování normality dat: pomocí 2 rozdělení ověřování se neprovádí: pro velké množství dat normalitu zamítneme normalitu nezamítáme při malém počtu pozorování statistické metody jsou málo citlivé na mírné porušení normality
t - testy Má se zjistit, zda se sjíždějí přední pravé pneumatiky stejně jako přední levé pneumatiky. Bylo vybráno 6 vozů stejné značky: H0: sjetí vpravo = sjetí vlevo H1: sjetí vpravo ≠ sjetí vlevo Předpoklady: Náhodné proměnné „sjetí vpravo“ a „sjetí vlevo“ pocházejí z normálního rozdělení. H0: střední hodnota sjetí vpravo ( 1) – střední hodnota sjetí vlevo ( 2) = 0. rozptyly obou proměnných se rovnají. Párový t - test
Předpoklad normality dat se neověřuje Pokud první soubor pochází z N ( 1, ) a druhý má rozdělení N( 2, ), pak rozdíl obou náhodných proměnných má rozdělení N(0, ). Hodnoty 1, 2, neznáme, známe pouze jejich výběrové odhady. Abychom dostali test nezávislý na konkrétních hodnotách parametrů rozdělení, při čemž známe pouze výběrové charakteristiky, nepoužijeme N(0, 1), ale Studentovo t-rozdělení.
Náš příklad. t (5) = 1.052, P = > 0.05 nezamítám H0 sjíždění pravých a levých stran je stejné P1P1 P2P2
Příklad. Byla sledována hmotnost lidí před a po absolvování diety: t(7) = 2,277, P = nezamítám H0 H0: před = po H1: před ≠ po P1 = P2 = Oboustranný test
Proto: H1: před – po > 0, tedy před > po H0: před ≤ po Jednostranný test t(7) = 2,277, P = P1 = / 2 = Zamítám H0 Hmotnost před dietou > hmotnost po dietě Postup. 1. Oboustranný test stanovení H0 stanovení H1 t-test, P 2. Jednostranný test stanovení H1 stanovení H0 t-test, P/2 Zamítám oboustranný test (P < 0.05) nezamítám oboustranný test (P ≥ 0.05) Zamítám jednostranný test (P < 0.025) Obě možnosti Pro jednostranný test (P ≥ 0.025)
Jednovýběrový t-test Automat plní sáčky moukou. V každém sáčku by měl být 1 kg. Při testu automatu byly získány následující hodnoty: 0.98, 1.05, 1.03, 0.995, 1.1, 0.998, 1.002,1.03, 0.99,0.99. Vykazuje automat systematickou chybu? Střední hodnota , t (9) = , P = ≥ 0.05 Nezamítám, že automat nevykazuje systematickou chybu. H0: automat nevykazuje systematickou chybu H1: automat vykazuje systematickou chybu