Popisné statistiky. Výskyt strupovitosti se zdá být ve vztahu s obsahem některých chemických prvků “ve slupkách“ hlíz. Některé odrůdy trpí strupovitostí více (citlivé), některé méně (střed), některé téměř strupovitostí netrpí (odolné). Sledujeme například množství Cu [mg/kg] ve slupce brambor. Hlízy jsou zhruba stejně velké, 60 – 65 dní po výsadbě. Pokusné plochy pro výsadbu byly zvoleny s přibližně stejnými půdními a klimatickými podmínkami. Přesto obsah Cu v hlízách není stejný. Nejsme schopni přesně definovat všechny faktory ovlivňující množství Cu v hlízách a Hlavně nejsme schopni analyzovat všechny hlízy. Definujeme náhodnou veličinu: obsah Cu v hlízách brambor. Náhodnou veličinu lze definovat: 1)Rozdělením pravděpodobností (histogram, spojitá křivka) obsahu Cu v hlíze 2)Charakteristikami (středu, variability,…)
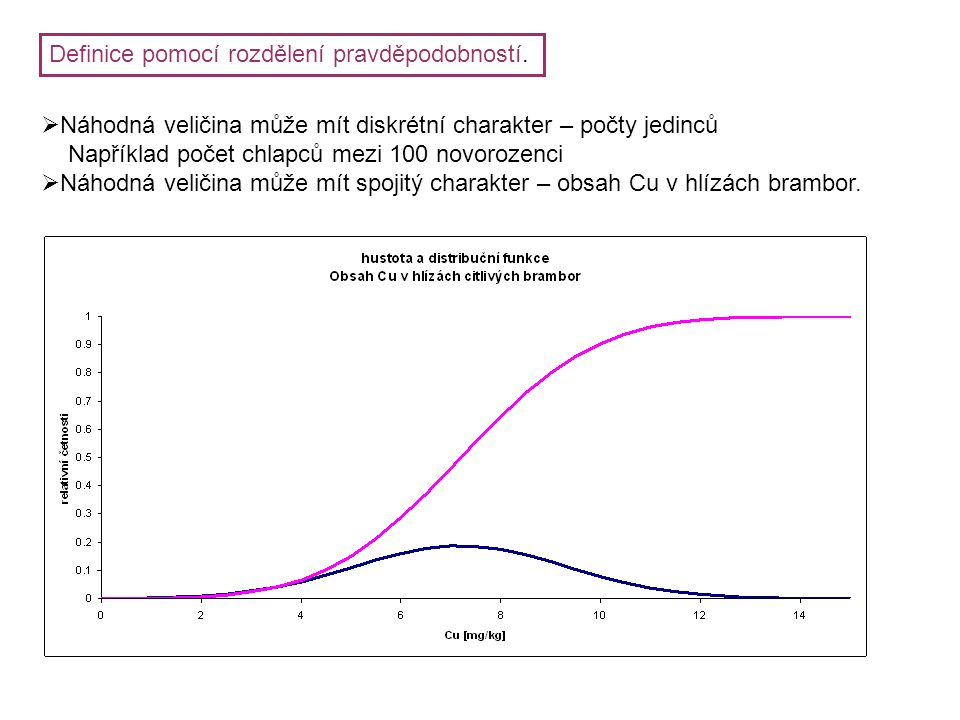
Definice pomocí rozdělení pravděpodobností. Náhodná veličina může mít diskrétní charakter – počty jedinců Například počet chlapců mezi 100 novorozenci Náhodná veličina může mít spojitý charakter – obsah Cu v hlízách brambor.
Definice pomocí charakteristik. 1. charakteristiky středu (polohy): střední hodnota median 2.charakteristiky variability: variance 2 směrodatná odchylka rozpětí max – min Variační koeficient /
Výběrové charakteristiky souboru pro výběr rozsahu n. Výběrová střední hodnota Výběrový rozptyl Výběrová směrodatná odchylkaS Výběrové charakteristiky jsou náhodné veličiny, závisejí na náhodném výběru, speciálně například na jeho rozsahu. Náhodný výběr musí být náhodný a musí odrážet strukturu základního souboru. Je-li tomu tak, pak: Kolísání výběrové střední hodnoty popisuje Standard error of mean Charakteristiky náhodné veličiny nejsou většinou známy. Na jejich hodnotu usuzujeme z výběrových charakteristik.
Kvantily. Slouží k představě o uspořádání dat. Data seřadíme vzestupně. Příklad souboru: 1,1,1,1,1,1,1,150 Median (prostřední hodnota) = 1 První (dolní) kvartil = 1 Druhý (prostřední) kvartil = median = 1 Třetí kvartil = 1 Střední hodnota = 157/8 = Většina dat má výrazně nižší hodnoty, než je průměr. Vychýlení průměru tvoří jen několik vychýlených hodnot. Stejným způsobem decily nebo percentily.