Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Úvod do gradientové analýzy

2
Community concept (from Mike Austin)
")
3
Continuum concept (from Mike Austin)
")
4
Skutečnost je někde mezi, a nejspíš je i o něco komplikovanější

5
Původně (a teoreticky)
Community concept jako základ pro klasifikaci Continuum concept jako základ pro ordinaci / gradientovou analýzu

6
V praxi Potřebuju vegetační mapu (nebo kategorie pro plán managementu pro AOPK) – Užiju klasifikaci Zajímají mě přechody, gradienty etc. – užiju gradientovou analýzu, ordinaci...

7
Methods of the gradient analysis

8
Na krátkém gradientu bývá lineární aproximace dobrou volbou, na dlouhém gradientu nikoliv

9
Nicméně Ve většině případů, soustředíme-li se na jednotlivý druh, tak ani lineární, ani unimodální odpověď nejsou ideálním řešením. Při studiu celého společenstva – a tedy mnoho druhů současně, užívám metody založené na lineárním nebo unimodálním modelu odpovědi jako rozumný kompromis mezi realističností a jednoduchostí.

10
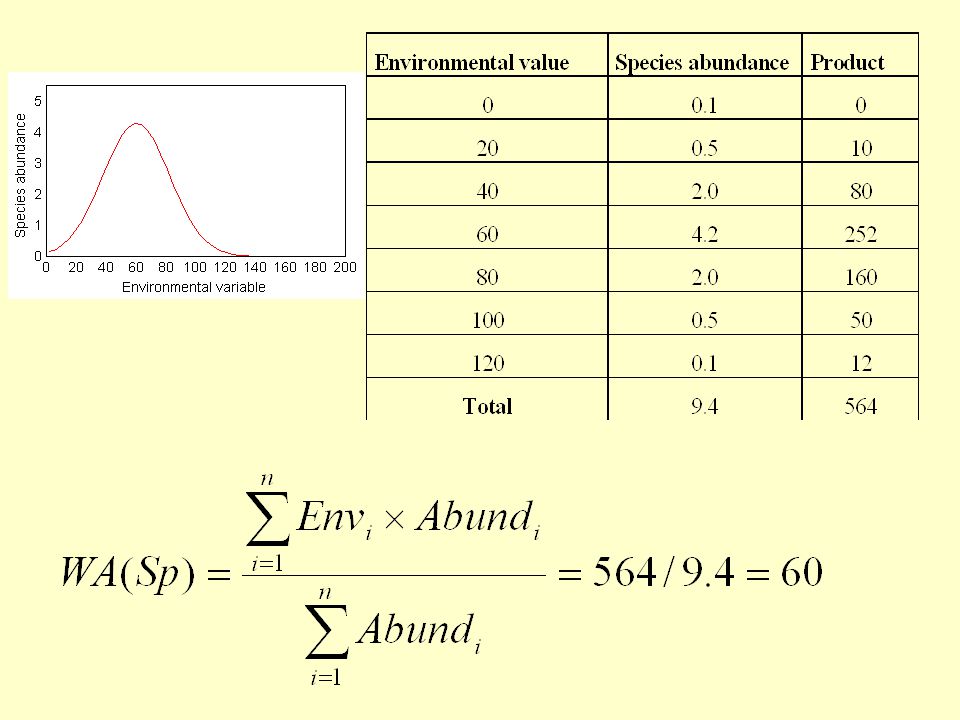
Odhadujeme optima druhů váženým průměrováním
“Weighted averaging regression” Odhadujeme optima druhů váženým průměrováním Optimum Tolerance

12
Techniky založené na lineárním modelu odpovědi jsou vhodné pro homogenní data (tedy krátké gradienty), metody založené na váženém průměrování jsou vhodné pro heterogenní data – dlouhé gradienty.
, metody založené na váženém průměrování jsou vhodné pro heterogenní data – dlouhé gradienty.")
13
Kalibrace (s užitím váženého průměrování)
")
14
Ordinační diagram Urtica Chenopodium Cactus Nymphea Menyanthes Comarum
Aira Drosera

15
Proximity means similarity
Ordinační diagram Nutrients Urtica Chenopodium Cactus Nymphea Menyanthes Water Comarum Aira Drosera Proximity means similarity

16
Dvě možné formulace problému ordinace
1. Nalezni konfiguraci vzorků (objektů) v ordinačním prostoru tak, aby vzdálenosti co nejlépe odpovídali nepodobnosti v jejich druhovém složení. Explicitně to dělá multidimensional scaling. (Metric and non-metric). Musíme mít definováno, jak se měří nepodobnost druhového složení. 2. Nalezni "latentní" proměnné (ordinační osy), které budou nejlepšími prediktory pro hodnoty všech druhů v souboru. Tento přístup vyžaduje, abychom měli definován model (pro všechny druhy stejný) odpovědi druhu na hodnotu prediktoru (tj. ordinační osy). Pozn. Obecně, místo vzorků a druhů můžeme mít objekty, a na nich měřené charakteristiky (proměnné)
 v ordinačním prostoru tak, aby vzdálenosti co nejlépe odpovídali nepodobnosti v jejich druhovém složení. Explicitně to dělá multidimensional scaling. (Metric and non-metric). Musíme mít definováno, jak se měří nepodobnost druhového složení. 2. Nalezni latentní proměnné (ordinační osy), které budou nejlepšími prediktory pro hodnoty všech druhů v souboru. Tento přístup vyžaduje, abychom měli definován model (pro všechny druhy stejný) odpovědi druhu na hodnotu prediktoru (tj. ordinační osy). Pozn. Obecně, místo vzorků a druhů můžeme mít objekty, a na nich měřené charakteristiky (proměnné)")
17
Terminologie Staré CANOCO – vzorky (samples), druhy (species), proměnné prostředí (environmental variables) Nové Canoco5 – obecně případy (cases), odpovědi (reponse variables), vysvětlující proměnné (predictors) – ty si ale můžeme libovolně nazvat
, odpovědi (reponse variables), vysvětlující proměnné (predictors) – ty si ale můžeme libovolně nazvat.")
18
Model linearní odpovědi je předpokládán v tzv
Model linearní odpovědi je předpokládán v tzv. lineárních metodách ordinace, model unimodální odpovědi v metodách užívajících weighted averaging (též zvané unimodální metody). V lineárních metodách je sample score lineární kombinací (váženým součtem) skore druhů, v unimodálních metodách je to vážený průměr (+nějaké přeškálování). Note: Algoritmus weighted averaging zahrnuje implicitní dvojí standardizaci (po vzrcích i po druzích) U lineárních metod si můžeme vybrat, jestli (a kterou) standardizaci chceme, a kterou ne.
. V lineárních metodách je sample score lineární kombinací (váženým součtem) skore druhů, v unimodálních metodách je to vážený průměr (+nějaké přeškálování). Note: Algoritmus weighted averaging zahrnuje implicitní dvojí standardizaci (po vzrcích i po druzích) U lineárních metod si můžeme vybrat, jestli (a kterou) standardizaci chceme, a kterou ne.")
19
Kvantitativní data Transformace je algebraická funkce Xij’=f(Xij) – aplikujeme ji nezávisle na ostatních hodnotách. Standardizaci provádíme buď s ohledem na ostatní hodnoty ve vzorku (standardization by samples) nebo na hodnoty daného druhu v ostatních vzorcích (standardization by species). [obecně standardizaci provádíme pro případy/objekty – cases, nebo proměnné – variables. Centering znamená odečtení průměru. Výsledný sloupec nebo řádek má potom nulový průměr Standardizace obvykle dělíme hodnotu sumou nebo normou (sloupce nebo řádku). Standardization by total / by norm.
 – aplikujeme ji nezávisle na ostatních hodnotách. Standardizaci provádíme buď s ohledem na ostatní hodnoty ve vzorku (standardization by samples) nebo na hodnoty daného druhu v ostatních vzorcích (standardization by species). [obecně standardizaci provádíme pro případy/objekty – cases, nebo proměnné – variables. Centering znamená odečtení průměru. Výsledný sloupec nebo řádek má potom nulový průměr. Standardizace obvykle dělíme hodnotu sumou nebo normou (sloupce nebo řádku). Standardization by total / by norm.")
20
Weighted averaging implikuje užití chi2 distance
Všimněte si, že v této míře už je zahrnutá dvojitá standardizace (by total)
")
21
Obě formulace mohou vést ke stejnému řešení
Obě formulace mohou vést ke stejnému řešení. (Kdyby byly vzorky podobného složení na ordinační ose daleko od sebe, tak ta ordinační osa nemůže mít dobré predikční schopnosti.) Například, principal component analysis – PCA – může být formulována jako projekce v Euklidovském prostoru, nebo jako hledání nejlepšího lineárního prediktoru. Specifikováním typu odpovědi specifikujeme vlastně i užitou míru podobnosti (a vice versa), ale pro některé míry podobnosti neexistuje odpovídající model.
 Například, principal component analysis – PCA – může být formulována jako projekce v Euklidovském prostoru, nebo jako hledání nejlepšího lineárního prediktoru. Specifikováním typu odpovědi specifikujeme vlastně i užitou míru podobnosti (a vice versa), ale pro některé míry podobnosti neexistuje odpovídající model.")
22
„Dobrá” osa zachovává původní vzdálenosti (nepodobnosti), a je také dobrým prediktorem pro jednotlivé druhy, ‚špatná“ osa nedokáže ani jedno, ani druhé. „bad“ „good“

23
„Dobrá” osa zachovává původní vzdálenosti (nepodobnosti), a je také dobrým prediktorem pro jednotlivé druhy, „špatná“ osa nedokáže ani jedno, ani druhé.
, a je také dobrým prediktorem pro jednotlivé druhy, „špatná osa nedokáže ani jedno, ani druhé.")
24
“Špatná osa” je zcela neužitečná jako prediktor pro jednotlivé druhy

25
Když jsou proměnné (druhy) prakticky nezávislé, žádná dobrá osa neexistuje – vzdálenosti nejsou zachovávány, a osa neslouží jako prediktor
 prakticky nezávislé, žádná dobrá osa neexistuje – vzdálenosti nejsou zachovávány, a osa neslouží jako prediktor")
26
Za výsledky ordinace považujeme hodnoty jednotlivých vzorků (případů) na ordinační ose (latentní proměnné - latent variable) zvané sample/case scores a odhady optim druhů na této proměnné (the species scores, variable scores) [pro unmodální metody; pro lineární metody jsou to charakteristiky lineární závislosti]. Přitom požadujeme, abych charakteristiky (score) snímků mohly být odhadnuty z charakteristik druhů (váženým průměrováním), a aby charakteristiky druhů mohly být stejně odhadnuty z charakteristik (score) vzorků, Toho lze dosáhnout pomocí následujícího algoritmu:
![Za výsledky ordinace považujeme hodnoty jednotlivých vzorků (případů) na ordinační ose (latentní proměnné - latent variable) zvané sample/case scores a odhady optim druhů na této proměnné (the species scores, variable scores) [pro unmodální metody; pro lineární metody jsou to charakteristiky lineární závislosti].](http://slideplayer.cz/slide/3093535/11/images/26/Za+v%C3%BDsledky+ordinace+pova%C5%BEujeme+hodnoty+jednotliv%C3%BDch+vzork%C5%AF+%28p%C5%99%C3%ADpad%C5%AF%29+na+ordina%C4%8Dn%C3%AD+ose+%28latentn%C3%AD+prom%C4%9Bnn%C3%A9+-+latent+variable%29+zvan%C3%A9+sample%2Fcase+scores+a+odhady+optim+druh%C5%AF+na+t%C3%A9to+prom%C4%9Bnn%C3%A9+%28the+species+scores%2C+variable+scores%29+%5Bpro+unmod%C3%A1ln%C3%AD+metody%3B+pro+line%C3%A1rn%C3%AD+metody+jsou+to+charakteristiky+line%C3%A1rn%C3%AD+z%C3%A1vislosti%5D..jpg "Přitom požadujeme, abych charakteristiky (score) snímků mohly být odhadnuty z charakteristik druhů (váženým průměrováním), a aby charakteristiky druhů mohly být stejně odhadnuty z charakteristik (score) vzorků, Toho lze dosáhnout pomocí následujícího algoritmu:")
27
Step 1 Začni s vybranými (z palce vycucanými) počátečními skore (souřadnicemi) vzorků {xi}
Step 2 Spočti skore druhů {yi} pomocí [weighted averaging] regrese z hodnot {xi} Step 3 Spočti nová skore vzorků {xi} pomocí [weighted averaging] kalibrace z hodnot {yi} Step 4 Odstraň „smrštění“ ordinační osy pomocí lineárního přeškálování (natéhni osy – „jako gumu“) Step 5 Při konvergenci můžeš skončit, jinak GO TO Step 2 =eigenvalue
 Step 5 Při konvergenci můžeš skončit, jinak GO TO Step 2. =eigenvalue.")
28
10 Steps 1 to 3 Jako bych měl značky na gumě, a tu gumu natáhnul xmin xmax 10

29
Délka osy je často arbitrárně daná (ale jsou výjimky – viz dále)
Orientace os je arbitrární (co je důležité jsou vzájemné pozice druhů a snímků)
")
30
Čím větší je eigenvalue (charakteristické číslo), tím větší je vysvětlující síla dané prdinační osy. Množství vysvětlené variability je úměrné hodnotě eigenvalue. Ve weighted averaging, eigenvalues < 1 (=1 je jenom pro perfect partitioning). V programu CANOCO jsou lineární metody škálovány tak, že sume hodnot eigenvalue = 1 (nemusí platit pro jiné programy) samples perfect partitioning x x 0 x x x x x 0 x species x 0 x x 0 x x x 0 x
. V programu CANOCO jsou lineární metody škálovány tak, že sume hodnot eigenvalue = 1 (nemusí platit pro jiné programy) samples. perfect partitioning. x x 0 x x x x x 0 x. species. x 0 x x 0 x x x 0 x.")
31
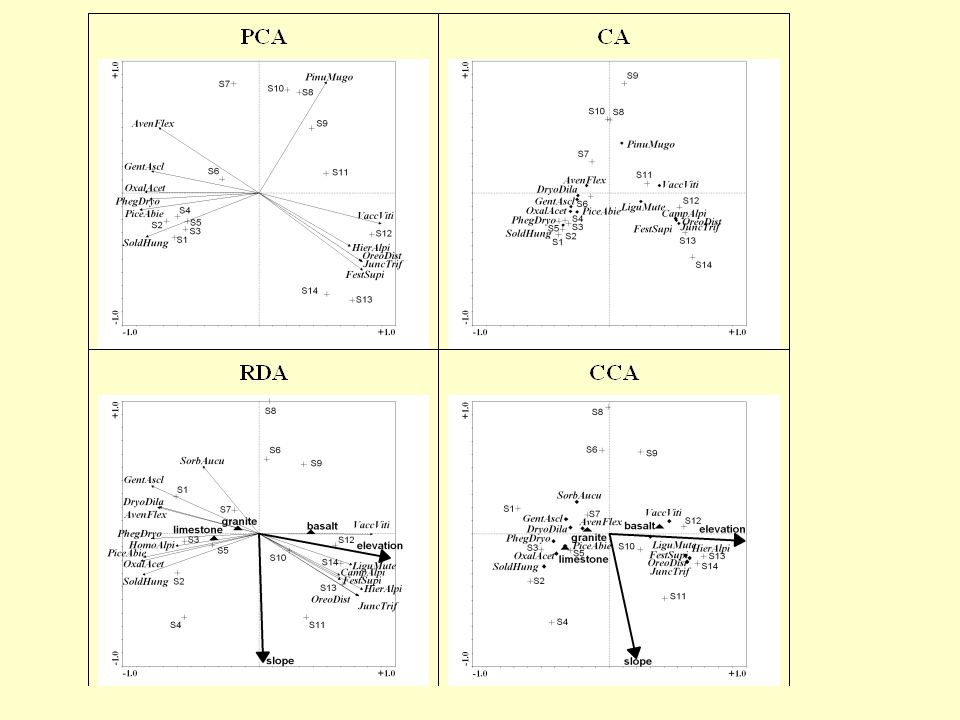
Constrained ordination
Osa je lineární kombinací měřených proměnných (lineární kombinace = a X1 +b X2 + c X3 ) Step 1 Začni s vybranými (z palce vycucanými) počátečními skore (souřadnicemi) vzorků {xi} Step 2 Spočti skore druhů {yi} pomocí [weighted averaging] regrese z hodnot {xi} Step 3 Spočti nová skore vzorků {xi} pomocí [weighted averaging] kalibrace z hodnot {yi} Step 4 Odstraň „smrštění“ ordinační osy pomocí lineárního přeškálování (natéhni osy – „jako gumu“) Step 5 Při konvergenci můžeš skončit, jinak GO TO Step 2
 Step 1 Začni s vybranými (z palce vycucanými) počátečními skore (souřadnicemi) vzorků {xi} Step 2 Spočti skore druhů {yi} pomocí [weighted averaging] regrese z hodnot {xi} Step 3 Spočti nová skore vzorků {xi} pomocí [weighted averaging] kalibrace z hodnot {yi} Step 4 Odstraň „smrštění ordinační osy pomocí lineárního přeškálování (natéhni osy – „jako gumu ) Step 5 Při konvergenci můžeš skončit, jinak GO TO Step 2.")
32
Constrained ordination
Osa je lineární kombinací měřených proměnných (lineární kombinace = a X1 +b X2 + c X3 ) Step 1 Začni s vybranými (z palce vycucanými) počátečními skore (souřadnicemi) vzorků {xi} Step 2 Spočti skore druhů {yi} pomocí [weighted averaging] regrese z hodnot {xi} Step 3 Spočti nová skore vzorků {xi} pomocí [weighted averaging] kalibrace z hodnot {yi} Step 3a – Spočti regresi skore vzorků {xi} na měřených hodnotách prostředí a původní hodnoty nahraď regresními odhady Step 4 Odstraň „smrštění“ ordinační osy pomocí lineárního přeškálování (natéhni osy – „jako gumu“) Step 5 Při konvergenci můžeš skončit, jinak GO TO Step 2
 Step 1 Začni s vybranými (z palce vycucanými) počátečními skore (souřadnicemi) vzorků {xi} Step 2 Spočti skore druhů {yi} pomocí [weighted averaging] regrese z hodnot {xi} Step 3 Spočti nová skore vzorků {xi} pomocí [weighted averaging] kalibrace z hodnot {yi} Step 3a – Spočti regresi skore vzorků {xi} na měřených hodnotách prostředí a původní hodnoty nahraď regresními odhady. Step 4 Odstraň „smrštění ordinační osy pomocí lineárního přeškálování (natéhni osy – „jako gumu ) Step 5 Při konvergenci můžeš skončit, jinak GO TO Step 2.")
33
CaseR vs. CaseE Step 3a – Spočti regresi skore vzorků {xi} na měřených hodnotách prostředí a původní hodnoty nahraď regresními odhady CaseR score = hodnota spočtená z druhového složení (kde je vzorek podle druhového složení[nebo obecně podle response variables]) – nicméně, dv souřadnicích os, které jsou určeny proměnými prostředí CaseE score = fitovaná hodnota, tj . Lineární kombinace hodnot proměnných prostředí/ prediktorů (kde by měl vzorek být podle fitovaného modelu) – při kreslení omezených ordinací je to default
 – nicméně, dv souřadnicích os, které jsou určeny proměnými prostředí. CaseE score = fitovaná hodnota, tj . Lineární kombinace hodnot proměnných prostředí/ prediktorů (kde by měl vzorek být podle fitovaného modelu) – při kreslení omezených ordinací je to default.")
34
Základní ordinační techniky
Detrending Hybridní analýzy

36
Detrending – druhá osa je BY DEFINITION lineárně nezávislá na první ose (korelční koeficient je nula) – to ale nevylučuje možnost nějaké kvadratické závislosti.
 – to ale nevylučuje možnost nějaké kvadratické závislosti.")
37
Tak vezmeme kladivo a narovnáme ji
Pozor, to děláme při každé iteraci – to velmi často donutí metodu najít ekologicky smysluplný gradient - druhá osa, která je kvadratickou funkcí první osy takovým gradientem často nebývá

38
Detrending by segments (vysoce neparametrické) nebo by polynomials
Tak ji narovnáme Detrending by segments (vysoce neparametrické) nebo by polynomials Bez ohledu na svou “heuristickou” povahu, detrending udělá druhou osu často interpretovatelnou
 nebo by polynomials. Bez ohledu na svou heuristickou povahu, detrending udělá druhou osu často interpretovatelnou.")
39
Detrending by segments je spojeno s takzvaným non-linear rescaling - smysl s.d. – units
Myšlenka je Odpověď druhu na gradient (zde představovaný osou) má tvar gaussovské křivky – „šířka niky“ může být charakterizována pomocí „s.d.“ (odpovídá směrodatné odchylce příslušného normálního rozdělení – průměrná s.d. (přes všechny druhy) je s.d. unit 1 s.d.
 má tvar gaussovské křivky – „šířka niky může být charakterizována pomocí „s.d. (odpovídá směrodatné odchylce příslušného normálního rozdělení – průměrná s.d. (přes všechny druhy) je s.d. unit. 1 s.d.")
40
Jednoduchost vs. realističnost
V unimodálních metodách, souřadnice (skore) druhů jsou optima druhů (předpokládaný vrchol unimodální křivky), v lineárních metodách jsou šipky směry lineární odpovědi Bylo by samozřejmě hezké mít pro každý druh realističtější odpověď – nicméně, u při uvedeném výrazném zjednodušení nedostaneme do ordinačního diagramu obvykle všechny druhy. Uvést komplikovanější typy odpovědí by znamenalo mít ještě méně druhů, a přehlednost by se úplně ztratila.
 druhů jsou optima druhů (předpokládaný vrchol unimodální křivky), v lineárních metodách jsou šipky směry lineární odpovědi. Bylo by samozřejmě hezké mít pro každý druh realističtější odpověď – nicméně, u při uvedeném výrazném zjednodušení nedostaneme do ordinačního diagramu obvykle všechny druhy. Uvést komplikovanější typy odpovědí by znamenalo mít ještě méně druhů, a přehlednost by se úplně ztratila.")
41
CCA (D)CA nebo DVA PŘÍSTUPY
Když máme k dispozici jak data o druhovém složení, tak data o prostředí (obecně, odpovědi i prediktory), máme dvě možnosti. 1. Nejdřív spočteme neomezenou (unconstrained) ordinaci, a do ní pasivně promítneme proměnné prostředí (pomocí regrese), nebo spočteme ordinaci přímou. (D)CA S pasivně promítnutými proměnnými prostředí. nebo CCA
, máme dvě možnosti. 1. Nejdřív spočteme neomezenou (unconstrained) ordinaci, a do ní pasivně promítneme proměnné prostředí (pomocí regrese), nebo spočteme ordinaci přímou. (D)CA. S pasivně promítnutými proměnnými prostředí. nebo. CCA.")
42
Tyto dva přístupy jsou kompementární a měly bychom je užívat oba – nejprve neomezenou, a poté omezenou ordinaci! Pomocí neomezené ordinace jistě zachytíme osy největší variability v druhovém složení, ale některá proměnná prostředí, která má průkazní, ale níkoliv dominantní efekt se může jevit jako nedůležitá, nic nevysvětlující. Když počítáme přímou ordinaci, můžeme vhodně otestovat všechny proměnné prostředí, ale může nám uniknout nejdůležitější osa variability druhového složení, pakliže jsme k ní neměřili příslušnou určující proměnnou prostředí.

43
Co budeme dělat s kategoriálními proměnnými?

45
ANOVA grouping=var4 Regression Summary for Dependent Variable: Var7 (Spreadsheet1) Independent Var5 and Var6 R= R2= Adjusted R2= F(2,7)= p< Std.Error of estimate:
= p< Std.Error of estimate:")
46
Dummy variables V Canoco 5 (nikoliv ve starších versích), expanze faktoru do dummy variables je dělána automaticky (prostě řekneme programu, tohle je faktor – ale je třeba o tom vědět.
, expanze faktoru do dummy variables je dělána automaticky (prostě řekneme programu, tohle je faktor – ale je třeba o tom vědět.")
47
Prediktory an odpovědi jsou obvykle různě korelované, rozdělení odpovědí není normální. Pro testování užíváme proto Monte Carlo permutation test.

48
Monte Carlo permutation test
10,058 – myšleno zde, obecně je to F v nepermutovaných datech

Podobné prezentace



>")
















