Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
AII = Algoritmy pro inženýrskou informatiku
Přednášky

2
Členění přednášek první 2-3 přednášky: úplné základy na téma „jak počítá počítač“ další cca 4 přednášky: základy jazyka Pascal (Delphi) celý zbytek semestru: algoritmy

3
Literatura první téma je popsáno v mnoha menších článcích; souhrnné zpracování neexistuje k výuce Pascalu je vhodná jakákoliv učebnice, na kterou narazíte (ve skriptárně jich je průběžně několik pro FEL, ale vhodné jsou i stredoškolské učebnice apod.).
.")
4
…pokračování... Pro algoritmy je předepsaná učebnice Wirth, Niklaus: Algoritmy a struktúry údajov, ALFA, Bratislava 1988,9. Ideální, ale drahá a anglická je Cormen, Leiserson, Rivest, Stein: Introduction to Algorithms (je to standardní učebnice US vysokých škol, existuje asi ve 30 různých vydáních).
.")
5
…pokračování Jako učebnice Delphi jsou vynikající knihy od Marko Cantú: Mastering Delphi 1...7, jejich české překlady jsou Mistrovství v Delphi 1..4, resp. Myslíme v Delphi Pozor na Mistrovství v Delphi 5; pod tímto názvem vyšlo v češtině něco jiného (není to moc dobré).
.")
6
Požadavky Program přednášek, cvičení, otázky ke zkoušce a další informace jsou na Podmínky pro udělení zápočtu AII: Úspěšné složení nadpoloviční většiny testů, které se budou psát v rámci cvičení z AII.

7
…pokračování Složení zkoušky z AII: Zkouška má teoretickou a praktickou část, tou druhou začíná v učebně 308. Každý student dostane za úkol vytvořit program, na jeho odladění má jednu až cca pět hodin času. Až se mu to povede, může jej obhájit u ústní části. Navazující teoretická část vychází ze zkouškových otázek z tohoto předmětu.

8
Základní funkční bloky počítače
AB mnoho dalších registrů Periférie PC=čítač instrukcí RAM,ROM PSW, SP, ... 100: 37 101: 02 102: 114 103: 56 R/W střadač (akumulátor) dekodér instrukcí ALU μP DB
 dekodér instrukcí. ALU. μP. DB.")
9
…pokračování Základní funkční bloky PC jsou mikroprocesor (μP), paměti (RAM, ROM), periferní zařízení (diskové jednotky, …) navzájem jsou propojeny 3 sběrnicemi: řídicí (zde nakreslen jen vodič R/Ŵ) adresová datová
 adresová. datová.")
10
Adresová sběrnice Jednosměrná: µP -> periférie
šířka 32 bitů: adresovací prostor 232 starší mikroprocesory: šířka jen 20 (24) bitů, adresovací prostor 220 = 1MB, zcela nedostačující, nutnost stránkování
 bitů, adresovací prostor 220 = 1MB, zcela nedostačující, nutnost stránkování.")
11
Datová sběrnice Obousměrná: µP -> periférie nebo periférie -> µP
o směru toku dat rozhoduje vodič R/Ŵ z řídicí sběrnice směr (čtení/zápis) se vždy posuzuje z hlediska mikroprocesoru
 se vždy posuzuje z hlediska mikroprocesoru.")
12
Mikroprocesor Obsahuje mnoho specializovaných pamětí (= registrů)
pro nás jsou důležité střadač (=akumulátor), čítač instrukcí PC, ukazatel zásobníku SP, stavový registr PSW ALU = aritmeticko-logická jednotka, provádí výpočty (výsledek vesměs ukládá do střadače)
, čítač instrukcí PC, ukazatel zásobníku SP, stavový registr PSW. ALU = aritmeticko-logická jednotka, provádí výpočty (výsledek vesměs ukládá do střadače)")
13
Instrukční cyklus Popis instrukčního cyklu zahájíme tím, že čítač instrukcí (PC) obsahuje adresu instrukce, která se má provést. Tudíž ji je potřeba nejprve načíst do µP (tzv. Fetch) obsah PC se po adresové sběrnici rozšíří do všech periférních zařízení ale adresa je jedinečná, proto jen 1 zařízení na ni může reagovat
 obsahuje adresu instrukce, která se má provést. Tudíž ji je potřeba nejprve načíst do µP (tzv. Fetch) obsah PC se po adresové sběrnici rozšíří do všech periférních zařízení. ale adresa je jedinečná, proto jen 1 zařízení na ni může reagovat.")
14
…pokračování... Představme si, že adresa je 100
na adresu 100 zareaguje paměť ROM. Zjistí, že na adrese 100 je hodnota 37. Protože vodič R/Ŵ je ve stavu Read, tak paměť hodnotu 37 přiloží na datovou sběrnici. hodnota z paměti se rozšíří po celém počítači, tedy i do µP

15
…pokračování... Uvnitř µP se hodnota načte do dekodéru instrukcí.
dekodér instrukcí má za úkol rozšifrovat, o jakou se jedná instrukci a podle toho zařídit její provedení po vykonání instrukce čítne PC o +1 takže na adresové sběrnici se objeví další adresa (101) a celý proces se opakuje
 a celý proces se opakuje.")
16
…pokračování... Většina instrukcí není tak jednoduchých
Kdyby se například jednalo o instrukci „přičti číslo, které následuje, k obsahu střadače“, muselo by se nejdříve načíst to „číslo, které následuje“. To znamená, že instrukční cyklus by pokračoval: PC by na adresovou sběrnici přiložil adresu 101,

17
…pokračování... paměť by na datovou sběrnici přiložila obsah adresy 101, v našem případě číslo 02 číslo 02 by se načetlo do µP. Tentokrát by se ale hodnota nenačetla do dekodéru instrukcí, ale přes přepnutý vnitřní přepínač by se přivedla do ALU ALU provede výpočet. Výsledek většinou zůstane ve střadači

18
…pokračování Kdyby šlo o instrukci, která má data zapsat do paměti, průběh by byl obdobný až na to, že vodičem R/Ŵ by se namísto čtení z adresy 101 vyvolal zápis do adresy 101 Tedy: program je posloupnost čísel, která mohou znamenat jak data, tak instrukce - rozhoduje o tom pořadí (první je vždycky instrukční kód)
")
19
Nepodmíněný skok Popsali jsme si průběh programu, který je zcela lineární. Takový program by nebyl k velkému užitku (nepodmíněné) skoky na jinou adresu se provádějí tak, že se do PC vloží cílová adresa skoku (často načtená z paměti, nebo vypočtená) program pak pokračuje od jiné adresy
 skoky na jinou adresu se provádějí tak, že se do PC vloží cílová adresa skoku (často načtená z paměti, nebo vypočtená) program pak pokračuje od jiné adresy.")
20
Podmíněný skok Důležité jsou skoky podmíněné - provádějí se jen tehdy, když nastaly určité podmínky µP obsahuje sadu jednobitových pamětí, sestavených do registru PSW. Po každé instrukci se v PSW nastaví bity podle výsledku instrukce (např. jestli je výsledek nula, záporný, došlo k přetečení apod.) Podmíněné skoky se provedou, když je v PSW správná hodnota
 Podmíněné skoky se provedou, když je v PSW správná hodnota.")
21
Volání procedury Často potřebujeme opakovat nějakou část programu - např. výpočet nějaké funkce Jednoduché: na začátek funkce by šlo skočit z mnoha míst Ale problém: jak zajistit, aby skok na konci funkce směřoval, kam má?! 200 hlavní program 900 funkce 980 300

22
…pokračování... nápad: při skoku na podprogram si poznamenat, odkud se skok prováděl nevýhoda: kdyby si µP poznamenával návratové adresy do registrů, mohl by realizovat jen tolik úrovní podprogramů, kolik by měl registrů řešení: v paměti RAM vytvořit zásobník (stack), velikost podle potřeby
, velikost podle potřeby.")
23
…pokračování... registr SP (=Stack Pointer) bude vždy ukazovat na vrchol zásobníku na začátku např. SP=2000 zavedeme novou instrukci, volání podprogramu (Call) STACK 2000: 2001: 2002: ... SP 2000
 STACK. 2000: 2001: 2002: ... SP")
24
…pokračování... Kdyby v hlavním programu na adrese 200 bylo volání funkce začínající na 900, tak se: návratová adresa (v našem případě 201) zapíše do zásobníku tam, kam ukazuje SP (to znamená na adresu 2000) posune SP tak, aby zase ukazoval na volné místo (tedy na 2001) provede skok na podprogram (v našem příkladu na adresu 900) viz následující obrázek
 zapíše do zásobníku tam, kam ukazuje SP (to znamená na adresu 2000) posune SP tak, aby zase ukazoval na volné místo (tedy na 2001) provede skok na podprogram (v našem příkladu na adresu 900) viz následující obrázek.")
25
…pokračování... STACK 2000: 201 2001: 2002: ... SP 2001

26
…pokračování... Kdyby uvnitř funkce (třeba na adrese 955) bylo další volání (jiného) podprogramu, volání by proběhlo zcela obdobně viz následující obrázek

27
…pokračování STACK 2000: 201 2001: 956 2002: ... SP 2002

28
Návrat z podprogramu Na konci podprogramu musí být zvláštní instrukce RET = návrat z podprogramu Operace se zásobníkem se dělají inverzně k volání, to znamená: STACK 2000: 201 2001: 956 2002: ... SP 2001

29
…pokračování... SP se vrátí na předcházející pozici (je tam číslo 956)
obsah té pozice (číslo 956) se načte a použije se jako adresa, na kterou se skočí. Takže skok na adresu 956 znamená, že jsme se vrátili těsně za poslední volání podprogramu
 se načte. a použije se jako adresa, na kterou se skočí. Takže skok na adresu 956 znamená, že jsme se vrátili těsně za poslední volání podprogramu.")
30
…pokračování až na konci podprogramu (980) najdeme RET, postup se opakuje takže nastane návrat na adresu 201, tedy za volání funkce. STACK 2000: 201 2001: 956 2002: ... SP 2000

31
Teorie a praxe Popsaný postup byl jen schéma; realita se dost liší:
zásobník (stack) roste k menším číslům, t.zn. narůstá nahoru, návratové adresy mají více bytů, a proto zásobník roste/klesá po více bytech, na zásobník se ukládají i četné jiné údaje.
 roste k menším číslům, t.zn. narůstá nahoru, návratové adresy mají více bytů, a proto zásobník roste/klesá po více bytech, na zásobník se ukládají i četné jiné údaje.")
32
Přerušení Typickým příkladem, kdy se pracuje s přerušením, je obsluha pomalých zařízení (tiskárna) přerušení funguje podobně jako volání procedury; vyvolává se však hardwarově na rozdíl od CALL je přerušení asynchronní, může nastat kdykoliv musíme se postarat o PSW na zásobník se ukládá i PSW pro návrat musí být zvláštní instrukce IRET

33
Architektura von Neumannova
Popsaná architektura počítače se nazývá von Neumannova další klasická architektura je harvardská (má oddělenou sběrnici pro přenos dat od sběrnice, po které se přenáší program – vyšší rychlost, zejména při zpracování dat) moderní vývoj zaměřen na zvyšování výkonu hlavně víceprocesorová řešení
 moderní vývoj zaměřen na zvyšování výkonu hlavně víceprocesorová řešení.")
34
Víceprocesorové počítače
Hlavní problém: i malé množství sekvenčních instrukcí dokáže výrazně zpomalit výpočty Několik koncepcí, např. tatáž instrukce x N procesorů (operují na různých datech) maticové procesory (hyperkrychle) RISC (=Reduced Instruction Set Computer)
 maticové procesory (hyperkrychle) RISC (=Reduced Instruction Set Computer)")
35
RISC zjednodušená sada instrukcí: všechny instrukce mají stejný počet taktů (např. 5) současně se vykonává několik (např. 5 instrukcí), ale každá je v jiné fázi důsledek: během každé fáze se dokončí 1 instrukce načtení instrukce výpočet adresy načtení operandu výpočet zápis výsledku
, ale každá je v jiné fázi. důsledek: během každé fáze se dokončí 1 instrukce. načtení instrukce. výpočet adresy. načtení operandu. výpočet. zápis výsledku.")
36
Základy programového vybavení
Program = posloupnost instrukcí a dat, přičemž rozlišit je lze jen pořadím Strojový kód: čitelný pro stroj (ne pro lidi) Jazyk symbolických adres (assembler): zavedení mnemonik (CALL, JMP ADD…). Převod na instrukce 1:1 Vyšší programovací jazyky (FORTRAN, COBOL, LISP, …) - 1 řádek programu se rozvede na N instrukcí
 Jazyk symbolických adres (assembler): zavedení mnemonik (CALL, JMP ADD…). Převod na instrukce 1:1. Vyšší programovací jazyky (FORTRAN, COBOL, LISP, …) - 1 řádek programu se rozvede na N instrukcí.")
37
Vyšší programovací jazyky
zdrojový text se přeloží do mezijazyku (někdy do assembleru) kompilátor připojí se knihovny sestavovací program (linker) výsledek se dopřeloží do spustitelného kódu (vesměs součást linkeru) zdroje knihovny mezikód program
 kompilátor. připojí se knihovny sestavovací program (linker) výsledek se dopřeloží do spustitelného kódu (vesměs součást linkeru) zdroje. knihovny. mezikód. program.")
38
Interpreter Některé jazyky (BASIC, Pascal) lze vedle kompilace také interpretovat. Interpretace probíhá tak, že se program nepřeloží najednou jako celek, nýbrž řádek po řádku se načte přeloží vykoná zapomene. Výhoda: snadné ladění. Nevýhoda: pomalé

39
Krize programování Snaha odstranit omezení, která na programátora kladl programovací jazyk: generace jazyků umožňujících "skoro všechno" (Fortran 77, PL/1, ADA) Zklamání: programátor věnuje psaní kódu jen 20% času, pouhých 10% vymýšlení algoritmů a celých 70% ladění !
 Zklamání: programátor věnuje psaní kódu jen 20% času, pouhých 10% vymýšlení algoritmů a celých 70% ladění !")
40
Jazyky pro usnadnění ladění
snaha definovat jazyky, které by automatizovaly ladění: jazyky 3. generace (PASCAL, ...) Problém: tyto jazyky nepodporují spolupráci více programátorů na jednom projektu !
 Problém: tyto jazyky nepodporují spolupráci více programátorů na jednom projektu !")
41
…pokračování Jak toho dosáhnout:
maximum chyb odhalit už při kompilaci (zejména syntaktické chyby) za chodu programu sledovat podezřelé anomálie, které mohou signalizovat chybu Tímto postupem nelze odhalit algoritmické chyby !
 za chodu programu sledovat podezřelé anomálie, které mohou signalizovat chybu. Tímto postupem nelze odhalit algoritmické chyby !")
42
PASCAL a snadné ladění Silná typová kontrola
nelze použít nic, co nebylo předem deklarováno kontrola správnosti typů při přiřazení apod. kontrola rozsahů a typů za běhu programu „znechucování“ programátorů typický příklad: GOTO strukturované programování

43
Strukturované programování
Programy nelze zkoumat odděleně od dat, nad kterými operují; nutno je chápat v jednotě Programy i data postupně dekomponovat na jednodušší části Důsledek: pro programy používat strukturované příkazy

44
Strukturované příkazy
Strukturovaný příkaz má 1 vstup a 1 výstup Důsledek: příkazy a skupiny příkazů lze do sebe hierarchicky vnořovat Nestrukturované příkazy (jako je IF) nutno upravit
 nutno upravit.")
45
Další vývoj? Objektově orientované programování (viz předmět OOP)
Deklarativní programování (neříkáme počítači, jak to má udělat, ale jen co se má udělat) Grafické programovací rozhraní, programování příkladem, umělá inteligence...
 Grafické programovací rozhraní, programování příkladem, umělá inteligence...")
46
Lokální sítě Omezení na pozemek jednoho majitele (právní důvody)
Celková délka kabelů do stovek metrů Přenosová rychlost (teoreticky) 10, 100 nebo 1000 Mbit/s Médium: optické kabely, metalické kabely (dříve koaxiální, dnes téměř výlučně symetrický kabelový pár = twist)
 10, 100 nebo 1000 Mbit/s. Médium: optické kabely, metalické kabely (dříve koaxiální, dnes téměř výlučně symetrický kabelový pár = twist)")
47
Síť s kruhovou topologií
stanice A stanice D stanice B monitorovací uzel stanice C

48
…pokračování... Když stanice A chce poslat zprávu stanici C, rozdělí ji do rámců (paketů): adresa odesílatele adresa příjemce služební údaje DATA zabezpečení

49
…pokračování... Existují 2 technologie: buď existuje konstantní počet rámců (shodný s počtem stanic), nebo se rámce vkládají stanice A odešle svůj rámec po směru sítě, tzn. stanici B. ta zjistí, že rámec není určen pro ni beze změny ho pošle dál

50
…pokračování... Až stanice C zjistí, že rámec je její a načte si její obsah ve služebních údajích nastaví bit, že si zprávu načetla. Pak paket pošle dál až paket dorazí zpátky k odesílateli A, je to pro něj potvrzením o správném doručení odesílatel A paket stáhne z oběhu

51
…pokračování... Problém: co když vlivem nějaké poruchy dojde k poškození adresy odesílatele? vznikne bludný paket, který bloudí sítí věčně, zdržuje a nikdo ho nezruší proti bludným paketům se zavede monitorovací uzel, který si každý paket při průchodu označí. Jakmile nějaký paket projde monitorovacím uzlem 2x, je bludný a je vyřazen.

52
…pokračování... Typické pro optická vlákna (protože jsou jednosměrná)
známý obchodní produkt: Token Ring® (IBM) největší nevýhoda: citlivost na poruchy (možnost zlepšit zdvojením, viz následující obrázek)
 největší nevýhoda: citlivost na poruchy (možnost zlepšit zdvojením, viz následující obrázek)")
53
Dvojitá kruhová síť stanice A stanice D stanice B stanice C

54
…pokračování... Když v některé sekci dojde k poruše, přilehlé stanice automaticky sekci vyřadí a síť je schopna pokračovat v práci viz obrázek na následující straně

55
…pokračování stanice A stanice D stanice B stanice C

56
Topologie sběrnice/hvězda
Typické pro sítě s protokolem CSMA/CD (Carrier Sense, Multiple Access/Collision Detection): Mnohonásobný náhodný přístup s detekcí nosné a řešením kolize Obchodní produkt: Ethernet® stanice A stanice B stanice Z
: Mnohonásobný náhodný přístup s detekcí nosné a řešením kolize. Obchodní produkt: Ethernet® stanice A. stanice B. stanice Z.")
57
CSMA/CD Zajímavost: poprvé navržena pro rádiovou síť Aloha (universita na Havaji) přenos probíhá v paketech síť nemá žádný řídicí člen (supervizora), což je důležité z hlediska spolehlivosti (vojenství)
, což je důležité z hlediska spolehlivosti (vojenství)")
58
…pokračování... Když stanice A chce odeslat paket, nejprve si poslechne, jestli na lince neběží nějaký přenos (= detekce nosné) pokud zjistí cizí přenos, počká náhodnou dobu a pokusí se znovu pokud nezjistí žádný přenos, začne vysílat svůj paket (= mnohonásobný náhodný přístup)
")
59
…pokračování... kdyby se stalo, že několik stanic začne vysílat současně, jde o kolizi. jak k ní může dojít? Vlivem konečné rychlosti šíření signálu! To je také jeden z důvodů, proč je omezena fyzická délka kabelů. stanice kolizi zjistí tak, že současně s vysíláním poslouchá a kontroluje, jestli přijala totéž, co vyslala

60
…pokračování... při zjištění kolize okamžitě přestane vysílat (resp. ještě odešle signál JAM), počká náhodnou dobu a pokusí se o odeslání paketu později dojde-li k poškození paketu přenosem, zjistí se to pomocí CRC a paket se zahodí o to, aby došly všechny pakety (a ve správném pořadí), se starají vyšší vrstvy podle modelu ISO/OSI
, počká náhodnou dobu a pokusí se o odeslání paketu později. dojde-li k poškození paketu přenosem, zjistí se to pomocí CRC a paket se zahodí. o to, aby došly všechny pakety (a ve správném pořadí), se starají vyšší vrstvy podle modelu ISO/OSI.")
61
Zahlcení sítě Když budeme zvyšovat požadavky na přenos, roste pravděpodobnost kolize. Protože při kolizi se nic nepřeneslo, každá kolize současně zvyšuje požadavky na přenos! V krajním případě může dojít k zahlcení sítě, při kterém se už pro samé kolize nepřenese vůbec nic!

62
…pokračování... teorie skutečně přenesené pakety bod zahlcení
požadavky na přenos

63
…pokračování Proti zahlcení se bojuje tím, že časy, po které stanice při kolizi čeká, jsou sice náhodné - ale při rostoucí hustotě kolizí se protahují. Tak se sice zhoršuje propustnost sítě, ale nikdy nedojde k zablokování (modrá křivka)
")
64
PASCAL - základy syntaxe
slova se oddělují mezerou, tabulátorem, CR/LF nebo komentářem komentář: závorky { xxx } nebo (* xxx *) nebo od // až do konce řádku kompilátor NEROZLIŠUJE malá/velká písmena (samozřejmě mimo stringy) příkazy se oddělují středníkem
 nebo od // až do konce řádku. kompilátor NEROZLIŠUJE malá/velká písmena (samozřejmě mimo stringy) příkazy se oddělují středníkem.")
65
Zlaté pravidlo o střednících
Kdykoliv jste na rozpacích, zda máte či nemáte napsat středník, použijte ho. Jediné 3 případy, kdy se středník napsat nesmí: mezi IF…THEN…ELSE za RECORD (nebo CLASS) za koncem programu ( je tam END. )
 za koncem programu ( je tam END. )")
66
Typický „zubatý“ tvar BEGIN WRITE (‘Toto je příklad‘); IF X<10 THEN
Y := X + 1; WRITE (‘Je menší‘); END;
; END;")
67
Identifikátory Jakákoliv kombinace písmen a číslic, začínající písmenem (znak __ se bere jako písmeno), ale nelze používat diakritiku rozlišuje se jen prvních 64 znaků doporučeno: používat DLOUHÉ identifikátory a kombinovat malá/velká písmena: PlatZaUcetniObdobi

68
Blok LABEL { deklarace návěští } CONST {deklarace konstant }
TYPE {deklarace typů } VAR {deklarace proměnných } PROCEDURE x FUNCTION BEGIN { tělo = výkonná část bloku } END deklarativní procedurální

69
Struktura programu PROGRAM JmenoProgramu; tečka BLOK

70
Procedury a funkce PROCEDURE NazevProcedury (Parametry);
FUNCTION NazevFunkce (Parametry) : Typ; BLOK BLOK
 : Typ; BLOK. BLOK.")
71
Konstanty Pi = 3.141; DlouheCislo = 245897556174;
Sestnactkove = $FF08; JedenZnak = JinyZnak = Chr(64); // nebo #$40, #64 Retezec = ‘Toto je text’; JinyRetezec = ‘Řetězec na tři’#13#10 + ‘řádky‘^M‘pod sebou‘;
; // nebo #$40, #64. Retezec = ‘Toto je text’; JinyRetezec = ‘Řetězec na tři’#13#10 + ‘řádky‘^M‘pod sebou‘;")
72
Typy: klasifikace Obecné schéma: IdentifikátorTypu = Specifikace;
Typy jsou: jednoduché strukturované pointer

73
Jednoduché typy ordinální typy reálné typy
INTEGER 4 byty, a četné odvozené CHAR ASCII, nebo WideChar…UNICODE BOOLEAN jen TRUE nebo FALSE výčtový typ (Karel, Jan, Martin, Lojza) interval reálné typy REAL 8 bytů a četné odvozené
 interval reálné typy. REAL 8 bytů a četné odvozené.")
74
Integer

75
Real

76
Příklady jednoduchých typů
TDenTydne = (Pondeli, Utery, Streda, Ctvrtek, Patek, Sobota, Nedele); // výčet TPracDen = Pondeli..Patek; // výčet TVelkaPismena = ‘A‘..‘Z‘; // interval
; // výčet. TPracDen = Pondeli..Patek; // výčet. TVelkaPismena = ‘A‘..‘Z‘; // interval.")
77
Strukturované typy Pole Záznam (record) Množina Soubor
ARRAY [index] OF TypPrvků Záznam (record) RECORD Množina SET OF BázovýTyp Soubor TEXTFILE // textový FILE OF TypPrvků // binární s typy FILE // binární, netypový
 RECORD. Množina. SET OF BázovýTyp. Soubor. TEXTFILE // textový. FILE OF TypPrvků // binární s typy. FILE // binární, netypový.")
78
Příklady polí ARRAY [Pondeli..Patek] of Real; ARRAY [Char] OF 1..1024;
ARRAY [1..5] OF ARRAY [-6..30] OF ARRAY [1..2] OF Byte; ARRAY [1..5, , 1..2] OF Byte;
![Příklady polí ARRAY [Pondeli..Patek] of Real; ARRAY [Char] OF ;](http://slideplayer.cz/slide/3036757/11/images/78/P%C5%99%C3%ADklady+pol%C3%AD+ARRAY+%5BPondeli..Patek%5D+of+Real%3B+ARRAY+%5BChar%5D+OF+%3B.jpg "ARRAY [1..5] OF ARRAY [-6..30] OF ARRAY [1..2] OF Byte; ARRAY [1..5, , 1..2] OF Byte;")
79
String = zvláštní případ pole
slouží k práci s texty, a to buď v ASCII nebo v UNICODE mnoho stringových procedur a funkcí prakticky neomezená délka Délka, ReferenceCount a nulový byte stringy v Delphi jsou plně kompatibilní s typem PChar 1=RefC 4=délka A H O J ? ?

80
Záznam TZaznam = RECORD A : Real; B, C : Byte; S : String;
R : ARRAY [1..5] OF Real; END;

81
Reference na položky záznamu
Reference se dělá pomocí „tečkové notace“: nejdříve v části TYPE nadeklarujeme typ (např. typ Tzaznam podle předch. obrázku) pak v části VAR vytvoříme proměnnou toho typu, např. Zaznam : TZaznam;
 pak v části VAR vytvoříme proměnnou toho typu, např. Zaznam : TZaznam;")
82
…pokračování pak se lze odvolávat na jednotlivé části záznamu například takto: Zaznam.A …reálné číslo Zaznam.C …byte Zaznam.S …string Zaznam.S [6] …6-tý znak stringu Zaznam.R [3] …3-tí reálné číslo pole R bez mezer kolem tečky !

83
Záznam s variantní částí
Začátek je konstantní data od CASE až na konec jsou variantní. Selektor záznamu je nepovinný; není-li uveden, musí se jednotlivé identifikátory lišit tak, aby je kompilátor rozpoznal (pozor, v Delphi se musí lišit vždy!)
")
84
Příklad záznamu s variantní částí
TZv = RECORD Cena : Real; CASE D: TDenTydne OF Pondeli: (A : real; B : Byte); Utery ..Nedele: (X : Integer); END;
; Utery. ..Nedele: (X : Integer); END;")
85
(doplněno podle nejdelší varianty)
…vysvětlení se selektorem záznamu: bez selektoru záznamu Cena Cena Cena Cena D D A X A X B B volné místo (doplněno podle nejdelší varianty)
")
86
Množina Smyslem množiny je, zpřístupnit rychlé strojové instrukce AND, OR apod. Bázový typ množiny musí být ordinální Z praktických důvodů smí mít nejvýše 256 prvků (= 32 bytů) Množina se vytváří konstruktorem množiny
 Množina se vytváří konstruktorem množiny.")
87
Příklad práce s množinou
TYPE TMnozina = SET OF CHAR; VAR X, Y : TMnozina; BEGIN X := [‘A‘,‘B‘,‘X‘]; Y := X + [‘Y‘]; // sjednocení X := Y * [‘A‘, ‘Y‘, ‘C‘]; // průnik IF ‘X‘ IN Y …. // je prvkem ?

88
Soubory textový soubor: čitelný pro člověka (číslo je ve formě jednotlivých číslic, jako když se tiskne na tiskárně), ale kvůli nutným konverzím pomalé binární soubor: čísla jsou ve stejném formátu jako v paměti binární soubor je typový (všechny záznamy musejí být stejného typu) nebo netypový (není určeno, jaká data obsahuje) v OOP je zvláštní případ Stream
, ale kvůli nutným konverzím pomalé. binární soubor: čísla jsou ve stejném formátu jako v paměti. binární soubor je typový (všechny záznamy musejí být stejného typu) nebo netypový (není určeno, jaká data obsahuje) v OOP je zvláštní případ Stream.")
89
Příklad čtení textového souboru
VAR F : TextFile; S : string; R : Real; BEGIN AssignFile (F, ‘C:\TEMP\Data.TXT‘); Reset (F); Read (F, R); ReadLn (F, S); ReadLn (F, R, S); CloseFile (F); neuvedeme-li F, čte se z klávesnice stringy se mohou číst jedině pomocí ReadLn
; Reset (F); Read (F, R); ReadLn (F, S); ReadLn (F, R, S); CloseFile (F); neuvedeme-li F, čte se z klávesnice. stringy se mohou číst jedině. pomocí ReadLn.")
90
Zápis do textového souboru
VAR F : TextFile; S : string; R : Real; BEGIN AssignFile (F, ‘C:\TEMP\Data.TXT‘); Rewrite (F); // nebo Append (F); Write (F, 3.141); //přípustné formátové specifikace R:7:2 WriteLn (F, R, ‘je výsledek‘); CloseFile (F);
; Rewrite (F); // nebo Append (F); Write (F, 3.141); //přípustné formátové specifikace R:7:2. WriteLn (F, R, ‘je výsledek‘); CloseFile (F);")
91
Čtení typ. binárního souboru
VAR F : FILE OF Real; R : Real; BEGIN AssignFile (F, ‘C:\TEMP\Data.TXT‘); Reset (F); Read (F, R); Seek (F, 23); // současně otevře i pro zápis Read (F, R); // ReadLn samozřejmě nelze CloseFile (F);
; Reset (F); Read (F, R); Seek (F, 23); // současně otevře i pro zápis. Read (F, R); // ReadLn samozřejmě nelze. CloseFile (F);")
92
Zápis do typ. binárního souboru
VAR F : FILE OF Real; R : Real; BEGIN AssignFile (F, ‘C:\TEMP\Data.TXT‘); Rewrite (F); // nebo Append (F); Write (F, 3.141); Seek (F, 23); // současně otevře i pro čtení Write (F, R); // nebo Read (F, R); CloseFile (F);
; Rewrite (F); // nebo Append (F); Write (F, 3.141); Seek (F, 23); // současně otevře i pro čtení. Write (F, R); // nebo Read (F, R); CloseFile (F);")
93
Čtení z netypového souboru
VAR F : FILE; i, j : Integer; Buf : ARRAY[ ] OF Byte; BEGIN AssignFile (F, ‘C:\Data.TXT‘); Reset (F, 1); i := SizeOf (Buf); BlockRead (F, Buf, i, j); IF i<>j THEN Chyba…. počet bytů na 1 položku poslední parametr je nepovinný
; Reset (F, 1); i := SizeOf (Buf); BlockRead (F, Buf, i, j); IF i<>j THEN Chyba…. počet bytů na 1 položku. poslední parametr. je nepovinný.")
94
Proměnné zapisují se v části VAR obecné schéma:
Identifikátor : TypProměnné; teprve zápisem v části VAR se proměnným přiděluje místo v paměti. Mluvíme o statické alokaci paměti. Později uvidíme, že existuje i dynamická alokace.

95
Typované konstanty Chovají se jako proměnné, ve starších verzích do nich šlo i přiřazovat hodnotu (dnes o tom rozhoduje direktiva kompilatoru) Jedinou podstatnou změnou je, že mají definovanou počáteční hodnotu. Poznámka: typované konstanty si každý procvičí individuálně; na cvičení se budou probírat složitější případy!

96
…pokračování... CONST Maximum: word = 26; Pomer: real = -0.723;
Adresa : pointer = Addr(X); { musím znát při kompilaci } Zahlavi: string[5]='Sekce'; Pravda : string[9] ='Ano';
; { musím znát při kompilaci } Zahlavi: string[5]= Sekce ; Pravda : string[9] = Ano ;")
97
…pokračování... Typovanými konstantami mohou být též pole a recordy, což je velmi výhodné, protože se do nich jednoduše zadávají počáteční hodnoty. Vektory pole se uzavřou do závorky:

98
…pokračování... TYPE TPole = ARRAY[1..3] OF string[20]; CONST
Pole : TPole = ( 'Jedna', 'Dva', 'Tri' ); Digits: ARRAY [1..9] OF Char = ('1','2','3','4','5','6','7','8','9');
![…pokračování... TYPE TPole = ARRAY[1..3] OF string[20]; CONST](http://slideplayer.cz/slide/3036757/11/images/98/%E2%80%A6pokra%C4%8Dov%C3%A1n%C3%AD...+TYPE+TPole+%3D+ARRAY%5B1..3%5D+OF+string%5B20%5D%3B+CONST.jpg "Pole : TPole = ( Jedna , Dva , Tri ); Digits: ARRAY [1..9] OF Char = ( 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 );")
99
…pokračování... Digits : ARRAY [1..9] OF Char { dovolené zjednodušení } = ' ';
![…pokračování... Digits : ARRAY [1..9] OF Char { dovolené zjednodušení } = ;](http://slideplayer.cz/slide/3036757/11/images/99/%E2%80%A6pokra%C4%8Dov%C3%A1n%C3%AD...+Digits+%3A+ARRAY+%5B1..9%5D+OF+Char+%7B+dovolen%C3%A9+zjednodu%C5%A1en%C3%AD+%7D+%3D+%3B.jpg "…pokračování... Digits : ARRAY [1..9] OF Char { dovolené zjednodušení } = ;")
100
…pokračování... Pokud je pole vícerozměrné, musí se do závorek uzavřít vektory v každé dimenzi: TYPE TMatrix = ARRAY [0..1, 0..1] OF integer; CONST Matrix : TMatrix = ( (1,2), (3,4) );
, (3,4) );")
101
…pokračování... Podobně (tzn. v závorkách) se dají zadat též položky recordu. U recordů se navíc musí udat též jméno položky (zakončené dvojtečkou) a položky se musí zapsat v přesně stejném pořadí jako byly deklarovány. Příklad:
 se dají zadat též položky recordu. U recordů se navíc musí udat též jméno položky (zakončené dvojtečkou) a položky se musí zapsat v přesně stejném pořadí jako byly deklarovány. Příklad:")
102
…pokračování... TYPE TBod = RECORD X,Y : real END; CONST Bod : TBod

103
…pokračování... Podobná pravidla platí i pro množiny, které se konstruují uzavřením do hranatých závorek: TYPE TDig = SET OF 0..9; CONST Licha : TDig = [1,3,5,7,9];

104
…pokračování... Ale pozor, nefunguje použití typované konstanty jako dimenze pole. Potřebujeme-li vytvořit dynamická pole, musíme postupovat jinak (viz dynamická a otevřená pole).
.")
105
…pokračování Toto nefunguje! CONST Mez : integer = 28; TYPE
Pole = ARRAY[1..Mez] OF ...

106
Deklarace procedur a funkcí
Procedury + funkce = Metody procedury nevracejí hodnotu funkce vracejí hodnotu (libovolného typu) deklarace používá formální parametry, které jsou při volání nahrazeny skutečnými parametry (samozřejmě musejí být kompatibilního typu)
 deklarace používá formální parametry, které jsou při volání nahrazeny skutečnými parametry (samozřejmě musejí být kompatibilního typu)")
107
Hlavička a tělo metod Existují dvě varianty: tělo procedury = blok
hlavička metody, za ní bezprostředně tělo nebo hlavička (tzv. forward = dopředná deklarace) a na jiném místě hlavička i tělo; v takovém případě by obě hlavičky měly být totožné (používejte Ctrl+Shift+C) tělo procedury = blok všechny deklarace jsou v bloku lokální po opuštění bloku ztrácejí proměnné hodnotu
 a na jiném místě hlavička i tělo; v takovém případě by obě hlavičky měly být totožné (používejte Ctrl+Shift+C) tělo procedury = blok. všechny deklarace jsou v bloku lokální. po opuštění bloku ztrácejí proměnné hodnotu.")
108
Příklady hlaviček PROCEDURE Jedna ( S:string; P,Q:real );
FUNCTION Dva : TDenTydne; FUNCTION Tri ( var A:byte; B:char ) : real; PROCEDURE Ctyri ( const X: string ); pokud se použijí specifikátory (override, overload, abstract, virtual, dynamic apod.), tak se píší jen za první hlavičku a oddělují se středníkem
 : real; PROCEDURE Ctyri ( const X: string ); pokud se použijí specifikátory (override, overload, abstract, virtual, dynamic apod.), tak se píší jen za první hlavičku a oddělují se středníkem.")
109
Parametry metod není-li uvedeno jinak, předávají se hodnotou. Hodnota parametru se zkopíruje na zásobník, kde s ní metoda pracuje a po ukončení metody se ta hodnota zapomene uvnitř metody můžeme s hodnotou libovolně pracovat a měnit ji žádná změna parametru se nepřenese ven z metody

110
Parametry volané odkazem
parametry označené jako VAR se předávají odkazem = jménem = adresou. Metodě se nepředává parametr jako takový, ale jen adresa jeho umístění v paměti. změny VAR parametrů jsou trvalé (je to způsob, jak exportovat výsledky ven) jako skutečné parametry lze za VAR parametry dosadit jen to, co má adresu (příklad: 3*(N+1) je špatně !!)
 jako skutečné parametry lze za VAR parametry dosadit jen to, co má adresu (příklad: 3*(N+1) je špatně !!)")
111
Příkazy všechny příkazy jazyka Pascal (Delphi) jsou strukturované
 jsou strukturované")
112
Příkazy: klasifikace... Jednoduchý příkaz přiřazovací := bez mezer!
volání procedury/funkce použitím jména a skutečných parametrů skok GOTO prázdný ; ;

113
…pokračování Strukturované příkazy složený BEGIN … END podmíněný IF
CASE cyklu FOR WHILE REPEAT with WITH

114
Přiřazovací příkaz dvojznak := bez mezery
přiřazovat lze jen výrazy slučitelného (kompatibilního typu). Nemusejí to být jen totožné typy (může např. jít o 2 intervaly na tomtéž hostitelském typu apod.) přiřazuje se celá proměnná, i strukturovaná (tzn. netřeba přiřazovat po položkách). Výjimka u pointerů (stringy, objekty, …)
. Nemusejí to být jen totožné typy (může např. jít o 2 intervaly na tomtéž hostitelském typu apod.) přiřazuje se celá proměnná, i strukturovaná (tzn. netřeba přiřazovat po položkách). Výjimka u pointerů (stringy, objekty, …)")
115
Konverze při přiřazení
při přiřazení se automaticky provádí konverze INTEGER REAL obráceným směrem to nejde !

116
Příkaz (volání) procedury, funkce
zapíše se její jméno se skutečnými parametry (musejí být správného typu) srovnejte deklaraci: FUNCTION Xyz (A:integer; B,C: real) : string; a volání této funkce: S := Xyz ( N, 123, N*(22/7) ); Poznámka: další podrobnosti probereme později
 srovnejte deklaraci: FUNCTION Xyz (A:integer; B,C: real) : string; a volání této funkce: S := Xyz ( N, 123, N*(22/7) ); Poznámka: další podrobnosti probereme později.")
117
Některé standardní procedury
Rewrite (F) otevře soubor pro zápis Append (F) dtto, ale za koncem Reset (F) otevře soubor pro čtení Read (F, Var1, Var2, …) načtení Write (F, Var1, Var2, …) zápis CloseFile (F) zavření souboru
 otevře soubor pro zápis. Append (F) dtto, ale za koncem. Reset (F) otevře soubor pro čtení. Read (F, Var1, Var2, …) načtení. Write (F, Var1, Var2, …) zápis. CloseFile (F) zavření souboru.")
118
Některé standardní funkce...
ABS (X) absolutní hodnota SQR (X) X2 SQRT (X) odmocnina SIN (X), COS (X), ARCTAN (X) EXP (X) eX LN (X) lneX TRUNC (X) odsekávání 3.7 3 ROUND (X) zaokrouhlení 3.7 4
 absolutní hodnota. SQR (X) X2. SQRT (X) odmocnina. SIN (X), COS (X), ARCTAN (X) EXP (X) eX. LN (X) lneX. TRUNC (X) odsekávání 3.7 3. ROUND (X) zaokrouhlení 3.7 4.")
119
…pokračování... ORD (X) ordinální číslo CHR (X) ASCII znak číslo X
SUCC (X) následovník PRED (X) předchůdce ODD (X) True, je-li X liché EOF (F) True, je-li konec souboru F EOLN (F) True na konci řádky textového souboru
 následovník. PRED (X) předchůdce. ODD (X) True, je-li X liché. EOF (F) True, je-li konec souboru F. EOLN (F) True na konci řádky. textového souboru.")
120
…pokračování... FORMAT (‘Toto je %d. formátovací %s‘,
[ 1, ‘string‘] ); IntToStr (123); StrToInt (‘000321’); DateTimeToStr (Now); ShowMessage (‘Stiskni tlačítko‘); k := MessageDlg (‘Toto se vypíše‘, mtError, [mbYes, mbNo], );
; IntToStr (123); StrToInt (‘000321’); DateTimeToStr (Now); ShowMessage (‘Stiskni tlačítko‘); k := MessageDlg (‘Toto se vypíše‘, mtError, [mbYes, mbNo], );")
122
Příkaz GOTO není strukturovaný, ale je užitečný
aby se omezilo riziko jeho použití, jsou uměle kladeny překážky nutno definovat návěští (v části LABEL) návěštím nutno označit cíl skoku skok lze provádět jen uvnitř jednoho bloku!
 návěštím nutno označit cíl skoku. skok lze provádět jen uvnitř jednoho bloku!")
123
Příklad GOTO LABEL CilSkoku; BEGIN ……. CilSkoku: GOTO CilSkoku;

124
Prázdný příkaz neobsahuje nic: ; ; ;
; ; ; má hlavně syntaktický význam: způsobuje, že středník můžeme napsat skoro všude (je-li tam nadbytečný, pokládá se za prázdný příkaz)
")
125
Priorita operátorů NOT * + = / - <> DIV OR < <=
/ - <> DIV OR < <= MOD XOR > >= AND

126
středník zde být nemusí,
Složený příkaz „programové závorky“ BEGIN P1; P2; … Pn END středník zde být nemusí, ale může

127
Podmíněný příkaz IF IF podmínka THEN příkaz1
IF podmínka THEN příkaz1 ELSE příkaz2 zde nesmí být středník ! podmínka příkaz1 příkaz2

128
Podmíněný příkaz CASE... příkaz1 příkaz2 příkazN

129
za zapomenutí tohoto END
…pokračování CASE... CASE proměnná OF Varianta1: Příkaz1; Varianta2: Příkaz2; ….. VariantaN: PříkazN; END; za zapomenutí tohoto END se vyhazuje od zkoušky !

130
…pokračování CASE Obvyklá rozšíření: 3..5 3, 4, 5
interval namísto výčtu variant: , 4, 5 ELSE pro neuvedené varianty nejsou zde žádné BREAKy apod. provede se jen správný příkaz (v Pascalu jsou příkazy paralelně, v C sériově!)
")
131
Cyklus FOR FOR i := Pondeli TO Nedele DO příkaz;
FOR i := Nedele DOWNTO Pondeli DO příkaz pracuje s jakýmkoliv ordinálním typem krok může být jen +1 nebo -1 řídicí proměnná cyklu musí být z téhož bloku! příkaz smí být jen jeden (BEGIN…END)
")
132
Cyklus WHILE - +

133
WHILE - pokračování WHILE podmínka DO příkaz;
test je před příkazem, tedy příkaz nemusí proběhnout ani jednou ! cyklus ukončí hodnota False příkaz je jen jeden (složený BEGIN…END)
")
134
Cyklus REPEAT - +

135
REPEAT - pokračování oproti WHILE je „všecho naopak“:
test je až na konci, proto příkazy vždy proběhnou aspoň jednou příkazů může být více cyklus se ukončí hodnotou True typické pro nekonečný cyklus: REPEAT ….. UNTIL False

136
Nestandardní rozšíření cyklů
BREAK - vyskočí se z cyklu ven a pokračuje se příkazem následujícím za cyklem CONTINUE - zvětší/zmenší se řídicí proměnná a zahájí se nový průchod cyklem EXIT (platí obecně, ne jen v cyklech) - vyskočí se ven z procedury/funkce
 - vyskočí se ven z procedury/funkce.")
137
Příkaz WITH není to výkonný příkaz - nedělá nic viditelného
usnadňuje programování při práci s recordy (jde o jakési „vytknutí před závorku“) doporučuje se hojně používat, protože kompilátor s ním vytváří optimalizovaný kód
 doporučuje se hojně používat, protože kompilátor s ním vytváří optimalizovaný kód.")
138
Příklad WITH WITH Xyz DO BEGIN A := … D := B + Cena; END;
proměnná Xyz WITH Xyz DO BEGIN A := … D := B + Cena; END; namísto Xyz.A.. Xyz.D.. apod Cena D A B

139
Oblast platnosti identifikátorů
identifikátor platí uvnitř bloku, ve kterém je definován sejdou-li se 2 stejné identifikátory, které označují každý něco jiného, tak má přednost ten lokálnější, tzn. vnitřnější. Méně lokální identifikátor jím je přemaskován, tedy není přístupný, ale nepřestal existovat!

140
Příklad kolize identifikátorů
zde platí A, B a A, Z, ale nelze použít A , protože je přemaskován A VAR A, B VAR A, Z zde platí A, B a neplatí A, Z

141
ALGORITMY a datové struktury

142
Základní pravidlo OOP Algoritmy a data nikdy nelze posuzovat odděleně, ale vždy jen ve vzájemné jednotě a souvislostech.

143
Zásobník LIFO=Last In, First Out Realizace #1: pomocí pole
potřebujeme pole P a ukazatel Z na vrchol zásobníku (= index prvního volného místa) 3 2 1
")
144
… pokračování Zásobníku ...
při zápisu se zapíše na (volné) místo, kam ukazuje Z, pak se Z posune na další volné místo. Přitom nutno kontrolovat přetečení, tzn. aby Z nepřesáhlo meze pole. při čtení se nejdřív Z o jednu pozici vrátí a potom se čte z místa, kam ukazuje Z. Přitom nutno kontrolovat podtečení (tzn. aby Z nebylo menší než nejmenší index pole, čili aby se nečetlo, co ještě nebylo zapsáno)
 místo, kam ukazuje Z, pak se Z posune na další volné místo. Přitom nutno kontrolovat přetečení, tzn. aby Z nepřesáhlo meze pole. při čtení se nejdřív Z o jednu pozici vrátí a potom se čte z místa, kam ukazuje Z. Přitom nutno kontrolovat podtečení (tzn. aby Z nebylo menší než nejmenší index pole, čili aby se nečetlo, co ještě nebylo zapsáno)")
145
…pokračování Zásobníku
Realizace #2: pomocí spojového seznamu (viz později) - jedná se o jeho zvláštní případ zvlášť výhodné je použití zásobníku při rekurzi
 - jedná se o jeho zvláštní případ. zvlášť výhodné je použití zásobníku při rekurzi.")
146
Fronta FIFO=First In, First Out Realizace #1: pomocí pole
potřebujeme pole P, ukazatel Z na začátek fronty a ukazatel K na konec fronty 3 2 1

147
…pokračování Fronty... A H O J K Z při zápisu se zapíše na (volné) místo, kam ukazuje Z, pak se Z posune na další volné místo při čtení se čte z místa, kam ukazuje K a po přečtení se K posune na další pozici. Přitom nutno kontrolovat podtečení (tzn. aby K nepředběhlo nebo nebylo rovno Z)
")
148
… pokračování Fronty Realizace #2: pomocí spojového seznamu (viz později) - jedná se o jeho zvláštní případ typické použití: klávesnice, tiskárna, … problém: pole by mělo být „nekonečné“ řešení: kruhová fronta

149
Kruhová fronta dosahuje se funkcí modulo:
i:=(i+1) mod N je nutno také kontrolovat přetečení, tzn. aby začátek nedosáhl či nepřepsal konec
 mod N. je nutno také kontrolovat přetečení, tzn. aby začátek nedosáhl či nepřepsal konec.")
150
statické proměnné (VAR)
Volná paměť = heap program statické proměnné (VAR) zásobník volná paměť Motivace: dosavadní prostředky neumožnily dynamicky měnit velikost nebo počet proměnných Volná paměť (Heap) se využívá jako prostor, ve kterém si můžeme dočasně vytvářet (a rušit) proměnné
 zásobník. volná paměť. Motivace: dosavadní prostředky neumožnily dynamicky měnit velikost nebo počet proměnných. Volná paměť (Heap) se využívá jako prostor, ve kterém si můžeme dočasně vytvářet (a rušit) proměnné.")
151
Dynamické proměnné Proměnné, které dynamicky (=za chodu a podle potřeby) vytváříme ve volné paměti se nazývají dynamické proměnné na začátku nepotřebujeme znát jejich počet podstatný rozdíl: ke statickým proměnným (VAR) přistupujeme přes jejich název (identifikátor) dynamické proměnné název nemají (a mít nemohou): jak se k nim přistupuje ?!
 přistupujeme přes jejich název (identifikátor) dynamické proměnné název nemají (a mít nemohou): jak se k nim přistupuje !")
152
Pojem POINTERu Pointer = směrník = ukazatel
vypovídá o proměnné 2 věci: kde se proměnná v paměti nachází, tzn. určuje její adresu jak se s proměnnou má pracovat, tzn. definuje její typ z hlediska syntaxe se chová jako každá jiná proměnná

153
Příklady deklarace pointeru...
VAR JmenoPromenne : ^NejakyTyp; nebo JinaPromenna : JmenoTypuPointer; pokud jsme ovšem předtím provedli TYPE JmenoTypuPointer = ^NejakyTyp;

154
…a vysvětlení VAR P : ^real;
tím jsme vytvořili statickou proměnnou P, dlouhou 4 byty. Ta (po přiřazení) bude obsahovat adresu do paměti (typicky do heapu) a na této adrese bude ležet proměnná typu real paměť statických proměnných P 4567 obsah= 3.141 adresa= 4567 volná paměť (heap)
 bude obsahovat adresu do paměti (typicky do heapu) a na této adrese bude ležet proměnná typu real. paměť statických proměnných. P obsah= adresa= volná paměť (heap)")
155
Konvence Podobně jako je zvykem, všechny typy označovat pomocí identifikátorů začínajících na T…, tak je zvykem pointery označovat pomocí identifikátorů začínajících na P…, např. type PReal = ^real; PPrvek = ^TPrvek;

156
Pomůcka stříška ^ před typem proměnné je zdegenerovaná šipka , která bývala na starých klávesnicích nad klávesou 6 to mělo mnemotechnický význam: P : ^real se dá číst jako „P je typu šipka (=ukazatel) na real“
 na real")
157
New pro práci s dynamickou pamětí existuje procedura New. Jako parametr se jí předá pointer New z volné paměti „vyřízne“ tolik bytů, kolik je potřeba (podle toho, na jaký typ ten pointer ukazuje) a do pointeru přiřadí adresu té „vyříznuté“ paměti
 a do pointeru přiřadí adresu té „vyříznuté paměti.")
158
Příklad New var P: ^real; begin New (P);
ve volné paměti se našlo místo pro 1 číslo real, na které ukazuje P P volná paměť (heap)
")
159
Poznámky kolik místa se má z volné paměti „vyříznout“, pozná New podle toho, na jaký typ P ukazuje obsah paměti, na kterou P po provedení New(P) ukazuje, není definován. Proto je třeba přiřadit si do P^ nějakou hodnotu, než budeme P^ používat
 ukazuje, není definován. Proto je třeba přiřadit si do P^ nějakou hodnotu, než budeme P^ používat.")
160
Dispose Obrácenou operací k New je Dispose
Za to, aby se nepotřebné dynamické proměnné vrátily systému pomocí Dispose, je odpovědný programátor ! Proceduře Dispose se jako parametr předá pointer na dynamickou proměnnou. Dispose „přilepí“ místo zabrané tou proměnnou zpátky k volné paměti POZOR, Dispose hodnotu P nezmění, ale P^ se pak už nesmí používat !

161
Fragmentace paměti Nevýhodou častého používání New a Dispose je, že časem dojde ke fragmentaci paměti. Některé jazyky používají Garbagge Collector (obdoba Defrag pro paměť), ale Delphi nikoliv (problém real-time aplikací) Pascal používá jiný mechanismus v Delphi se objektový mechanismus stará o správné Dispose nepotřebných objektů
, ale Delphi nikoliv (problém real-time aplikací) Pascal používá jiný mechanismus. v Delphi se objektový mechanismus stará o správné Dispose nepotřebných objektů.")
162
Dereference... Základní operace s pointerem se nazývá dereference. Je to nalezení proměnné, na kterou pointer ukazuje. Označuje se šipkou (resp. stříškou): Je-li P : ^real; tak P^ je dereference která znamená „vyjdi z P, jdi po směru šipky a pracuj s proměnnou, na kterou tam narazíš“
: Je-li P : ^real; tak P^ je dereference která znamená „vyjdi z P, jdi po směru šipky a pracuj s proměnnou, na kterou tam narazíš")
163
…vysvětlení P^ tedy znamená proměnnou (v našem případě typu real)
velký praktický význam mají pointery na typ record 4567 proměnná real adresa= 4567 volná paměť (heap)
")
164
funkce Addr (X) Rozšíření jazyka: funkce P := Addr (X);
vrací adresu (pointer) na libovolnou proměnnou X. Platí i na statické proměnné. Tato funkce je kompatibilní s libovolným pointerem. Platí rovnost Addr(X)^ = X v Delphi má stejný význam i (nedoporučuji používat)
 na libovolnou proměnnou X. Platí i na statické proměnné. Tato funkce je kompatibilní s libovolným pointerem. Platí rovnost Addr(X)^ = X. v Delphi má stejný význam i (nedoporučuji používat)")
165
Pointer a položky recordu
Pokud P je pointer na nějaký record, pak P^ znamená celý tento record. Na jednotlivé položky recordu se můžeme odvolávat běžným způsobem pomocí „tečkové notace“. Například: P^.Jmeno …v recordu, na který ukazuje pointer P, bereme položku Jmeno (string) P^.Dalsi …v recordu, na který ukazuje pointer P, bereme položku Dalsi (pointer)
 P^.Dalsi …v recordu, na který ukazuje pointer P, bereme položku Dalsi (pointer)")
166
Přiřazování pointerů Z hlediska syntaxe je pointer proměnná jako každá jiná; lze ji tedy i přiřazovat (při zachování pravidel kompatibility; přiřazovat lze mezi ukazateli na kompatibilní typy) NIL je kompatibilní s jakýmkoliv pointerem a znamená „pointer který neukazuje nikam“ (má hodnotu $0000) typ POINTER je kompatibilní s jakýmkoliv ukazatelem (ale nelze ho dereferovat!)
 NIL je kompatibilní s jakýmkoliv pointerem a znamená „pointer který neukazuje nikam (má hodnotu $0000) typ POINTER je kompatibilní s jakýmkoliv ukazatelem (ale nelze ho dereferovat!)")
167
Pozor při přiřazování Při přiřazování pointerů je třeba dávat pozor: existují 2 různé zápisy; oba jsou správné, ale každý znamená něco jiného! varianta 1 P := Q; varianta 2 P^ := Q^;

168
Přiřazení 1 P P := Q; způsobí, že P bude ukazovat na stejnou adresu jako Q tedy P^ i Q^ dá stejnou hodnotu 5678 ale P i Q teď ukazují na tutéž proměnnou k proměnné „1234“ se ztratil přístup (!) 1234 Q 5678 P 1234 Q 5678
 Q P Q")
169
Přiřazení 2 P^ := Q^; způsobí, že do P^ se zkopíruje obsah Q^
tedy P^ i Q^ dá stejnou hodnotu 5678 P i Q pořád jsou různé proměnné 1234 Q 5678 P 5678 Q 5678

170
Použití pointerů v recordech
Typické je používání pointerů v recordech: TPrvek = record Jmeno: string; Plat: real; … Další: ^TPrvek; end; Výjimka z pravidla, že identifikátor musí být dřív nadeklarován, než je použit (Zdůvodnění: každý pointer má délku 4 byty, lze mu tudíž přiřadit místo v paměti)
")
171
Vysvětlení... Položka Další v recordu TPrvek na první pohled vypadá, jako by šlo o nějakou divnou rekurzi, při které record ukazuje sám na sebe Tak to ale vůbec není! Další neukazuje na stejný record, nýbrž na jiný record stejného typu

172
… vysvětlení prostřednictvím položky „Další“ se recordy mohou navzájem různě propojovat typické použití: seznamy Jméno Plat Další Jméno Plat Další

173
Jednoduchý spojový seznam
Jednoduchý = propojený 1 pointerem Spojový = realizovaný pomocí pointerů (spojů) Seznam = nějaká data Další nějaká data Další nějaká data Další
 Seznam = nějaká data. Další. nějaká data. Další. nějaká data. Další ")
174
Seznam Aby se k seznamu dalo přistupovat, potřebujeme jednu statickou proměnnou, která bude ukazovat na jeho začátek (obvykle se nazývá Hlava) Ostatní prvky seznamu už mohou být vytvořeny ve volné paměti (heapu)
")
175
Vytvoření seznamu Na začátku je seznam prázdný, tzn. neobsahuje žádný prvek, proto Hlava neukazuje nikam, má hodnotu NIL var Hlava: ^TPrvek; begin Hlava := Nil;

176
Přidat prvek na začátek seznamu
Hlava Pom na začátku máme hlavu seznamu Hlava (obsahuje NIL) a pomocnou proměnnou Pom (typu ^TPrvek) X X
 a pomocnou proměnnou Pom (typu ^TPrvek) X. X.")
177
Přidat prvek na začátek (krok 1)
Hlava Pom pomocí New vytvoříme nový prvek, na který ukazuje Pom do nového prvku naplníme data X Jméno Plat

178
Přidat prvek na začátek (krok 2)
Hlava Pom to, co předtím bylo v pointeru Hlava, překopírujeme do položky Další toho nového prvku (v našem příkladu tam byla hodnota NIL, proto se do Pom^.Další vlozi NIL) Pom^.Další := Hlava; X Jméno Plat X
 Pom^.Další := Hlava; X. Jméno. Plat. X.")
179
Přidat prvek na začátek (krok 3)
Hlava Pom do pointeru Hlava nakopírujeme obsah Pom, čili adresu nového prvku tím je přidání skončeno poznámka: nemohli jsme provést rovnou New(Hlava), protože by se nám tím ztratil původní obsah pointeru Hlava Jméno Plat X
, protože by se nám tím ztratil původní obsah pointeru Hlava. Jméno. Plat. X.")
180
Přidat prvek na začátek (příklad)
Hlava Pom var Pom: ^TPrvek; begin New(Pom); Pom^.Jmeno := …..; Pom^.Další := Hlava; Hlava := Pom; Jméno Plat X
; Pom^.Jmeno := …..; Pom^.Další := Hlava; Hlava := Pom; Jméno. Plat. X.")
181
Přidat prvek na začátek (další)
postupovali jsme takto, protože to je univerzální algoritmus, který lze aplikovat i na částečně už zaplněný seznam Hlava Pom Jméno Jméno Plat Plat X

182
Procházení seznamem seznamem se dá procházet jen jedním směrem
potřebujeme pomocný pointer Pom začíná se vždy v Hlava Pom := Hlava; procházení: Pom := Pom^.Další; Hlava Jméno Plat Jméno Jméno Plat Plat X

183
Seznam x zásobník Povšimněte si, že když procházíme seznam od Hlavy ke konci, pořadí prvků je od nejnovějšího po nejstarší, tedy LIFO tedy zásobník lze realizovat jako specielní případ seznamu, u kterého přidáváme na začátek a čteme od Hlava

184
Přidat prvek na konec seznamu
na konec seznamu se přidává špatně, protože bychom museli nejprve ten konec najít (což je zdlouhavé) proto vedle pointeru Hlava zavedeme ještě další pointer ZaKonec, který bude ukazovat za konec seznamu na sentinel za koncem seznamu vytvoříme pomocný prvek, sentinel (nárazník)
 proto vedle pointeru Hlava zavedeme ještě další pointer ZaKonec, který bude ukazovat za konec seznamu na sentinel. za koncem seznamu vytvoříme pomocný prvek, sentinel (nárazník)")
185
Vytvoření seznamu ani nově vytvořený seznam tedy nebude prázdný, protože bude obsahovat sentinel begin New(Hlava); ZaKonec := Hlava; Hlava^.Další := Nil; Hlava ZaKonec (nic) (nic) X
; ZaKonec := Hlava; Hlava^.Další := Nil; Hlava. ZaKonec. (nic) (nic) X.")
186
Práce se seznamem Prohledávání tohoto seznamu i přidávání prvků na začátek je stejné

187
Vložení prvku na konec (krok 1)
do sentinelu se naplní data Hlava ZaKonec ... Jméno Plat X

188
Vložení prvku na konec (krok 2)
za původním sentinelem se vytvoří sentinel nový New(ZaKonec^.Dalsi); Hlava ZaKonec ... Jméno Plat (nic) (nic) (nic)
; Hlava. ZaKonec. ... Jméno. Plat. (nic) (nic) (nic)")
189
Vložení prvku na konec (krok 3)
pointer ZaKonec se přesune na nový sentinel doplní se NIL v novém sentinelu ZaKonec := ZaKonec^.Dalsi; ZaKonec^.Další := Nil; Hlava ZaKonec ... Jméno Plat (nic) (nic) X
 (nic) X.")
190
Seznam x fronta Povšimněte si, že když procházíme od Hlavy seznam se vkládáním „na konec“, pořadí prvků je od nejstaršího po nejnovější, tedy FIFO tedy frontu lze realizovat jako specielní případ seznamu, u kterého přidáváme na konec a čteme od Hlava

191
Vložení prvku doprostřed
Pro vkládání „doprostřed“ i pro další operace potřebujeme nějak označit místo v seznamu, se kterým pracujeme proto zavedeme další statickou proměnnou Značka Značka bude vždy ukazovat na ten prvek seznamu, se kterým pracujeme

192
Vložení prvku za značku (krok 1)
Pom Značka využijeme pomocnou proměnnou k vytvoření a naplnění nového prvku New(Pom); Pom^.Jmeno := …; Jméno Jméno Plat Plat
; Pom^.Jmeno := …; Jméno. Jméno. Plat. Plat.")
193
Vložení prvku za značku (krok 2)
Pom Značka adresu následujícího prvku nakopírujeme do nově vytvořeného prvku Pom^.Další := Značka^.Další; Jméno Jméno Plat Plat

194
Vložení prvku za značku (krok 3)
Pom Značka adresu nového prvku vložíme do „Další“ prvku, na který ukazuje značka Značka^.Další := Pom; Jméno Jméno Plat Plat

195
Odstranit prvek za značkou
Podobně jako vložit, i odstranit prvek za značkou je snadné

196
Odstranit prvek za značkou(1)
do pomocné proměnné Pom si zapamatujeme adresu rušeného prvku Pom := Značka^.Další Značka Pom Jméno toto Jméno Plat odstranit Plat

197
Odstranit prvek za značkou(2)
změníme pointer na následující prvek seznamu Značka^.Další := Pom^.Další Značka Pom Jméno toto Jméno Plat odstranit Plat

198
Odstranit prvek za značkou(3)
nepotřebný prvek zrušíme Dispose (Pom); Značka Pom Jméno Jméno Plat Plat
; Značka. Pom. Jméno. Jméno. Plat. Plat.")
199
Odstranit prvek se značkou
Přestože se zdánlivě jedná o podobný případ, je to mnohem obtížnější Důvod: nevíme, odkud vychází modrý pointer, proto ho nemůžeme změnit, jak bychom potřebovali (červená) Značka toto Jméno odstranit Plat
 Značka. toto. Jméno. odstranit. Plat.")
200
Možnosti řešení najít ten neznámý „předcházející“ prvek a tím to převést na řešení předchozí úlohy „odstranit prvek za značkou“ - pomalé ! nebo znát „fintu“ (viz dále) Poznámka: u zkoušky nutno buď znát fintu, nebo umět napsat program, jímž se najde „předcházející“ prvek
 Poznámka: u zkoušky nutno buď znát fintu, nebo umět napsat program, jímž se najde „předcházející prvek.")
201
Finta (výchozí stav) toto je výchozí stav Značka toto Jméno odstranit
Plat

202
Finta (krok 1) Značka Pom na prvek, následující za prvkem označeným značkou, si nastavit pomocnou proměnnou Pom := Značka^.Další; toto Jméno odstranit Plat

203
Finta (krok 2) Značka Pom do prvku, na kterém je značka, nakopírovat celý prvek za ním následující úloha se tím vlastně převedla na předcházející úlohu „odstranit prvek za značkou“, kterou už umíme řešit Značka^ := Pom^; Jméno Jméno Plat Plat

204
Finta (krok 3) pomocí Dispose zrušit prvek, na který ukazuje Pom
Značka Pom X pomocí Dispose zrušit prvek, na který ukazuje Pom Dispose(Pom); Jméno Plat
; Jméno. Plat.")
205
Vložit prvek před značku
Úloha: vložte nový prvek před prvek, na který ukazuje značka Problém: stejný jako při „odstranit prvek se značkou“ Řešení: podobné jako v předchozím. Vložit nový prvek za značku a pak do něj obsah prvku se značkou okopírovat. Nakonec vložit nová data tam, kam ukazuje Značka

206
Seznam je trojice Trojice pointerů Hlava + ZaKonec + Značka je pro seznam tak častá a charakteristická, že někteří autoři pod pojmem „seznam“ chápou právě tuto trojici

207
Seznam - realizace pomocí pole
Byla ukázána realizace seznamu pomocí dynamických proměnných; to ale neznamená, že seznam nelze realizovat statickými proměnnými, např. pomocí pole: A H O J volné místo Značka ZaKonec

208
Uspořádaný seznam pro Seznam je typické, že prvky se identifikují pomocí jejich pozice v seznamu pro zvýšení rychlosti hledání můžeme seznam uspořádat, tzn. jeho prvky seřadit podle hodnot jejich klíčů, ale není to moc výhodné (spojové seznamy nelze snadno půlit, viz metoda půlení) struktura, ve které jsou prvky identifikovány hodnotou svého klíče, se nazývá tabulka
 struktura, ve které jsou prvky identifikovány hodnotou svého klíče, se nazývá tabulka.")
209
Dvojitý seznam Největší nevýhodou jednoduchého seznamu je, že neumíme rychle najít předcházející prvek (procházení je jednosměrné) kde to vadí, použijeme dvojitě zřetězený seznam: (nějaká data) (nějaká data) (nějaká data) Nahoru Nahoru Nahoru Dolů Dolů Dolů
 (nějaká data) (nějaká data) Nahoru. Nahoru. Nahoru. Dolů. Dolů. Dolů.")
210
Stromy pomocí recordů, ze kterých vede více pointerů, se snadno realizují stromy nejčastější strom je dichotomický, který má z každého uzlu 2 pointery: na levý podstrom a na pravý podstrom

211
Strom - terminologie (nějaká data) kořen podstrom (zde levý) Klíč uzly
Pravý uzly větve (nějaká data) (nějaká data) Klíč Klíč listy Levý Pravý Levý Pravý
 (nějaká data) Klíč. Klíč. listy. Levý. Pravý. Levý. Pravý.")
212
Binární strom Binární strom = dichotomický strom, pro který navíc platí, že všechny klíče v levém podstromu jsou menší a v pravém podstromu větší než klíč (předpoklad: klíče jsou jednoznačné)
")
213
Binární strom - příklady
32 45 26 kdyby zde bylo 36 nebyl by binární 14 63 28

214
Binární strom - význam nejdůležitější vlastnost: snadné a velmi rychlé hledání půlením je-li N počet uzlů, tak počet kroků log2N

215
Binární strom: hledáme klíč=28
28<32, proto pokračuji levým podstromem 28>26, proto pokračuji praým podstromem 32 45 26 14 63 28 Klíč nalezen. Dojde-li se na list, aniž by byl klíč nalezen, pak neexistuje.

216
Binární strom: vložit klíč=27
27<32, proto pokračuji levým podstromem 27>26, proto pokračuji praým podstromem 32 45 26 14 63 28 Klíč neexistuje. Protože 27<32, vkládáme ho do levé větve 27

217
Hromada = heap jedná se o jiný heap než byla volná paměť!
Heap je forma, jak binární strom zapsat do pole (a ušetřit tak místo na pointery) vychází z toho, že binární strom má v kořenu 1 uzel, v 1. úrovni 2 uzly, ve 3. úrovni 4 uzly atd, tedy v N-té úrovni je 2N uzlů
 vychází z toho, že binární strom má v kořenu 1 uzel, v 1. úrovni 2 uzly, ve 3. úrovni 4 uzly atd, tedy v N-té úrovni je 2N uzlů.")
218
Heap - princip proto se v poli postupně pro i-tou úroveň přidělí 2N pozic (místa pro uzly, které ve stromu chybí, zůstanou prázdná) poměrně jednoduchým algoritmem se dá najít vztah mezi pozicí uzlu v binárním stromě a mezi jeho indexem v poli=heapu protože pozice všech uzlů jsou známé, lze pomocí heapu realizovat mnohé algoritmy, které pomocí pointerů napsat nelze

219
Heap - znázornění 1 2 3 4 5 6 7 8 9 10 11 12 13 ...

220
Heap - výpočet pozice nechť kořen je na indexu 1
jestliže jsme v uzlu s indexem K, tak (pokud existují): jeho rodič má index K div 2 levý podstrom má index 2*K pravý podstrom má index 2*K + 1
: jeho rodič má index K div 2. levý podstrom má index 2*K. pravý podstrom má index 2*K + 1.")
221
Nevýhoda binárního stromu
při nevhodném pořadí vkládaných uzlů mohou větve narůstat nerovnoměrně, až v krajním případě může strom zdegenerovat na lineární seznam: 32 33 X 34 X 35 X X

222
AVL stromy odstraňují hlavní slabinu binárního stromu
AVL strom je binární strom, u kterého navíc pro každý jeho uzel platí, že výška levého podstromu se od výšky pravého podstromu liší nejvýše o 1 abs( High(L) - High(P) ) 1 čili Nevyváženost 1
 - High(P) ) 1. čili Nevyváženost 1.")
223
Výška (pod)stromu 32 levý = 3 pravý = 2 45 26 14 63 28 27
stromu 32 levý = 3 pravý =")
224
Nevyváženost (pod)stromu
32 45 26 14 63 28 nevyváženost = 1 27

225
AVL strom - jak dosáhnout
pomocí Nevyváženosti je definováno, co AVL strom je, ale nijak se tím neřeší, jak ho vytvořit platí: každý binární strom lze přetransformovat na AVL strom, a to pomocí konečného počtu rotací, aplikovaných na vhodné uzly stromu

226
Pravá rotace (výchozí stav)
toto je kořen, strom není AVL, protože Nevyváženost = 2 32 45 26 14 28 27

227
Krok 1: z tohoto uzlu uděláme kořen
Pravá rotace (krok 1) 32 Krok 1: z tohoto uzlu uděláme kořen Problém: na kořen nesmí vést žádná větev Poznámka: Kdyby se jednalo o rotaci podstromu, změníme pointer co vedl na uzel 32 tak, aby ukazoval na uzel 26. 45 26 14 28 27
 32. Krok 1: z tohoto uzlu uděláme kořen. Problém: na kořen nesmí. vést žádná větev. Poznámka: Kdyby se jednalo. o rotaci podstromu, změníme pointer co. vedl na uzel 32 tak, aby ukazoval na uzel")
228
směr této větve obrátíme,
Pravá rotace (krok 2) 32 Krok 2: směr této větve obrátíme, aby byla dodržena „podmínka pro kořen“ Problém: z tohoto uzlu vedou 3 větve 45 26 14 28 27
 32. Krok 2: směr této větve obrátíme, aby byla dodržena. „podmínka pro kořen Problém: z tohoto uzlu. vedou 3 větve")
229
Pravá rotace (krok 3) 32 Krok 3: tuto větev přesuneme
pod vedlejší uzel 45 26 14 28 27

230
Pravá rotace (výsledek)
26 14 32 28 45 27
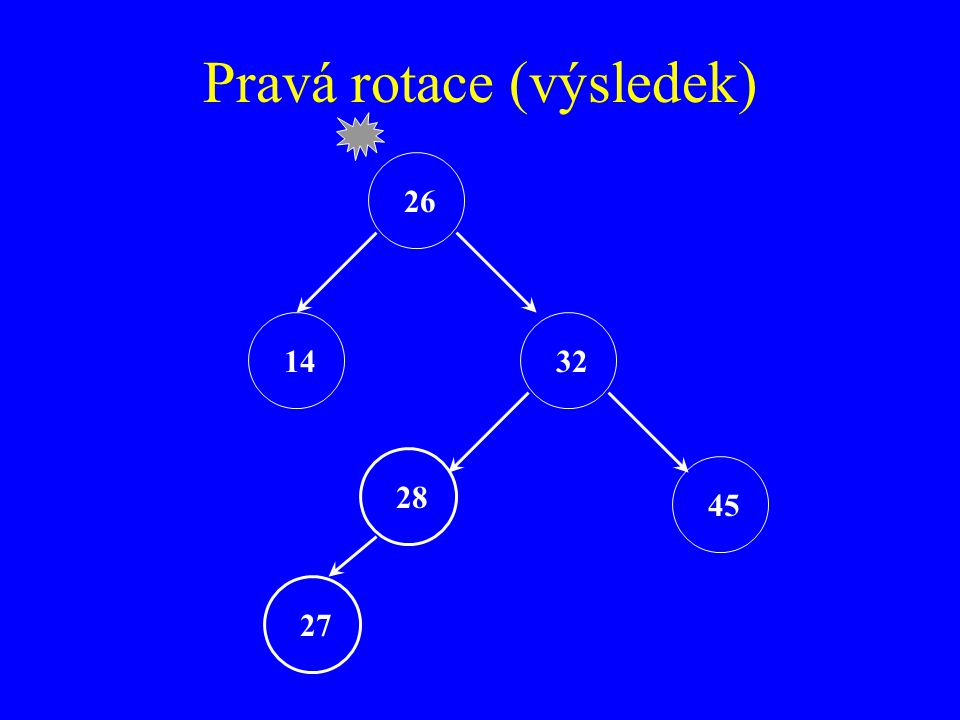
231
Rotace - poznámky předchozí příklad převedl binární strom na AVL
nikde ale není psáno, že každá rotace (a nad každým uzlem) musí vést k výsledku! Nevhodná aplikace může situaci i zhoršit. podobně jako pravá rotace, existuje i levá rotace. Je zcela symetrická (zkouší se!)
 musí vést k výsledku! Nevhodná aplikace může situaci i zhoršit. podobně jako pravá rotace, existuje i levá rotace. Je zcela symetrická (zkouší se!)")
232
Rotace - princip aplikace
princip, podle kterého se aplikují rotace, vychází z faktu, že k AVL stromu lze uzel přidat v zásadě 6 způsoby: A B A levá rotace kolem uzlu A vyrovná nevyváženost na 0 přidané uzly pravá rotace kolem uzlu A a následně levá rotace kolem uzlu B vyrovná nevyváženost na 1

233
B-stromy pozor - „B“ neznamená binární, ale „Bayerovy“
doposud probrané struktury předpokládaly stejně rychlý přístup ke všem prvkům, což v praxi neplatí (paměť:disk až 106) a neomezenou velikost paměti (což také neplatí) B-stromy dávají dobrý návod, jak optimalizovat stránkování paměti (=přesouvání mezi pamětí a diskem) z hlediska rychlosti
 a neomezenou velikost paměti (což také neplatí) B-stromy dávají dobrý návod, jak optimalizovat stránkování paměti (=přesouvání mezi pamětí a diskem) z hlediska rychlosti.")
234
B-stromy stránkování model stránkování (kdyby se do paměti vešly jen 5 uzlů):
:")
235
B-stromy řádu K každá stránka obsahuje maximálně 2K a minimálně (s výjimkou kořene) K uzlů každá stránka je buď list (=nevedou z ní žádné větve) anebo z ní vede M+1 větví, kde M=aktuální počet uzlů ve stránce všechny listové stránky jsou na téže úrovni strom narůstá „vzhůru“, tzn. u kořene
 anebo z ní vede M+1 větví, kde M=aktuální počet uzlů ve stránce. všechny listové stránky jsou na téže úrovni. strom narůstá „vzhůru , tzn. u kořene.")
236
B-strom řádu K=2, příklad
stránky musejí mít 2..4 uzly: 25 10 20 30 40 <10 >20 mezi 22 24

237
B-strom, vložit 23 najít správnou stránku
pokud je místo, vložit do stránky <25 25 10 20 30 40 >20

238
B-strom, vložit 17 najít správnou stránku
protože už není místo, nutno přeuspořádat 10 20 17 13 14 17 18 vybrat prostřední a vytlačit nahoru

239
B-strom, vloženo 17, výsledek
kdyby se i horní stránka přeplnila, pokračovalo by se analogicky vzhůru 25 30 40 13 14 17 18

240
B-stromy, strategie stránkování
lze předpokládat, že bude vyžadován přístup k datům „blízko sebe“ v paměti držet vrcholovou stránku + z každé úrovně stránku na kterou se přistupovalo naposledy

241
Hledání Předpoklady: jednoznačný (=neopakující se) klíč,
žádné dodatečné informace, žádná dodatečná paměť

242
Přímé (indexové) hledání v tabulce
tabulka musí mít podobu pole klíč musí být malé ordinální číslo klíč se přímo použije jako index do pole; na daném indexu se nacházejí data nevýhody: index musí být ordinální a vede k řídkému poli 1 2 3 4 5 6 7 B A C D

243
Postupné prohledávání
nejtriviálnější, ale pomalé N i := 0; while (i<Počet-1) and (Pole[i].Klíč <> HledanyKlic) do i := i+1; if Pole[i].Klíč=HledanyKlic then Nalezeno; 1 2 3 4 5 6 7 C B A D
 and. (Pole[i].Klíč <> HledanyKlic) do i := i+1; if Pole[i].Klíč=HledanyKlic then Nalezeno; C. B. A. D.")
244
Postupné prohledávání, nárazník
cíl: odstranit zbytečný test na konec pole za konec pole vložit hledanou hodnotu klíče (nárazník=sentinel) tím je zaručeno, že se klíč vždycky najde po ukončení cyklu nutno testovat, zda bylo nalezeno uvnitř pole, nebo zda se jedná o sentinel
 tím je zaručeno, že se klíč vždycky najde. po ukončení cyklu nutno testovat, zda bylo nalezeno uvnitř pole, nebo zda se jedná o sentinel.")
245
Nárazník = sentinel i := 0; Pole[Počet].Klíč := ‘K‘;
while Pole[i].Klíč <> ‘K‘` do i := i+1; if i<Počet then Nalezeno; 1 2 3 4 5 6 7 C B A D K
![Nárazník = sentinel i := 0; Pole[Počet].Klíč := ‘K‘;](http://slideplayer.cz/slide/3036757/11/images/245/N%C3%A1razn%C3%ADk+%3D+sentinel+i+%3A%3D+0%3B+Pole%5BPo%C4%8Det%5D.Kl%C3%AD%C4%8D+%3A%3D+%E2%80%98K%E2%80%98%3B.jpg "while Pole[i].Klíč <> ‘K‘` do i := i+1; if i<Počet then Nalezeno; C. B. A. D. K.")
246
Metoda půlení pole dodatečná podmínka: setříděnost
tabulka musí mít podobu pole velká výhoda: rychlost log2N je možno použít na jakýkoliv klíč (i nečíselný, např. na stringy) velká nevýhoda: data se musejí udržovat uspořádaná, což zvyšuje režii vhodné: kde se málo vkládá a často čte
 velká nevýhoda: data se musejí udržovat uspořádaná, což zvyšuje režii. vhodné: kde se málo vkládá a často čte.")
247
Metoda půlení (krok 1) máme 2 indexy: Dn=0 a Up=PočetKlíčů
nalezneme Střed := (Dn+Up) div 2; Dn Střed Up 1 2 3 4 5 6 7 A B C D Q X Y Z
 div 2; Dn. Střed. Up A. B. C. D. Q. X. Y. Z.")
248
Metoda půlení (krok 2) předpokládejme, že hledáme klíč „C“
porovnáme klíč s obsahem prvku pod indexem Střed (je to „D“) protože klíč<Pole[Střed], vybereme dolní polovinu Up:=Střed-1 Dn Střed Up 1 2 3 4 5 6 7 A B C D Q X Y Z
 protože klíč<Pole[Střed], vybereme dolní polovinu Up:=Střed-1. Dn. Střed. Up A. B. C. D. Q. X. Y. Z.")
249
Metoda půlení (krok 3) znovu najdeme Střed:=(Up+Dn) div 2=„B“
protože klíč<Pole[Střed], vybereme horní polovinu Dn:=Střed+1 postup se opakuje, dokud buď není nalezen klíč, nebo se nenajde konec Up<Dn Střed Dn Up 1 2 3 4 5 6 7 A B C D Q X Y Z

250
Metoda transformace klíče
= metoda hashování [hešování] vychází z přímého (indexového) hledání odstraňuje jeho nedostatky (řídké pole a nutnost ordinálního indexu) libovolný typ indexu (např. string) velmi rychlý přístup
 hledání. odstraňuje jeho nedostatky (řídké pole a nutnost ordinálního indexu) libovolný typ indexu (např. string) velmi rychlý přístup.")
251
Transformace klíče, příklad
klíčem nechť je plat metodu vysvětlíme na příkladu podle vedlejší tabulky zvolím hashovací funkci f(X):=X mod 10 pozor, to není dobrá volba (zde jsem ji použil jen pro její názornost) Mozart 2530 Brahms 1893 Beethoven 5422 Chopin 2215 Bach Čajkovskij 4914 Verdi
:=X mod 10. pozor, to není dobrá volba (zde jsem ji použil jen pro její názornost) Mozart Brahms Beethoven Chopin Bach Čajkovskij Verdi")
252
Transformace klíče, vkládání
údaje budeme vkládat do pole A délky 10 vkládáme tak, že klíč nejprve přetransformujeme hashovací funkcí a pak číslo, které dostaneme, použijeme jako index do pole A stejně se postupuje pro všechny údaje 1 2 3 4 5 6 … Chopin: 2215 h(2215) = 5 vložit sem
 = 5. vložit sem.")
253
Transformace klíče, kolize
v okamžiku, kdy se pokusíme vložit Verdi: 3175 nastane problém: pozice už je obsazena ! nastala kolize existují 2 způsoby řešení kolize: vnitřní vnější 0 Mozart 1 2 Beethoven 3 Brahms 4 Čajkovskij 5 Chopin 6 7 8 Bach 9 Verdi: 3175 h(3175) = 5 KOLIZE
 = 5. KOLIZE.")
254
Vnější řešení kolize vnější, protože se řeší vně hashovacího pole 4
princip: pozice nalezená hashováním je současně hlavou spojového seznamu (kolizní seznam) 4 5 Chopin: 2215 6 Verdi: 3175
 4. 5 Chopin: Verdi:")
255
Vnitřní řešení kolize (1)
údaje se ukládají uvnitř hashovacího pole je třeba upravit algoritmus ukládání i hledání ! když nastane kolize, hledá se první volné místo a na to se údaj uloží

256
Vnitřní řešení kolize (2)
modifikace: vkládání na nejbližší volné místo (index+1) vede k shlukům proto se někdy krok volí proměnlivý podle nějaké tabulky hledání tomu musí odpovídat 0 Mozart: 2530 1 2 Beethoven: 5422 3 Brahms: 1893 4 Čajkovskij:4914 5 Chopin: 2215 6 Verdi: 3175 7 8 Bach: 6048 9 Verdi: 3175 h(3175) = 5 Kolize index 5 je obsazen, proto vložíme na nejbližší volný (6)
 vede k shlukům proto se někdy krok volí proměnlivý podle nějaké tabulky. hledání tomu musí odpovídat. 0 Mozart: Beethoven: Brahms: Čajkovskij: Chopin: Verdi: Bach: Verdi: h(3175) = 5. Kolize. index 5 je obsazen, proto vložíme na nejbližší volný (6)")
257
Vnitřní řešení kolize (3)
jiný příklad: někdy se musí dát dost daleko Hledání: hledá se buď klíč, nebo první volné místo ! 0 Mozart: 2530 1 2 Beethoven: 5422 3 Brahms: 1893 4 Čajkovskij:4914 5 Chopin: 2215 6 Verdi: 3175 7 Dvořák: 2723 8 Bach: 6048 9 Dvořák: 2723 h(2723) = 3 Kolize index 3 je obsazen, proto vložíme na nejbližší volný ( až 7! )
 = 3. Kolize. index 3 je obsazen, proto vložíme na nejbližší volný ( až 7! )")
258
Vnitřní řešení kolize (4)
Problém: při vnitřním řešení kolize není možno údaje vymazat! kdybychom např. vymazali Chopin:2215, vzniklo by volné místo, které by znemožnilo nalezení Dvořák i Verdi proto se „vymazané“ údaje jen označí jako neplatné a při nejbližší příležitosti přepíší 0 Mozart: 2530 1 2 Beethoven: 5422 3 Brahms: 1893 4 Čajkovskij:4914 5 Chopin: 2215 6 Verdi: 3175 7 Dvořák: 2723 8 Bach: 6048 9

259
Volba hashovací funkce
cílem je zvolit funkci, která údaje rozprostře rovnoměrně z typu klíče udělá ordinální číslo omezené velikosti (odpovídající velikosti hashovacího pole) z tohoto hlediska DIV ani MOD 10 nejsou dobré dobré jsou např. MOD Prvočíslo, MD5, … stringy a recordy možno brát jako binární
 z tohoto hlediska DIV ani MOD 10 nejsou dobré. dobré jsou např. MOD Prvočíslo, MD5, … stringy a recordy možno brát jako binární.")
260
Třídění = řazení Předpoklady: jednoznačný (=neopakující se) klíč,
žádné dodatečné informace, žádná dodatečná paměť

261
Bublinkové třídění Bubblesort nejtriviálnější, ale nejméně účinné N2
postupné přesouvání dat připomíná „probublávání“ bublin v kapalině Postupně se testují dvojice za sebou jdoucích dat: Pokud první údaj je větší než druhý, navzájem se přehodí. Přejde se na další dvojici

262
Bubblesort (příklad)... 15 68 17 84 21 18 33 96 1. Klíče jsou ve správném pořadí (15<68), žádná akce 2. Nesprávné pořadí, prohodit 68 a 17 3. Klíče jsou ve správném pořadí (teď se testuje 68 proti 84), žádná akce …. a tak dále až do konce dat
, žádná akce. …. a tak dále až do konce dat.")
263
… pokračování 15 68 17 84 21 18 33 96 15 17 68 84 21 18 33 96 15 17 68 21 84 18 33 96 15 17 68 21 18 84 33 96 15 17 68 21 18 33 84 96 15 17 68 21 18 33 84 96 nový průchod atd.

264
Bubblesort - počet průchodů
na efektivnost bubblesortu má vliv, kolikrát se polem dat prochází nejjednodušší podmínka: je-li dat N, pole se projde N-krát. Protože při každém průchodu se hodnota posune aspoň o 1 pozici, jsou po N průchodech i v nejnepříznivějším případě všechna data na svém místě

265
Bubblesort II podmínku N průchodů lze modifikovat:
zavede se pomocná proměnná, která se na začátku každého průchodu nastaví na False kdykoliv dojde k prohození dat, pomocná proměnná se nastaví na True pokud je po skončení průchodu pomocná proměnná False, nedošlo k žádnému prohození, tudíž data jsou setříděna a je možno skončit

266
Bubblesort III efektivnost lze ještě dále zvýšit tím, že se nebudou procházet všechna data: při každém průchodu si poznamenáme pozici P1 první změny a P2 poslední změny následující průchod se provádí jen od P1-1 do P2+1

267
Shakesort nepříjemnou vlastností bubblesortu je nesymetrie: „84“ se na správné místo dostala už během prvního průchodu, zatímco „18“ postoupila jen o 1 pozici řešení: pole střídavě procházet shora a zdola programová realizace: dva cykly (to/downto) za sebou 15 17 68 84 21 18 33 96 15 17 68 21 84 18 33 96 15 17 68 21 18 84 33 96 15 17 68 21 18 33 84 96
 za sebou")
268
Shellsort 15 17 68 84 21 18 33 96 15 17 68 84 21 18 33 96 15 17 21 18 68 84 33 96 pokusy o urychlení: nejprve dlouhý krok, aby se data rychle dostala do blízkosti správné posice, pak postupně zjemňovat existují doporučené posloupnosti kroků

269
Insertsort další triviální, ale pomalý algoritmus N2
funguje, jako když si člověk rovná v ruce karty: nalevo už jsou setříděné, napravo ještě nesetříděné z nesetříděných se postupně zleva doprava jedna vybere… …a zasune na správné místo mezi setříděné (mezera se vytvoří posunutím karet)
")
270
Insertsort příklad index= vezmeme číslo a postupně ho od začátku porovnáváme se setříděnými, až nalezneme správnou pozici vytvoříme mezeru tak, že setříděné (od té mezery) posuneme o 1 pozici doleva číslo do vzniklé mezery vložíme a tím je zatříděno
 posuneme o 1 pozici doleva. číslo do vzniklé mezery vložíme a tím je zatříděno")
271
Insertsort program for j:=Low(A)+1 to High(A) do begin Klic := A[j];
i := j-1; while (i>0)and(A[i]>Klic) do A[i+1] := A[i]; i := i-1; end; A[i+1] := Klic; index=
![Insertsort program for j:=Low(A)+1 to High(A) do begin Klic := A[j];](http://slideplayer.cz/slide/3036757/11/images/271/Insertsort+program+for+j%3A%3DLow%28A%29%2B1+to+High%28A%29+do+begin+Klic+%3A%3D+A%5Bj%5D%3B.jpg "i := j-1; while (i>0)and(A[i]>Klic) do. A[i+1] := A[i]; i := i-1; end; A[i+1] := Klic; index=")
272
Quicksort vynikající rychlost řádu N log2N, což je mezi tříděními bez dodatečných předpokladů nejlepší známý výsledek kombinuje rekurzi s metodou půlení

273
Quicksort krok 1 zvolíme medián. (Medián je prvek s prostřední hodnotou.) Protože nalezení mediánu je časově náročné, nahrazuje se nalezením prvku ležícího uprostřed (zhoršení rychlosti je obvykle malé) obvykle se realizuje pomocí div 2
 Protože nalezení mediánu je časově náročné, nahrazuje se nalezením prvku ležícího uprostřed (zhoršení rychlosti je obvykle malé) obvykle se realizuje pomocí div")
274
Quicksort krok 2 postupujeme zleva doprava a najdeme první prvek větší než medián postupujeme zprava doleva a nalezneme první prvek menší než medián oba prvky spolu prohodíme

275
Quicksort krok 2 dokončení
kdyby se (jako nám) stalo, že na jedné straně už nebude s čím prohazovat, prohodíme s mediánem skončíme, když všechny prvky menší než medián jsou nalevo a všechny prvky větší napravo od mediánu
 stalo, že na jedné straně už nebude s čím prohazovat, prohodíme s mediánem. skončíme, když všechny prvky menší než medián jsou nalevo a všechny prvky větší napravo od mediánu")
276
Quicksort krok 3 skončili jsme ve stavu, kdy nalevo od mediánu jsou všechny prvky menší než medián (byť nesetříděné) a napravo všechny prvky větší než medián na obě tyto části rekurzívně aplikujeme stejný algoritmus rekurze rekurze
 a napravo všechny prvky větší než medián. na obě tyto části rekurzívně aplikujeme stejný algoritmus rekurze. rekurze.")
277
Třídění v lineárním čase
z toho, že Quicksort je nejrychlejší algoritmus pracující bez dodatečných předpokladů nelze usuzovat, že je za všech okolností nejlepší ukážeme 2 algoritmy, které s poměrně malými předpoklady dosahují dokonce lineární rychlosti, tj. rychlost N

278
Počítací třídění Counting sort
předpoklad: pro nějaké (ne moc velké) K všechny klíče jsou typu integer 0..K základní myšlenka: když pro každý prvek X víme, kolik prvků je menších, můžeme X rovnou zatřídit příklad: jestliže víme, že 17 prvků je menších než X, tak X musí ležet na 18. pozici s malou modifikací lze zpracovat i případ více shodných klíčů
 K všechny klíče jsou typu integer 0..K. základní myšlenka: když pro každý prvek X víme, kolik prvků je menších, můžeme X rovnou zatřídit. příklad: jestliže víme, že 17 prvků je menších než X, tak X musí ležet na 18. pozici. s malou modifikací lze zpracovat i případ více shodných klíčů.")
279
Counting sort princip (1)
Budeme pracovat se 3 poli: A[1..N] bude obsahovat vstupní data, B[1..N] setříděná data a C[1..K] je pomocné. N je počet dat a K je limit velikosti klíče s pomocí této znalosti přeřadíme prvky z B do A A B ? ? ? ? ? ? ? ? C

280
Counting sort princip (2)
A do C[i] napočítáme počet prvků s klíčem rovným i hodnoty sečteme tak, aby C[i] obsahovalo počet prvků s klíčem menším než i C A C

281
Counting sort princip (3)
postupně pro všechny prvky z A, zprava doleva: vezmeme prvek jeho klíč použijeme jako index do C hodnotu nalezenou v C použijeme jako index do B, kam uložíme prvek A 3 C 7 B ? ? ? ? ? ? 3 ?

282
Counting sort princip (4)
předcházející postup by vyhovoval, kdyby všechny klíče byly jedinečné připouštíme-li opakování klíčů, po každém zápisu do B musíme zmenšit C[i] aby následující zápis šel na předchozí index takže v našem příkladu se C[i] zmenší ze 7 na 6 a následující klíč 3 už půjde do B[6] výsledné pole B po zpracování: B

283
Counting sort program for i := 0 to K do C[i] := 0;
for i := 1 to High(A) do C[ A[i] ] := C[ A[i] ] + 1; for i := 1 to K do C[i] := C[i] + C[i+1]; for i := High(A) downto 1 do begin B[ C[A[i]] ] := A[i]; C[ A[i] ] := C[ A[i] ] - 1; // dec(….) end;
![Counting sort program for i := 0 to K do C[i] := 0;](http://slideplayer.cz/slide/3036757/11/images/283/Counting+sort+program+for+i+%3A%3D+0+to+K+do+C%5Bi%5D+%3A%3D+0%3B.jpg "for i := 1 to High(A) do. C[ A[i] ] := C[ A[i] ] + 1; for i := 1 to K do. C[i] := C[i] + C[i+1]; for i := High(A) downto 1 do. begin. B[ C[A[i]] ] := A[i]; C[ A[i] ] := C[ A[i] ] - 1; // dec(….) end;")
284
Bucket sort bucket = kbelík
dává dobrou rychlost (skoro lineární N) za předpokladu rovnoměrného rozložení, tzn. že všechny klíče jsou stejně pravděpodobné funguje na klíče real <0..1) nebo když lze klíče na tento interval přetransformovat
 za předpokladu rovnoměrného rozložení, tzn. že všechny klíče jsou stejně pravděpodobné. funguje na klíče real <0..1) nebo když lze klíče na tento interval přetransformovat.")
285
Bucket sort princip interval <0..1) se rozdělí na N stejných podintervalů (to jsou ty kýble ) protože rozdělení je rovnoměrné, do každého intervalu padne jen málo klíčů, takže setřídění uvnitř intervalu je snadné a rychlé (trochu to připomíná hashování) postupně projdeme intervaly a v nich klíče podle velikosti
 postupně projdeme intervaly a v nich klíče podle velikosti.")
286
Bucket sort příklad for i := 1 to High(A) do begin
Podle A[i] určit interval j; Přidat A[i] k seznamu začínajícímu v B[j]; end; for j := 0 to 4 do Setřídit seznam B[j]; Spojit seznamy Vstup (pole A): 0,78 0,17 0,39 0,26 0,72 Pracovní pole B: ,2 0, ,6 0, | | | | 0,17 0,39 0,78 0,26 0,72
: ,78 0,17 0,39 0,26 0,72. Pracovní pole B: 0 0,2 0,4 0,6 0, | | | | 0,17. 0,39. 0,78. 0,26. 0,72.")
287
The End

Podobné prezentace






 Fronta (FiFo)>")












