Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Automatická fonetická segmentace pomocí UNS Registr - 36 neuronových sítí MLNN (pro každou českou hlásku jedna UNS) Trénovací množina: databáze promluv zdravých dětí 15 různých variant každé hlásky od několika dětí doba trvání hlásky: jako medián z trvání všech variant pro každou hlásku: matice P k ij, i=Du k med, j=15, k=1,...,36. Vstupní data do MLNN: TREN MLNN hláska, na kterou má být daná síť natrénována (odpovídající target hodnota je „1“) 250 vektorů obsahujících náhodné úseky řeči neobsahují hlásku z první části (odpovídající target hodnota je „0“) přeřazení vektorů v náhodném pořadí 12 LPC koeficientů a chyba predikce Algoritmy a struktury neuropočítačů ASN – P8
 250 vektorů obsahujících náhodné úseky řeči neobsahují hlásku z první části (odpovídající target hodnota je „0 ) přeřazení vektorů v náhodném pořadí 12 LPC koeficientů a chyba predikce Algoritmy a struktury neuropočítačů ASN – P8.")
2
UNS: 4 vrstvy 13-20-10-1 aktivační funkce: hyperbolická tangenta Vyhledání jednotlivých hlásek postupné testování neuronových sítí z registru pomocí plovoucího okna --- přes celý signál výstup ze sítě nabývá hodnoty z intervalu rozhodovací mez zvolena experimentálně výstup mez překročí testovaný úsek = hláska na kterou byla testovaná neuronová síť natrénovaná

3
Segmentace pomocí SOM - 2 úrovně vstupní signál je přiveden do hlavní KSOM trénovaná na všechny hlásky podle umístění shluku vektorů s podobnými vlastnostmi je aktivována některá z vedlejších map Hlavní mapa klasifikuje „hrubě“. vedlejší mapy KSOM -- klasifikují přesněji o počtu a složení vedlejších map rozhoduje rozmístění shluků v hlavní KSOM KSOM : čtvercová, hrana 30 neuronů u hlavní mapy 15 (10) neuronů u vedlejší mapy funkce tvaru okolí vítězného neuronu: gaussian poloměr okolí: postupně se zmenšoval z 20 na 1 hlavní mapa z 10 na 1 vedlejší mapa počet interací: 10 tisíc
 neuronů u vedlejší mapy funkce tvaru okolí vítězného neuronu: gaussian poloměr okolí: postupně se zmenšoval z 20 na 1 hlavní mapa z 10 na 1 vedlejší mapa počet interací: 10 tisíc.")
4
Parametrizace: 20 melovských kepstrálních koeficientů 16 ms segmenty s 50% překryvem Hammingovo okno 1-3 vektory o 20-ti elementech (v závislosti na trvání hlásky) Trénovací soubor TREN SOM Program: SEGANN – SEGmentation by ANN Matlab 7, NN Toolbox
 Trénovací soubor TREN SOM Program: SEGANN – SEGmentation by ANN Matlab 7, NN Toolbox")
6
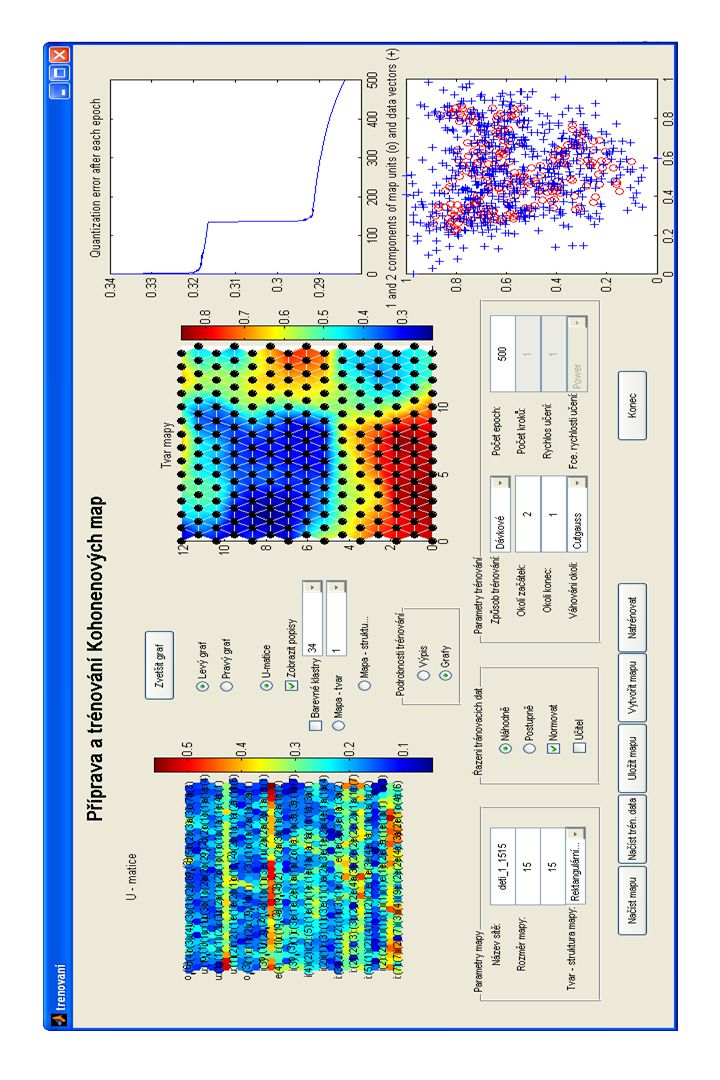
Vytvoření a natrénování Kohonenových map. Vstup: struktura dat vytvořená v předchozím kroku. Výstup: struktura s natrénovanou mapou a struktura trénovacích dat ve formátu podle SOM Toolboxu. Obsahuje různé volby pro vytvoření a trénování KSOM jméno mapy, její rozměry, topologie a struktura mapy, způsob řazení dat v trénovací matici, možnost normování dat, způsob trénování, nastavení okolí vítězného neuronu, počet trénovacích epoch, nastavení funkce rychlosti učení. SEGANN – program pro fonémovou segmentaci Velký problém – souvisí s češtinou: při fonémové segmentaci a labelování je to počet souhlásek stojících vedle sebe např. krk, prst, mrtvá !!! Nejvíce explosívy obtížné určení hranic jsou velmi krátké Nárůst problémů: nedbalá výslovnost, narušená řeč

7
Okno pro segmentaci řeči Vstup: - natrénované Kohonenovy mapy - zvukový signál, který chceme segmentovat Výstup: textový soubor - stejný formát jako při ručním segmentování tři sloupce: fonetická transkripce, začátek hlásky ve vzorcích (od začátku wav ‑ souboru) doba trvání hlásky Graf: 8 oken aktuálně zpracovávaného signálu Nad jednotlivými okny je název hlásky, která byla v příslušném okně rozpoznána
 doba trvání hlásky Graf: 8 oken aktuálně zpracovávaného signálu Nad jednotlivými okny je název hlásky, která byla v příslušném okně rozpoznána")
Podobné prezentace









>")






>")


