Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Mikroprocesory Procesory

2
Procesor je synchronní zařízení provádí operace s daty je programovatelný pomocí mikroinstrukcí je více rodin procesorů (jednočipy > 8051, rodina x86, IA64, Sparc, …) je více výrobců
 je více výrobců")
3
Rychlost procesoru interní rychlost procesoru je součinem FSB * multiplikátor celý počítač pracuje synchronně s hodinovým signálem

4
Programování CPU CPU zpracovává strojové instrukce (strojový jazyk, strojový kód) programuje se ale v jazyku symbolických adres (assembly language) většinou ale pomocí pseudoinstrukcí (direktiv) z programovacího jazyku
 programuje se ale v jazyku symbolických adres (assembly language) většinou ale pomocí pseudoinstrukcí (direktiv) z programovacího jazyku")
5
Dvě koncepce procesorů CISC (Complete Instruction Set Computer) vznikla z Neumannovy koncepce obsahuje plnou sadu instrukcí RISC (Reduced Instr. Set Comp.) vznikla z harwardské koncepce jednoúčelové procesory dnešní CPU mají prvky obou
 vznikla z harwardské koncepce jednoúčelové procesory dnešní CPU mají prvky obou.")
6
Instrukční sady každé vylepšení architektury vyžaduje nové instrukce např. pro práci s pamětí multimediální instrukce MMS SSE 3DNow! KNI, atd.

7
Části procesoru Jádrem procesoru je ALU, která provádí výpočty. Procesor obsahuje také ŘADIČ, který na základě instrukcí činnost procesoru řídí Dále obsahuje BLOK REGISTRŮ (FIFO a LIFO) REGISTRY UNIVERZÁLNÍ – DATOVÉ REGISTRY S PEVNĚ STANOVENÝM VÝZNAMEM: PC – Program Counter (IP – Instruction Pointer) – F, FL, FLAGS – registr příznaků SP – Stack Pointer – ukazatel zásobníku, zásobník = zvláštní část paměti
 REGISTRY UNIVERZÁLNÍ – DATOVÉ REGISTRY S PEVNĚ STANOVENÝM VÝZNAMEM: PC – Program Counter (IP – Instruction Pointer) – F, FL, FLAGS – registr příznaků SP – Stack Pointer – ukazatel zásobníku, zásobník = zvláštní část paměti.")
8
Části procesoru 2 jednotky pro práci s pamětí koprocesor další jednotky např. předvídání skoků spekulativní provádění buffery – fronty

10
Komunikace CPU s I/O zařízením PIO – přímá programová obsluha Interrupt (IRQ) – obsluha s přerušením DMA – přímý přístup do paměti
 – obsluha s přerušením DMA – přímý přístup do paměti")
11
Zvyšování výkonu procesoru rychlost (FSB * multiplikátor) pipelining skalární procesory – zřetězení Branch prediction (předpovídání větvení programu) Spekulativní provádění cache paměť koprocesor
 pipelining skalární procesory – zřetězení Branch prediction (předpovídání větvení programu) Spekulativní provádění cache paměť koprocesor")
13
PIPELINING (overlapping) PF D1 D2 EX WB 1234567 I1I1 I2I2 I1I1 I2I2 I1I1 I2I2 I1I1 I2I2 I1I1 I2I2 I3I3 I4I4 I3I3 I4I4 I3I3 I4I4 I3I3 I4I4 I3I3 I4I4 I5I5 I6I6 I5I5 I6I6 I5I5 I6I6 I5I5 I6I6 I5I5 I6I6 I7I7 I8I8 I7I7 I8I8 I7I7 I8I8 I7I7 I8I8 I7I7 I8I8 8 I9I9 I 10 I9I9 I9I9 I9I9 I 11 I 12 I 11 I 12 I 11 I 12 I 13 I 14 I 13 I 14 I 15 I 16
 PF D1 D2 EX WB I1I1 I2I2 I1I1 I2I2 I1I1 I2I2 I1I1 I2I2 I1I1 I2I2 I3I3 I4I4 I3I3 I4I4 I3I3 I4I4 I3I3 I4I4 I3I3 I4I4 I5I5 I6I6 I5I5 I6I6 I5I5 I6I6 I5I5 I6I6 I5I5 I6I6 I7I7 I8I8 I7I7 I8I8 I7I7 I8I8 I7I7 I8I8 I7I7 I8I8 8 I9I9 I 10 I9I9 I9I9 I9I9 I 11 I 12 I 11 I 12 I 11 I 12 I 13 I 14 I 13 I 14 I 15 I 16")
14
Další parametry CPU cache patice použitá technologie výroby napájení, příkon, tepelný výkon sběrnice počet prvků operace za vteřinu (MIPS, MFLOPS)
")
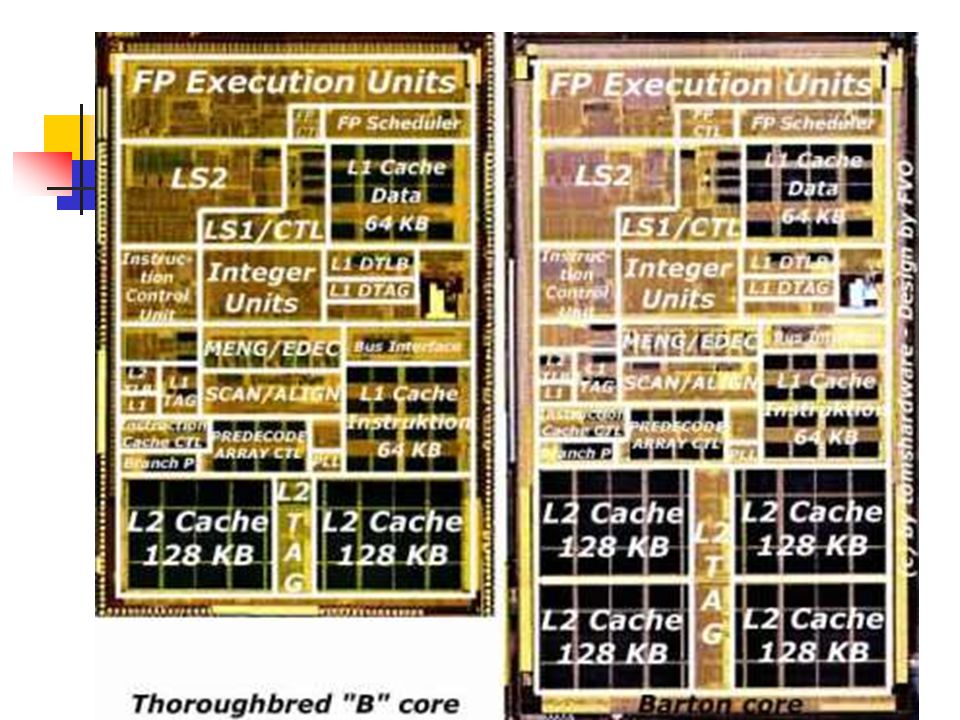
15
cache primární L1 sekundární L2 … umístění … instrukční a datová na velikosti záleží řežimy práce WB – write back (opožděný zápis) WT – write through (současně zapisuje i RAM) Pipelined Burst (zřetězení, přednačítání bloků)
 WT – write through (současně zapisuje i RAM) Pipelined Burst (zřetězení, přednačítání bloků)")
18
patice patice nebo socket ZIF označení nejprve pořadovým číslem (socket 1 – 7, slot 1 – 2, slot A) potom počtem pinů a typem pouzdra procesoru (Socket 478, LGA 775, Socket 939, Socket 754
 potom počtem pinů a typem pouzdra procesoru (Socket 478, LGA 775, Socket 939, Socket 754")
20
použitá technologie výroby dříve TTL (tranzistor – tranzistor logic) pak MOS (Metal Oxid Semiconductor) CMOS (complementary …) MOSFET (… field efected tranzistor)
 pak MOS (Metal Oxid Semiconductor) CMOS (complementary …) MOSFET (… field efected tranzistor)")
22
napájení, příkon, tepelný výkon od 5V 3,3 pro Pentia dnes proměnné, zvlášť pro jádro CPU a pro IO jednotky rozsah od 1V výše

23
sběrnice datová adresová řídící šířka rychlost propustnost

24
počet prvků od řádově stovek a tisíců v prvních IO přes ca 42 000 000 v Pentiu I po miliardy v dnešních procesorech

25
operace za vteřinu MIPS – sleduje ALU MFLOPS – sleduje FPU výkon (a stabilita) procesoru se testuje benchmarky např. Whetstone, Dhrystone

Podobné prezentace















 programová (procesy, vlákna) algoritmická (uf... ) Motivace: zvýšení výkonu redundance jiné cíle,>")

>")







