Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Cesta k DNA. Replikace, transkripce, translace.
2008

2
Cesta k DNA 1869 němec Friedrich Miescher izoloval z buněčných jader látku, která byla bílá, slabě kyselá a obsahovala fosfor. Nazval ji proto nukleová (jaderná) kyselina. 1920 P.A. Levene objevil, že nukleová kyselina může být rozložena na jednotlivé nukleotidy. Nukleotid obsahuje pětiuhlíkatý cukr, fosfátovou skupinu, a jednu ze čtyř bází: adenin, guanin, cytosin, tymin.
 kyselina P.A. Levene objevil, že nukleová kyselina může být rozložena na jednotlivé nukleotidy. Nukleotid obsahuje pětiuhlíkatý cukr, fosfátovou skupinu, a jednu ze čtyř bází: adenin, guanin, cytosin, tymin.")
3
Cesta k DNA Levene učinil dva závěry, jeden správný, jeden nesprávný:
každá dusíkatá báze se váže k molekule cukru, který se dále váže k fosfátové skupině (správně) tyto nukleotidy jsou seskupeny po čtyřech v pravidelném pořádku v útvaru, který nazval tetranukleotid. Tento nesprávný názor se udržel přes deset let.
 tyto nukleotidy jsou seskupeny po čtyřech v pravidelném pořádku v útvaru, který nazval tetranukleotid. Tento nesprávný názor se udržel přes deset let.")
4
Cesta k DNA 1928 Frederick Griffith hledal lék proti baktériím (Streptococcus pneumoniae), způsobujícím zápal plic: Griffith měl k dispozici dvě varianty baktérií: patogení (způsobující nemoc) a neškodnou
 a neškodnou.")
5
Cesta k DNA Griffith byl překvapen, když v jedné variantě pokusu teplem usmrtil patogenní formu a injikoval ji do myší spolu s neškodnou formou: myši zemřely a v jejich krvi byly živé patogení bakterie. Závěr: „něco“ z mrtvých patogeních bakterií muselo přejít do neškodných a přeměnit je v škodlivé. Griffith tuto látku nazval jednoduše transforming factor

6
Cesta k DNA „Averyho bomba“
1944 Oswald Avery, Maclyn McCarthy a Colin MacLeod po pečlivých analýzách zjistili, že Griffithův transforming factor je DNA Oswald Avery

7
Cesta k DNA Ve čtyřicátých letech začínají Max Delbrück a Salvador Luria experimenty s bakteriofágy. Fág T4 Bakteriofág = virus, který se živí bakteriemi Na obrázku je bakterie Escherichia coli napadená fágy T4

8
Další objevy Alfred Mirsky objevil, že všechny buňky daného organismu obsahují stejné množství DNA. Výjimkou jsou gamety, pohlavní buňky, které obsahují pouze polovinu DNA

9
Chargaffova pravidla Erwin Chargaff 1947 anylzoval DNA různých organismů a objevil, že obsah jednotlivých dusíkatých bází se liší druh od druhu, ale v rámci buněk jednoho druhu je stálý množství adeninu je stejné jako thyminu množství guaninu je stejné jako cytosinu

10
Alfred Hershey a Marta Chase, 1952
Bylo již známo, že fágy se sestávají z bílkovin a nukleových kyselin rovněž bylo známo, že fágy dovedou nějak přeprogramovat bakterii v továrnu vyrábějící ve velkém množství kopie fágů

11
Alfred Hershey a Marta Chase, 1952
V experimentu byla použita radioaktivní síra 35S a radioaktivní fosfor 32P. Fosfor se nachází v DNA ale ne v bílkovinách, síra se naopak nachází v bílkovinách, ale ne v DNA bakterie vykazovaly radioaktivitu, pokud byly napadeny fágem obsahujícím radioaktivní fosfor. Pokud byly napadeny fágy s radiaktivní sírou, bakterie nevykazovaly radioaktivitu Závěr: do bakterií vstupuje DNA a ne bílkoviny

12
Hershey-Chase experiment

13
Hledání trojrozměrné struktury
Začátkem 50.let již bylo známo složení řetězce DNA předpokládalo se, že cukrfosfátová kostra je uprostřed a báze směřují ven všemi směry

14
Hledání trojrozměrné struktury
Trojrozměrnou strukturu hledal Linus Pauling v USA (Kalifornie) a v Anglii Maurice Wilkins a Rosalinda Franklinová Linus Pauling, objevitel α-helixu u bílkovin
 a v Anglii Maurice Wilkins a Rosalinda Franklinová. Linus Pauling, objevitel α-helixu u bílkovin.")
15
Rosalinda Franklinová
Röentgen strukturní analýza neukazuje přímo tvar molekuly. Skvrny na obrázku jsou způsobeny tím, jak jsou röentgenové paprsky rozptýleny průchodem přes krystaly DNA. Matematicky lze z rozložní těchto skvrn odvodit trojrozměrnou strukturu molekuly

16
1953 James Watson a Francis Crick objevili strukturu DNA „The Double Helix!“

17
Watson a Crick, duben 1953 užili drátěný model
Užili výsledky röentgen srtukturní krystalografie Rosalindy Franklinové odtud věděli šířku DNA: odhadli tak, že purin se musí párovat s pyrimidinem užili drátěný model Článek v Nature měl jen jednu stránku a jeden řádek...

18
Erwin Chargaff: „Že za našich dnů mohou takoví trpaslíci vrhat tak dlouhé stíny, jen dokazuje, že se připozdívá…“

19
Struktura DNA

20
Vodíkové můstky drží dvoušroubovici pohromadě
Mezi thyminem a adeninem jsou dva vodíkové můstky mezi guaninem a cytosinem jsou tři vodíkové můstky toto párování je ve shodě s Chargaffovými pravidly

21
Model replikace DNA Molekula DNA má dva komplementární řetězce. A se páruje s T a C se páruje s G. Prvním krokem replikace je oddělení obou řetězců. Každý z řetězců nyní může sloužit jako matrice pro nový řetězec. Nové nukleotidy jsou potom spojeny cukr-fosfátovou kostrou. „Dceřinná“ molekula tak má jeden „rodičovský“ řetězec a jeden nový.

22
Replikace Poté co Watson a Crick navrhli dvoušroubovicový model DNA, byly navrženy tři modely pro replikaci: konzervativní, semikonzervativní a disperzivní. Semikonzervativní model se ukázal správný.

23
Matt Meselson a Franklin Stahl
Matthew Meselson a Franklin Stahl potvrdili koncem 50.let semikonzervativní model replikace DNA V experimentu byl použit těžký izotop dusíku, 15N

24
Začátek replikace Replikace začíná na místech DNA zvaných „origins of replication“ Bakteriální chromozom, který je kruhovitý má jedno místo ori, eukaryontní chromozomy mají počátků replikace mnoho. Jádro somatické buňky člověka obsahuje 46 molekul DNA a více než 6 miliard pb (=párů bazí; angl. bp), jedno místo ori na chromosom by nestačilo. Zkopírovat toto obrovské množství pb trvá několik hodin (S- fáze) s přesností 1 chyba na cca miliardu pb.
, jedno místo ori na chromosom by nestačilo. Zkopírovat toto obrovské množství pb trvá několik hodin (S- fáze) s přesností 1 chyba na cca miliardu pb.")
25
Počátek replikace

26
Počátek replikace u prokaryot
Baktérie: proteiny, schopné rozeznat sekvenci ori se k ní naváží a tím započnou replikační proces. Replikace potom postupuje oběma směry.

27
Počátek replikace u eukaryot
u eukarot je na každém chromosomu několik stovek až několik tisíc počátků replikace podobně jako u prokaryot postupuje replikace na každé „bublině“ oběma směry

28
Elongace replikace u prokaryot napojuje enzym DNA polymeráza 500 nukleotidů za vteřinu u člověka je to jen 50 nukleotidů za vteřinu

29
Replikace Syntézu DNA katalyzuje enzym DNA polymeráza. Tento enzym používá jeden řetězec mateřské DNA jako templát. U bakterií je rychlost elongace asi 500 nukleotidů za vteřinu, u buněk člověka asi 50 nukleotidů za vteřinu

30
Energii pro replikaci dodávají trifosfáty ATP, GTP, CTP a TTP

31
Řetězce DNA jsou antiparalelní
Abychom odlišili číslování bází od číslování deoxyribózy, píšeme čísla uhlíků cukru s čárkou. Každý řetězec DNA má tedy 3´konec a 5´ konec řetězce DNA jsou antiparalelní, 5´konci jednoho řetěce odpovídá 3´konec druhého řetězce

32
Replikace Dva řetězce DNA jsou antiparalelní. DNA polymeráza ovšem může syntetizovat nový řetězec DNA pouze ve směru 5´ ke 3´. Nové nukleotidy jsou tedy přiřazovány pouze k 3´ konci. Tato vlastnost způsobuje problém pro replikaci dvouřetězcové DNA

33
Nový nukleotid se může připojit pouze ke 3´konci
Nový řetězec DNA tedy může růst pouze ve směru 5´ 3´

34
Replikační vidlička Při replikaci DNA může DNA-polymeráza jednoduše přidávat k jednomu z řetězců nukleotidy ve směru 5´ 3´. Tomuto řetězci se říká vedoucí řetězec Při elongaci druhého vlákna nové DNA se ale DNA- polymeráza musí pohybovat ve směru pryč od replikační vidličky. Řetězec takto syntetizované DNA se nazývá opožďující se řetězec Opožďující se řetězec Vedoucí řetězec

35
Opožďující se řetězec Tak jak se replikační vidlička otevírá, jsou následně syntetizovány nové a nové části opožďujícího se řetězce. Opožďující se řetězec je tedy syntetizován jako serie segmentů tyto segmenty se nazývají Okazakiho fragmenty a jsou u eukaryot dlouhé nukleotidů enzym DNA-ligáza pak jednotlivé Okazakiho fragmenty spojuje do souvislého řetězce

36
Syntéza vedoucího a opožďujícího se řetězce DNA
Vedoucí řetězec Opožďující se (váznoucí) řetězec
 řetězec.")
37
Primery DNA-polymeráza má ještě jedno omezení: může přidávat nové nukleotidy pouze k již existujícímu řetězci. Při replikaci tedy musí být nějak zařízena syntéza několika prvních nukleotidů Těchto několik prvních nukleotidů se nazývá primer a syntetizuje jej enzym primáza. Primer překvapivě není tvořen DNA, ale RNA eukaryotické primery jsou nukleotidů velké

38
Primery

39
Enzymy potřebné k replikaci
Helikáza - odvíjí dvoušroubovici DNA za vzniku dvou jednořetězcových vláken. Tato vlákna jsou chráněna SSB proteiny Primáza - tvorba primerů DNA-polymeráza elongace nového řetězce u opožďujícího se řetězce odstranění primeru a jeho nahrazení deoxyribonukleotidovou sekvencí Ligáza - spojuje Okazakiho fragmenty Gyráza – uvolňuje nadšroubovicové vinutí

40
Replikace Při syntéze DNA a při tvorbě replikační vidlice je třeba velkého množství enzymů a dalších proteinů. SSB proteiny chrání jednořetězcové úseky DNA (SSB = Single Strand Binding Proteins)
")
41
Ligáza SSB proteiny Primáza DNA polymeráza Helikáza

42
DNA replikace: enzymy (shrnutí)
")
43
Replikace DNA

44
Replikace DNA současné představy

45
Replikace DNA současné představy
Všechny enzymy potřebné k replikaci jsou zřejmě nějak spojeny a fungují jako jeden celek tento enzymový komplex je zřejmě ukotven k nukleoskeletu a místo, aby se pohyboval po DNA, je spíše DNA komplexem protahována

46
Replikace DNA je velmi přesná

47
Oprava chybného párování bází (DNA mismatch repair)
Kdyby špatně nasyntetizovaný nukleotid nebyl odstraněn, došlo by v příštím kole replikace k zafixování chyby Replikační aparát udělá cca 1 chybu na 107 nasyntetizovaných nukleotidů. 99% z nich je pak odstraněno opravou chybného párování bází jak opravný systém rozpozná který řetězec má opravit, není přesně známo

48
Oprava chybného párování bází (excizní reparace)
DNA je stále ohrožena, radioaktivním zářením, UV zářením, chemickými látkami atd. každá buňka neustále monitoruje a opravuje svou DNA u E. coli je známo asi 100 enzymů opravujících DNA, u člověka zatím asi 130 30% procent úmrtí v Evropě a USA jsou zapříčiněny rakovinou, která je způsobena selháním mechanismů opravy DNA

49
Oprava chybného párování bází (excizní reparace)
Na obr. je vidět vznik tzv. tyminových dimerů toto poškození je iniciováno UV světlem tyto dimery znesnadňují replikaci pokud selžou opravné mechanismy, výsledkem může být choroba xeroderma pigmentosum

50
Xeroderma pigmentosum
Lidem s touto dědičnou chorobou chybí enzym, provádějící excizní reparaci. Po osvitu sluncem je výsledkem rakovina kůže.

51
Problém nedoreplikovaných konců
Ve většině opravných procesů pracují DNA-polymerázy. Ty jsou ale omezeny vlastními limity: mohou přidávat nukleotidy pouze k 3´konci každé kolo replikace tak produkuje stále kratší a kratší molekuly DNA problém nenastane u kruhové DNA prokaryot

52
Telomery chromosomální DNA eukaryot má na svých koncích speciální sekvence, telomery telomery neobsahují geny, ale jsou tvořeny krátkými sekvencemi, které se mnohonásobně opakují u lidských telomer se jedná o sekvenci TTAGGG, která je opakována krát po mnoha buněčných cyklech může nastat potřeba obnovit stále se zkracující telomery

53
Telomery Telomery jsou obarveny žlutým barvivem

54
Telomeráza Prodlužování telomer způsobuje enzym telomeráza
jak ale může telomeráza nahradit sekvence, které již byly ztraceny? Telomeráza je pozoruhodná tím, že v sobě obsahuje krátký RNA řetězec, který slouží jako templát, matrice pro prodlužování 3´konce telomery

55
Telomeráza Telomeráza však překvapivě není přítomna ve většině buněk mnohobuněčných organismů telomeráza naopak je přítomna v tzv. germ- line cells, ze kterých vznikají gamety

56
Telomeráza Telomeráza je překvapivě přítomna rovněž u buněk rakovinných nádorů pokud se prokáže její vliv na udržení nesmrtelnosti rakovinných buněk, mohla by se stát důležitým cílem pro diagnózu i terapii rakoviny

57
Telomeráza

58
Telomeráza

59
Telomeráza

60
Centrální dogma Centrální dogma molekulární biologie popisuje dvoustupňový proces, kterým se dostává informace uložená v genech do proteinů: DNA RNA protein

61
Jakmile se jednou informace dostane do bílkoviny, již se nemůže dostat zpět

63
Dějiny Beadle a Tatum (pokusy s Neurospora crassa): one gene – one enzyme později: jeden gen – jeden protein ještě později: jeden gen – jeden polypeptidový řetězec

64
Transkripce a translace u prokaryot
U prokaryot je transkripce spojená s translací; translace začíná již ve chvíli, kdy je mRNA teprve syntetizována (u eukaryot transkripce probíhá v jádře a translace v cytoplazmě)
")
65
Transkripce a translace u prokaryot
Protože u prokaryot chybí jádro, které by prostorově oddělovalo transkripci a translaci, translace nastává už během transkripce.

66
Transkripce a translace u eukaryot
U eukaryot je transkripce od translace oddělena v čase i prostoru. Transkripce probíhá v jádře a jejím výsledkem je pre-mRNA (=hnRNA)
")
67
Transkripce a translace u eukaryot
Tato pre-mRNA je potom upravována až vznikne mRNA která opouští jádro a v cytoplazmě se účastní translace.

68
Transkripce a translace u prokaryot a eukaryot

69
Gen Strukturní gen = úsek DNA řetězce, jehož informace se vyjadřuje v primární struktuře polypeptidu jako translačního produktu Gen pro funkční RNA = úsek DNA řetězce přepisovaný do primární struktury tRNA nebo rRNA případně dalších druhů RNA, které nejsou určeny k translaci Gen jako regulační oblast = úsek na DNA plnící regulační funkci, který je rozeznáván specifickým proteinem signalizujícím zahájení nebo zastavení transkripce

70
Gen Strukturní gen = úsek DNA řetězce, jehož informace se vyjadřuje v primární struktuře polypeptidu jako translačního produktu vývojové geny – určují stavební plán těla, regulují jeho vývoj terminální cílové geny – jsou využívány jen v některých diferencovaných typech buněk a jejich aktivita je spouštěna vývojovými geny metabolické geny (housekeeping genes) řídí produkci látek nezbytných k zajištění základních životních funkcí Gen pro funkční RNA = úsek DNA řetězce přepisovaný do primární struktury tRNA nebo rRNA případně dalších druhů RNA, které nejsou určeny k translaci Gen jako regulační oblast = úsek na DNA plnící regulační funkci, který je rozeznáván specifickým proteinem signalizujícím zahájení nebo zastavení transkripce
 řídí produkci látek nezbytných k zajištění základních životních funkcí. Gen pro funkční RNA = úsek DNA řetězce přepisovaný do primární struktury tRNA nebo rRNA případně dalších druhů RNA, které nejsou určeny k translaci. Gen jako regulační oblast = úsek na DNA plnící regulační funkci, který je rozeznáván specifickým proteinem signalizujícím zahájení nebo zastavení transkripce.")
71
Existují cca 4 typy RNA; každá je kódována svým vlastní typem genů.
Genomová DNA obsahuje všechny informace o struktuře a funkci organismu V konkrétní buňce jsou ovšem pouze některé geny exprimovány (přepsány do mRNA a proteinů)
")
72
Jsou 4 typy RNA, každá kódována svým vlastním typem genu
mRNA (messengerová RNA): kóduje aminokyselinovou sekvenci polypeptidu tRNA (transferová RNA) – přináší do ribozómu aminokyseliny během translace rRNA (ribosomální RNA) – spolu s ribozomálními proteiny vytváří ribozómy, organely, na kterých probíhá translace mRNA snRNA (small nuclear RNA) spolu s proteiny tvoří komplexy které se uplatňují při sestřihu pre –mRNA u eukaryot (nikoli u prokaryot)
: kóduje aminokyselinovou sekvenci polypeptidu. tRNA (transferová RNA) – přináší do ribozómu aminokyseliny během translace. rRNA (ribosomální RNA) – spolu s ribozomálními proteiny vytváří ribozómy, organely, na kterých probíhá translace mRNA. snRNA (small nuclear RNA) spolu s proteiny tvoří komplexy které se uplatňují při sestřihu pre –mRNA u eukaryot (nikoli u prokaryot)")
73
Strukturní gen (= gen který kóduje protein) se sestává z
promotoru – sekvence nukleotidů která určuje kde přesně začne transkripce kódující sekvence určuje pořadí aminokyselin v polypeptidu terminátor – sekvence která určí konec transkriptu RNA

74
RNA je strukturálně podobná DNA

75
Transkripce v eukaryotické buňce…
…má tři fáze: iniciace elongace terminace

76
DNA řetězce 5´AGTACG 3´nebo 5´CGTACT 3´kódující/sense/+ řetězec
3´TCATGC 5´ nebo 3´GCATGA 5´matrixový/antisense/ - řetězec 5´AGUACG 3´ nebo 5´CGUACU 3´ mRNA Ser Thr Arg Ser protein kódující řetězec = sense řetězec = Watsonův řetězec = plus řetězec = RNA sekvence matrixový řetězec = antisense řetězec = Crickův řetězec = minus řetězec = reversní řetězec

77
DNA řetězce CpG = takto označujeme cytosin a guanin na jednom řetězci DNA CG = takto označujeme cytosin a guanin na komplementárních řetězcích dvoušroubovice

78
DNA Escherichia coli

79
DNA eukaryotického chromosomu
tmavě je zbytek proteinového lešení

80
Syntéza RNA spočívá v rozpletení DNA řetězců a v tvorbě RNA molekuly v 5´ ke 3´směru. Reakci katalyzuje RNA- polymeráza, která používá řetězec DNA jako templát.

81
RNA polymeráza prokaryota mají jediný typ RNA polymerázy eukaryota:
RNA polymeráza I. RNA polymeráza II. – jen ta vytváří mRNA RNA polymeráza III.

82
Transkripce začíná na promotoru, pokračuje
přes kódující sekvenci a končí na terminátoru.

84
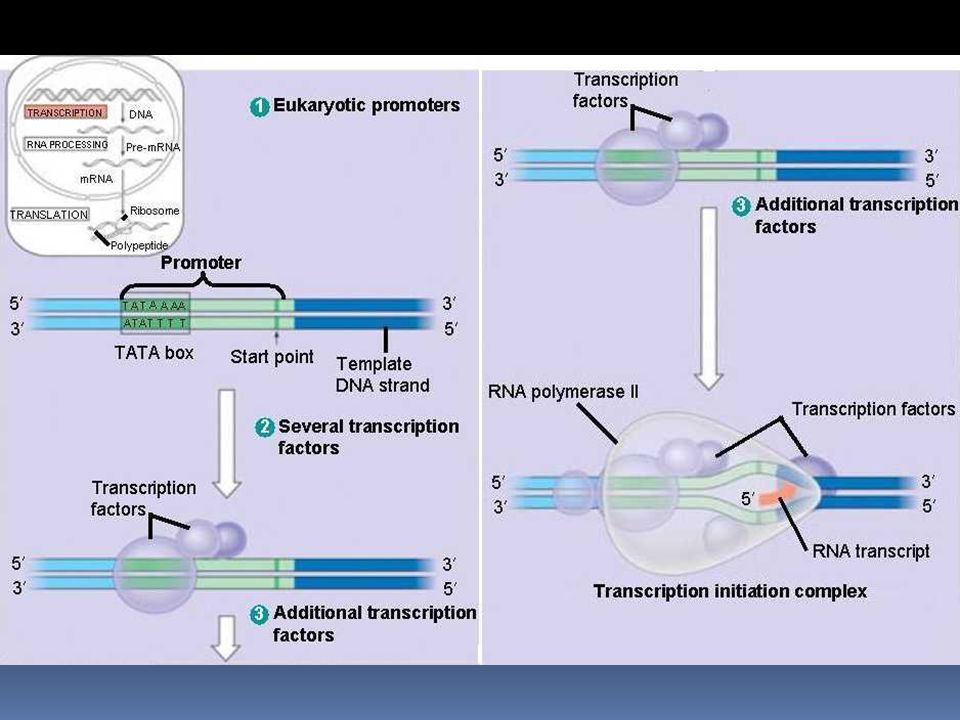
Transkripce Promotor: místo na DNA, obvykle několik desítek bp před začátkem přepisovaného úseku. Důležité místo je TATA box, asi 25 bp „proti proudu“ Na promotor se naváže proteiny zvané transkripční faktory Na tento útvar se naváže RNA polymeráza. Transkripční iniciační komplex = promotor + transkripční faktory + RNA polymeráza

85
celých 6 % genomu eukaryot jsou geny kódující transkripční faktory!

86
Promotory pro hlubší zájemce
TATA box = asi -25pb proti proudu jedná se o variace na sekvenci TATAAA mutace v TATA elementu neovlivní iniciaci transkripce, ale transkripce začne na nesprávném nukleotidu GC box jedná se o variace na sekvenci GGGCGG nachází se v mnoha genech, i v těch, kterým chybí TATA box CAAT box = asi – 80pb proti proudu velmi silně ovlivňuje sílu promotoru

87
Promotory pro hlubší zájemce
enhancery = posilovače transkripce (o kterých ještě bude řeč) = sekvence DNA nalézaných často i ve velkých vzdálenostech od promotoru váží se na ně regulační proteiny, dojde k ohybu DNA a enhancery se dostanou do těsné blízkosti promotoru proteiny vážící se k enhancerům interagují s transkripčními faktory na promotoru nebo i s RNA polymerázou silencery = regulační sekvence se stejnými vlastnostmi jako mají enhancery, ovšem tentokráte inhibují transkripci
 = sekvence DNA nalézaných často i ve velkých vzdálenostech od promotoru. váží se na ně regulační proteiny, dojde k ohybu DNA a enhancery se dostanou do těsné blízkosti promotoru. proteiny vážící se k enhancerům interagují s transkripčními faktory na promotoru nebo i s RNA polymerázou. silencery = regulační sekvence se stejnými vlastnostmi jako mají enhancery, ovšem tentokráte inhibují transkripci.")
88
mRNA u prokaryot

89
mRNA u eukaryot Transkript eukaryotického genu je molekula, která musí
být ještě upravena; jsou z ní vystřiženy některé sekvence (introny)
")
90
Elongace RNA polymeráza rozplétá asi 10-20 nukleotidový úsek DNA.
RNA polymeráza vytváří u eukaryot premRNA rychlostí asi 60 nukleotidů za vteřinu po průchodu RNA polymerázy se obnovuje dvoušroubovice DNA

91
Terminace transkripce
elongace pokračuje, dokud RNA polymeráza nenarazí na terminační sekvenci na DNA existuje zřejmě několik typů terminace transkripce, detaily stále nejsou známy u prokaryot terminace končí přesně v místě terminačního signálu u eukaryot porbíhá transkripce ještě několik stovek nukleotidů za terminačním signálem, kterým je sekvence AAUAAA na pre-mRNA ovšem několik desítek nukleotidů za touto sekvencí je pre- mRNA odstřižena od RNA polymerázy na pre-mRNA je potom navázán tzv. poly(A) tail
 tail.")
92
Transkripce - opakování

93
Eukaryotické buňky po transkripci modifikují pre-mRNA
oba konce pre-mRNA jsou změněny: 5´konec nese tzv. čepičku (=modifikovaný guanin) na 3´konec je nasyntetizováno 50 – 250 adeninových nukleotidů
 na 3´konec je nasyntetizováno 50 – 250 adeninových nukleotidů.")
94
5´ konec: čepička čepičku tvoří 7- methylguanosin vázaný na další nukleotid trifosfátem čepička má dva úkoly: chrání pre-mRNA před účinkem hydrolytických enzymů je signálem pro navázání se k malé ribozomální podjednotce, čímž začíná translace

95
Sestřih pre-mRNA Většina eukaryotických genů obsahuje segmenty zvané introny, které přerušují sekvence kódující aminokyseliny (exony) Transkriptem těchto genů je pre-mRNA (precursor – mRNA) Pre-mRNA je upravena v jádře tak že jsou vystřiženy introny a exony jsou spojeny do mRNA. Tato mRNA opouští jádro a v cytoplazmě podléhá translaci.
 Pre-mRNA je upravena v jádře tak že jsou vystřiženy introny a exony jsou spojeny do mRNA. Tato mRNA opouští jádro a v cytoplazmě podléhá translaci.")
96
Sestřih průměrná pre-mRNA je asi 8 000 pb dlouhá
průměrná mRNA je asi 1200 pb dlouhá a dává vznik proteinu tvořenému asi 400 aminokyselinami tato čísla jsou pouze průměrná, výjimky existují na obě strany člověk: čím delší gen, tím více intronů

97
Sestřih

98
Introny a exony intron = část pre-mRNA, která bude vystřižena
exon = část pre-mRNA, která bude exprimována do proteinového řetězce do cytoplazmy se dostává již sestřižená mRNA Intergenic DNA = nekódující sekvence DNA nacházející se mezi geny

99
Sestřih pre-mRNA obrázek znázorňuje pre-mRNA pro ß-globin, jeden z polypeptidů hemoglobinu čísla označují kódóny, ß-globin má délku 146 aminokyselin

100
Eukaryotická pre-mRNA obvykle obsahuje introny. Pomocí
částic snRNP jsou introny vystřiženy a exony připojeny k sobě snRNP, jak již název napovídá, se nachází v jádře a jsou tvořeny z tzv. snRNA a proteinů snRNA = small nuclear RNA, snRNA je cca 150 nukleotidů dlouhá několik různých snRNA se spojují s proteiny za vzniku snRNP (small nuclear ribonucleoproteins) snRNP se spojují ještě s dalšími proteiny za vzniku spliceosomu
 snRNP se spojují ještě s dalšími proteiny za vzniku spliceosomu.")
101
Introny většina intronů začíná sekvencí GT a končí sekvencí AG (GT-AG, respektive GU-AG) kromě GT a AG je třetím důležitým místem tzv. branch site, které je většinou situováno asi 40 nukleotidů před koncovou sekvencí AG jen mál intronů začíná AU a končí AC (AU-AC) a jsou zvané AT-AC introny
 a jsou zvané AT-AC introny.")
102
Fáze sestřihu štěpení primárního transkriptu (=pre- mRNA) na 5´ začátku intronu nukleofiliní atak koncového G nukleotidu na A nukleotid na branch site za vzniku lasovité formy štěpení intronu na 3´konci a uvolnění lasovité RNA (lariat RNA)
")
103
Fáze sestřihu

104
Sestřih pre-mRNA snRNP (= malé jaderné ribonukleoproteinové částice = small nuclear ribonucleoprotein particles; jedná se o komplex snRNA a proteinů) se navážou k intronu a vytvoří spliceosom Intron je vystřižen a exony jsou připojeny k sobě Výsledná mRNA může opustit jádro a v cytoplazmě podléhá translaci
 se navážou k intronu a vytvoří spliceosom. Intron je vystřižen a exony jsou připojeny k sobě. Výsledná mRNA může opustit jádro a v cytoplazmě podléhá translaci.")
105
Spliceosom se sestává z pěti typů snRNA a z více než 50 proteinů
vazbou proteinů k snRNA vznikne snRNP snRNA se váže k RNA, která má být sestřižena za vzniku RNA-RNA párování bází

106
Ribozym někdy může pouze snRNA způsobit sestřih bez pomoci proteinů (pozorováno u prvoka Tetrahymena) objev učinil v 80. letech Thomas Cech v USA padlo tím dogma, že enzymem může být pouze protein… … a napovídá to představě, že při vzniku života byla prvotní RNA před proteiny

107
Ribozym v této souvislosti stojí za to uvést, že i ribozóm je de facto ribozym – vlastní syntézu proteinu – tvorbu peptidické vazby - katalyzuje rRNA a nikoli ribosomální proteiny, které mají zřejmě jen podpůrnou funkci ribozóm je možno chápat jako ribozym stabilizovaný proteiny dříve snad existovaly ribozómy tvořený pouze z rRNA bez proteinů

108
Polyadenylace Odstřižení primárního transkriptu (=pre-mRNA) se děje asi nukleotidů za terminačním signálem AAUAAA
 se děje asi nukleotidů za terminačním signálem AAUAAA.")
109
Evoluční důležitost intronů: alternativní sestřih
introny snad plní v buňce regulační funkci samotný proces sestřihu jistě reguluje průchod mRNA ven z jádra introny ale s určitostí umožňují tzv. alternativní sestřih např. u drosofily zřejmě alternativní sestřih jedné pre-mRNA určuje výsledné pohlaví! u člověka se alternativním sestřihem vysvětluje relativně malý počet genů (možná jen kolem )
")
110
Alternativní sestřih u člověka odhadováno snad až 40 % genů má alternativní sestřih

111
Evoluční důležitost intronů
proteiny obsahují rovněž často úseky nazývané domény např. jedna doména může tvořit aktivní místo enzymu, zatímco druhá může enzym kotvit k membráně introny pak umožňují crossing-over v místech, kde „neškodí“ a způsobí pak přeskupení jednotlivých exonů a tím i vznik proteinů nových vlastností

112
Domény

113
Centrální dogma molekulární biologie

114
Základním stavebním kamenem bílkoviny je aminokyselina

115
V živých organismech je známo 20 aminokyselin
které se odlišují svojí R- skupinou Zde jsou čtyři z nich

116
Peptidová vazba Aminokyseliny jsou spolu spojeny prostřednictvím peptidové vazby. Peptidová vazba je tvořena mezi karboxylovou skupinou jedné aminokyseliny (na obrázku Amino acid 1) a aminoskupinou druhé aminokyseliny (Amino acid 2)
 a aminoskupinou druhé aminokyseliny (Amino acid 2)")
117
Genetický kód: od RNA k proteinu
Jazyk RNA se překládá do jazyka proteinů. Genetický kód nazýváme tripletový, protože tři nukleotidy v RNA specifikují jednu aminokyselinu v proteinu RNA se sestává ze čtyř „písmen“: A,U,G,C

118
Tripletový kód

119
Genetický kód byl rozluštěn na počátku šedesátých let XX. století

120
Rozluštění genetického kódu
1961: Marshall Nirenberg vytvořil umělou mRNA, která se sestával ze samých uracilů: UUUUUUUUUUUUUUUU atd. výsledkem translace byla bílkovina, sestávající ze samých fenylalaninů: phe-phe- phe-phe atd. Nirenberg uzavřel: kodón UUU kóduje fenylalanin do 1965 byl znám celý genetický kód

121
Genetický kód se musel vyvinout velmi dávno
Genetický kód je (téměř) univerzální, sdílí jej celá živá příroda, od nejjednodušších bakterií po savce příjemným důsledkem je, že díky technikám genových manipulací jž dnes baktérie vyrábí látky důležité pro člověka (např. insulin, STH) Rostlinka tabáku, do které byl vložen gen pro luciferázu od světlušek.
 univerzální, sdílí jej celá živá příroda, od nejjednodušších bakterií po savce. příjemným důsledkem je, že díky technikám genových manipulací jž dnes baktérie vyrábí látky důležité pro člověka (např. insulin, STH) Rostlinka tabáku, do které byl vložen gen pro luciferázu od světlušek.")
122
Genetický kód se musel vyvinout velmi dávno
Do těchto prasat byl vložen gen z medúzy a prasata ve tmě světélkují

123
Genetický kód je tripletový
AUG je startovní kodón, kóduje metionin UAA, UAG, UGA jsou stop kódony Genetický kód je degenerovaný: ve většině případů je jedna aminokyselina kódována víc než jedním tripletem (max. 6)
")
124
Mitochondriální kód se v pěti trojicích liší

125
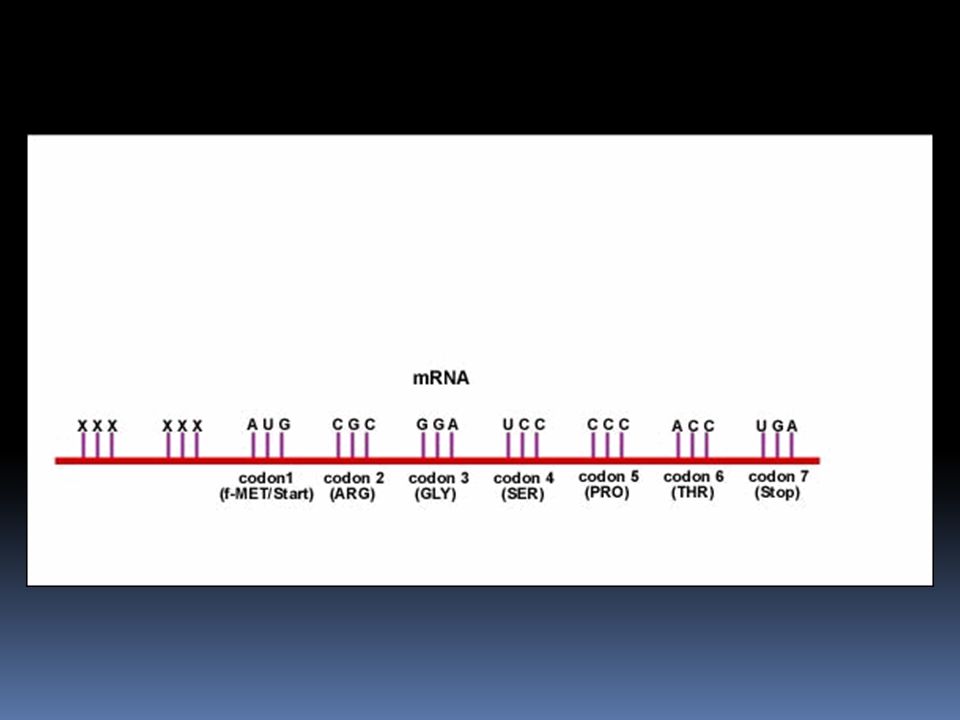
Čtecí rámec kódony mezi sebou nemají mezery, ale přesto jsou čteny jako třípísmenková „slova“. Čtecí rámec specifikuje první písmeno, od kterého začínáme číst a dává nám smysl věty: děd jed med ědj edm ed anglická verse: The red dog ate the cat her edd oga tet hec at nebo Why did the red bat eat the fat rat? W hyd idt her edb ate att hef atr at

126
Translace v eukaryotické buňce
Strukturní gen je přepsán do pre- mRNA Pre-mRNA je upravena do mRNA mRNA opouští jádro Na ribozómech podléhá mRNA translaci a vzniká polypeptidový řetězec

127
V prokaryotické buňce je transkripce spojena s translací

128
mRNA se sestává z vedoucí sekvence,(leader)
transkripční jednotky a koncové sekvence (trailer) Jednotlivé mRNA se odlišují ve složení nukleotidů, kterými jsou kódovány jednotlivé aminokyseliny, ve čtecím rámci a rovněž odlišným složením vedoucí a koncové sekvence
 Jednotlivé mRNA se odlišují ve složení nukleotidů, kterými. jsou kódovány jednotlivé aminokyseliny, ve čtecím rámci a. rovněž odlišným složením vedoucí a koncové sekvence.")
129
Eukaryotická mRNA

130
Ribozómy Ribosómy jsou organely na kterých probíhá translace mRNA.
Ribozóm se sestává ze dvou podjednotek, které obsahují rRNA a proteiny na ribosomu jsou tři místa: Exit Peptidylové Aminoacyové

131
Současné představy o stavbě ribozómu
Prokaryotická buňka obsahuje i více ribosomů

132
Současné představy o stavbě ribosomu

133
Ribozóm se skládá z větší a menší podjednotky
A = aminoacylové místo P = peptidylové místo E = exit

134
Prokaryotický a eukaryotický ribozóm
70S 80S 50S 5S rRNA (120 nukleotidů) 23S rRNA (2 904 nukleotidů) 34 proteinů 60S 5S rRNA 5,8S rRNA 28S rRNA 40 proteinů 30S 16S rRNA (1 542 nukleotidů ) 21 proteinů 40S 18S rRNA 30 proteinů Prokaryota Eukaryota
 23S rRNA (2 904 nukleotidů) 34 proteinů. 60S. 5S rRNA. 5,8S rRNA. 28S rRNA. 40 proteinů. 30S. 16S rRNA (1 542 nukleotidů ) 21 proteinů. 40S. 18S rRNA. 30 proteinů. Prokaryota. Eukaryota.")
135
Při translaci prochází mRNA skrze ribozóm
Při translaci prochází mRNA skrze ribozóm. Zde jsou rozpoznány kódony mRNA pomocí transferové RNA, která přinese příslušnou aminokyselinu Každá ribozomální podjednotka se sestává z rRNA (=ribozomální RNA, kterou kodují rRNA geny) a z ribozomálních proteinů
 a z ribozomálních proteinů.")
136
U eukaryot má větší podjednotka sedimentační konstantu 60S (pojmenovanou podle toho, jak rychle sedimentuje při centrifugaci) a obsahuje 28S; 5,8S a 5S rRNA a asi 50 ribozomálních proteinů Malá podjednotka má konstantu 40S a obsahuje 18S rRNA a asi 30 proteinů

137
tRNA 75 – 80 nukleotidů tRNA přináší během translace aminokyseliny do ribozómu a tyto aminokyseliny jsou včleněny do polypeptidového řetězce

138
tRNA

139
tRNA tRNA jsou kódovány tRNA geny
Všechny tRNA mají podobný tvar a velikost Všechny tRNA končí na 3´konci sekvencí CCA; zde se k nim váže příslušná aminokyselina Na opačném „konci“ tRNA molekuly je antikodon, který během translace „čte“ kodony na mRNA

140
Ala - tRNA Pokud z 64 kodónů jsou tři terminační, mělo by existovat 61 druhů tRNA. Existuje ale jen 45 druhů tRNA. Toto množství stačí, neboť tRNA mají antikodóny, které jsou schopny rozeznat i více než jeden kodón. například U na 5´konci antikodónu se může vázat jak s A tak i s G na antikodónu. Jevu se říká „Pravidlo o kolísání párů bazí“

141
Aminoacyl-tRNA syntetázy

142
Enzym zvaný aminoacyl-tRNA syntetáza
navazuje správné aminokyseliny k správným tRNA

143
Správná aminokyselina se naváže na správnou tRNA pomocí enzymu zvaného aminoacyl-tRNA syntetáza. Proces se nazývá aminoacylace Protože se do bílkovin začleňuje 20 druhů aminokyselin, existuje 20 druhů aminoacyl-tRNA syntetáz Všechny tRNA nesoucí stejnou aminokyselinu jsou „nabity“ pomocí stejného enzymem, ačkoli se antikodony příslušné tRNA mohou odlišovat

144
Iniciace translace Iniciační komplex translace se sestává z obou
ribozomálních podjednotek a iniciátorové tRNA (met-tRNA) která se přičlení na startovní kodon na mRNA
 která se přičlení na startovní kodon na mRNA.")
145
Iniciace translace

146
Elongace polypeptidového řetězce
Elongace začíná přičleněním aminoacyl-tRNA ke správnému kodonu na A místě ribozomu

147
Elongace translace

149
Terminace translace Na stop kodon se navazuje bílkovina zvaná „release factor“ a syntéza polypeptidu je ukončena. Nově vzniklý polypeptid se uvolní od tRNA; tRNA se uvolní z ribozómu a dvě ribozomální podjednotky se uvolní od mRNA Syntéza polypeptidu pokračuje dokud není dosaženo stop kodonu

150
Terminace translace

151
Polysomy V daném čase může tutéž mRNA číst několik ribozómů
Celému útvaru se říká polyribozóm nebo polyzóm

152
Polysomy Danou mRNA může v daném čase číst více ribozómů
Tímto způsobem je možné vytvořit současně mnoho polypeptidů z jediné mRNA

153
Elongace Iniciace Terminace

154
Polyribozómy

155
Ribosomy v eukaryotické buňce existují ribosomy dvojího typu:
volné v cytoplasmě vázané na endoplasmatické retikulum (drsné ER) na volných ribosomech jsou syntetizovány proteiny potřebné pro buněčný provoz na ribosomech vázaných k ER se syntetizují proteiny potřebné pro endomembránový systém a proteiny „na export“) ribosomy obou skupin jsou identické a mohou svou pozici v buňce měnit
 na volných ribosomech jsou syntetizovány proteiny potřebné pro buněčný provoz. na ribosomech vázaných k ER se syntetizují proteiny potřebné pro endomembránový systém a proteiny „na export ) ribosomy obou skupin jsou identické a mohou svou pozici v buňce měnit.")
156
Ribosomy jak je ale možné, že některé ribosomy jsou volné a jiné vázané? syntéza všech proteinů začíná na volných ribosomech v cytoplasmě, kde se mRNA napojuje na volný ribosom takto syntéza pokračuje dál, pokud sám vznikající protein neobsahuje signál, aby se ribosom připojil k ER proteiny pro endomembránový systém a na export obsahují signální peptid, který poutá protein k ER

157
Signální peptidy určují právě vzniklým proteinům jejich buněčnou destinaci

158
Signální peptid signální peptid je tvořen sekvencí cca 20 aminokyselin na nebo poblíž N-konci vznikajícího peptidu signální peptid je rozeznán tzv. SRP částicí (signal-recognition particle). Tato částice poutá peptid a ribosom k receptorovému proteinu v membráně ER. receptorový protein v sobě obsahuje pór, kterým peptid pronikne do ER. Enzymy potom signální peptid obyvkle odstraní
. Tato částice poutá peptid a ribosom k receptorovému proteinu v membráně ER. receptorový protein v sobě obsahuje pór, kterým peptid pronikne do ER. Enzymy potom signální peptid obyvkle odstraní.")
159
Spojení transkripce a translace v prokaryotické buňce
Protože v prokaryotické buňce chybí jádro, transkripce je spojena s translací a nově vzniklý protein se může rychle přesunout na své místo v buňce

160
Transkripce a translace v eukaryotické buňce přehled

161
Mutace Bodové mutace = změna jediného nukleotidu Inzerce Delece
substituce

162
Srpkovitá anémie

163
Substituce = Nahrazení nukleotidu (a jeho komplementárního partnera) jiným nukleotidem Některé substituce jsou tzv. tiché mutace. Díky redundanci genetického kódu je totiž kódována stejná aminokyselina. Kdyby např, v DNA proběhla mutace z CCG na CCA, mRNA by měla změněný kodón z GGC na GGU. Oba kodóny však znamenají“glycin“, takže na struktuře proteinu se mutace neprojeví

164
Substituce Jiné substituce se sice projeví tak, že dojde ke změně aminokyseliny; pokud ale má nová aminokyselina podobné vlastnosti a není v aktivním centru či jiné důležité oblasti proteinu, změna se téměř nemusí projevit „missense muattions“ – záměna jedné aminokyseliny za jinou „nonsense mutations“ – záměna aminokyseliny za stop kodón

165
Kategorie bodových mutací

166
Mutageny Spontánní mutace = mutace, u kterých neznáme přčinu
Mutagen = fyzikální či chemická agens, která způsobí mutaci Rentgenové paprsky UV záření (tyminové dimery) Řada chemických látek
 Řada chemických látek.")
167
Inzerce a delece Inzerce = přidání jednoho nukleotidu (nebo bp)
Delece = ztráta nukleotidu (či bp) Obě tyto mutace mají devastující efekt, neboť mění čtecí rámec. Vznikne tedy úplně jiný polypeptid
 Obě tyto mutace mají devastující efekt, neboť mění čtecí rámec. Vznikne tedy úplně jiný polypeptid.")
168
Kategorie bodových mutací

169
...mnoho radosti z biologie
přeje Orko

Podobné prezentace


>")






>")

>")








