Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Regresní analýza, korelační analýza, časové řady
3. přednáška

2
Regresní analýza-maticové vyjádření regresního modelu
Příklady (funkce lineární v parametrech) Obecný zápis kde jsou známé funkce jedné proměnné-regresory Lineární funkce má dva regresory Kvadratická funkce má tři regresory Logaritmická funkce má dva regresory U většiny běžných regresních funkcí Počet parametrů
 Obecný zápis. kde jsou známé funkce jedné proměnné-regresory. Lineární funkce má dva regresory. Kvadratická funkce má tři regresory. Logaritmická funkce má dva regresory. U většiny běžných regresních funkcí. Počet parametrů.")
3
Regresní analýza-maticové vyjádření regresního modelu
Označíme pro i-té pozorování

4
Příklad Marketingové oddělení jisté firmy zkoumalo vztah mezi objemem výroby (v tis. kusech) a celkovými náklady (v mil Kč). V deseti vybraných provozech byly zjištěny následující údaje Proveďte výpočty parametrů regresní přímky pomocí matice F Objem výroby 2 4 8 10 6 Celkové náklady 15 20 25 17 30 22 21 35
 a celkovými náklady (v mil Kč). V deseti vybraných provozech byly zjištěny následující údaje. Proveďte výpočty parametrů regresní přímky pomocí matice F. Objem výroby Celkové náklady")
5
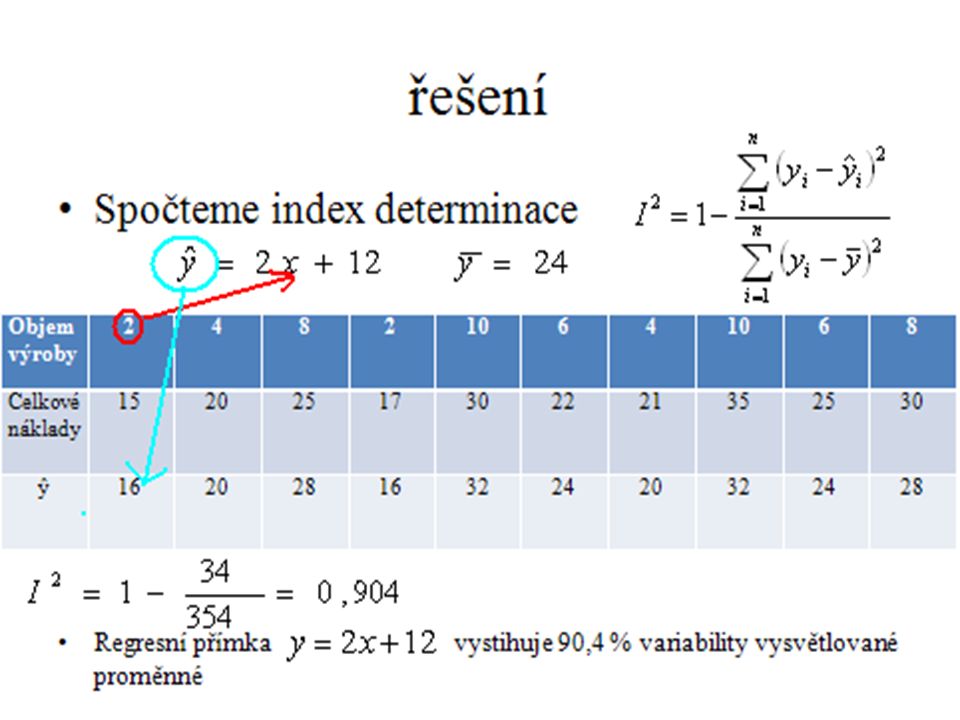
řešení

6
Volba vhodného modelu Apriorní volba- model je zvolen na základě znalosti závislostí v problému Empirická volba- model je zvolen pomocí regresní analýzy Důležité je posouzení bodového grafu

7
Volba vhodného modelu Nejvhodnější je ta funkce, jejíž graf je nejblíže zjištěným hodnotám ve výběrovém souboru To zjistíme hodnotou reziduálního rozptylu kde n…..rozsah výběrového souboru p…..počet odhadovaných parametrů

8
Volba vhodného modelu Index determinace
Čím blíže je index determinace jedné, tím vhodnější je regresní funkce Blíží-li se jedné- silná závislost Blíží-li se nule, jde o slabou závislost Hodnotu indexu determinace interpretujeme v procentech Hodnota indexu determinace udává, kolik % variability vysvětlované proměnné je zachyceno zvoleným regresním modelem

9
Příklad Marketingové oddělení jisté firmy zkoumalo vztah mezi objemem výroby (v tis. kusech) a celkovými náklady (v mil Kč). V deseti vybraných provozech byly zjištěny následující údaje Posuďte vhodnost modelu Objem výroby 2 4 8 10 6 Celkové náklady 15 20 25 17 30 22 21 35
 a celkovými náklady (v mil Kč). V deseti vybraných provozech byly zjištěny následující údaje. Posuďte vhodnost modelu. Objem výroby Celkové náklady")
11
Volba vhodného modelu Z nalezených regresních modelů vybereme ten, který má nejvyšší index determinace a nejnižší reziduální rozptyl. Pozor! Index determinace zvýhodňuje modely s více odhadovanými parametry. Proto se hlavně ve stat. software používá upravený(adjusted) index determinace Vhodnost regresního modelu můžeme měřit i kladnou odmocninou z indexu determinace, kterou nazýváme index korelace Dáváme přednost jednoduššímu modelu (při odlišnosti o ±2% volíme jednodušší model) i
 index determinace. Vhodnost regresního modelu můžeme měřit i kladnou odmocninou z indexu determinace, kterou nazýváme index korelace. Dáváme přednost jednoduššímu modelu (při odlišnosti o ±2% volíme jednodušší model) i.")
12
Intervalové odhady pro regresní koeficienty
bi je bodový odhad βi Odhad kovarianční matice Oboustranný interval spolehlivosti pro regresní parametr βj ………… % kvantil rozdělení t o (n-p) stupních volnosti s(bj)…….odmocnina prvku hlavní diagonály matice
 stupních volnosti. s(bj)…….odmocnina prvku hlavní diagonály matice.")
13
Testy hypotéz o nulové hodnotě regresních koeficientů
Jednotlivé t-testy (o statistické významnosti jednotlivých regresních koeficientů) Pokud regresní model je lineární funkce, pak nezamítnuté H0 znamená , že proměnné jsou lineárně nezávislé
 Pokud regresní model je lineární funkce, pak nezamítnuté H0 znamená , že proměnné jsou lineárně nezávislé.")
14
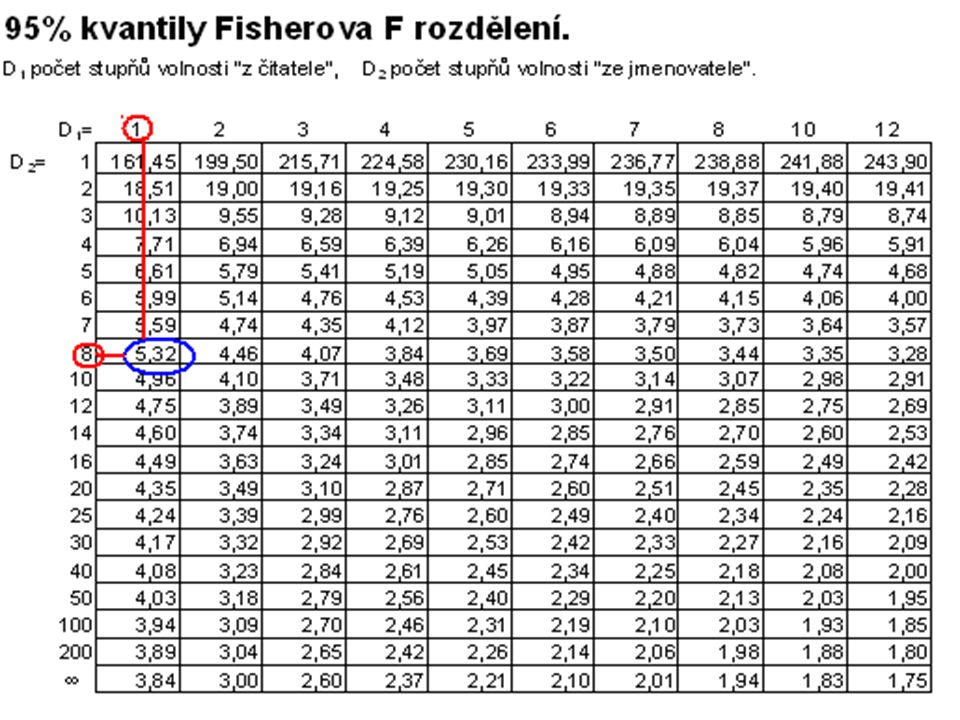
celkový F-test Celkový F-test (o statistické významnosti modelu)
Kde je 1-α% kvantil Fisherova rozdělení o p-1 a n-p stupních volnosti Zamítnutí H0- prokázání závislosti vysvětlované proměnné na zvolených regresorech (neznamená to, zvolený model je nejvhodnější, ani že je vhodný. Znamená to prokázání, že zvolená skupina regresorů způsobuje statisticky významné změny vysvětlované proměnné y)
")
15
Příklad pokračování Marketingové oddělení jisté firmy zkoumalo vztah mezi objemem výroby (v tis. kusech) a celkovými náklady (v mil Kč). V deseti vybraných provozech byly zjištěny následující údaje Prokažte závislost celkových nákladů na zvolených regresorech modelu Objem výroby 2 4 8 10 6 Celkové náklady 15 20 25 17 30 22 21 35
 a celkovými náklady (v mil Kč). V deseti vybraných provozech byly zjištěny následující údaje. Prokažte závislost celkových nákladů na zvolených regresorech modelu. Objem výroby Celkové náklady")
16
řešení V případě modelu, ve kterém odhadujeme pouze dva parametry, jsou nulové hypotézy obou testů stejné Test prokázal závislost vysvětlované proměnné na zvolených regresorech( 1,x)
")
18
Analýza reziduí Rezidua yi ……empirické hodnoty vysvětlované proměnné
ŷi ……odhadnuté hodnoty (modelem) vysvětlované proměnné Rezidua musí splňovat: A) mají normální rozdělení N(0,σ2) B) náhodná a nezávislá C) rozptyl reziduí σ2 je konstantní Nesplnění některé z těchto tří podmínek znamená, že se do modelu nepodařilo zahrnout celou systematickou složku a model nelze použít.
 vysvětlované proměnné. Rezidua musí splňovat: A) mají normální rozdělení N(0,σ2) B) náhodná a nezávislá. C) rozptyl reziduí σ2 je konstantní. Nesplnění některé z těchto tří podmínek znamená, že se do modelu nepodařilo zahrnout celou systematickou složku a model nelze použít.")
19
Vyšetřování normality reziduí N(0,σ2)
Normalitu ověříme některým z testů dobré shody nebo alespoň histogramem Nulovou střední hodnotu ověříme parametrickým testem pro µ, s nulovou hypotézou µ=0

20
Vyšetřování náhodnosti reziduí
Vyšetřením bodového grafu reziduí-počet kladných a záporných reziduí by měl být přibližně stejný. (ale toto subjektivní) Pomocí testu náhodnosti (znaménkový test, test založený na bodech zvratu)
 Pomocí testu náhodnosti (znaménkový test, test založený na bodech zvratu)")
21
Znaménkový test Neparametrický test H0: rezidua jsou náhodná
H1: rezidua nejsou náhodná Testové kritérium Vypočteme rozdíly Určíme počet kladných a záporných rozdílů S je větší z těchto čísel(nulové rozdíly se vypustí, tím se sníží n) Kritický obor
 Kritický obor.")
22
Příklad pokračování Marketingové oddělení jisté firmy zkoumalo vztah mezi objemem výroby (v tis. kusech) a celkovými náklady (v mil Kč). V deseti vybraných provozech byly zjištěny následující údaje Prokažte náhodnost reziduí regresního modelu Objem výroby 2 4 8 10 6 Celkové náklady 15 20 25 17 30 22 21 35 ŷ 16 28 32 24
 a celkovými náklady (v mil Kč). V deseti vybraných provozech byly zjištěny následující údaje. Prokažte náhodnost reziduí regresního modelu. Objem výroby Celkové náklady ŷ")
23
řešení Objem výroby 2 4 8 10 6 Celkové náklady 15 20 25 17 30 22 21 35
ŷ 16 28 32 24 e -1 -3 1 -2 3 ei+1-ei

24
Vyšetření nezávislosti reziduí
Pomocí testů nezávislosti -Durbin-Watsonův test Pomocí grafu ACF(autokorelační funkce)
")
25
Vyšetření konstantnosti rozptylu
Pomocí grafu reziduí Se zvětšujícím se x, by rezidua neměla růst ani klesat. Neboli rezidua by mě být stejně vzdálená od osy x. Homoskedasticita – konstantní rozptyl Heteroskedasticita – nekonstantní rozptyl

26
Vyšetření konstantnosti rozptylu
Rezidua rozdělíme na polovinu a provedeme dvouvýběrový test na srovnání rozptylů. Nulová hypotéza: rozptyly v obou polovinách se rovnají Alternativní hypotéza rozptyly v obou polovinách jsou různé Dvouvýběrový F-test

27
Korelační analýza Korelace-vzájemný lineární vztah mezi náhodnými veličinami Míry korelace – vyjadřují sílu (těsnost) tohoto vztahu Korelační koeficient Jeho bodovým odhadem je výběrový párový korelační koeficient

29
Výběrový párový korelační koeficient
Nabývá hodnot z intervalu Jestliže existuje mezi proměnnými přímá korelace Jestliže existuje mezi proměnnými nepřímá korelace Jestliže proměnné jsou lineárně nezávislé (nekorelované)
")
30
Výběrový párový korelační koeficient
Druhá mocnina regresního koeficientu se nazývá koeficient determinace Pro regresní přímku platí, že vyjadřuje jakou část variability vysvětlované proměnné y je možno popsat danou regresní přímkou.

31
Příklad Marketingové oddělení jisté firmy zkoumalo vztah mezi objemem výroby (v tis. kusech) a celkovými náklady (v mil Kč). V deseti vybraných provozech byly zjištěny následující údaje Změřte sílu lineární závislosti mezi objemem výroby a celkovými náklady pomocí koeficientu korelace a interpretujte jej. Objem výroby 2 4 8 10 6 Celkové náklady 15 20 25 17 30 22 21 35
 a celkovými náklady (v mil Kč). V deseti vybraných provozech byly zjištěny následující údaje. Změřte sílu lineární závislosti mezi objemem výroby a celkovými náklady pomocí koeficientu korelace a interpretujte jej. Objem výroby Celkové náklady")
32
řešení Výběrový párový korelační koeficient
Hodnota korelačního koeficientu udává silnou přímou závislost. Při zvyšujícím se objemu výroby se zvyšují i celkové náklady. Veličiny jsou silně korelované.

33
Test nulové hodnoty korelačního koeficientu
H0: ρ(x,y) = H1:ρ(x,y)≠0 Testové kritérium Kritický obor
 = 0 H1:ρ(x,y)≠0. Testové kritérium. Kritický obor.")
34
Příklad pokračování Otestujte nulovou hodnotu ρ(x,y)
H0: ρ(x,y) = H1:ρ(x,y)≠0 H0 zamítáme. Přijímáme hypotézu o nenulové hodnotě korelačního koeficientu v základním souboru. Hodnota korelačního koeficientu je statisticky významná.
 =0 H1:ρ(x,y)≠0. H0 zamítáme. Přijímáme hypotézu o nenulové hodnotě korelačního koeficientu v základním souboru. Hodnota korelačního koeficientu je statisticky významná.")
35
Pořadová korelace- Spearmanův koeficient
Při zkoumání vztahu mezi proměnnými nás zajímá někdy více pořadí hodnot, než hodnoty samotné Používáme tam, kde jsme schopni každou jednotku uspořádat podle nějakého hlediska Původní hodnoty xi ,yi nahradíme jejich pořadovými čísly ix,iy Označme di = ix,-iy i=1,2,…..,n

36
Spearmanův korelační koeficient
Pořadová korelace Nabývá hodnot z Při shodném pořadí jsou hodnoty všech di = 0 , tedy rS = 1. Je – li pořadí opačné, rS = -1 Pro hodnoty rS blízké nule můžeme usuzovat, že pořadí ix a iy jsou náhodně zpřeházena a mezi znaky x a y není závislost. Při opakování hodnot v souboru – přiřazujeme průměr z pořadových čísel, která na ně připadají Test o nulové hodnotě koeficientu pořadové korelace rs je stejný jako test pro ρ(x,y) Je málo citlivý na přítomnost vybočujících hodnot
 Je málo citlivý na přítomnost vybočujících hodnot.")
37
Příklad Restaurace uspořádala ochutnávku sedmi jídel ze svého jídelního lístku s hodnocením . Tato jídla (označená A, B, C, D, E, F, G) posuzovala jak odborná porota, tak porota sestavená z návštěvníků restaurace. Výsledky pořadí hodnocení jsou uvedeny v tabulce Ohodnoťte shodu obou porot. odborníci B C F G D A E laici
 posuzovala jak odborná porota, tak porota sestavená z návštěvníků restaurace. Výsledky pořadí hodnocení jsou uvedeny v tabulce. Ohodnoťte shodu obou porot. odborníci. B. C. F. G. D. A. E. laici.")
38
řešení Data uspořádáme do tabulky a spočteme diference
Byla prokázána poměrně silná shoda obou porot v hodnocení jídel. jídla ix iy diference Kvadrát diference A 6 5 1 B C 2 4 -2 D -1 E 7 F 3 G

39
Časové řady Posloupnost hodnot určitého kvantitativního ukazatele uspořádaná v čase (zaznamenávaná v pravidelných periodách) Rozlišujeme č.ř. podle délky periody : krátkodobé a dlouhodobé Podle vzniku údajů: základní –hodnoty ukazatele jsou přímo zjištěny, změřeny (č.ř. UOZ-uchazeči o zaměstnání) odvozené-hodnoty ukazatele je nutno vypočítat (č.ř. míry nezaměstnanosti) Podle povahy sledovaného ukazatele: okamžikové- hodnota ukazatele zachycená v určitém bodu času (č.ř. stavu zásob, UOZ, počtu studentů) intervalové -hodnota ukazatele je akumulovaná od minulého pozorování(č.ř. objem zisku, počet uzavřených dohod, počet návštěvníků) U intervalové časové řady: průměrná hodnota sledovaného znaku se vypočte jako aritmetický průměr U okamžikové časové řady: průměrná hodnota sledovaného znaku se vypočte jako chronologický průměr
 odvozené-hodnoty ukazatele je nutno vypočítat (č.ř. míry nezaměstnanosti) Podle povahy sledovaného ukazatele: okamžikové- hodnota ukazatele zachycená v určitém bodu času (č.ř. stavu zásob, UOZ, počtu studentů) intervalové -hodnota ukazatele je akumulovaná od minulého pozorování(č.ř. objem zisku, počet uzavřených dohod, počet návštěvníků) U intervalové časové řady: průměrná hodnota sledovaného znaku se vypočte jako aritmetický průměr. U okamžikové časové řady: průměrná hodnota sledovaného znaku se vypočte jako chronologický průměr.")
40
Časové řady Periodické chování-č.ř. ve kterých dochází pravidelně k systematickým výkyvům Č.ř. by měly být ekvidistantní: u okamžikových č.ř. by okamžiky měření měly být stejně vzdálené u intervalových č.ř. by časové intervaly měly být stejně dlouhé U mnohých č.ř. tomu tak není: např. v měsíční časové řadě mají měsíce různý počet dnů, atd.

41
Oprava neekvidistantních intervalových časových řad
yt původní ukazatele Lt délka t-tého období T celkový počet sledovaných období

42
Deskriptivní charakteristiky časových řad
Absolutní přírůstky (první diference) O kolik jednotek sledovaná hodnota vzrostla(poklesla) oproti předchozímu období Průměrný absolutní přírůstek
 O kolik jednotek sledovaná hodnota vzrostla(poklesla) oproti předchozímu období. Průměrný absolutní přírůstek.")
43
Deskriptivní charakteristiky časových řad
Koeficienty růstu- kolikrát daná hodnota vzrostla(poklesla) oproti předchozímu období Bezrozměrná charakteristika, vždy kladná Nemá smysl je počítat u časových řad, kde ukazatel střídá znaménka( má jak kladné, tak záporné hodnoty) Interpretujeme v % , např Říká, že ve třetím sledovaném období došlo k poklesu na 73 % oproti hodnotě ukazatele ve druhém sledovaném období Průměrný koeficient růstu
 oproti předchozímu období. Bezrozměrná charakteristika, vždy kladná. Nemá smysl je počítat u časových řad, kde ukazatel střídá znaménka( má jak kladné, tak záporné hodnoty) Interpretujeme v % , např. Říká, že ve třetím sledovaném období došlo k poklesu na 73 % oproti hodnotě ukazatele ve druhém sledovaném období. Průměrný koeficient růstu.")
44
Řetězové a bazické indexy
Koeficient růstu - řetězový index Udává změnu oproti předchozímu sledovanému období Bazický index Udává změnu oproti základnímu,(bazickému) období Platí
 období. Platí.")
45
Deskriptivní charakteristiky časových řad
Relativní přírůstky- o kolik % vzrostla (poklesla) hodnota sledovaného ukazatele oproti předchozímu období Může mít jak kladné tak záporné hodnoty
 hodnota sledovaného ukazatele oproti předchozímu období. Může mít jak kladné tak záporné hodnoty.")
46
Příklad rok 2001 2002 2003 2004 2005 2006 2007 2008 t 1 2 3 4 5 6 7 8 yt 193 178 188 195 169 152 175 182 dt - -15 10 -26 23 kt 0,92 1,056 1,037 0,87 0,899 1,11 1,04 rt -0,08 0,056 0,037 -0,13 -0,09 0,11 0,04

47
Interpretace % změny yt ........ počty UOZ v regionu X
Změna počtu UOZ v roce 2004 oproti roku 2003 – nárůst o 3,7% k4-k3=1,037-1,056= -0,019 V roce 2004 došlo oproti roku 2003 v časové řadě UOZ k poklesu o 1,9 procentního bodu rok 2003 2004 t 3 4 yt 188 195 dt 10 7 kt 1,056 1,037 rt 0,056 0,037

48
Modely časových řad Aditivní model empirické hodnoty ukazatele
teoretické hodnoty ukazatele reziduální hodnoty trendová složka –popisuje dlouhodobou tendenci vývoje časové řady sezónní složka- popisuje sezónní výkyvy v časové řadě s periodou kratší než jeden rok cyklická složka- popisuje kolísání kolem trendu v periodách větších než rok

49
Modely časových řad Multiplikativní model empirické hodnoty ukazatele
teoretické hodnoty ukazatele reziduální hodnoty trendová složka –popisuje dlouhodobou tendenci vývoje časové řady sezónní složka- popisuje sezónní výkyvy v časové řadě s periodou kratší než jeden rok cyklická složka- popisuje kolísání kolem trendu v periodách větších než rok

50
Volba modelu Aditivní model -volíme tehdy, když sezónní výkyvy kolem trendu jsou konstantní a nemění se se změnou trendu Multiplikativní model- se vzrůstajícím trendem rostou i sezónní výkyvy

51
Model trendu Pomocí regresní analýzy
Pomocí klouzavých průměrů-prosté klouzavé průměry Klouzavé průměry liché délky K Kde Klouzavé průměry sudé délky K

52
Klouzavé průměry Klouzavé průměry délky K- vytvoříme okno délky K, z hodnot v okně vypočteme prostý průměr a posuneme okno o jednu hodnotu dopředu Centrované klouzavé průměry-v případě klouzavých průměrů sudé délky se dvě sousední hodnoty klouzavých průměrů ještě zprůměrují. Délka okna se u časových řad volí takové délky, aby pokryla přirozenou periodu v řadě Čtvrtletní časové řady: K=4 Měsíční časové řady: K=12 Denní časové řady: K=7 Nevýhoda klouzavých průměrů- vždy ztrácíme několik hodnot zpočátku a konce sledovaného časového intervalu časové řady

53
Klouzavé průměry

54
Příklad Máme k dispozici údaje o sklizni kukuřice v ČR (v tis. tunách) za léta Spočtěte klouzavé průměry délky 3. rok 2000 2001 2002 2003 2004 2005 2006 2007 2008 yt 98 150 104 157 109 113 139 160 136

55
řešení rok 2000 2001 2002 2003 2004 2005 2006 2007 2008 yt 98 150 104 157 109 113 139 160 136 y‾t(k) - 117,3 137 123,3 126,3 120,3 137,3 145
 - 117, ,3. 126,3. 120,3. 137,")
56
Příklad Čtvrtletní tržby obchodu (v mil. Kč) za roky jsou uvedeny v následující tabulce rok 2008 2009 2010 čtvrtletí I. II. III. IV. yt 25 31 41 66 28 33 45 72 32 38 55 81

57
řešení

58
Model trendu Pomocí regresní analýzy Nezávisle proměnná : čas t
Za t budeme brát pořadová čísla postupně, jak byla data v čase pořizována t=1,2,….,T Závisle proměnná yt

59
Příklad O vývoji zisku určité firmy v mil. Kč.(prom. y) v období máme k dispozici tyto údaje Nalezněte trend časové řady vyjádřený regresní přímkou a interpretujte regresní koeficient b1 a předpovězte hodnotu zisku firmy pro rok 2012 rok 2007 2008 2009 2010 2011 yt 25 26,2 27,2 28,4 29,5

60
Řešení rok 2007 2008 2009 2010 2011 t 1 2 3 4 5 yt 25 26,2 27,2 28,4 29,5

61
Řešení pokračování Regresní přímka
Interpretace b1 : Každý rok zisky firmy vzrostou o 1,12mil Kč (o Kč) V roce 2012 se dají očekávat zisky ve výši
 V roce 2012 se dají očekávat zisky ve výši.")
62
INDEXY slouží pro porovnání téhož číselného ukazatele ve dvou různých obdobích Q, q … extenzitní ukazatele (objem,velikost rozsah, množství, atd.) p=Q/q … intenzitní ukazatel(poměr extenzitních ukazatelů), nebo-li Q=p·q 0…základní (bazické; starší) období 1…běžné (aktuální; novější) období
, nebo-li Q=p·q. 0…základní (bazické; starší) období. 1…běžné (aktuální; novější) období.")
63
Individuální indexy jednoduché
porovnávány přímo zjištěné ukazatele iq=q1/q0 iQ=Q1/Q0 ip=p1/p0 Q=p·q → iQ=ip·iq

64
Individuální indexy jednoduché
Př. (Zákl.stat. díl III): Změna výkonu přepravy? Železniční doprava 1990 1996 přepr.osob (mil.) 289,573 219,244 prům. vzdál. (km) 45,975 36,995 počet přepravených osob … q prům. přepravní vzdálenost … p celkový přepravní výkon … Q = pq (Q bude vyjádřeno v mil. „osobokilometrů“ )
: Změna výkonu přepravy Železniční doprava přepr.osob (mil.) 289, ,244. prům. vzdál. (km) 45, ,995. počet přepravených osob … q. prům. přepravní vzdálenost … p. celkový přepravní výkon … Q = pq. (Q bude vyjádřeno v mil. „osobokilometrů )")
65
Analytické zdůvodnění této změny?
Příklad Př. (Základy statistiky…III): Železniční doprava 1990 1996 přepr.osob = q 289,573 219,244 prům. vzdál. = p 45,975 36,995 přepr. výkon = Q 13313,119 8110,932 iq = q1/q0 = 0, … pokles q o 24,3 % ip = p1/p0 = 0, … pokles p o 19,5 % iQ = Q1/Q0 = 0,609 … pokles Q o 39,1 % Analytické zdůvodnění této změny?
: Železniční doprava přepr.osob = q. 289, ,244. prům. vzdál. = p. 45, ,995. přepr. výkon = Q , ,932. iq = q1/q0 = 0,757 … pokles q o 24,3 % ip = p1/p0 = 0,805 … pokles p o 19,5 % iQ = Q1/Q0 = 0,609 … pokles Q o 39,1 % Analytické zdůvodnění této změny")
66
Individuální indexy jednoduché
Př. (Základy statistiky…III): Platí: iQ = ip·iq (0,609 = 0,805·0,757) → interpretace – analytické zdůvodnění: Hodnota indexu celkových přepravních výkonů klesla na 80,5 % v důsledku poklesu průměrné přepravní vzdálenosti (p) a na 75,7 % v důsledku poklesu přepraveného množství osob (q); na celkovou změnu Q měla změna q větší vliv než změna p.
: Platí: iQ = ip·iq (0,609 = 0,805·0,757) → interpretace – analytické zdůvodnění: Hodnota indexu celkových přepravních výkonů klesla na 80,5 % v důsledku poklesu průměrné přepravní vzdálenosti (p) a na 75,7 % v důsledku poklesu přepraveného množství osob (q); na celkovou změnu Q měla změna q větší vliv než změna p.")
67
Individuální indexy složené
extenzitní údaje vznikají úhrnem Iq = Σq1/Σq0 = = Σ [(q1/q0)·q0] / Σq0 = bylo doplněno q0 = Σ(iq·q0) / Σq iq=ind.indexy jednoduché IQ= ΣQ1/ΣQ0 = Σ(p1q1) / Σ(p0q0) Ip = (ΣQ1/Σq1) / (ΣQ0/Σq0) = = [Σ(p1q1)/Σq1] / [Σ(p0q0)/Σq0]
·q0] / Σq0 = bylo doplněno q0. = Σ(iq·q0) / Σq0 iq=ind.indexy jednoduché. IQ= ΣQ1/ΣQ0 = Σ(p1q1) / Σ(p0q0) Ip = (ΣQ1/Σq1) / (ΣQ0/Σq0) = = [Σ(p1q1)/Σq1] / [Σ(p0q0)/Σq0]")
68
Příklad Př. (Zákl.stat. díl III): Změny výnosů pšenice
Spočtěte celkovou sumu sklizně … Q Spočtěte celkovou sumu plochy. … q Spočtěte výnosy … p = Q/q (vyjde v t/ha) v jednotlivých letech Vyjádřete změny výnosů pšenice.
 v jednotlivých letech. Vyjádřete změny výnosů pšenice.")
69
Příklad pokračování iq(soukr) = 445/225 = 1,978 (plocha: +97,8 %)
iq(ost) = 354/558 = 0, (plocha: -36,6 %) Iq = (1,978·225+0,634·558)/783 = = ( )/783 = 799/783 = 1,020 (celkem vzrostla plocha osetá pšenicí o 2 %)
 = 354/558 = 0,634 (plocha: -36,6 %) Iq = (1,978·225+0,634·558)/783 = = ( )/783 = 799/783 = 1,020. (celkem vzrostla plocha osetá pšenicí o 2 %)")
70
Příklad pokračování Analog. iQ(soukr) = 1,997 (sklizeno: +99,7 %)
iQ(ost) = 1742,3/2310,0 = 0, (-24,6 %) IQ = 3727,2/3304,0 = 1,128 (celkem vzrostla sklizeň pšenice o 12,8 %)
 = 1742,3/2310,0 = 0,754 (-24,6 %) IQ = 3727,2/3304,0 = 1,128. (celkem vzrostla sklizeň pšenice o 12,8 %)")
71
Příklad pokračování ip(soukr) = 4,460/4,418 = 1,010 (výnos: +1 %)
ip(ost) = 4,922/4,140 = 1, (výnos: +18,9 %) Ip = (3727,2/799) / (3304,0/783) = = 4,665/4,220 = 1,105 Celkem vzrostl hektarový výnos pšenice o 10,5 %
 = 4,922/4,140 = 1,189 (výnos: +18,9 %) Ip = (3727,2/799) / (3304,0/783) = = 4,665/4,220 = 1,105. Celkem vzrostl hektarový výnos pšenice o 10,5 %")
72
Individuální indexy složené
Analytické indexy - změna Q při fixním p0 : IQ(p0) = Σ(p0q1) / Σ(p0q0) - změna Q při fixním q1 : IQ(q1) = Σ(p1q1) / Σ(p0q1) Platí: IQ = IQ(q1) · IQ(p0) (Analogicky: nejprve fixní q0, pak p1 )
 = Σ(p0q1) / Σ(p0q0) - změna Q při fixním q1 : IQ(q1) = Σ(p1q1) / Σ(p0q1) Platí: IQ = IQ(q1) · IQ(p0) (Analogicky: nejprve fixní q0, pak p1 )")
73
Příklad dokončení IQ(p0) = (4,418·445+4,140·354) / 3304,0 =
= 3431,6 / 3304,0 = 1,039; Vlivem změny plochy by při výnosech z roku 1993 vzrostla sklizeň pšenice o 3,9 %

74
Příklad dokončení IQ(q1) = 3727,2 / (4,418·445+4,140·354) =
= 3727,2 / 3431,6 = 1,086; Vlivem změny výnosů by při ploše z roku 1996 vzrostla sklizeň pšenice o 8,6 % kontrola: 1,128 = 1,086 · 1,039

75
Indexy souhrnné pro heterogenní extenzitní údaje, kde nelze počítat úhrn (tuny rýže + tuny brambor…) Indexy souhrnné – cenové (pokud p=cena) Laspeyresův Ip(La)= Σp1q0 / Σp0q0 Paascheův Ip(Pa)= Σp1q1 / Σp0q1 Fisherův Ip(Fi)= √(ILa·IPa)
 Laspeyresův Ip(La)= Σp1q0 / Σp0q0. Paascheův Ip(Pa)= Σp1q1 / Σp0q1. Fisherův Ip(Fi)= √(ILa·IPa)")
76
Indexy souhrnné Indexy souhrnné - objemové (q=množství)
Iq = Σpq1 / Σpq0 za p volíme p0, p1 nebo jakékoli jiné Indexy souhrnné - hodnotové (p=cena, q=množství) IQ = ΣQ1 / ΣQ0 = Σp1q1 / Σp0q0
 IQ = ΣQ1 / ΣQ0 = Σp1q1 / Σp0q0.")
77
Indexy souhrnné Ihodnotový = Icenový · Iobjemový
Analytický rozklad Ihodnotový = Icenový · Iobjemový naopak : Iobjemový = Ihodnotový / Icenový při jiném významu q,Q a p platí např: Ireál.mezd = Inomin.mezd / Ispotřeb.cen

Podobné prezentace














>")




: Potvrzení H O Vyvrácení H O →přijmutí H 1 (H A ) Ptáme se: 1.) Pochází zkoumaný výběr (jeho x, s 2.>")