Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Akcelerace genetických algoritmů na grafických kartách 4. část Mikuláš Dítě Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti

2
Připomenutí problému udržování tyče na vozíku pěstování vozíků zdlouhavý výpočet fitness funkce

3
Paměťová náročnost přenesení dat do paměti GPU CPUCPU + GPU

4
Další optimalizace pouze GPU start zápis na GPU čtení z GPU každá generace paralelní výpočet vlastní implementace rand() a další výpočty vlastní implementace rand() a další výpočty
 a další výpočty vlastní implementace rand() a další výpočty")
5
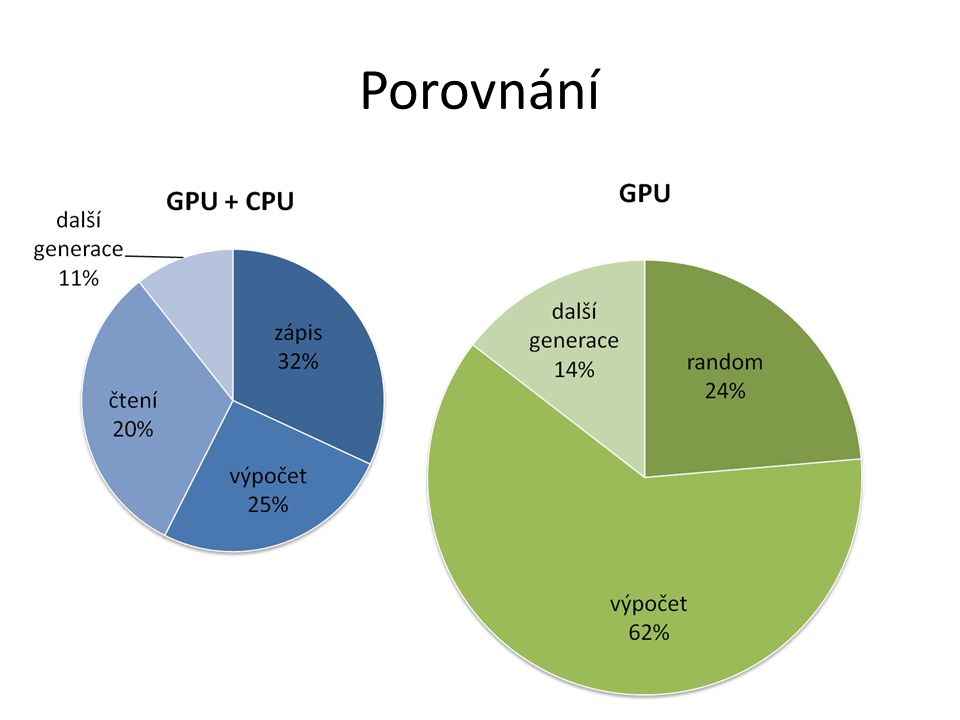
Porovnání CPU, GPU+CPU a GPU

6
Porovnání

8
Pokrok projektu implementace na GPU v CUDA vytvořeno testovací prostředí naměřeno snížit čas zápisu do paměti GPU zvětšit diverzitu (vzdálenost) jedinců a dále vylepšovat genetický algoritmus
 jedinců a dále vylepšovat genetický algoritmus")
9
Závěr celkově je výpočet pouze na GPU rychlejší než kombinace s CPU, ale minimalistická implementace OpenCL zpomaluje mohli bychom získat další zrychlení – speciálně navrženým kernelem pro ROM na GPU – použitím HW random (šum z okolí, …) – … ?
 – …")
10
Odkazy Ing. Miroslav Čepek (Katedra počítačů FEL ČVUT) Ing. Vladimír Pospíšil (Cesta k vědě) Poděkování https://github.com/Mikulas/PoleBalanceGPU https://github.com/Mikulas/PoleBalanceGPU
 Poděkování")
11
Zdroje [1] BROWNLEE, J. The pole balancing problem. [online]. [cit. 8. 1. 2011]. Dostupné z http://www.ict.swin.edu.au/personal/jbrownlee/2005/TR07- 2005.pdf [2] Genetic algorithm. [online]. [cit. 8. 1. 2011]. Dostupné z http://en.wikipedia.org/wiki/Genetic_algorithm [3] NP-hard. [online]. [cit. 8. 1. 2011]. Dostupné z http://en.wikipedia.org/wiki/Np-hard [4] KOZOLA, S. Improving Optimization Performance with Parallel Computing. [online]. [cit. 8. 1. 2011]. Dostupné z http://www.mathworks.com/company/newsletters/digest/2009/mar/par allel-optimization.html
![Zdroje [1] BROWNLEE, J. The pole balancing problem.](http://images.slideplayer.cz/12/3650915/slides/slide_11.jpg "[online]. [cit ]. Dostupné z pdf [2] Genetic algorithm. [online]. [cit ]. Dostupné z [3] NP-hard. [online]. [cit ]. Dostupné z [4] KOZOLA, S. Improving Optimization Performance with Parallel Computing. [online]. [cit ]. Dostupné z allel-optimization.html.")
Podobné prezentace






![Genetické algoritmy [GA]](/8/2469778/big_thumb.jpg "Genetické algoritmy [GA]>")
 vznikl na základě řešení projektu OPVK, registrační číslo CZ.1.07/1.5.00/34.0794 s názvem „Výuka na gymnáziu podporovaná.>")











