Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Organizace a zpracování dat I
Dynamické metody

2
Rozšiřitelné hašování (Fagin)
K lokalizaci stránek s daty využívá adresář. Připouští jak přidávání, tak odebírání záznamů. K získání dat stačí 1-2 přístupy na disk. Neumí se vypořádat se situací, kdy pro příliš mnoho různých klíčů je hašovaná hodnota totožná.

3
Rozšiřitelné hašování - schéma
2 3 000 001 3 010 011 3 100 101 110 1 111
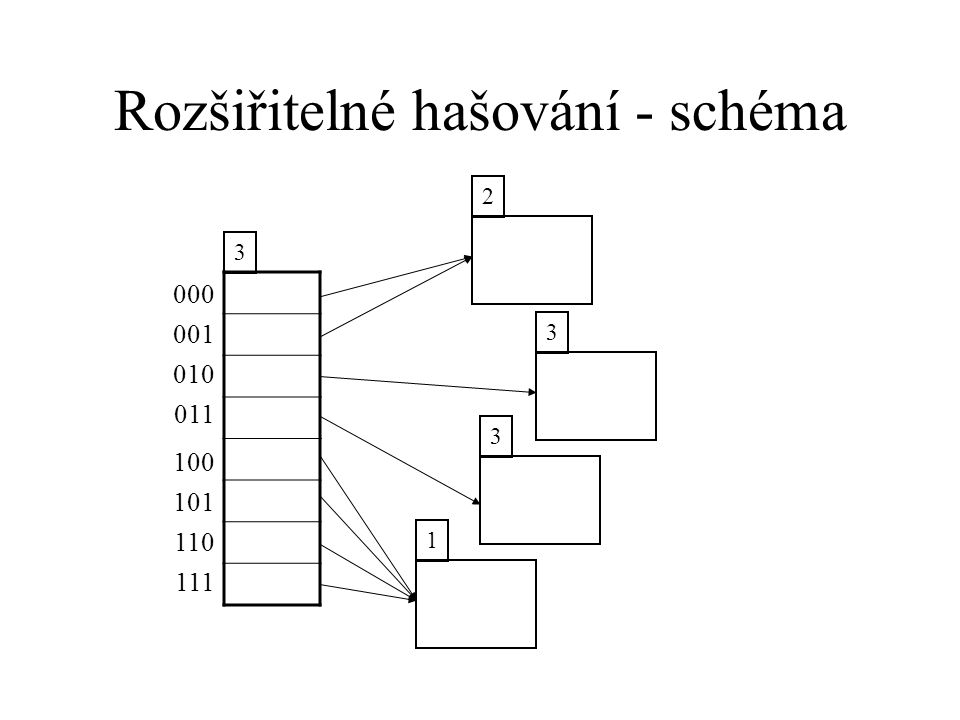
4
Rozšiřitelné hašování – schéma (2)
3 3 000 001 3 010 011 100 2 101 110 111 2
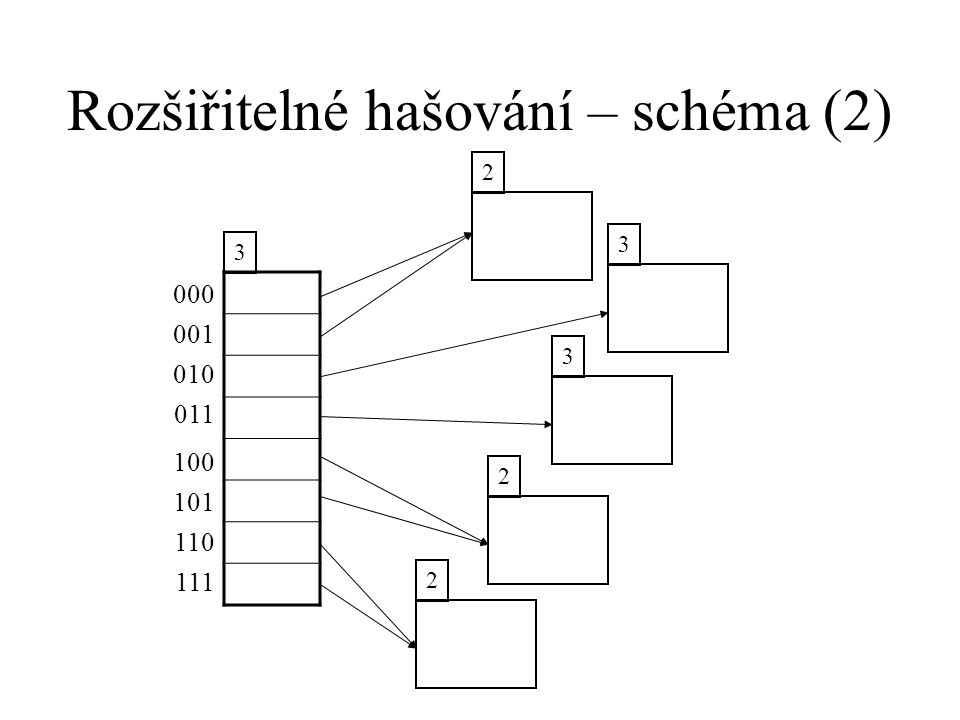
5
Rozšiřitelné hašování – schéma (3)
2 4 3 0000 0001 0010 4 0011 0100 0101 4 0110 0111 1000 2 1001 1010 1011 2 1100 1101 1110 1111

6
Rozšiřitelné hašování – pomocné funkce
GetPage(pt,pg) – čte stránku z adresy pt do vyrovnávací paměti pg. Collision-Act – ošetřuje kolizi/nenalezení záznamu
 – čte stránku z adresy pt do vyrovnávací paměti pg. Collision-Act – ošetřuje kolizi/nenalezení záznamu.")
7
Rozšiřitelné hašování - Access
procedure Access(var pt:pgadr; var index:integer; k:key; var found:bool); var pg:page; b:hashkey; begin b:=h(k); pt:=directory[brbr-1…br-d+1]; index:=bt+sbt+s+1…bt+1; GetPage(pt,pg); if pg.body[index].dk = k then begin found:=true; return end; Collision-Act(pg,index,k,found); end;
; var pg:page; b:hashkey; begin b:=h(k); pt:=directory[brbr-1…br-d+1]; index:=bt+sbt+s+1…bt+1; GetPage(pt,pg); if pg.body[index].dk = k then. begin found:=true; return end; Collision-Act(pg,index,k,found); end;")
8
Rozšiřitelné hašování - Insert
procedure Insert(r:drec; var ok:Bool); var index,j,k:integer; found:Bool; pt,pt1:pgadr; buffer,pg,pg1:page; begin Access(pt,index,r.dk,found); if found then ok:=false; return end; GetPage(pt,pg); if not IsFree(pg) then begin buffer:=pg; pg.LocD:=pg.LocD+1; pg1.LocD:=pg.LocD; Clean(pg); for i:=1 to m do Insert1(buffer.body[i],pg,pg1); Insert1(r,pg,pg1); Indicate(pt,j,k); for i:=j to k do directory[i]:=pt1; PutPage(pt1,pg1); end else Insert1(r,pg,pg); ok:=true; PutPage(pt,pg); end;
; var index,j,k:integer; found:Bool; pt,pt1:pgadr; buffer,pg,pg1:page; begin Access(pt,index,r.dk,found); if found then ok:=false; return end; GetPage(pt,pg); if not IsFree(pg) then begin. buffer:=pg; pg.LocD:=pg.LocD+1; pg1.LocD:=pg.LocD; Clean(pg); for i:=1 to m do Insert1(buffer.body[i],pg,pg1); Insert1(r,pg,pg1); Indicate(pt,j,k); for i:=j to k do directory[i]:=pt1; PutPage(pt1,pg1); end else Insert1(r,pg,pg); ok:=true; PutPage(pt,pg); end;")
9
Rozšiřitelné hašování - vlastnosti
Nalezení záznamu vyžaduje 2 přístupy na disk Adresář bývá možné držet ve vnitřní paměti (pak je jen 1 přístup na disk) Lze zrychlit provádění aktualizací při dávkovém zpracování: požadavky setřídit dle hašované hodnoty, a pak postupovat jako při aktualizaci setříděných sekvenčních souborů
 Lze zrychlit provádění aktualizací při dávkovém zpracování: požadavky setřídit dle hašované hodnoty, a pak postupovat jako při aktualizaci setříděných sekvenčních souborů.")
10
Lineární hašování – Litwin, 1980
Stránky je možné štěpit po pevném počtu vložení záznamů Předpokládá se hašovací funkce h(K), která pro libovolný klíč vrátí binární celé číslo v dostatečném rozsahu
, která pro libovolný klíč vrátí binární celé číslo v dostatečném rozsahu.")
11
Lineární hašování – postupné štěpení stánek
1 1 2 1 2 3 1 2 3 4 expanze expanze

12
Lineární hašování - GetLinAddr
FUNCTION GetLinAddr(K:Key):BlockAddr; VAR w, a : Integer; BEGIN w:=log2(pages+1) ; a:=h(K) mod 2w; IF a pages THEN a:=a mod 2w+1; return a END;
:BlockAddr; VAR w, a : Integer; BEGIN. w:=log2(pages+1) ; a:=h(K) mod 2w; IF a pages THEN a:=a mod 2w+1; return a. END;")
13
Lineární hašování - dokončení
Aneb: stačí využít vhodný počet dolních bitů z hašovaného klíče. Při štěpení stránky rozdělujeme záznamy dle (w-1)-ního bitu: ty s ‚0‘ zůstávají, ty s ‚1‘ jdou do nové stránky. Pozor! Musí se zpracovat i záznamy ze stránky přetečení!!
-ního bitu: ty s ‚0‘ zůstávají, ty s ‚1‘ jdou do nové stránky. Pozor! Musí se zpracovat i záznamy ze stránky přetečení!!")
14
Skupinové štěpení stránek
Stránky štěpeny po určitém počtu přidaných záznamů do souboru Snaha o rovnoměrnější rozdělení záznamů do stránek než u lineárního hašování Soubor dělený do s skupin po g stránkách Skupiny se při štěpení přerozdělují do g+1 stránek

15
Skupinové štěpení stránek (2)
Předpoklad: Existence posloupnosti nezávislých hašovacích funkcí h0,h1,… : K<0,g> FUNCTION PgAddr(k:key,d,sp:integer):integer; VAR j,s,x: integer; BEGIN x:=hash(k); s:=s0; FOR j:=0 TO d-1 DO BEGIN x:=x mod s + hj(k)*s; s:=s*(g+1)/g END; IF x mod s < sp THEN x:=x mod s+hd(k)*s; PgAddr:=x END;
:integer; VAR j,s,x: integer; BEGIN. x:=hash(k); s:=s0; FOR j:=0 TO d-1 DO. BEGIN x:=x mod s + hj(k)*s; s:=s*(g+1)/g END; IF x mod s < sp THEN x:=x mod s+hd(k)*s; PgAddr:=x. END;")
16
Skupinové štěpení stránek
Algoritmus přístupu k datům simuluje umístění záznamu v průběhu celého postupu štěpení stránek. Lineární (Litwinovo) hašování je skupinovým štěpením stránek pro g=1.
 hašování je skupinovým štěpením stránek pro g=1.")
17
Stromy Asi nejčastější dynamická datová na vnějších pamětech s přímým přístupem. Orientovaný graf je složený z uzlů a hran – uspořádaných dvojic uzlů. Každý uzel má konečnou množinu uzlů - (bezprostředních) následníků / potomků a množinu uzlů zvaných předchůdci či rodiče. Strom je orientovaný graf, kdy každý uzel kromě jednoho má právě jednoho rodiče. Uzel bez rodiče se nazývá kořen stromu, uzly bez potomků nazýváme listy.
 následníků / potomků a množinu uzlů zvaných předchůdci či rodiče. Strom je orientovaný graf, kdy každý uzel kromě jednoho má právě jednoho rodiče. Uzel bez rodiče se nazývá kořen stromu, uzly bez potomků nazýváme listy.")
18
B-strom B-strom (řádu m) je rozvětvený výškově vyvážený strom splňující tato omezení: kořen má nejméně dva potomky, není-li listem každý uzel kromě kořene a listů má nejméně m/2 a nejvýše m potomků každý uzel má nejméně m/2 - 1 a nejvíce m-1 datových záznamů všechny větve jsou stejně dlouhé

19
p0,(k1,p1,d1),(k2,p2,d2),…,(kn,pn,dn),u
B-strom (2) data v uzlu jsou organizována takto: p0,(k1,p1,d1),(k2,p2,d2),…,(kn,pn,dn),u kde pi jsou ukazatelé na potomky, ki klíče, di data a u nevyužitý prostor záznamy (ki,pi,di) jsou uspořádány vzestupně dle klíčů
 data v uzlu jsou organizována takto: p0,(k1,p1,d1),(k2,p2,d2),…,(kn,pn,dn),u. kde pi jsou ukazatelé na potomky, ki klíče, di data a u nevyužitý prostor. záznamy (ki,pi,di) jsou uspořádány vzestupně dle klíčů.")
20
B-strom - modifikace kořen podstromu může rozdělovat klíče v uzlech podstromu neostře (strom pak nazýváme redundantní - na původní verzi se budeme odkazovat jako na neredundantní), což dovolí i následující úpravy: data mohou být uložena pouze v listech - v nelistových uzlech jsou pouze klíče data mohou být uložena odděleně - na poslední úrovni pak ukazatelé neukazují na další uzly stromu, ale na data
, což dovolí i následující úpravy: data mohou být uložena pouze v listech - v nelistových uzlech jsou pouze klíče. data mohou být uložena odděleně - na poslední úrovni pak ukazatelé neukazují na další uzly stromu, ale na data.")
21
Neredundantní B-strom (2-3-strom)
B-strom - příklad 51 25 68 35 42 85 12 17 57 62 Neredundantní B-strom (2-3-strom)
")
22
B-strom - struktury Pro neredundantní variantu s daty v uzlech můžeme použít tyto struktury: TYPE rec = RECORD p:PgAdr; k:Key; d:Data END; page = RECORD m : Integer; {zaplnění stránky} leaf : Boolean; {je to list?} body : ARRAY [1..MaxM] OF rec; END;

23
B-strom – struktury (2) Pro rekurzivní variantu s daty v uzlech je třeba použít variantní strukturu: TYPE irec = RECORD p:PgAdr; k:Key; END; drec = RECORD k:Key; d:Data END;

24
B-strom – struktury (3) Také je třeba si pamatovat celou větev ve stromě (přinejmenším pro vkládání a vypouštění): TYPE Branch = RECORD h:integer; PgPtr: ARRAY [1..hmax] OF PgAdr; Ind: ARRAY [1..hmax] OF Integer; END;

25
B-strom - Access PROCEDURE Access(root:PgAdr; k:Key; VAR s:Branch; VAR found:Boolean); VAR pt:PgAdr; i:Integer; BEGIN s.h:=0; pt:=root; IF root=NIL THEN BEGIN found:=false; Exit END; REPEAT s.h:=s.h+1; s.ptr[s.h]:=pt; GetPage(pt,pg); Search(pg,k,found,i,pt); s.ind[s.h]:=i UNTIL pg.leaf END;
; Search(pg,k,found,i,pt); s.ind[s.h]:=i. UNTIL pg.leaf. END;")
26
B-strom - Insert PROCEDURE Insert(VAR root:PgAdr; r:rec; VAR ok:Boolean); VAR wr:rec; wk:Key; pt:PgAdr; p1,p2:page; found:Boolean; s:Branch; i:Integer; BEGIN IF root=NIL THEN InitRoot(root,s) ELSE BEGIN Access(root,r.k,s,found); IF found THEN BEGIN ok:=false; Exit END END; ok:=true; wr:=r; GetPage(s.ptr[s.h],p1);
 ELSE BEGIN Access(root,r.k,s,found); IF found THEN BEGIN ok:=false; Exit END. END; ok:=true; wr:=r; GetPage(s.ptr[s.h],p1);")
27
B-strom – Insert (2) FOR i:=s.h DOWNTO 1 DO WITH p1 DO BEGIN
IF m<MaxM THEN BEGIN MemIns(p1,wr,s.ind[i]); Exit END; Split(p1,wr,p2,pt); IF i=1 THEN BEGIN NewRoot(p1,p2,root,pt); Exit END; wk:=body[m].k; GetPage(s.ptr[i-1],p1); body[s.ind[i-1]].k:=wk; wr.k:=p2.ibody[p2.m].k; wr.p:=pt END;
; Exit END; Split(p1,wr,p2,pt); IF i=1 THEN. BEGIN NewRoot(p1,p2,root,pt); Exit END; wk:=body[m].k; GetPage(s.ptr[i-1],p1); body[s.ind[i-1]].k:=wk; wr.k:=p2.ibody[p2.m].k; wr.p:=pt. END;")
Podobné prezentace








>")
Vytvořím prázdný seznam příkazem LIST:=nil.>")




 dle daného klíče vzestupně (od nejmenší do největší hodnoty klíče) sestupně (od největší.>")




