Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Test dobré shody a testy nezávislosti, regresní analýza 2.přednáška

2
Test χ 2 dobré shody Neparametrický test- testujeme tvar rozdělení Testem ověřujeme shodu mezi empirickým a teoretickým rozdělením Obor hodnot náhodné veličiny rozdělíme do r≥2 disjunktních tříd (kategorií) π j …..pravděpodobnost, NV nabude hodnoty z j=té třídy
 π j …..pravděpodobnost, NV nabude hodnoty z j=té třídy")
3
Předpoklady teoretické četnosti n π j0 byly větší než 1 v každé třídě teoretické četnosti n π j0 byly větší než 5 v 80% tříd. Nevyhovují-li některé četnosti této podmínce, lze dosáhnout jejího splnění sloučením několika sousedních tříd (tím se sníží počet stupňů volnosti, neboť r je rovno počtu tříd po sloučení). Slučujeme skupiny nějak příbuzné, věcně spolu související.
. Slučujeme skupiny nějak příbuzné, věcně spolu související..")
4
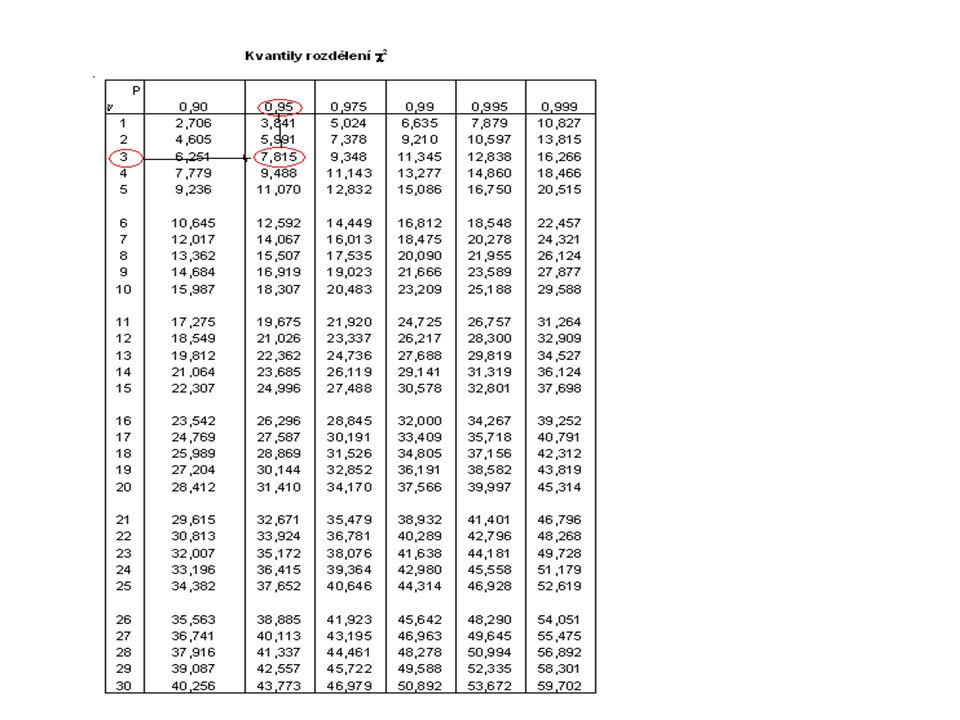
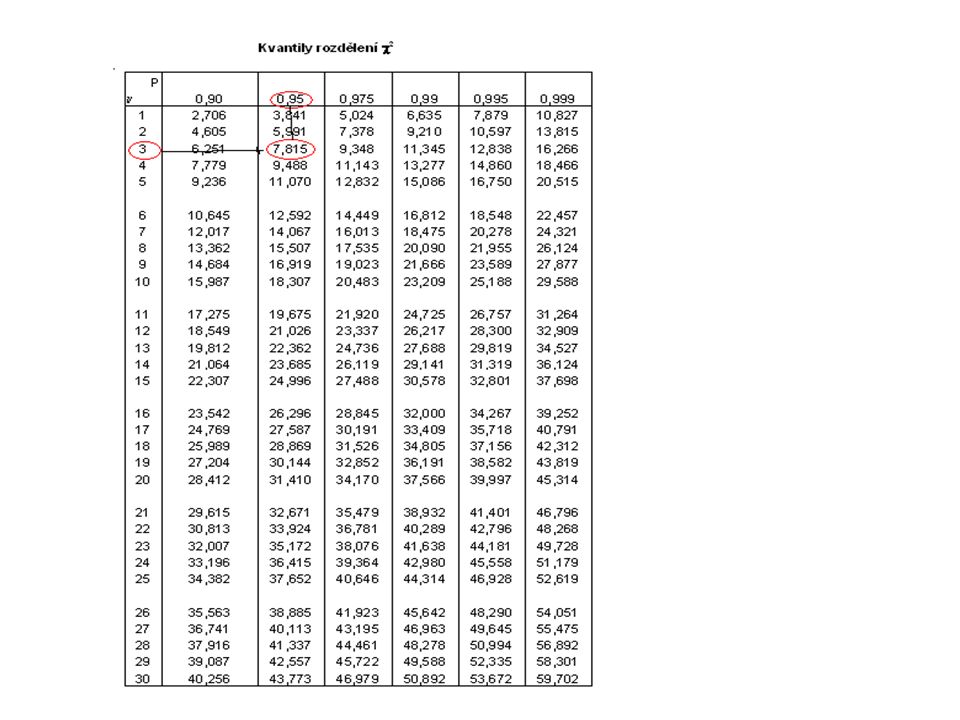
Test χ 2 dobré shody H 0 je shoda H 1 není shoda H 0 : π j = π j0 j=1………,r H 1 : non H 0 Testové kritérium n j ….empirické četnosti o j ….teoretické (očekávané) četnosti o j =n π j Kritický obor c…počet odhadovaných parametrů rozdělení
 četnosti o j =n π j Kritický obor c…počet odhadovaných parametrů rozdělení")
5
Příklad 1 Firma chce uvést na trh nový výrobek ve čtyřech různých provedeních designu a předpokládá, že zájem o jednotlivé druhy designu (označme je A,B,C,D) bude následující. Design A 35% všech zájemců o tento typ výrobku, design B 10%, design C 5% a design D 50% zájemců. Pro potvrzení svého předpokladu provedla firma průzkum, ze kterého vyplynulo, že z 300 potencionálních zájemců o tento výrobek by zájem o design A projevilo 110 zájemců, o design B 20 zájemců, o design C 10 zájemců a o design D 160 zájemců. Ověřte na 5% hladině významnosti, zda tyto zjištěné výsledky potvrzují předpoklad firmy.

6
řešení r=4 H 0 : π 1 = 0,35 H 1 : non H 0 π 2 = 0,1 π 3 = 0,05 π 4 = 0,5 n 1 =110, n 2 =20, n 3 =10, n 4 =160, n=300 o 1 =300.0,35=105, o 2 =300.0,1=30, o 3 =300.0,05=15, o 4 =300.0,5=150 Předpoklady splněny

7
řešení Testové kritérium Předpoklad firmy není v rozporu se zjištěnou strukturou zájmu o výrobek z průzkumu

9
Příklad 2 Na úřadu byl sledován počet občanů přicházejících s žádostmi v průběhu rozšířených úředních hodin pro veřejnost. Pro zjištění rovnoměrnosti využití těchto hodin pro veřejnost byly během jednoho úředního dne zjištěny tyto údaje Lze na základě těchto dat učinit závěr, že zákazníci přicházejí v průběhu dne na úřad rovnoměrně?(Otestujte na 5% hladině významnosti) doba9-1111-1313-1515-1717-19 počet3640273944
 doba počet")
10
řešení H 0 : π 1 = 0,2 H 1 : non H 0 π 2 = 0,2 π 3 = 0,2 π 4 = 0,2 π 5 = 0,2 n 1 = 36, n 2 = 40, n 3 = 27, n 4 = 39, n 5 = 44, n=186 o 1 = o 2 = o 3 = o 4 =o 5 =37,2

11
řešení zjištěná data neprokázala(na 5% hladině významnosti) nerovnoměrnost příchodu občanů na úřad v průběhu úředních hodin pro veřejnost
 nerovnoměrnost příchodu občanů na úřad v průběhu úředních hodin pro veřejnost")
12
Příklad 3 V následující tabulce je uveden počet kazů na kusu látky vždy o rozměru 1m 2. Prozkoumáno bylo celkem 20m 2. Rozhodněte, zda je možno počet kazů na 1 m 2 látky považovat za náhodnou veličinu, která se řídí Poissonovým rozdělením Počet kazů01234567 Počet kusů o velikosti 1m 2 23242241

13
Řešení Teoretické pravděpodobnosti Po(λ) nemáme informaci o parametru λ Musíme ho odhadnout EX= λ λ≈68∕20=3,4
 nemáme informaci o parametru λ Musíme ho odhadnout EX= λ λ≈68∕20=3,4")
14
Řešení Počet kazůTeoretické pravděpodobnosti Teoretické četnosti Sloučené teoretické četnosti Sloučené empirické četnosti 00,0333730,66746 10,1134692,26938 20,1928983,857966,79487 30,2186174,37234 40,1858253,71658,088846 50,1263612,52722 60,0716041,43208 70,0578531,157065,116367

15
Řešení Na 5% hladině významnosti nelze zamítnout hypotézu o tom, že data pochází z Poissonova rozdělení

16
Dodatky Spolehlivost – testu dobré shody se zvyšuje s rostoucím rozsahem výběru n. Je dobré, aby byla splněna podmínka n > 50 Další testy dobré shody Kolmogorov - Smirnovův test – Musí být plně známo teoretické rozdělení včetně parametrů je použitelný i v případech, kdy není použitelný 2 – test dobré shody (např. v případě výběru malého rozsahu, velký podíl teoretických četností menších než 5). vychází z původních jednotlivých napozorovaných hodnot a nikoliv z údajů setříděných do tříd (kategorií). používá se k ověření hypotézy, že pořízený výběr pochází z rozdělení se spojitou distribuční funkcí F(x), Davidův test normality- ověřujeme nulovou hypotézu, která říká, že náhodný výběr pochází z normálního rozdělení
. vychází z původních jednotlivých napozorovaných hodnot a nikoliv z údajů setříděných do tříd (kategorií). používá se k ověření hypotézy, že pořízený výběr pochází z rozdělení se spojitou distribuční funkcí F(x), Davidův test normality- ověřujeme nulovou hypotézu, která říká, že náhodný výběr pochází z normálního rozdělení.")
17
Dvourozměrné rozdělení četností Ve statistickém souboru zjišťujeme hodnoty dvou statistických znaků x a y. Tabulka rozdělení četností A) znaky x a y kvantitativní-korelační tabulka B) znaky x a y kvalitativní-kontingenční tabulka
 znaky x a y kvantitativní-korelační tabulka B) znaky x a y kvalitativní-kontingenční tabulka.")
18
Dvourozměrné rozdělení četností y xy1y1 y2y2 …ysys n i* x1x1 n 11 n 12 …n 1s n 1* x2x2 n 21 n 22 …n 2s n 2* ……………… xrxr n r1 n r2 …n rs n r* n *j n *1 n *2 …n *s n

19
Vlastnosti četností

20
Příklad Známky 30 žáků z písemných prací z matematiky (proměnná x) a českého jazyka (proměnná y) jsou uvedeny v následující tabulce x 223145411233122421132245122331 y 511124332223441123314333251123
 a českého jazyka (proměnná y) jsou uvedeny v následující tabulce x y")
21
Kontingenční tabulka y yxyx 1 výborně 2 chvalitebně 3 dobře 4 dostat. 5 nedost. n i* 11241-8 23212210 3321--6 4112--4 5--11-2 n *j 8794230

22
Podmíněné charakteristiky Podmíněný průměr Podmíněný druhý centrovaný moment

23
Příklad pokračování Z kontingenční tabulky z předchozího příkladu spočtěte podmíněné průměry známek z českého jazyka.

24
Elementární zjišťování závislosti Hodnoty znaku y jsou roztříděny do r tříd podle znaku x Variabilita podmíněných průměrů kolem celkového průměru je způsobena závislostí znaku y na znaku x. Variabilita znaku y uvnitř jednotlivých skupin je způsobena závislostí znaku y na jiných činitelích

25
Celkový průměr, celkový rozptyl Celkový průměr y ij …j-té pozorování v i-tém podmíněném rozdělení Celkový druhý centrovaný moment Rozptyl podmíněných průměrů(meziskupinová variabilita)
")
26
Determinační poměr Průměr podmíněných rozptylů (vnitroskupinová variabilita) Celkový rozptyl Součty čtverců, kde Determinační poměr hodnoty z Korelační nezávislost Pevná závislost
 Celkový rozptyl Součty čtverců, kde Determinační poměr hodnoty z Korelační nezávislost Pevná závislost")
27
Test χ 2 o nezávislosti dvou znaků Diskrétní znaky(veličiny) Oba znaky kvantitativní, oba kvalitativní, jeden kvantitativní jeden kvalitativní Opakování: dva jevy A,B byly nezávislé právě tehdy, když Soubor roztříděn podle dvou znaků do dvourozměrné tabulky rozdělení četností π ij pravděpodobnost, že vybraná jednotka souboru bude zařazena do třídy(kategorie) (x i, y j ) i=1,…,r, j=1,..,s π i* pravděpodobnost, že vybraná jednotka souboru bude zařazena do třídy(kategorie) x i, i=1,…,r π * j pravděpodobnost, že vybraná jednotka souboru bude zařazena do třídy(kategorie) y j j=1,..,s
 Oba znaky kvantitativní, oba kvalitativní, jeden kvantitativní jeden kvalitativní Opakování: dva jevy A,B byly nezávislé právě tehdy, když Soubor roztříděn podle dvou znaků do dvourozměrné tabulky rozdělení četností π ij pravděpodobnost, že vybraná jednotka souboru bude zařazena do třídy(kategorie) (x i, y j ) i=1,…,r, j=1,..,s π i* pravděpodobnost, že vybraná jednotka souboru bude zařazena do třídy(kategorie) x i, i=1,…,r π * j pravděpodobnost, že vybraná jednotka souboru bude zařazena do třídy(kategorie) y j j=1,..,s")
28
Test χ 2 o nezávislosti dvou znaků Nulová hypotéza- nezávislost Testové kritérium, kde Kritický obor 1-α% kvantil rozdělení o (s-1)(r-1) stupních volnosti
(r-1) stupních volnosti")
29
Příklad Bylo zkoumáno, zda život na vesnici, či v různě velkých městech ovlivňuje rozvodovost manželských párů. Pro zjištění vlivu života v různě velkých obcích na rozvodovost manželství byla provedena následující studie, ve které byly dotazovány manželské páry 5 let po prvním sňatku. Údaje z této studie jsou uvedeny v následující tabulce. Na 5% hladině významnosti ověřte zda rozvodovost manželských párů v počátcích manželství závisí na velikosti obce, ve které manželský pár žije. vesniceměstysmalé městovelké město Stále v témže manželství 4478 76 Rozvedeni nebo odloučeni 28423024

30
řešení Znak x …..stav manželství Znak y……velikost bydliště s=4, r=2 vesniceměstysmalé město velké město n i* Stále v témže manželst ví 44=n 11 78=n 12 78=n 13 76=n 14 276 Rozvede ni nebo odlouče ni 28=n 21 42=n 22 30=n 23 24=n 24 124 n *j 72120108100400 vesniceměstysmalé městovelké měston i* Stále v témže manželství 276*72/400 =o 11 276*120/400 =o 12 276*108/400 =o 13 276*100/400 =o 14 276 Rozvedeni nebo odloučeni 124*72/400 =o 21 124*120/400 =o 22 124*108/400 =o 23 124*100/400 =o 24 124 n *j 72120108100400

31
řešení t=5,81 H 0 nelze zamítnout, rozvodovost manželských párů v počátcích manželství nezávisí na velikosti obce, ve které manželský pár žije. vesniceměstysmalé městovelké město Stále v témže manželství 49,68=o 11 82,8=o 12 74,52=o 13 69 =o 14 Rozvedeni nebo odloučeni 22,32 =o 21 37,2=o 22 33,48 =o 23 31 =o 24 vesniceměstysmalé městovelké město Stále v témže manželství (44-49,68) 2 /49,68 =0,649 (78-82,8) 2 /82,8 =0,278 (78-74,52) 2 /74,52 =0,1625 (76-69 ) 2 /69 =0,71 Rozvedeni nebo odloučeni (28-22,32) 2 /22,32 =1,445 (42-37,2) 2 /37,2) = 0,619 (30-33,48) 2 /33,48 =0,3617 (24-31) 2 /31 =1,581
 2 /49,68 =0,649 (78-82,8) 2 /82,8 =0,278 (78-74,52) 2 /74,52 =0,1625 (76-69 ) 2 /69 =0,71 Rozvedeni nebo odloučeni (28-22,32) 2 /22,32 =1,445 (42-37,2) 2 /37,2) = 0,619 (30-33,48) 2 /33,48 =0,3617 (24-31) 2 /31 =1,581.")
33
ANOVA-jednofaktorová analýza rozptylu Test, kterým ověřujeme závislost diskrétní (v r kategoriích) a spojité veličiny Předpoklady: nezávislé náhodné výběry pocházejí z normálních rozdělení se středními hodnotami µ 1, µ 2..... µ r se stejným rozptylem σ 2 N(µ i,σ 2 ) Shodu rozptylů ověříme Bartlettovým testem Nulová hypotéza- nezávislost Testové kritérium kde r je počet kategorií, n rozsah výběrového souboru
 Shodu rozptylů ověříme Bartlettovým testem Nulová hypotéza- nezávislost Testové kritérium kde r je počet kategorií, n rozsah výběrového souboru.")
34
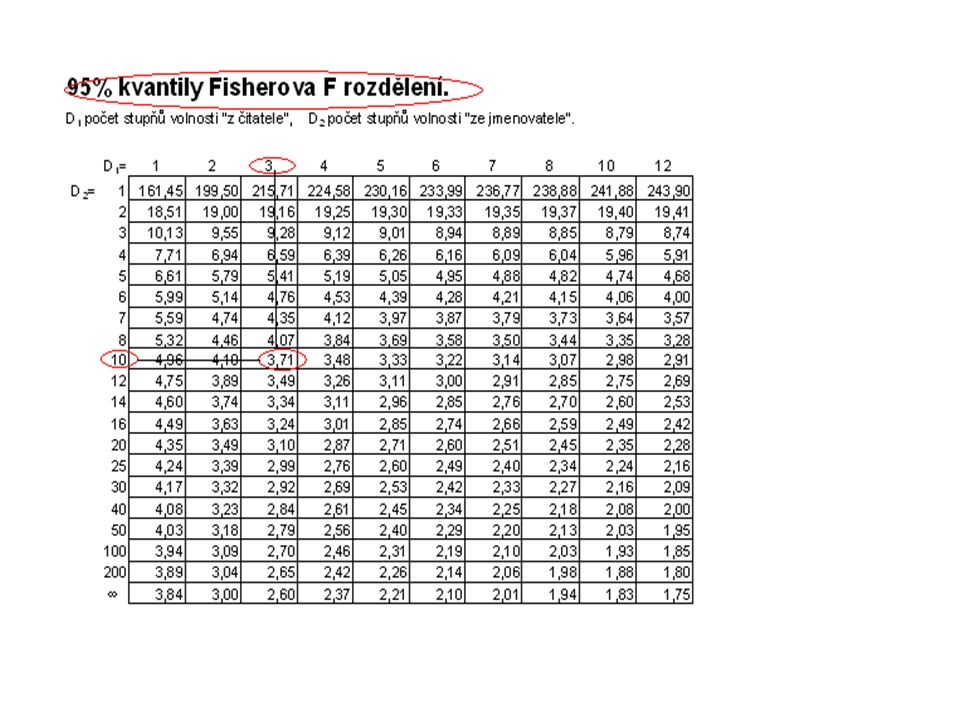
ANOVA-jednofaktorová analýza rozptylu Kritický obor 1-α% kvantil Fischerova rozdělení o (r-1) a (n-r) stupních volnosti Zdroj variability Součet čtverců Počet stupňů volnosti Průměrné čtverce Testové kritérium Faktor AQmQm r-1Q m /(r-1)t=Q m /(r-1)/ Q ν /(n-r) reziduálníQνQν n-rQ ν /(n-r) celkovýQyQy n-1
 a (n-r) stupních volnosti Zdroj variability Součet čtverců Počet stupňů volnosti Průměrné čtverce Testové kritérium Faktor AQmQm r-1Q m /(r-1)t=Q m /(r-1)/ Q ν /(n-r) reziduálníQνQν n-rQ ν /(n-r) celkovýQyQy n-1")
35
příklad Zemědělské družstvo, které se specializuje na pěstování zeleniny použilo při pěstování květáku čtyř různých směsí hnojiva a sledovalo, zda má použité hnojivo vliv na výnosnost zeleniny. (měřená ve váze jednoho květáku). Údaje jsou uvedeny v následující tabulce. Na 5% hladině významnosti rozhodněte, zda hnojící směs má vliv na výnosnost květáku. Směs hnojiva A 0,90,80,90,6- Směs hnojiva B 1,3 1,0- - Směs hnojiva C 1,11,21,0-- Směs hnojiva D 1,51,61,11,31,5
. Údaje jsou uvedeny v následující tabulce. Na 5% hladině významnosti rozhodněte, zda hnojící směs má vliv na výnosnost květáku. Směs hnojiva A 0,90,80,90,6- Směs hnojiva B 1,3 1,0- - Směs hnojiva C 1,11,21,0-- Směs hnojiva D 1,51,61,11,31,5.")
36
řešení Celkový průměr Podmíněné průměry

37
řešení Celkový součet čtverců Zdroj variabilitySoučet čtvercůPočet stupňů volnosti Průměrné čtverce Testové kritérium Faktor A0,81630,816/3=0,272t=0,272/ 0,02727=9,973 reziduální0,3110,3/11=0,02727 celkový1,11614

38
řešení t=9,973 Protože v tabulkách není uveden kvantil o těchto stupních volnosti, použijeme nejbližší o stupních volnosti 3,10 H 0 zamítáme, test prokázal, že použité hnojivo ovlivňuje výnosnost květáků.

40
Regresní analýza Metoda pro popis závislostí mezi dvěma nebo více proměnnými (mezi vysvětlovanou (závislou) proměnnou a vysvětlujícími (nezávislými) proměnnými) Slouží k odhadu hodnot vysvětlované proměnné Jednoduchá regresní analýza- pouze jedna vysvětlující proměnná Vícenásobná regresní analýza- více než jedna vysvětlovaná proměnná
 proměnnou a vysvětlujícími (nezávislými) proměnnými) Slouží k odhadu hodnot vysvětlované proměnné Jednoduchá regresní analýza- pouze jedna vysvětlující proměnná Vícenásobná regresní analýza- více než jedna vysvětlovaná proměnná")
41
Regresní model Regresní model se snaží o popis závislosti mezi proměnnými pomocí funkčního předpisu složka popisující vliv vysvětlující proměnné náhodná složka (nepopsané vlivy)-nelze ji funkčně vyjádřit
-nelze ji funkčně vyjádřit")
42
Regresní analýza Příklady (funkce lineární v parametrech) Nebo funkce nějakou transformací převoditelná na funkci lineární v parametrech
 Nebo funkce nějakou transformací převoditelná na funkci lineární v parametrech")
43
Jak vybrat mezi např. lineárními funkcemi tu nejlepší? A která je ta nejlepší? K dispozici máme pouze výběrový soubor Najdeme pouze odhady parametrů Budu vybírat tak, aby se body ležící na přímce od naměřené hodnoty lišily co nejméně. Nejméně ve smyslu čtverců.

44
Metoda nejmenších čtverců [x,y] dvojice náhodných veličin [1,2],[2,4],[3,5] nalezněte přímku, která nejlépe popisuje závislost proměnné y na proměnné x
![Metoda nejmenších čtverců [x,y] dvojice náhodných veličin [1,2],[2,4],[3,5] nalezněte přímku, která nejlépe popisuje závislost proměnné y na proměnné x](http://images.slideplayer.cz/42/11524500/slides/slide_44.jpg "Metoda nejmenších čtverců [x,y] dvojice náhodných veličin [1,2],[2,4],[3,5] nalezněte přímku, která nejlépe popisuje závislost proměnné y na proměnné x")
45
Soustava normálních rovnic Jak se hledá minimum funkce ? Pomocí derivací Dostaneme soustavu normálních rovnic Jejím řešením je

46
Příklad Marketingové oddělení jisté firmy zkoumalo vztah mezi objemem výroby (v tis. kusech) a celkovými náklady (v mil Kč). V deseti vybraných provozech byly zjištěny následující údaje Popište závislost celkových nákladů na objemu výroby lineární funkcí Interpretujte regresní koeficient b 1 Interpretujte regresní koeficient b 0 Odhadněte, jaké celkové náklady může firma očekávat v provozu, který plánuje vyrobit 7 tis. Ks výrobků Objem výroby 24821064 68 Celkové náklady 15202517302221352530
 a celkovými náklady (v mil Kč). V deseti vybraných provozech byly zjištěny následující údaje Popište závislost celkových nákladů na objemu výroby lineární funkcí Interpretujte regresní koeficient b 1 Interpretujte regresní koeficient b 0 Odhadněte, jaké celkové náklady může firma očekávat v provozu, který plánuje vyrobit 7 tis. Ks výrobků Objem výroby Celkové náklady")
47
řešení nejprve musíme vypočítat průměry a druhý centrovaný moment Regresní koeficient udává náklady (12 mil. Kč), kdyby se nevyrábělo – fixní náklady Regresní koeficient udává, o kolik (2 mil. Kč) se zvednou náklady, když se objem výroby zvedne o jednu jednotku(tis. ks) celkové náklady, které může firma očekávat v provozu, který plánuje vyrobit 7 tis. Ks výrobků, jsou
, kdyby se nevyrábělo – fixní náklady Regresní koeficient udává, o kolik (2 mil. Kč) se zvednou náklady, když se objem výroby zvedne o jednu jednotku(tis. ks) celkové náklady, které může firma očekávat v provozu, který plánuje vyrobit 7 tis. Ks výrobků, jsou.")
Podobné prezentace













 R je předpis, který každému číslu z množiny D(f) přiřazuje právě jedno reálné číslo. Jinak: Nechť A, B jsou neprázdné.>")

.>")



