Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

2
Statistické metody v digitálním zpracování obrazu Jindřich Soukup 3. února 2012

3
Osnova ● Úvod ● (Neparametrické) odhady hustoty pravděpodobnosti ● Bootstrap ● Použití logistické regresi při klasifikaci
 odhady hustoty pravděpodobnosti ● Bootstrap ● Použití logistické regresi při klasifikaci")
4
Odhady hustoty pravděpodobnosti - motivace ● Zhodnotit pravidelnost daných struktur ● Rozdělení vzdáleností d-tých nejbližších sousedů ● Radiální distribuční funkce

5
Odhady hustoty pravděpodobnosti - motivace ● Naměřené hodnoty beru jako realizace náhodného jevu ● Histogramy jsou pouze odhady hustoty pravděpodobnosti tohoto jevu

6
Odhady hustoty pravděpodobnosti - rozdělení ● x i - naměřené hodnoty, ρ - hustota pravděpodobnosti ● Histogram, frekvenční polynom, jádrové odhady ● θ - vektor parametrů ● Bayes, MLE

7
Histogram - po částech konstantní odhad hustoty pravděpodobnosti ● k - počet binů, h - šířka binu ● k = ceiling( (max(x)-min(x)) / h ) ● k, resp. h jsou klíčové

8
Histogram - šířka binu ● Sturgesovo pravidlo (1926) - to odpovídá ● ! nepoužívat pro větší soubory dat !

9
Histogram - šířka binu ● Sturgesovo pravidlo (1926) - to odpovídá ● ! nepoužívat pro větší soubory dat ! ● Scott (1979) - optimální ve smyslu minimalizace MSE
 - optimální ve smyslu minimalizace MSE.")
10
Histogram - šířka binu ● Sturgesovo pravidlo (1926) - to odpovídá ● ! nepoužívat pro větší soubory dat ! ● Scott (1979) - optimální ve smyslu minimalizace MSE ● Odhady R(ρ') - ● (Scott 1979, Friedman a Diaconis 1981)
 - optimální ve smyslu minimalizace MSE ● Odhady R(ρ ) - ● (Scott 1979, Friedman a Diaconis 1981).")
11
Řád konvergence, citlivost ● Odhady založené na Scottově vzorci mají řád konvergence N -2/3 (pro porovnání MLE má N -1 ).
.")
12
Řád konvergence, citlivost ● Odhady založené na Scottově vzorci mají řád konvergence N -2/3 (pro porovnání MLE má N -1 ). ● Citlivost

13
Řád konvergence, citlivost ● Odhady založené na Scottově vzorci mají řád konvergence N -2/3 (pro porovnání MLE má N -1 ). ● Citlivost

14
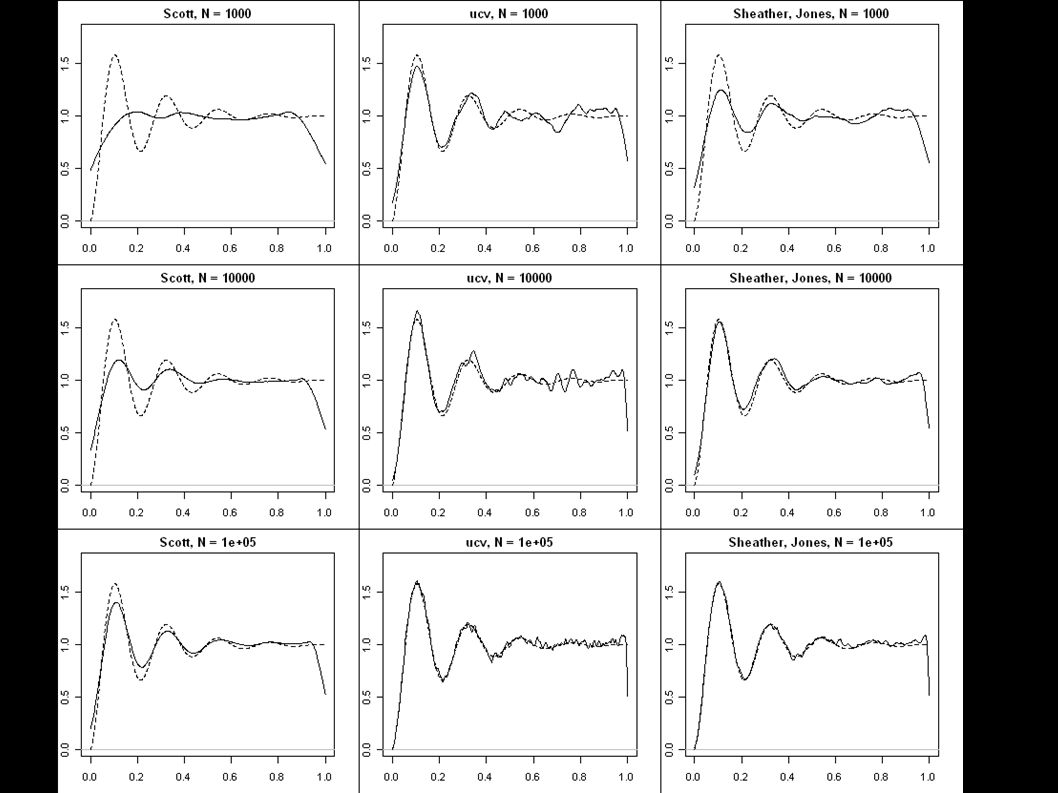
Porovnání pravidel

15
Literatura

16
Kernel density estimation ● Jádrové odhady, Parzenovo okénko... ● Klouzavý vážený průměr

17
Tvar jádra, šířka jádra, citlivost ● Optimální šířka jádra (Scott - kniha) ● Optimální je tzv. Epanechnikovo jádro ● Vyšší citlivost na nesprávně zvolenou šířku

19
Shrnutí ● Histogram je vhodný pro prvotní náhled ● Pokud je to možné použijeme parametrické metody (vyšší řád konvergence) ● Pro velké soubory dat (řádově >10 4 ) použít raději jádrové odhady ● Šířky binů/jádra ovlivní přesnost - záleží na nich ● Problémy ve více dimenzích
 ● Pro velké soubory dat (řádově >10 4 ) použít raději jádrové odhady ● Šířky binů/jádra ovlivní přesnost - záleží na nich ● Problémy ve více dimenzích")
20
Software Matlab ● Histogram (fce hist) - není implementováno žádné pravidlo pro počet binů ● Jádrové odhady (ksdensity) - pravidla pro šířku jádra - pouze to nejjednodušší ● R - všechny zmiňovaná pravidla: hist(x,breaks="volba_pravidla"), resp. plot(density(x,kernel="tvar_jádra", breaks="volby_pravidla"))
).")
21
Další využití ● Klasifikace ● Statistické zpracování výsledků ● Segmentace...

23
Časosběrné snímky ● Pro každý pixel směrodatná odchylka okolí pixelu, průměrováno přes čas (či obráceně) ● Rozdělení hodnot - superpozice dvou gausovek
 ● Rozdělení hodnot - superpozice dvou gausovek")
24
Časosběrné snímky ● Pro každý pixel směrodatná odchylka okolí pixelu, průměrováno přes čas (či obráceně) ● Rozdělení hodnot - superpozice dvou gausovek
 ● Rozdělení hodnot - superpozice dvou gausovek")
25
Výsledky ● Matlab - statistický toolbox "Gaussian mixture" ● Viditelné jpg artefakty ● Úspěšnost srovnatelná s nejlepší volbou prahu

26
Intermezzo ● Strategie vědeckého poznání, filozofie vědy ● Jak psát články, pracovat se zdroji, komunikovat s recenzenty

27
Bootstrap ● Simulační statistická metoda ● Efron (1979) - první článek ● Jak recyklovat data tak, abych je mohl považovat za data nová (nezávislá na původních) ● Vhodné, pokud je získání dalších dat příliš drahé, náročné či nemožné
 - první článek ● Jak recyklovat data tak, abych je mohl považovat za data nová (nezávislá na původních) ● Vhodné, pokud je získání dalších dat příliš drahé, náročné či nemožné")
28
Princip ● Na základě dat {x i } chci získat rozdělení statistiky s

29
Princip ● Na základě dat {x i } chci získat rozdělení statistiky s ● Provedu náhodný výběr s vracením z {x i } a spočtu statistiku na těchto datech

30
Princip ● Na základě dat {x i } chci získat rozdělení statistiky s ● Provedu náhodný výběr s vracením z {x i } a spočtu statistiku na těchto datech ● Opakuji dostatečně-krát

31
Příklad ● Statistický výzkum mezi lidmi (známky ve škole)
")
32
Příklad ● Statistický výzkum mezi lidmi (známky ve škole) ● Zpracování pomocí metody hlavních komponent
 ● Zpracování pomocí metody hlavních komponent")
33
Příklad ● Statistický výzkum mezi lidmi (známky ve škole) ● Zpracování pomocí metody hlavních komponent ● Získám výsledky - jaká je ale jejich přesnost?
 ● Zpracování pomocí metody hlavních komponent ● Získám výsledky - jaká je ale jejich přesnost")
34
Příklad ● Statistický výzkum mezi lidmi (známky ve škole) ● Zpracování pomocí metody hlavních komponent ● Získám výsledky - jaká je ale jejich přesnost? ● Vytvořím si z původního souboru dat několik bootstrapový výběrů a na nich znova provedu analýzu hlavních komponent

35
Příklad ● Statistický výzkum mezi lidmi (známky ve škole) ● Zpracování pomocí metody hlavních komponent ● Získám výsledky - jaká je ale jejich přesnost? ● Vytvořím si z původního souboru dat několik bootstrapový výběrů a na nich znova provedu analýzu hlavních komponent ● Z rozdělení bootstrapových odhadů spočítám směrodatnou odchylku pro vlastní čísla a vektory (a cokoli dalšího, co mě zajímá)
.")
36
Kolikrát opakovat? ● Podle toho, co chci získat

37
Kolikrát opakovat? ● Podle toho, co chci získat ● Pokud chci odhadovat momenty rozdělení (směrodatná odchylka, šikmost,...), stačí 200- 600 opakování (podle některých zdrojů jen 50- 200)
, stačí opakování (podle některých zdrojů jen ).")
38
Kolikrát opakovat? ● Podle toho, co chci získat ● Pokud chci odhadovat momenty rozdělení (směrodatná odchylka, šikmost,...), stačí 200- 600 opakování (podle některých zdrojů jen 50- 200) ● Pokud chci získat distribuční funkci dané statistiky (např. abych pak z ní získal konfidenční interval), potřebuju řádově 1000 a více opakování
, stačí opakování (podle některých zdrojů jen ) ● Pokud chci získat distribuční funkci dané statistiky (např. abych pak z ní získal konfidenční interval), potřebuju řádově 1000 a více opakování.")
39
Kolikrát opakovat? ● Podle toho, co chci získat ● Pokud chci odhadovat momenty rozdělení (směrodatná odchylka, šikmost,...), stačí 200- 600 opakování (podle některých zdrojů jen 50- 200) ● Pokud chci získat distribuční funkci dané statistiky (např. abych pak z ní získal konfidenční interval), potřebuju řádově 1000 a více opakování ● Existují metody, jak snížit počet opakování
, stačí opakování (podle některých zdrojů jen ) ● Pokud chci získat distribuční funkci dané statistiky (např. abych pak z ní získal konfidenční interval), potřebuju řádově 1000 a více opakování ● Existují metody, jak snížit počet opakování.")
40
Kde nepoužívat? ● Když vím, že odhadovaná statistika je divoká ● Není vhodné pro odhady extrémů ● Pokud jsou data v původním souboru navzájem závislá, musíme modifikovat ● Můžeme používat i pokud máme odlehlé hodnoty, výsledky na to nejsou příliš citlivé

41
Literatura ● Efron, Tibshirani - An introduction to bootstrap ● Prášková (ROBUST 2004) - Metoda bootstrap ● Davison, Hinkley - Bootstrap Methods and Their Application
 - Metoda bootstrap ● Davison, Hinkley - Bootstrap Methods and Their Application")
42
Intermezzo ● Kurz: Úvod do programování v Matlabu ● Doktorandští studenti numeriky ● www.papez.org/matlab ● 13. - 17. února od 9 do 13h ● přihlásit se do 5. února

43
Regrese vs. klasifikace - shrnutí ● Je možné provádět klasifikaci pomocí logistické regrese - model pro učení ● Získáme pravděpodobnosti

44
Logistická regrese ● Není to matematicky ekvivalentní se SVM - minimalizujeme různé veličiny ● Výsledky můžou být srovnatelně dobré

45
Transformace souřadnic ● U regrese jsou užitečné triky, které se dají použít v klasifikaci - transformace souřadnic

46
Data z tunelovacího mikroskopu ● Poissonovský proces - velikost šumu závisí na intezitě signálu ● Škálujeme pomocí log

47
Děkuji za pozornost Diskuze

Podobné prezentace
















>")
 6. předn.1 chování výběrového průměru nechť X 1, X 2,…,X n jsou nezávislé náhodné veličiny s libovolným rozdělením.>")



