Analýza kvantitativních dat: 1. úvod do SPSS Jiří Šafr jiri.safr(zavináč)seznam.cz vytvořeno , poslední aktualizace UK FHS Historická sociologie a Řízení a supervize (LS 2011)
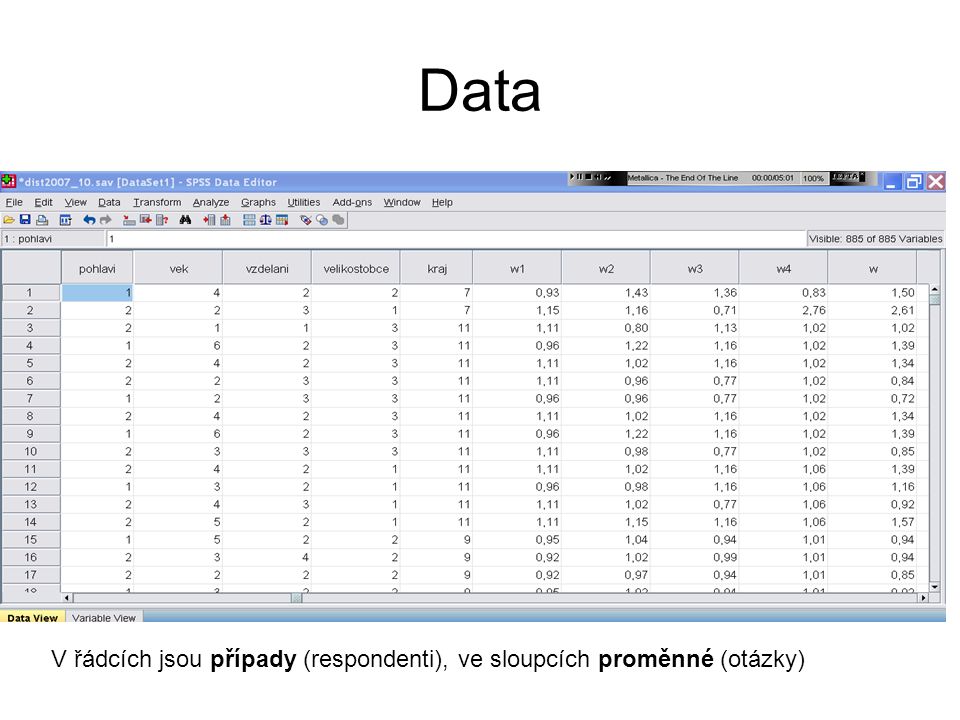
Data V řádcích jsou případy (respondenti), ve sloupcích proměnné (otázky)
Správa proměnných
Output
Úprava dat
Analýza
Syntax
Vkládání dat
Transformace dat → Transform Výpočet ► vytváření nových (umělých) znaků → Compute Rekódování → Recode (do stejné do nové promenné) Visual Binding – nástroj pro snadné rokódování (dle percentilů apod.)
Úpravy dat a výstupů → Data Uspořádání případů → Sort Cases Rozdělení na podsoubory → Split File Výběr případů (filtrování) → Select Cases Vážení → Weight Cases
Analýzy → Analyze Descriptive statistics Tables Compare means Correlate Data Reduction Nonparametric Tests Missing Value Analysis Multiple Response
Grafy → Graphs
Načtení dat ze syntaxu *data -hodnoty proměnných jsou oddělena mezerou. DATA LIST LIST / okres (A15) polit duch vek obyv. BEGIN DATA. "Benešov" "Kladno" "M. Boleslav" "Příbram" "Dobříš" END DATA. *Labely. VAR LAB polit "Program pro seniory" VAR LAB duch "Domovy důchodců - počet" VAR LAB vek "Průměrný věk". VAR LAB obyv "Počet obyvatel". VAL LAB polit 0 "Ne" 1 "Ano". *formát čísel. FORMATS polit duch vek obyv (f8).
Načtení dat z agregované existující kontingenční tabulky ****nacteni kontingencni tabulky aneb sekundarni analyza dat. data list list/Age Religion Vote freq. val lab religion 1 "ne" 2 "ano" / Age 1"1" 2"2" / Vote 1"ne" 2 "ano". begin data end data. wei by freq. cro religion by vote.
Nastavení SPSS
Nastavení labelů při zobrazování tabulek v outputu SET TNumbers=Both ONumbers=Both CCC='-,,,' CCE='-,,,' CCB='-,,,' OVars=Both CCD='-,,,' TVars=Both CCA='-,,,'. NEW FILE.
Nastavení labelů při zobrazování tabulek v outputu Bez názvu proměnné a hodnot kategorií → lze pro finální prezentaci v textu S názvem proměnné a hodnotami kategoriemi → vhodnější pro analýzy