Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Paralelní a distribuované MAM Jakub Lokoč

2
Osnova Úvod do problematiky Paralelní MAM M-Tree M-Tree Distribuované MAM GHT* GHT* VPT* VPT* MCAN MCAN M-Chord M-Chord

3
Úvod do problematiky U centralizovaných indexů je silná korelace mezi velikostí DB a náklady na vyhodnocení podobnostních dotazů (lineární závislost, limituje škálovatelnost) Objem indexovatelných MM dat roste exponenciálně (jen 1% dat na Internetu jsou texty) Vývoj HW narazil na fyzikální hranice, trendem je paralelizace (více jader v CPU atp.) Řešením je vývoj efektivnějších indexačních struktur, nebo využití více zdrojů (CPU, HDD, …) při řešení dotazů stávajícími metodami
 Objem indexovatelných MM dat roste exponenciálně (jen 1% dat na Internetu jsou texty) Vývoj HW narazil na fyzikální hranice, trendem je paralelizace (více jader v CPU atp.) Řešením je vývoj efektivnějších indexačních struktur, nebo využití více zdrojů (CPU, HDD, …) při řešení dotazů stávajícími metodami")
4
Zákony paralelizace Ne vždy lze paralelizací vylepšit stávající algoritmus navržený původně pro sekvenční zpracování – Amdahl's law Algoritmus se skládá z částí, které nelze paralelizovat – nelze urychlit Algoritmus se skládá z částí, které nelze paralelizovat – nelze urychlit Zvyšováním počtu výpočetních jednotek se urychluje jen část algoritmu Zvyšováním počtu výpočetních jednotek se urychluje jen část algoritmu Vztahuje se ke konstantnímu problému – výsledný čas se přidáváním zdrojů blíží limitně k času sériově zpracovávané části (100;100), (100;50-50), (100;25-25-25- 25), …, (100; 1-1-1-1…) Vztahuje se ke konstantnímu problému – výsledný čas se přidáváním zdrojů blíží limitně k času sériově zpracovávané části (100;100), (100;50-50), (100;25-25-25- 25), …, (100; 1-1-1-1…) Každý dostatečně velký problém se dá paralelizovat - Gustafson's law Zvětšováním problému (paralelní části) se dá dosáhnout stejného času při využití více zdrojů Zvětšováním problému (paralelní části) se dá dosáhnout stejného času při využití více zdrojů Důležitý faktor pro návrh škálovatelných systémů Důležitý faktor pro návrh škálovatelných systémů S rostoucí velikostí problému se snižuje význam času sériově zpracovávané části (100;100), (100;100-100), (100;100-100-100-100), … S rostoucí velikostí problému se snižuje význam času sériově zpracovávané části (100;100), (100;100-100), (100;100-100-100-100), …
, (100;50-50), (100; ), …, (100; …) Vztahuje se ke konstantnímu problému – výsledný čas se přidáváním zdrojů blíží limitně k času sériově zpracovávané části (100;100), (100;50-50), (100; ), …, (100; …) Každý dostatečně velký problém se dá paralelizovat - Gustafson s law Zvětšováním problému (paralelní části) se dá dosáhnout stejného času při využití více zdrojů Zvětšováním problému (paralelní části) se dá dosáhnout stejného času při využití více zdrojů Důležitý faktor pro návrh škálovatelných systémů Důležitý faktor pro návrh škálovatelných systémů S rostoucí velikostí problému se snižuje význam času sériově zpracovávané části (100;100), (100; ), (100; ), … S rostoucí velikostí problému se snižuje význam času sériově zpracovávané části (100;100), (100; ), (100; ), …")
5
Efektivita paralelizace Speed-up = ST / BT (small/big system time) Lineární, pokud n x věší systém je n x rychlejší (pro stejnou úlohu) Lineární, pokud n x věší systém je n x rychlejší (pro stejnou úlohu) Scale-up = STSP / BTBP (small/big system time small/big problem) Lineární, pokud se rovná/blíží 1 Lineární, pokud se rovná/blíží 1
 Lineární, pokud n x věší systém je n x rychlejší (pro stejnou úlohu) Lineární, pokud n x věší systém je n x rychlejší (pro stejnou úlohu) Scale-up = STSP / BTBP (small/big system time small/big problem) Lineární, pokud se rovná/blíží 1 Lineární, pokud se rovná/blíží 1")
6
Paralelní MAM Paralelní zařízení Skládá se z několika procesorů a disků Skládá se z několika procesorů a disků Sdílí paměť a komunikační kanály Sdílí paměť a komunikační kanály Paralelní index – požadavky Data (DB objekty) jsou sdílena všemi procesory, tzn. každý CPU může v každém okamžiku číst/měnit libovolná data (s výjimkou vzájemného vyloučení při vstupu do kritické sekce) Data (DB objekty) jsou sdílena všemi procesory, tzn. každý CPU může v každém okamžiku číst/měnit libovolná data (s výjimkou vzájemného vyloučení při vstupu do kritické sekce) Lze spustit součastně více operací na různých CPU Lze spustit součastně více operací na různých CPU Data jsou paralelně ukládána na více disků Data jsou paralelně ukládána na více disků
 Data (DB objekty) jsou sdílena všemi procesory, tzn. každý CPU může v každém okamžiku číst/měnit libovolná data (s výjimkou vzájemného vyloučení při vstupu do kritické sekce) Lze spustit součastně více operací na různých CPU Lze spustit součastně více operací na různých CPU Data jsou paralelně ukládána na více disků Data jsou paralelně ukládána na více disků.")
7
Paralelní M-Tree Základní typy paralelismu CPU paralelismus CPU paralelismus I/O paralelismus I/O paralelismus Limitující faktory pro zpracování dotazu Stromová struktura – nelze zpracovat objekty v potomkovi, pokud nebyl zpracován příslušný objekt v rodičovském uzlu Stromová struktura – nelze zpracovat objekty v potomkovi, pokud nebyl zpracován příslušný objekt v rodičovském uzlu Sériové odebírání požadavků z fronty (PQ) u kNN dotazů Sériové odebírání požadavků z fronty (PQ) u kNN dotazů
 u kNN dotazů Sériové odebírání požadavků z fronty (PQ) u kNN dotazů")
8
CPU paralelizace Dotazování Pořadí zpracování uzlů je dáno dynamicky budovanou frontou Pořadí zpracování uzlů je dáno dynamicky budovanou frontou Z koordinačních důvodů je zpracovávána dedikovaným procesorem Z koordinačních důvodů je zpracovávána dedikovaným procesorem Zbylé procesory se používají pouze pro paralelizaci výpočtů vzdáleností k jednotlivým směrovacím/listovým záznamům v aktuálně zpracovávaném uzlu Zbylé procesory se používají pouze pro paralelizaci výpočtů vzdáleností k jednotlivým směrovacím/listovým záznamům v aktuálně zpracovávaném uzlu Tvorba stromu – štěpení uzlu Omezení CPU paralelizace Počet klíčů v uzlu Počet klíčů v uzlu Sériové odebírání prvků z PQ Sériové odebírání prvků z PQ

9
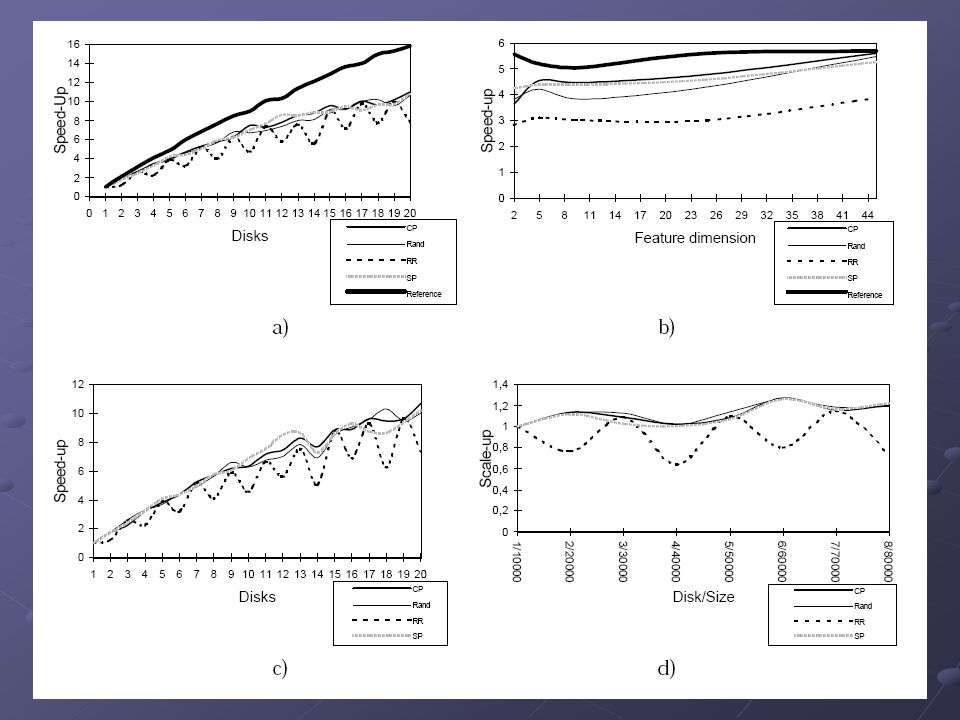
I/O paralelizace Načítání uzlů do paměti – v jednom výpočetním kroku se snaží načíst co nejvíce uzlů z různých disků do pomocné struktury TEMP Míra paralelizace načítání během zpracování dotazu závisí na metodě/strategii ukládání uzlů na disk (tzn. jejich rozložení) Globální alokace Globální alokace Random (náhodně rozděluje) Round-robin (rovnoměrné rozložení uzlů) Proximity-based alokace (bere v potaz rozložení okolních regionů) Proximity-based alokace (bere v potaz rozložení okolních regionů) Simple-proximity – součet poloměrů mínus vzdálenost Complex-proximity – pravděpodobnost, že dotaz protne oba regiony K určení disku dochází po štěpení uzlu U kNN dotazu nemusí vadit, že byl upřednostněn jiný uzel z důvodu zajištění paralelizace I/O Filtrování uzlů probíhá i v TEMP
 Globální alokace Globální alokace Random (náhodně rozděluje) Round-robin (rovnoměrné rozložení uzlů) Proximity-based alokace (bere v potaz rozložení okolních regionů) Proximity-based alokace (bere v potaz rozložení okolních regionů) Simple-proximity – součet poloměrů mínus vzdálenost Complex-proximity – pravděpodobnost, že dotaz protne oba regiony K určení disku dochází po štěpení uzlu U kNN dotazu nemusí vadit, že byl upřednostněn jiný uzel z důvodu zajištění paralelizace I/O Filtrování uzlů probíhá i v TEMP.")
11
I/O paralelizace – vylepšení ? Mezi jednotlivé disky se rozdělují záznamy v listu (a ne uzly) Listový uzel obsahuje pouze adresy objektů na jednotlivých HDD Objekty jsou distribuovány mezi disky vzhledem ke globálnímu rozdělení objektů Vložení objektu Po nalezení listového uzlu se položí rozsahový dotaz (poloměr je vzdálenost k pivotu listového uzlu a střed je nový objekt) Po nalezení listového uzlu se položí rozsahový dotaz (poloměr je vzdálenost k pivotu listového uzlu a střed je nový objekt) Z vrácených odpovědí se zjistí nejméně frekventovaný disk, na který se uloží nově vkládaný objekt Z vrácených odpovědí se zjistí nejméně frekventovaný disk, na který se uloží nově vkládaný objekt Vede k téměř optimálnímu rozdělení objektů mezi HDD Vliv na rychlost dotazů nebyl v článku uveden
 Listový uzel obsahuje pouze adresy objektů na jednotlivých HDD Objekty jsou distribuovány mezi disky vzhledem ke globálnímu rozdělení objektů Vložení objektu Po nalezení listového uzlu se položí rozsahový dotaz (poloměr je vzdálenost k pivotu listového uzlu a střed je nový objekt) Po nalezení listového uzlu se položí rozsahový dotaz (poloměr je vzdálenost k pivotu listového uzlu a střed je nový objekt) Z vrácených odpovědí se zjistí nejméně frekventovaný disk, na který se uloží nově vkládaný objekt Z vrácených odpovědí se zjistí nejméně frekventovaný disk, na který se uloží nově vkládaný objekt Vede k téměř optimálnímu rozdělení objektů mezi HDD Vliv na rychlost dotazů nebyl v článku uveden.")
12
Distribuované MAM Distribuované prostředí (DP) Počítače (uzly) propojené vysokorychlostní sítí – využívají vzájemně výpočetní sílu svých CPU a svá datová úložiště Počítače (uzly) propojené vysokorychlostní sítí – využívají vzájemně výpočetní sílu svých CPU a svá datová úložiště Každý počítač má vlastní pamět (volně vázané systémy) Každý počítač má vlastní pamět (volně vázané systémy) Je zapotřebí infrastruktura pro alokaci a zpracování objektů v DP Je zapotřebí infrastruktura pro alokaci a zpracování objektů v DP Zajištění základních operací je realizováno zasíláním požadavků mezi uzly pomocí směrovacích mechanismů Zajištění základních operací je realizováno zasíláním požadavků mezi uzly pomocí směrovacích mechanismů Není omezena škálovatelnost jako u paralelního zpracování Není omezena škálovatelnost jako u paralelního zpracování Síť několika počítačů je levnější než jeden superpočítač Síť několika počítačů je levnější než jeden superpočítač Základní paradigmata distribuovaných indexů SDDS (scalable and distributed data structures) SDDS (scalable and distributed data structures) P2P P2P
 Počítače (uzly) propojené vysokorychlostní sítí – využívají vzájemně výpočetní sílu svých CPU a svá datová úložiště Počítače (uzly) propojené vysokorychlostní sítí – využívají vzájemně výpočetní sílu svých CPU a svá datová úložiště Každý počítač má vlastní pamět (volně vázané systémy) Každý počítač má vlastní pamět (volně vázané systémy) Je zapotřebí infrastruktura pro alokaci a zpracování objektů v DP Je zapotřebí infrastruktura pro alokaci a zpracování objektů v DP Zajištění základních operací je realizováno zasíláním požadavků mezi uzly pomocí směrovacích mechanismů Zajištění základních operací je realizováno zasíláním požadavků mezi uzly pomocí směrovacích mechanismů Není omezena škálovatelnost jako u paralelního zpracování Není omezena škálovatelnost jako u paralelního zpracování Síť několika počítačů je levnější než jeden superpočítač Síť několika počítačů je levnější než jeden superpočítač Základní paradigmata distribuovaných indexů SDDS (scalable and distributed data structures) SDDS (scalable and distributed data structures) P2P P2P")
13
Požadavky na SDDS a P2P SDDS (servery obsahují data a klienti provádí operace) Scalability – efektivní migrace dat na nové uzly (jen pokud jsou stávající dostatečně zaplněné) Scalability – efektivní migrace dat na nové uzly (jen pokud jsou stávající dostatečně zaplněné) No hotspot – bez centralizovaného adresáře s adresami objektů No hotspot – bez centralizovaného adresáře s adresami objektů Independence – operace nevyžadují atomické změny více uzlů Independence – operace nevyžadují atomické změny více uzlůP2P Peer – každý uzel struktury se chová jako klient i jako server, tzn. může zasílat dotazy a součastně ukládat data Peer – každý uzel struktury se chová jako klient i jako server, tzn. může zasílat dotazy a součastně ukládat data Fault tolerance – pokud uzel vypadne, tak se dají zpracovávat všechny operace dál, jen dočasně neuvidí na všechna data Fault tolerance – pokud uzel vypadne, tak se dají zpracovávat všechny operace dál, jen dočasně neuvidí na všechna data Redundancy – replikace dat za účelem zvýšení dostupnosti, využíváno algoritmy pro vyhledávání Redundancy – replikace dat za účelem zvýšení dostupnosti, využíváno algoritmy pro vyhledávání

14
GHT*, VPT* Založený na GHT (VPT), využívá P2P paradigma Splňuje základní vlastnosti SDDS a P2P přístupů Scalability – každý uzel (peer) se může kdykoliv nezávisle rozštěpit a distribuovat data na jiné uzly Scalability – každý uzel (peer) se může kdykoliv nezávisle rozštěpit a distribuovat data na jiné uzly No hotspot – každý peer udržuje vlastní adresní schéma, aktualizace probíhá pouze lokálně (štěpení nezahlcuje síť) No hotspot – každý peer udržuje vlastní adresní schéma, aktualizace probíhá pouze lokálně (štěpení nezahlcuje síť) Peer – každý uzel může ukládat data a součastně klást dotazy Peer – každý uzel může ukládat data a součastně klást dotazyArchitektura Každý uzel (peer) obsahuje úložiště pro data tzv. „kapsu“ (bucket) – počet a kapacita závisí na možnostech uzlu (nemusí mít vůbec). Každý uzel (peer) obsahuje úložiště pro data tzv. „kapsu“ (bucket) – počet a kapacita závisí na možnostech uzlu (nemusí mít vůbec). Po zaplnění kapsy dojde k jejímu štěpení, nová kapsa může být umístěna na jiný uzel. Je možné i slučovat kapsy. Po zaplnění kapsy dojde k jejímu štěpení, nová kapsa může být umístěna na jiný uzel. Je možné i slučovat kapsy. Základní struktura pro lokalizaci objektů je AST (address search tree), uložená v každém uzlu tzn. vyhodnocování adres je lokální záležitost Základní struktura pro lokalizaci objektů je AST (address search tree), uložená v každém uzlu tzn. vyhodnocování adres je lokální záležitost AST se automaticky aktualizuje v průběhu vyhodnocování dotazů AST se automaticky aktualizuje v průběhu vyhodnocování dotazů
 – počet a kapacita závisí na možnostech uzlu (nemusí mít vůbec). Každý uzel (peer) obsahuje úložiště pro data tzv. „kapsu (bucket) – počet a kapacita závisí na možnostech uzlu (nemusí mít vůbec). Po zaplnění kapsy dojde k jejímu štěpení, nová kapsa může být umístěna na jiný uzel. Je možné i slučovat kapsy. Po zaplnění kapsy dojde k jejímu štěpení, nová kapsa může být umístěna na jiný uzel. Je možné i slučovat kapsy. Základní struktura pro lokalizaci objektů je AST (address search tree), uložená v každém uzlu tzn. vyhodnocování adres je lokální záležitost Základní struktura pro lokalizaci objektů je AST (address search tree), uložená v každém uzlu tzn. vyhodnocování adres je lokální záležitost AST se automaticky aktualizuje v průběhu vyhodnocování dotazů AST se automaticky aktualizuje v průběhu vyhodnocování dotazů.")
15
AST – address search tree Vychází z GHT (VPT) Vnitřní uzly obsahují 2 směrovací objekty Každý list reprezentuje buď ukazatel na lokální úložiště tzv. kapsu (pomocí BID) nebo na jiný uzel sítě (pomocí NNID), kde se data nachází. Pro zjištění nekonzistence mezi AST na různých uzlech sítě je u každého vnitřního uzlu jeho sériové číslo, které se mění při změně části stromu. Změny v AST jsou vyvolány štěpením nebo sléváním kapes. Problém s lineární závislostí replikovaných pivotů – logaritmická replikace – stromy obsahují jen nezbytné pivoty – větve vedoucí jen na NNID se zkrátí
 nebo na jiný uzel sítě (pomocí NNID), kde se data nachází. Pro zjištění nekonzistence mezi AST na různých uzlech sítě je u každého vnitřního uzlu jeho sériové číslo, které se mění při změně části stromu. Změny v AST jsou vyvolány štěpením nebo sléváním kapes. Problém s lineární závislostí replikovaných pivotů – logaritmická replikace – stromy obsahují jen nezbytné pivoty – větve vedoucí jen na NNID se zkrátí.")
16
Štěpení kapsy Alokace nové kapsy – pokud možno na stejném uzlu Výberou se dva noví pivoti Výpočetně náročné Výpočetně náročné Inkrementální výběr pivotů – hypotéza, že GHT je lepší pro vzdálené pivoty Inkrementální výběr pivotů – hypotéza, že GHT je lepší pro vzdálené pivoty První dva objekty jsou kandidáti, každý nový objekt se porovná jen s kandidáty První dva objekty jsou kandidáti, každý nový objekt se porovná jen s kandidáty Přesun vybraných objektů do nové kapsy

17
Vkládání a změny v GHT* Traverzuje AST v aktuálním uzlu Pokud nalezne BID, tak vloží (může se štěpit) Pro NNID přeposílá požadavek příslušnému uzlu v síti Aby se zabránilo redundantním výpočtům vzdáleností, tak se zašle i BPATH (bit path 0-left, 1-right + serial numbers) Změna objektu = smazat původní a znovu vložit nový Smazání objektu Vyhledání kapsy v AST a odebrání Vyhledání kapsy v AST a odebrání Pokud je kapsa dostatečně prázdná, hledá kapsu pro sloučení (kapsa nalevo v AST – inverzní ke štěpení) Pokud je kapsa dostatečně prázdná, hledá kapsu pro sloučení (kapsa nalevo v AST – inverzní ke štěpení)
 Pro NNID přeposílá požadavek příslušnému uzlu v síti Aby se zabránilo redundantním výpočtům vzdáleností, tak se zašle i BPATH (bit path 0-left, 1-right + serial numbers) Změna objektu = smazat původní a znovu vložit nový Smazání objektu Vyhledání kapsy v AST a odebrání Vyhledání kapsy v AST a odebrání Pokud je kapsa dostatečně prázdná, hledá kapsu pro sloučení (kapsa nalevo v AST – inverzní ke štěpení) Pokud je kapsa dostatečně prázdná, hledá kapsu pro sloučení (kapsa nalevo v AST – inverzní ke štěpení)")
18
Dotazy Range Prochází AST, vyhovovat může více větví, v listu se pro BID prohledá lokální úložiště, jinak zasílá požadavek na NNID (včetně BPATH), pro více stejných NNID se zašle pouze jeden dotaz a čeká na odpověď Prochází AST, vyhovovat může více větví, v listu se pro BID prohledá lokální úložiště, jinak zasílá požadavek na NNID (včetně BPATH), pro více stejných NNID se zašle pouze jeden dotaz a čeká na odpověďKNN Na rozdíl od centralizovaných indexů nezačíná velkým poloměrem, ale položí bodový dotaz a vybere nejvhodnější kapsu, ze které vezme prvních k obejktů. Tím je definován poloměr pro rozsahový dotaz z jehož výsledku se vybere k nejbližších. Na rozdíl od centralizovaných indexů nezačíná velkým poloměrem, ale položí bodový dotaz a vybere nejvhodnější kapsu, ze které vezme prvních k obejktů. Tím je definován poloměr pro rozsahový dotaz z jehož výsledku se vybere k nejbližších. Pokud nebylo prvním bodovým dotazem získáno alespoň k objektů, zkusí položit rozsahový dotaz negarantující nalezení k objektů. Pokud jich opět nevrátí dost, musí se zvětšovat poloměr pomocí jedné ze strategií Pokud nebylo prvním bodovým dotazem získáno alespoň k objektů, zkusí položit rozsahový dotaz negarantující nalezení k objektů. Pokud jich opět nevrátí dost, musí se zvětšovat poloměr pomocí jedné ze strategií Optimistická – zvětší poloměr málo, riskuje další iterace Pesimistická – zvětší poloměr hodně, nižší pravděpdodobnost opakovaných dotazů

19
Aktualizace AST Lokální změny AST se nemusí šířit k ostatním uzlům sítě K detekci rozdílů a aktualizaci dochází během operací vkládání, mazání a dotazování – se zaslaným požadavkem jde i BPATH Různá délka cesty Různá délka cesty Různá sériová čísla Různá sériová čísla Uzel, který vyhodnocuje BPATH, zjistí část AST, kterou potřebuje odesílatel aktualizovat (pro více zpracovávaných požadavků zašle více částí) Peer serializuje části stromu a zašle IAM (Image Adjustment Message) Při rekurzivním volání NNID se rekurzivně zasílají i IAM
 Peer serializuje části stromu a zašle IAM (Image Adjustment Message) Při rekurzivním volání NNID se rekurzivně zasílají i IAM")
20
MCAN Založen na CAN (Content Addressable Network) Distribuovaná hash tabulka – prvky jsou uzly sítě, mapování objektů Distribuovaná hash tabulka – prvky jsou uzly sítě, mapování objektů Každý uzel je dynamicky asociován s částí d-dimenzionálního Kartézského prostoru (může mu být přiřazena pouze jedna) Každý uzel je dynamicky asociován s částí d-dimenzionálního Kartézského prostoru (může mu být přiřazena pouze jedna) Podporuje vkládání, vyhledávání a mazání objektů (K, V) Podporuje vkládání, vyhledávání a mazání objektů (K, V) Uzel uchovává objekty, které jsou mapovány do jeho regionu, má ukazatele na sousední uzly (vzhledem k pozici v mapovaném prostoru) Uzel uchovává objekty, které jsou mapovány do jeho regionu, má ukazatele na sousední uzly (vzhledem k pozici v mapovaném prostoru) Zobecnění na metrické prostory - MCAN K mapování objektů (fce F) do vektorového prostoru se použije sada n pivotů K mapování objektů (fce F) do vektorového prostoru se použije sada n pivotů Objekt O je přiřazen uzlu, do jehož prostoru padne F(O) Objekt O je přiřazen uzlu, do jehož prostoru padne F(O) Vzdálenost objektů v R n se počítá kontraktivní L max metrikou Vzdálenost objektů v R n se počítá kontraktivní L max metrikou Uzel MCAN struktury obsahuje IP adresy a virtuální souřadnice zón svých sousedů Uzel MCAN struktury obsahuje IP adresy a virtuální souřadnice zón svých sousedů Jednotlivé zóny se nepřekrývají, prvotní inicializace je inkrementální selekcí Jednotlivé zóny se nepřekrývají, prvotní inicializace je inkrementální selekcí Dodatečné filtrování pomocí dalších pivotů Dodatečné filtrování pomocí dalších pivotů
 Distribuovaná hash tabulka – prvky jsou uzly sítě, mapování objektů Distribuovaná hash tabulka – prvky jsou uzly sítě, mapování objektů Každý uzel je dynamicky asociován s částí d-dimenzionálního Kartézského prostoru (může mu být přiřazena pouze jedna) Každý uzel je dynamicky asociován s částí d-dimenzionálního Kartézského prostoru (může mu být přiřazena pouze jedna) Podporuje vkládání, vyhledávání a mazání objektů (K, V) Podporuje vkládání, vyhledávání a mazání objektů (K, V) Uzel uchovává objekty, které jsou mapovány do jeho regionu, má ukazatele na sousední uzly (vzhledem k pozici v mapovaném prostoru) Uzel uchovává objekty, které jsou mapovány do jeho regionu, má ukazatele na sousední uzly (vzhledem k pozici v mapovaném prostoru) Zobecnění na metrické prostory - MCAN K mapování objektů (fce F) do vektorového prostoru se použije sada n pivotů K mapování objektů (fce F) do vektorového prostoru se použije sada n pivotů Objekt O je přiřazen uzlu, do jehož prostoru padne F(O) Objekt O je přiřazen uzlu, do jehož prostoru padne F(O) Vzdálenost objektů v R n se počítá kontraktivní L max metrikou Vzdálenost objektů v R n se počítá kontraktivní L max metrikou Uzel MCAN struktury obsahuje IP adresy a virtuální souřadnice zón svých sousedů Uzel MCAN struktury obsahuje IP adresy a virtuální souřadnice zón svých sousedů Jednotlivé zóny se nepřekrývají, prvotní inicializace je inkrementální selekcí Jednotlivé zóny se nepřekrývají, prvotní inicializace je inkrementální selekcí Dodatečné filtrování pomocí dalších pivotů Dodatečné filtrování pomocí dalších pivotů")
21
Operace v MCAN Vkládání – může začít v lib. uzlu U – vypočítá se jeho pozice ve virtuálním vektorovém prostou. Otestuje se, zda se nachází přímo v U, pokud ne tak se požadavek na vložení směruje na souseda, jenž je nejblíže novému objektu (L max ), což může opět vést k dalšímu směrování. Uzel do kterého se nakonec objekt vložil zasílá zprávu uzlu U. Štěpení – pokud je objekt vložen do plného uzlu, tak dojde k balancovanému disjunktnímu štěpení – polovina objektů se vloží do nového uzlu (ze seznamu volných uzlů připravených k rozšíření sítě). Na závěr se aktualizuje seznam sousedů. Rozsahový dotaz – dotaz je mapován fcí F do vektorového prostoru, kde se porovná s aktuálním uzlem. V případě průniku zpracuje dotaz, jinak směruje dotaz na souseda, který je „blíže“ k regionu dotazu. Jakmile se najde průnik, tak se vyhodnotí dotaz (vlastní struktura na uložení dat) a přepošle se sousedům, kteří také „protínají“ dotaz. Uzel předává seznam navštívených uzlů INL, po vyhodnocení zasílá zpět volajícímu výsledek a INL rozšířený o nově kontaktované uzly. Každý dotaz má vlastní identifikátor – nedochází k duplicitnímu hledání v uzlech.
, což může opět vést k dalšímu směrování. Uzel do kterého se nakonec objekt vložil zasílá zprávu uzlu U. Štěpení – pokud je objekt vložen do plného uzlu, tak dojde k balancovanému disjunktnímu štěpení – polovina objektů se vloží do nového uzlu (ze seznamu volných uzlů připravených k rozšíření sítě). Na závěr se aktualizuje seznam sousedů. Rozsahový dotaz – dotaz je mapován fcí F do vektorového prostoru, kde se porovná s aktuálním uzlem. V případě průniku zpracuje dotaz, jinak směruje dotaz na souseda, který je „blíže k regionu dotazu. Jakmile se najde průnik, tak se vyhodnotí dotaz (vlastní struktura na uložení dat) a přepošle se sousedům, kteří také „protínají dotaz. Uzel předává seznam navštívených uzlů INL, po vyhodnocení zasílá zpět volajícímu výsledek a INL rozšířený o nově kontaktované uzly. Každý dotaz má vlastní identifikátor – nedochází k duplicitnímu hledání v uzlech..")
22
M-Chord – z čeho vychází iDistance Metoda pro podobnostní vyhledávání ve vektorových prostorech Metoda pro podobnostní vyhledávání ve vektorových prostorech Mapuje objekty do clusterů, pro každý vybírá referenční objekt P Mapuje objekty do clusterů, pro každý vybírá referenční objekt P Každému objektu je přiřazeno číslo (iDistance key) = vzdálenost k P Každému objektu je přiřazeno číslo (iDistance key) = vzdálenost k P Konstanta c pro oddělení clusterů -> iDist(x) = d(p i, x) + i*c Konstanta c pro oddělení clusterů -> iDist(x) = d(p i, x) + i*c Klíče jsou ukládány v B+-tree Klíče jsou ukládány v B+-tree Vyhledávání – berou se pouze ty intervaly, které protne dotaz (+ další ořezání) Vyhledávání – berou se pouze ty intervaly, které protne dotaz (+ další ořezání) Chord (P2P protokol) – lokalizace uzlu pouze O(log n) zpráv Efektivní lokalizace uzlu, který obsahuje data (vzhledem k odpovídajícímu klíči) Efektivní lokalizace uzlu, který obsahuje data (vzhledem k odpovídajícímu klíči) Dynamická struktura (přidání, odebrání uzlu) založená na zasílání zpráv Dynamická struktura (přidání, odebrání uzlu) založená na zasílání zpráv Mapuje doménu vyhledávacích klíčů do Chord domény [0, 2 m ) Mapuje doménu vyhledávacích klíčů do Chord domény [0, 2 m ) Každý Chord uzel má přiřazen klíč K i ze stejné domény [0, 2 m ), uzly jsou setříděny dle vztahu K i i i<j, uzel Ni je zodpovědný za hodnoty (K i-1, K i ] mod 2 m a obsahuje ukazatele na následníka a předchůdce + finger table
![M-Chord – z čeho vychází iDistance Metoda pro podobnostní vyhledávání ve vektorových prostorech Metoda pro podobnostní vyhledávání ve vektorových prostorech Mapuje objekty do clusterů, pro každý vybírá referenční objekt P Mapuje objekty do clusterů, pro každý vybírá referenční objekt P Každému objektu je přiřazeno číslo (iDistance key) = vzdálenost k P Každému objektu je přiřazeno číslo (iDistance key) = vzdálenost k P Konstanta c pro oddělení clusterů -> iDist(x) = d(p i, x) + i*c Konstanta c pro oddělení clusterů -> iDist(x) = d(p i, x) + i*c Klíče jsou ukládány v B+-tree Klíče jsou ukládány v B+-tree Vyhledávání – berou se pouze ty intervaly, které protne dotaz (+ další ořezání) Vyhledávání – berou se pouze ty intervaly, které protne dotaz (+ další ořezání) Chord (P2P protokol) – lokalizace uzlu pouze O(log n) zpráv Efektivní lokalizace uzlu, který obsahuje data (vzhledem k odpovídajícímu klíči) Efektivní lokalizace uzlu, který obsahuje data (vzhledem k odpovídajícímu klíči) Dynamická struktura (přidání, odebrání uzlu) založená na zasílání zpráv Dynamická struktura (přidání, odebrání uzlu) založená na zasílání zpráv Mapuje doménu vyhledávacích klíčů do Chord domény [0, 2 m ) Mapuje doménu vyhledávacích klíčů do Chord domény [0, 2 m ) Každý Chord uzel má přiřazen klíč K i ze stejné domény [0, 2 m ), uzly jsou setříděny dle vztahu K i i i<j, uzel Ni je zodpovědný za hodnoty (K i-1, K i ] mod 2 m a obsahuje ukazatele na následníka a předchůdce + finger table](http://images.slideplayer.cz/18/5750313/slides/slide_22.jpg "M-Chord – z čeho vychází iDistance Metoda pro podobnostní vyhledávání ve vektorových prostorech Metoda pro podobnostní vyhledávání ve vektorových prostorech Mapuje objekty do clusterů, pro každý vybírá referenční objekt P Mapuje objekty do clusterů, pro každý vybírá referenční objekt P Každému objektu je přiřazeno číslo (iDistance key) = vzdálenost k P Každému objektu je přiřazeno číslo (iDistance key) = vzdálenost k P Konstanta c pro oddělení clusterů -> iDist(x) = d(p i, x) + i*c Konstanta c pro oddělení clusterů -> iDist(x) = d(p i, x) + i*c Klíče jsou ukládány v B+-tree Klíče jsou ukládány v B+-tree Vyhledávání – berou se pouze ty intervaly, které protne dotaz (+ další ořezání) Vyhledávání – berou se pouze ty intervaly, které protne dotaz (+ další ořezání) Chord (P2P protokol) – lokalizace uzlu pouze O(log n) zpráv Efektivní lokalizace uzlu, který obsahuje data (vzhledem k odpovídajícímu klíči) Efektivní lokalizace uzlu, který obsahuje data (vzhledem k odpovídajícímu klíči) Dynamická struktura (přidání, odebrání uzlu) založená na zasílání zpráv Dynamická struktura (přidání, odebrání uzlu) založená na zasílání zpráv Mapuje doménu vyhledávacích klíčů do Chord domény [0, 2 m ) Mapuje doménu vyhledávacích klíčů do Chord domény [0, 2 m ) Každý Chord uzel má přiřazen klíč K i ze stejné domény [0, 2 m ), uzly jsou setříděny dle vztahu K i i i<j, uzel Ni je zodpovědný za hodnoty (K i-1, K i ] mod 2 m a obsahuje ukazatele na následníka a předchůdce + finger table")
23
M-Chord Namísto referenčních objektů se z objektů vybírají pivoti Pomocí nich se mapují objekty do jednorozměrného prostoru iDistance doména představuje klíče v Chord protokolu – tzn. musí se transformovat do [0, 2 m ) pomocí uniformní hash fce h zachovávající pořadí – m-chord(x) = h(d(p i, x) + i*c) Každý uzel sítě je zodpovědný za interval klíčů (i více intervalů iDist) Vkládání – oslovený uzel vypočítá m-chord(x) a zašle mu požadavek. Po vložení uzel zašle potvrzení. Pokud dojde ke štěpení, tak se přibere nový uzel a interval se rozpůlí Pokud je rozsah intervalu klíčů přes více intervalů iDist tak vybírá prostřední iDist hranici Pokud je rozsah intervalu klíčů přes více intervalů iDist tak vybírá prostřední iDist hranici Jinak dělí na dvě poloviny Jinak dělí na dvě poloviny K ukládání m-chord klíčů používá B + -tree, ukládá se i vzd. k pivotům Vyhledávání – uzel spočítá k dotazu intervaly (pro všechny pivoty) a zašle zprávy uzlům k vyhodnocení
 pomocí uniformní hash fce h zachovávající pořadí – m-chord(x) = h(d(p i, x) + i*c) Každý uzel sítě je zodpovědný za interval klíčů (i více intervalů iDist) Vkládání – oslovený uzel vypočítá m-chord(x) a zašle mu požadavek. Po vložení uzel zašle potvrzení. Pokud dojde ke štěpení, tak se přibere nový uzel a interval se rozpůlí Pokud je rozsah intervalu klíčů přes více intervalů iDist tak vybírá prostřední iDist hranici Pokud je rozsah intervalu klíčů přes více intervalů iDist tak vybírá prostřední iDist hranici Jinak dělí na dvě poloviny Jinak dělí na dvě poloviny K ukládání m-chord klíčů používá B + -tree, ukládá se i vzd. k pivotům Vyhledávání – uzel spočítá k dotazu intervaly (pro všechny pivoty) a zašle zprávy uzlům k vyhodnocení.")
24
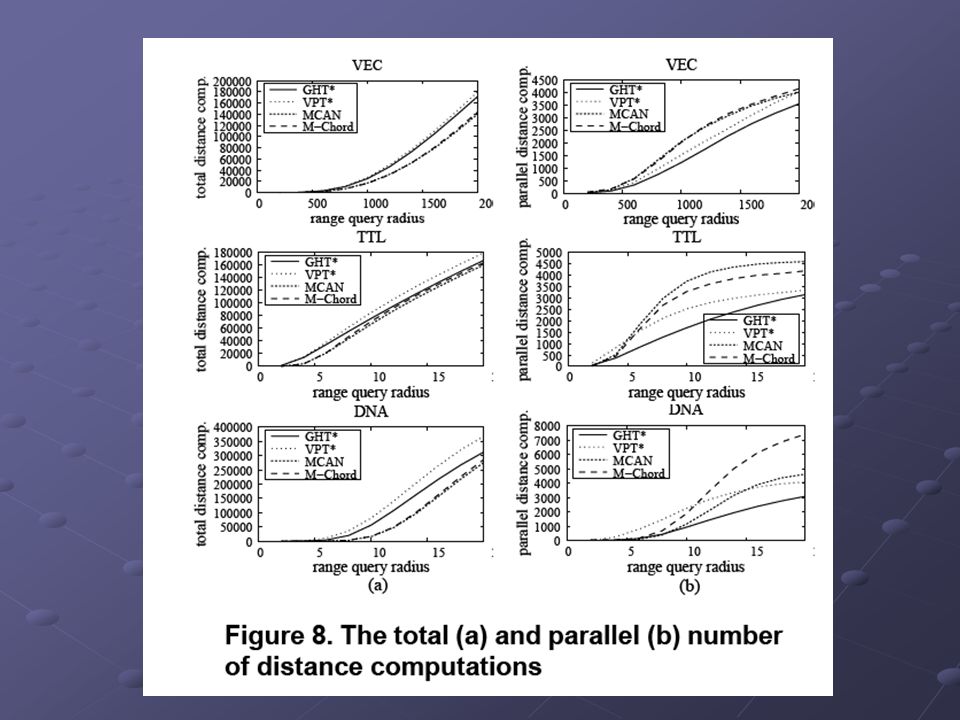
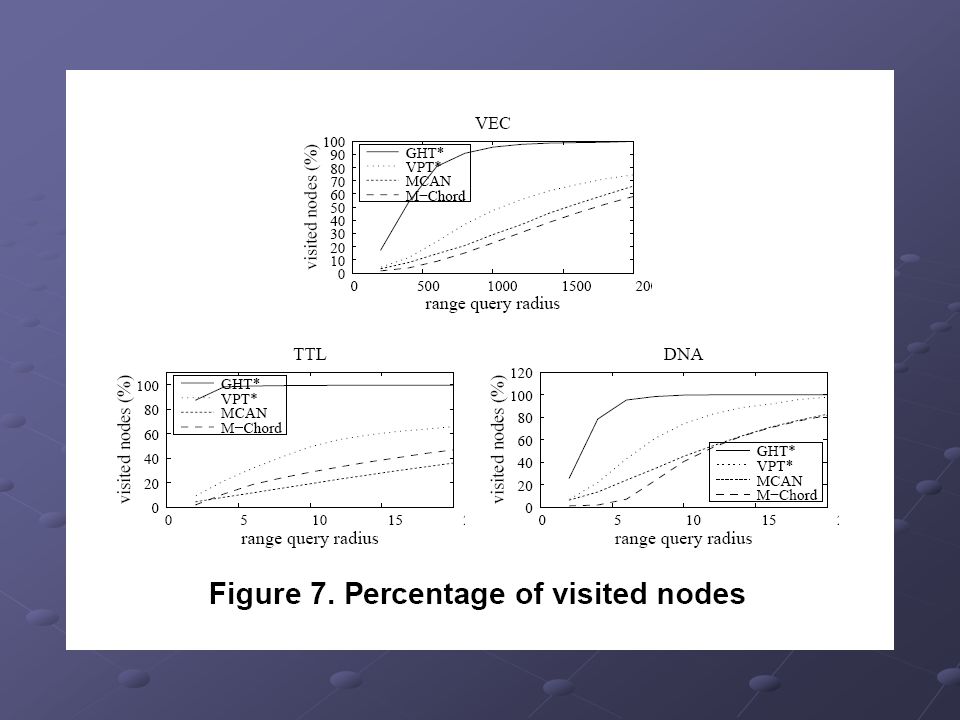
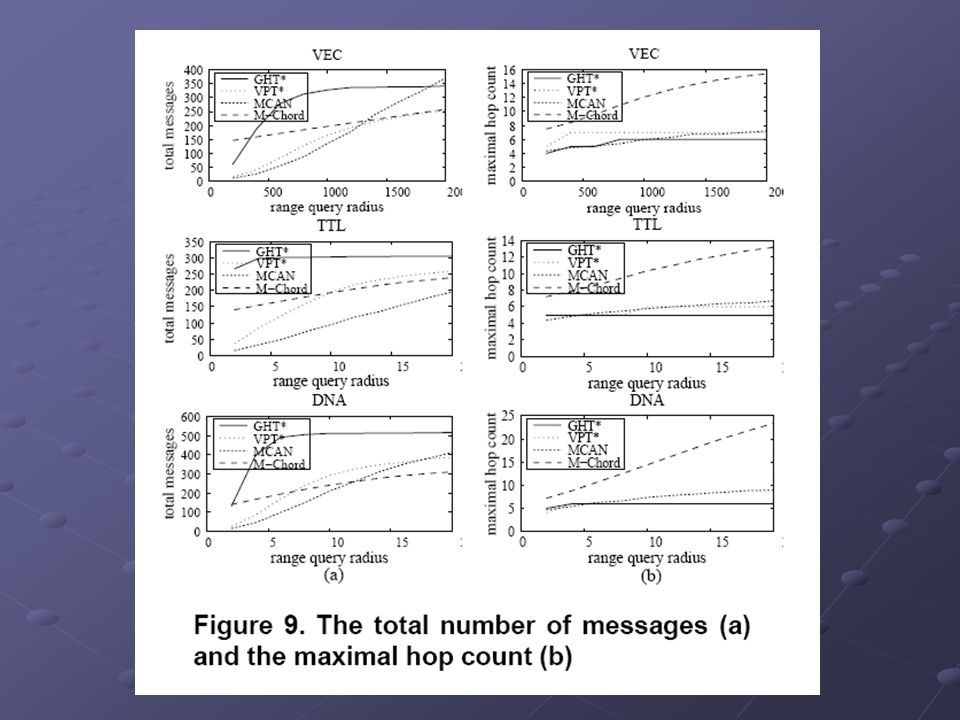
Porovnání Systém 300 aktivních uzlů Pro GHT* (VPT*) uzel 5 kapes pro 1000 obj Pro GHT* (VPT*) uzel 5 kapes pro 1000 obj Uzly MCAN a M-Chord s kapacitou 5000 obj Uzly MCAN a M-Chord s kapacitou 5000 obj MCAN – 4 pivoty pro mapování, 40 pivotů pro filtrování M-Chord – používá 40 pivotů Propojeno vysokorychlostní LAN Propojeno vysokorychlostní LAN Datové sady – 500.000 objektů 45 dim vektory (color image features), kvadratická forma 45 dim vektory (color image features), kvadratická forma Názvy a podnázvy českých knížek a časopisů, editační vzdálenost Názvy a podnázvy českých knížek a časopisů, editační vzdálenost DNA sekvence délky 16, vážená editační vzdálenost (vrací hodnoty 0-100) DNA sekvence délky 16, vážená editační vzdálenost (vrací hodnoty 0-100)
 uzel 5 kapes pro 1000 obj Pro GHT* (VPT*) uzel 5 kapes pro 1000 obj Uzly MCAN a M-Chord s kapacitou 5000 obj Uzly MCAN a M-Chord s kapacitou 5000 obj MCAN – 4 pivoty pro mapování, 40 pivotů pro filtrování M-Chord – používá 40 pivotů Propojeno vysokorychlostní LAN Propojeno vysokorychlostní LAN Datové sady – objektů 45 dim vektory (color image features), kvadratická forma 45 dim vektory (color image features), kvadratická forma Názvy a podnázvy českých knížek a časopisů, editační vzdálenost Názvy a podnázvy českých knížek a časopisů, editační vzdálenost DNA sekvence délky 16, vážená editační vzdálenost (vrací hodnoty 0-100) DNA sekvence délky 16, vážená editační vzdálenost (vrací hodnoty 0-100)")
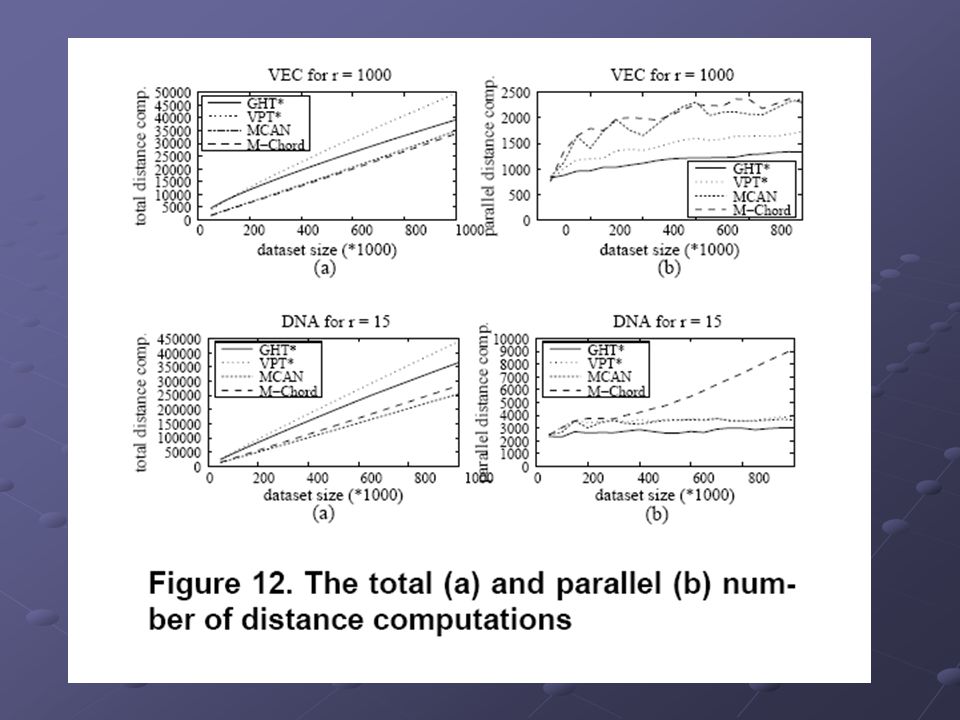
29
Výsledky porovnání

30
Reference Články Processing M-trees with Parallel Resources A Parallel Similarity Search in High Dimensional Metric Space Using M-Tree On Scalability of the Similarity Search in the World of Peers Fast Parallel Similarity Search in Multimedia Databases A Content–Addressable Network for Similarity Search in Metric Spaces M-Chord: A Scalable Distributed Similarity Search Structure Knihy Similarity Search The Metric Space Approach

Podobné prezentace