Stáhnout prezentaci
1
Klasifikace a rozpoznávání
Bayesovská rozhodovací teorie

2
Extrakce příznaků Granáty Jablka Četnost Váha [dkg]
![Extrakce příznaků Granáty Jablka Četnost Váha [dkg]](http://slideplayer.cz/slide/4170317/13/images/2/Extrakce+p%C5%99%C3%ADznak%C5%AF+Gran%C3%A1ty+Jablka+%EF%83%A0+%C4%8Cetnost+%EF%83%A0+V%C3%A1ha+%5Bdkg%5D.jpg "Extrakce příznaků Granáty Jablka Četnost Váha [dkg]")
3
Pravděpodobnosti - diskrétní příznaky
Uvažujme diskrétní příznaky – „váhové kategorie“ Nechť tabulka reflektuje skutečné pravděpodobnosti jednotlivých kategorií 1 6 12 15 2 50 4 23 14 3 100 nejlehčí lehčí lehký střední 0.3 – 0.4 těžký 0.4 – 0.5 těžší 0.5 – 0.6 nejtěžší 0.6 – 0.7 [kg]

4
Apriorní pravděpodobnost – Stav věci
Hádej co mám za zády, jablko nebo granát? Klasifikační pravidlo: Vyber čeho je nejvíc Třída s největší apriorní pravděpodobností (a-priori probability) P ( g r a n t ) = 5 1 P ( j a b l k o ) = 1 5 P ! ( ) = 1 1 6 12 15 2 50 4 23 14 3 100 nejlehčí lehčí lehký střední 0.3 – 0.4 těžký 0.4 – 0.5 těžší 0.5 – 0.6 nejtěžší 0.6 – 0.7 [kg]
 P. ( g. r. a. n. t. ) = P. ( j. a. b. l. k. o. ) = P. ! ( ) = nejlehčí lehčí lehký střední. 0.3 – 0.4. těžký. 0.4 – 0.5. těžší. 0.5 – 0.6. nejtěžší. 0.6 – 0.7. [kg]")
5
Společná pravděpodobnost
Je to těžké. Hádej co to je? Klasifikační pravidlo: Ve sloupci váhové kategorie vyber nejčastější třídu Třída s největší společnou pravděpodobností (joint probability) – pravděpodobnost chlívečku. … ale také největší podmíněnou pravděpodobností (viz další slajd) P ( g r a n t ; e z k y ) = 1 2 5 P ( j a b l k o ; t e z y ) = 6 1 5 P ! ; x ( ) = 1 1 6 12 15 2 50 4 23 14 3 100 nejlehčí lehčí lehký střední 0.3 – 0.4 těžký 0.4 – 0.5 těžší 0.5 – 0.6 nejtěžší 0.6 – 0.7 [kg]
 – pravděpodobnost chlívečku. … ale také největší podmíněnou pravděpodobností (viz další slajd) P. ( g. r. a. n. t. ; e. z. k. y. ) = P. ( j. a. b. l. k. o. ; t. e. z. y. ) = P. ! ; x. ( ) = nejlehčí lehčí lehký střední. 0.3 – 0.4. těžký. 0.4 – 0.5. těžší. 0.5 – 0.6. nejtěžší. 0.6 – 0.7. [kg]")
6
Podmíněná pravděpodobnost
Je to těžké. Z jakou pravděpodobností je to granát? Podmíněnou pravděpodobnost (conditional probability) - pravděpodobnost chlívečku dáno sloupec P ( g r a n t j e z k y ) = 1 2 + 6 1 6 12 15 2 50 4 23 14 3 100 nejlehčí lehčí lehký střední 0.3 – 0.4 těžký 0.4 – 0.5 těžší 0.5 – 0.6 nejtěžší 0.6 – 0.7 [kg]
 - pravděpodobnost chlívečku dáno sloupec. P. ( g. r. a. n. t. j. e. z. k. y. ) = nejlehčí lehčí lehký střední. 0.3 – 0.4. těžký. 0.4 – 0.5. těžší. 0.5 – 0.6. nejtěžší. 0.6 – 0.7. [kg]")
7
Ještě nějaké další pravděpodobnosti
( g r a n t ) = 5 1 P ( g r a n t j e z k y ) = 1 2 + 6 P ( t e z k y ) = 1 2 + 6 5 P ( t e z k y j g r a n ) = 1 2 5 P ( g r a n t ; e z k y ) = j 1 2 5 P ( g r a n t ; e z k y ) = j 1 2 5 1 6 12 15 2 50 4 23 14 3 100 nejlehčí lehčí lehký střední 0.3 – 0.4 těžký 0.4 – 0.5 těžší 0.5 – 0.6 nejtěžší 0.6 – 0.7 [kg]
 = P. ( g. r. a. n. t. j. e. z. k. y. ) = P. ( t. e. z. k. y. ) = P. ( t. e. z. k. y. j. g. r. a. n. ) = P. ( g. r. a. n. t. ; e. z. k. y. ) = j P. ( g. r. a. n. t. ; e. z. k. y. ) = j nejlehčí lehčí lehký střední. 0.3 – 0.4. těžký. 0.4 – 0.5. těžší. 0.5 – 0.6. nejtěžší. 0.6 – 0.7. [kg]")
8
Bayesův teorém P ( ! j x ) = P ( ! ; x ) = j P ( x ) = ; ! P ( t · e z
Posteriorní pravděpodobnost (posterior probability) Věrohodnost (likelihood) Apriorní pravděpodobnost (prior probability) P ( ! j x ) = Evidence Věrohodnost nás zatím moc nezajímala, ale za chvíli to bude hlavní co se budeme snažit odhadovat z trénovacích dat. Již dříve jsme viděli že (product rule): Pro evidenci platí (sum rule): např.: P ( ! ; x ) = j P ( x ) = ! ; P ( t e z k y ) = g r a n ; + j b l o 1 2 5 6
 Věrohodnost. (likelihood) Apriorní pravděpodobnost. (prior probability) P. ( ! j. x. ) = Evidence. Věrohodnost nás zatím moc nezajímala, ale za chvíli to bude hlavní co se budeme snažit odhadovat z trénovacích dat. Již dříve jsme viděli že (product rule): Pro evidenci platí (sum rule): např.: P. ( ! ; x. ) = j. P. ( x. ) = ! ; P. ( t. e. z. k. y. ) = g. r. a. n. ; + j. b. l. o")
9
Maximum a-posteriori (MAP) klasifikátor
Mějme 2 třídy ω1 a ω2 Pro daný příznak x vyber třídu ω s větší posteriorní pravděpodobností P(ω|x) Vyber ω1 pouze pokud: P ( ! 1 j x ) > 2 P ( x j ! 1 ) > 2 P ( ! 1 ; x ) > 2
 Vyber ω1 pouze pokud: P. ( ! 1. j. x. ) > 2. P. ( x. j. ! 1. ) > 2. P. ( ! 1. ; x. ) > 2.")
10
Maximum a-posteriori (MAP) klasifikátor
Pro každé x minimalizuje pravděpodobnost chyby: P(chyby|x) = P(ω1|x) pokud vybereme ω2 P(chyby|x) = P(ω2|x) pokud vybereme ω1 Pro dané x vybíráme třídu ω s větším P(ω|x) minimalizace chyby Musíme ovšem znát skutečná rozložení P(ω|x) nebo P(x,ω) nebo P(x|ω) a P(ω), které reflektují rozpoznávaná data Obecně pro N tříd Vyber třídu s největší posteiorní pravděpodobností: a r g m x ! P ( j ) = p
 = P(ω1|x) pokud vybereme ω2. P(chyby|x) = P(ω2|x) pokud vybereme ω1. Pro dané x vybíráme třídu ω s větším P(ω|x) minimalizace chyby. Musíme ovšem znát skutečná rozložení. P(ω|x) nebo P(x,ω) nebo P(x|ω) a P(ω), které reflektují rozpoznávaná data. Obecně pro N tříd. Vyber třídu s největší posteiorní pravděpodobností: a. r. g. m. x. ! P. ( j. ) = p.")
11
Spojité příznaky P ( x 2 a ; b ) = R p d p ( x j ! )
P(.) – bude pravděpodobnost p(.) – bude hodnota funkce rozložení pravděpodobnosti P ( x 2 a ; b ) = R p d Bude nás zajímat funkce rozložení pravděpodobnosti příznaků podmíněné třídou p ( x j ! ) 3.5 Plocha pod funkci musí být 1 Hodnoty mohou být ale libovolné kladné 0.7 [kg]
 – bude pravděpodobnost. p(.) – bude hodnota funkce rozložení pravděpodobnosti. P. ( x. 2. a. ; b. ) = R. p. d. Bude nás zajímat funkce rozložení pravděpodobnosti příznaků podmíněné třídou. p. ( x. j. ! ) 3.5. Plocha pod funkci musí být 1. Hodnoty mohou být ale libovolné kladné. 0.7 [kg]")
12
Bayesův teorém – spojité příznaky
( ! j x ) = p p ( x j ! ) p ( ! ; x ) = j P p ( ! j x ) 3.5 2.5 1 x x x
 = p. p. ( x. j. ! ) p. ( ! ; x. ) = j. P. p. ( ! j. x. ) x. x. x.")
13
MAP klasifikátor – spojité příznaky
Opět se budeme rozhodovat podle: nebo P ( ! 1 ; x ) > 2 P ( ! 1 j x ) > 2 p ( ! ; x ) p ( ! j x ) 2.5 1 Na obrazcích vidíme, že obě pravidla vedou ke stejným rozhodnutím x x
 > 2. P. ( ! 1. j. x. ) > 2. p. ( ! ; x. ) p. ( ! j. x. ) Na obrazcích vidíme, že obě pravidla vedou ke stejným rozhodnutím. x. x.")
14
MAP klasifikátor – pravděpodobnost chyby
Říkali jsme, že MAP klasifikátor minimalizuje pravděpodobnost chyby Plocha pod funkci společného rozložení pravděpodobnosti p(ω,x) v určitém intervalu x je pravděpodobnost výskytu vzoru třídy ω s příznakem v daném intervalu Jaká je tedy celková pravděpodobnost, že klasifikátor udělá chybu? Pravděpodobnost, že modrá třída je chybně klasifikována jako červená Jakákoli snaha posunout hranice povede jen k větší chybě 2.5 2.5 p ( ! ; x ) p ( ! ; x ) x x
 v určitém intervalu x je pravděpodobnost výskytu vzoru třídy ω s příznakem v daném intervalu. Jaká je tedy celková pravděpodobnost, že klasifikátor udělá chybu Pravděpodobnost, že modrá třída je chybně klasifikována jako červená. Jakákoli snaha posunout hranice povede jen k větší chybě p. ( ! ; x. ) p. ( ! ; x. ) x. x.")
15
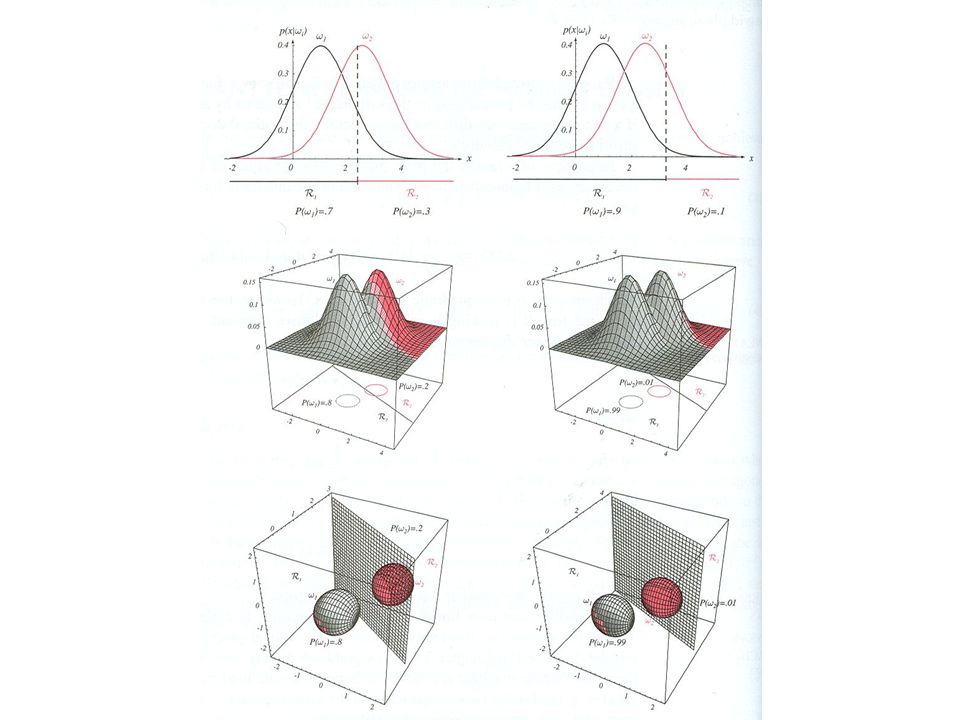
Posteriorní pravděpodobnosti pro různé apriorní pravděpodobnosti
Změna apriorních pravděpodobností tříd může vézt k různým rozhodnutím P ( ! 1 ) = 3 ; 2 P ( ! 1 ) = 2 ; P ( ! 1 ) = 9 ; 2 x x x
 = 3. ; 2. P. ( ! 1. ) = 2. ; P. ( ! 1. ) = 9. ; 2. x. x. x.")
16
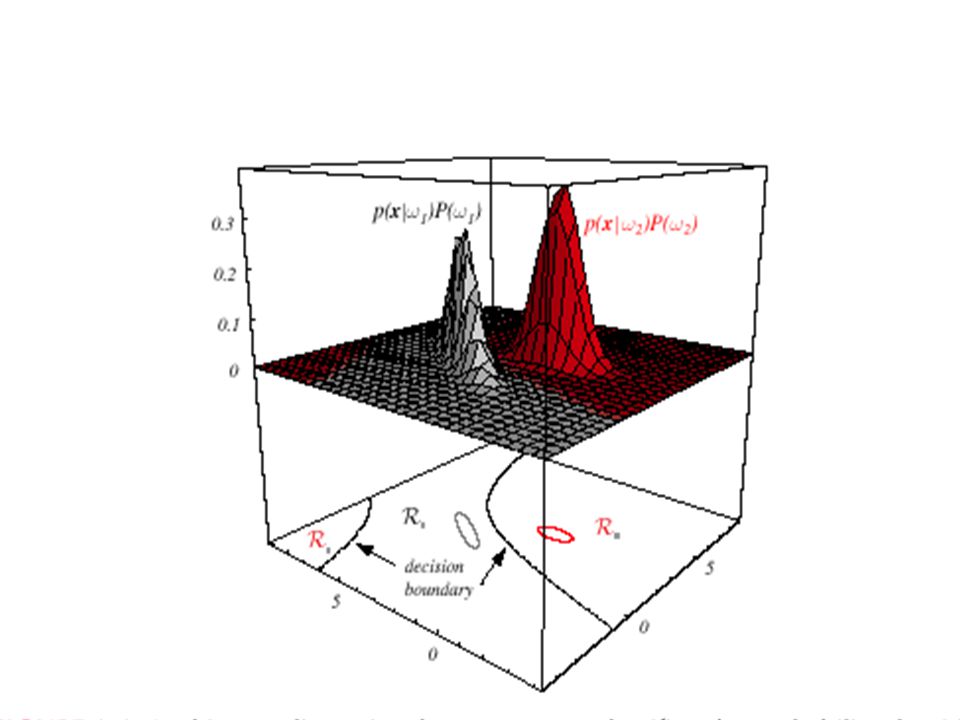
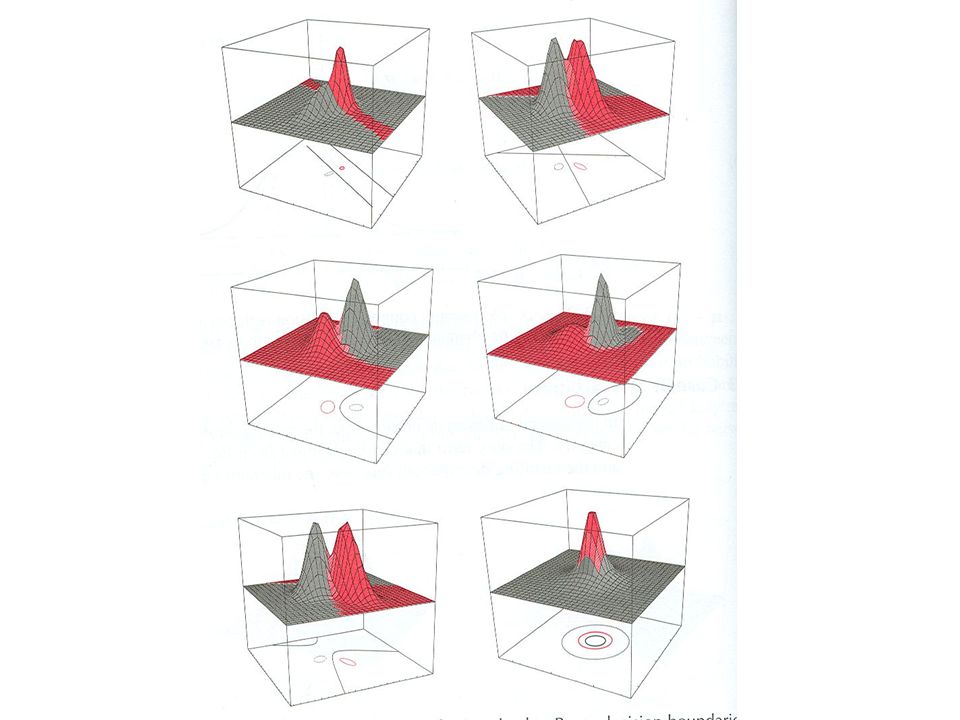
Vícerozměrné příznaky
Místo jednorozměrného příznaku máme N rozměrný příznakový vektor x = [x1, x2, …, xN] např. [váha, červenost] MAP klasifikátor opět vybírá nejpravděpodobnější třídu p ( ! ; x ) x1 x2
 x1. x2.")
18
Parametrické modely Pro rozpoznávání s MAP klasifikátorem jsme doposud předpokládali, že známe skutečná rozloženi P(ω|x) nebo P(x,ω) nebo P(x|ω) a P(ω) Ve skutečnosti ale většinou známe jen trénovací vzory Pokusíme se tato rozložení odhadnout z dat – budeme trénovat statistické modely unvoiced voiced silence
 nebo P(x,ω) nebo P(x|ω) a P(ω) Ve skutečnosti ale většinou známe jen trénovací vzory. Pokusíme se tato rozložení odhadnout z dat – budeme trénovat statistické modely. unvoiced. voiced. silence.")
19
Parametrické modely Můžeme se pokusit modelovat přímo posteriorní pravděpodobnost, a tu použít přímo k rozpoznávání P(ω|x) tzv. diskriminativní trénování Ale o tomto bude řeč až později Běžnější je odhadovat rozložení P(x|ω) a P(ω) Tato rozložení popisují předpokládaný proces generování dat – generativní modely Nejprve se musíme rozhodnout pro formu modelu, který použijeme. (např. gaussovské rozložení) unvoiced voiced silence
 a P(ω) Tato rozložení popisují předpokládaný proces generování dat – generativní modely. Nejprve se musíme rozhodnout pro formu modelu, který použijeme. (např. gaussovské rozložení) unvoiced. voiced. silence.")
20
Gaussovské rozložení (jednorozměrné)
x ; 2 ) = 1 p e
 = 1. p. e.")
22
Gaussovské rozložení (dvourozměrné)
x ; ) = 1 p 2 P j e T
 = 1. p. 2. P. j. e. T.")
26
Odhad parametrů modelu s maximální věrohodností
^ c l a s M L = r g m x Y i 2 p ( j ) Hledáme taková nastavení parametrů rozložení pravděpodobnosti Θ, které maximalizuje věrohodnost trénovacích dat (Maximum Likelihood, ML) V následujících příkladech předpokládáme, že odhadujeme parametry nezávisle pro jednotlivé třídy. Pro zjednodušení notace tedy u rozložení neuvádíme závislost na třídě ω, pouze na jejích parametrech Θ. Modely kterými se budeme zabývat jsou: Gaussovské rozloženi Směs gaussovských rozložení (Gaussian Mixture Model, GMM) V následujících přednáškách přibudou další (např. HMM)
 Hledáme taková nastavení parametrů rozložení pravděpodobnosti Θ, které maximalizuje věrohodnost trénovacích dat (Maximum Likelihood, ML) V následujících příkladech předpokládáme, že odhadujeme parametry nezávisle pro jednotlivé třídy. Pro zjednodušení notace tedy u rozložení neuvádíme závislost na třídě ω, pouze na jejích parametrech Θ. Modely kterými se budeme zabývat jsou: Gaussovské rozloženi. Směs gaussovských rozložení (Gaussian Mixture Model, GMM) V následujících přednáškách přibudou další (např. HMM)")
27
Gaussovské rozložení (jednorozměrné)
x ; 2 ) = 1 p e ML odhad parametrů: = 1 T P i x 2 = 1 T P i ( x )
 = 1. p. e. ML odhad parametrů: = 1. T. P. i. x. 2. = 1. T. P. i. ( x. )")
28
Gaussovské rozložení (dvourozměrné)
x ; ) = 1 p 2 P j e T ML odhad of parametrů: = 1 T P i x = 1 T P i ( x )
 = 1. p. 2. P. j. e. T. ML odhad of parametrů: = 1. T. P. i. x. = 1. T. P. i. ( x. )")
29
Směs gaussovských rozložení GMM
p ( x j ) = P c N ; kde = f P c ; g P c = 1
 = P. c. N. ; kde. = f. P. c. ; g. P. c. = 1.")
30
Gaussian Mixture Model
Evaluation: p ( x j ) = P c N ; 2 Vzoreček můžeme chápat jen jako něco co definuje tvar funkce hustoty pravděpodobnosti… nebo jej můžeme vidět jako složitější generativní model,který generuje příznaky následujícím způsobem: Napřed je jedna z gaussovských komponent vybrána tak aby respektovala apriorní pravděpodobnosti Pc Příznakový vektor se generuje z vybraného gaussovského rozložení. Pro vyhodnoceni modelu ale nevíme, která komponenta příznakový vektor generovala a proto musíme marginalizovat (suma přes gaussovské komponenty násobené apriorními pravděpodobnostmi)
 = P. c. N. ; 2. Vzoreček můžeme chápat jen jako něco co definuje tvar funkce hustoty pravděpodobnosti… nebo jej můžeme vidět jako složitější generativní model,který generuje příznaky následujícím způsobem: Napřed je jedna z gaussovských komponent vybrána tak aby respektovala apriorní pravděpodobnosti Pc. Příznakový vektor se generuje z vybraného gaussovského rozložení. Pro vyhodnoceni modelu ale nevíme, která komponenta příznakový vektor generovala a proto musíme marginalizovat (suma přes gaussovské komponenty násobené apriorními pravděpodobnostmi)")
31
Training GMM –Viterbi training
Intuitive and Approximate iterative algorithm for training GMM parameters. Using current model parameters, let Gaussians to classify data as the Gaussians were different classes (Even though the both data and all components corresponds to one class modeled by the GMM) Re-estimate parameters of Gaussian using the data associated with to them in the previous step. Repeat the previous two steps until the algorithm converge.
 Re-estimate parameters of Gaussian using the data associated with to them in the previous step. Repeat the previous two steps until the algorithm converge.")
32
Training GMM – EM algorithm
Expectation Maximization is very general tool applicable in many cases were we deal with unobserved (hidden) data. Here, we only see the result of its application to the problem of re-estimating parameters of GMM. It guarantees to increase likelihood of training data in every iteration, however it does not guarantees to find the global optimum. The algorithm is very similar to Viterbi training presented above. Only instead of hard decisions, it uses “soft” posterior probabilities of Gaussians (given the old model) as a weights and weight average is used to compute new mean and variance estimates. ^ ( n e w ) c = P i x ^ 2 c ( n e w ) = P i x c i = P N ( x ; ^ o l d ) 2
 data. Here, we only see the result of its application to the problem of re-estimating parameters of GMM. It guarantees to increase likelihood of training data in every iteration, however it does not guarantees to find the global optimum. The algorithm is very similar to Viterbi training presented above. Only instead of hard decisions, it uses soft posterior probabilities of Gaussians (given the old model) as a weights and weight average is used to compute new mean and variance estimates. ^ ( n. e. w. ) c. = P. i. x. ^ 2. c. ( n. e. w. ) = P. i. x. c. i. = P. N. ( x. ; ^ o. l. d. ) 2.")













 je pravděpodobnostní prostor:>")






