Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Akcelerace genetických algoritmů na grafických kartách 5. část Mikuláš Dítě

2
Připomenutí problému udržování tyče na vozíku pěstování konstant zdlouhavý výpočet fitness funkce

3
Paměťová náročnost přenesení dat do paměti GPU CPUCPU + GPU

4
Další optimalizace pouze GPU start zápis na GPU čtení z GPU každá generace paralelní výpočet vlastní implementace rand() a další výpočty vlastní implementace rand() a další výpočty
 a další výpočty vlastní implementace rand() a další výpočty")
5
Porovnání CPU, GPU+CPU a GPU

6
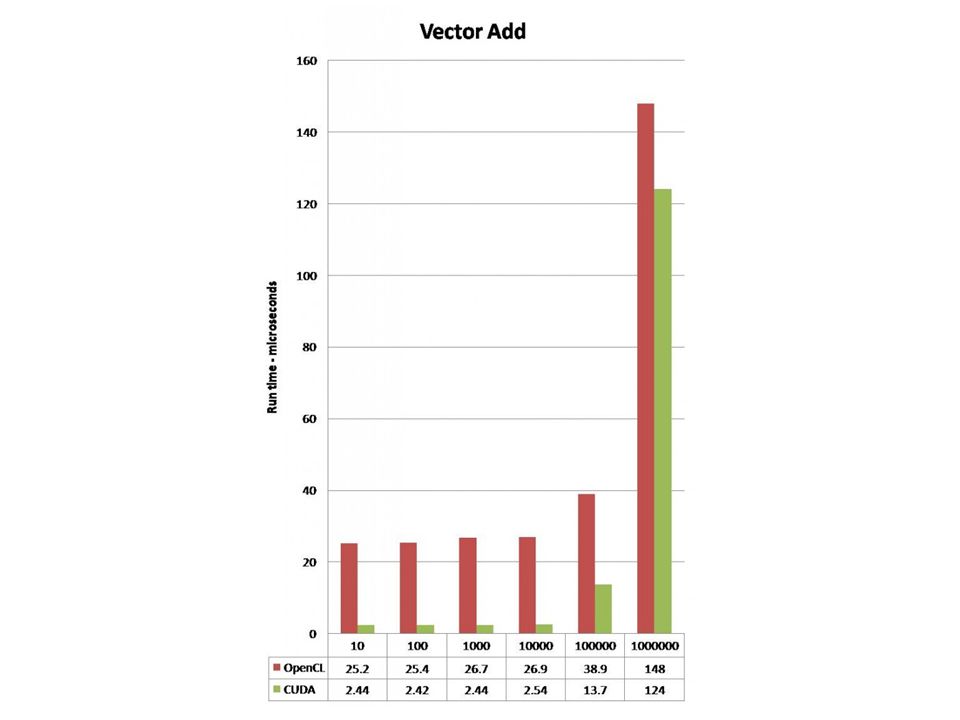
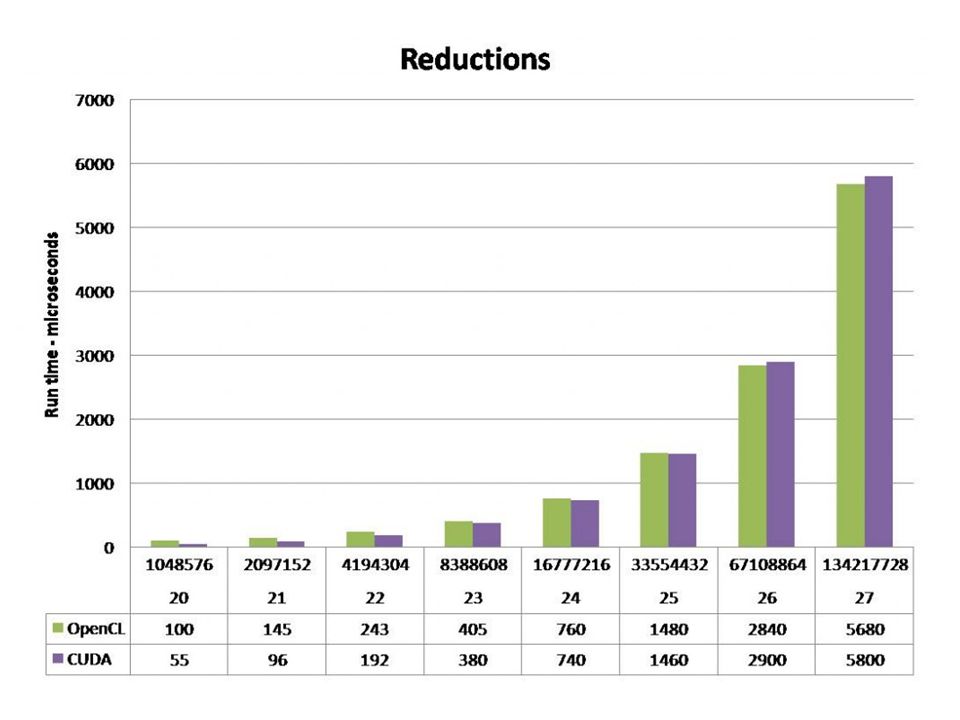
Porovnání

7
OpenCL vs CUDA programování pro grafickou kartu OpenCL je (víc) multiplatformní – 1.1 vyšla ještě 2010 CUDA vytvořila Nvidia – 4.0 stable (květen 2011)
 multiplatformní – 1.1 vyšla ještě 2010 CUDA vytvořila Nvidia – 4.0 stable (květen 2011)")
8
CUDA maximální rozměr textury 65 536 x 65 535

11
Odkazy Ing. Miroslav Čepek (Katedra počítačů FEL ČVUT) Ing. Vladimír Pospíšil (Cesta k vědě) Poděkování https://github.com/Mikulas/PoleBalanceGPU https://github.com/Mikulas/PoleBalanceGPU
 Poděkování")
12
Zdroje [1] BROWNLEE, J. The pole balancing problem. [online]. [cit. 8. 1. 2011]. Dostupné z http://www.ict.swin.edu.au/personal/jbrownlee/2005/TR07- 2005.pdf [2] Genetic algorithm. [online]. [cit. 8. 1. 2011]. Dostupné z http://en.wikipedia.org/wiki/Genetic_algorithm [3] NP-hard. [online]. [cit. 8. 1. 2011]. Dostupné z http://en.wikipedia.org/wiki/Np-hard [4] KOZOLA, S. Improving Optimization Performance with Parallel Computing. [online]. [cit. 8. 1. 2011]. Dostupné z http://www.mathworks.com/company/newsletters/digest/2009/mar/par allel-optimization.html
![Zdroje [1] BROWNLEE, J. The pole balancing problem.](http://images.slideplayer.cz/12/4130960/slides/slide_12.jpg "[online]. [cit ]. Dostupné z pdf [2] Genetic algorithm. [online]. [cit ]. Dostupné z [3] NP-hard. [online]. [cit ]. Dostupné z [4] KOZOLA, S. Improving Optimization Performance with Parallel Computing. [online]. [cit ]. Dostupné z allel-optimization.html.")
Podobné prezentace


 Definujte pojem gradient. Vypočítejte gradient funkce.>")
 Elektronky, relé = drahé, pomalé Druhá generace (1951 - 1965) Tranzistory = zmenšování.>")
![Genetické algoritmy [GA]](/8/2469778/big_thumb.jpg "Genetické algoritmy [GA]>")














, základní charakteristika.>")