Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Datové struktury bit /binary digit) - nejmenší jednotka informace (jedna ze dvou možností, nula nebo jedna) byte - nejmenší adresovatelná jednotka paměti (8bitů) 8 bitů = 1 znak kombinací = ASCII tabulka (American Standard Code for Information Interchange) 0-31 speciální znaky anglická abeceda, číslice KB = 210 bytů (1024 bytů) MB = 220 bytů ( bytů) GB = 230 bytů (1, bytů) Unicode Kódování češtiny = PC Latin2 (CP 852) MS Windows (CP 1250)
 8 bitů = 1 znak kombinací = ASCII tabulka. (American Standard Code for Information Interchange) 0-31 speciální znaky anglická abeceda, číslice. KB = 210 bytů (1024 bytů) MB = 220 bytů ( bytů) GB = 230 bytů (1, bytů) Unicode. Kódování češtiny = PC Latin2 (CP 852) MS Windows (CP 1250)")
2
Uložení čísel v počítači
čísla celá čísla reálná (v pohyblivé řádové čárce) 725 = (mantisa 3 byty - až 7 platných dekadických číslic - 6 hexadecimálních)
 725 = (mantisa 3 byty - až 7 platných dekadických číslic - 6 hexadecimálních)")
3
BIN HEX DEC OCT 1010 A 10 1011 B 11 1100 C 12 1101 D 13 1110 E 14 1111 F 15

4
Převody mezi číselnými soustavami
725 = (2) = = 87(10) B5(16) = = 181(10) B5(16) = 1011 | 0101(2) ( = 181(10) ) 0101 | 0111(2) = 57(16) ( = 87(10) )
 = = 87(10) B5(16) = = 181(10) B5(16) = 1011 | 0101(2) ( = 181(10) ) 0101 | 0111(2) = 57(16) ( = 87(10) )")
5
87 : 2 = 43 zbytek 1 43 : 2 = 21 1 21 : 2 = 10 1 10 : 2 = 5 0 5 : 2 = 2 1 2 : 2 = 1 0 1 : 2 = 0 1 výsledek zapisujeme zdola nahoru , tj

6
Datové typy typ, deklarace typu, operace s daty standardní datové typy integer real (float, double) boolean (logical) char (jednoznakové proměnné) string (textové řetězce) definované typy dat (typ definovaný výčtem) (typ den , hodnota .. středa)
 char (jednoznakové proměnné) string (textové řetězce) definované typy dat (typ definovaný výčtem) (typ den , hodnota .. středa)")
7
Strukturované typy dat
typ struktury (homogenní, heterogenní strukt.) uspořádání prvků ( statické, dynamické strukt.) označení prvků typ prvků (jednoduché, strukturované typy) operace s prvky
 uspořádání prvků ( statické, dynamické strukt.) označení prvků. typ prvků (jednoduché, strukturované typy) operace s prvky.")
8
Typ pole typ záznam typ množina typ soubor

9
Abstraktní datové typy
lineární seznam zásobník fronta nelineární tabulka graf (binární strom)
")
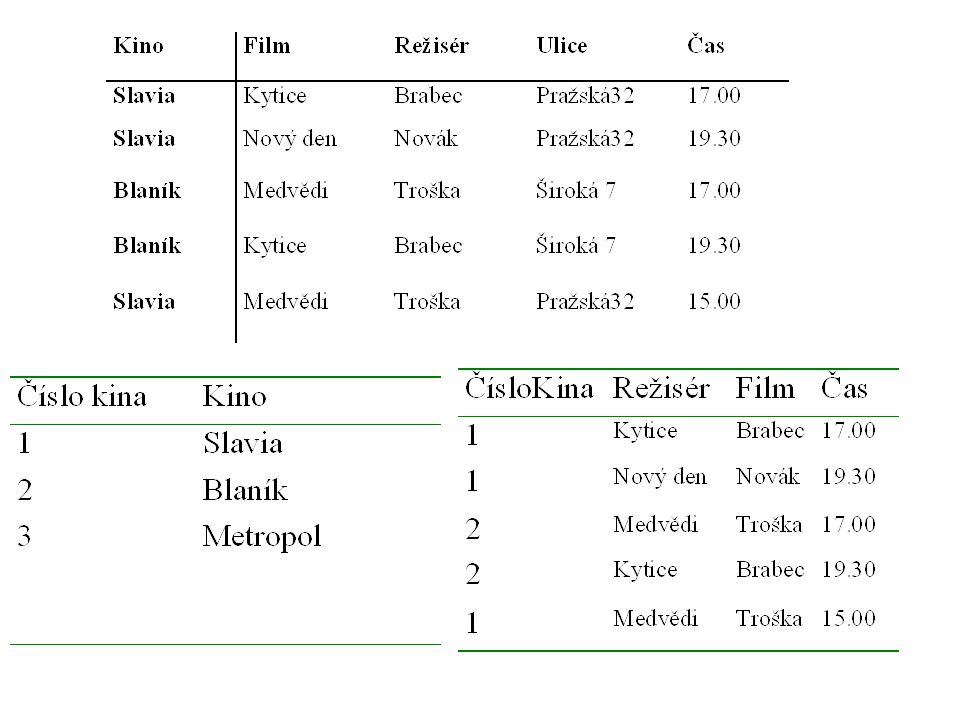
10
databáze - jisté množství údajů vztahujících se k určité problematice - telefonní seznam, adresář klientů firmy, katalog zboží konkrétního obchodního domu, seznam knih ve fondu určité knihovny….. Tyto informace jsou shromažďovány a vedeny na počítači za účelem jejich praktického využívání - vyhledávání požadovaných informací co nejrychlejším a nejspolehlivějším způsobem. Nahradila klasické kartotéky na administrativních pracovištích, - knihovny (kartotéka registračních kartiček jednotlivých knih), sklady (kartotéka skladových karet) lékař (kartotéka s osobními kartami pacientů). Každá jednotlivá karta příslušné kartotéky obsahovala určité údaje o sledované problematice, např. o konkrétním pacientovi. V případě většího množství sledovaných jednotek byly velmi složité problémy při aktualizaci jednotlivých údajů, vyhledávání a přerovnávání dle konkrétních požadavků.
, sklady (kartotéka skladových karet) lékař (kartotéka s osobními kartami pacientů). Každá jednotlivá karta příslušné kartotéky obsahovala určité údaje o sledované problematice, např. o konkrétním pacientovi. V případě většího množství sledovaných jednotek byly velmi složité problémy při aktualizaci jednotlivých údajů, vyhledávání a přerovnávání dle konkrétních požadavků..")
11
DATABÁZE Množina vzájemně logicky souvisejících dat, která se vztahují k určité problematice – seznam pracovníků seznam studentů katalog zboží seznam zákazníků evidence pacientů telefonní seznam náhrada klasických kartoték (u nich problémy při vyhledávání, třídění, aktualizaci)
")
12
Vývoj přístupů ke zpracování dat na počítači
významné především dva aspekty: míra vzájemné integrovanosti organizace dat a stupeň nezávislosti programů od způsobů jejich uložení. čtyři vývojové skupiny: ) konvenční přístupy . agendové zpracování dat, . integrované zpracování dat; ) databázový přístup . databázové zpracování dat, objektové zpracování dat.
 konvenční přístupy. . agendové zpracování dat, . integrované zpracování dat; ) databázový přístup. . databázové zpracování dat, objektové zpracování dat.")
13
Prvním pokusem řešit problematiku zpracování hromadných dat na počítači bylo tzv. souborové (agendové) zpracování.
 zpracování..")
14
řešení samostatných, vzájemně oddělených a rozsahem malých úloh - agend. Každá agenda měla svoje vlastní soubory - vícenásobné ukládání a následné zpracování značného počtu stejných dat. Soubory dat jednotlivých agend nebyly navzájem propojeny, proto míra jejich integrovanosti byla minimální. Programy, které pracovaly s těmito soubory, silně závisely na struktuře a uložení dat, ke každému konkrétnímu programu provozovanému v daném podniku, existoval příslušný datový zdroj - soubor. To vedlo k tomu, že v množině těchto datových souborů zpracovávané v dané organizační jednotce se některé údaje několikanásobně zcela zbytečně opakovaly, což způsobovalo velké problémy při aktualizaci těchto dat a vedlo k nárůstu doby zpracování. Narůstající objem uchovávaných dat, stejně tak jako zvyšující se frekvence zpracování, množství souborů, počet programů a různé metody jejich organizace komplikovaly provozování dat. Redundance vyžadovala vícenásobné zpracování, aby bylo možné aktualizovat všechny výskyty té jisté položky.

15
úlohy: - vyhledávání požadovaných dat, - aktualizace evidovaných dat. Data v agendovém zpracování jsou zpravidla organizována tak, že každý objekt evidované reality je popsán záznamem souboru a vlastnosti tohoto objektu jeho položkami. Popis všech objektů tvoří soubor, který je základem tohoto zpracování. V souvislosti s tímto lze odvodit, že soubor - popisuje všechny vlastnosti všech objektů; záznam - popisuje vlastnosti jediného objektu; položka záznamu - popisuje jedinou vlastnost jediného objektu.

16
nevýhody Soubory jsou navrženy podle potřeb konkrétních programů, které je používají. Pokud je vytvářen program řešící daný problém, je nejprve nutno zjistit potřebná data k získání požadovaných výsledků a podle toho navrhnout odpovídající soubory, které tak budou ”šité” na vytvářený program. Každý program musí obsahovat přesný popis souborů, které používá. S tím jsou pak spojeny problémy s redundancí a konzistencí dat. Redundance - některé evidované informace se vyskytují opakovaně ve více souborech, přičemž všechny tyto výskyty musí mít za všech okolností stejnou hodnotu, protože popisují stejnou vlastnost jediného objektu. Jestliže se tato vlastnost změní, musí se tato změna provést ve všech výskytech a ve všech souborech. Pokud toto není zajištěno, data ztrácí svoji konzistenci, což znamená, že daná vlastnost jediného objektu má hodnoty, které si navzájem odporují.

17
obtížná dosažitelnost evidovaných dat- k navrženým souborům existují příslušné aplikační programy, jejichž pomocí uživatelé získávají odpovědi na své dotazy. je třeba již dopředu znát základ těchto dotazů, aby mohl být připraven k tomu účelu odpovídající aplikační program. problémem je možnost současného přístupu více uživatelů k takto pojatým souborům. V této souvislosti půjde o koordinaci paralelních procesů jako např. jeden uživatel aktualizuje a druhý vyhledává), které je nutno přesně synchronizovat. nedostatkem je ochrana dat proti případnému zneužití. agendy mají důvěrný charakter konta v bance), není žádoucí, aby mohl kdokoli provádět s daty jakékoli operace ( převádět peníze na svoje konto) nebo mít přístup ke všem informacím ( možnost zjistit heslo cizí vkladní knížky apod.). V agendovém zpracování dat lze tyto záležitosti zajistit velmi obtížně. integrita dat znamená, že všechna zpracovávaná data musí odpovídat vlastnostem popisovaných objektů reálného světa. Protože však tyto vlastnosti se mění v čase, je třeba zajistit, aby se tyto změny včas a při zachování konzistence odrazily v datech, které je zachycují
, které je nutno přesně synchronizovat. nedostatkem je ochrana dat proti případnému zneužití. agendy mají důvěrný charakter konta v bance), není žádoucí, aby mohl kdokoli provádět s daty jakékoli operace ( převádět peníze na svoje konto) nebo mít přístup ke všem informacím ( možnost zjistit heslo cizí vkladní knížky apod.). V agendovém zpracování dat lze tyto záležitosti zajistit velmi obtížně. integrita dat znamená, že všechna zpracovávaná data musí odpovídat vlastnostem popisovaných objektů reálného světa. Protože však tyto vlastnosti se mění v čase, je třeba zajistit, aby se tyto změny včas a při zachování konzistence odrazily v datech, které je zachycují.")
18
Databázové zpracování :
Struktury aplikačních programů jsou odděleny od datových souborů. Přístup k datům je možný jen prostřednictvím programů databázového systému a nikoli přímo. Dotazy nejsou pevné. Je umožněn přístup více uživatelů současně a je zajištěna ochrana dat proti zneužití. Báze dat - množina dat vztahující se k určité problematice. množina souborů logicky spolu související. Báze dat spolu s prostředky pro její řízení a udržování- tzv. databázový systém. strukturovanost a uspořádanost databází. Databáze je uspořádaný seznam dat (informací) sloužící k co nejjednoduššímu a nejrychlejšímu vyhledávání informací podle určitého klíče, vyhledání telefonního čísla podle příjmení účastníka nebo výpůjčního čísla knihy podle zadaného autora nebo názvu knihy.
 sloužící k co nejjednoduššímu a nejrychlejšímu vyhledávání informací podle určitého klíče, vyhledání telefonního čísla podle příjmení účastníka nebo výpůjčního čísla knihy podle zadaného autora nebo názvu knihy.")
19
Princip databázového zpracování

20
Architektura informačního systému Princip databázového systému : DBS = DB + SŘBD data jsou organizována v databázi (DB) a jsou řízena systémem řízení báze dat (SŘBD; angl. DataBase Management Systém - DBMS), tj. programovým aparátem pro popis a manipulaci s daty uloženými v bázi dat, který si uživatel kupuje od výrobce, např. FoxPro, Paradox atd. Dohromady tzv. databázový systém (DBS, někdy též databanka). Jednou z nejčastějších aplikací vyvinutých pod konkrétním SŘBD je informační systém (IS), který využívá data z DBS buď přímo, nebo je zpracovává dalšími aplikačními programy.
, tj. programovým aparátem pro popis a manipulaci s daty uloženými v bázi dat, který si uživatel kupuje od výrobce, např. FoxPro, Paradox atd. Dohromady tzv. databázový systém (DBS, někdy též databanka). Jednou z nejčastějších aplikací vyvinutých pod konkrétním SŘBD je informační systém (IS), který využívá data z DBS buď přímo, nebo je zpracovává dalšími aplikačními programy..")
21
DATABÁZOVÉ SYSTÉMY DBS
IS DBS DB SŘBD DBS = DB + SŘBD DB – databáze, báze dat SŘBD – systém řízení báze dat

22
SŘBD SW, který zajišťuje: popis dat uložení a aktualizaci dat
víceuživatelský přístup k datům ochranu dat dotazy tvorbu vstupních obrazovek výstup dat na tiskárně ve formě soustav… MS Access, Paradox, FoxPro, dBASE…

23
Báze dat je kolekce údajů (společný zdroj dat), která je odrazem reálného světa je popsána pomocí datového modelu - vytváří se centrální popis báze dat data se ukládají 1x a vícenásobně se využívají

24
Funkce systému řízení báze dat
třídění - je vytvořen identický datový soubor, jehož řádky, tj. záznamy jsou uspořádány dle uživatelem zadaných kriterií vzestupně nebo sestupně; vytváření součtů - výsledkem je vždy nový soubor obsahující sumarizované hodnoty uživatelem zadaných sloupců, tj. položek; tvorba vstupních obrazovek - jde o uživatelem vytvořenou grafickou podobu zobrazovaných informací z daného souboru za účelem snadnějšího vyhledávaní a aktualizování sledovaných údajů; často tato obrazovka kopíruje grafickou podobu formuláře, z něhož je DB naplňována; výstup evidovaných dat na tiskárnu ve formě požadovaných sestav. Moderní databázové prostředky - tzv. generátory,uživatel pouze graficky navrhuje výslednou podobu sestavy, vstupní obrazovky apod., na jejímž základě příslušný generátor vygeneruje odpovídající zdrojový program.

25
Data mají určitou fyzickou organizaci na fyzických médiích určených k uložení dat jako jsou např. dříve magnetická páska nebo nyní disk. Například data na discích jsou uložena podle válců, stop atd. data mají také určitou logickou organizaci, což ovlivňuje propojení informačního systému s uživateli. Datový model je souhrn pravidel pro reprezentaci logické organizace dat v databázi. Je to návod, udávající, jak mohou být data a vztahy mezi nimi logicky organizovány. Sestává z pojmenovaných logických datových jednotek a vztahů mezi nimi. Datový model nespecifikuje hodnoty dat v databázi, určuje, jak mohou být data logicky organizována a jak mohou navzájem souviset. Například relační datový model určuje, že data mají být organizována podle typu záznamu a datových položek. Pro typ záznamu ZAMĚSTNANEC to znamená, že data o každém zaměstnanci musí být seskupena tak, aby obsahovala hodnoty odpovídající číslu zaměstnance, jeho jménu, adrese, věku, oddělení, kvalifikaci a platu. Každá takováto konkrétní skupina se nazývá výskyt záznamu a každá takováto konkrétní datová položka se nazývá hodnota datové položky. Pohled je část databáze, tak jak je viděna z hlediska aplikačního programu. Reprezentace dat v pohledu obvykle odpovídá datovému modelu databáze.

26
Výhody databázových systémů
Nezávislost aplikačních programů na změnách ve fyzickém uložení dat: při změnách ve fyzické struktuře báze dat není třeba měnit aplikační programy Ochrana dat před neoprávněným přístupem a poruchami: SŘBD kontroluje, zda uživatel je oprávněn používat data příslušným způsobem, znovuvytvoří bázi dat po selhání systému Odstranění redundance: každý údaj je v bázi dat ve většině případů uložen pouze jedenkrát. Sdílení dat: při využití SŘBD mohou být tatáž data používána několika uživateli; důležitou funkcí SŘBD je zajištění “paralelního” přístupu ke stejným datům z několika programů. Komplexní kontrola nerozpornosti (konzistence) dat: SŘBD centrálně kontroluje, aby některý aplikační program nepřivedl data do stavu, v němž by byla v rozporu s omezujícími podmínkami danými sémantikou reálného světa. (Nedovolí např. aby věk zaměstnance byl vyšší než jeho rodičů).
 dat: SŘBD centrálně kontroluje, aby některý aplikační program nepřivedl data do stavu, v němž by byla v rozporu s omezujícími podmínkami danými sémantikou reálného světa. (Nedovolí např. aby věk zaměstnance byl vyšší než jeho rodičů).")
27
Uživatelé vytvořené DB
Správce databáze - systémový programátor, který má celou databázi na starosti. Tento pracovník navrhuje konceptuální schéma DB, rekonstruuje ji v případě poškození, udílí práva přístupu a vyhodnocuje její využívání. Správcem databáze obvykle ve větších organizacích odborný útvar, který zahrnuje osoby odpovědné za výše uvedené záležitosti. Aplikační programátor je programátor profesionál - vytváří konkrétní aplikační programy a pracuje přitom s dílčí části schématu (např.pomocí SQL). Příležitostný uživatel nemá detailní znalosti programování, typické pro předchozí skupiny. Dokáže popsat strukturu své databáze, naplnit ji daty a formulovat své dotazy prostřednictvím QBE. Naivní (parametrický) uživatel používá jen hotové programy, předdefinované dotazy a pohybuje se pouze v oblasti nabídek (např. manipulantka při rezervaci letenek). Tato kategorie je stále početnější.
. Příležitostný uživatel nemá detailní znalosti programování, typické pro předchozí skupiny. Dokáže popsat strukturu své databáze, naplnit ji daty a formulovat své dotazy prostřednictvím QBE. Naivní (parametrický) uživatel používá jen hotové programy, předdefinované dotazy a pohybuje se pouze v oblasti nabídek (např. manipulantka při rezervaci letenek). Tato kategorie je stále početnější.")
28
Databáze na osobním počítači - vlastník počítače je zpravidla i uživatelem databáze a musí si tedy umět popsat data jako správce databáze. Mikropočítačové databáze proto používají jen velmi jednoduchého jazyka, který neklade přehnané nároky na uživatele. Uživatele databází na osobních počítačích lze tedy rozdělit na: Naivní uživatele, kteří používají jen hotové programy. Aplikační uživatele, kteří dokáží popsat strukturu své databáze, naplnit ji daty a formulovat své dotazy pomocí dotazovacího jazyka

29
Modelování reálného světa
Svět, který nás obklopuje je velmi složitý a je velmi obtížné jeho dílčí části databázově popsat. Jednotlivé etapy vedoucí k vytvoření odpovídající báze dat jsou následující: přípravná (koncepční) -navrhujeme schéma báze dat, tj. modelujeme reálný svět, technická - na počítači pomocí databázového prostředku vytváříme bázi dat, uživatelská -využíváme bázi dat, např. formou dotazů.
 -navrhujeme schéma báze dat, tj. modelujeme reálný svět, technická - na počítači pomocí databázového prostředku vytváříme bázi dat, uživatelská -využíváme bázi dat, např. formou dotazů.")
30
Tvorba báze dat

31
Domy a osoby jsou uvažovány jako množiny entit
Domy a osoby jsou uvažovány jako množiny entit. V tomto případě tedy vztah mezi domy a osobami definuje vztah mezi množinami entit. Takovýto vztah je nazýván jako asociace a může nabývat hodnot 1:1, 1:N nebo N:M.

32
Konceptuální modely relativně jednoduché grafické metody, které slouží k zachycení reálného světa. Nejrozšířenějším je E-R model (anglicky Entity-Relation), který je dnes všeobecně akceptován a je základem řady metodických souborů, především produktů CASE. - orientace na objekty (entity). Uvažuje se v objektech (čtenář, exemplář) a nikoliv v identifikacích, které je označují (Č_ČTENÁŘE, ISBN), funkcionální podstata vztahů, tj. vztahy mezi objekty jsou definovány jako funkce (MÁ_KOPIE), ISA-hierarchie (termín vypůjčený z umělé inteligence) umožňuje pracovat s nadtypy a podtypy typů objektů (KNIHA je - podtypem DOKUMENT,) hierarchický mechanismus pro konstrukci objektů z jiných objektů.
, který je dnes všeobecně akceptován a je základem řady metodických souborů, především produktů CASE. - orientace na objekty (entity). Uvažuje se v objektech (čtenář, exemplář) a nikoliv v identifikacích, které je označují (Č_ČTENÁŘE, ISBN), funkcionální podstata vztahů, tj. vztahy mezi objekty jsou definovány jako funkce (MÁ_KOPIE), ISA-hierarchie (termín vypůjčený z umělé inteligence) umožňuje pracovat s nadtypy a podtypy typů objektů (KNIHA je - podtypem DOKUMENT,) hierarchický mechanismus pro konstrukci objektů z jiných objektů.")
34
knihovna disponuje určitým počtem knih v několika exemplářích, které si vypůjčují a rezervují konkrétní čtenáři.

35
typy entit, jimž odpovídají množiny účelově vybraných odpovídajících objektů - entit. KNIHA, ČTENÁŘ označují typ entit, vlastními entitami je kniha s ISBN 310, čtenář I34 apod.; typy vztahů, do nichž entity vybraných typů mohou vstupovat. typům vztahů odpovídá příslušná množina objektů - vztahů. Např. ČTENÁŘ (typ entity) MÁ_VYPŮJČENO (typ vztahů) daný EXEMPÁŘ (typ entity). Entita čtenář I34 může být ve vztahu “MÁ_VYPŮJČENO” k entitě exemplář 00109; na základě přiměřené úrovně abstrakce přiřadí jednotlivým typům entit a vztahů atributy, které blíže popisují vlastnosti entit a vztahů. TITUL (údaj popisného typu) pro entity typu KNIHA, DAT_ZPĚT (údaj popisného typu), kdy daný čtenář vrátil daný exemplář, tj. jde o atribut vztahů mezi čtenáři a exempláři ( typ vztahu je MÁ_VYPŮJČENO); formulace příslušných integritních omezení vyjadřující s větší nebo menší přesností soulad vytvářeného schématu s modelovanou realitou (každý čtenář může mít vypůjčeno více exemplářů a každá kniha může být ve více exemplářích).
 MÁ_VYPŮJČENO (typ vztahů) daný EXEMPÁŘ (typ entity). Entita čtenář I34 může být ve vztahu MÁ_VYPŮJČENO k entitě exemplář 00109; na základě přiměřené úrovně abstrakce přiřadí jednotlivým typům entit a vztahů atributy, které blíže popisují vlastnosti entit a vztahů. TITUL (údaj popisného typu) pro entity typu KNIHA, DAT_ZPĚT (údaj popisného typu), kdy daný čtenář vrátil daný exemplář, tj. jde o atribut vztahů mezi čtenáři a exempláři ( typ vztahu je MÁ_VYPŮJČENO); formulace příslušných integritních omezení vyjadřující s větší nebo menší přesností soulad vytvářeného schématu s modelovanou realitou (každý čtenář může mít vypůjčeno více exemplářů a každá kniha může být ve více exemplářích).")
36
V datovém modelování se řeší jako hlavní problém transformace konceptuálního schématu do databázového modelu, jehož nejčastější případem je převod konceptuálního schématu E-R modelu do relačního modelu dat. V technické etapě se nejprve navrhne relační tabulka (tzv. univerzální relace) tak, že bude obsahovat všechny potřebné údaje.Ve většině případů se však v ní některé konkrétní hodnoty jednotlivých údajů budou opakovat vícekrát. Takovýto nadbytečný (redundantní) výskyt zbytečně zvětšuje velikost tabulky a prodlužuje tak její zpracování. Navíc představuje velké problémy při změnách (aktualizaci) těchto údajů. Tento nedostatek je nutno odstranit dekomponováním takovéto tabulky do více tabulek postupem, který je označován termínem normalizace. Jde o činnost, která vede od nesprávně navržené relační tabulky k jejímu přetvořenému normalizovanému tvaru (NF).
 tak, že bude obsahovat všechny potřebné údaje.Ve většině případů se však v ní některé konkrétní hodnoty jednotlivých údajů budou opakovat vícekrát. Takovýto nadbytečný (redundantní) výskyt zbytečně zvětšuje velikost tabulky a prodlužuje tak její zpracování. Navíc představuje velké problémy při změnách (aktualizaci) těchto údajů. Tento nedostatek je nutno odstranit dekomponováním takovéto tabulky do více tabulek postupem, který je označován termínem normalizace. Jde o činnost, která vede od nesprávně navržené relační tabulky k jejímu přetvořenému normalizovanému tvaru (NF).")
37
Normalizace dat představuje takový způsob seskupení datových prvků do struktur záznamů (dekompozice nenormalizovaných tabulek), který zabraňuje problémům s jejich aktualizací.
, který zabraňuje problémům s jejich aktualizací.")
38
NENORMALIZOVANÁ DATA Záznamy s opakujícími se skupinami dat Dekomponuj takovéto datové struktury do více vět (záznamů) 1. NORMÁLNÍ FORMA Záznamy bez opakujících se skupin dat Dekomponuj tak, aby všechny datové prvky závisely na primárním klíči 2. NORMÁLNÍ FORMA Všechna neklíčová data jsou funkčně závislá na primárním klíči Dekomponováním tabulky odstraň všechny tranzitivní závislosti 3. NORMÁLNÍ FORMA Všechna neklíčová data jsou plně funkčně nezávislá mezi sebou

40
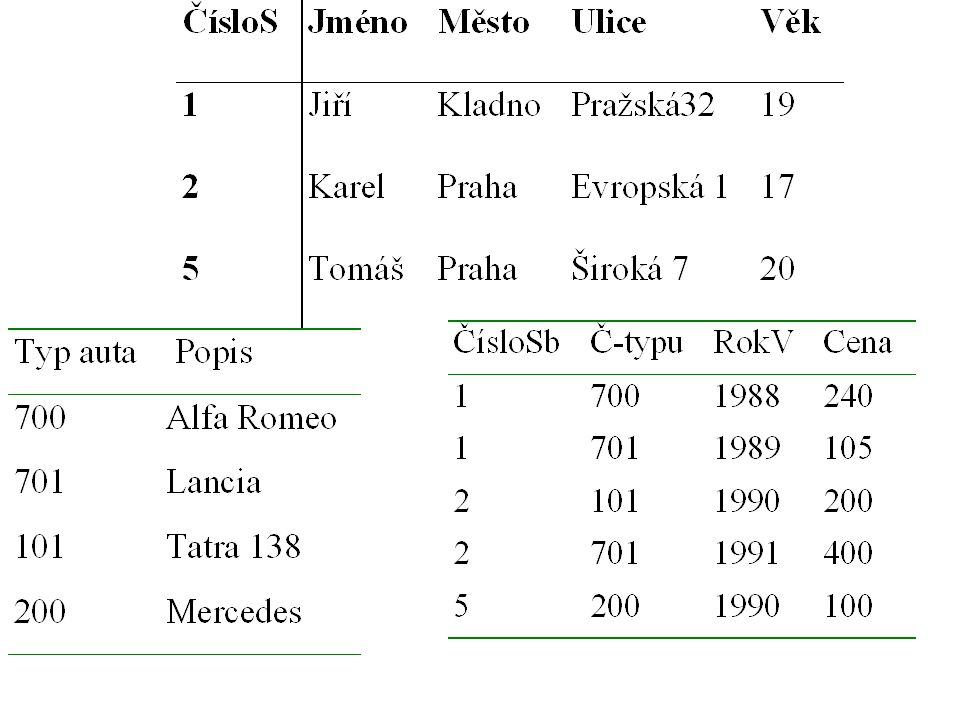
Nenormalizovaná tabulka
Sbírka

42
Vytvoření 1. normální formy:
Mějme relaci KNIHOVNA, kterou budeme normalizovat. Její struktura je následující: KNIHOVNA: (Kód_knihy, Název_knihy, Autor, Rok_vydání). Tato relace není 1. normální formě, protože některé knihy mohou mít více autorů (např. vědecké publikace). Proto ji musíme dekomponovat do dvou následujících relací. KNIHY: ( Kód_knihy, Název_knihy, Rok_vydání) AUTOŘI: (Kód_knihy, Autor). V relaci AUTOŘI se bude Kód_knihy opakovat na tolika řádcích, kolik autorů kniha má.
. Tato relace není 1. normální formě, protože některé knihy mohou mít více autorů (např. vědecké publikace). Proto ji musíme dekomponovat do dvou následujících relací. KNIHY: ( Kód_knihy, Název_knihy, Rok_vydání) AUTOŘI: (Kód_knihy, Autor). V relaci AUTOŘI se bude Kód_knihy opakovat na tolika řádcích, kolik autorů kniha má.")
43
Zavedení 2. normální formy:
Mějme relaci NABÍDKA s následující strukturou: NABÍDKA: (Podnik, Zboží, Množství, Adresa) Z uvedené relace vyplývá, že: - atribut Adresa závisí na atributu Podnik, - atribut Množství závisí na atributech Podnik a Zboží, - klíčem je dvouprvková množina Podnik,Zboží. Atribut Adresa na rozdíl od atributu Množství nezávisí sémanticky na celém klíči, ale jen na jeho podmnožině (tj. Podnik), což komplikuje případy, kdy podnik přestane vyrábět, protože pak musíme zrušit příslušné řádky o něm a tím ztrácíme informace o jeho existenci. Dalším nedostatkem je to, že pokud podnik změní svoji adresu, budeme muset opravit mnoho řádek.
 Z uvedené relace vyplývá, že: - atribut Adresa závisí na atributu Podnik, - atribut Množství závisí na atributech Podnik a Zboží, - klíčem je dvouprvková množina Podnik,Zboží. Atribut Adresa na rozdíl od atributu Množství nezávisí sémanticky na celém klíči, ale jen na jeho podmnožině (tj. Podnik), což komplikuje případy, kdy podnik přestane vyrábět, protože pak musíme zrušit příslušné řádky o něm a tím ztrácíme informace o jeho existenci. Dalším nedostatkem je to, že pokud podnik změní svoji adresu, budeme muset opravit mnoho řádek.")
44
Řešením těchto problémů je převedení relace do 2. normální formy
Řešením těchto problémů je převedení relace do 2. normální formy. Relace je v 2. normální formě, jestliže všechny její atributy závisí vždy na celém klíči a nikoli jen na jeho podmnožině. Proto bude nutno provést dekompozici do dvou následujících relací: PODNIKY: (Podnik, Adresa) NABIDKA: (Podnik, Zboží, Množství)
 NABIDKA: (Podnik, Zboží, Množství)")
45
Normalizace do 3. normální formy:
Předpokládejme relaci PROJEKTY s následující strukturou: PROJEKTY: (Číslo_zaměstnance, Jméno_zaměstnance, Plat, Projekt, Datum_dokončení) Tato relace má tyto nedostatky: - před získáním prvního zaměstnance pro daný projekt nelze zaznamenat datum jeho dokončení; - pokud všichni zaměstnanci opustí projekt, bude smazáno i datum jeho dokončení; - změnu datumu dokončení nutno provést u všech zaměstnanců pracujících na daném projektu.
 Tato relace má tyto nedostatky: - před získáním prvního zaměstnance pro daný projekt nelze zaznamenat datum jeho dokončení; - pokud všichni zaměstnanci opustí projekt, bude smazáno i datum jeho dokončení; - změnu datumu dokončení nutno provést u všech zaměstnanců pracujících na daném projektu.")
46
Řešením bude dekomponování relace do dvou následujících relací:
ZAMĚSTNANCI: (Číslo_zaměstnance, Jméno_zaměstnance, Plat, Projekt) PROJEKTY: (Projekt, Datum_dokončení)
 PROJEKTY: (Projekt, Datum_dokončení)")
47
Typy datových modelů Organizace dat je reprezentována datovým modelem, který představuje intelektuální prostředek umožňující porozumět logické organizaci dat. Abychom plně pochopili datový model, je nutno vyjít ze způsobu lidského vnímání, který dané údaje rozlišuje na několika úrovních. Na jedné úrovni lidé logicky organizují své vnímání reálného světa, na jiné úrovni tento svět interpretují (dávají mu smysl), na další úrovni používají pak datové modely k popisu a zaznamenání interpretace této reality ve formě dat vkládaných do počítače. V reálném světě vnímáme události vcelku i jednotlivě, tak jak odpovídají dané realitě. Jako pomůcku v těchto myšlenkových procesech a v komunikaci s ostatními lidmi užíváme modely reálného světa. V nich jsou podobné objekty obvykle sdruženy do tříd objektů zvaných typy objektů (Object types)
, na další úrovni používají pak datové modely k popisu a zaznamenání interpretace této reality ve formě dat vkládaných do počítače. V reálném světě vnímáme události vcelku i jednotlivě, tak jak odpovídají dané realitě. Jako pomůcku v těchto myšlenkových procesech a v komunikaci s ostatními lidmi užíváme modely reálného světa. V nich jsou podobné objekty obvykle sdruženy do tříd objektů zvaných typy objektů (Object types)")
48
třída objektů DOMY. Typ objektu se popisuje udáním seznamu jeho charakteristik, takže například typ objektu domy má charakteristiky adresa, typ domu, stavební styl a cena. typ objektu sám může být charakteristikou dalšího typu objektu; např. adresa je typ objektu s charakteristikami název ulice a číslo domu. Jestliže se však třída domů připojí k modelu světa, pak se adresa chápe jako charakteristika typu objektu domy. každá charakteristika může mít několik výskytů (Instances), např. charakteristika styl typu objektu domy zahrnuje následující výskyty: secesní, kubistický, funkcionalistický atd. Tyto výskyty charakteristik typu objektu se obvykle používají k rozlišení různých výskytů objektů v tomtéž typu objektu. Množina charakteristik, které jednoznačně identifikují objekt v jeho typu objektu, se nazývá klíč.
, např. charakteristika styl typu objektu domy zahrnuje následující výskyty: secesní, kubistický, funkcionalistický atd. Tyto výskyty charakteristik typu objektu se obvykle používají k rozlišení různých výskytů objektů v tomtéž typu objektu. Množina charakteristik, které jednoznačně identifikují objekt v jeho typu objektu, se nazývá klíč..")
49
Typy objektů, které existují nezávisle a mohou být smysluplně uvažovány samy o sobě, se interpretují jako množiny entit (Entity sets); např. typ objektu domy je množina entit. Množina entit je zcela popsána pomocí svých atributů (Attributes); např. množina entit domy je popsána atributy jako jsou adresa, typ domu, stavební styl a cena. Pro každou množinu entit mohou její atributy nabývat určitých hodnot; přičemž množina možných hodnot příslušného atributu se nazývá doména (Domain) atributu. Množina atributů, které jednoznačně determinují výskyt entity, se nazývá klíč.
 atributu. Množina atributů, které jednoznačně determinují výskyt entity, se nazývá klíč.")
50
Typy datových modelů síťový hierarchický relační objektový

51
Síťový datový model Síťový datový model (Network data model) je základem běžně používaných databázových systémů na velkých počítačích a představuje souhrn navzájem propojených segmentů tak, že jednotlivé datové struktury vytvářejí síť. Každý segment představuje vstup do této struktury a vlastní propojení je realizováno přes uložené adresy, tzv. ”spojky”. Tento model se tedy sestává z typů záznamů a spojek.

52
Hierarchický model V tomto modelu jsou data uspořádána podle tzv
Hierarchický model V tomto modelu jsou data uspořádána podle tzv.hierarchických stromů (např. ZEMĚ, STÁT, HLAVNÍ MĚSTO, MĚSTO, ...). Každý uzel tohoto stromu reprezentuje typ záznamu a každá hrana spojku mezi dvěma typy záznamů. V hierarchickém stromu existuje jeden speciální význačný typ záznamu, tzv. kořen. Ostatní typy záznamů se nazývají závislé typy záznamů a jsou ve struktuře hierarchického stromu na nižší úrovni.(rodiče a potomci)
. Každý uzel tohoto stromu reprezentuje typ záznamu a každá hrana spojku mezi dvěma typy záznamů. V hierarchickém stromu existuje jeden speciální význačný typ záznamu, tzv. kořen. Ostatní typy záznamů se nazývají závislé typy záznamů a jsou ve struktuře hierarchického stromu na nižší úrovni.(rodiče a potomci)")
53
Relační datový model Princip tohoto modelu jako první popsal v roce 1969 E. F. Codd, matematik z laboratoře IBM v San Jose. Relační datový model je důsledně budován na teoretickém základě, tj. je definována struktura dat a povolené operace nad nimi. Základním pojmem teorie relačních datových bází je relace (neformálně prezentována jako tabulka). V relační bázi dat jsou datové soubory chápány jako množiny. Z uživatelského hlediska jsou data v relačním datovém modelu uspořádána v dvourozměrných tabulkách. Každá samostatná tabulka je označována termínem relace, je tvořena záhlavím, kde jsou specifikována jména sloupců (nazývaných též atributy tabulky) a řádky (označovanými jako n-tice podle toho, že sdružují hodnoty z n sloupců tabulky). Každý sloupec obsahuje hodnoty určitého datového typu, přičemž obor těchto hodnot, které se v daném sloupci mohou vyskytovat, se nazývá doména sloupce nebo atributu.
. V relační bázi dat jsou datové soubory chápány jako množiny. Z uživatelského hlediska jsou data v relačním datovém modelu uspořádána v dvourozměrných tabulkách. Každá samostatná tabulka je označována termínem relace, je tvořena záhlavím, kde jsou specifikována jména sloupců (nazývaných též atributy tabulky) a řádky (označovanými jako n-tice podle toho, že sdružují hodnoty z n sloupců tabulky). Každý sloupec obsahuje hodnoty určitého datového typu, přičemž obor těchto hodnot, které se v daném sloupci mohou vyskytovat, se nazývá doména sloupce nebo atributu.")
54
Základní pojmy relace (tabulka) atribut - vlastnost objektu
doména - množina hodnot, kterých může nabývat atribut primární klíč - položka jednoznačně identifikující jednotlivé záznamy složený klíč - z více položek index – datová struktura pro udržování pořadí záznamů, umožňuje zobrazovat záznamy v pořadí odlišném od pořadí určeného primárním klíčem

55
Databáze jsou rozčleněny do posloupnosti řádků a sloupců tak, aby každá část informace byla snadno dostupná. Každý takovýto sloupec má záhlaví, které popisuje typ informace, řádky pak obsahují vlastní údaje. V relační databázové terminologii je sloupec nazýván položkou a řádek záznamem neboli větou. Průsečík řádku a sloupce je označován jako pole. Každé pole může obsahovat pouze hodnoty takového datového typu, který je specifikován pro příslušný sloupec.

56
věta (angl. record) je souhrnem všech údajů o jednom objektu uloženém v databázi, např. o jedné knize nebo o jednom účastníkovi telefonní sítě. V případě kartičkového systému evidence odpovídá jeden záznam databáze jedné konkrétní kartičce takovéhoto katalogu. Sloupce tabulky reprezentují jednotlivé vlastnosti neboli atributy objektů, tedy jednotlivé druhy údajů o objektech, které chceme evidovat. Všechny takovéto záznamy v rámci jedné tabulky mají stejnou strukturu, která obsahuje několik vždy stejných položek (polí, angl. fields), které odpovídají vlastnostem (atributům) sledovaných objektů. V případě telefonního seznamu např. jméno účastníka, příjmení účastníka, adresa, jeho telefonní číslo atd. Každá takováto položka musí mít svůj název a typ. Název musí jednoznačně identifikovat, o kterou položku se jedná. V případě telefonního seznamu je možno jeho položky pojmenovat např. JMENO, PRIJMENI, ADRESA, OBVOD a TEL_CISLO. Typ položky určuje, jakého druhu jsou údaje v položce obsažené
, které odpovídají vlastnostem (atributům) sledovaných objektů. V případě telefonního seznamu např. jméno účastníka, příjmení účastníka, adresa, jeho telefonní číslo atd. Každá takováto položka musí mít svůj název a typ. Název musí jednoznačně identifikovat, o kterou položku se jedná. V případě telefonního seznamu je možno jeho položky pojmenovat např. JMENO, PRIJMENI, ADRESA, OBVOD a TEL_CISLO. Typ položky určuje, jakého druhu jsou údaje v položce obsažené.")
57
znakový (charakter) - používá se pro textové údaje (např
znakový (charakter) - používá se pro textové údaje (např. názvy zboží, jména účastníků); může obsahovat písmena, číslice i znaky cizích abeced, maximální délka údaje je 255 znaků; číselný (numeric, float) - je určen pro číselné údaje (např. množství, cena), může obsahovat pouze číslice, řádovou tečku a znaky plus (+) a mínus (-). je nutné uvést počet desetinných míst; datumový (date) - slouží pro zaznamenání datumu (např. DD-MM-RR - den, měsíc, rok, nebo MM-DD-RR, apod.); logický (logical) - umožňuje záznam pouze dvou hodnot: “1” interpretovaná jako pravda (true) a “0” jako nepravda (false); slouží k rozlišení jednoduchých stavů, např. zaplaceno - nezaplaceno, zdravý - nemocný atd.; poznámkový (memo) - rozsah údaje není omezen; rozsáhlé popisy ( charakteristika předmětu, obsah knihy, apod.); obrazový (picture) - obrázek ve zvoleném grafickém formátu Název a typ položky je stejný pro všechny záznamy v dané konkrétní databázi
 - používá se pro textové údaje (např. názvy zboží, jména účastníků); může obsahovat písmena, číslice i znaky cizích abeced, maximální délka údaje je 255 znaků; číselný (numeric, float) - je určen pro číselné údaje (např. množství, cena), může obsahovat pouze číslice, řádovou tečku a znaky plus (+) a mínus (-). je nutné uvést počet desetinných míst; datumový (date) - slouží pro zaznamenání datumu (např. DD-MM-RR - den, měsíc, rok, nebo MM-DD-RR, apod.); logický (logical) - umožňuje záznam pouze dvou hodnot: 1 interpretovaná jako pravda (true) a 0 jako nepravda (false); slouží k rozlišení jednoduchých stavů, např. zaplaceno - nezaplaceno, zdravý - nemocný atd.; poznámkový (memo) - rozsah údaje není omezen; rozsáhlé popisy ( charakteristika předmětu, obsah knihy, apod.); obrazový (picture) - obrázek ve zvoleném grafickém formátu. Název a typ položky je stejný pro všechny záznamy v dané konkrétní databázi.")
58
. Jeden sloupec v relační tabulce musí vždy jednoznačně specifikovat jednotlivé řádky a je označován jako primární klíč (angl. key). Obvykle by měl figurovat jako první sloupec v tabulce. V případě seznamu telefonních účastníků jím může být příjmení účastníka. Protože však může existovat více účastníků stejného příjmení, je nutno doplnit tento klíč o další položku, tj. jméno účastníka. Toto křestní jméno se stává tzv. sekundární klíčovou položkou. Je-li tedy zapotřebí použít více sloupců pro jednoznačné určení řádků, mluvíme pak o tzv. složeném klíči.
. Obvykle by měl figurovat jako první sloupec v tabulce. V případě seznamu telefonních účastníků jím může být příjmení účastníka. Protože však může existovat více účastníků stejného příjmení, je nutno doplnit tento klíč o další položku, tj. jméno účastníka. Toto křestní jméno se stává tzv. sekundární klíčovou položkou. Je-li tedy zapotřebí použít více sloupců pro jednoznačné určení řádků, mluvíme pak o tzv. složeném klíči..")
60
relační tabulka : všechny hodnoty v tabulce musí být elementární, tj. dále nedělitelné na další údaje; v tabulce je 1 až n sloupců, přičemž jejich pozice je nevýznamná, tj. pořadí těchto sloupců lze libovolně měnit; v tabulce je 0 až m řádků, jejichž pozice je rovněž nevýznamná, tj. pořadí řádků lze libovolně měnit; sloupec musí být homogenní, tj. obor hodnot tohoto sloupce musí být stejný (údaje stejného druhu); každý sloupec musí být jednoznačně pojmenován, toto jméno je tzv. atribut; každý řádek tabulky musí být jednoznačně rozlišitelný, v tabulce nesmí existovat dva stejné řádky shodující se ve všech sloupcích.
; každý sloupec musí být jednoznačně pojmenován, toto jméno je tzv. atribut; každý řádek tabulky musí být jednoznačně rozlišitelný, v tabulce nesmí existovat dva stejné řádky shodující se ve všech sloupcích.")
61
Relační algebra formální matematický aparát pro práci s relacemi
množina objektů a určité operace nad touto množinou, výsledkem operace je prvek algebry př. (celá čísla, +, -), (reálná čísla, *, /) Relační algebra množinou objektů jsou relace operace : selekce, projekce, spojení, průnik, rozdíl
, (reálná čísla, *, /) Relační algebra. množinou objektů jsou relace. operace : selekce, projekce, spojení, průnik, rozdíl.")
62
Relační algebra Vytvořené a naplněné tabulky jsou předpokladem pro jejich další využívání. Nejčastější forma takovéto využití je realizace dotazů, v nichž uživatel specifikuje své požadavky na vyhledání konkrétních informací. Pro tento účel existuje formální matematický aparát - relační algebra, který popisuje vlastnosti jednotlivých relačních operací (selekce, projekce a spojení) a představuje teoretický nástroj k objasnění postupů manipulace s relacemi.
 a představuje teoretický nástroj k objasnění postupů manipulace s relacemi.")
63
Základní operace relační algebry nezbytné a zároveň postačující pro tvorbu jakéhokoliv uživatelského dotazu : Operace projekce (project) Slouží pro potlačení označených sloupců (atributů). Výsledkem je relace o p-sloupcích, která vznikla z původní relace s n-sloupci, přičemž platí, že pn. Schematicky lze tuto operaci znázornit takto:

64
Operace selekce (select) Při této operaci vzniká nová relace, do které jsou vybírány pouze ty řádky (záznamy) z původní tabulky, které splňují uživatelem specifikovanou podmínku.
 Při této operaci vzniká nová relace, do které jsou vybírány pouze ty řádky (záznamy) z původní tabulky, které splňují uživatelem specifikovanou podmínku.")
65
Operace spojení (join) je jednou z hlavních operací relační algebry
Operace spojení (join) je jednou z hlavních operací relační algebry. Spojením dvou relací se vytváří třetí relace. Tato výsledná tabulka vždy obsahuje všechny kombinace, které vyhovují zadané podmínce. Podle způsobu porovnání hodnot ve spojovaných sloupcích se rozlišují 3 druhy spojení: - na rovnost, na nerovnost, vnější - inkluze, řádky vzniknou zřetězením těch řádků první tabulky s takovými řádky 2. tabulky, ve kterých je splněna podmínka týkající se vztahu 2 srovnatelných atributů výchozích relací.
 je jednou z hlavních operací relační algebry. Spojením dvou relací se vytváří třetí relace. Tato výsledná tabulka vždy obsahuje všechny kombinace, které vyhovují zadané podmínce. Podle způsobu porovnání hodnot ve spojovaných sloupcích se rozlišují 3 druhy spojení: - na rovnost, na nerovnost, vnější - inkluze, řádky vzniknou zřetězením těch řádků první tabulky s takovými řádky 2. tabulky, ve kterých je splněna podmínka týkající se vztahu 2 srovnatelných atributů výchozích relací.")
66
Dotazovací prostředky v databázovém technologii
tvorba uživatelských dotazů na data, která jsou uložena v bázi dat. Každý je funkcí, která z dané množiny všech údajů báze dat vybírá takovou podmnožinu, která je pro uživatele v daném okamžiku důležitá. Tyto dotazy jsou předurčeny existujícím dotazovacím prostředkem neboli dotazovacím jazykem, který představuje souhrn prostředků umožňující snadné zadávání úloh pro relační databáze. Podle způsobu zadávání těchto dotazů rozlišujeme dotazovací prostředky na jazyky procedurální a neprocedurální. Procedurální jazyky - je nutné zadat algoritmus pro získání požadované odpovědi. Z tohoto důvodu jsou určeny především pro profesionální programátory ( např. jazyk COBOL). Neprocedurální jazyky jsou mnohem jednodušší, neboť vyžadují pouze zadat podmínky, které má požadovaná odpověď splňovat.
. Neprocedurální jazyky jsou mnohem jednodušší, neboť vyžadují pouze zadat podmínky, které má požadovaná odpověď splňovat.")
67
jazyk SQL (Structured Query Language - strukturovaný dotazovací jazyk), při jeho tvorbě byla dodržena zásada přiblížit specifikování dotazu principu kladení otázek v přirozeném jazyce, tj. v angličtině; jazyk QBE (Query By Example), umožňuje zadávání dotazů v grafické podobě většinou na základě interaktivní komunikace mezi databázovým systémem a uživatelem, přičemž vlastní dotaz je sestavován pomocí určitých symbolů zapisovaných do dotazovacích formulářů. Oba dva typy dotazovacích jazyků jsou značně rozšířeny a umožňují řešit všechny operace relační algebry. Z tohoto důvodu jsou také označovány jako dotazovací jazyky relačně úplné. umožňují i aritmetické výpočty (např. ze dvou sloupců vypočítat třetí údaj, tzv. dopočítanou neboli odvozenou položku) a agregační funkce (např. funkce SUM pro vyčíslení součtu hodnot v určitém sloupci za celou tabulku).
, umožňuje zadávání dotazů v grafické podobě většinou na základě interaktivní komunikace mezi databázovým systémem a uživatelem, přičemž vlastní dotaz je sestavován pomocí určitých symbolů zapisovaných do dotazovacích formulářů. Oba dva typy dotazovacích jazyků jsou značně rozšířeny a umožňují řešit všechny operace relační algebry. Z tohoto důvodu jsou také označovány jako dotazovací jazyky relačně úplné. umožňují i aritmetické výpočty (např. ze dvou sloupců vypočítat třetí údaj, tzv. dopočítanou neboli odvozenou položku) a agregační funkce (např. funkce SUM pro vyčíslení součtu hodnot v určitém sloupci za celou tabulku).")
68
Jazyk QBE konkrétní podobu prostředku QBE lze demonstrovat na příkladu relačně databázového prostředku ACCESS.

69
Sestavený dotaz lze realizovat tlačítkem Otevřít
Sestavený dotaz lze realizovat tlačítkem Otevřít. QBE je v jednotlivých databázových prostředcích různě implementován, SQL má obecnější charakter

70
Syntaxe příkazu SQL Syntaxe příkazů jazyka SQL je následující:
.Klíčová slova příkazů jsou zapsána velkými písmeny. V lomených závorkách jsou zapsány syntaktické konstrukce, místo kterých je třeba doplnit konkrétní tvary. Nepovinné části příkazů jsou uzavřeny v hranatých závorkách . Svislou čarou jsou odděleny volitelné varianty. Jsou-li varianty uzavřeny ve složených závorkách , musí být jedna z nich použita. Tři tečky ... vyjadřují, že konstrukce v předchozí závorce se může opakovat.

71
EXEMPLÁŘ (relace evidující údaje o jednotlivých exemplářích v dané knihovně)
")
72
VÝPŮJČKA (relace evidující údaje o příslušných výpůjčkách v dané knihovně)
")
73
ČTENÁŘ (relace zachycující čtenáře, kteří navštěvují danou knihovnu)
")
74
REZERV (relace zachycující požadavky čtenářů na rezervování knih)
")
75
Definice tabulky v SQL CREATE TABLE, ALTER TABLE a DROP TABLE.
CREATE TABLE specifikuje jméno vytvářené tabulky a pro každý sloupec se určí jeho jméno a datový typ. Syntaxe tohoto příkazu je následující: CREATE TABLE jméno-tabulky (jméno-sloupce datový- typ NOT NULL ,jméno-sloupce datový- typ NOT NULL... Přidáním klíčových slov NOT NULL k popisu sloupce se zabezpečí, že všechna pole v daném sloupci nesmí obsahovat hodnotu NULL, tj. při vkládání řádků musí být hodnota pole zadána. Tento parametr se využívá především v souvislosti s definicí klíče.

76
SQL umožňuje definovat následující typy atributů (dle normy ANSI):
INTEGER celé číslo se znaménkem ve 4 bytech; SMALLINT celé číslo se znaménkem ve 2 bytech; DECIMAL(p,q) desetinné číslo se znaménkem, celkový počet míst p (1=p=15); FLOAT reálné číslo v pohyblivé řádové čárce se znaménkem v 8 bytech (mantisa je tvořena 14 bity); CHAR(n) Znakový řetězec pevné délky n (1= n = 240); VARCHAR(n) Znakový řetězec maximální délky n. V některých produktech je navíc implementován datový typ DATE pro reprezentaci smysluplného datumu.
 desetinné číslo se znaménkem, celkový počet míst p (1=p=15); FLOAT reálné číslo v pohyblivé řádové čárce se znaménkem v 8 bytech (mantisa je tvořena 14 bity); CHAR(n) Znakový řetězec pevné délky n (1= n = 240); VARCHAR(n) Znakový řetězec maximální délky n. V některých produktech je navíc implementován datový typ DATE pro reprezentaci smysluplného datumu.")
77
Výše uvedenou tabulku ČTENÁŘ lze vytvořit následujícím příkazem CREATE TABLE:
CREATE TABLE ČTENÁŘ (Č-ČT CHAR(4) NOT NULL, JMÉNO VARCHAR(30), ADRESA VARCHAR(50)); Po zadání a odeslání tohoto příkazu se vytvoří prázdná relace ČTENÁŘ, přičemž jméno této relace a typy atributů se zaznamenají do systémového katalogu.
 NOT NULL, JMÉNO VARCHAR(30), ADRESA VARCHAR(50)); Po zadání a odeslání tohoto příkazu se vytvoří prázdná relace ČTENÁŘ, přičemž jméno této relace a typy atributů se zaznamenají do systémového katalogu.")
78
Změny dat v tabulkách (aktualizace)
Jazyk SQL umožňuje vkládání dat příkazem INSERT, rušení dat příkazem DELETE a opravu uložených dat příkazem UPDATE. Na data uložená v tabulkách jsou však kladena určitá omezení, označovaná jako integritní omezení (dále jen IO). Je požadováno, aby data v každém okamžiku vyhovovala těmto IO, tj. aby aktualizace převáděly tabulky ze stavu vyhovujícího IO do stavu rovněž vyhovujícímu IO. V této souvislosti je nutno poznamenat, že respektování integritních omezení je velkou slabinou jazyka SQL. Většina implementací totiž zajišťuje pouze entitní integritu pomocí definování jednoznačného indexu. Zajištění zbývajících dvou integritních omezení je zcela ponecháno na tvůrci databáze nebo uživateli.
. Je požadováno, aby data v každém okamžiku vyhovovala těmto IO, tj. aby aktualizace převáděly tabulky ze stavu vyhovujícího IO do stavu rovněž vyhovujícímu IO. V této souvislosti je nutno poznamenat, že respektování integritních omezení je velkou slabinou jazyka SQL. Většina implementací totiž zajišťuje pouze entitní integritu pomocí definování jednoznačného indexu. Zajištění zbývajících dvou integritních omezení je zcela ponecháno na tvůrci databáze nebo uživateli.")
79
Vkládání dat do vytvořené tabulky
Vlastní data se do vytvořené tabulky vkládají pomocí příkazu INSERT, vždy po jedné n-tici. Pro výše uvedenou tabulku ČTENÁŘ bude mít tento příkaz následující podobu: INSERT INTO ČTENÁŘ VALUES (‘A100',’Karel Novák’,’PRAHA 1’); INSERT INTO ČTENÁŘ VALUES (‘A123',’Jiří Klouček’,’PRAHA 1’); atd
; INSERT INTO ČTENÁŘ VALUES (‘A123 ,’Jiří Klouček’,’PRAHA 1’); atd.")
80
Modifikování struktury tabulky
Pro dodatečné modifikování struktury vytvořené tabulky slouží příkaz ALTER TABLE, jehož syntaxe je následující: ALTER TABLE jméno-tabulky ADD jméno-sloupce datový-typ , jméno-sloupce datový-typ ... Pokud bychom nyní chtěli například dodatečně modifikovat strukturu relace ČTENÁŘ přidáním atributu DAT_NAR, museli bychom odeslat příkaz ALTER TABLE následujícího tvaru: ALTER TABLE ČTENÁŘ ADD DAT_NAR DATE;

81
Rušení záznamů Odstranění určitých záznamů z dané relace zajistí příkaz DELETE, který má následující syntaxi: DELETE FROM jméno-tabulky WHERE výběrová-podmínka Příklad: předpokládejme požadavek na zrušení všech záznamů, pro něž platí, že hodnota atributu ZEMĚ_VYD je rovna GB. Tomu odpovídající příkaz DELETE bude mít následující tvar: DELETE FROM EXEMPLÁŘ WHERE ZEMĚ_VYD=’GB’;

82
Opravy dat Modifikaci relace lze provádět na jedné specifikované n-tici nebo na množině n-tic pomocí příkazu UPDATE. Syntaxe tohoto příkazu je následující: UPDATE jméno-tabulky SET jméno-sloupce = hodnota ,jméno-sloupce = hodnota ... WHERE výběrová-podmínka Výběrová podmínka specifikuje řádky, kterých se oprava týká, přičemž opravu lze provádět i ve více sloupcích tabulky najednou.

83
Příklad: Předpokládejme následující požadavek modifikace relace EXEMPLÁŘ, který spočívá ve změně hodnoty atributu CENA na novou hodnotu rovnou 300 pro exemplář s ISBN rovným hodnotě 900. Tomu bude odpovídat následující příkaz UPDATE: UPDATE EXEMPLÁŘ SET CENA=300 WHERE ISBN=’900’; Zreálnění cen všech exemplářů dražších 300 Kč na 50% hodnotu lze zajistit následujícím příkazem: SET CENA=CENA/2 WHERE CENA > 300’;

84
Zrušení relace Zrušení relace se provede pomocí příkazu DROP, jehož syntaxe je následující: DROP TABLE jméno-tabulky Příklad: Zjistíme-li, že rezervace knih se již v knihovně nebudou provádět, příslušnou relaci (tj. REZERV) zrušíme následujícím příkazem: DROP TABLE REZERV; V souvislosti s tímto příkazem je nutno upozornit, že v takovémto případě se zruší i případné indexové soubory existující k dané relaci.
 zrušíme následujícím příkazem: DROP TABLE REZERV; V souvislosti s tímto příkazem je nutno upozornit, že v takovémto případě se zruší i případné indexové soubory existující k dané relaci.")
85
Dotazy v SQL Základem dotazovacího jazyka SQL je příkaz SELECT (česky vyber). Syntaxe tohoto příkazu je následující: SELECT DISTINCT seznam-sloupců FROM jméno-tabulky , jméno-tabulky ... WHERE výběrová-podmínka GROUP BY seznam-sloupců HAVING výběrová-podmínka ORDER BY jméno-sloupce ASC DESC ,jméno-sloupce ASC DESC ...

86
seznam sloupců (oddělený čárkami), které mají být v požadované odpovědi obsaženy. FROM specifikuje tabulku, z které jsou data vybírána a WHERE specifikuje podmínku na výběr řádků, tj. v odpovědi budou pouze ty řádky, které splňují tuto podmínku. Chybí-li klausule WHERE, budou vybrány všechny řádky dané tabulky. Příklad: Požadavek na výpis sloupců Č_ČT a JMÉNO z tabulky ČTENÁŘ pomocí SELECT v následujícím tvaru: SELECT Č_ČT,JMENO FROM ČTENÁŘ; Odpovědí na tento dotaz bude následující výběr: Č_ČT JMÉNO A Karel Novák A Jiří Klouček B Karel Kalaš B Martin Haleš D Libor Dvořák operace projekce relační algebry.

87
Požadavek na výpis všech sloupců dané tabulky lze zkrátit zadáním hvězdičky místo seznamu sloupců. Následující příkaz vybírá všechny data ze specifikované tabulky (tj. ČTENÁŘ): SELECT * FROM ČTENÁŘ; Výsledkem tohoto příkazu bude tento výběr: Č_ČT JMÉNO ADRESA A Karel Novák PRAHA 1 A Jiří Klouček PRAHA 1 B Karel Kalaš PRAHA 9 B Martin Haleš PRAHA 3 D Libor Dvořák PRAHA 9

88
Příklad: Výběr záznamů o čtenářích, kteří bydlí v Praze 1
Příklad: Výběr záznamů o čtenářích, kteří bydlí v Praze 1. Takovémuto požadavku bude odpovídat následující příkaz SELECT: SELECT * FROM ČTENÁŘ WHERE ADRESA=PRAHA 1; Výsledkem takto specifikovaného příkazu pak bude tento výběr těchto záznamů: Č_ČT JMÉNO ADRESA A Karel Novák PRAHA 1 A Jiří Klouček PRAHA 1

Podobné prezentace