Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Vyhledávání v multimediálních databázích Tomáš Skopal KSI MFF UK 7. Metrické přístupové metody (MAM) 2. část – maticové a statické metody, D-index
 2. část – maticové a statické metody, D-index.")
2
Osnova maticové MAM AESA, LAESA statické MAM gh-strom GNAT vp-strom mvp-strom SAT metrické hašování – D-index metody volby globálních pivotů

3
AESA/LAESA (1) (Linear) Approximating and Eliminating Search Algorithm volba globálních pivotů u AESA je počet pivotů roven |S| tj. při přidání objektu do S vzroste i počet pivotů u LAESA se vybere konstantní počet pivotů k < |S| při přidání objektu do S se pivoty nemění konstrukce matice vzdáleností (index) od pivotů k objektům v S AESA – časová i prostorová složitost O(n 2 ), po přidání nového objektu O do S (což je taky pivot) je potřeba do matice přidat a spočítat sloupec vzdáleností od O ke všem ostatním objektům LAESA – časová i prostorová složitost O(kn)
 od pivotů k objektům v S AESA – časová i prostorová složitost O(n 2 ), po přidání nového objektu O do S (což je taky pivot) je potřeba do matice přidat a spočítat sloupec vzdáleností od O ke všem ostatním objektům LAESA – časová i prostorová složitost O(kn).")
4
AESA/LAESA (2) úzká spojitost s kontraktivní pivot-based metodou matice vzdáleností = mapování do vektorového prostoru dimenze k při dotazování se využívá L metrika (v kombinaci s původní metrikou; to navíc dovoluje implementovat i kNN dotazy)
 úzká spojitost s kontraktivní pivot-based metodou matice vzdáleností = mapování do vektorového prostoru dimenze k při dotazování se využívá L metrika (v kombinaci s původní metrikou; to navíc dovoluje implementovat i kNN dotazy)")
5
AESA/LAESA (2) původně určeno pro NN dotazy AESA – průměrná složitost vyhledání je O(1) – experimentálně LAESA – průměrná složitost vyhledání je k + O(1) – experiment. lze modifikovat i pro kNN a rozsahové dotazy pro kNN se udržuje k kandidátů implementace rozsahového dotazu je triviální – přímé odfiltrování objektů podle L metriky (kontraktivní vzdálenosti) a dofiltrování původní metrikou d optimalizováno pouze pro minimalizaci počtu aplikací původní metriky tj. database „un-friendly“, prochází se sekvenčně celá matice
 a dofiltrování původní metrikou d optimalizováno pouze pro minimalizaci počtu aplikací původní metriky tj. database „un-friendly , prochází se sekvenčně celá matice.")
6
NN dotaz - AESA podobný algoritmus jako hledání nejbližšího souseda v A i u kontraktivního SparseMap mapování (viz předchozí přednáška) myšlenka: počítají se průběžně hodnoty mapovaného vektoru q pro dotaz Q a zároveň se filtrují irelevantní objekty (resp. příslušné vektory) Algoritmus: 1) (inicializace) Mějme NN dotaz Q a neprázdnou množinu pivotů S’ = S. Aktuální vzdálenost k nejbližšímu sousedovi O nn nechť je d min = . 2) Náhodně se vybere pivot P S’ 3) Spočítá se vzdálenost d(Q, P), tj. nějaká souřadnice mapovaného vektoru q. Pokud d min > d(Q, P), pak d min := d(Q, O nn ) a O nn := P. S’ := S’ – {P}. 4) (eliminace) Z S se odfiltrují objekty O i, pro jejichž vektory platí L (q, o i ) > d min. U o i se uvažují pouze ty souřadnice, které už byly vypočítány i pro q. 5) (aproximace) Pokud je S’ již prázdná, NN byl nalezen (je to O nn ) a algoritmus končí, jinak se nalezne ten pivot P S’, jehož vektor p má nejmenší L (q, p). 6) Opakuje se od kroku 3, až než se odfiltrují všechny objekty z S (tj. zbude jediný kandidát O nn – pravý nejbližší soused)
 Algoritmus: 1) (inicializace) Mějme NN dotaz Q a neprázdnou množinu pivotů S’ = S. Aktuální vzdálenost k nejbližšímu sousedovi O nn nechť je d min = . 2) Náhodně se vybere pivot P S’ 3) Spočítá se vzdálenost d(Q, P), tj. nějaká souřadnice mapovaného vektoru q. Pokud d min > d(Q, P), pak d min := d(Q, O nn ) a O nn := P. S’ := S’ – {P}. 4) (eliminace) Z S se odfiltrují objekty O i, pro jejichž vektory platí L (q, o i ) > d min. U o i se uvažují pouze ty souřadnice, které už byly vypočítány i pro q. 5) (aproximace) Pokud je S’ již prázdná, NN byl nalezen (je to O nn ) a algoritmus končí, jinak se nalezne ten pivot P S’, jehož vektor p má nejmenší L (q, p). 6) Opakuje se od kroku 3, až než se odfiltrují všechny objekty z S (tj. zbude jediný kandidát O nn – pravý nejbližší soused).")
7
NN dotaz - LAESA lze implementovat dvěma způsoby jednofázově – podobně jako AESA souřadnice mapovaného dotazového objektu se počítají postupně a zároveň se filtruje výhodné, když k je velké, resp. srovnatelné s |S| modifikace oproti AESA je v tom, že pivotů je méně – S’ S – a tudíž po vyčerpání všech pivotů se zbytek neodfiltrovaných objektů zpracuje dvoufázovým způsobem (kde odpadá první krok, protože vektor q už je celý spočítaný) dvoufázově 1) spočítá se nejdříve celý vektor q mapovaného dotazového objektu Q 2) objekty O i S se setřídí vzestupně podle vzdáleností L (q, o i ) 3) v tomto pořadí se počítá se d(Q, O i ), podle toho se aktualizuje kandidát O nn na nejbližšího souseda a jakmile d(Q, O nn ) < L (q, o i ), filtrování končí (neexistuje žádný bližší kandidát než O nn ) - tj. O nn je výsledek
 dvoufázově 1) spočítá se nejdříve celý vektor q mapovaného dotazového objektu Q 2) objekty O i S se setřídí vzestupně podle vzdáleností L (q, o i ) 3) v tomto pořadí se počítá se d(Q, O i ), podle toho se aktualizuje kandidát O nn na nejbližšího souseda a jakmile d(Q, O nn ) < L (q, o i ), filtrování končí (neexistuje žádný bližší kandidát než O nn ) - tj. O nn je výsledek.")
8
AESA/LAESA - zobecnění pro kNN u algoritmu AESA se v kroku 5 (aproximace) neuvažuje pouze nejbližší vektor, ale k nejbližších vektorů – d min je potom nastaveno na vzdálenost d min := min(d min, d k ) d k je maximum ze vzdáleností d(Q, P i ), kde P i jsou pivoty příslušné těm k vektorům u dvoufázového algoritmu LAESA se v kroku 3 aktualizuje k kandidátů (místo jednoho) a filtruje se podle toho nejvzdálenějšího (nejvzdálenějšího podle d) srovnání jednofázového a dvoufázového algoritmu jednofázový alg. je výhodný pokud k je vysoké (v krajním případě k = |S|, tj. případ AESA), tj. dvoufázový algoritmus by v prvním kroku sekvenčně „prohledal“ značnou část S dvoufázový je výhodný pro malé k, protože po jednorázovém namapování je potřeba setřídit vektory podle L pouze jednou, čímž se redukují ostatní CPU náklady
, tj. dvoufázový algoritmus by v prvním kroku sekvenčně „prohledal značnou část S dvoufázový je výhodný pro malé k, protože po jednorázovém namapování je potřeba setřídit vektory podle L pouze jednou, čímž se redukují ostatní CPU náklady.")
9
(L)AESA – rozšíření pro rozsahový dotaz Algoritmus: 1)Mějme rozsahový dotaz (Q, r Q ) 2)Zvolí se „malý“ počet pivotů k. 3)Dopočítá se příslušný počet souřadnic vektoru dotazu q. 4)Sekvenčně se procházejí (zbylé) vektory v S a filtrují se podle k dimenzí, tj. jsou odfiltrovány ty objekty, pro které L (q, o i ) > r Q. 5)Pokud zbyl v S “malý” počet objektů (anebo byly vyčerpány všechny pivoty), zbytek S se dofiltruje sekvenčně, jinak se zvýší k a pokračuje se krokem 3. Ukázka filtrování podle jedné dimenze (pivotu) tyto objekty zůstaly v S, je potřeba dofiltrovat přes d
Dopočítá se příslušný počet souřadnic vektoru dotazu q. 4)Sekvenčně se procházejí (zbylé) vektory v S a filtrují se podle k dimenzí, tj. jsou odfiltrovány ty objekty, pro které L (q, o i ) > r Q. 5)Pokud zbyl v S malý počet objektů (anebo byly vyčerpány všechny pivoty), zbytek S se dofiltruje sekvenčně, jinak se zvýší k a pokračuje se krokem 3. Ukázka filtrování podle jedné dimenze (pivotu) tyto objekty zůstaly v S, je potřeba dofiltrovat přes d.")
10
Další LAESA-based indexační metody TLAESA redukce I/O nákladů použitím stromové struktury podobné gh- stromu (viz dále) ROAESA AESA + heuristiky pro redukci průchodu maticí (omezeno pouze na kNN dotazy) Spaghettis redukce I/o nákladů použitím polí setříděných párů objekt-pivot (jakoby indexování zvlášť přes všechny pivoty) OmniFamily využití R-stromu a dalších SAM pro indexování vektorů
 ROAESA AESA + heuristiky pro redukci průchodu maticí (omezeno pouze na kNN dotazy) Spaghettis redukce I/o nákladů použitím polí setříděných párů objekt-pivot (jakoby indexování zvlášť přes všechny pivoty) OmniFamily využití R-stromu a dalších SAM pro indexování vektorů")
11
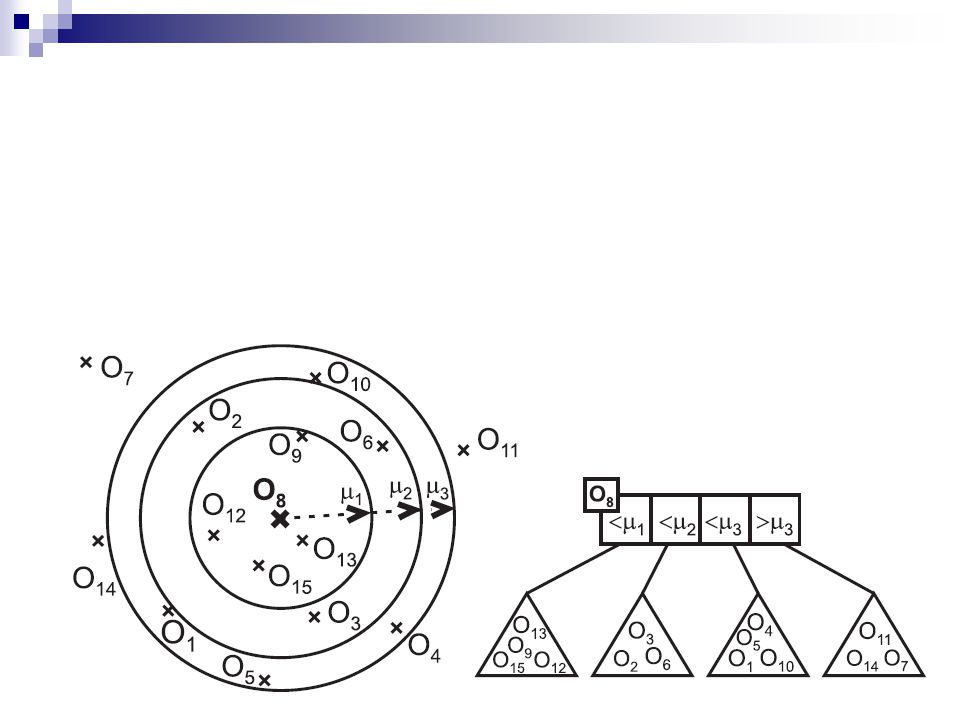
gh-strom (generalized-hyperplane tree) binární strom každý uzel má přiřazeny dva pivoty, podstromy uchovávají data prostorově rozdělená „nadrovinou“ mezi oběma pivoty podobné struktury Bisector tree Voronoi tree
 binární strom každý uzel má přiřazeny dva pivoty, podstromy uchovávají data prostorově rozdělená „nadrovinou mezi oběma pivoty podobné struktury Bisector tree Voronoi tree")
12
gh-tree Q Rozsahový dotaz Filtrování levého podstromu: Pokud nejbližší objekt uvnitř dotazu (vzhledem k O 1 ) je dál než nejvzdálenější objekt uvnitř dotazu (vhledem k O 6 ), může být levý podstrom odfiltrován Filtrování pravého podstromu obráceně.
 je dál než nejvzdálenější objekt uvnitř dotazu (vhledem k O 6 ), může být levý podstrom odfiltrován Filtrování pravého podstromu obráceně.")
13
GNAT (geometric nearest-neighbor access tree) zobecnění gh-stromu na n-ární strom + nějaká další rozšíření (neuvádíme) tj. n pivotů dělí prostor na n regionů, kde myšlenou hranici tvoří ty „body“ všech možných nadrovin (mezi všemi dvojicemi pivotů), které nezasahují dovnitř žádného regionu binárního dělení jinými slovy, všechny body prostoru jsou rozděleny do n regionů tak, že bod patří k regionů i, pokud je nejblíže k pivotu O i – všechny ostatní body tvoří onu hranici body hranice se nějakým dohodnotým způsobem rozdělí taky mezi regiony
, které nezasahují dovnitř žádného regionu binárního dělení jinými slovy, všechny body prostoru jsou rozděleny do n regionů tak, že bod patří k regionů i, pokud je nejblíže k pivotu O i – všechny ostatní body tvoří onu hranici body hranice se nějakým dohodnotým způsobem rozdělí taky mezi regiony.")
14
GNAT Q Rozsahový dotaz Filtrování O 5 -podstromu: Pokud nejbližší objekt uvnitř dotazu (vzhledem k O 5 ) je dál než nejvzdálenější objekt uvnitř dotazu (libovolně vhledem k O 1, O 3, O 4 ), může být O 5 -podstrom odfiltrován Filtrování odstatních podstromů podobně.
 je dál než nejvzdálenější objekt uvnitř dotazu (libovolně vhledem k O 1, O 3, O 4 ), může být O 5 -podstrom odfiltrován Filtrování odstatních podstromů podobně.")
15
vp-strom todo

17
mvp-strom todo

19
SAT (spatial approximation tree) todo
 todo")
21
Metrické hašování – D-index (1) založen na dělích hašovacích funkcích bps 1, ,j, kde P j je pivot, d m je medián vzdáleností k objektům a je rozdělující parametr funkce přiřadí objektu 0 pokud není uvnitř prstence (Pj, dm – r, dm + r) a to tak že je uvnitř koule dané menším poloměrem prstence, a 1 pokud také není uvnitř, ale je vně koule dané větším poloměrem jinak přiřadí 2 (když padne dovnitř prstence)
 založen na dělích hašovacích funkcích bps 1, ,j, kde P j je pivot, d m je medián vzdáleností k objektům a je rozdělující parametr funkce přiřadí objektu 0 pokud není uvnitř prstence (Pj, dm – r, dm + r) a to tak že je uvnitř koule dané menším poloměrem prstence, a 1 pokud také není uvnitř, ale je vně koule dané větším poloměrem jinak přiřadí 2 (když padne dovnitř prstence)")
22
Metrické hašování – D-index (2) funkce bps lze kombinovat, takže obdržíme až 2n hašovacích hodnot složených z 1 a 0, které odpovídají 2n regionům v prostoru (tvořených průniky) hašovací hodnoty, kde se vyskytuje alespoň jedna 2 tvoří tzv. množinu vyloučených (exclusion set) množina vyloučených lze dále stejným způsobem rozdělit (přičemž můžeme použít úplně jiné pivoty a parametry d m a )
 množina vyloučených lze dále stejným způsobem rozdělit (přičemž můžeme použít úplně jiné pivoty a parametry d m a ).")
23
D-index Výhody: - pokud je poloměr dotazu r Q < , na každé úrovni D-indexu se projde maximálně jedna kapsa - pokud navíc je celý dotaz na dané úrovni uvnitř množiny vyloučených, pokračuje se na další úrovni bez potřeby přistupovat do kapes na současné úrovni Nevýhody: - volba pivotů, parametrů dm a r a s tím spojená nevyváženost struktury - parametr r zpravidla musí být velmi malý, aby kapsy nebyly prázdné a vše neskončilo v množine vyloučených (tj. nevhodné pro „velké“ dotazy) Struktura D-indexu: hašované regiony mají své kapsy (buckets) na disku, množina vyloučených se dále rozděluje až je dostatečně malá. Tím obdržíme několikaúrovňový hašovaný index.
 Struktura D-indexu: hašované regiony mají své kapsy (buckets) na disku, množina vyloučených se dále rozděluje až je dostatečně malá. Tím obdržíme několikaúrovňový hašovaný index..")
24
Metody volby globálních pivotů todo

Podobné prezentace