Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Jiří Šafr jiri.safr(zavináč)seznam.cz
UK FHS Historická sociologie (LS 2011+) Analýza kvantitativních dat II. Kontingenční tabulka: vztahy mezi kategorizovanými znaky - míry asociace/korelace, znaménkové schéma Jiří Šafr jiri.safr(zavináč)seznam.cz poslední aktualizace ( ) ® Jiří Šafr, 2014
 Analýza kvantitativních dat II. Kontingenční tabulka: vztahy mezi kategorizovanými znaky - míry asociace/korelace, znaménkové schéma. Jiří Šafr jiri.safr(zavináč)seznam.cz. poslední aktualizace ( ) ® Jiří Šafr,")
2
Kontingenční tabulky sestavujeme tak, aby vyjadřovaly naší pracovní hypotézu.

3
Míra souvislosti mezi znaky - obecně Základní možnosti pro vztah dvou proměnných A x B (opakování)
Nominální A (kategoriální či „kvalitativní“ proměnná) a nominální B → procentní podíly (podmíněné pravděpodobnosti) kontingenční tabulka (+ chí kvadrát test), znaménkové schéma, koeficient kontingence Dtto ale ordinální → dtto + pořadové korelace (Sperman, Tab-B) Nominální A x kardinální (číselná) → průměry B v podskupinách A (+ T-test či One-way Anova, 95% konf. intervaly), koeficient asociace Eta = míra jednostranné závislosti kvantitativní vysvětlované proměnné na proměnné nominální
 a nominální B → procentní podíly (podmíněné pravděpodobnosti) kontingenční tabulka (+ chí kvadrát test), znaménkové schéma, koeficient kontingence. Dtto ale ordinální → dtto + pořadové korelace (Sperman, Tab-B) Nominální A x kardinální (číselná) → průměry B v podskupinách A (+ T-test či One-way Anova, 95% konf. intervaly), koeficient asociace Eta = míra jednostranné závislosti kvantitativní vysvětlované proměnné na proměnné nominální.")
4
Kategoriální data (nominálními a ordinální znaky)
1. „Celkový pohled“ na těsnost vztahů v kontingenční tabulce → Koeficienty asociace (pořadové korelace) Většinou jim předchází test hypotézy o celkové nezávislosti/homogenitě (dvoudimenzionální Chíkvadrát test).
 Většinou jim předchází test hypotézy o celkové nezávislosti/homogenitě (dvoudimenzionální Chíkvadrát test).")
5
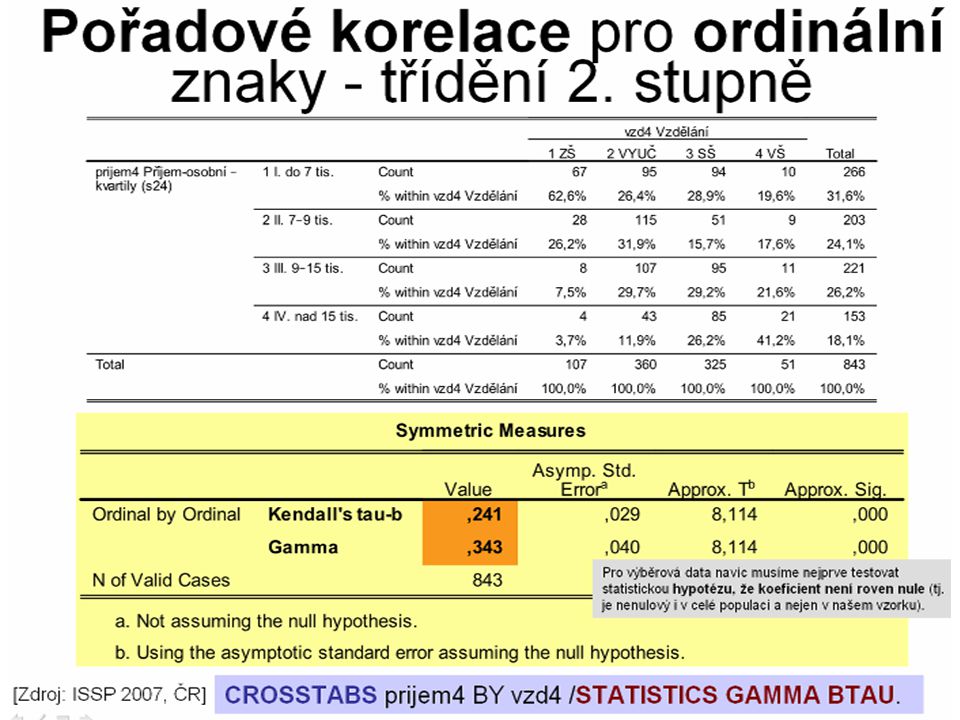
Míry asociace / korelace v kontingenční tabulce
Asociace nominálních znaků Míry asociace / korelace v kontingenční tabulce Vyjádření souvislosti kategoriálních znaků pomocí koeficientu (ekvivalent ke korelaci)
")
6
Asociace nominálních znaků: Kontingenční koeficient (CC)
Analogie korelačního koeficientu (ten je pro kardinální/ordinální znaky) → míra těsnosti závislosti. Neurčuje směr. Výsledek není kontingenčních tabulkách v intervalu (0,1) → existují různé korekce CC je rozšíření koef. Phi pro >2x2 tabulky. V SPSS: Analyze, Descriptive Statistics, Crosstabs; vložit Row a Column variables; → Statistics; → Contingency Coefficient / Phi & Cramer‘s V
 → míra těsnosti závislosti. Neurčuje směr. Výsledek není kontingenčních tabulkách v intervalu (0,1) → existují různé korekce CC je rozšíření koef. Phi pro >2x2 tabulky. V SPSS: Analyze, Descriptive Statistics, Crosstabs; vložit Row a Column variables; → Statistics; → Contingency Coefficient / Phi & Cramer‘s V.")
7
Míry asociace v kontingenční tabulce
Při interpretaci i měření souvislosti je důležité, zda jsou jedna nebo obě proměnné nominální nebo ordinální. Základním nástrojem analýzy jsou vždy procentní rozdíly. Navíc můžeme měřit míru těsnosti vzájemného vztahu pomocí: pro nominální znaky koeficientů asociace (Kontingenční koeficient, Cramérovo V, Lambda atd.). pro ordinální znaky navíc (kromě koeficientů asociace) koeficientů pořadové korelace (Spermanovo Rho, Gamma, Kendallovo Tau B, ..). Zadání nominálních asociací a pořadových korelací v SPSS uvádíme dále; podrobně viz 2. Korelace a asociace: vztahy mezi kardinálními/ ordinálními znaky na Pokud máme výběrová data (vzorek z populace), pak bychom měli testovat statistickou významnost koeficientů asociace/korelace (to se naučíme v AKD II.). K jednoduché analýze kontingenční tabulky také používáme např.: odds ratio = poměry šancí (→ vzájemně podmíněné pravděpodobnosti) Podrobně viz 5. Poměry šancí (Odds Ratio) míry rozptýlení, např. Index nepodobnosti (Δ) Viz 9. Míry variability: variační koeficient a další indexy
. pro ordinální znaky navíc (kromě koeficientů asociace) koeficientů pořadové korelace (Spermanovo Rho, Gamma, Kendallovo Tau B, ..). Zadání nominálních asociací a pořadových korelací v SPSS uvádíme dále; podrobně viz 2. Korelace a asociace: vztahy mezi kardinálními/ ordinálními znaky na Pokud máme výběrová data (vzorek z populace), pak bychom měli testovat statistickou významnost koeficientů asociace/korelace (to se naučíme v AKD II.). K jednoduché analýze kontingenční tabulky také používáme např.: odds ratio = poměry šancí (→ vzájemně podmíněné pravděpodobnosti) Podrobně viz 5. Poměry šancí (Odds Ratio) míry rozptýlení, např. Index nepodobnosti (Δ) Viz 9. Míry variability: variační koeficient a další indexy")
8
Míry asociace (pro nominální proměnné)
Obecně pro koeficienty asociace platí: Mají rozpětí 0 = žádná souvislost až 1 = dokonalá souvislost mezi znaky. V principu říkají kolik – jaký podíl variability jedné proměnné lze vysvětlit pomocí druhé. Ale pozor, „vysvětlení“ je třeba chápat ve smyslu redukce statistického rozptýlení dat, nikoliv ve smyslu kauzální interpretace. [Řehák, Řeháková 1986: 250] Nevyjadřují směr asociace (jako tomu je v případě korelací, nicméně některé koeficienty asociace jsou asymetrické (directional), tj. musíme definovat, která proměnná je závislá a které nezávislá). Kontingenční koeficient C (CC) Nejjednodušší na výpočet. Ale nepoužívejte je, tam kde porovnáváte míru asociace mezi tabulkami s různým počtem kategorií. Cramér's V (CV nebo Cr) obecně ho lze doporučit (ale má také nedostatky) Pokud jsou obě proměnné dichotomické (2×2 tabulka) používáme Phi koeficient (pro 2×2 tabulku je stejný jako CV) Lambda Λ (symetrická/ asymetrická) měří procentní zlepšení odhadu jedné proměnné na základě hodnot jiné proměnné (oboustranné – symetrická nebo pouze predikující závislou proměnnou – asymetrická) Všechny tyto koeficienty jsou k dispozici v SPSS pomocí CROSSTABS (viz dále)
, tj. musíme definovat, která proměnná je závislá a které nezávislá). Kontingenční koeficient C (CC) Nejjednodušší na výpočet. Ale nepoužívejte je, tam kde porovnáváte míru asociace mezi tabulkami s různým počtem kategorií. Cramér s V (CV nebo Cr) obecně ho lze doporučit (ale má také nedostatky) Pokud jsou obě proměnné dichotomické (2×2 tabulka) používáme Phi koeficient (pro 2×2 tabulku je stejný jako CV) Lambda Λ (symetrická/ asymetrická) měří procentní zlepšení odhadu jedné proměnné na základě hodnot jiné proměnné (oboustranné – symetrická nebo pouze predikující závislou proměnnou – asymetrická) Všechny tyto koeficienty jsou k dispozici v SPSS pomocí CROSSTABS (viz dále)")
9
Pozor: pokud nenaměříme korelaci, mezi znaky stále ještě může být (nominální) asociace.
Pokud není přítomná ordinální závislost – korelace, tak to automaticky neznamená statistickou nezávislost. Znamená to pouze, že není ordinálně uspořádaný vztah (~ linearita). Stále mezi znaky ale může být asociace, tj. vzájemný spoluvýskyt hodnot je např. kumulován do jednoho políčka tabulky (nebo několika políček mimo diagonálu resp. bez jakéhokoliv jiného „trendu“). Tuto situaci indikuje signifikantní koeficient asociace (např. Cramerovo V) zatímco ordinální korelace je přibližně nulová (např. Gamma). Pouze absence nominální závislosti – asociace znamená (celkovou) statistickou nezávislost. (např. CV = 0) → spočítejte oba typy koeficientů: asociace (Cramer‘s V atd.) i ordinální korelace (Gamma atd.) a porovnejte je.
. Stále mezi znaky ale může být asociace, tj. vzájemný spoluvýskyt hodnot je např. kumulován do jednoho políčka tabulky (nebo několika políček mimo diagonálu resp. bez jakéhokoliv jiného „trendu ). Tuto situaci indikuje signifikantní koeficient asociace (např. Cramerovo V) zatímco ordinální korelace je přibližně nulová (např. Gamma). Pouze absence nominální závislosti – asociace znamená (celkovou) statistickou nezávislost. (např. CV = 0) → spočítejte oba typy koeficientů: asociace (Cramer‘s V atd.) i ordinální korelace (Gamma atd.) a porovnejte je.")
10
Míry asociace v kontingenční tabulce a Elaborace
Míry asociace/korelace využíváme také při elaboraci tj. v třídění dat 3. stupně (vč. popisných cílů analýz). → Jsou asociace v podskupinách podle 3. kontrolní proměnné v zásadě stejné? A nebo se liší jejich intenzita, či dokonce v případě korelací i směr souvislosti?
. → Jsou asociace v podskupinách podle 3. kontrolní proměnné v zásadě stejné A nebo se liší jejich intenzita, či dokonce v případě korelací i směr souvislosti")
11
Míry asociace v třídění (2) a 3. stupně v CROSSTABS
V rámci CROSSTABS můžeme spočítat míry asociace a korelace pro proměnné Y x X (bivariátně) a navíc i odděleně v kategoriích kontrolního faktoru Z → což nám pomůže rychle posoudit interakce a zhodnotit „falešné“ vlivy. Pro nominální znaky (Y, X, Z-kontrolní faktor) koeficienty asociace (mají hodnoty 0-1): CROSSTABS var1 BY var2 BY var3-kontrolní /CELLS COL /STATISTICS CC PHI. Koeficienty asocice: CC = Kontingenční koeficient, PHI = Cramérovo V (+ ekvivalent pro dichotomické znaky Phi); jsou zde k dispozici i další koeficienty asociace a korelace (např. Lambda). Pro ordinální znaky (A, B) a nominální/ordinální kontrolní faktor (C) navíc krom asociací i pořadové korelace (hodnoty -1–0–1 → směr): CROSSTABS var1 BY var2 BY var3-kontrolní /CELLS COL /STATISTICS CC PHI GAMMA CORR BTAU. Korelační koeficienty: GAMMA = Goodman&Kruskalovo Gamma, BTAU = Kendaullovo Tau B, CORR = Spermanovo Rho (+ Pearsonův korel. koef. R pro kardinální znaky) Pozor, nenaměříme-li korelaci, neznamená to, že mezi znaky nemusí být silná závislost – asociace. Navíc u ordinálních znaků nám porovnání korelací a koeficientů asociace může napovědět o (nelineární) povaze vztahu. Poznámka: v případě průměrů v podskupinách v MEANS lze počítat koeficient(y) Eta2 (pro kardinální x nominální znak): MEANS var1-závislá-číselná BY var2-nezávislá-kateg. BY var3-kontrolní-kategoriální /CELLS MEAN STDDEV COUNT /STATISTICS ANOVA. Více o koeficientech asociace a korelace v 2. Korelace a asociace: vztahy mezi kardinálními/ ordinálními znaky na
 a navíc i odděleně v kategoriích kontrolního faktoru Z → což nám pomůže rychle posoudit interakce a zhodnotit „falešné vlivy. Pro nominální znaky (Y, X, Z-kontrolní faktor) koeficienty asociace (mají hodnoty 0-1): CROSSTABS var1 BY var2 BY var3-kontrolní /CELLS COL /STATISTICS CC PHI. Koeficienty asocice: CC = Kontingenční koeficient, PHI = Cramérovo V (+ ekvivalent pro dichotomické znaky Phi); jsou zde k dispozici i další koeficienty asociace a korelace (např. Lambda). Pro ordinální znaky (A, B) a nominální/ordinální kontrolní faktor (C) navíc krom asociací i pořadové korelace (hodnoty -1–0–1 → směr): CROSSTABS var1 BY var2 BY var3-kontrolní /CELLS COL /STATISTICS CC PHI GAMMA CORR BTAU. Korelační koeficienty: GAMMA = Goodman&Kruskalovo Gamma, BTAU = Kendaullovo Tau B, CORR = Spermanovo Rho (+ Pearsonův korel. koef. R pro kardinální znaky) Pozor, nenaměříme-li korelaci, neznamená to, že mezi znaky nemusí být silná závislost – asociace. Navíc u ordinálních znaků nám porovnání korelací a koeficientů asociace může napovědět o (nelineární) povaze vztahu. Poznámka: v případě průměrů v podskupinách v MEANS lze počítat koeficient(y) Eta2 (pro kardinální x nominální znak): MEANS var1-závislá-číselná BY var2-nezávislá-kateg. BY var3-kontrolní-kategoriální /CELLS MEAN STDDEV COUNT /STATISTICS ANOVA. Více o koeficientech asociace a korelace v 2. Korelace a asociace: vztahy mezi kardinálními/ ordinálními znaky na")
14
Pokud je min. jedna proměnná multi-nominální
Princip je stejný jako u ordinálních znaků, ale nemůžeme počítat korelace, pouze koeficienty asociace (Kontingenční koeficient, Cramérovo V, Lambda atd.). Pokud je nominální pouze 3. kontrolní proměnná (a ostatní ordinální), pak korelace počítat a vzájemně je porovnávat lze. Při interpretaci procentních rozdílů u nominálních znaků musíme brát v úvahu všechny kategorie závislé proměnné i nezávislých proměnných. Jednodušší je to, pokud je alespoň některá ordinální. Ideální je, pokud máme závislou proměnnou dichotomickou nebo ordinální. Pokud je závislá proměnná dichotomická, tak jde o ekvivalent porovnávání průměrů v pod/podskupinách.
. Pokud je nominální pouze 3. kontrolní proměnná (a ostatní ordinální), pak korelace počítat a vzájemně je porovnávat lze. Při interpretaci procentních rozdílů u nominálních znaků musíme brát v úvahu všechny kategorie závislé proměnné i nezávislých proměnných. Jednodušší je to, pokud je alespoň některá ordinální. Ideální je, pokud máme závislou proměnnou dichotomickou nebo ordinální. Pokud je závislá proměnná dichotomická, tak jde o ekvivalent porovnávání průměrů v pod/podskupinách.")
15
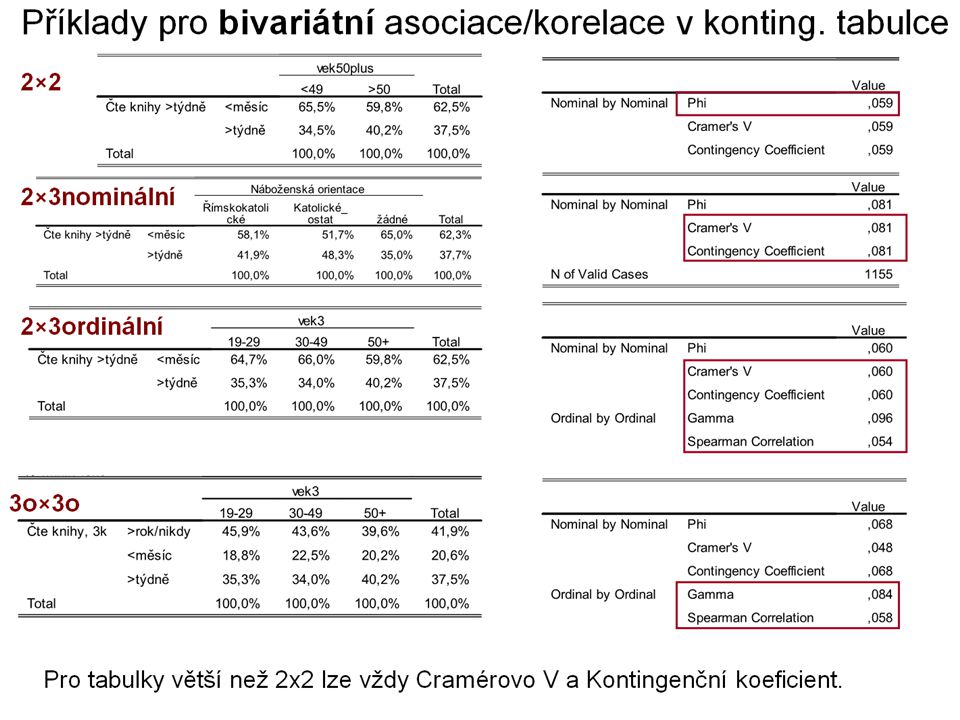
Typy kontingenčních tabulek se 3 proměnnými a míry asociace/korelace
Vždy lze míru asociace vyjádřit pomocí koef. asociace 2×2×2 (podobně 2×2×3n) – všechny dichotomické → koeficienty asociace a bodově biseriální korelace nebo tetrachorické korelace 2×3o×3n nebo 2×3o×2 – závislá dichotomická, nezávislá ordinální, kontrolní nominální → pořadové korelace ve skupinách kontrolního faktoru (bez možnosti posouzení trendu asociace/korelace). 2×3n×3o – závislá dichotomická, nezávislá nominální, kontrolní ordinální → pouze koeficienty asociace (lze posuzovat trend v asociacích mezi kategoriemi kontrolního faktoru) 3o×3o×3o (podobně i 2×2×3o) – všechny ordinální → pořadové korelace (lze posuzovat trend v korelacích mezi kategoriemi kontrolního faktoru) + koeficient parciální korelace Platí i pro více kategorií něž 3.
 – všechny dichotomické → koeficienty asociace a bodově biseriální korelace nebo tetrachorické korelace. 2×3o×3n nebo 2×3o×2 – závislá dichotomická, nezávislá ordinální, kontrolní nominální → pořadové korelace ve skupinách kontrolního faktoru (bez možnosti posouzení trendu asociace/korelace). 2×3n×3o – závislá dichotomická, nezávislá nominální, kontrolní ordinální → pouze koeficienty asociace (lze posuzovat trend v asociacích mezi kategoriemi kontrolního faktoru) 3o×3o×3o (podobně i 2×2×3o) – všechny ordinální → pořadové korelace (lze posuzovat trend v korelacích mezi kategoriemi kontrolního faktoru) + koeficient parciální korelace. Platí i pro více kategorií něž 3.")
17
Pozor na absolutní četnosti při třídění vyššího stupně
Při třídění 3. a vyššího stupně vždy bedlivě kontrolujte absolutní počty v jednotlivých polích tabulky, zejména u malých souborů. CROSSTABS var1 BY var2 BY var3 /CELLS COL COUNT. Pokud jsou četnosti v tabulkách velmi malé, pak je jejich interpretace ze statistického i věcného hlediska v podstatě bezcenná.

18
Pro ordinální a kardinální (číselné) proměnné viz prezentaci Korelace a asociace: vztahy mezi kardinálními/ ordinálními znaky (AKD2_korelace.ppt) Pořadové (ordinální) korelační koeficienty: Spearmanovo Rho, Kendaulovo Tau B, Gama,…
 korelační koeficienty: Spearmanovo Rho, Kendaulovo Tau B, Gama,…")
19
A ZNOVU a znovu … Asociace (korelace) a kauzalita
Asociace (korelace) neznamená automaticky kauzální vztah Podmínky kauzality (připomenutí podruhé): Naměřená korelace (asociace A-B) Časová souslednost (k A došlo před B) Lze vyloučit vliv další proměnné/ných (A-B/C) Směr působení nám může pomoci určit silná teorie
 neznamená automaticky kauzální vztah. Podmínky kauzality (připomenutí podruhé): Naměřená korelace (asociace A-B) Časová souslednost (k A došlo před B) Lze vyloučit vliv další proměnné/ných (A-B/C) Směr působení nám může pomoci určit silná teorie.")
20
Kategoriální data (nominálními a ordinální znaky)
2. Podrobný pohled „dovnitř“ kontingenční tabulky. Testování „odchylek“ četností v jednotlivých polích tabulky → Znaménkové schéma Předchází test hypotézy o celkové nezávislosti/homogenitě (dvoudimenzionální Chíkvadrát test).
.")
21
Nejprve viz presentaci Testování hypotéz (2) - zejména část o dvoudimenzionálním Chíkvadrát testu dobré shody →homogenita v kontingenční tabulce
 - zejména část o dvoudimenzionálním Chíkvadrát testu dobré shody →homogenita v kontingenční tabulce")
22
Krok 1. – celkové zhodnocení (ne)závislosti dvou kategoriálních znaků → Chíkvadrát test v kontingenční tabulce Vztahy dvou (a více) znaků v kontingenční tabulce Malé připomenutí - kopie z
 znaků v kontingenční tabulce. Malé připomenutí - kopie z.")
23
Kontingenční tabulka Statistické míry a testování
Nezávislost = oba znaky navzájem neovlivňují v tom, jakých konkrétních hodnot nabývají Homogenita (shodnost struktury) = očekávané četnosti jsou v políčcích každého řádku ve stejném vzájemném poměru bez ohledu na konkrétní volbu řádku → test dobré shody = porovnání očekávaných četností v jednotlivých polích tabulky - za předpokladu, že hodnoty obou sledovaných znaků na sobě nezávisí - a skutečných četností. Pokud hypotéza nezávislosti (resp. homogenity) platí, má testová statistika přibližně rozdělení chí kvadrát o (r-1)(s-1) stupních volnosti. Hodnota testové statistiky se tedy porovná s kritickou hodnotou (kvantilem) příslušné hladiny významnosti.
 = očekávané četnosti jsou v políčcích každého řádku ve stejném vzájemném poměru bez ohledu na konkrétní volbu řádku. → test dobré shody = porovnání očekávaných četností v jednotlivých polích tabulky - za předpokladu, že hodnoty obou sledovaných znaků na sobě nezávisí - a skutečných četností. Pokud hypotéza nezávislosti (resp. homogenity) platí, má testová statistika přibližně rozdělení chí kvadrát o (r-1)(s-1) stupních volnosti. Hodnota testové statistiky se tedy porovná s kritickou hodnotou (kvantilem) příslušné hladiny významnosti.")
24
Chí-kvadrát testy: test dobré shody připomenutí
Test pro homogenitu distribucí mezi kategoriemi znaku/ů test dobré shody = shody relativních četností ni/n a hypotetických pravděpodobností. Pro nominální znaky (i ordinální a kategorizované kardinální) Nevyžaduje znalost předchozího rozdělení znaku Očekávané frekvence: dle rozložení kategorií 1 znaku nebo v kontingenční tabulce vztah 2 znaků Odpovídá na otázku, zda jsou rozdíly mezi empirickými (pozorovanými - fO) četnostmi a teoretickými (očekávanými -fE) četnostmi náhodné nebo ne. Počet stupňů volnosti df = (r-1) (s-1) r = počet řádků s = počet sloupců v tabulce
 Nevyžaduje znalost předchozího rozdělení znaku. Očekávané frekvence: dle rozložení kategorií 1 znaku nebo v kontingenční tabulce vztah 2 znaků. Odpovídá na otázku, zda jsou rozdíly mezi empirickými (pozorovanými - fO) četnostmi a teoretickými (očekávanými -fE) četnostmi náhodné nebo ne. Počet stupňů volnosti df = (r-1) (s-1) r = počet řádků s = počet sloupců v tabulce.")
25
Chí-kvadrát test nezávislosti
Nulová hypotéza „o nezávislosti“ odpovídá na otázku, zda jsou rozdíly mezi empirickými-pozorovanými a teoretickými četnostmi náhodné nebo ne. Očekávané četnosti lze získat z hodnot v populaci nebo porovnávat s teoretickou hodnotou, např. z jiného výzkumu. Nejčastěji třídíme údaje podle dvou nebo více znaků v kontingenční tabulce. Lze aplikovat na již existující agregovaná data (publikované tabulky apod.)
")
26
Princip testování vztahu 2 a více proměnných
Většina statistických testů je založena na srovnání naměřené (empirické) distribuce pozorování do polí tabulky s distribucí, jakou bychom obdrželi, kdyby pozorování byla zařazena do polí tabulky náhodně (teoretická četnost).
 distribuce pozorování do polí tabulky s distribucí, jakou bychom obdrželi, kdyby pozorování byla zařazena do polí tabulky náhodně (teoretická četnost).")
28
Zdroj: data ISSP 2007, ČR (neváženo)
")
29
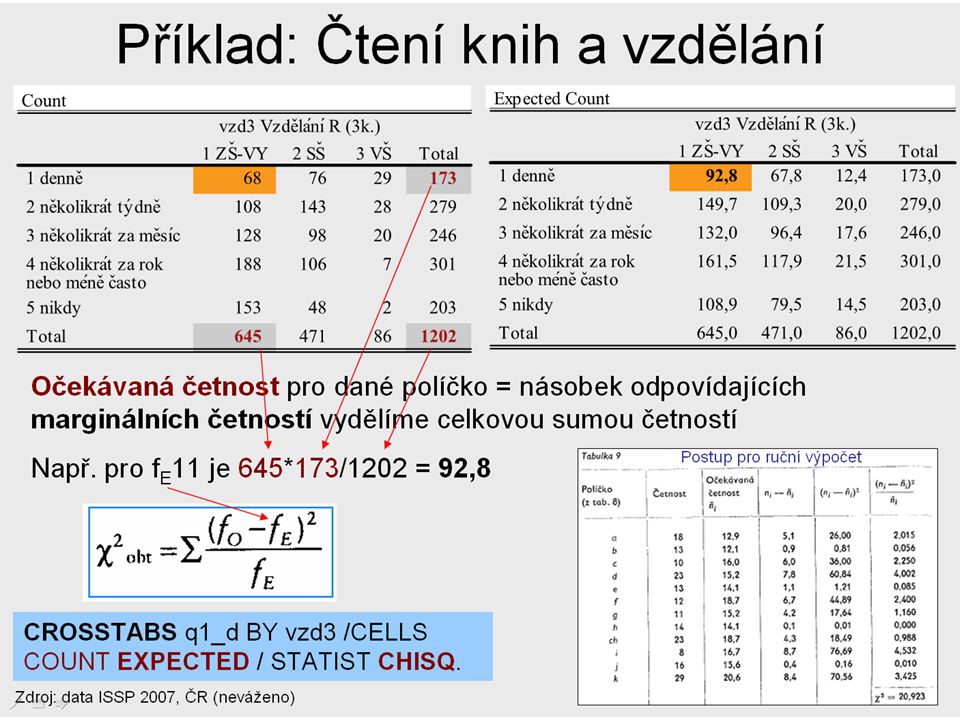
Příklad: Čtení knih a vzdělání
df = (5-1)(3-1) = 8 při Alpha 0,05 naměřená hodnota χ2 = 112,17 > χ2krit = 15,507 → nemůžeme přijmout (zamítáme) H0 „o nezávislosti“, tj., že ve čtení nejsou rozdíly mezi vzdělanostními kategoriemi → alespoň u jedné kategorie (buňce v tabulce) v porovnání s ostatními kategoriemi tabulky se liší očekávané od empirických četností (Test říká, že tuto skutečnost nalezneme s 95 % jistotou v celé populaci.) Místo porovnání hodnoty testovacího kritéria s kritickými – tabulkovými hodnotami se pro rozhodování o nulové hypotéze používá také p-hodnota, či significance kterou zjistíme pomocí statistického software (princip viz dále). p < α zamítáme H0 p > α nelze zamítnout H0
(3-1) = 8 při Alpha 0,05. naměřená hodnota χ2 = 112,17 > χ2krit = 15,507 → nemůžeme přijmout (zamítáme) H0 „o nezávislosti , tj., že ve čtení nejsou rozdíly mezi vzdělanostními kategoriemi. → alespoň u jedné kategorie (buňce v tabulce) v porovnání s ostatními kategoriemi tabulky se liší očekávané od empirických četností (Test říká, že tuto skutečnost nalezneme s 95 % jistotou v celé populaci.) Místo porovnání hodnoty testovacího kritéria s kritickými – tabulkovými hodnotami se pro rozhodování o nulové hypotéze používá také p-hodnota, či significance kterou zjistíme pomocí statistického software (princip viz dále). p < α zamítáme H0 p > α nelze zamítnout H0.")
30
Kontingenční tabulka a testy dobré shody – pozor na:
Prázdná pole a nízké četnosti v tabulce mohou zkreslit význam koeficientů měřících souvislost. Pro použití testů založených na testu dobré shody (test nezávislosti nebo homogenity) je třeba, aby se v tabulce nevyskytlo méně než 20 % políček, v nichž by očekávané (teoretické) četnosti byly menší než 5. V případě, že se tak stane, můžeme zvážit transformaci — sloučení některých méně obsazených kategorií (např. "ano" a "spíše ano").
 je třeba, aby se v tabulce nevyskytlo méně než 20 % políček, v nichž by očekávané (teoretické) četnosti byly menší než 5. V případě, že se tak stane, můžeme zvážit transformaci — sloučení některých méně obsazených kategorií (např. ano a spíše ano ).")
31
Kontingenční tabulka - vyjádření vztahů kategorií
Statistika Chí kvadrát nevypovídá nic o síle vztahu, pouze zamítá/nezamítá nulovou hypotézu o závislosti nebo homogenitě na dané hladině významnosti alfa. Pro zjištění síly vztahu → - koeficienty asociace (obdobné korelaci: CC), - znaménkové schéma – adjustovaná residua - podíl šancí (OR), - u ordinálních veličin korelační koef. dle pořadí. Odlišné testy pro nominální a ordinální proměnné (jedna / obě).
, - znaménkové schéma – adjustovaná residua - podíl šancí (OR), - u ordinálních veličin korelační koef. dle pořadí. Odlišné testy pro nominální a ordinální proměnné (jedna / obě).")
32
Po provedení testu celkové závislosti dvou kategoriálních znaků bychom měli pokračovat analýzou vztahů „uvnitř“ kontingenční tabulky. Test odchylky od nezávislosti v polích tabulky: Adjustovaná residua a znaménkové schéma

33
Test odchylky od nezávislosti v poli tabulky → znaménkové schéma
V případě zamítnutí hypotézy o celkové nezávislosti, tj. celkové homogenitě tabulky (např. pomocí Chíkvadrát testu) dále hledáme pole tabulky, kde je nezávislost porušena. → skryté souvislosti uvnitř tabulky → znaménkové schéma odhaluje pole, kde nastává významná závislost
 dále hledáme pole tabulky, kde je nezávislost porušena. → skryté souvislosti uvnitř tabulky. → znaménkové schéma odhaluje pole, kde nastává významná závislost.")
34
Kontingenční tabulka: očekávané četnosti a znaménkové schéma (obecný princip)
Očekávané (teoretické) četnosti vyjadřují model rozložení četností, za předpokladu, že by mezi znaky nebyl žádný vztah. = součin marginálních četností (daného políčka) dělený celkovou četností Očekávaná četnost: fO11 = 2121 * 452 / 3815 Znaménka: Rozdíl mezi pozorovanou (absolutní) a očekávanou četností (k učení síly viz dále) [Kapr, Šafář 1969: 186]
 četnosti vyjadřují model rozložení četností, za předpokladu, že by mezi znaky nebyl žádný vztah. = součin marginálních četností (daného políčka) dělený celkovou četností. Očekávaná četnost: fO11 = 2121 * 452 / Znaménka: Rozdíl mezi pozorovanou (absolutní) a očekávanou četností (k učení síly viz dále) [Kapr, Šafář 1969: 186]")
35
Adjustovaná residua (ASRESID) → Znaménkové schéma
v SPSS / PSPP v CROSSTABS: Adj. standardised (ASRESID) Adjustovaná residua = Residuum v daném políčku tabulky (= Pozorovaná (observed) minus Očekávaná (expected) hodnota) dělené odhadem vlastní standardní chyby. Standardizovaný residuál je vyjádřen v jednotkách směrodatné odchylky nad nebo pod průměrem. Znaménkové schéma → jednoduchá vizualizace kde abs(z) >= 3.29 nahradíme +++ resp. --- abs(z) >= 2.58 nahradíme ++ resp. -- abs(z) >= 1.96 nahradíme + resp. – Z-skóry ukazují na statistickou významnost odchylky empirických (naměřených) četností od očekávaných (teoretických) četností (viz Normované normální rozložení).
 Adjustovaná residua = Residuum v daném políčku tabulky (= Pozorovaná (observed) minus Očekávaná (expected) hodnota) dělené odhadem vlastní standardní chyby. Standardizovaný residuál je vyjádřen v jednotkách směrodatné odchylky nad nebo pod průměrem. Znaménkové schéma → jednoduchá vizualizace kde. abs(z) >= 3.29 nahradíme +++ resp. --- abs(z) >= 2.58 nahradíme ++ resp. -- abs(z) >= 1.96 nahradíme + resp. – Z-skóry ukazují na statistickou významnost odchylky empirických (naměřených) četností od očekávaných (teoretických) četností (viz Normované normální rozložení).")
36
Znaménkové schéma Kritérium v daném políčku tabulky (Adjustované residuum) označuje statistickou významnost rozdílu mezi empirickým zjištěnou četností a teoretickou (očekávanou) četností. Umožňuje rychlou orientaci mezi dvěma znaky. Znaménkové schéma opticky zvýrazní buňky, jejichž četnost se významně liší od očekávané četnosti za předpokladu nezávislosti sledovaných znaků. Typ znaménka reprezentuje směr odchylky: neliší-li se naměřená četnost významně od očekávané, v buňce bude znaménko „o“, vyšší naměřené četnosti oproti očekávání se označí znaménkem „+“, nižší naměřené četnosti oproti očekávání se naopak zvýrazní znaménkem „-“. V každé buňce se mohou vyskytnout jedno až tři znaménka plus nebo mínus podle statistické významnosti odchylky – jedno znaménko při 95% významnosti, dvě při 99% a tři při 99,9% významnosti. Zdroj: [
 označuje statistickou významnost rozdílu mezi empirickým zjištěnou četností a teoretickou (očekávanou) četností. Umožňuje rychlou orientaci mezi dvěma znaky. Znaménkové schéma opticky zvýrazní buňky, jejichž četnost se významně liší od očekávané četnosti za předpokladu nezávislosti sledovaných znaků. Typ znaménka reprezentuje směr odchylky: neliší-li se naměřená četnost významně od očekávané, v buňce bude znaménko „o , vyšší naměřené četnosti oproti očekávání se označí znaménkem „+ , nižší naměřené četnosti oproti očekávání se naopak zvýrazní znaménkem „- . V každé buňce se mohou vyskytnout jedno až tři znaménka plus nebo mínus podle statistické významnosti odchylky – jedno znaménko při 95% významnosti, dvě při 99% a tři při 99,9% významnosti. Zdroj: [")
37
Znaménkové schéma měří statistickou významnost odchylek, nikoli jejich velikost. Vznikne na základě adjustovaných reziduí, ty porovnáme s hodnotami z (1,96; 2,58;…), které odpovídají hladinám významnosti 5% (-/+), 1% (--/++), 0,1% (---/+++); hladina významnosti α = 0,05 (z >2) → 5% riziko chyby našeho závěru; Např. α = 0,06 → 6% riziko chyby → výsledek je statisticky nevýznamný, naznačuje určitou tendenci, ale nejsme schopni ji prokázat s konvenční hladinou spolehlivosti.
, které odpovídají hladinám významnosti 5% (-/+), 1% (--/++), 0,1% (---/+++); hladina významnosti α = 0,05 (z >2) → 5% riziko chyby našeho závěru; Např. α = 0,06 → 6% riziko chyby → výsledek je statisticky nevýznamný, naznačuje určitou tendenci, ale nejsme schopni ji prokázat s konvenční hladinou spolehlivosti.")
38
Znaménkové schéma: Znaménka a testování dílčích hypotéz
Struktura adjustovaných residuí může skrývat působení nějakých latentních faktorů, které jsou přímo neměřitelné, ale které se v dané asociační struktuře projevují. Jde o latentní vlivy, na které můžeme usuzovat pouze na základě takto zjištěného vnějšího projevu. V praxi je struktura charakterizována, např. tzv. znaménkovým schématem (s volbou hranic pro znaménka: -, + = významné na hladině 0,05; --, ++ = na 0,01; ---, +++ = na 0,001). Rozlišujeme: - simultánní inferenci, → postihuje významnou strukturu toku jako celku (implementováno v SPSS v Asresid), testování postupně všech jednotlivých polí → struktura znamének označuje významnost těchto jednotlivých proudů. Zde je schéma znamének v tabulce bohatší, protože prokázat statistickou vlastnost jednoho dílčího proudu bez ohledu na chování ostatních vyžaduje podstatně méně odchylné skóry než přijetí statisticky prokazatelného závěru o šedesáti dílčích proudech současně, tj. přijetí pravděpodobnostně spolehlivého závěru o tom, že všechny označené proudy jsou statisticky významně specifické (slabší nebo silnější) a tudíž jejich struktura může být interpretována jako systematicky vznikající celistvý tok. ZS je běžná rutina československých sociologů, umožňuje názorně pracovat se strukturou asociací v kontingenční tabulce. Je logickým krokem v analýze interakčních vazeb mezi kategoriemi řádků a sloupců. [Řehák, Mánek 1991]
. Rozlišujeme: - simultánní inferenci, → postihuje významnou strukturu toku jako celku (implementováno v SPSS v Asresid), testování postupně všech jednotlivých polí → struktura znamének označuje významnost těchto jednotlivých proudů. Zde je schéma znamének v tabulce bohatší, protože prokázat statistickou vlastnost jednoho dílčího proudu bez ohledu na chování ostatních vyžaduje podstatně méně odchylné skóry než přijetí statisticky prokazatelného závěru o šedesáti dílčích proudech současně, tj. přijetí pravděpodobnostně spolehlivého závěru o tom, že všechny označené proudy jsou statisticky významně specifické (slabší nebo silnější) a tudíž jejich struktura může být interpretována jako systematicky vznikající celistvý tok. ZS je běžná rutina československých sociologů, umožňuje názorně pracovat se strukturou asociací v kontingenční tabulce. Je logickým krokem v analýze interakčních vazeb mezi kategoriemi řádků a sloupců. [Řehák, Mánek 1991]")
39
Korespondenční analýza „jednoduchá“ → pro rozkrytí asociací ve složitější dvourozměrné tabulce

40
jednoduchá Korespondenční analýza
zde to ovšem není ideální příklad, protože kategorií v tabulce by mělo být alespoň 7x7. Ve verzi SPSS Base korespondenční analýza bohužel není, ale lze vložit kontingenční tabulku (absolutní četnosti) např. do freeware programu PAST. PAST lze si lze stáhnout z (a tento prográmek umí mnohem, mnohem víc...).
 např. do freeware programu PAST. PAST lze si lze stáhnout z (a tento prográmek umí mnohem, mnohem víc...).")
41
Zdroj: data ISSP 2007, ČR (neváženo)
")
42
Znaménkové schéma → Adjustovaná residua převedeme na znaménka
Čtení knih podle vzdělání abs(z): >= 1.96 nahradíme + / – >= 2.58 nahradíme ++ / -- >= 3.29 nahradíme +++ / ---
: >= 1.96 nahradíme + / – >= 2.58 nahradíme ++ / -- >= 3.29 nahradíme +++ / ---")
43
SPSS: zadání Chíkvadrát testu v CROSSTABS
CROSSTABS R_podnik BY j_podnik / STATISTICS CHISQ.

44
CROSSTABS: zadání adjustovaných residuí pro znaménkové schéma
Samotné znaménkové schéma musíme následně vytvořit ručně z tabulky (dle hodnot z ) a nebo použít skript
 a nebo použít skript.")
45
Procvičit v SPSS 0. kontrola absolutních četností v jednotlivých polích → transformace (sloučení) 1. správně orientovaná procenta 2. Chíkvadrát test nezávislosti (tabulky jako celku) 3. adjustovaná residua a znaménkové schéma k detekování statisticky významných odchylek Úkoly (data ISSP 2007): Pohlaví a volil v 2006 Náboženské vyznání x Volil 2006 Náboženské vyznání x Velikost bydliště Náboženské vyznání x Velikost bydliště x Volil 2006
 3. adjustovaná residua a znaménkové schéma k detekování statisticky významných odchylek. Úkoly (data ISSP 2007): Pohlaví a volil v Náboženské vyznání x Volil Náboženské vyznání x Velikost bydliště. Náboženské vyznání x Velikost bydliště x Volil")
46
Načtení tabelárních dat v SPSS z agregované existující kontingenční tabulky (→ vážení procenty)
****nacteni kontingencni tabulky aneb sekundarni analyza (ČR, ISSP 2007). DATA LIST LIST/vek vzdel volil freq. VAL LAB vzdel 1 "ZŠ+VY" 2 "SŠ+VŠ" / vek 1 "<49" 2 ">50" / volil 1 "nevolil" 2 "volil". BEGIN DATA END DATA. FORMATS vek vzdel volil freq (f8). WEIGHT by freq. CROSS vzdel by volil by vek. CROSS vzdel by volil. Volil Věk Vzdělání 1 nevolil 2 volil 1 <49 1 ZŠ+VY 138 92 2 SŠ+VŠ 106 218 2 >50 143 257 56 175 Syntax: crosstab_data_input.sps Pozice pole v tabulce Volil Věk Vzdělání 1 nevolil 2 volil 1 <49 1 ZŠ+VY 111 112 2 SŠ+VŠ 121 122 2 >50 211 212 221 222
. DATA LIST LIST/vek vzdel volil freq. VAL LAB vzdel 1 ZŠ+VY 2 SŠ+VŠ / vek 1 <49 2 >50 / volil 1 nevolil 2 volil . BEGIN DATA END DATA. FORMATS vek vzdel volil freq (f8). WEIGHT by freq. CROSS vzdel by volil by vek. CROSS vzdel by volil. Volil. Věk. Vzdělání. 1 nevolil. 2 volil. 1 <49. 1 ZŠ+VY SŠ+VŠ > Syntax: crosstab_data_input.sps. Pozice pole v tabulce. Volil. Věk. Vzdělání. 1 nevolil. 2 volil. 1 <49. 1 ZŠ+VY SŠ+VŠ >")
47
Poměr šancí - ODDS RATIO
další možnost vyjádření asociací uvnitř kontingenční tabulky → Poměr šancí (ODDS RATIO) Viz prezentaci Poměr šancí - ODDS RATIO AKD2_odds_ratio.ppt (následuje kopie jen toho nejdůležitějšího)
 Viz prezentaci. Poměr šancí - ODDS RATIO. AKD2_odds_ratio.ppt. (následuje kopie jen toho nejdůležitějšího)")
48
Pomocí OR můžeme vyjádřit vztahy mezi kategoriemi v kontingenční tabulce
OR _= f11 f22 / f12 f21 = OR = (424*68)/(19*674) = 2,25 U vysokoškoláků je v porovnání s ostatními 2,25x vyšší šance, že půjdou volit. V CROSSTABS v SPSS pozor na kódování kategorií (nelze nastavit, pouze překódovat).
/(19*674) = 2,25. U vysokoškoláků je v porovnání s ostatními 2,25x vyšší šance, že půjdou volit. V CROSSTABS v SPSS pozor na kódování kategorií (nelze nastavit, pouze překódovat).")
49
Úkoly k procvičení v SPSS (data ISSP 2007)
2 x 2 tabulky: Pohlaví a Volil v 2006 Pohlaví a Vzdělání n x n tabulky: Velikost bydliště x Vzdělání → sloučení nebo pro vybraná pole tabulky

50
S tříděním druhého stupně bychom se neměli spokojit
S tříděním druhého stupně bychom se neměli spokojit. → Třídění třetího (a vyššího) stupně a elaborace vztahů
 stupně a elaborace vztahů.")
51
Vyloučení a zhodnocení vlivu třetího jevu → Elaborace vztahů
→ Třídění 3 stupně Kontingenční tabulka A x B x C Příklad: Volil x VŠ x Pohlaví Další možnosti: Parciální asociace/korelace Standardizace podle kontrolního faktoru (převážení) Multivariační metody (je-li závislá proměnná kardinální-číselná např. regresní analýza (OLS), analýza rozptylu (ANOVA); když je kategoriální, např. logistická regrese, loglineární modely)
 Multivariační metody (je-li závislá proměnná kardinální-číselná např. regresní analýza (OLS), analýza rozptylu (ANOVA); když je kategoriální, např. logistická regrese, loglineární modely)")
52
Třídění 3 stupně aneb kontrola pro další faktor (opakování z AKD I.)
Elaborace Třídění 3 stupně aneb kontrola pro další faktor (opakování z AKD I.)
")
53
Vícerozměrná analýza: třídění třetího stupně
Připomenutí z AKD I. Vícerozměrná analýza: třídění třetího stupně Analyzujeme souběžně vztahy mezi několika proměnnými (nejčastěji více nezávislých – vysvětlujících znaků). Princip je stejný jako u dvourozměrné analýzy.
. Princip je stejný jako u dvourozměrné analýzy.")
54
Princip vícerozměrné analýzy: třídění 3. stupně (2x2x2 tabulka)
Jak často navštěvujete bohoslužby? Rozdíl 9 % bodů Rozdíl 16 % bodů Zdroj: General Social Survey, NORC. Závislá proměnná: Chození do kostela souběžně podle 2 nezávislých: Věk, Pohlaví Jak mezi muži tak ženami starší lidé chodí do kostela častěji než mladí (tj. s věkem roste religiozita). V každé věkové kategorii ženy navštěvují kostel častěji než muži. Podle tabulky, pohlaví má nepatrně větší efekt na chození do kostela než věk. Věk a pohlaví mají nezávislý vliv na chození do kostela. Uvnitř každé kategorie nezávislé proměnné odlišné vlastnosti té druhé přesto ovlivňují jednání. Podobně obě nezávislé proměnné mají kumulativní efekt na jednání: Starší ženy chodí do kostela nejčastěji, zatímco mladí muži nejméně často. Zdroj: [Babbie 1997: ]
. V každé věkové kategorii ženy navštěvují kostel častěji než muži. Podle tabulky, pohlaví má nepatrně větší efekt na chození do kostela než věk. Věk a pohlaví mají nezávislý vliv na chození do kostela. Uvnitř každé kategorie nezávislé proměnné odlišné vlastnosti té druhé přesto ovlivňují jednání. Podobně obě nezávislé proměnné mají kumulativní efekt na jednání: Starší ženy chodí do kostela nejčastěji, zatímco mladí muži nejméně často. Zdroj: [Babbie 1997: ]")
55
Zjednodušení předchozí tabulky:
→ 70 % méně často dopočet do 100 % Ukazujeme pouze pozitivní kategorie znaku („do kostela chodí týdně). Při tom neztrácíme žádný údaj. Četnosti v závorkách uvádí procentní základ, z něj lze dopočítat podíl nezobrazené kategorie. Zdroj: [Babbie 1997: 391]
. Při tom neztrácíme žádný údaj. Četnosti v závorkách uvádí procentní základ, z něj lze dopočítat podíl nezobrazené kategorie. Zdroj: [Babbie 1997: 391]")
56
Příklad I.: Nepravá souvislost 1. bivariátní vztah (třídění 2.st.)
Zdroj: [Disman 1993: ]

57
2. Při kontrole vlivu vzdělání (třídění 3 st.)
")
58
2. Při kontrole vlivu vzdělání (třídění 3 st.)
Zdroj: [Disman 1993: ]

59
Příklad II. : Potlačená souvislost (nepravá nezávislost) 1
Příklad II.: Potlačená souvislost (nepravá nezávislost) 1. bivariátní vztah (třídění 2.st.) Zdroj: [Disman 1993: ]
 1. bivariátní vztah (třídění 2.st.) Zdroj: [Disman 1993: ]")
60
2. s kontrolou pohlaví (třídění 3 st.)
muži ženy Kontrola 3 faktoru odhalila potlačenou souvislost (nepravou nezávislost) mezi dvěma proměnnými Příčina zkreslení → vztah mezi dvěma proměnnými existuje pouze v části populace
 mezi dvěma proměnnými. Příčina zkreslení → vztah mezi dvěma proměnnými existuje pouze v části populace.")
61
Testování/ kontrola vlivu dalšího faktoru
Vytvořením samostatných tabulek podle kategorií třetí proměnné je testovaný faktor (třetí proměnná) udržován na konstantní hodnotě. → souvislost mezi původními proměnnými je očištěna od zkreslujícího vlivu této další proměnné.
 udržován na konstantní hodnotě. → souvislost mezi původními proměnnými je očištěna od zkreslujícího vlivu této další proměnné.")
62
Testování vlivu dalšího faktoru
Porovnáme intenzitu souvislosti v původní tabulce se souvislosti zjištěnou v nových tabulkách s kontrolou 3 faktoru . Když v nových tabulkách souvislost mezi původními daty zmizí/ je podstatně oslabena → souvislost v původní tabulce je funkcí třetího faktoru

63
Třídění 3 st.: kontrola vlivu 3 proměnné: interpretace a uspořádání tabulky
Souvisí účast ve volbách s věkem, i při kontrole vlivu vzdělání? Hypotetická data Rozdíly mezi krajními kategoriemi věku: 14 % 13 % % Ptáme se: 1. Nacházíme rozdíly v X (věk) a Y (volil) uvnitř kategorií kontrolní proměnné Z (vzdělání)? Porovnáme s tabulkou třídění 2. st. Pro X a Y. 2. Jsou rozdíly mezi krajními kategoriemi X (věk) v rámci kategorií kontrolní proměnné Z (vzdělání) stejné? Zatímco v případě ZŠ a SŠ jsou rozdíly mezi nejmladšími a nejstaršími stejné, tak u VŠ je rozdíl větší. → Vzdělání tedy do vztahu mezi volební účastí a věkem částečně intervenuje.
 a Y (volil) uvnitř kategorií kontrolní proměnné Z (vzdělání) Porovnáme s tabulkou třídění 2. st. Pro X a Y. 2. Jsou rozdíly mezi krajními kategoriemi X (věk) v rámci kategorií kontrolní proměnné Z (vzdělání) stejné Zatímco v případě ZŠ a SŠ jsou rozdíly mezi nejmladšími a nejstaršími stejné, tak u VŠ je rozdíl větší. → Vzdělání tedy do vztahu mezi volební účastí a věkem částečně intervenuje.")
64
Pozor v SPSS tabulka vypadá jinak.
→ Je možno jí upravit pomocí Pivot tables (v menu): Rozkliknout (2x klik) → Pivot Trays a přesunout) Příklad 1. Volil × věk × vzdělání (kontrolní proměnná) Zdroj: data ISSP 2007, ČR (neváženo)
: Rozkliknout (2x klik) → Pivot Trays a přesunout) Příklad 1. Volil × věk × vzdělání (kontrolní proměnná) Zdroj: data ISSP 2007, ČR (neváženo)")
65
Interakční a aditivní efekt
Efekt 1 na 2 proměnnou závisí na 3 proměnné Interakční efekt: Dvě proměnné navzájem interagují a vytváří u 3 proměnné jiný výsledek než by měla každá zvlášť Při absenci interakčního efektu lze uvažovat o aditivním efektu, kdy vlivy jsou v principu podobné ale podél kategorií 1 proměnné zesilují/ oslabují

66
Interakční a aditivní efekt
Interakční efekt – efekt jedné proměnné na druhou závisí na hodnotě třetí proměněné Hypotetická data Dopočet do 100 % je % Nevolil Odlišný vliv věku v kategoriích vzdělání: u Mladých žádný rozdíl, u Starších se % Volení zvyšuje s vyšším vzděláním. Nejvyšší volební účast je u starších vysokoškoláků. Aditivní efekt – efekty obou proměnných se propojují navzájem Stejný rozdíl mezi katg. věku v katg. vzdělání Podobný vliv věku kategoriích vzdělání

67
Příklad: moderace pohlavím (2) [Bryman 2008: 331-332]
Využívá jiné možnosti k pravidelnému cvičení než tělocvičnu x Věk x Pohlaví ← Pozor absolutní četnosti! Vzorec odpovědí je pro muže a ženy jiný: muži jako celek, ženy nárůst s věkem
![Příklad: moderace pohlavím (2) [Bryman 2008: ]](http://slideplayer.cz/slide/2902192/10/images/67/P%C5%99%C3%ADklad%3A+moderace+pohlav%C3%ADm+%282%29+%5BBryman+2008%3A+%5D.jpg "Využívá jiné možnosti k pravidelnému cvičení než tělocvičnu x Věk x Pohlaví. ← Pozor absolutní četnosti! Vzorec odpovědí je pro muže a ženy jiný: muži jako celek, ženy nárůst s věkem.")
68
Interakce (statistická)
vzájemný vliv dvou nebo více faktorů, který nastává pouze při jejich současném působení a projevuje se navíc nad samostatné působení jednotlivých faktorů a nad společné působení jen některých z nich. Podle počtu faktorů se hovoří o interakci druhého, třetího, k-tého řádu. Interakce se používá v modelech, ve kterých se hodnoty závisle proměnné vyjadřují jako součet (resp. součin) příspěvků dílčích vlivů nezávislých faktorů a jejich kombinací. Zdroj: [Řehák 1996: 441 (in Velký sociologický slovník)]
 příspěvků dílčích vlivů nezávislých faktorů a jejich kombinací. Zdroj: [Řehák 1996: 441 (in Velký sociologický slovník)]")
69
Odhalení vlivu 3. proměnné pomocí asociačních koeficientů
Rychlou identifikaci vlivu 3. proměnné můžeme provést pomocí asociačních koeficientů spočítaných zvlášť v jejích kategoriích. pro nominální znaky: Lambda, Phi, Cramérovo V, Koeficient kontingence pro ordinální znaky: ordinální korelace (Kendaullovo Tau-B a Tau-C, Spermanův korelační koeficient, Gamma) (Viz první část presentace.)
 (Viz první část presentace.)")
70
Dalším krokem analýzy může být přímá standardizace (podle faktoru Z)
Ukazujeme tzv. čistý vztah dvou proměnných očištěný o vliv třetí proměnné. Tabulku standardizujeme (převážíme) podle faktoru Z, tj. jako kdyby všichni v kategoriích X měli stejné podíly v kategoriích Z (např. stejné vzdělání). Jde o analogický postup k parciálním korelacím v případě tří kardinálních (ordinálních) znaků. Viz prezentaci Standardizace v kontingenční tabulce – kontrola vlivu 3 faktoru
 podle faktoru Z, tj. jako kdyby všichni v kategoriích X měli stejné podíly v kategoriích Z (např. stejné vzdělání). Jde o analogický postup k parciálním korelacím v případě tří kardinálních (ordinálních) znaků. Viz prezentaci Standardizace v kontingenční tabulce – kontrola vlivu 3 faktoru")
71
Vztahy mezi X-Y a (Z) podrobněji z hlediska kauzality
Moderace a mediace úvod

72
Vztah X-Y a Z: moderace a mediace
Mediátor (Z) propojuje příčinu a následek. Příčina ovlivňuje mediátorovou proměnnou a ta pak působí na závislou proměnnou Y. Moderátor (Z) modifikuje přímé působení nezávislé X na závislou proměnnou Y. Stálá vlastnost (např. kontextuální proměnná jako charakteristika okolí) modifikuje příčinnou závislost. [Hendl 2010].
 propojuje příčinu a následek. Příčina ovlivňuje mediátorovou proměnnou a ta pak působí na závislou proměnnou Y. Moderátor (Z) modifikuje přímé působení nezávislé X na závislou proměnnou Y. Stálá vlastnost (např. kontextuální proměnná jako charakteristika okolí) modifikuje příčinnou závislost. [Hendl 2010].")
73
Vztah X-Y a Z: moderace a mediace
Mediátor Moderátor Zdroj: [Hendl 2010: 3, 6]

74
Literatura Disman, M. (1993): Jak se vyrábí sociologická znalost. Praha: Karolinum. Kapitola 9. „Všechno je jinak aneb vícerozměrná analýza.“ (s ). Babbie, E. (1995). The Practice of social Research. 7th Edition. Belmont: Wadsworth Kapitola 16. „Elaboration Model.“ (s ). Hendl, J „Analýza působení mediátorových a moderátorových proměnných“ Informační Bulletin České statistické společnosti 21(1): 1-15. Řehák, J., B. Řeháková Analýza kategorizovaných dat v sociologii. Praha: Academia. Treiman, D. J Quantitative data analysis: doing social research to test ideas. San Francisco: Jossey-Bass. Kapitola 2. „More on Tables.“ (s ).
. Babbie, E. (1995). The Practice of social Research. 7th Edition. Belmont: Wadsworth. Kapitola 16. „Elaboration Model. (s ). Hendl, J „Analýza působení mediátorových a moderátorových proměnných Informační Bulletin České statistické společnosti 21(1): Řehák, J., B. Řeháková Analýza kategorizovaných dat v sociologii. Praha: Academia. Treiman, D. J Quantitative data analysis: doing social research to test ideas. San Francisco: Jossey-Bass. Kapitola 2. „More on Tables. (s ).")
Podobné prezentace







seznam.cz>")
>")


>")




>")



