Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Základní statistické charakteristiky

2
Údaje nestačí charakterizovat jenom střední hodnotou.
Omezenost středních hodnot spočívá v tom, že udávají pouze to, kolem jaké hodnoty se data „centrují“, resp. které hodnoty jsou nejčastější. Data se stejnou střední hodnotou mohou mít různou rozptýlenost. Velikost proměnlivosti dat zachycujeme vhodně vybranou mírou rozptýlenosti dat. Existuje mnoho měr rozptýlenosti a záleží na okolnostech, kdy a které použijeme. Numerické charakteristiky tvaru rozdělení dat mají důležitý význam při kondenzaci dat do několika málo údajů (nejlepší představu o datech nám ale poskytuje graf).
.")
3
Charakteristiky variability (rozptýlenosti)
měří rozptýlení hodnot příslušného souboru, tzn. určují rozmezí, v němž se výběrové údaje vyskytují využívají se k posouzení vypovídací schopnosti aritmetického průměru Obecně lze říci, že vypovídací schopnost aritmetického průměru je tím větší, čím je variabilita sledovaného znaku menší. rozšiřují informace o statistickém souboru

4
Míry (charakteristiky) variability
Absolutní – charakterizují měnlivost statistického souboru v absolutní velikosti, tzn. ve stejných jednotkách, jaké má znak (kg, l, m apod.) Mohou být vyjádřeny ve formě: prosté – není provedeno třídění, vážené – bylo provedeno třídění. Relativní – slouží k porovnávání variability statistických znaků lišících se měrnou jednotkou – měří variabilitu v poměru k úrovni sledovaného znaku
 Mohou být vyjádřeny ve formě: prosté – není provedeno třídění, vážené – bylo provedeno třídění. Relativní – slouží k porovnávání variability statistických znaků lišících se měrnou jednotkou. – měří variabilitu v poměru k úrovni. sledovaného znaku.")
5
Absolutní charakteristiky variability
Variační rozpětí rozdíl největší a nejmenší hodnoty znaku R = xmax – xmin Přednost: – rychlost výpočtu a jednoduchá interpretace Nevýhody: výskyt extrému vyvolá značnou velikost R (velká citlivost vůči odlehlým hodnotám) neříká nic o variabilitě hodnot uvnitř R
 neříká nic o variabilitě hodnot uvnitř R.")
6
Průměrná absolutní odchylka
aritmetický průměr absolutních individuálních odchylek jednotlivých hodnot znaku X od aritmetického průměru používá se výhradně pro přímé vyjádření úrovně variability Prostá forma Vážená forma

7
Rozptyl měří současně variabilitu hodnot kolem aritmetického průměru a také variabilitu ve smyslu vzájemných odchylek jednotlivých hodnot znaku je definován jako průměrná kvadratická odchylka měření od aritmetického průměru (průměr čtverců odchylek jednotlivých hodnot znaku od jejich aritmetického průměru) dává větší váhu extrémnějším hodnotám než průměrná absolutní odchylka používá se především při statistické indukci, např. při výpočtu různých testovacích statistik
 dává větší váhu extrémnějším hodnotám než průměrná absolutní odchylka. používá se především při statistické indukci, např. při výpočtu různých testovacích statistik.")
8
Prostá forma rozptylu Výpočtové tvary rozptylu

9
Vážená forma rozptylu Výpočtový tvar

10
Směrodatná odchylka uvádí se ve stejných měrných jednotkách jako zkoumaný znak Vlastnosti rozptylu Rozptyl konstanty je roven nule. Přičteme-li ke všem hodnotám znaku konstantu, rozptyl se nezmění. Násobíme-li všechny hodnoty znaku konstantou, rozptyl je násoben čtvercem této konstanty.

11
Rozptyl součtu dvou proměnných sz2, kde zi = xi + yi, je roven součtu rozptylů obou proměnných zvětšenému o dvojnásobek kovariance. Kovariance proměnných x a y charakterizuje závislost obou proměnných – blíže v regresní a korelační analýze.

12
Předpokládejme, že statistický soubor o rozsahu n statistických jednotek je rozdělen do k dílčích podsouborů, kde známe dílčí rozptyly , dílčí průměry a četnosti ni. Pak rozptyl celého souboru je dán součtem rozptylu skupinových (dílčích) průměrů a průměru ze skupinových rozptylů.
 průměrů a průměru ze skupinových rozptylů..")
13
Při pokusu porozumět výpočtu směrodatné odchylky si všímáme jednotlivých operací:
Nejdříve vypočteme jednotlivé odchylky od průměru, které pro daný údaj vyjadřují, jak se liší od typické hodnoty. Čtverec odchylky (umocnění na druhou) převádí záporné odchylky na kladná čísla a zároveň větším odchylkám dává větší váhu. Například odchylce –2 dává váhu 4, ale odchylce 3 dává váhu 9. Součet (suma) čtverců odchylek zachycuje všechny odchylky jedním číslem. Dělením číslem (n–1) počítáme průměr kvadratických odchylek. Odmocnina převádí druhou mocninu do původního měřítka dat.
 převádí záporné odchylky na kladná čísla a zároveň větším odchylkám dává větší váhu. Například odchylce –2 dává váhu 4, ale odchylce 3 dává váhu 9. Součet (suma) čtverců odchylek zachycuje všechny odchylky jedním číslem. Dělením číslem (n–1) počítáme průměr kvadratických odchylek. Odmocnina převádí druhou mocninu do původního měřítka dat.")
14
Základní vlastnosti směrodatné odchylky:
směrodatná odchylka měří rozptýlenost kolem průměrů a má se používat jenom tehdy, když průměr je vhodný jako míra střední hodnoty, s = 0 pouze tehdy, když se všechna data rovnají stejné hodnotě, jinak s > 0, stejně jako průměr je i směrodatná odchylka silně ovlivněna extrémními hodnotami – jedna nebo dvě odlehlé hodnoty zvětšují silně s, jestliže je rozdělení dat silně zešikmené, směrodatná odchylka neposkytuje dobrou informaci o rozptýlenosti dat – v takovém případě používáme kvantilové míry.

15
Relativní charakteristiky variability
slouží ke srovnávání variability různých statistických znaků a souborů chceme-li posoudit relativní velikost rozptýlenosti dat vzhledem k průměru počítáme je, když chceme porovnat rozptýlenost dat skupin měření stejné proměnné s různým průměrem nebo v těch případech, kdy se mění velikost směrodatné odchylky tak, že je přímo závislá na úrovni měřené proměnné , kde k je konstanta)
")
16
Relativní průměrná odchylka
Variační koeficient V > 50 % je znakem značné nesourodosti souboru

17
Příklad Máme k dispozici následující data: 2 8 9 10 1 0 5.
Chceme popsat variabilitu tohoto souboru. Protože nebylo provedeno třídění, veškeré vztahy budou vyjádřeny ve formě prosté.

20
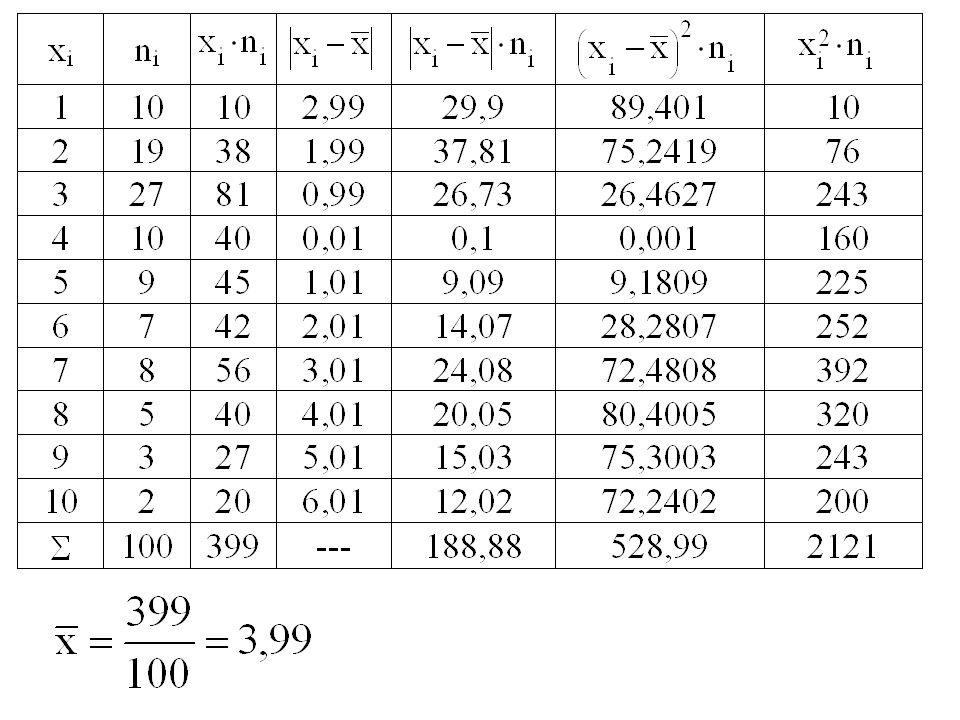
Příklad Máme data týkající se věku pojištěných aut. Tento soubor chceme popsat pomocí charakteristik variability. Vzhledem k provedenému třídění je nutno použít vážené formy pro všechny charakteristiky variability.

23
Variační koeficient nabývá hodnoty 57,9 %, což svědčí o značné rozptýlenosti hodnot souboru (rozložení jednotlivých četností vykazuje určité výkyvy). Pokud bychom na základě tohoto souboru prováděli další statistická šetření (odhady na základní soubor), budou závěry těmito výsledky značně zkresleny.
, budou závěry těmito výsledky značně zkresleny..")
24
Příklad Zajímá nás variabilita měsíčních výdajů sledovaných domácností.

27
Kvantilové charakteristiky
Kvantily – hodnoty, které dělí uspořádaný statistický soubor na určitý počet stejně obsazených částí. Kvartily – dělí uspořádaný soubor na čtyři stejně obsazené části. dolní kvartil odděluje 25 % nejmenších hodnot prostřední kvartil (medián) dělí uspořádaný výběr na dvě stejně obsazené části, z nichž každá obsahuje 25 % jednotek horní kvartil odděluje 75 % uspořádaných hodnot znaku od 25 % největších hodnot znaku
 dělí uspořádaný výběr na dvě stejně obsazené části, z nichž každá obsahuje 25 % jednotek. horní kvartil odděluje 75 % uspořádaných hodnot znaku od 25 % největších hodnot znaku.")
28
Decily – dělí uspořádaný soubor na deset stejně obsazených částí
Percentily – dělí soubor na sto stejně obsazených částí. Kvantilové rozpětí – rozdíl mezi nejvyšším a nejnižším kvantilem. Kvartilové rozpětí – diference horního a dolního kvartilu (v tomto intervalu se nachází 50 % údajů, není tak citlivé vůči odlehlým hodnotám) Decilové rozpětí
 Decilové rozpětí.")
29
Kvantilová odchylka – aritmetický průměr kladných odchylek sousedních kvantilů
Kvartilová odchylka – průměr kladných odchylek sousedních kvartilů Decilová odchylka

30
Kvartilová odchylka představuje tzv
Kvartilová odchylka představuje tzv. robustní alternativu směrodatné odchylky, tzn. není ovlivňována extrémně malými, resp. extrémně velkými hodnotami analyzovaného souboru. Relativní kvantilové rozpětí – kvantilové rozpětí dělené mediánem Relativní kvartilová odchylka – kvartilová odchylka dělená mediánem

31
Shrnutí Kvantilová rozpětí jsou lepšími měrami než variační rozpětí R, protože nejsou ovlivněna extrémními hodnotami (nejsou citlivá k odlehlým hodnotám). Nevýhodou kvantilových charakteristik variability je to, že nezachycují variabilitu všech hodnot znaku a vzhledem k jejich konstrukci je nelze hlouběji analyzovat a rozkládat.
. Nevýhodou kvantilových charakteristik variability je to, že nezachycují variabilitu všech hodnot znaku a vzhledem k jejich konstrukci je nelze hlouběji analyzovat a rozkládat.")
32
R = xmax – xmin = 3508 – 833 = 2675 Příklad Kvartilové rozpětí
Vypočtěte kvantilové míry variability pro tento soubor (pro výpočet kvantilových měr je potřeba hodnoty souboru seřadit podle velikosti): 833 1346 1505 1684 2327 856 1354 1534 1805 2867 1077 1419 1652 2116 3508 R = xmax – xmin = 3508 – 833 = 2675 Kvartilové rozpětí
: R = xmax – xmin = 3508 – 833 = Kvartilové rozpětí.")
33
Decilové rozpětí

34
Kvartilová odchylka Decilová odchylka

35
Míry šikmosti slouží k jemnějšímu popisu specifických stránek dat, hodnotíme pomocí nich také to, jak se rozdělení dat podobá normální křivce jsou založeny na srovnání stupně nahuštěnosti malých hodnot sledovaného statistického znaku se stupněm nahuštěnosti velkých hodnot tohoto znaku stejný stupeň hustoty malých a velkých hodnot se zpravidla projevuje v symetrii tvaru rozdělení větší (stupeň) koncentrace malých hodnot a menší koncentrace velkých hodnot (ve srovnání s hustotou velkých hodnot) se projeví sešikmeným tvarem rozdělení, které označujeme jako kladné
 koncentrace malých hodnot a menší koncentrace velkých hodnot (ve srovnání s hustotou velkých hodnot) se projeví sešikmeným tvarem rozdělení, které označujeme jako kladné.")
36
větší (stupeň) koncentrace velkých hodnot ve srovnání s menší koncentrací (hustotou) malých hodnot se projeví zpravidla záporně sešikmeným tvarem rozdělení (příslušné míry jsou záporné) Výpočet se opírá o stanovení třetího centrálního momentu, míry mohou mít opět formu prostou a formu váženou (záleží na provedeném třídění). Forma prostá Forma vážená
. Forma prostá. Forma vážená.")
37
Kvantilové míry šikmosti
= 0 platí přibližně pro rozdělení přibližně symetrické, 0 pro rozdělení s kladným zešikmením, rozdělení zešikmená doleva 0 pro rozdělení se záporným zešikmením, rozdělení zešikmená doprava Kvantilové míry šikmosti -1 1, ve zcela symetrickém rozdělení nabývá hodnoty 0 Kvartilová míra šikmosti

38
Příklad na výpočet měr šikmosti

39
Všechny soubory mají stejný rozsah, průměr, rozptyl, medián a modus
Všechny soubory mají stejný rozsah, průměr, rozptyl, medián a modus. Přesto se ale liší.

40
= 15 Základní charakteristiky Soubor A = soubor B = soubor C
Soubor A – rozdělení četností je souměrné okolo průměru Soubor B a C – rozdělení četností je nesouměrné Rozdělení souboru B – polovina malých hodnot znaku má menší variabilitu než polovina velkých hodnot, tzn. jde o rozdělení s kladnou šikmostí (rozdělení zešikmené doleva). Rozdělení souboru C – polovina malých hodnot znaku má větší variabilitu než polovina velkých hodnot znaku, tzn. jedná se o rozdělení se zápornou šikmostí (rozdělení zešikmené doprava).
. Rozdělení souboru C – polovina malých hodnot znaku má větší variabilitu než polovina velkých hodnot znaku, tzn. jedná se o rozdělení se zápornou šikmostí (rozdělení zešikmené doprava).")
41
Výpočet míry šikmosti – vzhledem k provedené třídění je nutno použít váženou formu
Soubor A xi ni 10 13 -5 25 -125 -1625 15 24 20 5 125 1625 50 x

42
Soubor B = 1,86280 sešikmení doleva Soubor C = -1,86280 sešikmení doprava

43
Míry špičatosti představují stupeň koncentrace hodnot znaku kolem charakteristiky úrovně jsou založeny na srovnání stupně nahuštěnosti hodnot prostřední velikosti se stupněm nahuštěnosti ostatních hodnot, resp. všech hodnot proměnné je-li podíl četností prostředních hodnot srovnatelný s četnostmi ostatních hodnot, špičatost se projevuje zpravidla plochým tvarem rozdělení četností větší stupeň koncentrace (nahuštění) prostředních hodnot ve srovnání s četnostmi všech (ostatních) hodnot proměnné se projeví špičatým tvarem rozdělení
 prostředních hodnot ve srovnání s četnostmi všech (ostatních) hodnot proměnné se projeví špičatým tvarem rozdělení.")
44
Pro číselné stanovení šikmosti lze použít vzorec buď ve formě prosté nebo ve formě vážené
vyšší číselná hodnota – usuzuje se na špičatější rozdělení četností a tím zároveň na vyšší stupeň koncentrace prostředních hodnost ve srovnání s ostatními hodnotami míra špičatosti kladná – dané rozdělení je špičatější než normální míra špičatosti záporná – dané rozdělení je plošší než normální

45
Při posuzování špičatosti se vychází ze srovnání popisovaného rozdělení (z tabulky četností zkoumaného znaku) s normovaným normálním rozdělením. Charakteristika špičatosti se totiž opírá o čtvrtý moment směrodatné proměnné, který je u modelu normálního rozdělení roven 3, takže míra špičatosti u normálního rozdělení je pak rovna nule. Je-li u popisovaného rozdělení míra špičatosti větší než nula, potom je toto rozdělení špičatější než normované normální rozdělení. Je-li míra špičatosti menší než nula (záporné číslo, ne však menší než –3), je popisované rozdělení plošší než normované normální rozdělení. Čím je tato míra odlišnější od nuly, tím více je rozdělení špičatější, resp. plošší.
, je popisované rozdělení plošší než normované normální rozdělení. Čím je tato míra odlišnější od nuly, tím více je rozdělení špičatější, resp. plošší.")
46
Příklad na výpočet měr špičatosti
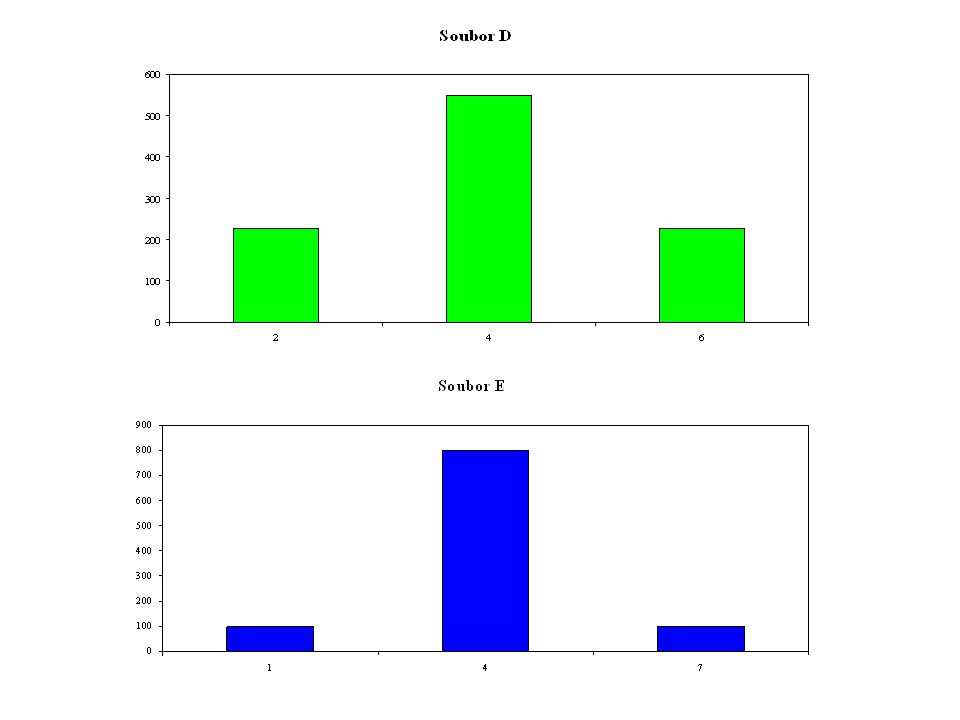
Soubory mají stejný rozsah n = 1000, stejný aritmetický průměr, medián, modus v hodnotě 4, stejný rozptyl s2 = 1,8018 a stejnou šikmost = 0; liší se koncentrací hodnot znaku kolem střední hodnoty.

48
Soubor D – plošší rozdělení četností

49
Soubor E = 1,99 vyšší koncentrace hodnot okolo střední hodnoty, rozdělení je špičatější

50
Kvartily (dolní, medián a horní) spolu s minimální a maximální hodnotou souboru tvoří tzv. pětičíselný souhrn charakteristik, který podává rychlou a přehlednou informaci o poloze, variabilitě i případném asymetrickém rozložení hodnot zkoumaného statistického souboru. Graficky se tento souhrn vyjadřuje pomocí speciálního diagramu, nazývaného box-and-whisker plot (stručněji boxplot nebo také krabicový graf). Boxplot umožňuje posoudit a porovnat jak centrální tendence dat, tak jejich rozptýlenost, dále umožňuje posoudit zešikmení a přítomnost odlehlých hodnot. Diagram zobrazuje data ve tvaru obdélníkové krabice a dvou úseček, které z ní vybíhají nalevo a napravo.
. Boxplot umožňuje posoudit a porovnat jak centrální tendence dat, tak jejich rozptýlenost, dále umožňuje posoudit zešikmení a přítomnost odlehlých hodnot. Diagram zobrazuje data ve tvaru obdélníkové krabice a dvou úseček, které z ní vybíhají nalevo a napravo.")
51
Krabice obsahuje 50 % dat a je rozdělena mediánem na dvě části (pro symetricky rozložená data je medián uprostřed krabice). Její dolní hrana (event. levá strana krabice) je určena dolním kvartilem a horní hrana (event. pravá strana krabice) odpovídá hornímu kvartilu. Délka krabice ukazuje na stupeň variability zobrazeného souboru (kvartilové rozpětí = třetí kvartil – první kvartil). Pokud je medián blízko jedné z horizontálních hran krabičky, rozdělení dat je zešikmené v opačném směru. Úsečky vybíhající z krabice spojují ty body, jež vyhovují relaci
 je určena dolním kvartilem a horní hrana (event. pravá strana krabice) odpovídá hornímu kvartilu. Délka krabice ukazuje na stupeň variability zobrazeného souboru (kvartilové rozpětí = třetí kvartil – první kvartil). Pokud je medián blízko jedné z horizontálních hran krabičky, rozdělení dat je zešikmené v opačném směru. Úsečky vybíhající z krabice spojují ty body, jež vyhovují relaci.")
52
Délka úseček pak signalizuje přítomnost asymetrického rozdělení (pokud je jedna z úseček zřetelně větší než druhá). Hodnoty ležící mimo vymezený vztah, tzn. že jsou vzdáleny od dolního (horního) kvartilu o více než 1,5násobek kvartilového rozpětí IQR, představují tzv. odlehlá pozorování a v diagramu jsou vyznačovány jako izolované body. Data, která jsou menší než dolní kvartil (respektive větší než horní kvartil) o více než trojnásobek kvartilového rozpětí, jsou považována za extrémní pozorování (tzn. pozorování výrazně inkonzistentní s analyzovaným datovým souborem).
 kvartilu o více než 1,5násobek kvartilového rozpětí IQR, představují tzv. odlehlá pozorování a v diagramu jsou vyznačovány jako izolované body. Data, která jsou menší než dolní kvartil (respektive větší než horní kvartil) o více než trojnásobek kvartilového rozpětí, jsou považována za extrémní pozorování (tzn. pozorování výrazně inkonzistentní s analyzovaným datovým souborem).")
53
Pro odlehlá pozorování může existovat několik vysvětlení:
jedná se o údaje, které se do souboru dostaly v důsledku nějakých hrubých chyb (např. v důsledku chybných měření, chyby při zápisu apod.), jedná se o pozorování, která nepocházejí z téhož ZS jako ostatní analyzovaná data, jedná se o správný údaj, který však reprezentuje nějaký mimořádný případ. Postupy, které lze použít v případě odlehlých pozorování: za určitých okolností (např. provedení testu) se odlehlá měření vyřazují z dalšího zpracování (pokud však nedojde ke značnému snížení rozsahu souboru). Při větších rozsazích souboru lze použít různá obecná pravidla, např. pravidlo tří sigma, boxplot.
, jedná se o pozorování, která nepocházejí z téhož ZS jako ostatní analyzovaná data, jedná se o správný údaj, který však reprezentuje nějaký mimořádný případ. Postupy, které lze použít v případě odlehlých pozorování: za určitých okolností (např. provedení testu) se odlehlá měření vyřazují z dalšího zpracování (pokud však nedojde ke značnému snížení rozsahu souboru). Při větších rozsazích souboru lze použít různá obecná pravidla, např. pravidlo tří sigma, boxplot.")
54
Při vylučování odlehlých hodnot nelze postupovat mechanicky, protože pro některé množiny dat jsou odlehlé hodnoty typickým jevem, což je nutné zohlednit v celé další statistické analýze. všechny propočty a úvahy se provedou pro množinu měření bez odlehlých hodnot a s odlehlými hodnotami a posuzuje se rozdílnost získaných závěrů, použijí se rezistentní odhady, které nejsou citlivé k odlehlým hodnotám (robustní charakteristiky). Při použití rezistentních odhadů se vychází z poznatku, že aritmetický průměr je velmi citlivý vůči krajním hodnotám. Při podezření, že výběr obsahuje odlehlé hodnoty, se ho snažíme nahradit jiným výpočtem. Medián tak lze prohlásit za rezistentní odhad střední hodnoty, protože vždy jde o 50% kvantil.
. Při použití rezistentních odhadů se vychází z poznatku, že aritmetický průměr je velmi citlivý vůči krajním hodnotám. Při podezření, že výběr obsahuje odlehlé hodnoty, se ho snažíme nahradit jiným výpočtem. Medián tak lze prohlásit za rezistentní odhad střední hodnoty, protože vždy jde o 50% kvantil.")
55
Jedním z nejefektivnějších a přitom jednoduchých odhadů parametru polohy je uřezaný (useknutý) průměr. Useknutý znamená, že při výpočtu aritmetického průměru zcela ignorujeme určité procento extrémních hodnot (jde o uřezané hodnoty na každém konci, tzn. jak hodnot nejvyšších, tak nejnižších). Optimální hodnota bývá 10 %. Useknutý průměr představuje vypuštění určitého počtu hodnot a to jak na straně minima, tak i maxima (useknutí je rovnoměrné z obou stran). ……………… Pokud chci useknout 2 proměnné, pak konečný soubor bude vypadat takto: ……………….. 25, tzn. dochází ke snížení rozsahu souboru.
. Optimální hodnota bývá 10 %. Useknutý průměr představuje vypuštění určitého počtu hodnot a to jak na straně minima, tak i maxima (useknutí je rovnoměrné z obou stran) ……………… Pokud chci useknout 2 proměnné, pak konečný soubor bude vypadat takto: ……………….. 25, tzn. dochází ke snížení rozsahu souboru.")
56
Winsorizovaný průměr Používá se tehdy, pokud soubor obsahuje extrémní hodnoty, ale jde o soubor malého rozsahu, kdy useknutí značným způsobem snižuje rozsah souboru. Winsorizovaný průměr představuje nahrazení extrému sousední hodnotou, a to jak na straně minima, tak i maxima (nahrazení je rovnoměrné z obou stran). ……………… Pokud chci odstranit 2 dolní extrémy, pak konečný soubor bude vypadat takto: ……………… , tzn. nedochází ke snížení rozsahu souboru. Z takto upravených hodnot se pak počítá aritmetický průměr.
 ……………… Pokud chci odstranit 2 dolní extrémy, pak konečný soubor bude vypadat takto: ……………… , tzn. nedochází ke snížení rozsahu souboru. Z takto upravených hodnot se pak počítá aritmetický průměr.")
57
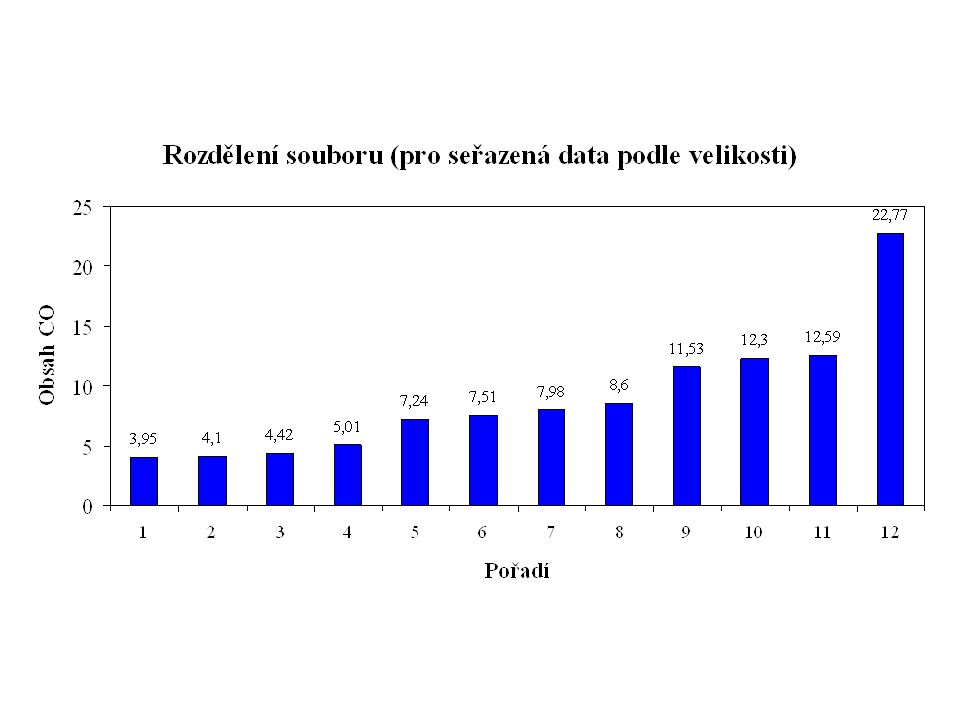
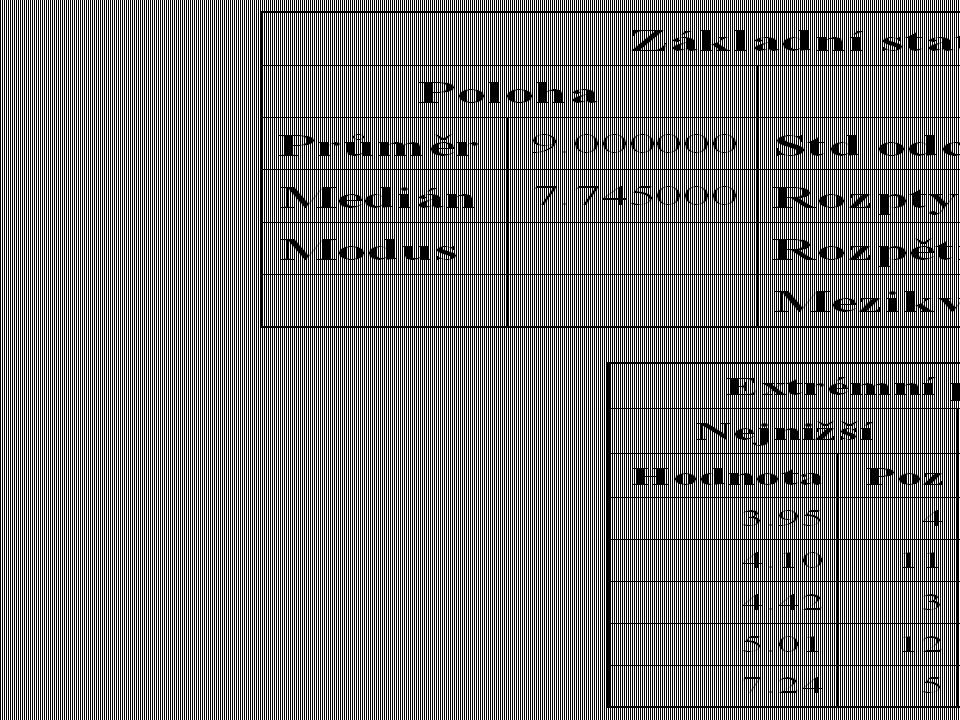
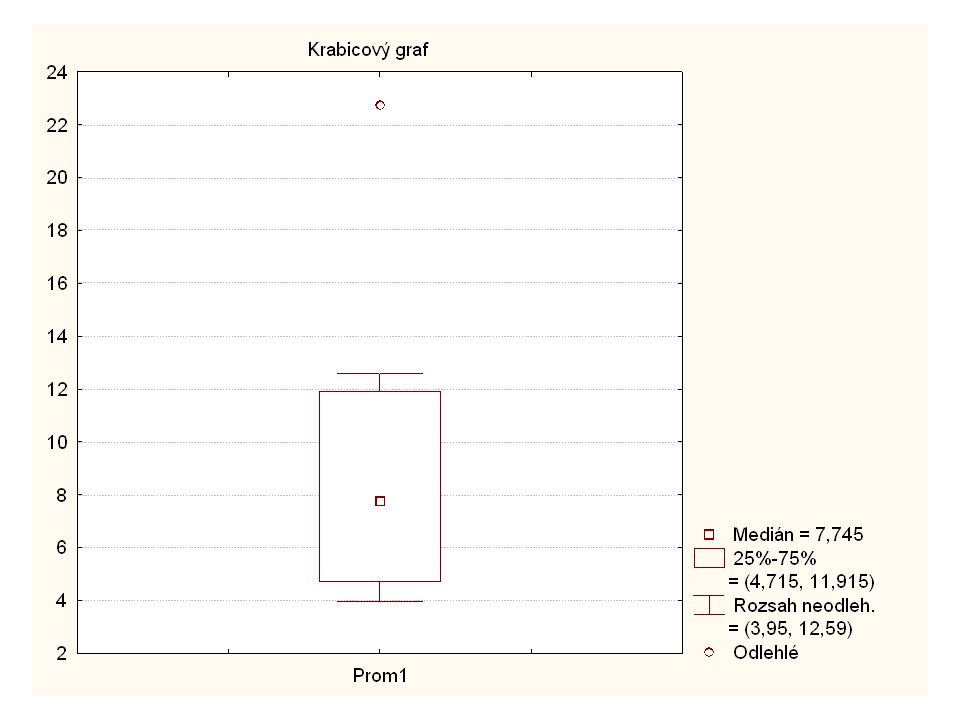
Příklad Při měření obsahu CO ve výfukových plynech automobilů byly zjištěny tyto hodnoty (v g/m3).
.")
62
Daný soubor obsahuje jedno odlehlé pozorování, které má vliv na velikost charakteristik polohy a variability. Z grafu je patrné, že toto odlehlé pozorování způsobilo posun aritmetického průměru směrem doprava (jeho hodnota se liší od mediánu), a proto v tomto případě představuje medián vhodnější charakteristiku polohy.
, a proto v tomto případě představuje medián vhodnější charakteristiku polohy.")
63
Průzkumová analýza jednorozměrných dat

64
Účelem průzkumové analýzy dat je odhalit jejich zvláštnosti a ověřit předpoklady pro následné statistické zpracování. Při průzkumové analýze složitějších, nákladných nebo unikátních měření je účelem posoudit zvláštnosti chování dat ještě před vlastní rutinní statistickou analýzou. Tak lze zabránit provádění numerických výpočtů bez hlubších statistických souvislostí. Při analýze všech typů měření je nezbytné uvažovat náhodný charakter naměřených hodnot xi. Při zpracování jednorozměrných výběrů, pocházejících se souborů o ne zcela známém rozdělení, je sledován pouze jeden znak. Počet prvků přitom může být omezený a soubor je pak konečný, nebo neomezený a soubor je nekonečný. Vymezení souboru je velmi důležité, protože ovlivňuje způsob vybírání prvků do výběru a interpretaci výsledků. Cílem statistického zpracování je z chování výběru usuzovat na chování celého souboru.

65
Z různých typů výběru se nejvíce uplatňuje náhodný výběr, jehož prvky (naměřené hodnoty) jsou chápány jako realizace jisté náhodné veličiny. Reprezentativní výběr je charakterizován následujícími předpoklady: jednotlivé prvky výběru jsou vzájemně nezávislé, výběr je homogenní, tj. všechna xi pocházejí ze stejného rozdělení pravděpodobnosti s konstantním rozptylem, předpokládá se také, že jde o normální rozdělení pravděpodobnosti, všechny prvky souboru mají stejnou pravděpodobnost, že budou zařazeny do výběru.

66
Uvedené předpoklady tvoří základ statistických metod vyhodnocení výsledků měření.
Pokud výběr nesplňuje uvedené předpoklady, je jeho statistická analýza daleko komplikovanější a nelze použít klasické postupy pro statistickou indukci (odhady). Před vlastní statistickou analýzou je nezbytné vyšetřit platnost základních předpokladů, tj. nezávislost, homogenitu a normalitu výběru. Postup statistické analýzy jednorozměrných dat lze shrnout do 3 bloků, které je možné provádět samostatně (blok A, blok B, blok A + B, blok B +C a bloky A + B + C). Blok A představuje samotnou průzkumovou analýzu, kdy se vyšetřují statistické zvláštnosti dat.
. Před vlastní statistickou analýzou je nezbytné vyšetřit platnost základních předpokladů, tj. nezávislost, homogenitu a normalitu výběru. Postup statistické analýzy jednorozměrných dat lze shrnout do 3 bloků, které je možné provádět samostatně (blok A, blok B, blok A + B, blok B +C a bloky A + B + C). Blok A představuje samotnou průzkumovou analýzu, kdy se vyšetřují statistické zvláštnosti dat.")
67
Blok A: průzkumová (exploratorní) analýza dat (EDA)
odhalení stupně symetrie a špičatosti výběrového rozdělení, indikace lokální koncentrace výběru dat, nalezení vybočujících a podezřelých prvků ve výběru, porovnání výběrového rozdělení dat s typickými rozděleními, mocninná transformace výběru, Boxova – Coxova transformace výběru. Mocninná nebo Boxova – Coxova transformace je vhodná především při asymetrii rozdělení původních dat, ale také při nekonstantnosti rozptylu.

68
V bloku B se ověřují základní předpoklady kladené na výběr jako jsou nezávislost prvků, homogenita výběru, dostatečný rozsah výběru a rozdělení výběru. Jsou-li závěry tohoto kroku optimistické, následuje vyčíslení klasických odhadů polohy a variability. Dále se vyčíslí intervaly spolehlivosti, následované testováním statistických hypotéz. V pesimistickém případě následuje další pokus o úpravu dat. Blok B: ověření předpokladů o datech ověření nezávislosti prvků výběru, ověření homogenity rozdělení výběru, určení minimálního rozsahu výběru, ověření normality rozdělení výběru.

69
Blok C představuje tzv. konfirmatorní analýzu (zaměřuje se na ověřování hypotéz), v rámci které je nabízena paleta rozličných odhadů polohy, variability a tvaru, jež lze rozdělit do dvou skupin – na klasické odhady a na robustní odhady (necitlivé na odlehlé prvky výběru, resp. další předpoklady o datech). Z nabídky odhadů parametrů vybírá uživatel uvážlivě ty, jež mají statistický smysl a odpovídají závěrům průzkumové analýzy dat a ověření předpokladů o výběru. Blok C: konfirmatorní analýza dat (CDA) – odhady parametrů (polohy, variability a tvaru): klasické odhady (bodové a intervalové) z výběru, robustní odhady (bodové a intervalové) z výběru.
 – odhady parametrů (polohy, variability a tvaru): klasické odhady (bodové a intervalové) z výběru, robustní odhady (bodové a intervalové) z výběru.")
70
Metody průzkumové analýzy dat
Cílem průzkumové analýzy je nalezení zvláštností statistického chování dat. Pro průzkumovou analýzu se užívají především grafické metody, které umožňují komplexní posouzení statistických zvláštností dat. Tyto metody jsou vhodné také pro zjednodušení popisu dat, identifikaci typu rozdělení výběru, konstrukci empirického rozdělení výběru a zlepšení rozdělení dat. Při průzkumové analýze se využívá především robustních kvantilových charakteristik, které umožňují sledování lokálního chování dat a které jsou vhodné pro malé nebo středně velké výběry. Pozn.: vychází se z pořádkových statistik, což jsou vzestupně setříděné prvky výběru x1 x2 … xn.

71
Grafy identifikace statistických zvláštností dat
Mezi základní statistické zvláštnosti patří stupeň symetrie a špičatosti rozdělení výběru, lokální koncentrace dat a přítomnost vybočujících pozorování. Jednotlivé grafy poskytují informace o několika, popř. pouze jedné, statistických zvláštnostech. Kvantilový graf – umožňuje přehledně znázornit data a snadněji rozlišit tvar rozdělení. Ten může být symetrický, zešikmený k vyšším nebo nižším hodnotám. Dále lze identifikovat lokální koncentrace dat, vybočující data atd.. Ke snadnějšímu porovnání s normálním rozdělením se do tohoto grafu zakreslují i kvantilové funkce normálního rozdělení.

72
Diagram rozptýlení – představuje jednorozměrnou projekci kvantilového grafu do osy x. I při své jednoduchosti tento diagram ukazuje na lokální koncentrace dat a indikuje i podezřelá a vybočující měření. Diagram percentilů – zobrazuje vybrané percentily, z výsledného obrazce lze usuzovat na symetrii rozdělení nebo na jeho tvar. Krabicový graf – pro částečnou sumarizaci dat, graf umožňuje znázornění robustního odhadu polohy (mediánu), posouzení symetrie v okolí kvantilů, posouzení symetrie u konců rozdělení, identifikaci odlehlých dat.
, posouzení symetrie v okolí kvantilů, posouzení symetrie u konců rozdělení, identifikaci odlehlých dat.")
73
Vrubový krabicový graf – obdoba krabicového grafu, umožňuje i posouzení variability medián.
Graf polosum – pro symetrické rozdělení je grafem polosum horizontální přímka, určená rovnicí y = M. U tohoto grafu je důležité, že zde body oscilují okolo horizontální přímky a vykazují tak náhodný shluk (mrak) a měřítko osy y je silně detailní. Naopak, pro asymetrické rozdělení vykazuje nenáhodný trend a body neoscilují okolo horizontální přímky a měřítko osy y není detailní. Graf symetrie – symetrická rozdělení jsou charakterizována přímkou y = M. Pokud tato přímka nemá nulovou směrnici, je směrnice odhadem parametru šikmosti. Asymetrické rozdělení vykazuje body uspořádané v trendu nějaké křivky.
 a měřítko osy y je silně detailní. Naopak, pro asymetrické rozdělení vykazuje nenáhodný trend a body neoscilují okolo horizontální přímky a měřítko osy y není detailní. Graf symetrie – symetrická rozdělení jsou charakterizována přímkou y = M. Pokud tato přímka nemá nulovou směrnici, je směrnice odhadem parametru šikmosti. Asymetrické rozdělení vykazuje body uspořádané v trendu nějaké křivky.")
74
Graf šikmosti – pro případ symetrického rozdělení rezultuje u grafu šikmosti přímková závislost s nulovým úsekem a jednotkovou směrnicí (body leží těsně na této přímce). U asymetrického rozdělení body neleží na této přímce a vykazují jinou směrnici. Graf špičatosti – pro normální rozdělení je grafem horizontální přímka a body leží převážně na této přímce. Pokud body tvoří nenáhodný trend, odpovídá hodnota směrnice této aktuální přímky parametru špičatosti). Diferenční kvantilový graf – slouží k posouzení rozdělení se špičatostí odpovídající normálnímu rozdělení. Graf rozptýlení s kvantily – základem je odhad kvantilové funkce výběru. Pro symetrická rozdělení má kvantilová funkce sigmoidální tvar, pro rozdělení zešikmená k vyšším hodnotám je konvexně rostoucí a pro rozdělení zešikmená k nižším hodnotám konkávně rostoucí.
. Diferenční kvantilový graf – slouží k posouzení rozdělení se špičatostí odpovídající normálnímu rozdělení. Graf rozptýlení s kvantily – základem je odhad kvantilové funkce výběru. Pro symetrická rozdělení má kvantilová funkce sigmoidální tvar, pro rozdělení zešikmená k vyšším hodnotám je konvexně rostoucí a pro rozdělení zešikmená k nižším hodnotám konkávně rostoucí.")
75
Histogram – sloupcový graf, kdy výšky sloupců odpovídají empirickým hustotám pravděpodobnosti.
Kvantilově – kvantilový graf (graf Q – Q) – umožňuje posoudit shodu výběrového rozdělení, jež je charakterizováno kvantilovou funkcí QE(P) s kvantilovou funkcí zvoleného teoretického rozdělení QT(P) (v případě shody je závislost lineární). Rankitový graf – pro porovnání rozdělení výběru s rozdělením normálním se Q-Q graf nazývá rankitový. Umožňuje orientační zařazení výběrového rozdělení do skupin podle šikmosti, špičatosti a délky konců. Podmíněný rankitový graf – používá se k ověření normality výběrových rozdělení (využívá standardizovanou kvantilovou funkci normálního rozdělení).
 – umožňuje posoudit shodu výběrového rozdělení, jež je charakterizováno kvantilovou funkcí QE(P) s kvantilovou funkcí zvoleného teoretického rozdělení QT(P) (v případě shody je závislost lineární). Rankitový graf – pro porovnání rozdělení výběru s rozdělením normálním se Q-Q graf nazývá rankitový. Umožňuje orientační zařazení výběrového rozdělení do skupin podle šikmosti, špičatosti a délky konců. Podmíněný rankitový graf – používá se k ověření normality výběrových rozdělení (využívá standardizovanou kvantilovou funkci normálního rozdělení).")
76
Pravděpodobností graf (P – P graf) – je alternativou ke Q – Q grafu, slouží k porovnání distribuční funkce výběru, vyjádřené přes pořadovou pravděpodobnost, se standardizovanou distribuční funkcí teoretického rozdělení. Při konstrukci P – P grafů je nezbytné znát teoretické rozdělení až do hodnot všech parametrů. Při porovnání Q-Q a P-P grafů platí, že P-P grafy jsou citlivé na odchylky od teoretického rozdělení ve střední části (v okolí módu), Q-Q grafy jsou citlivé na odchylky od teoretického rozdělení v oblasti konců. Je tedy patrné, že oba typy grafů se vzájemně doplňují. Kruhový graf – slouží k vizuálnímu ověření hypotézy, že výběr pochází z rozdělení definovaného distribuční funkcí, která je úplně specifikována, včetně svých parametrů.
, Q-Q grafy jsou citlivé na odchylky od teoretického rozdělení v oblasti konců. Je tedy patrné, že oba typy grafů se vzájemně doplňují. Kruhový graf – slouží k vizuálnímu ověření hypotézy, že výběr pochází z rozdělení definovaného distribuční funkcí, která je úplně specifikována, včetně svých parametrů.")
77
Ověření předpokladů o datech
Reprezentativní náhodný výběr je charakterizován třemi důležitými předpoklady, které je třeba před vlastní analýzou vždy ověřit. Jsou to nezávislost jednotlivých prvků, homogenita a případná normalita rozdělení prvků výběru. 1. předpoklad: prvky výběru jsou vzájemně nezávislé Pokud se podmínky pro měření dat mění s časem, projeví se tyto vznikem trendu mezi prvky výběru, uspořádanými v časovém sledu. K identifikaci časové závislosti prvků výběru nebo závislosti související s pořadím jednotlivých měření testuje se významnost autokorelačního koeficientu prvního řádu podle testovacích von Neumannova kritéria.

78
2. předpoklad: výběr je homogenní
Homogenní výběr znamená, že všechny jeho prvky pocházejí ze stejného rozdělení s konstantním rozptylem. K nehomogenitě naměřených dat dochází všude tam, kde se vyskytuje výrazná nestejnoměrnost naměřených vlastností vzorků nebo se náhle mění podmínky experimentů. Speciálním případem jsou odlehlá měření. Nehomogenita může být způsobena také nevhodnou specifikací souboru. Pokud lze daný výběr rozdělit podle nějakých logických kritérií do několika podskupin, je možno zpracovat statisticky každou podskupinu zvlášť a pak na základě testů shody středních hodnot v podskupinách rozhodnout, zda je toto dělení významné.

79
3. předpoklad: rozdělení výběru je normální
Normalita výběrových rozdělení patří k základním předpokladům, neboť je na ní založena celá klasická analýza dat, testování vybočujících měření a testy nezávislosti prvků výběru. Existují dva základní tyty testů normality: Je-li typ odchylek od normality při testování předem specifikován, používají se tzv. směrové testy. Není-li předem známo, jaké odchylky od normality se v datech vyskytují, používají se tzv. omnibus-testy. Testy jsou obecně vždy méně citlivé na odchylky od normality než diagnostické grafy a navíc odchylka od normality může být mnohdy způsobena vybočujícími hodnotami.

80
Když není normalita rozdělení prokázána, je nutné hlouběji analyzovat data.
Řada silných testů normality je odvozena z rankitových grafů. Příkladem je často užívaný test Shapirův – Wilkův. Proto je pro grafické vyšetření normality výhodné použít rankitových grafů.

81
Postup průzkumové analýzy
Průběh vlastní průzkumové, exploratorní analýzy dat (EDA) je možné libovolně kombinovat podle dosavadních informací o vyhodnocovaných datech. Zaměříme se na analýzu rutinních dat, o kterých jsou známy vlastnosti (např. rozdělení), a neznámých dat, o kterých nejsou známy dosud žádné předběžné informace a hrozí nebezpečí nesplnění předpokladů o datech. Postup analýzy rutinních dat Při zpracování rutinních výsledků měření předpokládáme, že známe rozdělení souboru dat. Rozdělení je obvykle normální a data splňují předpoklady nezávislosti a homogenity.
 je možné libovolně kombinovat podle dosavadních informací o vyhodnocovaných datech. Zaměříme se na analýzu rutinních dat, o kterých jsou známy vlastnosti (např. rozdělení), a neznámých dat, o kterých nejsou známy dosud žádné předběžné informace a hrozí nebezpečí nesplnění předpokladů o datech. Postup analýzy rutinních dat. Při zpracování rutinních výsledků měření předpokládáme, že známe rozdělení souboru dat. Rozdělení je obvykle normální a data splňují předpoklady nezávislosti a homogenity.")
82
Následuje pouze testování minimálního rozsahu dat (měření), testování nezávislosti prvků výběru – autokorelace, testování homogenity výběru, testování normality rozdělení výběru. Z grafických metod se k předběžné analýze rutinních dat nejčastěji užívá rankitových grafů a grafů rozptýlení s kvantily. Nejsou-li o rozdělení dat dostupné žádné informace, nebo očekává-li se výrazně nenormální rozdělení, je vhodné provést průzkumovou analýzu dat EDA s využitím řady grafických metod, určení výběrového rozdělení a jeho konstrukci.

83
Pokud nebylo nalezeno vhodné aproximující rozdělení, provádí se mocninná transformace, která by měla zlepšit rozdělení dat. Kombinace metod závisí na konkrétních datech a konkrétních požadavcích analýzy. Postup při nesplnění požadavků o datech Nesplnění požadavku nezávislosti prvků Pokud prvky měření nejsou nezávislé, vzrůstá nebezpečí, že odhady budou systematicky vychýleny a nadhodnoceny pro pozitivní hodnotu autokorelačního koeficientu. Nezbývá, než hlouběji analyzovat logické příčiny a snažit se o jejich odstranění, zkontrolovat celý měřicí řetězec a provést nová měření.

84
Nesplnění předpokladu normality výběru
Rozdělení dat je buď jiné než normální nebo jsou v datech vybočující měření. V případě nenormálního rozdělení dat může jít o odchylky pouze v délce konců, nebo se jedná o zešikmená rozdělení. V případě symetrických rozdělení lišících se od normálního délkou konců lze použít pro odhad parametrů polohy a variability jednoduché robustní techniky nebo vyzkoušet mocninnou transformaci. U zešikmených rozdělení je vždy výhodné začít hledáním mocninné transformace. Pokud byla mocninná transformace úspěšná, provádí se další analýza v této transformaci a nakonec se vyčíslí zpětná transformace do původních proměnných.

85
Nebyla-li mocninná transformace úspěšná, je možné pomocí technik průzkumové analýzy dat nalézt vhodné teoretické aproximující rozdělení a realizovat další postup na základě obecných vztahů pro rozptyl, příp. střední hodnotu. Přítomnost vybočujících hodnot Na základě logické analýzy je třeba nejdříve zvážit, zda nejde o zešikmené rozdělení. Body, které se jeví jako vybočující pro symetrické (speciálně normální) rozdělení, mohou naopak být přijatelné pro zešikmená rozdělení. Pokud jde o vybočující pozorování, lze použít dvou alternativ.
 rozdělení, mohou naopak být přijatelné pro zešikmená rozdělení. Pokud jde o vybočující pozorování, lze použít dvou alternativ.")
86
První spočívá v jejich vyloučení z další analýzy, což však není vždy zcela nejvhodnější. Pokud jsou vybočující měření výsledkem řídce se vyskytujících jevů, může tím dojít úplně ke ztrátě informace. Proto lze tyto hodnoty vyloučit jedině při doplnění o nová experimentální data. Druhá alternativa spočívá v použití robustních metod. Tento postup však nemusí být vždy korektní. Robustnost spočívá v přiblížení se k přijatému modelu měření bez ohledu na jeho platnost. Pokud se analýzy vybočujících měření účastní experimentátor, měl by rozhodnout, která měření jsou evidentní hrubé chyby (jako je selhání přístroje, špatný zápis dat) a která jsou jen podezřelá. Evidentní hrubé chyby je vhodné z další analýzy vyloučit, ale podezřelá měření je lépe ponechat. Robustními metodami se jejich vliv na odhady parametrů výrazně oslabí.
 a která jsou jen podezřelá. Evidentní hrubé chyby je vhodné z další analýzy vyloučit, ale podezřelá měření je lépe ponechat. Robustními metodami se jejich vliv na odhady parametrů výrazně oslabí.")
87
Nedostatečný rozsah výběru
Nejjednodušší je v tomto případě provést dodatečná měření. Platí, že čím jsou data méně rozptýlená, tím menší počet jich stačí k zajištění dostatečné přesnosti odhadu. Pokud nelze provést dodatečné experimenty, je možné použít techniky vhodné pro malé výběry. Tento postup je vhodný zejména pro analýzu rutinních měření, kde jsou o chování dat předběžné informace. Když se analyzují výsledky nových měření nebo neznámé výběry, je vždy třeba začít průzkumovou analýzu dat a stanovit statistické zvláštnosti výběru.

Podobné prezentace
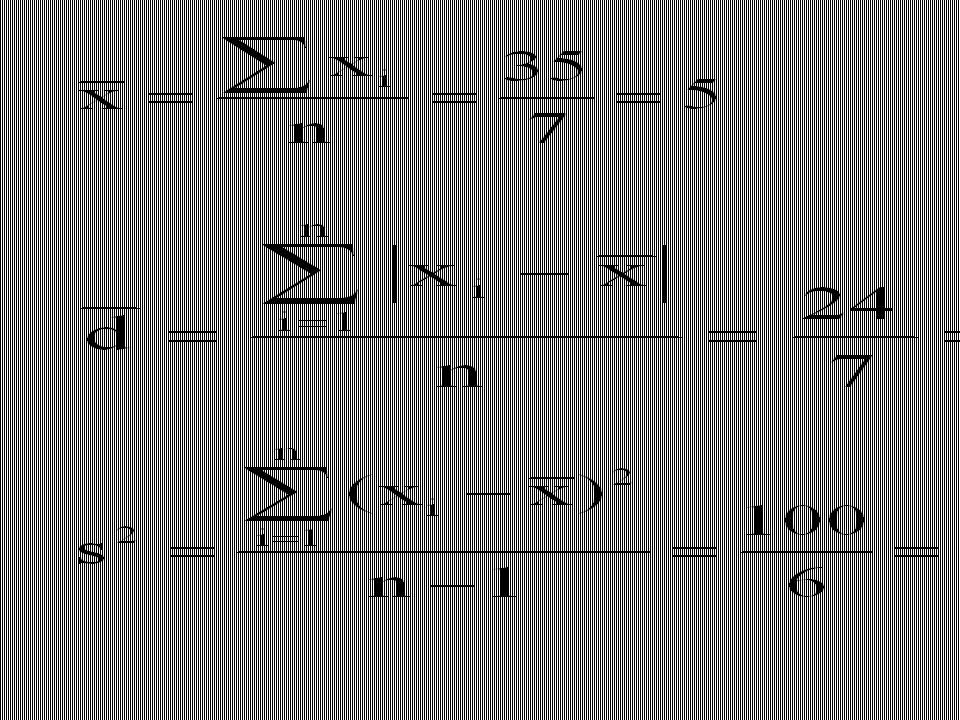
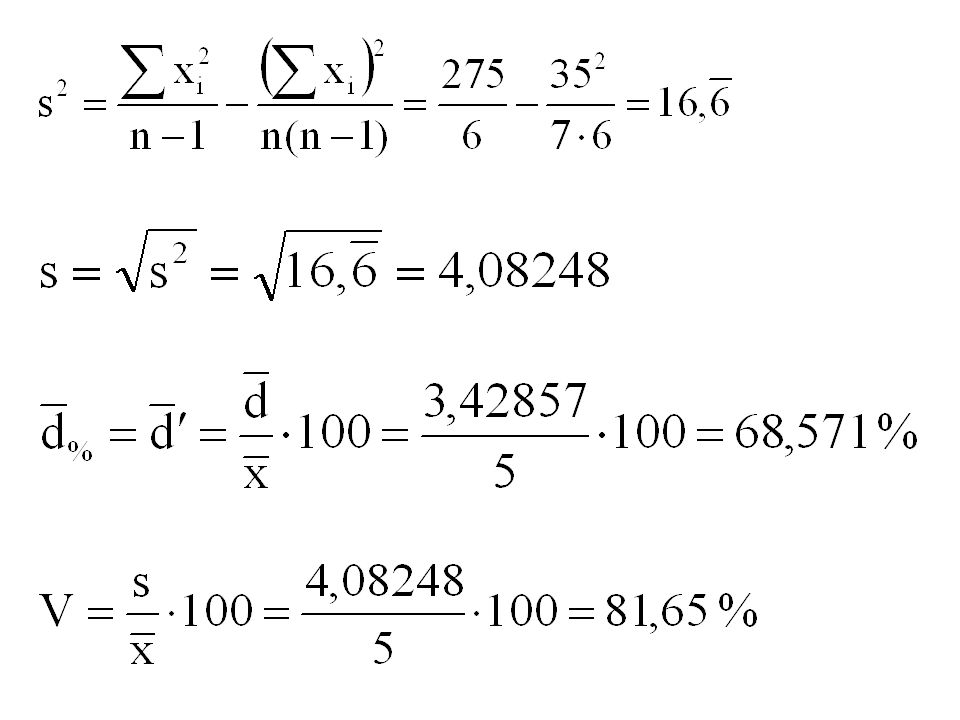
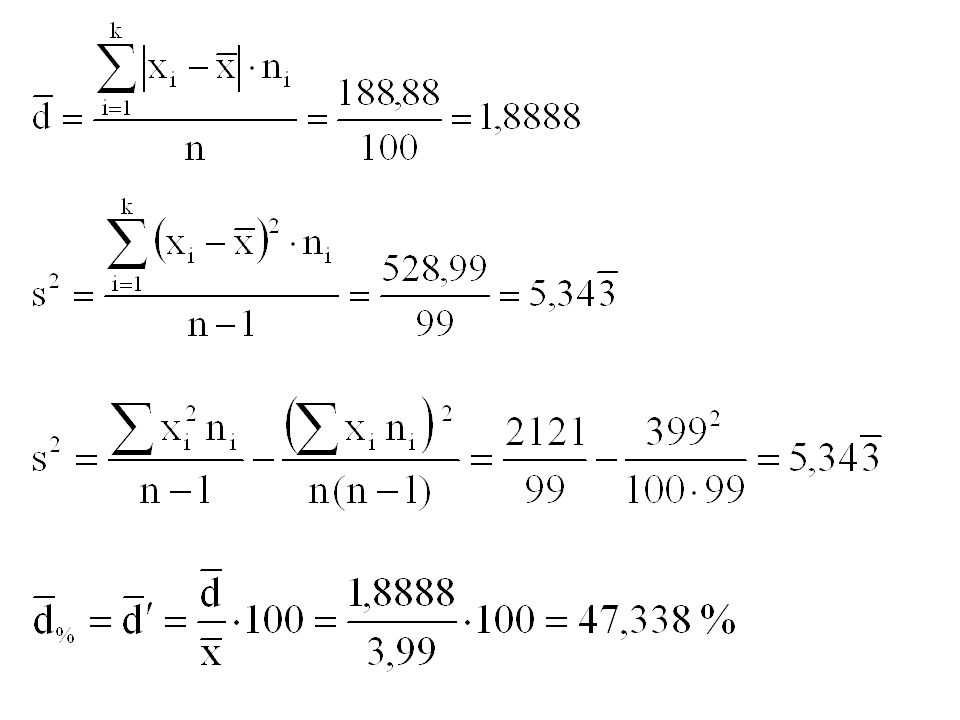
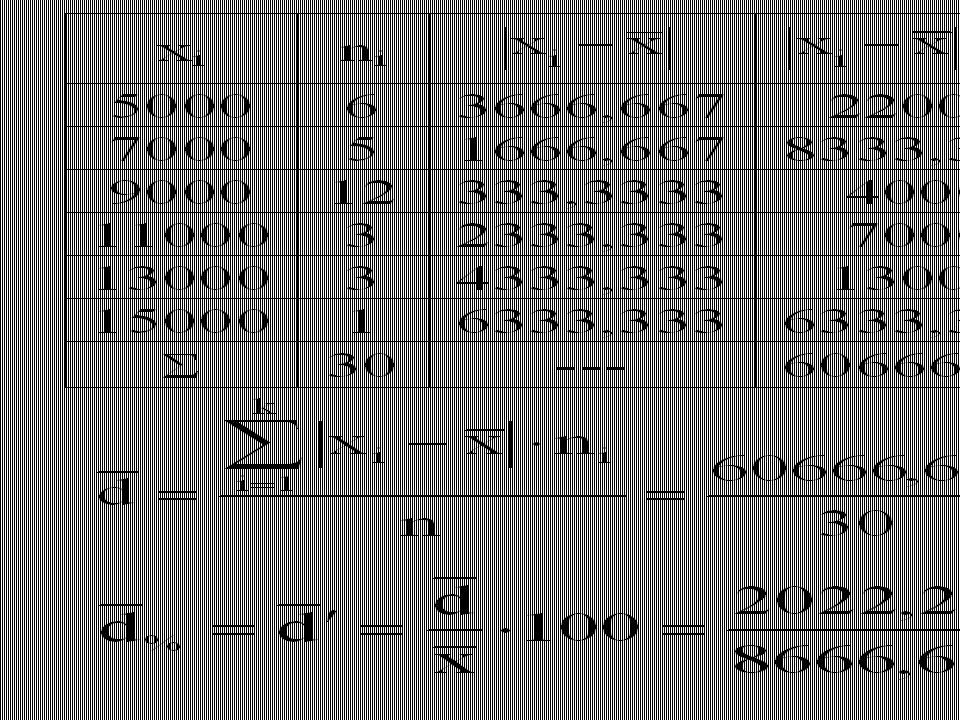
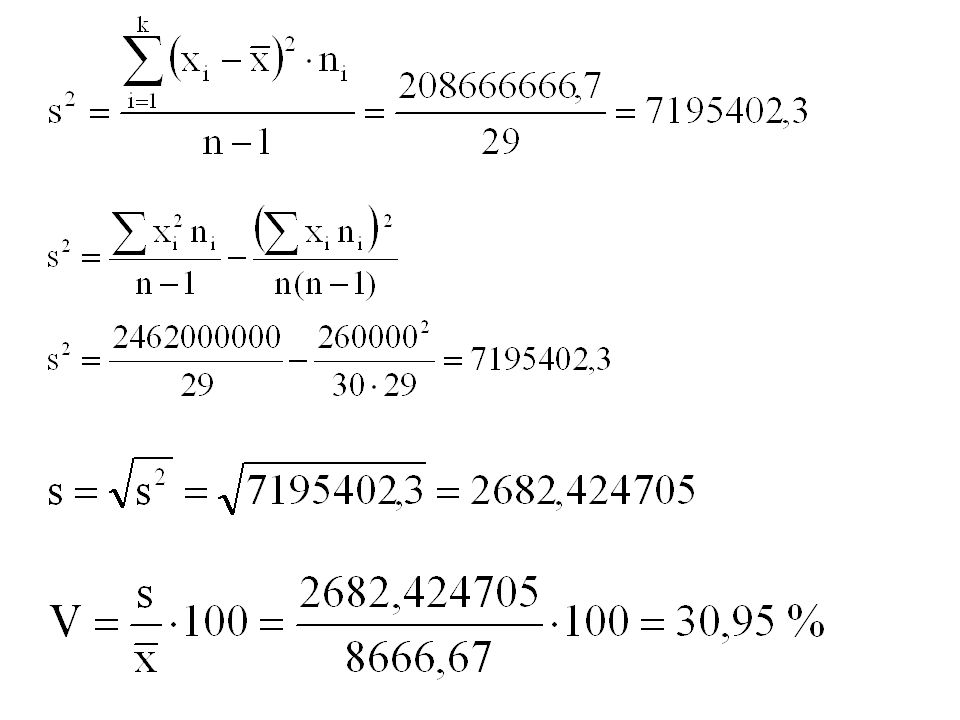




















>")