Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Chybějící hodnoty (item nonresponse)
Základy analýzy kvantitativních dat a SPSS Ivan Petrúšek

2
Obsah přednášky Definice chybějících hodnot
Mechanizmy chybějících hodnot Missing Completely At Random Missing At Random Not Missing At Random Tradiční řešení problému chybějících hodnot Postupy založené na vynechávání případů z analýzy Postupy založené na nahrazování chybějících hodnot

3
Definice chybějících hodnot
Chybějící hodnoty (missing values) = „prázdná“ místa v datové matici (tzn. u některých proměnných a některých případů nejsou hodnoty pozorovány) Předpoklad: chybějící hodnoty „zakrývají“ skutečné hodnoty, které by jinak byly smysluplnou součástí analýzy
 = „prázdná místa v datové matici (tzn. u některých proměnných a některých případů nejsou hodnoty pozorovány) Předpoklad: chybějící hodnoty „zakrývají skutečné hodnoty, které by jinak byly smysluplnou součástí analýzy.")
4
Chybějící hodnoty - příklady
Příjem osoby – v mnoha výzkumech odmítají respondenti uvádět výšku svého příjmu Česká volební studie 2010 – až 11,5% respondentů, kteří uvedli, že se zúčastnili parlamentních voleb, odmítlo odpovědět na otázku volby strany Někdy odpovědi typu „nevím“, „žádná preference“ nepředstavují chybějící hodnoty, ale naopak jsou dalšími platnými odpověďmi

5
Proč představují chybějící hodnoty problém?
Standardní statistické metody byly vyvinuty pro kompletní data (tzn. data bez chybějících hodnot) Ignorování chybějících hodnot a procesů jejich vzniku může vést vychýleným výsledkům analýz Neexistuje univerzální hranice, která určuje, kdy začíná být podíl chybějících hodnot v datech problematický → někdy se uvádí 5 %
 Ignorování chybějících hodnot a procesů jejich vzniku může vést vychýleným výsledkům analýz. Neexistuje univerzální hranice, která určuje, kdy začíná být podíl chybějících hodnot v datech problematický. → někdy se uvádí 5 %")
6
Chybějící hodnoty v SPSS
System missing values SPSS s nimi automaticky pracuje jako s chybějícími hodnotami Jedná se o tečky v datové matici (Data View) User-defined missing values Uživatel SPSS je musí jako chybějící hodnoty sám nadefinovat (příkaz mis val) – jinak s nimi SPSS pracuje jako s platnými hodnotami Někdy uživatelé definují jako chybějící také hodnoty, které z hlediska teorie chybějícími nejsou
 User-defined missing values. Uživatel SPSS je musí jako chybějící hodnoty sám nadefinovat (příkaz mis val) – jinak s nimi SPSS pracuje jako s platnými hodnotami. Někdy uživatelé definují jako chybějící také hodnoty, které z hlediska teorie chybějícími nejsou.")
7
Mechanizmy chybějících hodnot
Zjednodušeně řečeno mechanizmy popisují vztahy mezi pozorovanými a chybějícími hodnotami v datech Podle přítomného mechanizmu chybějících hodnot dokážeme odhadnout, jestli bude zvolená technika práce s chybějícími hodnotami vhodná, resp. problematická

8
Missing Completely At Random (MCAR)
Výskyt chybějících hodnot v datech nezávisí na pozorovaných hodnotách, a zároveň nezávisí ani na samotných hodnotách, které chybějí pravděpodobnost výskytu chybějících hodnot u proměnné Y1 nezávisí na pozorovaných hodnotách dalších proměnných (Y2, Y3, …, Yk) a nezávisí ani na hodnotách samotné proměnné Y1 Když data chybějí podle MCAR, tak pozorované hodnoty představují náhodný výběr z hypoteticky kompletního datového souboru
 a nezávisí ani na hodnotách samotné proměnné Y1. Když data chybějí podle MCAR, tak pozorované hodnoty představují náhodný výběr z hypoteticky kompletního datového souboru.")
9
Missing Completely At Random (MCAR)
Pro ověřování mechanizmu MCAR existuje několik statistických testů SPSS obsahuje test MCAR podle Littla (Roderick Little) (H0: Hodnoty chybějí podle MCAR) MCAR představuje velmi přísný předpoklad o chybějících hodnotách → v sociologické praxi není obecně velmi pravděpodobné, aby hodnoty chyběly podle mechanizmu MCAR
 (H0: Hodnoty chybějí podle MCAR) MCAR představuje velmi přísný předpoklad o chybějících hodnotách. → v sociologické praxi není obecně velmi pravděpodobné, aby hodnoty chyběly podle mechanizmu MCAR.")
10
Missing At Random (MAR)
Pravděpodobnost výskytu chybějících hodnot u proměnné Y1 závisí na platných hodnotách dalších proměnných, ale nezávisí na hodnotách samotné proměnné Y1 Název mechanizmu je zavádějící → hodnoty v datech totiž chybí „systematicky“ Problém: neexistuje způsob jak otestovat, že hodnoty chybějí podle mechanizmu MAR

11
Not Missing At Random (NMAR)
Pravděpodobnost výskytu chybějících hodnot proměnné Y1 závisí na hodnotách samotné proměnné Y1 Stejný problém jako u MAR: neexistuje způsob, jak ověřit, že hodnoty chybějí podle NMAR → jelikož neznáme chybějící hodnoty proměnné Y1, tak je nedokážeme porovnat s platnými hodnotami proměnné Y1

12
Tradiční řešení problému chybějících hodnot
Postupy založené na vynechávaní případů z analýzy Listwise deletion Pairwise deletion Postupy založené na nahrazování chybějících hodnot arithmetic mean imputation linear regression imputation stochastic regression imputation

13
Listwise deletion Výhody:
Každý případ, u kterého chybí alespoň jedna hodnota (u některé z proměnných vstupujících do analýzy) je z analýzy vyřazen Výhody: U mechanizmu MCAR se jedná o optimální řešení Při regresi produkuje nevychýlené odhady regresních koeficientů, když nezávislé proměnné chybí podle mechanizmu MAR Nevýhody: Často se stává, že výrazně zredukuje počet případů, na kterých je daná analýza provedena → redukce síly testu U MAR a NMAR produkuje vychýlené odhady parametrů
 je z analýzy vyřazen. Výhody: U mechanizmu MCAR se jedná o optimální řešení. Při regresi produkuje nevychýlené odhady regresních koeficientů, když nezávislé proměnné chybí podle mechanizmu MAR. Nevýhody: Často se stává, že výrazně zredukuje počet případů, na kterých je daná analýza provedena → redukce síly testu. U MAR a NMAR produkuje vychýlené odhady parametrů.")
14
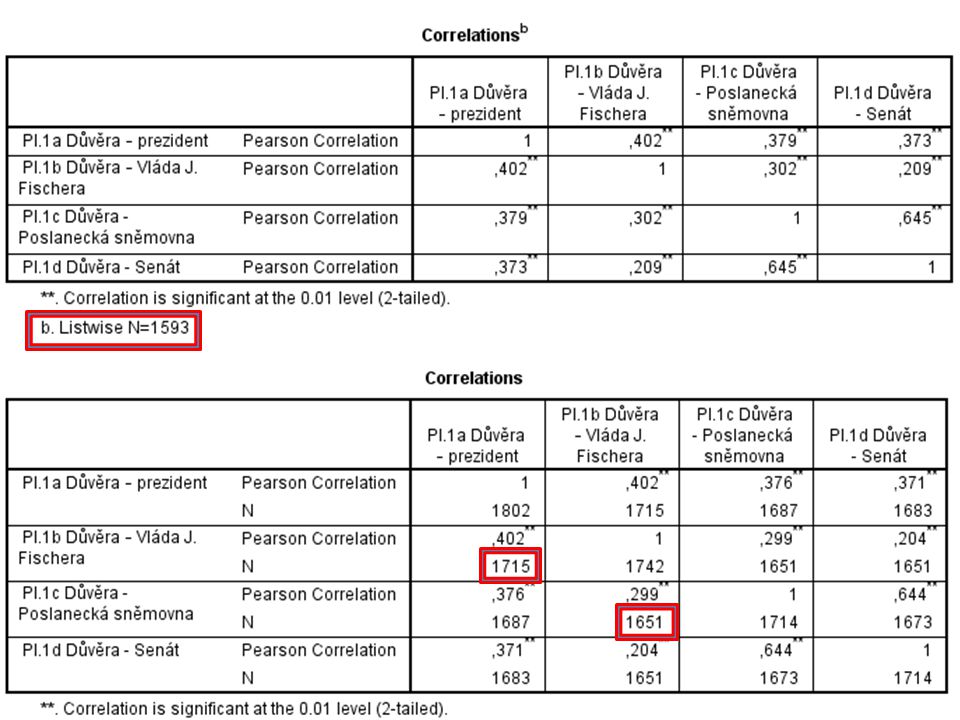
Pairwise deletion Případy jsou z analýzy vyřazené vždy v rámci párů proměnných (cílem je maximalizovat počet případů, na kterých je analýza provedena) → každá z buněk korelační matice je spočtena na jiném počtu případů Výhody: U mech. MCAR se jedná o relativně vhodné řešení Nevýhody U mechanizmů MAR a MCAR produkuje vychýlené odhady parametrů Produkuje také vychýlené odhady standardních chyb a testovacích statistik
 → každá z buněk korelační matice je spočtena na jiném počtu případů. Výhody: U mech. MCAR se jedná o relativně vhodné řešení. Nevýhody. U mechanizmů MAR a MCAR produkuje vychýlené odhady parametrů. Produkuje také vychýlené odhady standardních chyb a testovacích statistik.")
16
Arithmetic mean imputation
Každá chybějící hodnota proměnné je nahrazena hodnotou aritmetického průměru, který je spočten z platných hodnot dané proměnné Jediná malá výhoda: Máme k dispozici „kompletní“ data Nevýhody: Redukce variability hodnot dané proměnné (sníží se rozptyl i směrodatná odchylka) Vychýlené odhady parametrů u každého mechanizmu → jednoznačně nejhorší dostupná technika
 Vychýlené odhady parametrů u každého mechanizmu. → jednoznačně nejhorší dostupná technika.")
17
Regression imputation
Každá chybějící hodnota kardinální proměnné Y je nahrazena odhadem uskutečněným podle regresní rovnice (podle hodnot proměnné X) Výhody: Máme k dispozici „kompletní“ data Produkuje nevychýlené odhady průměru proměnné Y Nevýhody: Redukce variability hodnot proměnné Y Může zvýšit úroveň korelace mezi proměnnou s nahrazenými hodnotami Y a proměnnou X Regression imputation effectively suffers from the exact opposite problem as mean imputation because it imputes the data with perfectly correlated scores.
 Výhody: Máme k dispozici „kompletní data. Produkuje nevychýlené odhady průměru proměnné Y. Nevýhody: Redukce variability hodnot proměnné Y. Může zvýšit úroveň korelace mezi proměnnou s nahrazenými hodnotami Y a proměnnou X. Regression imputation effectively suffers from the exact opposite problem as mean imputation because it imputes the data with perfectly correlated scores.")
18
Stochastic regression imputation
Kromě výše popsaného postupu je nahrazovaná chybějící hodnota upravená náhodným reziduem – obnovuje se tak ztracená variabilita dat Výhoda: U mechanizmu MAR vede k nevychýleným odhadům parametrů Nevýhoda: Velkosti směrodatných chyb bývají podhodnocené → zvýšená pravděpodobnost chyby I. druhu

19
Metody práce s chybějícími hodnotami v SPSS
Modul BASE U jednotlivých analytických technik bývají dostupné v nabídce OPTIONS Většinou se jedná jen o listwise/pairwise vynechávání a nahrazování za aritmetický průměr Modul MISSING VALUES Speciální modul pro práci s chybějícími hodnotami Obsahuje test MCAR podle Littla a několik dalších diagnostických nástrojů Možnost nahrazovat chybějící hodnoty regresí

20
Závěr Chybějící hodnoty představují v společensko-vědných datech téměř všudypřítomný jev Při výběru techniky řešení problému je třeba mít představu o mechanizmu chybějících hodnot (pro danou analýzu a proměnné) Tradičně používané techniky problém většinou neřeší (kromě listwise vynechávání u MCAR a stochastické regrese u MAR) V současnosti už existují i postupy, které dosahují „kvalitních“ výsledků u mechanizmu MAR
 Tradičně používané techniky problém většinou neřeší (kromě listwise vynechávání u MCAR a stochastické regrese u MAR) V současnosti už existují i postupy, které dosahují „kvalitních výsledků u mechanizmu MAR.")
21
„The only really good solution to the missing data problem is not to have any. … Statistical adjustment can never make up for sloppy research.“ – Paul D. Allison Děkuji za pozornost!

22
Použitá literatura Allison, P. D Missing data. Thousand Oaks: Sage. Baraldi, A. N. Enders, C. K „An introduction to modern missing data analyses“. Journal of School Psychology 48 (1): 5-37. Enders, C. K Applied Missing Data Analysis. New York: The Guilford Press. Little, R. J. A., Rubin, D. B. (2002). Statistical Analysis with Missing Data (2nd ed.). Hoboken, N.J: Wiley.
: Enders, C. K Applied Missing Data Analysis. New York: The Guilford Press. Little, R. J. A., Rubin, D. B. (2002). Statistical Analysis with Missing Data (2nd ed.). Hoboken, N.J: Wiley.")
Podobné prezentace





>")







>")





