Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Mnohorozměrná statistická analýza dat
E=m.c = ? Hmax= log2s

2
Co jsou mnohorozměrná data
Mám fytocenologický snímek, ve kterém je mnoho proměnných (druhů) případně proměnných prostředí (velikost plochy, sklon, expozice, ph půdy, vlhkost půdy, způsob využívání, hnojení) Mám k dispozici soubor dat, např. druhy vážek z více lokalit. Charakteristiky každého druhu (početnost, dominance, diverzita) je ovlivněná mnohými faktory (proměnnými) prostředí (půdní typ, nadmořská výška, expozice, typ vegetace, sukcese, klimatické faktory, antropická činnost). U vodních živočichů to jsou fyzikálně-chemické vlastnosti vody, vegetace atd. Vysvětlované proměnné - druhová data (rostliny, živočichové) 2. Vysvětlující proměnné- vlastnosti prostředí
 případně proměnných prostředí (velikost plochy, sklon, expozice, ph půdy, vlhkost půdy, způsob využívání, hnojení) Mám k dispozici soubor dat, např. druhy vážek z více lokalit. Charakteristiky každého druhu (početnost, dominance, diverzita) je ovlivněná mnohými faktory (proměnnými) prostředí (půdní typ, nadmořská výška, expozice, typ vegetace, sukcese, klimatické faktory, antropická činnost). U vodních živočichů to jsou fyzikálně-chemické vlastnosti vody, vegetace atd. Vysvětlované proměnné - druhová data (rostliny, živočichové) 2. Vysvětlující proměnné- vlastnosti prostředí.")
3
Typy dat 1. Nominální (kvalitativní) - tento typ dat je bez numerických hodnot a nelze ho zařadit nai do tříd. Data presence/absence se kódují jako + - či 1/0. Hodnoty nemají vztah navzájem. Na tyto data nelze použít aritmetiku (sčítat, násobit atd.) 2. Ordinální (pořadové) - takováto data mohou být umístěna v řadu podél kontinua. Typickým příkladem jsou jednodušší škály abundance. S těmito daty mohou být prováděny 4 základní aritmetické operace. Je však třeba dbát na to, že např. rozdíl mezi "1 a 2" nemusí být stejný jako mezi "3 a 4". Proto i počítání průměru a dalších statistických hodnot může být nebezpečné a zavádějící 3. Intervalové (kvantitativní) - mají pevnou jednotku měření a tak mohou být rozdíly mezi hodnotami srovnávány (např. teplota: rozdíl 3 stupňů znamená tentýž rozdíl kdekoliv na celé škále). Specifické je však postavení nuly - není pevné. Nulová hodnota stupnice je dána definicí a její pozice na číselné ose je víceméně libovolná. Poměr dvou hodnot závisí na užitých jednotkách (5oC = 41oF; 10oC = 50oF) 4. Poměrné (kvantitativní) - obdobné (3), ale s pevně fixovanou nulou. Tak je možné definovat poměr. Poměr je nezávislý na jednotce, ve které je velikost znaku vyjádřena. Tedy - jestliže jeden kvadrát má plochu 2 m2 a druhý 4 m2, pak je druhý 2x větší než první.
 - tento typ dat je bez numerických hodnot a nelze ho zařadit nai do tříd. Data presence/absence se kódují jako + - či 1/0. Hodnoty nemají vztah navzájem. Na tyto data nelze použít aritmetiku (sčítat, násobit atd.) 2. Ordinální (pořadové) - takováto data mohou být umístěna v řadu podél kontinua. Typickým příkladem jsou jednodušší škály abundance. S těmito daty mohou být prováděny 4 základní aritmetické operace. Je však třeba dbát na to, že např. rozdíl mezi 1 a 2 nemusí být stejný jako mezi 3 a 4 . Proto i počítání průměru a dalších statistických hodnot může být nebezpečné a zavádějící 3. Intervalové (kvantitativní) - mají pevnou jednotku měření a tak mohou být rozdíly mezi hodnotami srovnávány (např. teplota: rozdíl 3 stupňů znamená tentýž rozdíl kdekoliv na celé škále). Specifické je však postavení nuly - není pevné. Nulová hodnota stupnice je dána definicí a její pozice na číselné ose je víceméně libovolná. Poměr dvou hodnot závisí na užitých jednotkách (5oC = 41oF; 10oC = 50oF) 4. Poměrné (kvantitativní) - obdobné (3), ale s pevně fixovanou nulou. Tak je možné definovat poměr. Poměr je nezávislý na jednotce, ve které je velikost znaku vyjádřena. Tedy - jestliže jeden kvadrát má plochu 2 m2 a druhý 4 m2, pak je druhý 2x větší než první.")
4
Jaké problémy řešíme s použitím mnohorozměrných dat
Snažíme se : • najít strukturu v datech (zjistit, které druhy se vyskytují pospolu, nebo které snímky/zápisy si jsou podobné) • najít korelaci druhů s charakteristikami prostředí • najít časovou nebo prostorovou variabilitu vegetace • provést statistický test vlivu pokusného faktoru.
 • najít korelaci druhů s charakteristikami prostředí. • najít časovou nebo prostorovou variabilitu vegetace. • provést statistický test vlivu pokusného faktoru.")
5
(environmentální gradienty = EF)
Gradienty prostředí (environmentální gradienty = EF) 1. Přímé – bezprostředně ovlivňují růst rostlin . světlo . teplota . voda . živiny 2. Nepřímé (zástupné) – snadno se měří a korelují s přímými faktory . nadmořská výška . geologické podloží . typ půdy . sklon a orientace svahu aj.
 1. Přímé – bezprostředně ovlivňují růst rostlin. . světlo. . teplota. . voda. . živiny. 2. Nepřímé (zástupné) – snadno se měří a korelují s. přímými faktory. . nadmořská výška. . geologické podloží. . typ půdy. . sklon a orientace svahu aj.")
6
Přímá a nepřímá gradientová analýza
Přímá gradientová analýza analyzuje změny druhového složení podle známého a předem stanoveného jednoho nebo několika gradientů prostředí (podle nadm. výšky, vlastností půdy, intenzity hnojení atd.) 2. Nepřímá gradientová analýza analyzuje variabilitu druhového složení společenstva nezávisle na prostředí směr největší variability druhového složení (cenoklina – komplexní gradient prostředí)
 2. Nepřímá gradientová analýza analyzuje variabilitu druhového složení společenstva nezávisle na prostředí směr největší variability druhového složení (cenoklina – komplexní gradient prostředí)")
7
Kódování kvantitativních a kvalitativních proměnných
Kategoriální vícestavové (dummy) proměnné Počet parametrů prostředí? Kolik parametrů? Parametry prostředí silně korelované (Inflation factor)
 proměnné. Počet parametrů prostředí Kolik parametrů Parametry prostředí silně korelované (Inflation factor)")
8
ORDINAČNÍ METODY Druh (objekty) jsou charakterizované p znaky je možné si představit jako body v p rozměrném prostoru, kde každý z rozměrů představuje hodnoty jednoho znaku. V případě dvou nebo tří znaků můžeme na dvou- případně troj- rozměrném diagramu bez problémů kontrolovat vztahy mezi objekty. V případě většího počtu znaků (rozměrů, dimenzí) možnost takovéto kontroly chybí. K tomuto účelu je zapotřebí redukovat celkový počet pozorovaných znaků na dva až tři nové znaky (rozměry) a to tak, aby došlo k co nejmenší ztrátě informace, která je v původních znacích obsažena. Ordinační metody slouží právě tomuto účelu. Jejich úspěšnost závisí na struktuře obsažené v datech. Dobře strukturovaná data umožňují koncentraci podstatné části informace do několika prvních ordinačních os. V praxi se používají nejčastěji analýza hlavních komponentů (principal component(s) analysis - PCA), detrendovaná korespondenční analýza (DCA), redundační analýza (RDA) a kanonická korespondeční analýza CCA).
 jsou charakterizované p znaky je možné si představit jako body v p rozměrném prostoru, kde každý z rozměrů představuje hodnoty jednoho znaku. V případě dvou nebo tří znaků můžeme na dvou- případně troj- rozměrném diagramu bez problémů kontrolovat vztahy mezi objekty. V případě většího počtu znaků (rozměrů, dimenzí) možnost takovéto kontroly chybí. K tomuto účelu je zapotřebí redukovat celkový počet pozorovaných znaků na dva až tři nové znaky (rozměry) a to tak, aby došlo k co nejmenší ztrátě informace, která je v původních znacích obsažena. Ordinační metody slouží právě tomuto účelu. Jejich úspěšnost závisí na struktuře obsažené v datech. Dobře strukturovaná data umožňují koncentraci podstatné části informace do několika prvních ordinačních os. V praxi se používají nejčastěji analýza hlavních komponentů (principal component(s) analysis - PCA), detrendovaná korespondenční analýza (DCA), redundační analýza (RDA) a kanonická korespondeční analýza CCA).")
9
Ordinační metody zjednodušují mnohorozměrný prostor na 1–4 rozměry (ordinační osy), princip není v redukci, ale v rotaci pohledu 1. osa zachycuje směr největší variability hyperprostoru 2. osa zachycuje další směr největší variability nezachycený 1. osou => nekoreluje s 1. osou další osy zachycují další směry největší variability, nezachycené předchozími osami v sestupném pořadí variabilita zachycená jednotlivými osami je vyjádřena tzv. charakteristickými čísly (eigenvalues)
")
10
Program CANOCO (jiné SPSS, SYN-TAX, NCSS)
")
11
CANOCO Data jsou v CanoImp transformované do Cornellovského formátu

12
CANOCO Modul CanoWin

13
CANOCO DCA Trendů zbavená korespondenční analýza DCA se
používá se jako 1. krok ordinační analýzy, ke zjištění délky gradientu (SD= směrodatná odchylka) Podle hodnoty SD volíme ordinační proceduru buď lineární metody ordinační analýzy PCA, RDA unimodální metody (DCA, CCA) Axes Total inertia Eigenvalues : Lengths of gradient : Cumulative percentage variance of species data :
 Podle hodnoty SD volíme ordinační proceduru buď. lineární metody ordinační analýzy PCA, RDA. unimodální metody (DCA, CCA) Axes Total inertia. Eigenvalues : Lengths of gradient : Cumulative percentage. variance of species data :")
14
CANOCO Modul CanoDraw 4.5

15
CANOCO grafy DCA Scatter plot

16
CANOCO grafy PCA

17
CANOCO grafy RDA Biplot 2 vrstvy druhy prostředí

18
CANOCO statistika 6 aluviální louky Environmental variable tested P-value (variable 6; F-ratio= 2.71; number of permutations= 499) 19 permutací – test pro 5% hladinu významnosti (P<0.05) 99 permutací – test pro 1% hladinu významnosti (P<0.01)
 19 permutací – test pro 5% hladinu významnosti (P<0.05) 99 permutací – test pro 1% hladinu významnosti (P<0.01)")
19
Koeficinety vyjadřující vztahy mezi objekty nebo znaky
Klasifikační metody Koeficinety vyjadřující vztahy mezi objekty nebo znaky Koeficinety vzdálenosti pro kvantitativní data (metric distances) Koeficinety vzdálenosti pro binární znaky (binary simmilarity coefficients) Koeficinety vzdálenosti pro smíšená data (coefficients for mixed data) Korelační koeficietnty (corelation coefficients)
 Koeficinety vzdálenosti pro binární znaky (binary simmilarity coefficients) Koeficinety vzdálenosti pro smíšená data (coefficients for mixed data) Korelační koeficietnty (corelation coefficients)")
20
Binární koeficienty podobnosti
Jaccardův index J = a/b+c-a (%) a – společný výskyt druhů b – počet druhů lokality „b“ c – počet druhů lokality „c“ Sørensenův index S = 2a/b+c (%) a – společný výskyt druhů b – druhů cenózy „A“ c – druhů cenózy „B“
 a – společný výskyt druhů. b – počet druhů lokality „b c – počet druhů lokality „c Sørensenův index. S = 2a/b+c (%) a – společný výskyt druhů. b – druhů cenózy „A c – druhů cenózy „B")
21
Koeficinety vzdálenosti pro kvantitativní data (metric distances)
Studované objekty jsou body v porostoru, mají své souřadnice, Dimenze prostoru je daná počtem znaků použitých k jejich popisu Pokud koeficienty splňují následovné, považují se za metriky Symetrie- vzdálenost objektů x,y d(x,y)= d(y,x)≥0 2. Vzdálenost totožných objektů d(x,y)= 0 když x=y 3. Vzdálenost objektů, které nejsou totožné d(x,y)> 0 když x≠y 4. Vzdálenost dvou d(x,y) je menčí (nebo rovna) součtu jejich vzdáleností od objektu třetího d(x,z) + d(y,z) d(x,y)≤ d(x,) + d(y,z)
= d(y,x)≥0. 2. Vzdálenost totožných objektů. d(x,y)= 0 když x=y. 3. Vzdálenost objektů, které nejsou totožné. d(x,y)> 0 když x≠y. 4. Vzdálenost dvou d(x,y) je menčí (nebo rovna) součtu jejich vzdáleností od objektu třetího d(x,z) + d(y,z) d(x,y)≤ d(x,) + d(y,z)")
22
Metrické koeficienty Euklidovská vzdálenost mezi objekty A [x1, y1] a B [x2, y ] představuje vzdálenost označenou jako „c“ (přepona trojúhelníku), Manhattanská vzdálenost představuje součet vzdáleností označených jako „a“ a „b“ (součet odvěsen trojúhelníku).
![Metrické koeficienty Euklidovská vzdálenost mezi objekty A [x1, y1] a B [x2, y ] představuje vzdálenost označenou jako „c (přepona trojúhelníku),](http://slideplayer.cz/slide/1906130/7/images/22/Metrick%C3%A9+koeficienty+Euklidovsk%C3%A1+vzd%C3%A1lenost+mezi+objekty+A+%5Bx1%2C+y1%5D+a+B+%5Bx2%2C+y+%5D+p%C5%99edstavuje+vzd%C3%A1lenost+ozna%C4%8Denou+jako+%E2%80%9Ec+%28p%C5%99epona+troj%C3%BAheln%C3%ADku%29%2C.jpg "Manhattanská vzdálenost představuje součet vzdáleností označených jako „a a „b (součet odvěsen trojúhelníku).")
23
Euklidovská vzdálenost mezi objekty x a y
nejznámější metrika- ordinální (kvantitativní data) Jestliže se druhy X a Y vyskytují ve snímcích 1 a 2, podobnost nebo-li "distance" mezi těmito dvěma snímky v geometrickém prostoru druhů x,y je definována pro více než 2 druhy pak kde Dij = Euklideova vzdálenost mezi snímky i a j; m = počet druhů; xik = abundance druhu k ve snímku i xjk = abundance druhu k ve snímku j
 Jestliže se druhy X a Y vyskytují ve snímcích 1 a 2, podobnost nebo-li distance mezi těmito dvěma snímky v geometrickém prostoru druhů x,y je definována. pro více než 2 druhy pak. kde Dij = Euklideova vzdálenost mezi snímky i a j; m = počet druhů; xik = abundance druhu k ve snímku i. xjk = abundance druhu k ve snímku j.")
24
Shluková - klastrová analýza
Cílem shlukové analýzy (cluster analysis) je nalézt v celém souboru dat takové skupiny objektů, které jsou si navzájem blízké či podobné, ale které se liší od objektů ostatních skupin. Jde v ní tedy o sloučení objektů (např. druhů) do skupin (do shluků) na základě jejich vlastností. Každá skupina pak obsahuje objekty s velmi podobnými vlastnostmi. Shluková analýza je především metodou prvního stupně analýzy dat, která má navrhnout určité hypotézy. Neměla by být konečným cílem žádné práce, ale spíše prvním vodítkem k použití dalších statistických metod. Ve shlukové analýze nedochází k testování hypotéz, tak ji někteří autoři nepovažují za statistickou metodu. Příklad použití shlukové analýzy: Mějme soubor stromů a pro každý z nich řadu naměřených parametrů. Shluková analýza nám vytvoří takové shluky (clusters) stromů, uvnitř kterých jsou stromy s podobnými parametry. A také obráceně: stromy zahrnuté do různých shluků se v daných parametrech liší více, než stromy obsažené v jednom shluku.
 je nalézt v celém souboru dat takové skupiny objektů, které jsou si navzájem blízké či podobné, ale které se liší od objektů ostatních skupin. Jde v ní tedy o sloučení objektů (např. druhů) do skupin (do shluků) na základě jejich vlastností. Každá skupina pak obsahuje objekty s velmi podobnými vlastnostmi. Shluková analýza je především metodou prvního stupně analýzy dat, která má navrhnout určité hypotézy. Neměla by být konečným cílem žádné práce, ale spíše prvním vodítkem k použití dalších statistických metod. Ve shlukové analýze nedochází k testování hypotéz, tak ji někteří autoři nepovažují za statistickou metodu. Příklad použití shlukové analýzy: Mějme soubor stromů a pro každý z nich řadu naměřených parametrů. Shluková analýza nám vytvoří takové shluky (clusters) stromů, uvnitř kterých jsou stromy s podobnými parametry. A také obráceně: stromy zahrnuté do různých shluků se v daných parametrech liší více, než stromy obsažené v jednom shluku.")
25
SHLUKOVACÍ (KLASTROVÉ) ANALÝZY
Shluk (klastr) - skupina objektů, které uvnitř nějaké větší skupiny nemají ani náhodný ani rovnoměrný výskyt. Existuje centrum shluku - centroid – prvek (např. hypotetický taxon), který má vlastnosti dané průměrnými hodnotami všech objektů. Shlukovací metody se dělí podle různých kriterií: způsob tvorby shluků: - aglomerativní metody – uplatňuje se postupná fúze objektů do větších skupin - divizivní – dochází k postupnému dělení objektů do menších skupin (2) uspořádání shluků: - hierarchické - v prvním případě jsou shluky hierarchicky uspořádané, - nehierarchické; druhé se objekty dělí jen do primárních skupin, klasifikace na vyšších úrovních tu chybí
 - skupina objektů, které uvnitř nějaké větší skupiny nemají ani náhodný ani rovnoměrný výskyt. Existuje centrum shluku - centroid – prvek (např. hypotetický taxon), který má vlastnosti dané průměrnými hodnotami všech objektů. Shlukovací metody se dělí podle různých kriterií: způsob tvorby shluků: - aglomerativní metody – uplatňuje se postupná fúze objektů do větších skupin. - divizivní – dochází k postupnému dělení objektů do menších skupin. (2) uspořádání shluků: - hierarchické - v prvním případě jsou shluky hierarchicky uspořádané, - nehierarchické; druhé se objekty dělí jen do primárních skupin, klasifikace na vyšších úrovních tu chybí.")
26
Jednospojová metoda, metoda nejbližšího souseda (single linkage, the nearest neighbor method)
Skupiny, které jsou na začátku analýzy reprezentované jednotlivými objekty se spojují podle vzdálenosti mezi jejich nejbližšími objekty. Vzdálenost mezi skupinami se tedy definuje jako vzdálenost mezi jejich nejbližšími příslušníky. Tato metoda se může použít s koeficienty podobnosti nebo s hodnotami vzdáleností.

27
Všespojová metoda, metoda nejvzdálenějšího souseda (complete linkage, the furthest neighbor method)
Tato metoda je přesným opakem jednospojové metody - vzdálenost mezi skupinami je definována jako vzdálenost mezi nejvzdálenějšími body (objekty) z těchto skupin.
 z těchto skupin.")
28
Průměrová metoda (average linkage, UPGMA - unweighted pair-group method using arithmetic averages)
Tato metoda definuje vzdálenost mezi skupinami jako průměr vzdáleností mezi všemi páry OTU ve dvou skupinách. Představuje užitečný kompromis mezi předchozími dvěma metodami. Geometrická interpretace průměrové metody je následující:

29
Princip shlukové analýzy
• Seřazení dat do tabulky- sloupce jsou tvořeny jednotlivými proměnnými a řádky objekty • Transformace dat- v souboru mohu mít proměnné s různými stupnicemi (cm, %, bezjednotková proměnná, atd.). Proto se data transformují na standartizovanou stupnici • Výpočet matice podobnosti či nepodobnosti mezi objekty (pomocí vzdálenosti mezi objekty) • Aplikace třídící strategie: vezmou se objekty, které mají v matici nepodobnosti nejnižší koeficient (tudíž jsou si nejbližší), sloučí se do stejné skupiny (do stejného shluku), pak se spočítá opět matice nepodobnosti mezi skupinami a opět se spojí nejbližší skupiny, atd. Byla vyvinuta celá řada třídících strategií • Výsledkem shlukové analýzy mů.e být např. Dendrogram. Počet shluků může být předem zadán, nebo je součástí procedury podle nějakého kritéria určit optimální počet shluků
. Proto se data transformují na. standartizovanou stupnici. • Výpočet matice podobnosti či nepodobnosti mezi objekty (pomocí vzdálenosti. mezi objekty) • Aplikace třídící strategie: vezmou se objekty, které mají v matici nepodobnosti. nejnižší koeficient (tudíž jsou si nejbližší), sloučí se do stejné skupiny (do. stejného shluku), pak se spočítá opět matice nepodobnosti mezi skupinami. a opět se spojí nejbližší skupiny, atd. Byla vyvinuta celá řada třídících strategií. • Výsledkem shlukové analýzy mů.e být např. Dendrogram. Počet shluků může. být předem zadán, nebo je součástí procedury podle nějakého kritéria určit. optimální počet shluků.")
30
Wardova metoda, metoda minimalizace zvyšování
Princip shlukové analýzy Wardova metoda, metoda minimalizace zvyšování chyby sumy čtverců Narozdíl od předchozích postupů tato metoda není založena na optimalizaci vzdálenosti mezi shluky, ale na optimalizaci homogenity shluků podle určitého kritéria, kterým je minimalizace zvyšování chyby sumy čtverců odchylek bodů shluku od jeho průměru (centroidu). Metodu navrhl Ward v roku 1963 tak, že se na každém stupni analýzy počítá ztráta informace, která je výsledkem seskupení OTU do shluků, a která je vyjádřena jako přírůstek celkové vnitroskupinové sumy čtverců odchylek každého bodu shluku od průměrné hodnoty bodů tohoto shluku. Na každém stupni analýzy se tato suma čtverců počítá pro spojení každého možného páru shluků. Spojují se potom takové shluky, kde dochází k minimálnímu nárůstu chyby sumy čtverců (the error sum of squares). Jinými slovy, tato metoda minimalizuje vnitroshlukový roptyl.
. Metodu navrhl Ward v roku 1963 tak, že se na každém stupni analýzy počítá ztráta informace, která je výsledkem seskupení OTU do shluků, a která je vyjádřena jako přírůstek celkové vnitroskupinové sumy čtverců odchylek každého bodu shluku od průměrné hodnoty bodů tohoto shluku. Na každém stupni analýzy se tato suma čtverců počítá pro spojení každého možného páru shluků. Spojují se potom takové shluky, kde dochází k minimálnímu nárůstu chyby sumy čtverců (the error sum of squares). Jinými slovy, tato metoda minimalizuje vnitroshlukový roptyl.")
31
Program NCSS

32
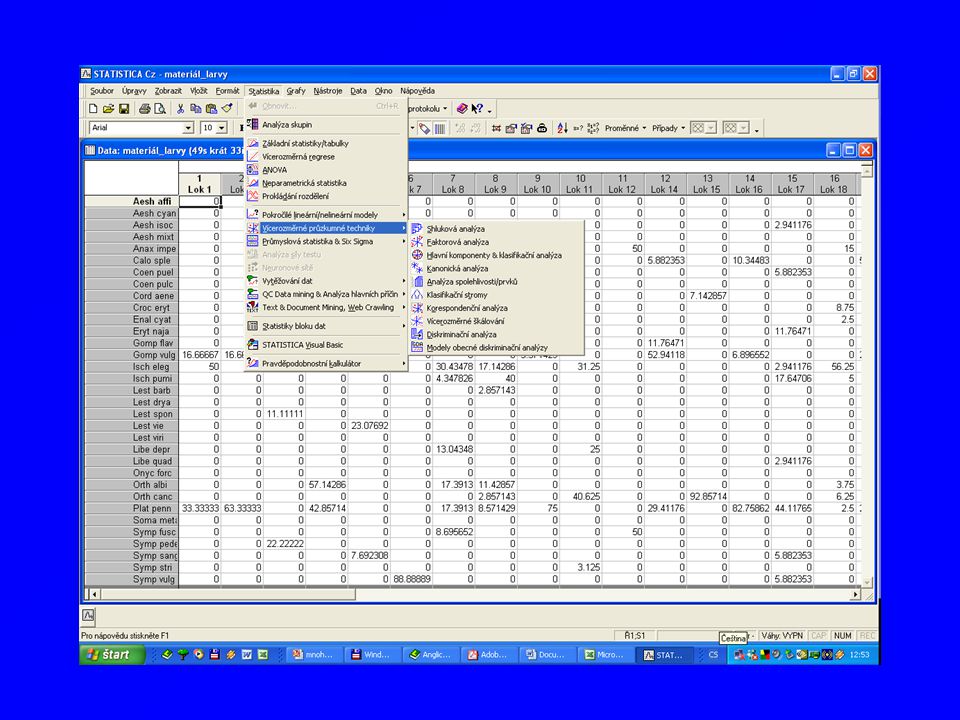
Statistica StatSoft, Inc. (2004). STATISTICA Cz [Softwarový systém na analýzu dat], verze 7.
![Statistica StatSoft, Inc. (2004). STATISTICA Cz [Softwarový systém na analýzu dat], verze 7.](http://slideplayer.cz/slide/1906130/7/images/32/Statistica+StatSoft%2C+Inc.+%282004%29.+STATISTICA+Cz+%5BSoftwarov%C3%BD+syst%C3%A9m+na+anal%C3%BDzu+dat%5D%2C+verze+7..jpg)
36
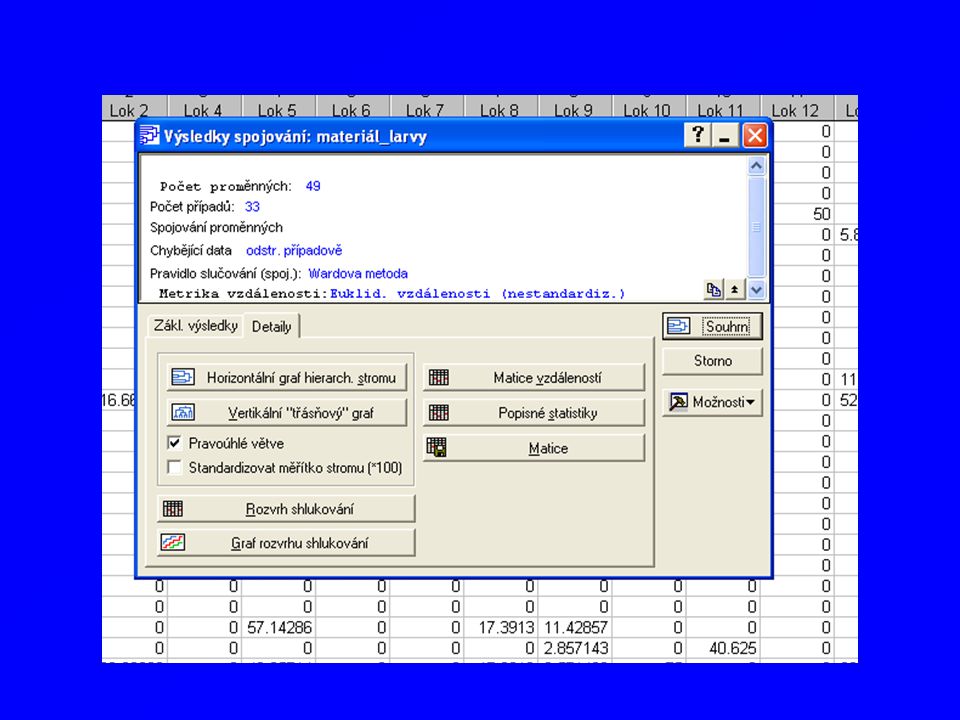
Dendrogram - klastr Jednoduché spojení Wardova metoda

37
Jak číst z dendrogramu? Dendrogram má na horizontální ose vynesený koeficient (po)nepodobnosti (si)dissimilarity a na ose vertikální jsou vyneseny objekty (v našem případě čísla (jméma) stromů - klastrů). Čím delší jsou ve stromovém diagramu horizontální úsečky, tím větší je rozdíl mezi objekty.
nepodobnosti (si)dissimilarity a na ose vertikální jsou vyneseny objekty (v našem případě čísla (jméma) stromů - klastrů). Čím delší jsou ve stromovém diagramu horizontální úsečky, tím větší je rozdíl mezi objekty..")
38
3D graf ze skóre na ordinační osy

39
Děkuji za pozornost S mnohorozměrnou analýzou do světa...

Podobné prezentace










>")





>")



