Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Klasifikace Míry (ne)podobnosti (Dis)similarity measures, Resemblance functions Shluková analýza - Cluster analysis TWINSPAN
podobnosti (Dis)similarity measures, Resemblance functions Shluková analýza - Cluster analysis TWINSPAN")
2
Míry podobnosti Similarity measures Každá ordinační nebo klasifikační metoda je (explicitně nebo implicitně) založena na nějakých míře (ne)podobnosti. (Vzpomeň na dvě možné formulace ordinace)
.")
3
Similarity (dissimilarity, vzdálenosti) Resemblance functions (aby tam byly jak similarity – S, tak dissimilarity - D) Pokud je similarita škálována tak, že 0 ≤ S ≤1, pak obvykle disimilaritu máme jako doplněk do jedné, příp. S transformací D = 1 – S nebo D = √(1 – S) nebo D = √(1 – S 2 ) Obvykle jsou jiné míry vhodné pro (ne)podobnost vzorků, a jiné pro (ne)podobnost druhů Dva snímky můžu porovnat, aniž k tomu potřebuju kontext celé studie, pro porovnání dvou druhů musím říct, v rámci jakého souboru snímků Soubor uvažovaných druhů je „pevný“ (e.g. Všechny cévnaté rostliny), vzorky jsou nějakým výběrem z “potenciálního souboru snímků”
 nebo D = √(1 – S 2 ) Obvykle jsou jiné míry vhodné pro (ne)podobnost vzorků, a jiné pro (ne)podobnost druhů Dva snímky můžu porovnat, aniž k tomu potřebuju kontext celé studie, pro porovnání dvou druhů musím říct, v rámci jakého souboru snímků Soubor uvažovaných druhů je „pevný (e.g. Všechny cévnaté rostliny), vzorky jsou nějakým výběrem z potenciálního souboru snímků .")
4
Míry podobnosti Stovky navrženy, desítky se užívají (často jeden pod různými jmény v různých oborech) Porovnáváme: vzorky - Qdruhy – R Typ dat Presence/absence (0 / 1) S ø rensen coefficient Jaccard coefficient Pearson V) coeff. Yule (Q) coefficient KvantitativníEuclidean distance distance Percentage similarity correlation coefficients distance
 coefficient KvantitativníEuclidean distance distance Percentage similarity correlation coefficients distance.")
5
Podobnost vzorků (snímků) založená na presenci/absenci SörensenJacquard d – počet druhů, které nejsou v žádném z porovnávaných vzorků (většinou se neužívá)
 založená na presenci/absenci SörensenJacquard d – počet druhů, které nejsou v žádném z porovnávaných vzorků (většinou se neužívá)")
6
Podobnost druhů (rozumněj podobnost ekologického chování) za základě prezence/absence d – počet vzorků, které neobsahují žádný druh – jeho užití je absolutně nutné
 za základě prezence/absence d – počet vzorků, které neobsahují žádný druh – jeho užití je absolutně nutné")
7
Podobnost druhů vs. vzorků Podobnost druhů (i.e. Podobnost ekol. chování, e.g. V, Q) – často je od -1 do 1. “Nulový model” znamená nezávislost druhů, a v tom případě V=Q=0. Podobnost vzorků (S, J), obvykle jde od 0 (žádné společné druhy) do 1 (identická druhová kombinace). Obvykle neuvažujeme žádný “nulový model”. (Teoreticky by snad šlo – oba snímky jsou náhodnými výběry z téhož souboru – za soubor bychom museli užít všechny druhy v dané tabulce. Podobnost snímků pak je „context dependent“.
 – často je od -1 do 1. Nulový model znamená nezávislost druhů, a v tom případě V=Q=0. Podobnost vzorků (S, J), obvykle jde od 0 (žádné společné druhy) do 1 (identická druhová kombinace). Obvykle neuvažujeme žádný nulový model . (Teoreticky by snad šlo – oba snímky jsou náhodnými výběry z téhož souboru – za soubor bychom museli užít všechny druhy v dané tabulce. Podobnost snímků pak je „context dependent ..")
8
Transformace je algebraická funkce X ij ’=f(X ij ),kterou aplikujeme nezávisle na jakýchkoliv jiných hodnotách (třeba log, nebo odmocnina). Standardizaci provádíme s ohledem na hodnoty ostatních druhů ve vzorku (standardization by samples) nebo s ohledem na hodnoty druhu v ostatních vzorcích (standardization by species). Kvantitativní data Centering je odečtení průměru druhu (nebo vzácněji vzorku) – výsledkem je, že daný druh (vzorek) má prměr rovný nule. Standardizace obvykle znamená přepočtení na procenta, nebo dělení „normou“.
 nebo s ohledem na hodnoty druhu v ostatních vzorcích (standardization by species). Kvantitativní data Centering je odečtení průměru druhu (nebo vzácněji vzorku) – výsledkem je, že daný druh (vzorek) má prměr rovný nule. Standardizace obvykle znamená přepočtení na procenta, nebo dělení „normou ..")
9
„Ordinal transformation „Br.-Bl. Stupnice zhruba odpovídá log-transformaci hodnot pokryvnosti.

10
Euclidean distance – užívá se v lineárních metodách For ED, standardizuj by sample norm, ne by total t značí vzorky standardizované by total, n vzorky standardizované by sample norm. ED1t2t = 1.41 (√2), zatímco ED3t4t=0.82. Pro vzorky standardizované by sample norm, ED1n2n=ED3n4n=1.41
, zatímco ED3t4t=0.82. Pro vzorky standardizované by sample norm, ED1n2n=ED3n4n=1.41.")
11
Percentual similarity (quantitative Sörensen)
")
12
Similarita druhů na základě kvantitativních dat Korelační koeficienty (ordinary, rank) Všimněte si implicitní dvojité transformace - z toho taky vyplývá, že chi-squared distance je „context dependent“, tj. její hodnota se mění se složením ostatních snímků v tabulce.

13
Podobnost vzorků vs. Podobnost společenstev Počáteční impuls – zdálo se, že v tropickém lese je obrovská beta-diverzita hmyzích společenstev

14
Očekávaný počet společných druhů, pokud výtáhnu n individuí z prvního kýble, a n individuí z druhého kýble 22 Normalized expected shared species (NESS) = Očekávaný počet společných druhů, pokud výtáhnu dvakrát n individuí z prvního kýble Očekávaný počet společných druhů, pokud výtáhnu dvakrát n individuí z druhého kýble Každý vzorek z lapače hodím do jednoho kýble
 = Očekávaný počet společných druhů, pokud výtáhnu dvakrát n individuí z prvního kýble Očekávaný počet společných druhů, pokud výtáhnu dvakrát n individuí z druhého kýble Každý vzorek z lapače hodím do jednoho kýble")
15
Similarity matrices – přímo je užíváme v Multidimensional scaling (both metric and non-metric) Mantel test
 Mantel test")
16
Mantel Test Otázka – je nějaká závislost mezi dvěma maticemi (ne)podobnosti/ vzdálenosti? např. – je nějaká závislost mezi vzdáleností individuí v reálném prostoru a genetickou podobností?

17
Individua v ploše Indiv. No. 5 A tohle individuum je nějaký divný (jedno z pěti, čistě náhodou)
")
18
Two dissimilarity matrices plant12345 1 21.41 31.002.24 41.00 1.41 512.0410.6312.7311.31 plant12345 1 20.1 30.2 40.10.30.2 50.90.60.70.8 Vzdálenost v plošeGenetická distance

19
Regrese je vysoce significantní (ale máme 10 “nezávislých” pozorování, založených na pěti rostlinách!) A ty čtyři distance – všechny k té jedné divné rostlině, jsou největší
 A ty čtyři distance – všechny k té jedné divné rostlině, jsou největší")
20
Řešení Permutační test Nepermutujeme jednotlivé vzdálenosti, ale jednotlivá individua

21
Klasifikace V podstatě jen historická vzpomínka

22
Hierarchická aglomerativní (cluster analysis)
")
23
Subjectivní volby v objektivní proceduře Nicméně, procedura je reproducible

24
Cluster analysis - spojování Vzdálenosti mezi objekty jsou v matici. Ale abychom vytvořili stromeček, potřebujeme i vzdálemosti mezi skupinami....

25
Single linkage (nearest neighbour, representant tzv. metod krátké ruky - short hand) and complete linkage (furthest neighbour, representant metod dlouhé ruky) Několik dalších metod, např. Wardova (minimum dispersion), “average linkage” – nejpopulárnjší, ale jméno užito pro několik různých metod – dnes užívané jméno UPGMA - Unweighted Pair Group Method with Arithmetic mean
 and complete linkage (furthest neighbour, representant metod dlouhé ruky) Několik dalších metod, např. Wardova (minimum dispersion), average linkage – nejpopulárnjší, ale jméno užito pro několik různých metod – dnes užívané jméno UPGMA - Unweighted Pair Group Method with Arithmetic mean.")
26
Single linkage - > chaining

27
V klasické cluster analysis nehraje pořadí roli – tyto dva dendrogramy znázorňují tentýž výsledek

28
TWINSPAN – Two Way INdicator SPecies ANalysis Vymyslel Mark Hill – v podstatě pro velké „fytocenologické“ tabulky Inspirován klasickou fytocenologickou metodikou Algoritus založen na presence/absence data Kvantitativní data – lze užít úpro definici „pseudospecies”

29
TWINSPAN 2 - pseudospecies Definice cut levels má podobný efekt jako transformace (vážení dominance vs. presence/absence) Compare 0, 1, 10, 100 vs. 0, 10, 20, 30, 40
 Compare 0, 1, 10, 100 vs. 0, 10, 20, 30, 40.")
30
Divisivní metoda – každá skupina je dělena na základě první CA osy Ale, většina vzorků je někde uprostřed – to bychom to sekli někde uprostře shluku -> potřebujeme nějakou polarizaci

31
Polarized ordination (based on “indicator species”)
")
32
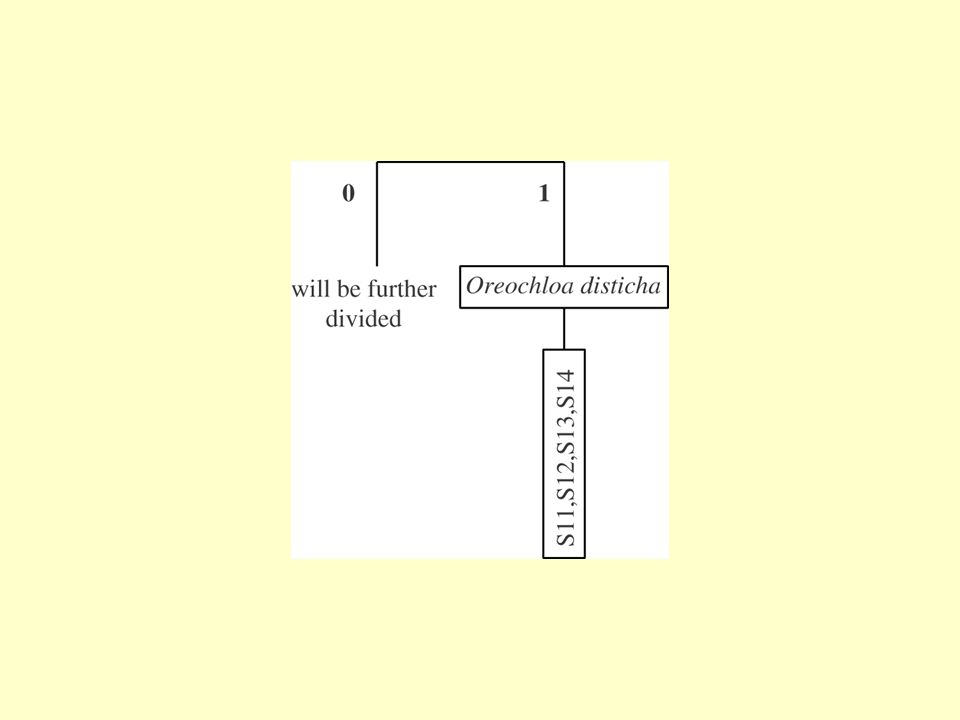
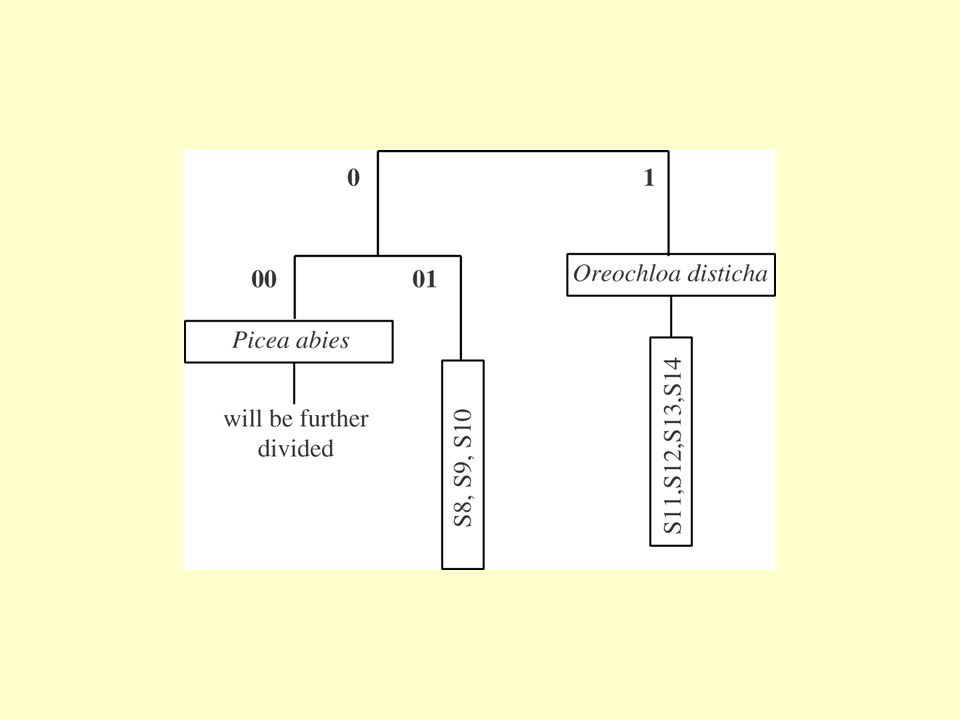
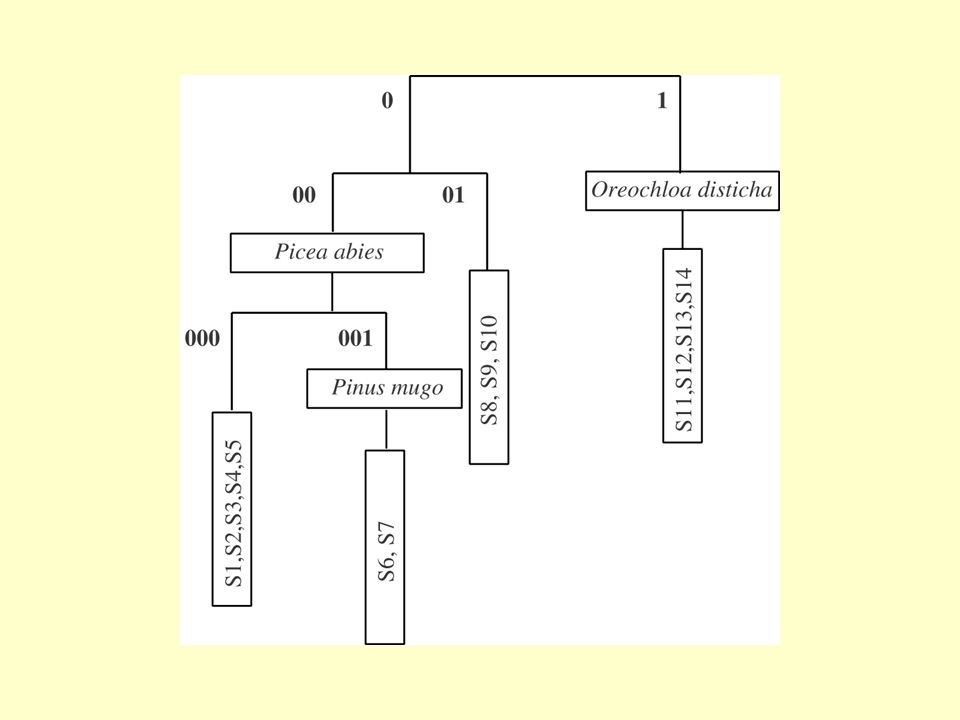
01 is more similar to 1 than 00 The order of groups reflects possible gradient in the table

Podobné prezentace



>")
















