Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Ing. Tomáš Vondra kat. kybernetiky FEL ČVUT v Praze
Big Data v Cloudu Ing. Tomáš Vondra kat. kybernetiky FEL ČVUT v Praze

2
Úvod Skupina Cloud Computing Center eClub: Enterpreneurs’ Club
Summer Camp Předměty Technologie pro velká data Vývoj internetových aplikací

3
Cloud Computing Center
Malá výzkumná skupina Vedoucí: Ing. Jan Šedivý, CSc. 6 doktorandů V tomto období nejisté množství diplomantů a bakalářů

4
Cloud Computing Center
Cíl: aplikovaný výzkum, spolupráce s průmyslem, výuka Firmy: Cloud Computing, Machine learning, Big Data Univerzita: algoritmy deskriptivní a prediktivní analýzy Příklady projektů: Kontextuální reklama založená na topic modelu Rozpoznávání jmen a označení firem ve větě Modelování chování hráčů on-line her Generování synonym pro vyhledávání Klasifikace spamu a vyžádaných newsletterů Předpověď vytížení cloudu pomocí časových řad Deployment aplikací do cloudu řízený performance modelem Škálování Hadoopu v cloudu

5
Enterpreneurs’ club Podpora studentských podnikatelských nápadů
Přednášky o soft skills, příběhy firem Přednášky streamujeme do dalších škol Studenti tvoří týmy, dělají prezentace Na konci soutěž o stipendium Stáž v inkubátoru v Silicon Valley V porotě také investoři

6
Summer Camp Tentokrát nebyl zaměřen jen na startupy
Projekty zadané partnery Pro studenty stipendia (dokončilo asi 16) Témata: Automatický překlad Twitteru (UFAL MFF UK) Cloud Computing Škálovatelné prediktivní modely Uživatelská rozhraní pro tablety v autě Automatické hraní her (Atari, Angry Birds)
 Témata: Automatický překlad Twitteru (UFAL MFF UK) Cloud Computing. Škálovatelné prediktivní modely. Uživatelská rozhraní pro tablety v autě. Automatické hraní her (Atari, Angry Birds)")
7
Předmět Big Data Volitelný předmět v letním semestru
Kapacita 40, poprvé přihlášeno 28 Schvalování bylo kontroverzní Prý je zaměření příliš průmyslové Podle nás je praxe na univerzitě důlžitá Definici Big Data uvádět raději nebudu Nestrukturovaná data nebo Velký objem nebo Rychle přibývající záznamy

8
Předmět Big Data Učitelé: Jan Šedivý, Tomáš Vondra, Tomáš Tunys, Ondřej Pluskal, Martin Pavlík (IBM) Cíl: naučit studenty aplikovat algoritmy Platforma: Hadoop (distr. IBM BigInsights) Zvolená data: Obsah české Wikipedie Objem jen 1 GB, ale jsou nestrukturovaná Hardware: virtuální servery v cloudu TC Písek Do dvojice studentů cluster 3 strojů Celkem včetně testovací instance 45 VM Fyzicky spuštěno na 2 serverech
 Zvolená data: Obsah české Wikipedie. Objem jen 1 GB, ale jsou nestrukturovaná. Hardware: virtuální servery v cloudu TC Písek. Do dvojice studentů cluster 3 strojů. Celkem včetně testovací instance 45 VM. Fyzicky spuštěno na 2 serverech.")
10
BDT: Program přednášek
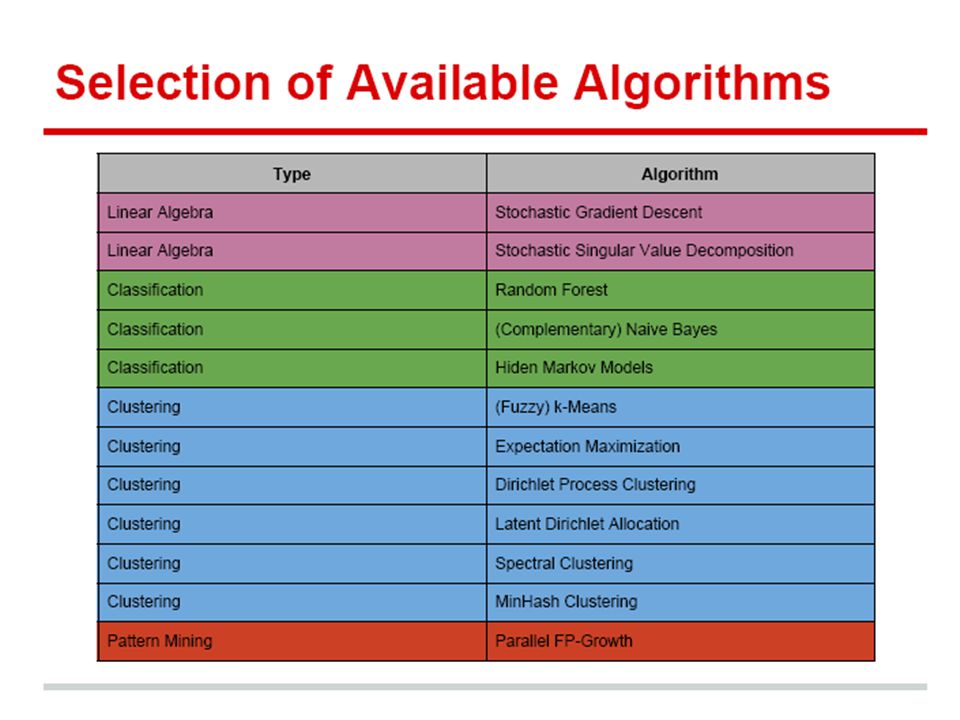
Cloud computing a platforma OpenStack Hadoop a jeho komponenty Paralelní programování a limitace Hadoopu Programování v Map-Reduce Implementace TF-IDF HDFS a databáze Hive a HBase Paralelní souborové systémy a administrace HDFS Knihovna Mahout Implementace clusterování k-Means Streaming data pomocí Apache Storm Cvíčení na Storm

13
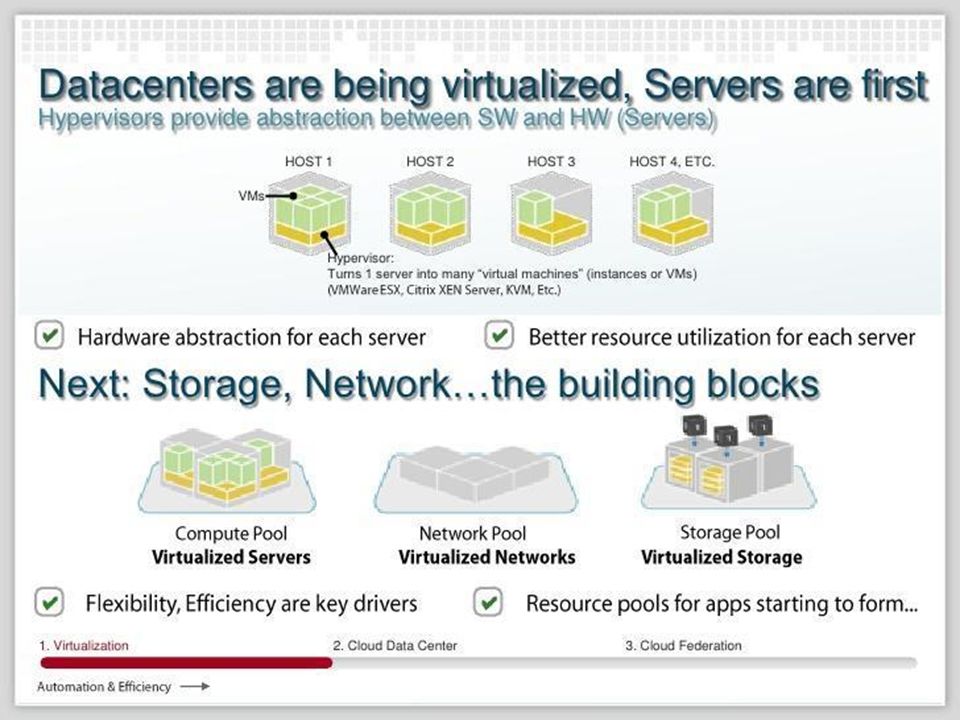
HDFS – Hadoop Distributed File System
File System where Hadoop components and applications expect their data Links together subsets of FS on nodes in cluster => brings new big virtual File System Uses Master / Slave architecture a b d c File1 NameNode DataNodes

14
Data never flows through NameNode
HDFS – Write example NameNode B1 B2 B3 Data never flows through NameNode DataNodeR1N1 DataNodeR2N1 DataNodeR2N1 Name node communication Data send from client (from DataNodes to next DataNodes in the pipeline DataNodeR1N2 DataNodeR2N2 DataNodeR1N3 DataNodeR2N3 ACK of successful write of packet (typically 64kB) DataNodeR1N4 DataNodeR1N4 DataNodeR2N4 ACK of successful write of a block (typically 64MB) DataNodeR1N5 DataNodeR2N5 DataNodeR2N5 DataNodeR1N6 DataNodeR2N6 DataNodeR1N7 DataNodeR2N7 DataNodeR1N8 DataNodeR2N8
 DataNodeR1N4. DataNodeR1N4. DataNodeR2N4. ACK of successful write of a block (typically 64MB) DataNodeR1N5. DataNodeR2N5. DataNodeR2N5. DataNodeR1N6. DataNodeR2N6. DataNodeR1N7. DataNodeR2N7. DataNodeR1N8. DataNodeR2N8.")
15
Distribute map tasks to cluster Return a single result set
MapReduce - explained Data stored in HDFS spanning inexpensive computers Bring algorithms to data Distribute application to the compute resources where the data is stored Hadoop Data Nodes Map Phase(break job into small parts) Shuffle(transfer interim output for final processing) Reduce Phase(boil all output down to a single result set) public static class TokenizerMapper extends Mapper<Object,Text,Text,IntWritable> { one = new IntWritable(1); private final static IntWritable private Text word = new Text(); public void map(Object key, Text val, Context StringTokenizer itr = new StringTokenizer(val.toString()); while (itr.hasMoreTokens()) { context.write(word, one); word.set(itr.nextToken()); } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWrita private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> val, Context context){ int sum = 0; sum += v.get(); for (IntWritable v : val) { . . . Distribute map tasks to cluster Shuffle Result Set Return a single result set
 Shuffle(transfer interim output for final processing) Reduce Phase(boil all output down to a single result set) public static class TokenizerMapper. extends Mapper<Object,Text,Text,IntWritable> { one = new IntWritable(1); private final static IntWritable. private Text word = new Text(); public void map(Object key, Text val, Context. StringTokenizer itr = new StringTokenizer(val.toString()); while (itr.hasMoreTokens()) { context.write(word, one); word.set(itr.nextToken()); } public static class IntSumReducer. extends Reducer<Text,IntWritable,Text,IntWrita. private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> val, Context context){ int sum = 0; sum += v.get(); for (IntWritable v : val) { Distribute map tasks to cluster. Shuffle. Result Set. Return a single result set.")
16
Parallel Reduce / Divide and Conquer
Parallel search on CRCW-concurrent Read x, search for x in n/p, write 1 if found What about EREW PRAM? Read using parallel distribution (only 1 input) Write using parallel reduce (to get 1 result) Both have O(log p) -> O(n/p+2log p)
 Write using parallel reduce (to get 1 result) Both have O(log p) -> O(n/p+2log p)")
17
Map-Reduce in Hadoop Not classical map and reduce
Uses the divide and conquer approach But no reduction trees - only two levels The single communication phase is managed Works with files or blocks of fixed size

18
WordCount algorithm

19
Document representation
A dataset of documents: corpus. How documents can be represented? Each language has a more-less fixed vocabulary. Is order of words in text significant? How many different words are present in one document?

20
Vocabulary : how to build it?
Should have the least amount of words, but most representative! Stop words? (a, the, or) Rare words? Advanced: Lemmatization Stemming Part of speech tagging
 Rare words Advanced: Lemmatization. Stemming. Part of speech tagging.")
21
TF-IDF : The Idea Does the length of the document matter?
TF = term frequency If we have some word in every document (e.g. word “love” in a corpus of romantic novels) does is it give enough information? IDF = inverse document frequency
 does is it give enough information IDF = inverse document frequency.")
22
Homework Assignment: Clean data and create vocabulary.
Create tf-idf from Wikipedia in sparse matrix representation.

23
CAP theorem - CA / noSQL (CP + AP)
")
24
Hive Framework for data-warehousing in Hadoop
Enable to run SQL queries on top of huge volumes of data stored in HDFS HiveQL - SQL dialect used on top of Hive Data are organized into tables Table creation Table population (no parsing, just copy / move to managed location on HDFS) CREATE TABLE records (year STRING, temperature INT, quality INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; LOAD DATA LOCAL INPATH 'input/ncdc/micro-tab/sample.txt' OVERWRITE INTO TABLE records;
 CREATE TABLE records (year STRING, temperature INT, quality INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY \t ; LOAD DATA LOCAL INPATH input/ncdc/micro-tab/sample.txt OVERWRITE INTO TABLE records;")
25
HBase - data model - columns
Row columns are grouped to column families All columns names has the following syntax: <col-fm-prefix>:<qualifying-tail>, e.g: temperature:air, temperature:dew_point Column families has to be defined with the table up-front members are stored in the file system together Columns can be defined and used on demand HBase is column-family store oriented Comparison of the model to RDBMS: Cells are versioned Rows are sorted according to row-key Columns can be added on the fly if family exists

26
Scalability, Tuning 1 CPU to disk ratio: 1 disk per 1 to 2 CPUs
Local node optimization Balance CPUs and RAM, don’t let it swap Each system process and map/reduce is JVM -Xmx=1000M is default The processes are mostly single-threaded (with asynchronous I/O), so 1 map per CPU mapred.tasktracker.map.tasks.maximum Most examples set reduce.tasks.maximum to half this number All may be running at once! Don’t forget the system process overhead Slaves: Just DataNode and TaskTracker Master: A lot of them :-) CPU to disk ratio: 1 disk per 1 to 2 CPUs
, so 1 map per CPU. mapred.tasktracker.map.tasks.maximum. Most examples set reduce.tasks.maximum to half this number. All may be running at once! Don’t forget the system process overhead. Slaves: Just DataNode and TaskTracker. Master: A lot of them :-) CPU to disk ratio: 1 disk per 1 to 2 CPUs.")
27
Hadoop on cloud 1 Advantages:
Fast deployment of Big Data infrastructure Sharing of servers with other tasks Increased utilization Disadvantages: Virtualization overhead 1s of % on CPU, 2 schedulers defeat Amdahl It is present in 10s of % on disk and net Specialties: add and remove nodes based on actual usage core datanodes and temp. tasktrackers Elastic MapReduce / Elastic Data Processing launch a cluster just for a single task

28
Hadoop on cloud 2 Problems:
Data redundancy. Replicas on different VMs may end on the same physical disk VMware: Hadoop Virtualization Extensions, in Hadoop 1.2 and 2.1+ Data persistence. VMs are temporary Use persistent disks - may be on a separate array Use cloud’s own filesystem, not HDFS, -”- Amazon S3, OpenStack Swift Use suspend function Use the physical machine as DataNode? Impact on disk and net for other tenants?

29
Hadoop on cloud 3 Implementations: Public: Amazon Elastic MapReduce
Microsoft HDInsight Rackspace Big Data Platform Private VMware Serengeti -> Big Data Extensions OpenStack Savanna This list is not exhaustive. There are and will be more providers.

31
Lloyd's k-Means Algorithm
Works in 2 steps (+ initialization): Initialization: Pick randomly K samples from dataset which become the initial cluster centroids. Assignment: For each data vector find the nearest centroid and assign the vector to its corresponding cluster. Refinement: Recalculate the cluster centroids as the means of the data vectors within their corresponding clusters. When do we stop? Threshold for the maximum number of iterations. Use the detla rule - If nothing moves much, halt!
: Initialization: Pick randomly K samples from dataset which become the initial cluster centroids. Assignment: For each data vector find the nearest centroid and assign the vector to its corresponding cluster. Refinement: Recalculate the cluster centroids as the means of the data vectors within their corresponding clusters. When do we stop Threshold for the maximum number of iterations. Use the detla rule - If nothing moves much, halt!")
32
K-means: Assignment

33
K-means: Refinement

34
K-means: Assignment

35
K-means: Assignment -> Terminate

36
Machine Learning Stream Processing Batch Processing S4 Storm Spark
Hadoop minutes to hours real time SAMOA MLib Mahout

37
Hadoop slow due to I/O operations

38
Spark

39
Storm oriented graph Terminology: Sprouts, Streams, Bolts

40
Vývoj internetových aplikací
Volitelný předmět v zimním semestru Kapacita 40, 4.rok a přihlášeno 37 Rovněž praktický předmět Zaměřeno na propojení cloudu a mobilní aplikace (ideálně i s Big Data) Některé technologie studenti vidí poprvé OpenStack, Android, SQLite, REST Jiné již znají z ostatních předmětů Java, servlety, JSON
 Některé technologie studenti vidí poprvé. OpenStack, Android, SQLite, REST. Jiné již znají z ostatních předmětů. Java, servlety, JSON.")
41
Vývoj internetových aplikací
Učitelé: Jan Šedivý, Filip Kolařík, Radek Pospíšil (HP), Tomáš Bařina, Tomáš Tunys, Tomáš Vondra Cíl: napsat mobilní aplikaci s cloudovým backendem Platforma: Samsung Galaxy a OpenStack Forma: Týmový projekt po 4-5 lidech Zadání vymýšlí studenti sami Hardware: zatím neznámo - během let se měnil Nejdříve Google App Engine, pak Eucalyptus, minule OpenStack na nevyhovujícím kancelářském HW Každému týmu tu stačí jeden až dva VM s 0,5 GB RAM Doufáme v další spolupráci s TC Písek
, Tomáš Bařina, Tomáš Tunys, Tomáš Vondra. Cíl: napsat mobilní aplikaci s cloudovým backendem. Platforma: Samsung Galaxy a OpenStack. Forma: Týmový projekt po 4-5 lidech. Zadání vymýšlí studenti sami. Hardware: zatím neznámo - během let se měnil. Nejdříve Google App Engine, pak Eucalyptus, minule OpenStack na nevyhovujícím kancelářském HW. Každému týmu tu stačí jeden až dva VM s 0,5 GB RAM. Doufáme v další spolupráci s TC Písek.")
42
VIA: Program přednášek
Platforma Android Programování pro Android Architektura REST Jak napsat REST v Javě Od hostingu ke cloudu Praktické příklady cloudových služeb Cloud Computing a OpenStack Spusťte si vlastní server Komunikace v Androidu Databáze MySQL SQLite v Androidu Performance engineering a load testing Bezpečnost webových aplikací

Podobné prezentace