Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Analýza kvantitativních dat I. Popisné statistiky a explorační analýza
UK FHS Historická sociologie (LS 2014+) Analýza kvantitativních dat I. Popisné statistiky a explorační analýza Jiří Šafr jiri.safr(zavináč)seznam.cz vytvořeno , poslední aktualizace
 Analýza kvantitativních dat I. Popisné statistiky a explorační analýza. Jiří Šafr jiri.safr(zavináč)seznam.cz. vytvořeno , poslední aktualizace")
2
Obsah Analýza kvantitativních dat (obecné principy)
Dva základní typy (přístupy ke) statistiky Připomenutí základních pojmů – typy znaků Jednoduché popisné statistiky → třídění dat 1. stupně (jednorozměrná analýza): Střední hodnoty: modus, medián, průměr Variance-rozptýlení dat: rozptyl, směrodatná odchylka Další míry variability-rozptýlení (rozpětí, kvantily, špičatost, šikmost) Střední hodnoty a míry variability v SPSS Míry variability pro kategoriální proměnné (úvod): Směrodatná odchylka pro dichotomickou proměnnou Variační poměr – v Vlastnosti rozdělení znaků Ověření normality rozložení dat Na co si dát v datech pozor Standardizace na z-skóre
 statistiky. Připomenutí základních pojmů – typy znaků. Jednoduché popisné statistiky → třídění dat 1. stupně (jednorozměrná analýza): Střední hodnoty: modus, medián, průměr. Variance-rozptýlení dat: rozptyl, směrodatná odchylka. Další míry variability-rozptýlení (rozpětí, kvantily, špičatost, šikmost) Střední hodnoty a míry variability v SPSS. Míry variability pro kategoriální proměnné (úvod): Směrodatná odchylka pro dichotomickou proměnnou. Variační poměr – v. Vlastnosti rozdělení znaků. Ověření normality rozložení dat. Na co si dát v datech pozor. Standardizace na z-skóre.")
3
Analýza kvantitativních dat
Předmětem statistického zkoumání jsou hromadné jevy: výskyt vlastností u velkého počtu prvků – statistických jednotek (osoby, organizace, události,…) Jejich vlastnosti vyjadřují statistické znaky (= proměnné): kvantitativní (číselné)/ kvalitativní (slovní). Získání dat pomocí šetření: - úplné-vyčerpávající - výběrové (pouze u části populace → výběrový soubor, který reprezentuje základní soubor) [Cyhelský, Hustopecký, Závodský 1978]
 Jejich vlastnosti vyjadřují statistické znaky (= proměnné): kvantitativní (číselné)/ kvalitativní (slovní). Získání dat pomocí šetření: - úplné-vyčerpávající - výběrové (pouze u části populace → výběrový soubor, který reprezentuje základní soubor) [Cyhelský, Hustopecký, Závodský 1978]")
4
Dva základní typy statistiky
Popisná statistika: metody pro zjišťování a sumarizaci informací → grafy, tabulky, popisné charakteristiky (průměr, rozptyl percentily,..) Inferenční statistika (statistická indukce): metody pro přijímání a měření spolehlivosti závěrů o populaci založených na informacích získaných z jejího výběru (odhad parametru na základě výběru z populace)
 Inferenční statistika (statistická indukce): metody pro přijímání a měření spolehlivosti závěrů o populaci založených na informacích získaných z jejího výběru (odhad parametru na základě výběru z populace)")
5
Proces analýzy dat musíme promyslet již ve stadiu plánování dotazníku (modelu vztahů a hypotéz).
.")
6
Nejprve malé připomenutí základních pojmů

7
Základní pojmy Populace Základní soubor Výběrový soubor (vzorek)
Datový soubor Znak Třídění dat (jedno a vícestupňové) Absolutní četnost Relativní (poměrná) četnost Kumulativní četnost Distribuce (rozdělení) hodnot proměnné
 Absolutní četnost. Relativní (poměrná) četnost. Kumulativní četnost. Distribuce (rozdělení) hodnot proměnné.")
8
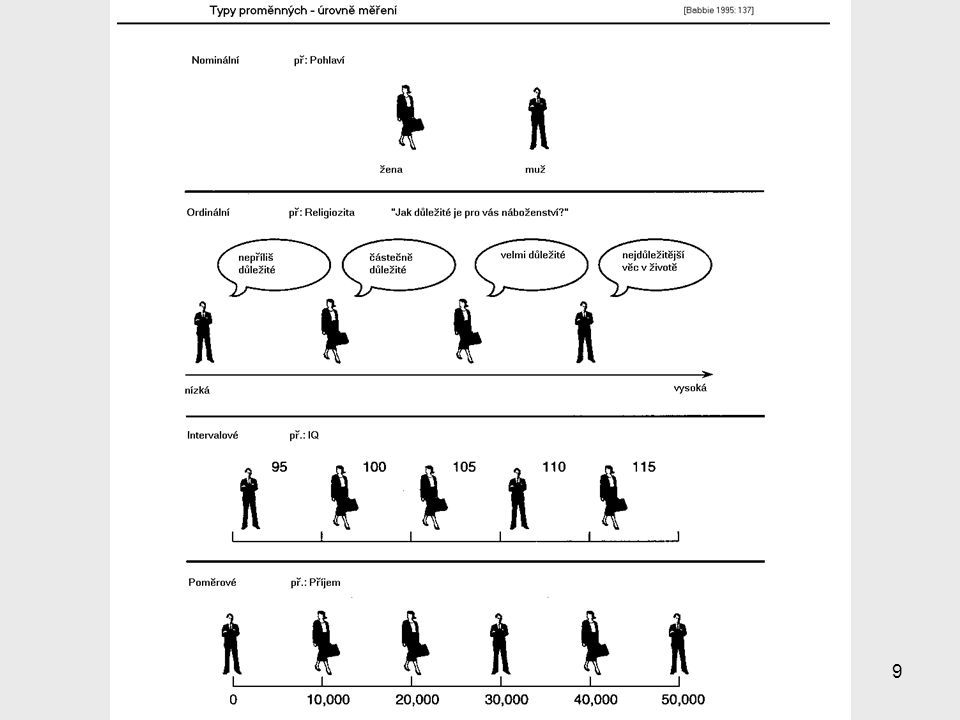
Typy znaků – proměnných
Kategoriální: Nominální Kategorie jsou rovnocenné (na úrovni jmen) př.: pohlaví, jména, typ rodiny, barva vlasů, profese Pořadové (ordinální) Kategorie lze seřadit do hierarchie Lze se ptát: vyšší/nižší apod., ale ne o kolik např.: spokojenost, stupeň souhlasu Kardinální (intervalové/poměrové): číselné proměnné lze se ptát větší/ menší a o kolik př.: věk, příjem, počet dětí → Různé typy znaků vyžadují v analýze odlišné přístupy (statistické míry).
 př.: pohlaví, jména, typ rodiny, barva vlasů, profese. Pořadové (ordinální) Kategorie lze seřadit do hierarchie. Lze se ptát: vyšší/nižší apod., ale ne o kolik. např.: spokojenost, stupeň souhlasu. Kardinální (intervalové/poměrové): číselné proměnné. lze se ptát větší/ menší a o kolik. př.: věk, příjem, počet dětí. → Různé typy znaků vyžadují v analýze odlišné přístupy (statistické míry).")
10
Znaky / proměnné kardinální
A) intervalové – nemají přirozený počátek: obsahový smysl má rozdíl ale nikoliv podíl Příklad: „Dnes je o 10 st. C tepleji“, ale ne „o 25% tepleji.“ / IQ nemá nulu B) poměrové – mají přirozený počátek (0 má význam), tudíž lze uvažovat i podíl. Příklad: „nulové“ i „dvojnásobné tržby“
 intervalové – nemají přirozený počátek: obsahový smysl má rozdíl ale nikoliv podíl Příklad: „Dnes je o 10 st. C tepleji , ale ne „o 25% tepleji. / IQ nemá nulu. B) poměrové – mají přirozený počátek (0 má význam), tudíž lze uvažovat i podíl. Příklad: „nulové i „dvojnásobné tržby")
11
Jednoduché popisné statistiky
třídění dat 1. stupně: Střední hodnoty Míry variability

12
Střední hodnoty: nominální znaky → modus
ordinální znaky → medián (aritmetický průměr) intervalové znaky → aritmetický průměr Pomocí „jednoho čísla“ vyjadřujeme vlastnost znaku → typická hodnota datové řady
 intervalové znaky → aritmetický průměr. Pomocí „jednoho čísla vyjadřujeme vlastnost znaku → typická hodnota datové řady.")
13
Základní střední hodnoty (míry centrální tendence)
Modus (Mo) = kategorie s největší četností Nelze s ním provádět žádné algebraické operace. Může existovat i více modálních kategorií. Medián (Me) = hodnota, která je ve prostředku všech pozorování seřazených podle hodnot nebo jinak řečeno: Hodnota proměnné, před níž je polovina pozorování majících menší hodnotu a za níž je druhá polovina pozorování majících větší hodnotu než má medián. Při sudém počtu hodnot: průměr dvou prostředních hodnot. _ Aritmetický průměr (X) = součet hodnot dělený počtem pozorování Pro symetrické rozložení hodnot je Mo = Me = X
 = kategorie s největší četností Nelze s ním provádět žádné algebraické operace. Může existovat i více modálních kategorií. Medián (Me) = hodnota, která je ve prostředku všech pozorování seřazených podle hodnot nebo jinak řečeno: Hodnota proměnné, před níž je polovina pozorování majících menší hodnotu a za níž je druhá polovina pozorování majících větší hodnotu než má medián. Při sudém počtu hodnot: průměr dvou prostředních hodnot. _. Aritmetický průměr (X) = součet hodnot dělený počtem pozorování. Pro symetrické rozložení hodnot je Mo = Me = X.")
14
Modus (mode) [Babbie 1995]
![Modus (mode) [Babbie 1995]](http://slideplayer.cz/slide/2785825/10/images/14/Modus+%28mode%29+%5BBabbie+1995%5D.jpg "Modus (mode) [Babbie 1995]")
15
Medián Poznámka: zde je důležité, aby hodnoty znaku byly seřazeny.
Máme 31 případů (žáků) seřazených podle věku, tj. medián je uprostřed (16. žák): 50 % případů je pod a 50 % nad ním. Zde je medián zároveň modusem i průměrem. [Babbie 1995]
 seřazených podle věku, tj. medián je uprostřed (16. žák): 50 % případů je pod a 50 % nad ním. Zde je medián zároveň modusem i průměrem. [Babbie 1995]")
16
Průměr [Babbie 1995]
![Průměr [Babbie 1995]](http://slideplayer.cz/slide/2785825/10/images/16/Pr%C5%AFm%C4%9Br+%5BBabbie+1995%5D.jpg "Průměr [Babbie 1995]")
17
Střední hodnoty a jejich limity
Střední hodnota → popis rozložení hodnot znaku „pomocí jednoho „typického“ čísla“ – těžiště uspořádání hodnot znaku To má pochopitelně limity: - jedno číslo většinou nestačí (málokdy mají všechny případy přibližně stejnou hodnotu) - neříká nic o variabilitě – rozptýlení dat - moc se nehodí pro kategoriální znaky (místo modusu ukazujeme raději celou distribuci v %) Proto je vždy používáme zároveň s údaji o variabilitě, rozptylu → “kvalitativní“ informace
 - neříká nic o variabilitě – rozptýlení dat. - moc se nehodí pro kategoriální znaky (místo modusu ukazujeme raději celou distribuci v %) Proto je vždy používáme zároveň s údaji o variabilitě, rozptylu → kvalitativní informace.")
18
Charakteristiky variability → „Kvalitativní“ charakteristiky středních hodnot
Rozptyl = střední hodnota kvadrátů odchylek od střední hodnoty Směrodatná odchylka = odmocnina z rozptylu náhodné veličiny (na rozdíl od rozptylu je v původních jednotkách proměnné) Výběrová směrodatná odchylka (dtto ale ve výběrovém souboru → malinká úprava ve vzorci, logicky jde o odmocninu z výběrového rozptylu)
 Výběrová směrodatná odchylka (dtto ale ve výběrovém souboru → malinká úprava ve vzorci, logicky jde o odmocninu z výběrového rozptylu)")
19
Charakteristiky variability kardinálních znaků: Rozptyl a Směrodatná odchylka
Udávají koncentraci nebo rozptýlení kolem střední hodnoty. Ukazují na „kvalitu“ průměru. Rozptyl (σ2) = součet kvadratických odchylek od průměru dělený rozsahem výběru (pokud jde o výběrový soubor tak navíc zmenšeným o 1) (anglicky Variance) Směrodatná odchylka (σ) = odmocnina z rozptylu (anglicky Standard Deviation – STDDEV) Směrodatná odchylka je míra rozptýlení hodnot od průměrné (střední) hodnoty vyjádřená v původních hodnotách, v nichž proměnnou měříme (např. u věku v letech). Naproti tomu samotný rozptyl je bezrozměrný a špatně se tak interpretuje. Existují také míry variability pro kategoriální (nominální) znaky, viz dále.
 = součet kvadratických odchylek od průměru dělený rozsahem výběru (pokud jde o výběrový soubor tak navíc zmenšeným o 1) (anglicky Variance) Směrodatná odchylka (σ) = odmocnina z rozptylu (anglicky Standard Deviation – STDDEV) Směrodatná odchylka je míra rozptýlení hodnot od průměrné (střední) hodnoty vyjádřená v původních hodnotách, v nichž proměnnou měříme (např. u věku v letech). Naproti tomu samotný rozptyl je bezrozměrný a špatně se tak interpretuje. Existují také míry variability pro kategoriální (nominální) znaky, viz dále.")
20
Výpočet směrodatné odchylky
pozorování: 2 5 4 3 1 8 6 7 odchylky od prům.: -2 -1 -3 čtverce odchylek 9 16 Máme pozorování: součet řady = 40; počet případů n = 10; průměr = 40/10 = 4 odchylky od průměru (X=4): (součet odchylek je 9 – 9 = 0) čtverce odchylek: součet čtverců odchylek = 52 průměrná čtvercová odchylka tj. rozptyl σ2= 52/10= 5,2 směrodatná odchylka (odmocnina z rozptylu) s = 2,28 Existují dva vzorečky: pro populační směrodatnou odchylku (zde – pro celou populaci) a pro výběrovou, tj. jen pro vzorek z populace, v níž je ve jmenovateli místo „n „n-1“.
: (součet odchylek je 9 – 9 = 0) čtverce odchylek: součet čtverců odchylek = 52. průměrná čtvercová odchylka tj. rozptyl σ2= 52/10= 5,2. směrodatná odchylka (odmocnina z rozptylu) s = 2,28. Existují dva vzorečky: pro populační směrodatnou odchylku (zde – pro celou populaci) a pro výběrovou, tj. jen pro vzorek z populace, v níž je ve jmenovateli místo „n „n-1 .")
21
Výpočet směrodatné odchylky
Obdobné jako předchozí příklad, ale vynechali jsme jedno – poslední pozorování (n=9). Příklad 2. Máme pozorování: Součet řady = 33; n = 9; průměr = 33/9 = 3,66 odchylky od průměru: -1,66 1,34 0,34 -0,66 -2,66 4, ,66 2,34 -1,66 součet odchylek je = 0 čtverce odchylek: 2,76; 1,80; 0,12; 0,44; 7,08; 18,84; 2,76; 5,48; 2,76 součet čtverců odchylek = 42,04 průměrná čtvercová odchylka tj. rozptyl = 42,04 /9= 4,67 směrodatná odchylka (odmocnina z rozptylu) = 2,16
. Příklad 2. Máme pozorování: Součet řady = 33; n = 9; průměr = 33/9 = 3,66. odchylky od průměru: -1,66 1,34 0,34 -0,66 -2,66 4,34 -1,66 2,34 -1,66. součet odchylek je = 0. čtverce odchylek: 2,76; 1,80; 0,12; 0,44; 7,08; 18,84; 2,76; 5,48; 2,76. součet čtverců odchylek = 42,04. průměrná čtvercová odchylka tj. rozptyl = 42,04 /9= 4,67. směrodatná odchylka (odmocnina z rozptylu) = 2,16.")
22
Příklad k procvičení DATA: Věk AKD1 LS 2012 Porovnejte střední hodnoty (průměr, medián) a směrodatnou odchylku u skupin studentů z Denního a Kombinovaného studia Denní 23 25 24 22 Kombinované 33 30 48 25 31 46 49 38 26 28

23
Směrodatná odchylka v Excelu
STDEVPA pro základní soubor STDEVA pro výběrový soubor V SPSS je výpočet pro výběrovou směrodatnou odchylku StD (tj. pro vzorek z populace).
.")
24
Další popisné statistiky - variabilita
Pro kardinální (číselné) proměnné Minimum / maximum Rozpětí (= max - min) Kvantily: dolní a horní kvartil → mezikvartilové rozpětí (jsou ale jiné členění do stejně početně zastoupených skupin, např. tercily (33 % / 33 % / 33 %), decily (10 % / 10 % …) Koeficienty šikmosti (Skewness) Koeficienty špičatosti (Kurtosis) Variační koeficient (= podíl směr.odchylky a průměru) Pro kategoriální proměnné míry variability (variační koeficient a jeho varianty) – viz AKD II. 9. Míry variability: variační koeficient a další indexy
 proměnné. Minimum / maximum. Rozpětí (= max - min) Kvantily: dolní a horní kvartil → mezikvartilové rozpětí (jsou ale jiné členění do stejně početně zastoupených skupin, např. tercily (33 % / 33 % / 33 %), decily (10 % / 10 % …) Koeficienty šikmosti (Skewness) Koeficienty špičatosti (Kurtosis) Variační koeficient (= podíl směr.odchylky a průměru) Pro kategoriální proměnné. míry variability (variační koeficient a jeho varianty) – viz AKD II. 9. Míry variability: variační koeficient a další indexy")
25
Různé typy proměnných a odpovídající popisné statistiky (střední hodnoty, míry variability, grafy, …) Zdroj: [Rachad 2003: 81].

26
Střední hodnoty a míry variability v SPSS
K dispozici máme více možností, např. pomocí příkazů: FREQUENCIES, MEANS, DESCRIPTIVES a EXAMINE. FREQUENCIES vek /STATISTICS MEAN STDDEV MEDIAN MODE. *průměr, směrodatná odchylka, medián a Modus (tabulku frekvencí lze vypnout pomocí přidání /FORMAT NOTABLE.). MEANS vek /CELLS MEAN STDDEV MEDIAN COUNT. *průměr, směrodatná odchylka, medián a počet případů. DESCRIPTIVES vek. *průměr, směrodatná odchylka, počet případů; vhodné pro porovnání hodnot u více proměnných. EXAMINE vek /PLOT NONE. *velké množství statistik pro střední hodnoty a variabilitu, zde bez grafů.
. MEANS vek /CELLS MEAN STDDEV MEDIAN COUNT. *průměr, směrodatná odchylka, medián a počet případů. DESCRIPTIVES vek. *průměr, směrodatná odchylka, počet případů; vhodné pro porovnání hodnot u více proměnných. EXAMINE vek /PLOT NONE. *velké množství statistik pro střední hodnoty a variabilitu, zde bez grafů.")
27
Střední hodnoty a míry variability v SPSS (output)
Frequencies Means Descriptives Explore

28
Směrodatná odchylka pro dichotomickou proměnnou (podíl)
Variance = p*q kde p (resp. q) je pravděpodobnost (tj. p = % / 100). Směrodatná odchylka = √p*q nebo √p(1-p) Příklad: p = 0,29 q = 0,71 StD = √0,29*0,71 = 0,45 Pokud máme hodnoty dichotomické proměnné kódovány jako 0/1 (např. 0=nepracuje, 1=pracuje), pak lze v SPSS použít např. Descriptives (vzorec není ale stejný – výsledek se může nepatrně lišit).
 je pravděpodobnost (tj. p = % / 100). Směrodatná odchylka = √p*q nebo √p(1-p) Příklad: p = 0,29 q = 0,71. StD = √0,29*0,71 = 0,45. Pokud máme hodnoty dichotomické proměnné kódovány jako 0/1 (např. 0=nepracuje, 1=pracuje), pak lze v SPSS použít např. Descriptives (vzorec není ale stejný – výsledek se může nepatrně lišit).")
29
Kvanitly Kvantily (obecně) → členění do stejně početně zastoupených skupin Tercily: tři skupiny (33 % / 33 % / 33 %) Decily: deset skupin (10 % / 10 % …) Kvartily: čtyři skupiny (25 % / 25 % / 25 % / 25 %) → mezikvartilové rozpětí: rozdíl horního a dolního kvartilu (x75 – x25) Zobrazujeme je (spolu s mediánem) v Boxplotu → jejich poloha ukáže na zešikmení (čím blíže je H nebo D kvartil k mediánu, tím větší zešikmení) Určení kvantilů v SPSS pomocí NTILES: FREQUENCIES vek /NTILES (4). *číslo v závorce určuje, pro kolik stejných skupin chceme určit hranice hodnot (na jejich základě můžeme dále rekódovat kardinální-spojitý znak na ordinální-kategoriální).
 Kvartily: čtyři skupiny (25 % / 25 % / 25 % / 25 %) → mezikvartilové rozpětí: rozdíl horního a dolního kvartilu (x75 – x25) Zobrazujeme je (spolu s mediánem) v Boxplotu → jejich poloha ukáže na zešikmení (čím blíže je H nebo D kvartil k mediánu, tím větší zešikmení) Určení kvantilů v SPSS pomocí NTILES: FREQUENCIES vek /NTILES (4). *číslo v závorce určuje, pro kolik stejných skupin chceme určit hranice hodnot (na jejich základě můžeme dále rekódovat kardinální-spojitý znak na ordinální-kategoriální).")
30
Boxplot – vousaté krabičky: vizualizace distribuce
KVARTILY dělí statistický soubor na desetiny: dolní Q0,25 (Q1) a horní Q0,denní5 (Q3) Interkvartilové rozpětí: HH = horní kvartil + 1,5 násobku interkvartilového rozpětí DH = dolní kvartil + 1,5 násobku interkvartilového rozpětí
 a horní Q0,denní5 (Q3) Interkvartilové rozpětí: HH = horní kvartil + 1,5 násobku interkvartilového rozpětí. DH = dolní kvartil + 1,5 násobku interkvartilového rozpětí.")
31
Variabilita hodnot u nominálního znaku
Na rozdíl od kardinálních-numerických znaků tvar rozložení nedává smysl (v histogramu), protože kategorie nemají žádný číselný - hierarchický význam. (u ordinálních znaků tvar rozložení ovšem určitou informaci podává). Variabilita znaku je dána rozptýleností / koncentrací podílů (%) v jednotlivých kategoriích (nulová je tehdy jsou-li kategorie % stejně zastoupené).
, protože kategorie nemají žádný číselný - hierarchický význam. (u ordinálních znaků tvar rozložení ovšem určitou informaci podává). Variabilita znaku je dána rozptýleností / koncentrací podílů (%) v jednotlivých kategoriích (nulová je tehdy jsou-li kategorie % stejně zastoupené).")
32
Míry variability pro kategoriální proměnné poněkud složitější situace (než u kardinálních znaků)
Nominální proměnné: Variační poměr – v Nominální rozptyl – D (nomvar) (Giniho koeficient) → relativní počet všech dvojic, které nejsou ve stejné kategorii Normalizovaný nominální rozptyl (norm. nomvar nebo IQV) Entropie – H normalizovaná entropie – H* Ordinální proměnné: Ordinální rozptyl - dorvar Variační koeficient a jeho varianty – viz AKD II. 9. Míry variability: variační koeficient a další indexy Viz také
 (Giniho koeficient) → relativní počet všech dvojic, které nejsou ve stejné kategorii. Normalizovaný nominální rozptyl (norm. nomvar nebo IQV) Entropie – H. normalizovaná entropie – H* Ordinální proměnné: Ordinální rozptyl - dorvar. Variační koeficient a jeho varianty – viz AKD II. 9. Míry variability: variační koeficient a další indexy Viz také")
33
Vlastnosti měr variability kategoriálních znaků
Čím vyšší hodnota tím vyšší heterogenita souboru Jsou rovny nule, když je celý soubor soustředěn do jedné kategorie (nulové rozptýlení) → úplná homogenita Maximální hodnota = rovnoměrné rozložení dat (kategorií) → úplná heterogenita Ukazují do jaké míry, jsou data koncentrována kolem své charakteristické hodnoty (→ modální kategorie), tj. jak moc je tato hodnota typická pro celý soubor. Zdroj: [Řehák, Řeháková 1986: 66-69]
 → úplná homogenita. Maximální hodnota = rovnoměrné rozložení dat (kategorií) → úplná heterogenita. Ukazují do jaké míry, jsou data koncentrována kolem své charakteristické hodnoty (→ modální kategorie), tj. jak moc je tato hodnota typická pro celý soubor. Zdroj: [Řehák, Řeháková 1986: 66-69]")
34
Variační poměr – v Nejjednodušší míra variability.
Pokud je více modálních kategorií uvažujeme nejvyšší četnost pouze jednou. Výhodou v je jednoduchost výpočtu. Nevýhodou v je, že je založeno pouze na modální četnosti (normvar – D je pracnější,ale odráží celou strukturu tabulky). Zdroj: [Řehák, Řeháková 1986: 66]
. Zdroj: [Řehák, Řeháková 1986: 66]")
35
Příklad: Variační poměr – v (DATA)
[Řehák, Řeháková 1986: 68-70; Agresti, Agresti 1978]

36
Příklad: Variační poměr – v
Způsob získávání denního tisku u pravidelných čtenářů, pro Periodikum J (N = 1289) Předplácí Kupuje K disp. v práci Půjčuje si Získává jinak Celkem N % z celku 48,3% 24,1% 6,9% 16,4% 43,0% 100 116 8,9 lze spočítat v Excelu: v = 1 – (56,028 / 116) = 0,517 V může sloužit k porovnání variability rozložení několika znaků (např. zde různých periodik) nebo podskupin v třídění 2.stupně (podobně jako Směrod.odchylka u kardinálních znaků). Zde způsoby získávání u různých periodik: např. periodikum J (v=0,517) má dvojnásobný variační poměr než periodikum H (v=0,224), tj. způsoby jeho získávání jsou mnohem variabilnější (všimněte si, že u tiskoviny H představuje modus „Kupuje“ celých 77,6 %). Zdroj: [Řehák, Řeháková 1986: 68-69]
 Předplácí. Kupuje. K disp. v práci. Půjčuje si. Získává jinak. Celkem. N. % z celku. 48,3% 24,1% 6,9% 16,4% 43,0% ,9. lze spočítat v Excelu: v = 1 – (56,028 / 116) = 0,517. V může sloužit k porovnání variability rozložení několika znaků (např. zde různých periodik) nebo podskupin v třídění 2.stupně (podobně jako Směrod.odchylka u kardinálních znaků). Zde způsoby získávání u různých periodik: např. periodikum J (v=0,517) má dvojnásobný variační poměr než periodikum H (v=0,224), tj. způsoby jeho získávání jsou mnohem variabilnější (všimněte si, že u tiskoviny H představuje modus „Kupuje celých 77,6 %). Zdroj: [Řehák, Řeháková 1986: 68-69]")
37
Nominální variance (nomvar) Index diversity (D)
nomvar nebo D Kde: p – podíl pozorování v dané i-té kategorii → podíl všech dvojic jednotek, které nemají stejnou hodnotu znaku nebo také → pravděpodobnost, že dva náhodně vybraní jedinci z populace budou patřit do rozdílných kategorií. Index je tím vyšší, čím více je kategorií a čím více jsou pozorování rozptýlena rovnoměrně v těchto kategoriích. [Řehák, Řeháková 1986: 68-70; Agresti, Agresti 1978]

38
Více k varianci kategoriálních znaků v AKD II. http://metodykv. wz
SPSS míry variability pro kategoriální proměnné neumí, ale na již hotovou tabulku (FREQUENCIES) lze v outputu použít skript Míry variability pro kategorizované proměnné
 lze v outputu použít skript Míry variability pro kategorizované proměnné.")
39
Vlastnosti rozdělení znaků
popisná statistka pro kardinální znaky v grafickém znázornění

40
Symetrie, variabilita Vlastnosti rozložení hodnot znaku, jsou dány střední hodnotou (průměrem) a rozptylem hodnot [Hanousek, Charamza 1992: 21]

41
Šikmost a špičatost → odchylky od symetrie (šikmost) a variability (špičatost/plochost) [Hanousek, Charamza 1992: 21]
![Šikmost a špičatost → odchylky od symetrie (šikmost) a variability (špičatost/plochost) [Hanousek, Charamza 1992: 21]](http://slideplayer.cz/slide/2785825/10/images/41/%C5%A0ikmost+a+%C5%A1pi%C4%8Datost+%E2%86%92+odchylky+od+symetrie+%28%C5%A1ikmost%29+a+variability+%28%C5%A1pi%C4%8Datost%2Fplochost%29+%5BHanousek%2C+Charamza+1992%3A+21%5D.jpg "Šikmost a špičatost → odchylky od symetrie (šikmost) a variability (špičatost/plochost) [Hanousek, Charamza 1992: 21]")
42
Normální rozložení hodnot a směrodatná odchylka
Rozložení hodnot (tvar křivky) je dán průměrem a rozptylem. Zde jde o normované (standardizované) normální rozdělení, kde μ=0 a σ=1 Platí, že v ploše pod křivkou vymezené +/- 1 směrodatnou odchylkou od průměru je 68 % případů (cca 2/3). Jde o teoretické rozložení hodnot, v praxi vždy dochází k nějaké odchylce od tohoto normálního rozložení. Pro většinu analýz kardinálních znaků (např. průměr nebo korelace) potřebujeme, aby se rozložení proměnných co nejméně odchylovalo od tohoto tvaru (gaussovy křivky).
 je dán průměrem a rozptylem. Zde jde o normované (standardizované) normální rozdělení, kde μ=0 a σ=1. Platí, že v ploše pod křivkou vymezené +/- 1 směrodatnou odchylkou od průměru je 68 % případů (cca 2/3). Jde o teoretické rozložení hodnot, v praxi vždy dochází k nějaké odchylce od tohoto normálního rozložení. Pro většinu analýz kardinálních znaků (např. průměr nebo korelace) potřebujeme, aby se rozložení proměnných co nejméně odchylovalo od tohoto tvaru (gaussovy křivky).")
43
A k čemu variabilita dat (směrodatná odchylka) je?
Směrodatná odchylka ukazuje na to, jak „kvalitně“ popisuje průměr data. (nulová STDEV = všechny případy mají stejnou hodnotu, tj. průměr) → uvádíme-li průměr, tak vždy uvedeme i směrodatnou odchylku (StDev) Distribuci hodnot – varianci v datech musíme věcně interpretovat (StdDev, míry šikmosti, percentily, …). Před výpočty u numerické proměnné (korelace, průměr, …) ověřujeme rozložení hodnot, zda se (výrazněji) nevychyluje od normálního rozložení. A pro výběrová data, tj. náhodný(!) vzorek z populace platí: normální rozdělení je vlastně zákonem chyb měření (a to i těch o nichž nevíme, tj. přímo jsme je neměřili). A na tom jsou postaveny principy inferenční statistiky (testování hypotéz) Směrodatná odchylka slouží k výpočtu Standardní chyby (S.E.) → kvantifikace chyb měření
 → uvádíme-li průměr, tak vždy uvedeme i směrodatnou odchylku (StDev) Distribuci hodnot – varianci v datech musíme věcně interpretovat (StdDev, míry šikmosti, percentily, …). Před výpočty u numerické proměnné (korelace, průměr, …) ověřujeme rozložení hodnot, zda se (výrazněji) nevychyluje od normálního rozložení. A pro výběrová data, tj. náhodný(!) vzorek z populace platí: normální rozdělení je vlastně zákonem chyb měření (a to i těch o nichž nevíme, tj. přímo jsme je neměřili). A na tom jsou postaveny principy inferenční statistiky (testování hypotéz) Směrodatná odchylka slouží k výpočtu Standardní chyby (S.E.) → kvantifikace chyb měření.")
44
Ověření normality rozložení dat
Histogram → vizuálně orientačně Podrobněji a přesněji: Q-Q graf (quantile-quantile): ukazuje kvantily pozorované distribuce proměnné proti kvantilů zvolené distribuční funkce Normálně rozložená data → přímkový charakter v SPSS: Analyze, Descriptive statistics, Q-Q plots Kolmogorov-Smirnov test: H0 = data jsou normálně rozložena, Pozor na interpretaci výsledku: nízké! p (< 0,05) → distribuce dat se statisticky signifikantně lišší od normální distribuce. v SPSS: Analyze, Nonparametric Tests, 1-Sample K-S... Dojde-li k porušení normality rozložení → rekódování, transformace (např. logaritmická), použití neparametrických metod
: ukazuje kvantily pozorované distribuce proměnné proti kvantilů zvolené distribuční funkce. Normálně rozložená data → přímkový charakter. v SPSS: Analyze, Descriptive statistics, Q-Q plots. Kolmogorov-Smirnov test: H0 = data jsou normálně rozložena, Pozor na interpretaci výsledku: nízké! p (< 0,05) → distribuce dat se statisticky signifikantně lišší od normální distribuce. v SPSS: Analyze, Nonparametric Tests, 1-Sample K-S... Dojde-li k porušení normality rozložení → rekódování, transformace (např. logaritmická), použití neparametrických metod.")
45
Rozložení četností a Q-Q graf

46
Na co si dát v datech pozor
Variance a střední hodnoty

47
Vzájemná poloha průměru a mediánu

48
Průměr a rozptyl nejsou všechno!
Ve všech třech případech stejné: maximum 170 průměr 85 směrodatná odchylka 25,8 Výsledek testu (interval hodnot) případ 1 případ 2 případ 3 případ 4 20-29 1 - 30-39 4 2 40-49 6 5 12 50-59 8 10 34 60-69 16 70-79 17 80-89 18 90-99 7 3 šikmost 0,00 0,57 špičatost -0,43 0,18 -1,23 -1,77 Zdroj: [Hanousek, Charamza 1992: 38-39]
 případ 1. případ 2. případ 3. případ šikmost. 0,00. 0,57. špičatost. -0,43. 0,18. -1,23. -1,77. Zdroj: [Hanousek, Charamza 1992: 38-39]")
49
Variabilita rozložení hodnot - doporučení
kardinální znaky Průměr a směrodatná odchylka nestačí, uvádějte ještě alespoň medián Grafické znázornění variability → Histogram (případně boxplot) Pokud chceme variabilitu popsat čísly: Koeficienty šikmosti (Skewness) a špičatosti (Kurtosis) nebo mezikvartilové rozpětí (rozdíl horního a dolního kvartilu) kategoriální (nominální) znaky Tabulka frekvencí (s %) nebo graficky → Barchart
 Pokud chceme variabilitu popsat čísly: Koeficienty šikmosti (Skewness) a špičatosti (Kurtosis) nebo mezikvartilové rozpětí (rozdíl horního a dolního kvartilu) kategoriální (nominální) znaky. Tabulka frekvencí (s %) nebo graficky → Barchart.")
50
Standardizace na z-skóre odstranění původní metriky u kardinálních-číselných znaků
Z – skóry: průměr X=0 a StD =1 V transformované proměnné je aritmetický průměr roven nule a směrodatná odchylka je jedna. Odchylka od průměru / směrodatnou odchylkou: Od každého pozorování odečteme průměr a vydělíme směrodatnou odchylkou. z-skóre = kolik standardních odchylek je danná hodnota vzdálena od střední hodnoty (aritmetického průměru) Většina nově transformovaných hodnot je v rozmezí od -3 do 3. → umožňuje porovnat znaky s odlišnou metrikou.
 Většina nově transformovaných hodnot je v rozmezí od -3 do 3. → umožňuje porovnat znaky s odlišnou metrikou.")
51
Standardizace na z-skóre
V SPSS jednoduše pomocí Descriptives přidáním SAVE: DESCRIPTIVES var1 /SAVE. V datech vznikne proměnná automaticky pojmenovaná Zvar1 (v Labelu je uvedeno „Zscore:“ a původní pojmenování) Pozor: Proměnná musí mít přibližně normální rozložení! (kontrolujeme aspoň vizuálně pomocí Histogramu) Pokud ne, pak lze transformovat na percentily. Existují i jiné principy standardizace dat, např. přímá standardizace.
 Pozor: Proměnná musí mít přibližně normální rozložení! (kontrolujeme aspoň vizuálně pomocí Histogramu) Pokud ne, pak lze transformovat na percentily. Existují i jiné principy standardizace dat, např. přímá standardizace.")
52
Webové nástroje pro analýzu
Index of On-line Stats Calculators Exact r×c Contingency Table: Statistical Calculations R. Webster West applets Učebnice: Interstat - hypertextová interaktivní učebnice statistiky pro ekonomy Statnotes: Topics in Multivariate Analysis, by G. David Garson StatSoft - Elektronická učebnice statistiky (anglicky)
 pg=navigace&nav=31")
53
Nejprve se ptej, k čemu analýza tvá má sloužit, potom teprv výběrem metody dej se soužit.
[Hanousek, Charamza 1992 : 61]

54
Literatura Babbie, E. (1995). The Practice of social Research. 7th Edition. Belmont: Wadsworth. (kapitola 15 – Elementary Analyses). Hanousek, Charamza Moderní metody zpracování dat. Matematická statistika pro každého. Praha: Grada. Řehák, J., B. Řeháková Analýza kategorizovaných dat v sociologii. Praha: Academia.

Podobné prezentace








seznam.cz>")






>")



