Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Cvičebnice statistiky
Projekt Zdravotnické studijní programy v inovaci na FZS Univerzity Pardubice CZ.1.07/2.2.00/ Cvičebnice statistiky Cíl: procvičit statistické zpracování dat na modelových příkladech, za použití statistického programu IBM SPSS Statistics (verze 19) Září 2012
 Září")
2
Předpokládá se, že student již rozumí základním principům statistického zpracování dat i používané terminologii. Student by měl již chápat, že základní otázkou statistické indukce je získání určitých závěrů o populaci na základě výsledků zjištěných na náhodném výběru z populace. Statistická indukce v sobě zahrnuje riziko omylu. Přitom se zabýváme testováním hypotéz (hypotézy nulové a alternativní). Student by již měl tomuto procesu rozumět, měl by chápat termíny jako je hladina významnosti, jednostranný / dvoustranný test atd. Je vhodné si výše zmíněné postupy a příslušnou terminologii zopakovat, protože tato cvičebnice se již zabývá pouze procvičováním testování statistických hypotéz na základě vybraných druhů testů (jejichž výběr je podmíněn popsanou situací, která je analyzována). V českém jazyce sice neexistují materiály specializující se na principy statistiky v ošetřovatelství, ale je možno vycházet z příbuzných disciplín (společenských věd, medicíny), např. z materiálu Škaloudové, viz Zdroje použité k tvorbě této cvičebnice jsou uvedené na jejím konci. Cvičebnice obsahuje příklady k procvičování, ty doprovázejí i zdrojová data v programu Microsoft Excel – student je může snadno zkopírovat do SPSS.
. V českém jazyce sice neexistují materiály specializující se na principy statistiky. v ošetřovatelství, ale je možno vycházet z příbuzných disciplín (společenských věd, medicíny), např. z materiálu Škaloudové, viz Zdroje použité k tvorbě této cvičebnice jsou uvedené na jejím konci. Cvičebnice obsahuje příklady k procvičování, ty doprovázejí i zdrojová data v programu Microsoft Excel – student je může snadno zkopírovat do SPSS.")
3
Obsah: Typy veličin………………………………………………………………………………………………………… slide 4 Příklad 1 (porovnání 2 typů intervence u 2 skupin, Mann Whitney U Test)…………. slide 5–46 Příklad 2 (porovnání 2 typů intervence u 2 skupin, Dvouvýběrový T-Test)………….. slide 47–60 Procvičování – příklad 1 („matky novorozenců“)………………………………………… slide 61–72 Procvičování – příklad 2 („analgesie sestrou versus analgesie řízená pacientem“) slide 73–82 Příklad 3 (porovnání skupiny před a po intervenci, Wilcoxon Signed Rank Test)….. slide 83–94 Příklad 4 (porovnání skupiny před a po interenci, párový T-test)………………………… slide 95–108 Procvičování – příklad 3 („hmotnost před a po rehabilitačním programu“)…….. slide 109–121 Procvičování – příklad 4 („bolest po masáži versus po medikaci“)…………………….. slide 122–141 Příklad 5 – korelace škál (dichotomizovaných výsledků, korelační koeficient phi)… slide 142–152 Příklad 6 – korelace škál (skutečných skóre, Spearmanův korelační koeficient)……. slide 153–160 Procvičování – příklad 5 („výška“ versus „skok daleký“)………………………………………. slide 161–172 Použité zdroje…………………………………………………………………………………………………….. slide 173
…………. slide 5–46. Příklad 2 (porovnání 2 typů intervence u 2 skupin, Dvouvýběrový T-Test)………….. slide 47–60. Procvičování – příklad 1 („matky novorozenců )………………………………………… slide 61–72. Procvičování – příklad 2 („analgesie sestrou versus analgesie řízená pacientem ) slide 73–82. Příklad 3 (porovnání skupiny před a po intervenci, Wilcoxon Signed Rank Test)….. slide 83–94. Příklad 4 (porovnání skupiny před a po interenci, párový T-test)………………………… slide 95–108. Procvičování – příklad 3 („hmotnost před a po rehabilitačním programu )…….. slide 109–121. Procvičování – příklad 4 („bolest po masáži versus po medikaci )…………………….. slide 122–141. Příklad 5 – korelace škál (dichotomizovaných výsledků, korelační koeficient phi)… slide 142–152. Příklad 6 – korelace škál (skutečných skóre, Spearmanův korelační koeficient)……. slide 153–160. Procvičování – příklad 5 („výška versus „skok daleký )………………………………………. slide 161–172. Použité zdroje…………………………………………………………………………………………………….. slide 173.")
4
V tento moment si alespoň zopakujme typy veličin:
Kvalitativní: a) Nominální – pohlaví, oddělení (číselné kódy pouze slouží k označení jednotlivých kategorií, např. 1 = muž; 2 = žena) b) Ordinální – např. školní klasifikace (výborně = 1, chvalitebně = 2 atd.), stupeň souhlasu…dají se seřadit, lze se ptát „nižší“, „vyšší“, ale ne, o kolik. Nominální a ordinální proměnné souhrnně označujeme za kvalitativní. Nemá smysl u nich zkoumat aritmetický průměr číselných kódů hodnot. Kvantitativní (kardinální): c) Intervalové (rozdílové) – mají vlastnost ordinálního měřítka (škály) a navíc lze stanovit vzdálenost mezi hodnotami určitou jednotkou měření. Přitom 0 neznamená „nic“ (nepřítomnost hodnoty). Příklad: teplota ve stupních Celsia. Lze se ptát „menší“, „větší“ a o kolik. Měření je relativní, ne absolutní. d) Poměrová (podílová) – má všechny znaky nominální, ordinální, intervalové, navíc existuje absolutní nula a lze vypočítat podíl mezi hodnotami. Neexistují záporné hodnoty. Příklad: Teplota ve stupních Kelvina; počet obyvatel města; počet dětí v rodině, kolik edukačních lekcí se pacient zúčastnil či kolik bodů získal v testu (1, 2, 3, ……..); tělesná hmotnost, atd. (počet obyvatel města je diskrétní proměnná a může nabývat jen celých čísel; tělesná hmotnost je příklad spojité proměnné). Nominální, ordinální a kvantitativní diskrétní proměnné = kategoriální. Zdroj: UK Praha, Pedagogická fakulta, SPSS nerozlišuje mezi intervalovými a poměrovými úrovněmi měření – v obou případech je označujeme jako „scale“ (škála). Nominální úroveň měření označujeme „nominal“ a ordinální „ordinal“.
 Nominální – pohlaví, oddělení (číselné kódy pouze slouží k označení jednotlivých kategorií, např. 1 = muž; 2 = žena) b) Ordinální – např. školní klasifikace (výborně = 1, chvalitebně = 2 atd.), stupeň souhlasu…dají se seřadit, lze se ptát „nižší , „vyšší , ale ne, o kolik. Nominální a ordinální proměnné souhrnně označujeme za kvalitativní. Nemá smysl u nich zkoumat aritmetický průměr číselných kódů hodnot. Kvantitativní (kardinální): c) Intervalové (rozdílové) – mají vlastnost ordinálního měřítka (škály) a navíc lze stanovit vzdálenost mezi hodnotami určitou jednotkou měření. Přitom 0 neznamená „nic (nepřítomnost hodnoty). Příklad: teplota ve stupních Celsia. Lze se ptát „menší , „větší a o kolik. Měření je relativní, ne absolutní. d) Poměrová (podílová) – má všechny znaky nominální, ordinální, intervalové, navíc existuje absolutní nula a lze vypočítat podíl mezi hodnotami. Neexistují záporné hodnoty. Příklad: Teplota ve stupních Kelvina; počet obyvatel města; počet dětí v rodině, kolik edukačních lekcí se pacient zúčastnil či kolik bodů získal v testu (1, 2, 3, ……..); tělesná hmotnost, atd. (počet obyvatel města je diskrétní proměnná a může nabývat jen celých čísel; tělesná hmotnost je příklad spojité proměnné). Nominální, ordinální a kvantitativní diskrétní proměnné = kategoriální. Zdroj: UK Praha, Pedagogická fakulta, kap=6. SPSS nerozlišuje mezi intervalovými a poměrovými úrovněmi měření – v obou případech je označujeme jako „scale (škála). Nominální úroveň měření označujeme „nominal a ordinální „ordinal .")
5
Příklad 1. Chceme zjistit, která metoda edukace je účinnější – zda: využití samostudijního materiálu nebo videa s procvičováním dovedností. Studenty rozdělíme do dvou skupin – jedna skupina bude edukována pouze metodou a) a druhá pouze metodou b). Po absolvování edukace budou všichni studenti testováni stejným typem testu (post-testu). Před statistickým zpracováním dat si stanovíme testovatelnou hypotézu. Např.: Ho: Mezi skupinami studentů nebude ve výkonu na post-testu statisticky významný rozdíl (tedy, obě metody edukace se jeví jako stejně efektivní). Ha: Mezi skupinami studentů bude ve výkonu na post-testu statisticky významný rozdíl (tedy, jedna metoda edukace se jeví jako více efektivní). Praktická významnost: Je důležité si předem stanovit, co je pro nás prakticky významné. Je možné, že např. nepatrný rozdíl ve výkonu na post-testu je statisticky významný. Nemusí to ale mít žádný praktický význam, pokud v jedné skupině studenti získají např. 80 % a ve skupině druhé 82 %. Tím pak i statisticky významný výsledek nemusí být příliš užitečný při rozhodování, kterou metodu edukace budeme aplikovat do praxe – je možné, že jiné faktory pro nás v ten moment budou důležitější (finanční náklady, „pracnost“ edukační metody, atd.).
 a druhá pouze metodou b). Po absolvování edukace budou všichni studenti testováni stejným typem testu (post-testu). Před statistickým zpracováním dat si stanovíme testovatelnou hypotézu. Např.: Ho: Mezi skupinami studentů nebude ve výkonu na post-testu statisticky významný rozdíl (tedy, obě metody edukace se jeví jako stejně efektivní). Ha: Mezi skupinami studentů bude ve výkonu na post-testu statisticky významný rozdíl (tedy, jedna metoda edukace se jeví jako více efektivní). Praktická významnost: Je důležité si předem stanovit, co je pro nás prakticky významné. Je možné, že např. nepatrný rozdíl ve výkonu na post-testu je statisticky významný. Nemusí to ale mít žádný praktický význam, pokud v jedné skupině studenti získají např. 80 % a ve skupině druhé 82 %. Tím pak i statisticky významný výsledek nemusí být příliš užitečný při rozhodování, kterou metodu edukace budeme aplikovat do praxe – je možné, že jiné faktory pro nás v ten moment budou důležitější (finanční náklady, „pracnost edukační metody, atd.).")
6
Výše stanovené hypotézy jsou spojeny s následující výzkumnou otázkou:
Bude mezi skupinami studentů ve výkonu na post-testu statisticky významný rozdíl (tedy, bude se jedna z metod edukace jevit jako efektivnější)? Pro výpočet můžeme použít např. program Microsoft Excel, při výpočtu zjišťovat hodnotu testové statistiky za pomoci vzorců, tu pak porovnávat s kritickou hodnotou (nalezneme v tabulkách, často v přílohách knih pojednávajících o statistice). Velmi populární jsou ale i statistické programy. Jednak umožňují velmi rychlé zpracování dat (i grafické), dále např. poskytnou informace o konfidenčních intervalech (intervalech spolehlivosti). Následuje zpracování výše uvedeného Příkladu 1 ve statistickém programu IBM SPSS, verze 19.
 Pro výpočet můžeme použít např. program Microsoft Excel, při výpočtu zjišťovat hodnotu testové statistiky za pomoci vzorců, tu pak porovnávat s kritickou hodnotou (nalezneme v tabulkách, často v přílohách knih pojednávajících o statistice). Velmi populární jsou ale i statistické programy. Jednak umožňují velmi rychlé zpracování dat (i grafické), dále např. poskytnou informace o konfidenčních intervalech (intervalech spolehlivosti). Následuje zpracování výše uvedeného Příkladu 1 ve statistickém programu IBM SPSS, verze 19.")
7
Otevřeme nový (prázdný) soubor.
Pokud máme před sebou „Data view“, klikneme na „Variable view“ (bude oranžové). (pozn.: variable = proměnná; view = zobrazení)
. (pozn.: variable = proměnná; view = zobrazení)")
8
Začneme vpisovat informace týkající se jednotlivých proměnných, např
Začneme vpisovat informace týkající se jednotlivých proměnných, např. budeme chtít definovat sloupec „číslo respondenta“. (Name = jméno; musí začít písmenem, může obsahovat až 8 znaků, včetně písmen, čísel a _) Jedná se o tzv. „String“ typ proměnné, tzn., že sice může obsahovat čísla, ale nejsou u ní povoleny matematické operace, jako je výpočet aritmetického průměru, směrodatné odchylky, atd. Typ je defaultně nastaven na „Numeric“, je nutno jej změnit na „String“ (viz další 2 slidy) (pozn.: string = řada, série, řetězec)
 Jedná se o tzv. „String typ proměnné, tzn., že sice může obsahovat čísla, ale nejsou u ní povoleny matematické operace, jako je výpočet aritmetického průměru, směrodatné odchylky, atd. Typ je defaultně nastaven na „Numeric , je nutno jej změnit na „String (viz další 2 slidy) (pozn.: string = řada, série, řetězec)")
9
Klikneme na buňku, kde je napsáno „Numeric“, vpravo se objeví rámeček se třemi tečkami (…), na něj klikneme a rozbalí se nový rámeček pro změnu typu proměnné na „String“ (viz další slide)
, na něj klikneme a rozbalí se nový rámeček pro změnu typu proměnné na „String (viz další slide)")
10
Po kliknutí na typu proměnné - „String“ – klikneme OK

11
Dále definujeme, že úroveň měření bude ordinální

12
Na druhý řádek vepíšeme „typ_edukace“, bude se jednat o stejný typ proměnné („String“), avšak budeme chtít označit, jakých hodnot typ edukace může nabývat, proto věnujeme pozornost sloupci „Values“ (hodnoty) – po kliknutí do buňky se objeví rámeček se třemi tečkami, po jeho zakliknutí se rozbalí další rámeček, nazvaný „Value labels“ - další postup viz další slide
, avšak budeme chtít označit, jakých hodnot typ edukace může nabývat, proto věnujeme pozornost sloupci „Values (hodnoty) – po kliknutí do buňky se objeví rámeček se třemi tečkami, po jeho zakliknutí se rozbalí další rámeček, nazvaný „Value labels - další postup viz další slide")
13
Zvolíme, že typ edukace bude nabývat hodnoty „1“ nebo „2“
Zvolíme, že typ edukace bude nabývat hodnoty „1“ nebo „2“. Jedná se o dichotomickou proměnnou (nabývá pouze dvou hodnot). Po vyplnění pole „Value“ a „Label“ klikneme na „Add“ a do velkého rámečku vpravo naskočí „1 = samostudijní materiál“). (pozn.: value = hodnota; add = přidat)
. Po vyplnění pole „Value a „Label klikneme na „Add a do velkého rámečku vpravo naskočí „1 = samostudijní materiál ). (pozn.: value = hodnota; add = přidat)")
14
Postup zopakujeme pro hodnotu 2, nakonec klikneme „Ok“.

15
Dokončíme řádek tak, že vybereme nominální úroveň měření.

16
Dokončíme řádek tak, že vybereme nominální úroveň měření.
Vepíšeme další položku, pro kterou potřebujeme vložit data – znalosti v post-testu (skóre). Jedná se o numerický typ proměnné, i když je diskrétní. Věnujeme pozornost definování chybějících dat („Missing values“) – po rozbalení příslušného rámečku nadefinujeme, že „99“ má být pokládáno za chybějící data (ne u všech respondentů bylo vždy získáno skóre, někteří test nemuseli psát – např. odmítli či nebyli přítomni). Je možno vybrat jinou hodnotu než „99“ – důležité je, aby se nejednalo o skutečné skóre, kterého by respondenti mohli dosáhnout. Definujeme „Measure“ – úroveň měření je „Scale“ (změníme, defaultně je uvedeno „Unknown“ Po dokončení překlikneme z „Variable view“ na „Data view“. (Pozn.: unknown = neznámá) Dokončíme řádek tak, že vybereme nominální úroveň měření.
. Jedná se o numerický typ proměnné, i když je diskrétní. Věnujeme pozornost definování chybějících dat („Missing values ) – po rozbalení příslušného rámečku nadefinujeme, že „99 má být pokládáno za chybějící data (ne u všech respondentů bylo vždy získáno skóre, někteří test nemuseli psát – např. odmítli či nebyli přítomni). Je možno vybrat jinou hodnotu než „99 – důležité je, aby se nejednalo o skutečné skóre, kterého by respondenti mohli dosáhnout. Definujeme „Measure – úroveň měření je „Scale (změníme, defaultně je uvedeno „Unknown Po dokončení překlikneme z „Variable view na „Data view . (Pozn.: unknown = neznámá) Dokončíme řádek tak, že vybereme nominální úroveň měření.")
17
Nyní můžeme překliknout na „Data view“

18
Zde se nám zobrazí názvy sloupců, tak jak jsme je vepsali ve „Variable view“

19
Pravděpodobně již máme data v tabulce v programu Microsoft Excel
Pravděpodobně již máme data v tabulce v programu Microsoft Excel. Okopírujeme je a vložíme do jednotlivých sloupců. Vidíme, že pokud jsme u daného edukanta (respondenta) měření neprovedli (a data nám tedy chybí), jsou tato chybějící data vyjádřena tak, jak jsme je definovali (hodnotou „99“)
 měření neprovedli (a data nám tedy chybí), jsou tato chybějící data vyjádřena tak, jak jsme je definovali (hodnotou „99 )")
20
Pro náš typ úlohy je vhodné použít dvouvýběrový t-test, ovšem za splnění následujících předpokladů:
Nezávislá proměnná (NP) se týká dvou nezávislých skupin (ano – NP je typ edukace, ta je u každé skupiny edukantů jiná, skupiny jsou na sobě nezávislé) Závislá proměnná (ZP) je na intervalové nebo podílové škále (ano – ZP je skóre, jedná se o podílovou škálu, má intervaly mezi hodnotami a navíc má nulu stanovenou absolutně a všechny hodnoty jsou kladné, i když diskrétní ZP má přibližně normální rozdělení v každé skupině Splnění předpokladu a) a b) je jasné již z výzkumného designu (plánu), tedy ještě před sběrem dat můžeme prohlásit, že tyto dva předpoklady jsou splněny. Splnění předpokladu c) není jasné z výzkumného designu, ale zjistíme ho až po sběru dat a jejich statistickém zpracování (provedeme test normality). Existují dvě hlavní metody testu normality: numerická a grafická. Posouzení normality z grafů vyžaduje jistou zkušenost. Začátečník by se naopak mohl spolehnout spíše na numerickou metodu, i když ta má též svoje nevýhody.
 se týká dvou nezávislých skupin (ano – NP je typ edukace, ta je u každé skupiny edukantů jiná, skupiny jsou na sobě nezávislé) Závislá proměnná (ZP) je na intervalové nebo podílové škále (ano – ZP je skóre, jedná se o podílovou škálu, má intervaly mezi hodnotami a navíc má nulu stanovenou absolutně a všechny hodnoty jsou kladné, i když diskrétní. ZP má přibližně normální rozdělení v každé skupině. Splnění předpokladu a) a b) je jasné již z výzkumného designu (plánu), tedy ještě před sběrem dat můžeme prohlásit, že tyto dva předpoklady jsou splněny. Splnění předpokladu c) není jasné z výzkumného designu, ale zjistíme ho až po sběru dat a jejich statistickém zpracování (provedeme test normality). Existují dvě hlavní metody testu normality: numerická a grafická. Posouzení normality z grafů vyžaduje jistou zkušenost. Začátečník by se naopak mohl spolehnout spíše na numerickou metodu, i když ta má též svoje nevýhody.")
21
Zjistíme, zda ZP má přibližně normální rozdělení: klikneme na „Analyze“ – „Descriptive Statistics“ – „Explore“ (pozn.: analyze = analyzovat; explore = prozkoumat)
")
22
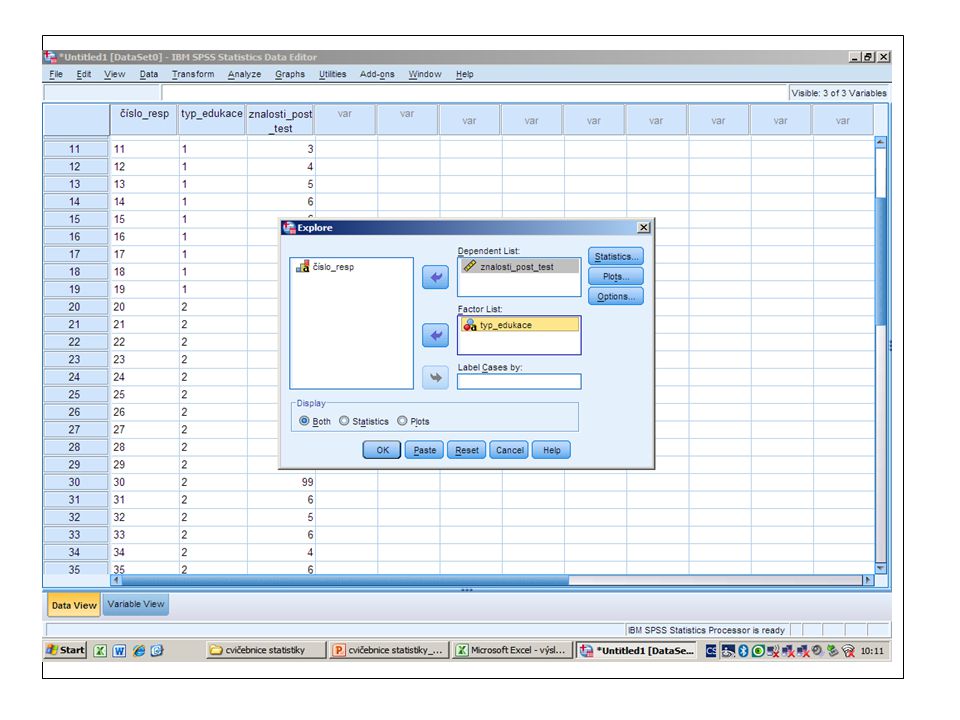
V levém poli se nám objeví nabídka všech sloupců z tabulky s daty
V levém poli se nám objeví nabídka všech sloupců z tabulky s daty. Vybereme z nich závislou proměnnou, tedy znalosti na post-testu (skóre), klikneme na šipce vedoucí k poli „Dependent List“, tím se nám tato ZP přesune do tohoto pole. (Pozn. dependent list = seznam závislých proměnných)
, klikneme na šipce vedoucí k poli „Dependent List , tím se nám tato ZP přesune do tohoto pole. (Pozn. dependent list = seznam závislých proměnných)")
23
Z pole na levé straně dále vybereme nezávislou proměnnou (NP), tedy typ edukace, klikneme na šipce vedoucí k poli „Factor List“, tím se nám tato NP přesune do tohoto pole.
, tedy typ edukace, klikneme na šipce vedoucí k poli „Factor List , tím se nám tato NP přesune do tohoto pole.")
25
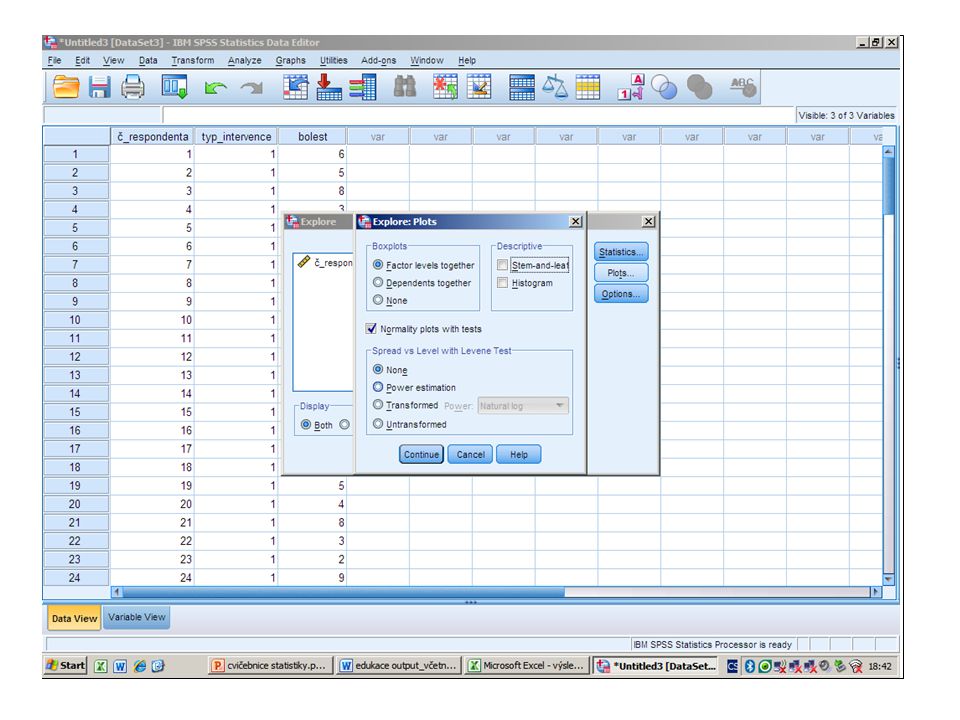
Klikneme na „Plots“ a rozbalí se nám nové okno, kde můžeme zatrhnout „Normality plots with tests“, klikneme na „Continue“ (pokračovat). To je důležité pro zjišťování normality. (pozn.: plot = graf)
")
26
Klikneme „Ok“.

27
Klikneme na „Statistics“ a rozbalí se nám nové okno, kde můžeme zatrhnout, že chceme získat popisnou statistiku („Descriptives“), klikneme na „Continue“ (pokračovat).
, klikneme na „Continue (pokračovat).")
28
Získáme výsledky…Získáme celou řadu výsledků vzhledem k tomu, že příkaz „Explore“ je používán nejen na test normality, ale i k dalším účelům. Např. první tabulka obsahuje absolutní a relativní četnosti (vidíme, že opravdu v dvou případech jsou chybějící data - byly vloženy hodnoty „99“) . V 2. tabulce se zobrazí popisná statistika, např. průměr, medián, směrodatná odchylka, atd. Protože se ale zabýváme testem normality, zajímá nás jednak tabulka označená „Tests of Normality“ (pro numerickou metodu) a dále „Normal Q-Q Plots (pro grafickou metodu) zjišťování normality.
 a dále „Normal Q-Q Plots (pro grafickou metodu) zjišťování normality.")
29
Detail výsledků: absolutní a relativní četnosti v každé skupině respondentů

30
Detail výsledků pro každou skupinu respondentů (popisná statistika)
")
31
Vraťme se nyní k testu normality
Vraťme se nyní k testu normality. Zde je prezentován výsledek testu normality – numerickou metodou. Pro malý soubor je vhodné se zaměřit na test Shapiro-Wilk, i když je možné tento test použít i pro větší vzorky. Zaměříme se na hodnotu ve sloupci „Sig.“ (significance = významnost). Ho = data jsou normálně rozložena Ha = data nejsou normálně rozložena Pokud je hodnota Sig. > 0,05, pak je rozložení dat pro daný typ edukace (samostudijní materiál nebo video s procvičováním dovedností) normální. Pokud je hodnota < 0,05, pak se distribuce dat signifikantně liší od normální distribuce dat. Závěr testu normality: u obou typů edukace je Sig. < 0,05; distribuce dat se tedy signifikantně liší od normální distribuce. Proto není splněn předpoklad normality a testování rozdílů ve znalostech mezi dvěma skupinami bude muset proběhnout za použití neparametrické metody – Mann Whitney U Testu (ne za použití dvouvýběrového t-testu, jak jsme plánovali).
. Ho = data jsou normálně rozložena. Ha = data nejsou normálně rozložena. Pokud je hodnota Sig. > 0,05, pak je rozložení dat pro daný typ edukace (samostudijní materiál nebo video s procvičováním dovedností) normální. Pokud je hodnota < 0,05, pak se distribuce dat signifikantně liší od normální distribuce dat. Závěr testu normality: u obou typů edukace je Sig. < 0,05; distribuce dat se tedy signifikantně liší od normální distribuce. Proto není splněn předpoklad normality a testování rozdílů ve znalostech mezi dvěma skupinami bude muset proběhnout za použití neparametrické metody – Mann Whitney U Testu (ne za použití dvouvýběrového t-testu, jak jsme plánovali).")
32
Zde je prezentován výsledek testu normality i grafickou metodou (pro typ edukace = samostudijní materiál). Normálně rozložená data mají přímkový charakter. My jsme již numerickou metodou zjistili, že data nejsou normálně rozložena.

33
Zde je prezentován výsledek testu normality i grafickou metodou (pro typ edukace = video s procvičováním dovedností). Normálně rozložená data mají přímkový charakter. My jsme již numerickou metodou zjistili, že data nejsou normálně rozložena. V dalších příkladech výsledky testu normality grafickou metodou pro jednoduchost zobrazovat nebudeme, i když tyto výsledky nám program SPSS poskytl.

34
Testování rozdílů ve znalostech mezi dvěma skupinami za použití neparametrické metody – Mann Whitney U Testu Než se pustíme do neparametrického testu, vrátíme se k definici jednotlivých typů proměnných. U typu edukace jsme typ definovali jako „String“, jedná se o speciální, binární proměnnou (tedy může nabývat jen dvou možných hodnot), na kterou někdy pohlížíme jako na numerickou. Typ v tento moment potřebujeme rekódovat právě na numerický typ, aby mohl proběhnout již zmíněný Mann Whitney U Test.
, na kterou někdy pohlížíme jako na numerickou. Typ v tento moment potřebujeme rekódovat právě na numerický typ, aby mohl proběhnout již zmíněný Mann Whitney U Test.")
35
Nyní jsme připraveni provést Mann Whitney U Test
Nyní jsme připraveni provést Mann Whitney U Test. Klikneme na „Analyze“ – „Nonparametric Tests“ – „Legacy Dialogues“ – „2 Independent Samples“

36
Objeví se tento rámeček

37
Závislou proměnnou – „znalosti_post_test“ – přesuneme do rámečku „Test Variable List“ a nezávislou proměnnou – „typ_edukace“ – do rámečku „Grouping Variable“ kliknutím na příslušnou šipku mezi rámečky.

38
Závislou proměnnou – „znalosti_post_test“ – přesuneme do rámečku „Test Variable List“ a nezávislou proměnnou – „typ_edukace“ – do rámečku „Grouping Variable“ kliknutím na příslušné šipky mezi rámečky. Ujistíme se, že je zakliknut rámeček „Mann Whitney U“. Nyní klikneme na „Define Groups“ (k tomu je potřeba, aby byla „Grouping Variable“ vyznačena oranžově jako na tomto snímku)
.")
39
Objeví se nový rámeček, kde pro „Group 1“ vepíšeme hodnotu 1 a pro „Group 2“ hodnotu 2 (takto jsme oba typy edukace již na samém počátku definovali). Důvod, proč tyto informace nyní znovu vpisujeme je ten, že můžeme mít víc různých typů edukace (např. 3) a mohli bychom chtít porovnávat různé kombinace typů edukace, např. typ 1 oproti typu 2, typ 1 oproti typu 3 atd.
 a mohli bychom chtít porovnávat různé kombinace typů edukace, např. typ 1 oproti typu 2, typ 1 oproti typu 3 atd..")
40
Klikneme „Continue“ (pokračovat).
.")
41
Pokud chceme získat i popisnou statistiku, klikneme na „Options“ (= možnosti), objeví se další rámeček a zaškrtneme „Descriptives“ a „Quartiles“, poté klikneme na „Continue“.
, objeví se další rámeček a zaškrtneme „Descriptives a „Quartiles , poté klikneme na „Continue .")
42
Klikneme „Ok“, abychom získali výsledek Mann Whitney U Testu.

43
Získáme tři tabulky

44
První tabulka obsahuje popisnou statistiku, ale data nejsou příliš užitečná vzhledem k tomu, že není rozlišeno, o jakou skupinu edukantů se jedná (data obou skupin byla sloučena), navíc nevíme, zda tato sloučená skupina edukantů má či nemá normální distribuci dat a zda je pro nás relevantní aritmetický průměr se směrodatnou odchylkou (tak by tomu bylo v případě normální distribuce dat) či medián a 25. a 75. percentil….(v případě nenormální distribuce dat…) Proto je lepší tuto tabulku ignorovat.

45
Druhá tabulka již obsahuje informace, která skupina respondentů měla vyšší znalosti: získáme „mean rank“ (průměrné pořadí) a „sum of ranks“ (sumu pořadí). Protože vyšší skóre znamená lepší znalosti, lze také říci, že znalosti byly lepší pro skupinu s typem edukace „video s procvičováním dovedností“ („mean rank“ = 21, 40). U skupiny edukované „samostudijním materiálem“ je „mean rank“ = 18, 53. Třetí tabulka nám pomůže určit, zda se jedná o statisticky významný rozdíl.
. U skupiny edukované „samostudijním materiálem je „mean rank = 18, 53. Třetí tabulka nám pomůže určit, zda se jedná o statisticky významný rozdíl..")
46
Třetí tabulka ukazuje hodnotu testové statistiky U (162,000) a hodnotu p (Asymp. Sig. 2-tailed = dvoustranný test). Protože je hodnota > 0,05 (je = 0,411), jedná se o statisticky nevýznamný rozdíl v mediánech znalostí u skupiny edukované jedním typem edukace oproti skupině edukované druhým typem edukace. Kdyby byla hodnota < 0,05, jednalo by se o statistiky významný rozdíl ve znalostech u jedné skupiny oproti druhé skupině. Poznámka: hovoříme o mediánech. Kolik byl medián znalostí (skóre) pro každou skupinu? To již víme z tabulky s popisnou statistikou, kterou jsme získali při testu normality. Je patrno, že medián u obou skupin byl 5,00 – tedy, byl stejný. Proto není možné, aby byl zjištěn statisticky významný rozdíl ve znalostech. Rozdíl samozřejmě neexistuje ani z praktického hlediska. Z výsledků post-testu nemůžeme tvrdit, že „stojí za to“ provádět jeden typ edukace oproti druhému typu edukace.
 pro každou skupinu To již víme z tabulky s popisnou statistikou, kterou jsme získali při testu normality. Je patrno, že medián u obou skupin byl 5,00 – tedy, byl stejný. Proto není možné, aby byl zjištěn statisticky významný rozdíl ve znalostech. Rozdíl samozřejmě neexistuje ani z praktického hlediska. Z výsledků post-testu nemůžeme tvrdit, že „stojí za to provádět jeden typ edukace oproti druhému typu edukace.")
47
Příklad 2. Pokračujeme s novým příkladem
Příklad 2. Pokračujeme s novým příkladem. Jedná se stále o stejné edukanty a dva již definované typy edukace. Nyní však testujeme dovednosti (ne znalosti). Opět nás zajímá, zda bude existovat statisticky významný rozdíl v dovednostech v závislosti na tom, zda se jednalo o skupinu edukovanou samostudijním materiálem nebo videem s procvičováním dovedností. Vepíšeme novou proměnnou – „dovednosti_posttest“; tu definujeme podobně jako „znalosti_posttest“.
. Opět nás zajímá, zda bude existovat statisticky významný rozdíl v dovednostech v závislosti na tom, zda se jednalo o skupinu edukovanou samostudijním materiálem nebo videem s procvičováním dovedností. Vepíšeme novou proměnnou – „dovednosti_posttest ; tu definujeme podobně jako „znalosti_posttest .")
48
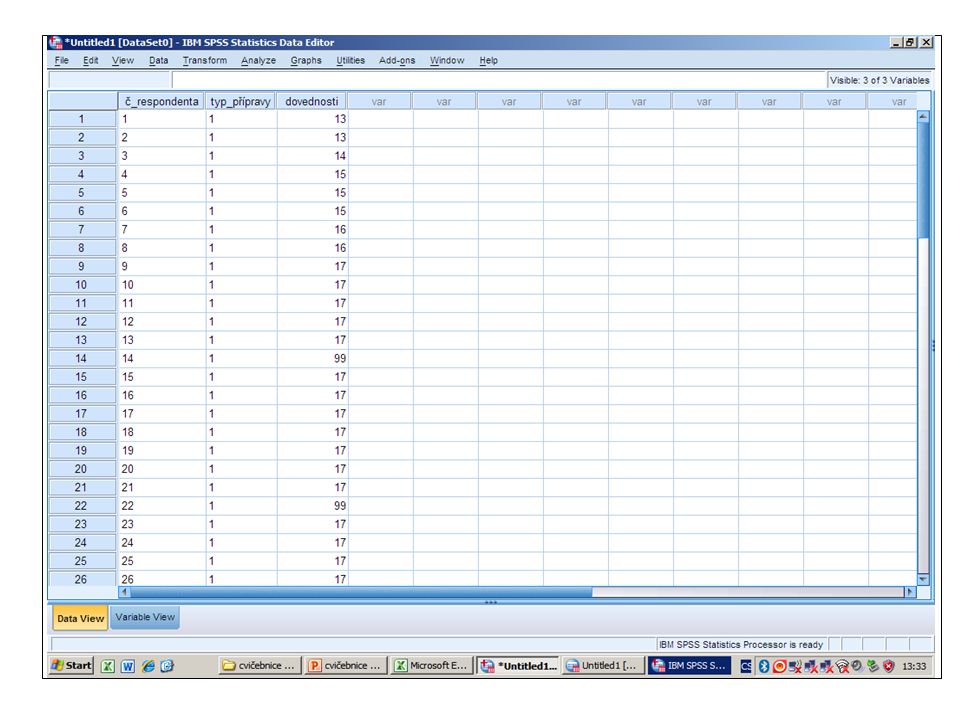
Z dokumentu vytvořeném v programu Microsoft Excel obsahujícím data o edukantech vložíme skóre získaná na dovednostním post-testu. Pro chybějící data jsme vložili hodnotu „99“ (to bylo třeba definovat ve „Variable view“).
..")
49
Již známým způsobem zjistíme, zda ZP (skóre na dovednostním post-testu) má přibližně normální rozdělení: klikneme na „Analyze“ – „Descriptive statistics“ – „Explore“. Pokud ne, opět bychom prováděli Mann Whitney U Test. Pokud bude rozdělení dat normální, budeme moci provést parametrický test – Dvouvýběrový T-test s nezávislými výběry.

50
Do rámečku „Dependent List“ přesuneme závislou proměnnou, tedy „dovednosti_post-test“ a do rámečku „Factor List“ nezávislou proměnnou, tedy typ edukace.

51
Klikneme na „Plots“, objeví se nový rámeček, zaškrtneme „Normality plots with tests“, pak klikneme „Continue“.

52
Klikneme „Ok“.

53
Získáme tři tabulky včetně popisné statistiky.

54
Třetí tabulka je testem normality
Třetí tabulka je testem normality. Opět se zaměříme na test Shapiro-Wilk. Pro obě skupiny je hodnota Sig. > 0,05, takže distribuce dat je normální a můžeme přistoupit k dvouvýběrovému T-testu s nezávislými výběry. Toto by bylo možné určit i grafickou metodou (grafy též získány ve výsledcích – ty v této cvičebnici nezobrazujeme).
.")
55
Dvouvýběrový T-test s nezávislými výběry: Klikneme na „Analyze“ – „Compare Means“ – „Independent Samples T Test“

56
Objeví se rámeček, kde pro „Test Variable(s)“ vybereme závislou proměnnou (dovednosti na post-testu) a pro „Grouping Variable“ typ edukace. Klikneme na „Define Groups“ a skupiny opět nadefinujeme (vyplníme Group 1 = 1, Group 2 = 2).
..")
57
Klikneme „Continue“.

58
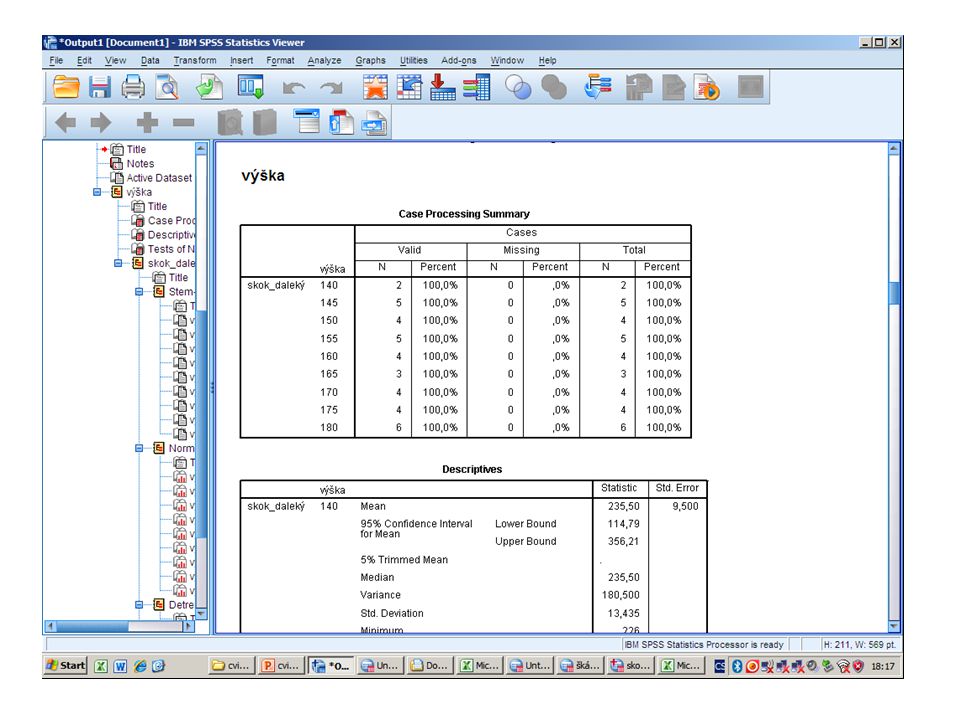
Klikneme „Ok“.

59
Výsledky: V první tabulce je popisná statistika včetně aritmetického průměru skóre získaných na příslušném dovednostním post-testu a včetně směrodatné odchylky pro každou skupinu edukantů. Je patrno, že skupina s videem a procvičováním dovedností získala lepší aritmetický průměr (7, 53 bodů) oproti skupině edukované samostudijním materiálem (6, 18 bodů). Na dalším slidu se zaměříme na druhou tabulku, kde je výsledek T-testu. Ten nám umožní zjistit, zda zjištěné rozdíly v aritmetických průměrech jsou statisticky významné nebo nejsou.
 oproti skupině edukované samostudijním materiálem (6, 18 bodů). Na dalším slidu se zaměříme na druhou tabulku, kde je výsledek T-testu. Ten nám umožní zjistit, zda zjištěné rozdíly v aritmetických průměrech jsou statisticky významné nebo nejsou..")
60
Před každým T-testem se provádí F-test, což je test hypotézy o shodě dvou rozptylů. V programu SPPS je v tabulce ukázán výsledek na dvou řádcích, kde u prvního řádku se předpokládá, že výsledek F-testu prokázal shodnost dvou rozptylů. V druhém řádku se předpokládá, že výsledek F-testu neprokázal shodnost dvou rozptylů. Výsledek F-testu: ve sloupečku vedle hodnoty F je hodnota p (Sig.) – pokud je > 0,05, rozptyly v obou skupinách považujeme na shodné. V našem případě je uvedeno Sig. = 0,114, takže rozptyly v obou skupinách považujeme opravdu za shodné. Proto je pro nás relevantní výsledek T-testu v prvním řádku a druhý řádek můžeme ignorovat. Statistická významnost rozdílu mezi skupinami: Pro T-test (testovou statistiku t = -2,660 – viz první řádek s výsledky) jsme získali hodnotu p (Sig.) = 0,012. I zde porovnáváme, zda tato hodnota je menší nebo větší než 0,05. Protože 0,012 < 0,05, docházíme k závěru, že rozdíly v dovednostech jsou mezi skupinami statisticky významné (na hladině významnosti 0,05). To znamená, že k rozdílům nedošlo náhodou, ale že vliv zde hrál vliv edukace (s 95% jistotou). Z první tabulky již víme, jaký je aritmetický průměr u každé skupiny. Praktická významnost rozdílu mezi skupinami: Na závěr je nutno se rozhodnout, zda zjištěné rozdíly jsou pro nás důležité i z praktického hlediska. Pokud bychom bývali stanovili, že prakticky významný je pro nás rozdíl v průměrném skóre skupin > 2 body, byly by výsledky z praktického hlediska nevýznamné.
 – pokud je > 0,05, rozptyly v obou skupinách považujeme na shodné. V našem případě je uvedeno Sig. = 0,114, takže rozptyly v obou skupinách považujeme opravdu za shodné. Proto je pro nás relevantní výsledek T-testu v prvním řádku a druhý řádek můžeme ignorovat. Statistická významnost rozdílu mezi skupinami: Pro T-test (testovou statistiku t = -2,660 – viz první řádek s výsledky) jsme získali hodnotu p (Sig.) = 0,012. I zde porovnáváme, zda tato hodnota je menší nebo větší než 0,05. Protože 0,012 < 0,05, docházíme k závěru, že rozdíly v dovednostech jsou mezi skupinami statisticky významné (na hladině významnosti 0,05). To znamená, že k rozdílům nedošlo náhodou, ale že vliv zde hrál vliv edukace (s 95% jistotou). Z první tabulky již víme, jaký je aritmetický průměr u každé skupiny. Praktická významnost rozdílu mezi skupinami: Na závěr je nutno se rozhodnout, zda zjištěné rozdíly jsou pro nás důležité i z praktického hlediska. Pokud bychom bývali stanovili, že prakticky významný je pro nás rozdíl v průměrném skóre skupin > 2 body, byly by výsledky z praktického hlediska nevýznamné.")
61
Procvičování – příklad 1

62
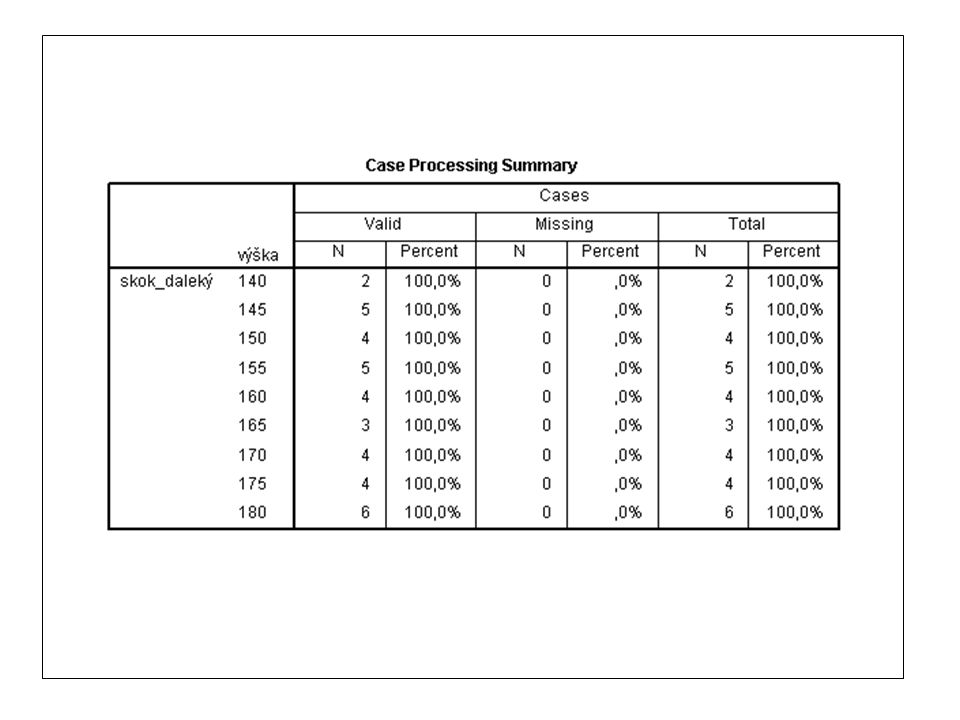
Procvičování - příklad 1: Je 60 respondentů – matek novorozenců
Procvičování - příklad 1: Je 60 respondentů – matek novorozenců. Jedna skupina matek podstoupila skupinovou přípravu na mateřství, při které se učila celou řadu úkonů od stravování (kojení) dítěte až po hygienu a navazování vztahu s dítětem. Druhá skupina žádnou přípravu neabsolvovala. Po 30 dnech se obě skupiny matek podrobily pozorování, kde byly sledovány, jak dobře se o dítě starají (např. zda dítě dobře drží při kojení atd.). Bylo sledováno celkem 20 položek, u každé položky byl možný jeden ze dvou výsledků (1 = správný postup; 0 = špatný postup), takže celkové skóre bylo minimálně 0 a maximálně 20. Existuje statisticky významný rozdíl v dovednostech matek dle toho, zda přípravu absolvovaly nebo neabsolvovaly? Připravte si data v programu Microsoft Excel, aby se do SPSS mohla přenést kopírováním. Matky č prošly přípravou, matky přípravou neprošly. U matky č. 14, 22, 34 a 45 jsou chybějící skóre, matky se na testování nedostavily. Skóre byla následující: Skóre a 0-12: nikdo Skóre 13: matka 1, 2, 31, 32, 33 Skóre 14: matka 3, 35, 36, 37, 38 Skóre 15: matka 4, 5, 6, 39, 40, 41, 42, 43, 44 Skóre 16: matka 7, 8, 46, 47, 48 Skóre 17: všechny ostatní matky Budeme za pomoci statistického testu zjišťovat, zda je mezi skupinami (matkami s přípravou oproti matkám bez přípravy) statisticky významný rozdíl v dovednostech matek (vyjádřeno získaným skóre).
 dítěte až po hygienu a navazování vztahu s dítětem. Druhá skupina žádnou přípravu neabsolvovala. Po 30 dnech se obě skupiny matek podrobily pozorování, kde byly sledovány, jak dobře se o dítě starají (např. zda dítě dobře drží při kojení atd.). Bylo sledováno celkem 20 položek, u každé položky byl možný jeden ze dvou výsledků (1 = správný postup; 0 = špatný postup), takže celkové skóre bylo minimálně 0 a maximálně 20. Existuje statisticky významný rozdíl v dovednostech matek dle toho, zda přípravu absolvovaly nebo neabsolvovaly Připravte si data v programu Microsoft Excel, aby se do SPSS mohla přenést kopírováním. Matky č prošly přípravou, matky přípravou neprošly. U matky č. 14, 22, 34 a 45 jsou chybějící skóre, matky se na testování nedostavily. Skóre byla následující: Skóre a 0-12: nikdo. Skóre 13: matka 1, 2, 31, 32, 33. Skóre 14: matka 3, 35, 36, 37, 38. Skóre 15: matka 4, 5, 6, 39, 40, 41, 42, 43, 44. Skóre 16: matka 7, 8, 46, 47, 48. Skóre 17: všechny ostatní matky. Budeme za pomoci statistického testu zjišťovat, zda je mezi skupinami (matkami s přípravou oproti matkám bez přípravy) statisticky významný rozdíl v dovednostech matek (vyjádřeno získaným skóre).")
63
Řešení příkladu 1 Data vložena do programu Microsoft Excel. Vkládáno s úmyslem definovat chybějící data v SPSS (v položce „Skóre“ hodnotou „99“); „absolvování přípravy“ již nyní reprezentováno číslem „1“ a „neabsolvování přípravy“ číslem „2“. Při kopírováním dat do SPSS však bude nutno význam (definici) těchto čísel nejprve zadat v záložce „Variable view“.
; „absolvování přípravy již nyní reprezentováno číslem „1 a „neabsolvování přípravy číslem „2 . Při kopírováním dat do SPSS však bude nutno význam (definici) těchto čísel nejprve zadat v záložce „Variable view .")
66
Získání popisné statistiky a provedení testu normality

67
Popisná statistika pro obě skupiny

68
Závěr testu normality: u obou typů přípravy je Sig
Závěr testu normality: u obou typů přípravy je Sig. < 0,05; distribuce dat se tedy signifikantně liší od normální distribuce. Proto není splněn předpoklad normality a testování statistické významnosti rozdílů v dovednostech mezi dvěma skupinami bude muset proběhnout za použití neparametrické metody – Mann Whitney U Testu (ne za použití dvouvýběrového t-testu). Zároveň stanovíme, jaký rozdíl je pro nás prakticky významný. Např. rozdíl ve skóre ≥ 3 body je pro nás již významný z praktického hlediska. Toto nevyčteme v učebnicích, spíše se řídíme praktickými zkušenostmi, zajímá nás časová a finanční náročnost edukační metody, atd.
. Zároveň stanovíme, jaký rozdíl je pro nás prakticky významný. Např. rozdíl ve skóre ≥ 3 body je pro nás již významný z praktického hlediska. Toto nevyčteme v učebnicích, spíše se řídíme praktickými zkušenostmi, zajímá nás časová a finanční náročnost edukační metody, atd.")
69
Nezapomeneme předefinovat typ proměnné u „typ přípravy“ na „Numeric“.

70
Mann Whitney U Test

71
Rozdíl v dovednostech je statistiky významný (na hladině významnosti 0,05) – ve prospěch skupiny, která absolvovala přípravu, jak je patrno z tabulky „Ranks“ – tzn., že k tomuto rozdílu (s 95% jistotou) nedošlo náhodou a lze tak předpovídat, že rozdíl v dovednostech ve prospěch skupiny absolvující přípravu existuje nejen v našem vzorku, ale v celé populaci matek. Vrátíme se k tabulce s popisnou tabulkou a podíváme se, jaký byl medián dovedností u každé skupiny.

72
Medián v dovednostech matek, které absolvovaly přípravu, je 17
Medián v dovednostech matek, které neabsolvovaly přípravu, je 16. Z praktického hlediska se nejedná o významný rozdíl. Zřejmě nestojí za to tento program přípravy dále provozovat, nejeví se jako příliš efektivní, i když k pozorovaným rozdílům v dovednostech nedošlo náhodou, ale vlivem absolvování přípravy (s 95% jistotou).
.")
73
Procvičování – příklad 2

74
Procvičování – příklad 2: Je 80 respondentů – pacientů po operaci kyčelního kloubu. Jedna skupina pacientů (pacient 1-40) dostávala po operaci analgesii od všeobecné sestry, druhá skupina (pacient 41-80) využívala tzv. „patient controlled analgesia“ (analgesii řízenou pacientem). Byla sledována rychlost, s jakou byli pacienti ve čtvrtý pooperační den schopni vstát z lůžka. Rychlost byla sledována v sekundách. Je mezi skupinami pacientů statisticky významný rozdíl v rychlosti vstávání, v závislosti na druhu použité analgesie? Připravte si data v programu Microsoft Excel, aby se do SPSS mohla přenést kopírováním. Rychlost vstávání byla následná: 0-4 s: nikdo 5 s: pacient 1-5, 41-49 6 s: pacient 6-7, 50-55 7 s: pacient 8, 56-59 8-10 s: nikdo 11 s: pacient 9-13, 60-65 12 s: pacient 14-18, 66-67 13-14 s: nikdo 15 s: pacient 19-28, 68-75 16 s: pacient 29-33, 76 17 s: pacient 77-79 18 s: pacient 34-38 19 s: pacient 39 20 s: pacient 80 21-27 s: nikdo 28 s: pacient 40

75
Řešení příkladu 2 Data vložena do programu Microsoft Excel. „Analgesie sestrou“ již nyní reprezentována číslem „1“ a „analgesie řízená pacientem“ číslem „2“. Při kopírováním dat do SPSS však bude nutno význam (definici) těchto čísel nejprve zadat v záložce „Variable view“.
 těchto čísel nejprve zadat v záložce „Variable view .")
76
Proměnné nadefinovány v záložce „Variable view“.

77
Data zkopírována z Excelu do záložky „Data view“.

78
Test normality a získání popisné statistiky

79
Popisná statistika, vrátíme se k ní později

80
Výsledky testu normality:
U obou typů analgesie je dle testu Shapiro-Wilk Sig. < 0,05; distribuce dat se tedy signifikantně liší od normální distribuce. Proto není splněn předpoklad normality a testování statistické významnosti rozdílů v rychlosti vstávání mezi dvěma skupinami bude muset proběhnout za použití neparametrické metody – Mann Whitney U Testu (ne za použití dvouvýběrového t-testu). Stanovíme i praktickou významnost rozdílů, např. minimálně 4 s.
. Stanovíme i praktickou významnost rozdílů, např. minimálně 4 s.")
81
Mann Whitney U Test. Nezapomeneme nejprve změnit typ proměnné pro „typ analgesie“ (ze „String“ na „Numeric“, k tomu je třeba překliknout na „Variable view“).
..")
82
Mann Whitney U Test. Tabulka „Ranks“ napovídá, že rychlost vstávání je nižší u skupiny, která měla analgesii řízenou pacientem. Asymp. Sig. Mann-Whitney U Testu je < 0,05, jedná se o statisticky významný rozdíl v mediánech rychlosti vstávání u obou skupin (efekt nevznikl náhodou, ale vlivem metody aplikace analgesie – s 95% jistotou). Medián rychlosti vstávání u skupiny s analgesií řízenou pacientem byl 11 s, u skupiny s analgesií sestrou byl 15 s (viz tabulka s popisnou statistikou). Rozdíl mezi skupinami je tedy i prakticky významný, laicky řečeno, „stojí to za to pacientům nabízet analgesii řízenou pacientem“ (protože efekt je „velký“….i přesto, že tento typ analgesie stojí více peněz, atd. atd.)
. Medián rychlosti vstávání u skupiny s analgesií řízenou pacientem byl 11 s, u skupiny s analgesií sestrou byl 15 s (viz tabulka s popisnou statistikou). Rozdíl mezi skupinami je tedy i prakticky významný, laicky řečeno, „stojí to za to pacientům nabízet analgesii řízenou pacientem (protože efekt je „velký ….i přesto, že tento typ analgesie stojí více peněz, atd. atd.).")
83
Příklad 3. Vrátíme se k edukantům a ke studiu účinku edukace
Příklad 3. Vrátíme se k edukantům a ke studiu účinku edukace. Nyní nás zajímá rozdíl mezi znalostmi před edukací (znalostní před-test) a po absolvování edukace (znalostní post-test). Podstatným rozdílem mezi příkladem 3 a příkladem 1 v úvodu je to, že edukanti nejsou děleni na skupiny, avšak nyní všichni edukanti podstupují stejný typ edukace. Druhým podstatným rozdílem je, že stejní edukanti jsou testováni dvakrát – před a po edukaci. Pro tento typ situace je vhodný párový t-test, ovšem za předpokladu, že rozdíl mezi znalostmi v post-testu a před-testu má normální rozdělení. Více si situaci rozebereme na následujícím slidu. Praktická významnost: např., edukace je účinná, pokud se znalosti zlepší alespoň o dva body.
 a po absolvování edukace (znalostní post-test). Podstatným rozdílem mezi příkladem 3 a příkladem 1 v úvodu je to, že edukanti nejsou děleni na skupiny, avšak nyní všichni edukanti podstupují stejný typ edukace. Druhým podstatným rozdílem je, že stejní edukanti jsou testováni dvakrát – před a po edukaci. Pro tento typ situace je vhodný párový t-test, ovšem za předpokladu, že rozdíl mezi znalostmi v post-testu a před-testu má normální rozdělení. Více si situaci rozebereme na následujícím slidu. Praktická významnost: např., edukace je účinná, pokud se znalosti zlepší alespoň o dva body.")
84
Rozepišme si, za jakých podmínek je možno u tohoto příkladu použít párový t-test. Je nutné, aby byly splněny následující předpoklady: Závislá proměnná (ZP) je na intervalové nebo podílové škále (ano – ZP je skóre, jedná se o podílovou škálu, má intervaly mezi hodnotami a navíc má nulu stanovenou absolutně a všechny hodnoty jsou kladné, i když diskrétní Nezávislá proměnná (NP) je jen jedna skupina (ano – jedna skupina edukantů, testovaná dvakrát) Rozdíl mezi dvěma „skupinami“ má přibližně normální rozdělení (jedná se o rozdíl mezi znalostmi v před-testu a post-testu) Splnění předpokladu a) a b) je jasné již z výzkumného designu (plánu), tedy ještě před sběrem dat můžeme prohlásit, že tyto dva předpoklady jsou splněny. Splnění předpokladu c) není jasné z výzkumného designu, ale zjistíme ho až po sběru dat a jejich statistickém zpracování (provedeme test normality). Existují dvě hlavní metody tohoto testu: numerická a grafická. Posouzení normality z grafů vyžaduje jistou zkušenost. Začátečník by se naopak mohl spolehnout spíše na numerickou metodu, i když ta má též svoje nevýhody.
 je na intervalové nebo podílové škále (ano – ZP je skóre, jedná se o podílovou škálu, má intervaly mezi hodnotami a navíc má nulu stanovenou absolutně a všechny hodnoty jsou kladné, i když diskrétní. Nezávislá proměnná (NP) je jen jedna skupina (ano – jedna skupina edukantů, testovaná dvakrát) Rozdíl mezi dvěma „skupinami má přibližně normální rozdělení (jedná se o rozdíl mezi znalostmi v před-testu a post-testu) Splnění předpokladu a) a b) je jasné již z výzkumného designu (plánu), tedy ještě před sběrem dat můžeme prohlásit, že tyto dva předpoklady jsou splněny. Splnění předpokladu c) není jasné z výzkumného designu, ale zjistíme ho až po sběru dat a jejich statistickém zpracování (provedeme test normality). Existují dvě hlavní metody tohoto testu: numerická a grafická. Posouzení normality z grafů vyžaduje jistou zkušenost. Začátečník by se naopak mohl spolehnout spíše na numerickou metodu, i když ta má též svoje nevýhody.")
85
Pozor na definování chybějících dat u rozdílu
Pozor na definování chybějících dat u rozdílu. Na před-testu nebyla chybějící data, ale na post-testu ano, ta byla definována jako „99“. V závislosti na získaném skóre na před-testu mohla být chybějící data u rozdílu v rozpětí od 93 do 99 vzhledem k tomu, že maximální možné skóre na testu je 6 (např., pokud bylo skóre na před-testu 6 a na post-testu bylo skóre chybějící, je i rozdíl chybějící a jeho vypočítaná hodnota v programu Microsoft Excel je 99 – 6 = 93). Proto toto možné rozpětí chybějících hodnot uvedeme do pole „Range“, od „Low“ (= nízké) po „High“ (= vysoké).
. Proto toto možné rozpětí chybějících hodnot uvedeme do pole „Range , od „Low (= nízké) po „High (= vysoké).")
86
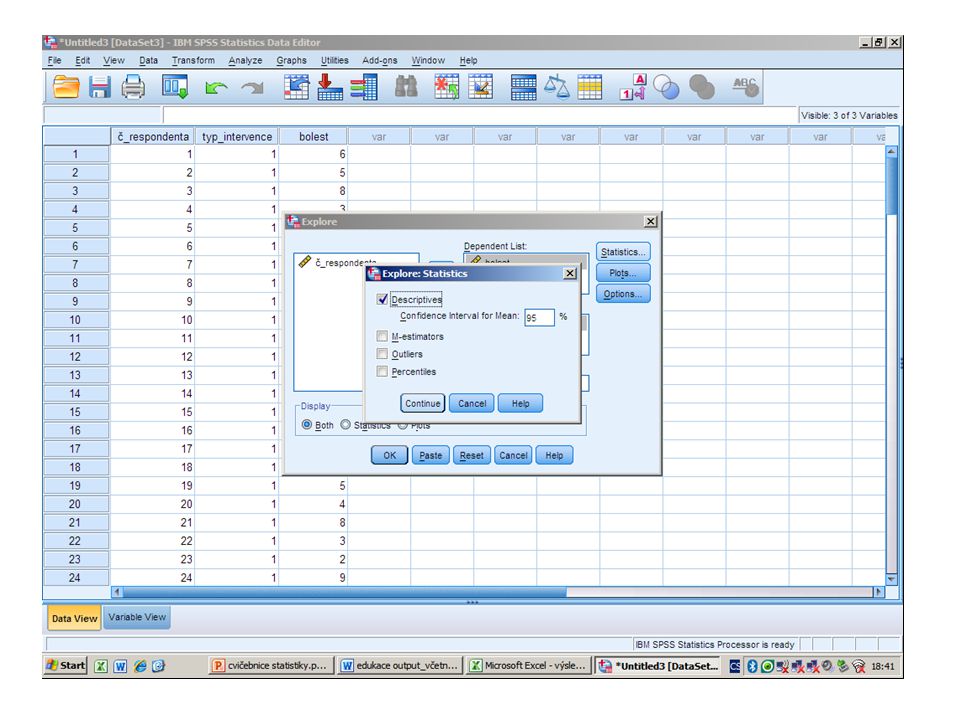
Test normality pro rozdíl ve znalostech (malý rámeček získáme kliknutím na „Plots“) a získání popisné statistiky (k tomu je třeba též zobrazit malý rámeček, který získáme kliknutím na „Statistics“). V malém rámečku nakonec vždy klikneme „Continue“, na závěr ve velkém rámečku klikneme „Ok“.

87
Popisná statistika

88
Test normality: dle Shapiro-Wilk, Sig. < 0,05
Test normality: dle Shapiro-Wilk, Sig. < 0,05. Distribuce dat (rozdílu mezi před-testem a post-testem) se tedy signifikantně liší od normální distribuce. Proto není splněn předpoklad normality a testování rozdílu mezi post-testem a před-testem bude muset proběhnout za použití neparametrické metody – Wilcoxon Signed Rank Test (ne za použití párového t-testu, jak jsme plánovali).
 se tedy signifikantně liší od normální distribuce. Proto není splněn předpoklad normality a testování rozdílu mezi post-testem a před-testem bude muset proběhnout za použití neparametrické metody – Wilcoxon Signed Rank Test (ne za použití párového t-testu, jak jsme plánovali).")
89
Wilcoxon Signed_Rank Test:
„Analyze“ – „Nonparametric Tests“ – „Legacy Dialogs“ – „2 Related Samples“.

90
¨Znalosti_post-test“ přesuneme kliknutím na šipce do rámečku vpravo, do sloupce s „Variable 1“ „znalosti před-test“ stejným způsobem přesuneme do sloupce s „Variable 2“. Ujistíme se, že je zaškrtnuto pole „Wilcoxon“.

91
Kliknutím na „Options“ se objeví menší rámeček, ve kterém je možno zatrhnout „Descriptive“ a „Quartiles“, čímž ve výsledcích získáme i popisnou statistiku. Klikneme „Continue“, menší rámeček zmizí a ve velkém rámečku klikneme „Ok“, čímž spustíme výpočet.

92
Pokud jsme zatrhli, že chceme získat popisnou statistiku, objeví se tento výsledek. Protože používáme neparametrický test, měli bychom se zaměřit na popis výsledků za použití kvartilů.

93
Z tabulky „Ranks“ je patrno, že 37 respondentů mělo v post-testu vyšší znalosti než v před-testu a 2 respondenti měli naopak nižší znalosti v post-testu než v před-testu.

94
Z tabulky „Test Statistics“ můžeme zjistit, zda je rozdíl ve znalostech v před-testu a post-testu statisticky významný. Zaměříme se na hodnotu P, tedy Asymp. Sig. (2-tailed), která je v tomto případě 0,000 (testová statistika Z je přitom -5,415 - její hodnotu bychom používali při výpočtu s použitím statistických tabulek). Protože 0,000 < 0,05, jedná se o statisticky významný rozdíl ve skóre na post-testu a před-testu (na hladině významnosti 0,05 – tento rozdíl ve skóre nevznikl náhodou, ale vlivem edukace; s 95% jistotou). Z popisné statistiky již víme, že medián znalostí v post-testu je 5,00, kdežto medián znalostí v před-testu je 2,00. Na závěr se vrátíme k praktické významnosti výsledků. Je zlepšení na post-testu opravdu značné z praktického hlediska? Pozn.: I u předešlých případů porovnáváme hodnotu p s hodnotou 0,05. To proto, že závěry tvoříme pro tuto hladinu významnosti.

95
Příklad 4. Stále studujeme edukanty a účinek edukace
Příklad 4. Stále studujeme edukanty a účinek edukace. Nyní nás zajímá rozdíl mezi postojem ke studované problematice před edukací (postoj před edukací) a po absolvování edukace (postoj po edukaci). Jednalo se totiž o edukaci zaměřenou na roli sestry při screeningu poruch polykání. Postoj je zjišťován za pomoci testu, kde maximální možné skóre je 8. Nízké skóre znamená, že respondenti vidí roli sestry v tomto screeningu jako zcela nedůležitou. Vysoké skóre znamená, že edukanti vidí roli sestry při screeningu jako v nejvyšší možné míře důležitou. Stejně jako v příkladu 3, edukanti nejsou děleni na skupiny; všichni podstupují stejný typ edukace. Stejní edukanti jsou opět dotazováni dvakrát – před a po edukaci. Pro tento typ situace je vhodný párový t-test, ovšem za předpokladu, že rozdíl mezi postojem v post-testu a před-testu má normální rozdělení. Situaci jsme již rozebrali na slidu u příkladu 3. Praktická významnost: např., edukace je účinná ve změně postoje k problematice (roli sestry při screeningu poruch polykání), pokud se postoj „zlepší“ alespoň o dva body.
 a po absolvování edukace (postoj po edukaci). Jednalo se totiž o edukaci zaměřenou na roli sestry při screeningu poruch polykání. Postoj je zjišťován za pomoci testu, kde maximální možné skóre je 8. Nízké skóre znamená, že respondenti vidí roli sestry v tomto screeningu jako zcela nedůležitou. Vysoké skóre znamená, že edukanti vidí roli sestry při screeningu jako v nejvyšší možné míře důležitou. Stejně jako v příkladu 3, edukanti nejsou děleni na skupiny; všichni podstupují stejný typ edukace. Stejní edukanti jsou opět dotazováni dvakrát – před a po edukaci. Pro tento typ situace je vhodný párový t-test, ovšem za předpokladu, že rozdíl mezi postojem v post-testu a před-testu má normální rozdělení. Situaci jsme již rozebrali na slidu u příkladu 3. Praktická významnost: např., edukace je účinná ve změně postoje k problematice (roli sestry při screeningu poruch polykání), pokud se postoj „zlepší alespoň o dva body.")
96
Chybějící hodnoty na rozdílu v postoji jsou v rozpětí bodů, protože se jedná o test, na kterém lze získat maximálně 8 bodů. Pokud edukant post-test nepsal, označili jsme u něho hodnotu 99 bodů, na před-testu mohl získat max. 8 bodů, maximální možný rozdíl je tedy 91.

97
Zkopírujeme data z programu Microsoft Exceu do „Data view“
Zkopírujeme data z programu Microsoft Exceu do „Data view“. Máme celkem 19 edukantů, žádná chybějící data.

98
Test normality pro rozdíl v postoji…

99
Test normality pro rozdíl v postoji…(malý rámeček získáme kliknutím na „Plots“, pak klikneme „Continue“) Test normality pro rozdíl v postoji…

100
…a získání popisné statistiky (malý rámeček získáme kliknutím na „Statistics“, pak klikneme „Continue“). Nakonec klikneme „Ok“.

101
Výsledek: získání popisné statistiky týkající se rozdílu v postoji před a po edukaci.

102
Výsledek: ve třetí tabulce jsou informace týkající se normality
Výsledek: ve třetí tabulce jsou informace týkající se normality. Dle testu Shapiro-Wilk je hodnota p (Sig.) 0,243 – je tedy větší než 0,05 a data mají normální rozložení. Je proto možno přistoupit k párovému T-testu.
 0,243 – je tedy větší než 0,05 a data mají normální rozložení. Je proto možno přistoupit k párovému T-testu.")
103
Párový T-test : Klikneme na „Analyze“ – „Compare means“ – „Paired Samples T Test“

104
„Postoj_po_ed“ přesuneme kliknutím na šipce do rámečku vpravo, do sloupce s „Variable 1“ „postoj_před_ed“ stejným způsobem přesuneme do sloupce s „Variable 2“. Párový T-test : Klikneme na „analyze“ – „compare means“ – „Paired Samples T Test“

105
„Postoj_po_ed“ přesuneme kliknutím na šipce do rámečku vpravo, do sloupce s „Variable 1“ „postoj_před_ed“ stejným způsobem přesuneme do sloupce s „Variable 2“. Párový T-test : Klikneme na „analyze“ – „compare means“ – „Paired Samples T Test“

106
Ve výsledcích získáme tabulky s popisnou statistikou, dále i výsledek párového T testu.

107
Průměrné skóre na testu vyjadřujícím postoj k roli sestry při screeningu poruch polykání je 6,26 bodů po edukaci a pouze 2,58 před edukací. Postoj se tedy „zlepšil“, tzn., že po edukaci vidí respondenti roli sestry při screeningu poruch polykání jako více důležitou.

108
Výsledek párového T testu: Je důležité si uvědomit, že výsledky se týkají rozdílu, v nadpisu vidíme „paired differences“. Proto je „mean“ (aritmetický průměr) aritmetickým průměrem rozdílů v postoji před a po edukaci. Nejedná se tedy o průměrný postoj. Stejným způsobem musíme pohlížet i na další výsledky (směrodatnou odchylku, atd.). T je hodnota T testu, df = „degree of freedom“ (stupeň volnosti), nás zajímá hodnota p (Sig.), ta je = 0,000. Protože je tato hodnota menší než 0,05, rozdíl v postoji před a po edukaci je statisticky významný. Z výsledků popisné statistiky již víme, že postoj se „zlepšil“, a to o téměř 4 body. Jaká je praktická významnost tohoto rozdílu? „Stojí za to“ tuto edukaci provádět, pokud nám jde o to, aby respondenti „zlepšili“ svůj postoj k důležitosti role sestry při poruchách polykání?

109
Procvičování – příklad 3

110
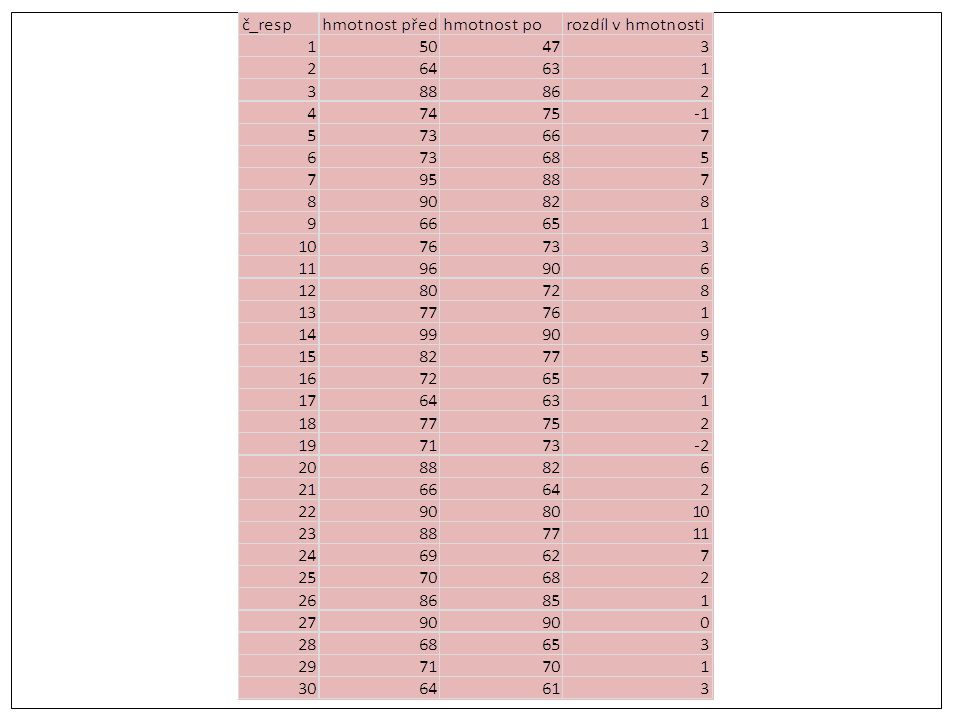
Procvičování – příklad 3: Máme 30 respondentů – pacientů, kteří podstoupili rehabilitační program s cílem redukce tělesné hmotnosti. Respondenti byli zváženi před zahájením rehabilitačního programu a po ukončení programu po 3 měsících. Existuje statisticky významný rozdíl ve hmotnosti respondentů před a po absolvování rehabilitačního programu? Připravte si data v programu Microsoft Excel, aby se do SPSS mohla přenést kopírováním. Data jsou prezentována na následujícím slidu.

112
Řešení příkladu 3: Data vložena do programu Microsoft Excel.

113
V SPSS proměnné nadefinovány v záložce „Variable view“.

114
Poté v záložce „Data view“ zkopírována data z programu Microsoft Excel.

115
Test normality a získání popisné statistiky (viz následující slide)
Test normality a získání popisné statistiky (viz následující slide). Pozor: do rámečku „dependent list“ je nutno zadat rozdíl v hmotnosti před a po rehabilitačním programu.
. Pozor: do rámečku „dependent list je nutno zadat rozdíl v hmotnosti před a po rehabilitačním programu.")
116
Test normality (viz předcházející slide) a získání popisné statistiky
Test normality (viz předcházející slide) a získání popisné statistiky. Na závěr klikneme „Ok“.
 a získání popisné statistiky. Na závěr klikneme „Ok .")
117
Výsledky: popisná statistika

118
Výsledky: test normality: dle testu Shapiro-Wilk je hodnota p (Sig
Výsledky: test normality: dle testu Shapiro-Wilk je hodnota p (Sig.) > 0,05, data (rozdíl v hmotnosti) tedy mají normální rozdělení. Je možno dále postupovat dle párového T testu, abychom zjistili statistickou významnost rozdílu v hmotnosti před a po absolvování rehabilitačního programu. Praktická významnost: např. v tomto konkrétním případě se jedná o velmi intenzivní a finančně náročný program, do kterého je angažováno mnoho rehabilitačních pracovníků a používají se nákladné přístroje, bazén, atd. Aby se provozování tohoto programu opravdu vyplatilo, chceme vidět markantní úbytek tělesné hmotnosti.
 > 0,05, data (rozdíl v hmotnosti) tedy mají normální rozdělení. Je možno dále postupovat dle párového T testu, abychom zjistili statistickou významnost rozdílu v hmotnosti před a po absolvování rehabilitačního programu. Praktická významnost: např. v tomto konkrétním případě se jedná o velmi intenzivní a finančně náročný program, do kterého je angažováno mnoho rehabilitačních pracovníků a používají se nákladné přístroje, bazén, atd. Aby se provozování tohoto programu opravdu vyplatilo, chceme vidět markantní úbytek tělesné hmotnosti.")
119
Párový T test

120
Výsledek: popisná statistika
Výsledek: popisná statistika. Průměrná tělesná hmotnost před zahájením rehabilitačního programu byla 77,23 kg a po ukončení programu byla 73,27 kg.

121
Výsledek: párový T test. Hodnota P (Sig
Výsledek: párový T test. Hodnota P (Sig.) je < 0,05, jedná se tedy o statisticky významný rozdíl v hmotnosti. Z výsledků popisné statistiky již víme, že došlo k redukci průměrné hmotnosti po absolvování rehabilitačního programu. Praktická významnost: víme, že došlo k redukci průměrné tělesné hmotnosti cca o 4 kg. Zjišťováním dalších údajů (např. výpočtem BMI, k čemuž jsme navíc použili výšku respondentů) vidíme, že podstatná část respondentů je stále obézní. Nedošlo k markantnímu úbytku na váze a protože je program finančně náročný, nebyla splněna podmínka, kterou jsme si v úvodu stanovili (aby program mohl pokračovat dále, chceme vidět markantní úbytek na váze a žádnou obezitu po absolvování programu). Na základě těchto úvah docházíme k závěru, že výsledky nejsou z praktického hlediska významné a neprokazují, že program je efektivní.
 je < 0,05, jedná se tedy o statisticky významný rozdíl v hmotnosti. Z výsledků popisné statistiky již víme, že došlo k redukci průměrné hmotnosti po absolvování rehabilitačního programu. Praktická významnost: víme, že došlo k redukci průměrné tělesné hmotnosti cca o 4 kg. Zjišťováním dalších údajů (např. výpočtem BMI, k čemuž jsme navíc použili výšku respondentů) vidíme, že podstatná část respondentů je stále obézní. Nedošlo k markantnímu úbytku na váze a protože je program finančně náročný, nebyla splněna podmínka, kterou jsme si v úvodu stanovili (aby program mohl pokračovat dále, chceme vidět markantní úbytek na váze a žádnou obezitu po absolvování programu). Na základě těchto úvah docházíme k závěru, že výsledky nejsou z praktického hlediska významné a neprokazují, že program je efektivní.")
122
Procvičování – příklad 4

123
Procvičování – příklad 4: Máme 131 respondentů – pacientů, kde prvních 70 získává medikaci pro bolest a zbývající respondenti získávají masáž. Respondenti pak na desetibodové škále hodnotí intenzitu svojí bolesti, kde 0 = žádná bolest, 10 = maximální možná bolest. Existuje statisticky významný rozdíl v intenzitě bolesti mezi skupinami pacientů, v závislosti na tom, který typ intervence dostávají (medikaci nebo masáž)? Zkopírujte si data z programu Microsoft Excel (viz doprovodný soubor).
.")
124
Řešení příkladu 4 Připravíme se na zkopírování dat do SPSS – ve „Variable view“ nadefinujeme proměnné.

125
Zkopírování dat do SPSS – v „Data view“.

126
Test normality a získání popisné statistiky

130
Výsledky: popisná statistika

131
Výsledky: popisná statistika

132
Výsledky: popisná statistika

133
Výsledky: test normality
Výsledky: test normality. Pouze u masáže je distribuce dat normální, u medikace není. Statistickou významnost rozdílu ve skóre bolesti mezi skupinou s medikací a skupinou s masáží budeme tedy testovat za pomoci neparametrického testu (Mann Whitney U Testu), ne za pomoci dvouvýběrového T testu.
, ne za pomoci dvouvýběrového T testu.")
134
Nezapomeneme změnit typ proměnné u typu intervence na „Numeric“.

135
Mann Whitney U Test

136
Mann Whitney U Test

137
Mann Whitney U Test

138
Mann Whitney U Test, včetně získání popisné statistiky

139
Výsledky popisné statistiky (pokud jsme v předcházejících krocích zatrhli, že ji chceme) a Mann Whitney U Testu.
 a Mann Whitney U Testu.")
140
První tabulku ignorujeme
První tabulku ignorujeme. Druhá napovídá, že intenzita bolesti je větší u masáže. Již při testu normality jsme získali detailní popisnou statistiku, kde bylo patrno, že ve skupině s medikací je medián bolesti 5 a ve skupině s masáží je medián bolesti 6.

141
Výsledek Mann Whitney U testu: hodnota P - Asymp. Sig
Výsledek Mann Whitney U testu: hodnota P - Asymp. Sig. (2-tailed) – je > 0,05, jedná se tedy o statisticky významný rozdíl mezi skupinami. Z popisné statistiky již víme, že se jedná o rozdíl ve prospěch skupiny s medikací (nižší bolest). Nutno se zamyslet nad praktickou významností tohoto rozdílu. „Stojí za to“ pacientům dávat medikaci oproti masáží? Co když je medikace velmi drahá, co když vede k mnoha nežádoucím účinkům, komplikacím atd.??? Pozn.: U velkých vzorků může být i malý rozdíl mezi skupinami statistiky významný. Jak jsme již viděli na předcházejícím příkladu, neznamená to, že statisticky významné rozdíly budeme automaticky propagovat jako ideální řešení nějakého praktického problému. Jinými slovy, i statisticky významné výsledky nakonec nemusí být prakticky použitelné. Je vhodné, aby se nad tímto student zamyslel (a např. tyto úvahy popsal, vyvodil z nich závěry).
 – je > 0,05, jedná se tedy o statisticky významný rozdíl mezi skupinami. Z popisné statistiky již víme, že se jedná o rozdíl ve prospěch skupiny s medikací (nižší bolest). Nutno se zamyslet nad praktickou významností tohoto rozdílu. „Stojí za to pacientům dávat medikaci oproti masáží Co když je medikace velmi drahá, co když vede k mnoha nežádoucím účinkům, komplikacím atd. Pozn.: U velkých vzorků může být i malý rozdíl mezi skupinami statistiky významný. Jak jsme již viděli na předcházejícím příkladu, neznamená to, že statisticky významné rozdíly budeme automaticky propagovat jako ideální řešení nějakého praktického problému. Jinými slovy, i statisticky významné výsledky nakonec nemusí být prakticky použitelné. Je vhodné, aby se nad tímto student zamyslel (a např. tyto úvahy popsal, vyvodil z nich závěry).")
142
Příklad 5: Máme 2 již existující škály pro riziko pádů (škálu č
Příklad 5: Máme 2 již existující škály pro riziko pádů (škálu č. 1 a škálu č. 2). Chceme zkoumat třetí škálu, která se zatím používá pouze v zahraničí a chceme zjistit, zda riziko pádů dle této nové škály lépe koreluje se škálou č. 1 nebo se škálou č. 2. Každá z těchto škál má jiné maximální možné skóre a jiný tzv. cut-off point, tedy hraniční bod, kdy je již pacient považován za rizikového. U škály č. 1 je pacient rizikový, pokud je skóre ≤ 25 (tedy hraniční bod je 25), u škály č. 2 je pacient rizikový, pokud je skóre ≤ 16 A u nové škály je pacient rizikový, pokud je skóre ≤ 18. Každá škála je složena z několika sledovaných kategorií (pohyblivost, úroveň vědomí, atd.), přičemž ne všechny kategorie jsou u každé škály stejné. V každé kategorii je přitom možno získat několik bodů, např. u škály č. 1 je v kategorii pohyblivost možno získat až 4 body, kde 0 = velký problém a 4 = žádný problém. Celkem proběhlo 53 měření na pacientech za použití všech tří škál. V průběhu řešení příkladu budeme pracovat s dichotomizovanými výsledky, tedy s výsledky, kde jednou možností je „pacient je rizikový“ a druhou možností je „pacient je bez rizika“. Například, u škály č. 1 bude pacient rizikový např. pokud je skóre 10, 12, 14, 25 atd. a bez rizika, pokud je skóre 26, 28, 30 atd. Uvidíme, že všichni rizikoví pacienti takto získají skóre „1“ a všichni bezrizikoví pacienti skóre „0“. Data jsou již připravena v programu Microsoft Excel (viz doprovodný materiál), aby se do SPSS mohla snadno přenést kopírováním.
. Chceme zkoumat třetí škálu, která se zatím používá pouze v zahraničí a chceme zjistit, zda riziko pádů dle této nové škály lépe koreluje se škálou č. 1 nebo se škálou č. 2. Každá z těchto škál má jiné maximální možné skóre a jiný tzv. cut-off point, tedy hraniční bod, kdy je již pacient považován za rizikového. U škály č. 1 je pacient rizikový, pokud je skóre ≤ 25 (tedy hraniční bod je 25), u škály č. 2 je pacient rizikový, pokud je skóre ≤ 16. A u nové škály je pacient rizikový, pokud je skóre ≤ 18. Každá škála je složena z několika sledovaných kategorií (pohyblivost, úroveň vědomí, atd.), přičemž ne všechny kategorie jsou u každé škály stejné. V každé kategorii je přitom možno získat několik bodů, např. u škály č. 1 je v kategorii pohyblivost možno získat až 4 body, kde 0 = velký problém a 4 = žádný problém. Celkem proběhlo 53 měření na pacientech za použití všech tří škál. V průběhu řešení příkladu budeme pracovat s dichotomizovanými výsledky, tedy s výsledky, kde jednou možností je „pacient je rizikový a druhou možností je „pacient je bez rizika . Například, u škály č. 1 bude pacient rizikový např. pokud je skóre 10, 12, 14, 25 atd. a bez rizika, pokud je skóre 26, 28, 30 atd. Uvidíme, že všichni rizikoví pacienti takto získají skóre „1 a všichni bezrizikoví pacienti skóre „0 . Data jsou již připravena v programu Microsoft Excel (viz doprovodný materiál), aby se do SPSS mohla snadno přenést kopírováním.")
143
V SPSS nadefinujeme proměnné ve „Variable view“

144
Zkopírujeme data z programu Microsoft Excel do SPSS v „Data view“

145
Nemůžeme provádět korelaci skóre vzhledem k tomu, že maximální možné skóre u každé škály je jiné. Avšak můžeme provést korelaci dichotomizovaných výsledků („riziko ano“ oproti „riziko ne“). Jedná se o nominální proměnné, proto provádíme výpočet korelačního koeficientu phi.
. Jedná se o nominální proměnné, proto provádíme výpočet korelačního koeficientu phi..")
146
Klikneme „Analyze“ – „Descriptive Statistics“ – „Crosstabs“

147
Objeví se rámeček „Crosstabs“ ( = kontingenční tabulka), šipkou přesuneme „škála nová_riziko“ do pole „Row“ ( = řádek) a „škála 1_riziko“ a škála 2_riziko“ do pole „Columns“ (= sloupce).
, šipkou přesuneme „škála nová_riziko do pole „Row ( = řádek) a „škála 1_riziko a škála 2_riziko do pole „Columns (= sloupce).")
148
Klikneme na „Statistics“ a v menším rámečku pak zatrhneme „Phi“, klikneme „Continue“

149
Výsledky

150
Výsledky: kontingenční tabulka – je patrno, že v 36 případech obě škály vedly ke stejnému závěru, že pacient nemá riziko pádu, a v dalších 4 případech ke stejnému závěru, že pacient má riziko pádu. Jinými slovy, škály se shodly ve 40 případech z 53. Avšak škála č. 1 v 11 případech označila pacienta za bezrizikového a přitom nová škála jej označila za rizikového. Jen ve dvou případech škála č. 1 označila pacienta za rizikového zatímco jej nová škála označila za bezrizikového.

151
Výsledky: korelační koeficient je 0,304. Dle autorů Fowler et al
Výsledky: korelační koeficient je 0,304. Dle autorů Fowler et al. (2002) se jedná o slabou korelaci. Avšak korelace je statisticky významná (approx. Sig. < 0,05), tzn., že je nepravděpodobné, že výše uvedená korelace ( i když je slabá) vznikla náhodou.
 se jedná o slabou korelaci. Avšak korelace je statisticky významná (approx. Sig. < 0,05), tzn., že je nepravděpodobné, že výše uvedená korelace ( i když je slabá) vznikla náhodou.")
152
Podobným způsobem zanalyzujeme výsledky získané při porovnání škály č
Podobným způsobem zanalyzujeme výsledky získané při porovnání škály č. 2 oproti nové škále. Škály se shodly celkem ve 44 případech. Počet případů, kdy jedna škála označila jako rizikového a druhá jako bezrizikového a naopak je více méně vyrovnaný (5 případů oproti 4 případům). Korelační koeficient phi je 0,574 – jedná se o střední korelaci, ta je statisticky významná (nevznikla jen náhodou). Celkově lze říci, že nová škála lépe koreluje se škálou č. 2 než se škálou č. 1.
. Korelační koeficient phi je 0,574 – jedná se o střední korelaci, ta je statisticky významná (nevznikla jen náhodou). Celkově lze říci, že nová škála lépe koreluje se škálou č. 2 než se škálou č. 1.")
153
Příklad 6. Tento příklad navazuje na příklad předcházející
Příklad 6. Tento příklad navazuje na příklad předcházející. Vzhledem k tomu, že jak škála č. 1, tak i nová škála obsahují kategorii „pohyblivost“ a v obou případech je v této kategorii možno získat 0–4 body, kde 0 = velký problém a 4 = žádný problém (jediný rozdíl tedy je v tom, jakým způsobem má sestra respondenta hodnotit a jakým je popsán „výkon“ pacienta). Proto je možno vypočítat korelační koeficient u obou škál v této dané kategorii za použití skutečných skóre od 0 do 4 (tedy v tomto případě nebudeme uplatňovat dichotomizované výsledky – ty hrají roli pouze při určování celkového rizika na základě celkového skóre).
. Proto je možno vypočítat korelační koeficient u obou škál v této dané kategorii za použití skutečných skóre od 0 do 4 (tedy v tomto případě nebudeme uplatňovat dichotomizované výsledky – ty hrají roli pouze při určování celkového rizika na základě celkového skóre).")
154
Data v programu Microsoft Excel.

155
V SPSS ve „Variable view“ nadefinujeme proměnné
V SPSS ve „Variable view“ nadefinujeme proměnné. Kategorie „pohyblivost“ má skórování od 0 do 4, je známa definice každé „úrovně“, tu vložíme do „Value Labels“.

156
V SPSS ve „Variable view“ nadefinujeme proměnné
V SPSS ve „Variable view“ nadefinujeme proměnné. Pohyblivost je ordinální proměnná.

157
Pro ordinální proměnné můžeme vypočítat Spearmanův korelační koeficient (není nutné, aby proměnné měly normální distribuci). Aby mohl proběhnout výpočet tohoto korelačního koeficientu, je třeba, aby u pohyblivosti byl typ nadefinován jako „Numeric“.

158
Ujistíme se, že jsme z programu Microsoft Excel zkopírovali příslušná data. Klikneme „Analyze“ – „Correlate“ – „Bivariate“.

159
Za pomoci šipky přesuneme do pravého pole „škála 1_pohyb“ a „škála nová_pohyb“, klikneme na „Spearman“, pak klikneme „Ok“.

160
Korelační koeficient je 0,781 – jedná se tedy o silnou korelaci
Korelační koeficient je 0,781 – jedná se tedy o silnou korelaci. Ta je navíc statisticky významná (a to na hladině 0,01), je tedy velmi nepravděpodobné, že k této korelaci došlo náhodou. V této dané položce tedy škála č. 1 a nová škála velmi dobře korelují.
, je tedy velmi nepravděpodobné, že k této korelaci došlo náhodou. V této dané položce tedy škála č. 1 a nová škála velmi dobře korelují.")
161
Procvičování – příklad 5

162
Procvičování - příklad 5. Máme 37 respondentů
Procvičování - příklad 5. Máme 37 respondentů. Zjistěte, jaká je korelace mezi jejich výškou a jejich výkonem při skoku dalekém. Měření jsou v cm.

163
Pozor na definování chybějících hodnot
Pozor na definování chybějících hodnot. Vybráno číslo „999“, protože „99“ by mohlo představovat skutečnou výšku respondenta (např. malého dítěte) či skutečný výkon na skoku dalekém.
 či skutečný výkon na skoku dalekém.")
164
Zkopírujeme data z programu Microsot Excel
Zkopírujeme data z programu Microsot Excel. Jedná se o poměrový typ proměnné, pro který lze použít Pearsonův korelační koeficient za předpokladu, že proměnné mají normální distribuci.

165
Test normality a získání popisné statistiky

168
Data mají normální rozložení pro všechny výšky.

170
Výpočet Pearsonova korelačního koeficientu.

171
Výsledek

172
Korelační koeficient je 0,834 – jedná se tedy o silnou korelaci
Korelační koeficient je 0,834 – jedná se tedy o silnou korelaci. Ta je navíc statisticky významná (a to na hladině 0,01), je tedy velmi nepravděpodobné, že k této korelaci došlo náhodou. V této dané položce tedy škála č. 1 a nová škála velmi dobře korelují.
, je tedy velmi nepravděpodobné, že k této korelaci došlo náhodou. V této dané položce tedy škála č. 1 a nová škála velmi dobře korelují.")
173
Použité zdroje: Fink A. Conducting research literature reviews. 2010, Sage Publications, Inc., Thousand Oaks, CA, USA. ISBN Fowler J, Jarvis P, Chevannes M. Practical Statistics for Nursing and Health Care. 2009, Wiley & Sons, Chichester, England. ISBN Greenhalgh T. How to read a paper Wiley-Blackwell, London, UK. ISBN IBM SPSS Statistics 19 Core System User’s Guide. Dostupný na

174
Děkuji Vám za pozornost
Projekt Zdravotnické studijní programy v inovaci na FZS Univerzity Pardubice CZ.1.07/2.2.00/ Děkuji Vám za pozornost Tato cvičebnice byla vytvořena v rámci projektu spolufinancovaného z Evropského sociálního fondu a státního rozpočtu ČR.

Podobné prezentace

















>")



