Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
Počet pravděpodobnosti ve statistice
Počet pravděpodobnosti je základem moderní induktivní statistiky. K tomu, aby se ze vzorků a podobných dílčích výsledků mohly odvodit závěry, jejichž vypovídací schopnost lze popsat, je nezbytné, aby výběr z populace byl proveden na principu náhodnosti (náhodný výběr, nezkreslený žádnou systematickou chybou, ne záměrně). Náhoda musí být ponechána „sama sobě“. Matematicky dokonalé a přesné jsou jen metody, jejich výsledkem jsou však odhady a pravděpodobnosti Zdánlivá přesnost statistiky klame jen laika, odborník ví, že statistika je spíše „nauka o odhadu“. Často lze počítat s přesností na mnoho desetinných míst, ale pravděpodobnost končí již před desetinnou čárkou. Pro „státovědnou“ statistiku 18. a 19. století měla pečlivá a přesná zjištění a úzkostlivě přesné matematické operace podstatný význam. Dnešní moderní (induktivní) statistika je naproti tomu převážně uměním určit, za jak nepřesné lze pokládat takové vypočtené údaje, jako je pravděpodobný výsledek, hypotéza či tvrzení.
. Náhoda musí být ponechána „sama sobě . Matematicky dokonalé a přesné jsou jen metody, jejich výsledkem jsou však odhady a pravděpodobnosti. Zdánlivá přesnost statistiky klame jen laika, odborník ví, že statistika je spíše „nauka o odhadu . Často lze počítat s přesností na mnoho desetinných míst, ale pravděpodobnost končí již před desetinnou čárkou. Pro „státovědnou statistiku 18. a 19. století měla pečlivá a přesná zjištění a úzkostlivě přesné matematické operace podstatný význam. Dnešní moderní (induktivní) statistika je naproti tomu převážně uměním určit, za jak nepřesné lze pokládat takové vypočtené údaje, jako je pravděpodobný výsledek, hypotéza či tvrzení.")
2
Binomické rozdělení Pro případy kdy máme dvě možnosti, dvě hodnoty u sledovaného znaku. V praxi je velmi časté, že rozlišujeme „hledaný znak“ a „všechny ostatní“. Pravděpodobnost, že z balíčku karet táhnu „pik“ je p a „všechny ostatní barvy“ je q, platí: p = (1 – q) a tedy p + q = 1 Binomické rozdělení udává, jaká je pravděpodobnost pro určitý výsledek výběrového souboru. Tvoří základnu pro teorii výběrových souborů. Umožňuje nám z přesně známého základního souboru, např. 52 karet, zjistit pravděpodobnost výsledku pro každé pořadí tahů. V praxi při vytváření výběrových souborů základní soubor neznáme, avšak víme, jak je pravděpodobné, že výběrové soubory poskytují jeho skutečný nebo nezkreslený obraz.
 a tedy p + q = 1. Binomické rozdělení udává, jaká je pravděpodobnost pro určitý výsledek výběrového souboru. Tvoří základnu pro teorii výběrových souborů. Umožňuje nám z přesně známého základního souboru, např. 52 karet, zjistit pravděpodobnost výsledku pro každé pořadí tahů. V praxi při vytváření výběrových souborů základní soubor neznáme, avšak víme, jak je pravděpodobné, že výběrové soubory poskytují jeho skutečný nebo nezkreslený obraz.")
3
Binomické rozdělení Př.: Kolik piků bude „pravděpodobně“ taženo, jestliže z dobře zamíchaného balíčku karet táhneme pětkrát za sebou po jedné kartě (a tažená karta se vrací a zamíchá zpět)? Při jednom tahu platí p = 0,25 (Při 5 tazích je „očekávaná“ hodnota 1,25 – to je ale orientační hodnota, pravděpodobnost nemůže být vyšší než 1. Říká nám to, že jeden pik mezi 5 kartami se asi vyskytne poměrně často.) Nejdříve vypočítáme oba extrémy: 5 piků a žádný pik. Protože při našich 5 tazích kartu vždy vracíme, jedná se o nezávislé pnsti, platí pravidlo o násobení pnstí. P5 piků = 0,25* 0,25* 0,25* 0,25* 0,25=(0,25)5 = 0, pouze v jednom z 1000 pokusů Častěji se dá počítat s 5 nepiky: P5 nepiků = (0,75)5 = 0,2373 P 1 pik a 4 nepiky = 0,25 * 0,754 = 0, 0791 jenže tento výsledek může nastat více způsoby, protože jeden pik může být tažen v různém pořadí (jako první, druhý, …). Násobíme tedy 5 = 0,395 V tomto případě lze všechny varianty ještě docela snadno vypočítat, ale ve složitějších případech by to bylo zdlouhavé. V těchto případech se používá Pascalův / aritmetický trojúhelník.
 Při jednom tahu platí p = 0,25. (Při 5 tazích je „očekávaná hodnota 1,25 – to je ale orientační hodnota, pravděpodobnost nemůže být vyšší než 1. Říká nám to, že jeden pik mezi 5 kartami se asi vyskytne poměrně často.) Nejdříve vypočítáme oba extrémy: 5 piků a žádný pik. Protože při našich 5 tazích kartu vždy vracíme, jedná se o nezávislé pnsti, platí pravidlo o násobení pnstí. P5 piků = 0,25* 0,25* 0,25* 0,25* 0,25=(0,25)5 = 0, pouze v jednom z 1000 pokusů. Častěji se dá počítat s 5 nepiky: P5 nepiků = (0,75)5 = 0,2373. P 1 pik a 4 nepiky = 0,25 * 0,754 = 0, 0791 jenže tento výsledek může nastat více způsoby, protože jeden pik může být tažen v různém pořadí (jako první, druhý, …). Násobíme tedy 5 = 0,395. V tomto případě lze všechny varianty ještě docela snadno vypočítat, ale ve složitějších případech by to bylo zdlouhavé. V těchto případech se používá Pascalův / aritmetický trojúhelník.")
4
Binomické rozdělení Pascalův, aritmetický trojúhelník Vrstva jedniček obklopuje trojúhelník, ve kterém je každé číslo složeno ze součtu obou šikmo nad ním. Představme si římskou kašnu, nahoře stéká jednotka vody, v následujícím stupni se dělí na ½ a ½, na třetím stupni na ¼ + ½ + ¼ atd. což přesně odpovídá výsledkům házení mincí. Z jednotlivých řádků lze vyčíst nahodilé pravděpodobnosti jevů všeho druhu.

5
Binomické rozdělení S Pascalovým trojúhelníkem souvisí i binomická poučka (a + b)2 = a2 + 2ab + b2 = 1 (a2) + 2 (ab) + 1 (a2) (a + b)3 = a3 + 3a2b + 3ab2 + b3 5. řádek pascalova trojúhelníku je 1 – 5 – 10 – 10 – 5 – 1 a proto (a + b)5 = a5 + 5a4b + 10a3b a2b3 + 5ab4 + b5 za a a b se dosadí p a q hledáme případ 1 pik a 4 nepiky a pak násobíme 5 (protože 5. člen výrazu je násoben 5), viz výpočet výše a = nepik, b = pik a5 (0,75)5 = 0,24 5a4b 5(0,25)4(0,75) = 0,01 10a3b2 10(0,25)3(0,75)2 = 0,09 10a2b3 10(0,25)2(0,75)3 = 0,26 5ab4 5(0,25)(0,75) 4 = 0,40 b5 (0,25)5 = 0,001
3 = a3 + 3a2b + 3ab2 + b3. 5. řádek pascalova trojúhelníku je 1 – 5 – 10 – 10 – 5 – 1. a proto (a + b)5 = a5 + 5a4b + 10a3b2 + 10a2b3 + 5ab4 + b5. za a a b se dosadí p a q. hledáme případ 1 pik a 4 nepiky a pak násobíme 5 (protože 5. člen výrazu je násoben 5), viz výpočet výše. a = nepik, b = pik. a5 (0,75)5 = 0,24. 5a4b 5(0,25)4(0,75) = 0,01. 10a3b2 10(0,25)3(0,75)2 = 0,09. 10a2b3 10(0,25)2(0,75)3 = 0,26. 5ab4 5(0,25)(0,75) 4 = 0,40. b5 (0,25)5 = 0,001.")
6
Normální rozdělení Slovo normální navozuje (neoprávněně) jakési souhlasné hodnocení. Je to myšlenkový model a početní pomůcka pro induktivní statistiku, tedy tam, kde se snažíme usuzovat o (pravděpodobné podobě) celku na základě dat z výběru, z dílčích pozorování (není to „přírodní zákon“). Teorie a praxe prokázaly správnost domněnky, že normální rozdělení platí pro téměř všechny výběry a rozdělení podchytitelných souborů. Jedním z prvních příkladů normálního rozdělení je Quételetovo měření obvodu prsou skotských vojáků (v průměru 39,5 coulů).
 celku na základě dat z výběru, z dílčích pozorování (není to „přírodní zákon ). Teorie a praxe prokázaly správnost domněnky, že normální rozdělení platí pro téměř všechny výběry a rozdělení podchytitelných souborů. Jedním z prvních příkladů normálního rozdělení je Quételetovo měření obvodu prsou skotských vojáků (v průměru 39,5 coulů).")
7
Normální rozdělení Grafickým zobrazením je normální křivka (zvonovitá křivka, Gaussova křivka rozdělení chyb, de Moivrova stochastika, křivka policejního klobouku). V závislosti na zvoleném měřítku je křivka strmější nebo plošší. Normální rozdělení je vždy jednoznačně určeno střední hodnotou (zpravidla průměrem, ale i modusem či mediánem) a rozptylem. Normální rozdělení má největší četnost uprostřed a je symetrické. Principem normálního rozdělení je to, že bezpočetné znaky a jejich hodnoty jsou rozloženy tak, že jeden výsledek měření je „nejčetnější“ a „na obě strany od něho“ jsou výsledky ponenáhlu stále méně četné, až konečně vykazují jen ojedinělou extrémní hodnotu.
. V závislosti na zvoleném měřítku je křivka strmější nebo plošší. Normální rozdělení je vždy jednoznačně určeno střední hodnotou (zpravidla průměrem, ale i modusem či mediánem) a rozptylem. Normální rozdělení má největší četnost uprostřed a je symetrické. Principem normálního rozdělení je to, že bezpočetné znaky a jejich hodnoty jsou rozloženy tak, že jeden výsledek měření je „nejčetnější a „na obě strany od něho jsou výsledky ponenáhlu stále méně četné, až konečně vykazují jen ojedinělou extrémní hodnotu.")
8
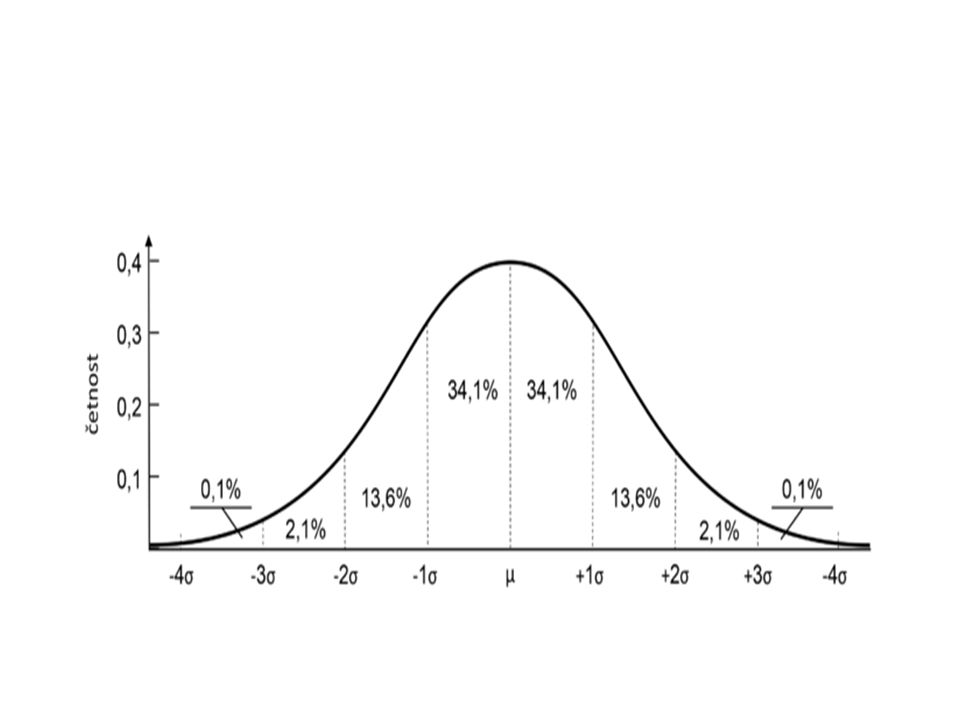
Normální rozdělení Jestliže pozorujeme plochu pod křivkou jako soubor, leží na obě strany od maxima (nejčetnější hodnota střední hodnoty) vždy přesně stejně velké části této plochy: Mezi +σ a – σ leží 68,26 % (tedy o něco více než 2/3 celkové plochy) Mezi +2σ a – 2σ leží skoro přesně 95 % Mezi +3σ a – 3σ leží skoro 99,7 % Hodnoty za třemi směrodatnými odchylkami se berou v potaz jen zřídka, i když teoreticky se normální křivka rozkládá od + ∞ do - ∞ Tímto postupem do nekonečna a plynulým průběhem se normální křivka liší od binomického rozdělení. Přesto je však mezi těmito oblastmi tak těsná souvislost, že normální rozdělení je možno v téměř všech případech pokládat za dostatečně přesné vyjádření binomického rozdělení.
 vždy přesně stejně velké části této plochy: Mezi +σ a – σ leží 68,26 % (tedy o něco více než 2/3 celkové plochy) Mezi +2σ a – 2σ leží skoro přesně 95 % Mezi +3σ a – 3σ leží skoro 99,7 % Hodnoty za třemi směrodatnými odchylkami se berou v potaz jen zřídka, i když teoreticky se normální křivka rozkládá od + ∞ do - ∞ Tímto postupem do nekonečna a plynulým průběhem se normální křivka liší od binomického rozdělení. Přesto je však mezi těmito oblastmi tak těsná souvislost, že normální rozdělení je možno v téměř všech případech pokládat za dostatečně přesné vyjádření binomického rozdělení.")
9
Normální rozdělení Cenná pomůcka statistické práce
Nesčetné dílčí vlivy vyvolávají větší nebo menší odchylky od průměru, který všude nacházíme a tato náhodná kombinace náhodných vlivů podléhá zákonům „hazardní hry“, pravidlům binomického rozdělení s téměř nekonečným počtem pokusů. Většina jevů v přírodě má normální rozložení (na stromě je málo hodně malých a hodně velkých listů, nejvíce je těch, co jsou nejblíž průměru). Historie normální křivky Objevena 1733 Abrahamem de Moivre, pak ale křivka upadla v zapomnění, až se objevil praktický problém, k jemuž řešení pomáhá a tehdy byla znovuobjevena jako Gaussova-Laplaceova křivka chyb. Astronomové totiž díky nedokonalým přístrojům na konci 18. a na poč. 19. stol. stáli před nepříjemnou situací, kdy při svých měřeních získávali hodnoty, které se od sebe více nebo méně lišily. Bylo třeba nalézt cestu, jak ze spousty naměřených dat získat hodnotu co nejvíce se blížící skutečnosti. Původně se Gauss domníval, že touto nejsprávnější hodnotou je průměr všech měření, potom ale došel podobně jako Laplace k představě rozdělení četností výsledků měření: zcela nesprávné jsou ojedinělé výsledky, pak následují měření stále si více podobná a zároveň četnější, četnost pak doslova vrcholí ve střední hodnotě.
. Historie normální křivky. Objevena 1733 Abrahamem de Moivre, pak ale křivka upadla v zapomnění, až se objevil praktický problém, k jemuž řešení pomáhá a tehdy byla znovuobjevena jako Gaussova-Laplaceova křivka chyb. Astronomové totiž díky nedokonalým přístrojům na konci 18. a na poč. 19. stol. stáli před nepříjemnou situací, kdy při svých měřeních získávali hodnoty, které se od sebe více nebo méně lišily. Bylo třeba nalézt cestu, jak ze spousty naměřených dat získat hodnotu co nejvíce se blížící skutečnosti. Původně se Gauss domníval, že touto nejsprávnější hodnotou je průměr všech měření, potom ale došel podobně jako Laplace k představě rozdělení četností výsledků měření: zcela nesprávné jsou ojedinělé výsledky, pak následují měření stále si více podobná a zároveň četnější, četnost pak doslova vrcholí ve střední hodnotě.")
10
Normální rozdělení Normální rozdělení (křivku) „proslavil“ Adolhe-Lamberte Quételet (zakladatel mezinárodní statistické společnosti), když ji aplikoval mimo jiné v biometrii při měření obvodu prsou skotských vojáků. Dospěl k závěru, že nepřihlížíme-li k poměru střední hodnoty a rozptylu, uspořádání velké spousta biometrických a dalších měření vykazuje přesně stejnou strukturu „chyb měření“, „křivku chyb“, normální rozdělení. Zřejmě byl prvním kdo mluvil o „normálním rozdělení“ - tedy dnes užívané označení. Podle Quételeta se příroda snaží vytvořit „ideální typ“ (homme moyen – „průměrný člověk“), ale v různé míře chybuje. Tato myšlenka měla velkou odezvu jak mezi jejími stoupenci tak odpůrci, kteří varovali před zveličováním filozofického rozměru tohoto rozdělení. Karl Pearson (obdivovatel normální křivky) objevil, že v přírodě se vyskytují i „nenormálně“ rozdělené veličiny (i když zároveň zjistil, že mnohá z nich se dají odvodit ze spletence více normálních rozdělení) např. věkové složení obyvatelstva, rozdělení příjmů mezi lidmi atd.
 „proslavil Adolhe-Lamberte Quételet (zakladatel mezinárodní statistické společnosti), když ji aplikoval mimo jiné v biometrii při měření obvodu prsou skotských vojáků. Dospěl k závěru, že nepřihlížíme-li k poměru střední hodnoty a rozptylu, uspořádání velké spousta biometrických a dalších měření vykazuje přesně stejnou strukturu „chyb měření , „křivku chyb , normální rozdělení. Zřejmě byl prvním kdo mluvil o „normálním rozdělení - tedy dnes užívané označení. Podle Quételeta se příroda snaží vytvořit „ideální typ (homme moyen – „průměrný člověk ), ale v různé míře chybuje. Tato myšlenka měla velkou odezvu jak mezi jejími stoupenci tak odpůrci, kteří varovali před zveličováním filozofického rozměru tohoto rozdělení. Karl Pearson (obdivovatel normální křivky) objevil, že v přírodě se vyskytují i „nenormálně rozdělené veličiny (i když zároveň zjistil, že mnohá z nich se dají odvodit ze spletence více normálních rozdělení) např. věkové složení obyvatelstva, rozdělení příjmů mezi lidmi atd.")
11
Normální normované rozdělení
I když jsou normální křivky pravidelné, symetrické a stejnorodé (bod obratu křivky leží vždy ve vzdálenosti + - σ, tečna v bodu obratu vždy protíná osu x ve vzdálenosti 2 σ a -2 σ, teoreticky je křivka rozložena do nekonečna, ale prakticky se při σ dotýká osy x), praktický význam získávají až standardizací (normováním). Struktura a vlastnosti normálního rozdělení se nemění, vždy je normální rozložení jednoznačně dáno poměrem průměru a směrodatné odchylky, nezáleží tedy na „jednotkách a na měřítku“. Průměr standardizované (normované) normální křivky se rovná nule (odchylky jsou tak +- „zrcadlové“ se stejnou „hodnotou“ jednou s + a podruhé s -). N (0,1) Rozdělení v normovaném normálním rozdělení záleží jen na „relativní“ )vzhledem ke střední hodnotě) velikosti směrodatné odchylky. Plocha po křivkou vyjadřuje celkovou pravděpodobnost výskytu daných hodnot (v rozmezí, nebo jen – nebo + nějaká hodnota) její úhrn je vždy 1, tedy p = 1. Nebo-li kolik % případů je mimo toleranční mez. Normovaná hodnota (z) = hodnota minus aritmetický průměr /směrodatná odchylka z = (x - µ)/σ z je vlastně normovaná směrodatná odchylka = standardizovaná (normalizovaná) odchylková veličina, je to hodnota, podle které se hledá v tabulkách označuje se různě: a, x, λ, „normální proměnná“, x/ σ, z, t
, praktický význam získávají až standardizací (normováním). Struktura a vlastnosti normálního rozdělení se nemění, vždy je normální rozložení jednoznačně dáno poměrem průměru a směrodatné odchylky, nezáleží tedy na „jednotkách a na měřítku . Průměr standardizované (normované) normální křivky se rovná nule (odchylky jsou tak +- „zrcadlové se stejnou „hodnotou jednou s + a podruhé s -). N (0,1) Rozdělení v normovaném normálním rozdělení záleží jen na „relativní )vzhledem ke střední hodnotě) velikosti směrodatné odchylky. Plocha po křivkou vyjadřuje celkovou pravděpodobnost výskytu daných hodnot (v rozmezí, nebo jen – nebo + nějaká hodnota) její úhrn je vždy 1, tedy p = 1. Nebo-li kolik % případů je mimo toleranční mez. Normovaná hodnota (z) = hodnota minus aritmetický průměr /směrodatná odchylka. z = (x - µ)/σ. z je vlastně normovaná směrodatná odchylka = standardizovaná (normalizovaná) odchylková veličina, je to hodnota, podle které se hledá v tabulkách. označuje se různě: a, x, λ, „normální proměnná , x/ σ, z, t.")
12
Normální normované rozdělení
Jak zacházet s tabulkami pravděpodobnosti? Hledáme hodnoty Φ (čti fí), tj. pravděpodobnosti, že standardizované směrodatné proměnné byly překročeny. Pravděpodobnosti se uvádí pro horní konec. Je-li „fí“ bez hvězdičky , označuje plošný podíl pod normální křivkou až k hledanému bodu – na obě strany a jeli Φ* pak plošný podíl na jednu stranu. Většina tabulek pracuje s polovinou plochy, tedy na jednu stranu. V záhlaví tabulek pravděpodobností bývá obrázek – vysvětlující nákres normální křivky nebo příklad použití hodnot z tabulek. Tento plošný podíl symbolizuje pravděpodobnost hledaného jevu.
, tj. pravděpodobnosti, že standardizované směrodatné proměnné byly překročeny. Pravděpodobnosti se uvádí pro horní konec. Je-li „fí bez hvězdičky , označuje plošný podíl pod normální křivkou až k hledanému bodu – na obě strany a jeli Φ* pak plošný podíl na jednu stranu. Většina tabulek pracuje s polovinou plochy, tedy na jednu stranu. V záhlaví tabulek pravděpodobností bývá obrázek – vysvětlující nákres normální křivky nebo příklad použití hodnot z tabulek. Tento plošný podíl symbolizuje pravděpodobnost hledaného jevu.")
14
Jiná rozdělení „Je mnoho věcí mezi nebem a zemí o kterých se normální křivce ani nezdá.“ V případech, kdy je nejčetnější hodnota blízko nuly, ale nelze předpokládat záporné výsledky (př. počet dětí v rodinách). Normální rozdělení se zde nehodí, protože naráží na bariéru nuly, která je zešikmuje. „Šikmost“ měří horizontální odchylku rozdělení od normálního rozdělení. Doplněk k němu je „exces“, jenž křiví zvonovitý tvar normální křivky ve svislém směru, tzn., že zvon je příliš strmý nebo příliš plochý. Je-li šikmost tak výrazná, že křivka dosahuje při nejnižších hodnotách nejvyšší četnosti (pokud by např. bezdětná manželství byla nejčastější), vzniká tak křivka L. L rozdělení se zprava zplošťuje. Je to rozdělení všech krásných a vzácných věcí (kromě dětí také např. příjmů). J rozdělení, J křivky jsou méně časté, protože neomezená možnost rozšíření vpravo přece jen vede dříve nebo později ke zploštění (mohou vzniknout tedy tam, kde je vpravo výrazná nepřekročitelná hranice). Rozdělení U je kombinací L a J rozdělení, je dvouvrcholové. (pravděpodobnost úmrtí podle věku).
. Normální rozdělení se zde nehodí, protože naráží na bariéru nuly, která je zešikmuje. „Šikmost měří horizontální odchylku rozdělení od normálního rozdělení. Doplněk k němu je „exces , jenž křiví zvonovitý tvar normální křivky ve svislém směru, tzn., že zvon je příliš strmý nebo příliš plochý. Je-li šikmost tak výrazná, že křivka dosahuje při nejnižších hodnotách nejvyšší četnosti (pokud by např. bezdětná manželství byla nejčastější), vzniká tak křivka L. L rozdělení se zprava zplošťuje. Je to rozdělení všech krásných a vzácných věcí (kromě dětí také např. příjmů). J rozdělení, J křivky jsou méně časté, protože neomezená možnost rozšíření vpravo přece jen vede dříve nebo později ke zploštění (mohou vzniknout tedy tam, kde je vpravo výrazná nepřekročitelná hranice). Rozdělení U je kombinací L a J rozdělení, je dvouvrcholové. (pravděpodobnost úmrtí podle věku).")
15
Poissonovo rozdělení Je to speciální rozdělení pro nepatrné pravděpodobnosti, početní schéma pro řídké události, kdy nelze použít binomické rozdělení. Objevitelem je francouzský matematik Poisson. Německý statistik Bortkiewitz sestavil tabulku Poissonova rozdělení pro počty úmrtní vojenských osob zabitých úderem koňského kopyta. Zjistil, že u souboru armádní sbor/rok nebyl ve 109 případech žádný úraz, 65krát se objevil jeden takový smrtelný úraz, u 22 armádních sborů se za rok objevila 2 taková úmrtí, 3 krát tři úmrtí, jedenkrát dokonce 4 úmrtí. Tedy celkový počet smrtelných případů je 122 (= 109*0 + 65*1 + 22*3 + 3*3 + 4*1) „Očekávaná hodnota smrtelných případů na armádní sbor za rok je 0,61
 „Očekávaná hodnota smrtelných případů na armádní sbor za rok je 0,61.")
16
Poissonovo rozdělení Na rozdíl od normálního rozdělení je poissonovo určeno pouze jedním parametrem λ.+ px = e-λ * λx/x! λ = očekávaná hodnota x = počet hledaných jevů e = 2,718 (základ přirozených logaritmů, e je souhrnem nekonečné řady a zároveň mezní hodnotou, e je extrémní výsledek výpočtu úroků z úroků, e je vyjádřením nekonečného postupného dělení časových úseků, e = 1/0! + 1/1! + ½! + 1/3! + ¼! + … Očekávaná hodnota je 0,61 a nyní hledáme pravděpodobnost, že jev nastane 0krát p0 = e-0,61 * 0,610/0! = 0,543*1/1 = 0,543 Z celého pole pravděpodobnosti tedy v o něco více než polovině případů se vyskytne „nulový jev“, tedy jev se nevyskytne (u poloviny souborů daných armádní sbor za rok nenastane žádné úmrtní úderem koňského kopyta). Tedy ve 543 případech z 1000, ve 109 z 200. V dalším kroku dosadíme za x = 1, pak x = 2 atd.
. Tedy ve 543 případech z 1000, ve 109 z 200. V dalším kroku dosadíme za x = 1, pak x = 2 atd.")
17
Poissonovo rozdělení Vypočítané pravděpodobnosti podle Poissonova rozdělení: Skutečnost: 0 mrtví p0 = 0,543 (543 z 1000, tedy 109 z 200) 109 1 mrtví p1 = 0,331 (331 z 1000, tedy 66 z 200) 2 mrtví p2 = 0,101 (101 z 1000, 20 z 200) 3 mrtví p3 = 0,021 (4 z 200) 4 mrtví p4 = 0, 003 (0,6 z 200) Poissonovo rozdělení se typicky používá např. pro výpočet pravděpodobnosti úrazů při…, pro počet nějakých řídkých událostí v čase
 mrtví p2 = 0,101 (101 z 1000, 20 z 200) mrtví p3 = 0,021 (4 z 200) 3. 4 mrtví p4 = 0, 003 (0,6 z 200) 1. Poissonovo rozdělení se typicky používá např. pro výpočet pravděpodobnosti úrazů při…, pro počet nějakých řídkých událostí v čase.")
Podobné prezentace



















 4. předn.1 Statistika (D360P03Z) akademický rok 2004/2005 doc. RNDr. Karel Zvára, CSc. KPMS MFF UK>")