Stáhnout prezentaci
Prezentace se nahrává, počkejte prosím

1
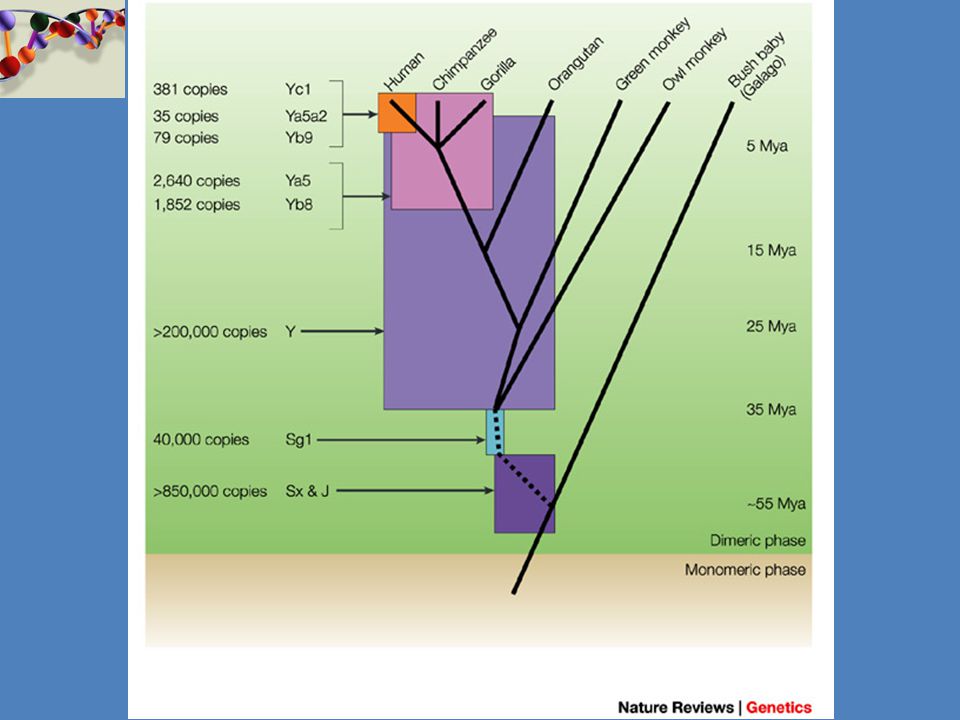
Možnosti identifikace osoby prostřednictvím analýzy DNA

2
cca 3 miliardy nukleotidů (2x)
MALÉ REVIEW SLOVNÍČEK: Gen = funkční (exprimovaný) úsek DNA Lokus = jakýkoli úsek či místo v DNA Marker = znak DNA užívaný při testování Alela = konkrétní varianta(forma) genu/lokusu/markeru Polymorfismus = existence více alel v témže genu/lokusu/markeru Lidský genom cca 3 miliardy nukleotidů (2x) max 10% kódující (geny), 90% nekódující max 30 tisíc genů
 úsek DNA. Lokus = jakýkoli úsek či místo v DNA. Marker = znak DNA užívaný při testování. Alela = konkrétní varianta(forma) genu/lokusu/markeru. Polymorfismus = existence více alel v témže genu/lokusu/markeru. Lidský genom. cca 3 miliardy nukleotidů (2x) max 10% kódující (geny), 90% nekódující. max 30 tisíc genů.")
3
INDIVIDUALITA V čem tkví genetická jedinečnost?
Nepolymorfní gen/lokus/marker Nízce polymorfní gen/lokus/marker Vysoce polymorfní gen/lokus/marker

4
INDIVIDUALITA V čem tkví genetická jedinečnost? GENETICKÝ PROFIL
Vysoce polymorfní lokus 1 Vysoce polymorfní lokus 2 Vysoce polymorfní lokus 3 Vysoce polymorfní lokus 4 Vysoce polymorfní lokus 5

5
V čem tkví genetická jedinečnost?
INDIVIDUALITA V čem tkví genetická jedinečnost? VNTR 1986 2000 201X? STR SNP

6
co máme v genomu 90% nekódující sekvence
méně než 50% jedinečné sekvence 10% kódující sekvence a spol. přes 50% repetitivní sekvence

7
co máme v genomu Nuclear genome 3000 Mb 65-80000 genes
Mitochondrial genome 16.6 kb 37 genes 30% 70% Genes and gene- related sequences Extragenic DNA Two rRNA genes 22 tRNA genes 13 polypeptide- encoding genes 80% 20% Unique or moderately repetitive 10% 90% Unique or low copy number Moderate to highly repetitive Coding DNA Noncoding DNA Pseudogenes Gene fragments Introns, untranslated sequences, etc. Tandemly repeated or clustered repeats Interspersed repeats

8
Míra variability lokusů v genomu
ROSTE S: mutační rychlostí lokusu (HOT SPOTS) stářím lokusu evoluční výhodou variability (pozitivním selekčním tlakem na nové mutace) (např. HLA) KLESÁ S: účinností reparačních mechanismů (nDNA vs. mtDNA) negativním selekčním tlakem na nové mutace (GENY)
 stářím lokusu. evoluční výhodou variability (pozitivním selekčním tlakem na nové mutace) (např. HLA) KLESÁ S: účinností reparačních mechanismů (nDNA vs. mtDNA) negativním selekčním tlakem na nové mutace (GENY)")
9
Srovnání typických genomů

10
repetitivní sekvence rozptýlené krátký motiv dlouhý motiv tandemové
LINE SINE VNTR STR krátký motiv dlouhý motiv tandemové

11
Rozptýlené repetitivní sekvence
Většina rozptýlených repetic má původ v transpozibilních elementech DNA transpozony gen pro transpozázu + na obou koncích invertovaná repetitivní sekvence (vzniká útvar stopka-očko) mechanismus cut´n´paste (jako při zrání imunoglobulinů a TLR) u lidí už neaktivní (mutace), ale…!!! Retrotranspozony pro skákání používají buněčné RNA polymerázy mechanismus copy´n´paste u lidí aktivní, tvoří přes 45% genomu, aktivní je jen každá cca 100 kopie (mutace) jsou buď autonomní (kódují potřebné proteiny), nebo neautonomní (využívají proteinový aparát jiných transpozónů)
 mechanismus cut´n´paste (jako při zrání imunoglobulinů a TLR) u lidí už neaktivní (mutace), ale…!!! Retrotranspozony. pro skákání používají buněčné RNA polymerázy. mechanismus copy´n´paste. u lidí aktivní, tvoří přes 45% genomu, aktivní je jen každá cca 100 kopie (mutace) jsou buď autonomní (kódují potřebné proteiny), nebo neautonomní (využívají proteinový aparát jiných transpozónů)")
12
LTR retrotranspozony – endogenní retroviry
připomínají svým složením proviry skutečných retrovirů obsahují LTR (long terminal repeats, dlouhé terminální repetice) a geny gag, pol, env a prt alespoň jeden z genů nezbytných pro sestavení infekčních virových částic je mutován nebo chybí → mohou se pohybovat pouze uvnitř buněk životní cyklus podobný infekčním retrovirům jako je HIV lidský genom v současné době obsahuje pouze fosilie endogenních retrovirů – cca 8% genomu Intaktní endogenní retroviry dlouhé 7-9 kb, ale také mnoho zkrácených často lze najít pouze samostatné LTR
 a geny gag, pol, env a prt. alespoň jeden z genů nezbytných pro sestavení infekčních virových částic je mutován nebo chybí → mohou se pohybovat pouze uvnitř buněk. životní cyklus podobný infekčním retrovirům jako je HIV. lidský genom v současné době obsahuje pouze fosilie endogenních retrovirů – cca 8% genomu. Intaktní endogenní retroviry dlouhé 7-9 kb, ale také mnoho zkrácených. často lze najít pouze samostatné LTR.")
13
non-LTR retrotranspozony LINE = long interspearsed nuclear elements
autonomní retrotranspozóny cca 21% lidského genomu rozeznáváme různé rodiny – LINE1 (L1), LINE 2, LINE 3 … LINE1 jsou aktivní (17% genomu) – kopií, z toho cca 100 stále schopno transpozice aktivní element L1 je dlouhý cca 6 kb obsahuje ORF1 (?) a ORF2 (reverzní transkriptáza)
, LINE 2, LINE 3 … LINE1 jsou aktivní (17% genomu) – kopií, z toho cca 100 stále schopno transpozice. aktivní element L1 je dlouhý cca 6 kb. obsahuje ORF1 ( ) a ORF2 (reverzní transkriptáza)")
14
neautonomní retrotranspozony
SINE = short interspearsed nuclear elements typicky kratší než 500 bp nejpočetnější rodinou jsou Alu repetice Alu mohou být náhodně aktivní (11% genomu) – kopií obsahují sekvenci 282 bp - patrně odvozena z RNA podjednotky SRP (7SL RNA) SRP = signal recognition particle - ribonukleoproteinový komplex - rozpoznává signální peptid, váže se na něj a přemístí komplex ribozom-mRNA-nascentní peptid ke kanálu endoplazmatického retikula (ER), skrz nějž je nascetní peptid translokován do lumenu ER nebo integrován v membráně ER Alu se tak může vázat na ribozom a díky svému "ocasu" bohatému na adenin také (pokud ribozom zrovna zpracovává LINE-1 mRNA) na nascentní protein ORF2 a zneužít ORF2 k reverzní transkripci a integraci vlastní RNA a nikoli LINE-1
 – kopií. obsahují sekvenci 282 bp - patrně odvozena z RNA podjednotky SRP (7SL RNA) SRP = signal recognition particle - ribonukleoproteinový komplex - rozpoznává signální peptid, váže se na něj a přemístí komplex ribozom-mRNA-nascentní peptid ke kanálu endoplazmatického retikula (ER), skrz nějž je nascetní peptid translokován do lumenu ER nebo integrován v membráně ER. Alu se tak může vázat na ribozom a díky svému ocasu bohatému na adenin také (pokud ribozom zrovna zpracovává LINE-1 mRNA) na nascentní protein ORF2 a zneužít ORF2 k reverzní transkripci a integraci vlastní RNA a nikoli LINE-1.")
16
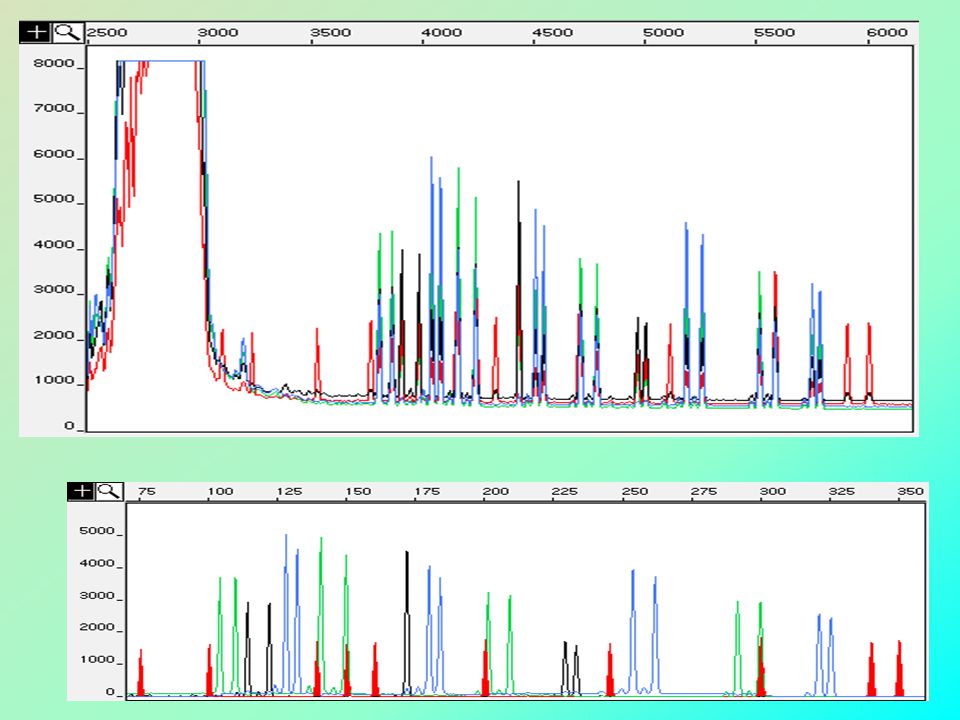
funkce transpozónů junk DNA, selfish DNA…
ze širšího hlediska – důležitá role – zvyšuje plasticitu genomu vyřazení genu z provozu změna exprese genu transpozice jinak netranspozibilních elementů (svezou se) indukce delecí, inverzí geny odvozené z transpozónů podpora mezichromozomového nerovnoměrného crosing-overu nebo intrachromozomové rekombinace uvažuje se o tom, že by transpozony mohly mít nějakou reálnou fyziologickou funkci, např. proto, že jejich exprese je obecně zvýšena během stresové odpovědi
 indukce delecí, inverzí. geny odvozené z transpozónů. podpora mezichromozomového nerovnoměrného crosing-overu nebo intrachromozomové rekombinace. uvažuje se o tom, že by transpozony mohly mít nějakou reálnou fyziologickou funkci, např. proto, že jejich exprese je obecně zvýšena během stresové odpovědi.")
17
tandemově repetitivní sekvence
VYSOCE REPETITIVNÍ NÍZCE REPETITIVNÍ α-satelity minisatelity = VNTR mikrosatelity = STR SINGLE COPY SEKVENCE rRNA, tRNA a histonové geny

18
α-satelitní DNA primární jednotka dlouhá 171 bp
tvoří funkční jádro centromery některé proteiny kinetochory se váží na alfa satelit v centromeře a tím zahajují sestavování kinetochory

19
minisatelitní DNA = LTR (dlouhé tandemové)
primární jednotka (motiv) dlouhá řádově desítky bazí – vzniká z mikrosatelitů více se vyskytují v subtelomerických oblastech chromozómů lze sem zařadit i cíleně vznikající TTAGGG repetice v oblasti telomer
 dlouhá řádově desítky bazí – vzniká z mikrosatelitů. více se vyskytují v subtelomerických oblastech chromozómů. lze sem zařadit i cíleně vznikající TTAGGG repetice v oblasti telomer.")
20
VNTR – co to je? VNTR (Variable Number of Tandem Repeats) označuje vlastně obecně jev, na němž byly založeny první identifikace, tj. existenci variability počtu opakování motivu v repetici tyto první testy prováděl Alec Jeffreys
 označuje vlastně obecně jev, na němž byly založeny první identifikace, tj. existenci variability počtu opakování motivu v repetici. tyto první testy prováděl Alec Jeffreys.")
21
VNTR Jeffreys studoval gen pro myoglobin
zjistil, že v jednom z intronů je repetitivní sekvence rozhodl se ji studovat tak, že vytvoří specifickou sondu, provede restrikci a vzniklou směs fragmentů bude hybridizovat se sondou sonda však nenašla jen jedno, ale celou řadu cílových míst – vznikl hybridizační vzor Jeffreys zjistil, že tento vzor je různý u různých osob způsob, jak zobrazit jedinečnost genomu, byl objeven

22
metoda se nazývá RFLPs DNA je inkubována s restriktázou
Mnoho možností, které restriktázy užít (i kombinace více restriktáz) DNA lze poté zviditelnit s použitím specifické sondy – výsledný hybridizační obraz je u různých osob různý (Restriction Fragment Length Polymorphisms) Délkový i sekvenční polymorfismus!!!
 DNA lze poté zviditelnit s použitím specifické sondy – výsledný hybridizační obraz je u různých osob různý (Restriction Fragment Length Polymorphisms) Délkový i sekvenční polymorfismus!!!")
23
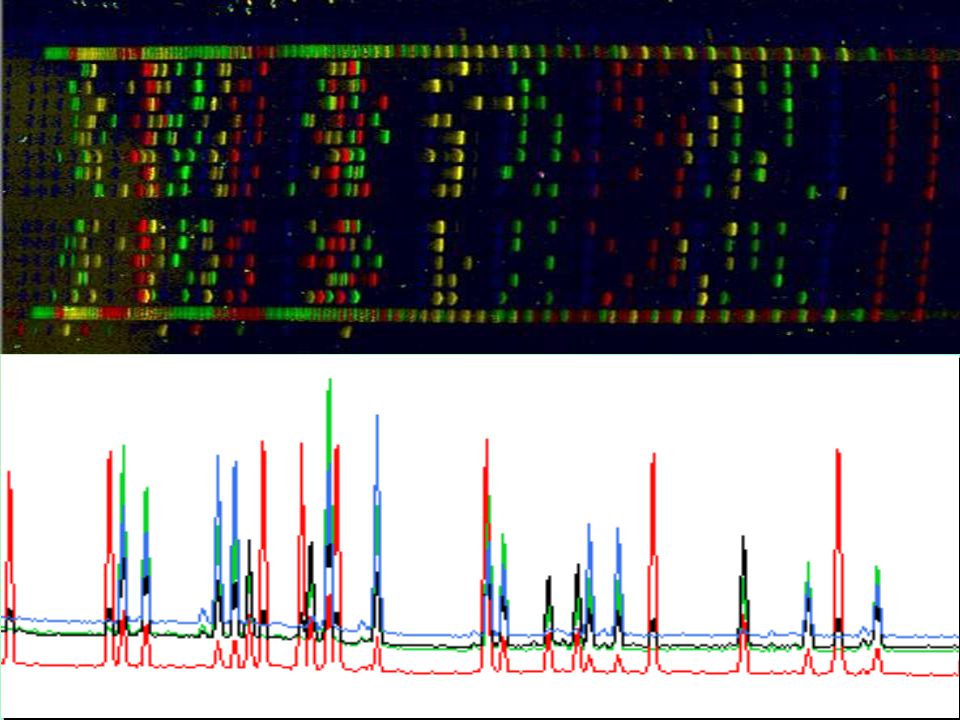
RFLP: Elektroforéza

24
RFLP: Autoradiogram

25
Jak jedinečné tyto obrazce jsou?
Těžko říct… The probability of 2 people having exactly the same DNA profile is between 1 in 5 million to 1 in 100 billion (greater than the population of humans on earth) This number becomes even larger if you consider more regions of DNA Thus, the odds that the DNA evidence from a crime scene will match your DNA profile is astronomically small (unless you have an evil identical twin)
 This number becomes even larger if you consider more regions of DNA. Thus, the odds that the DNA evidence from a crime scene will match your DNA profile is astronomically small (unless you have an evil identical twin)")
26
mikrosatelitní DNA = STR
primární jednotka (motiv) dlouhá řádově jednotky bazí (do 10 bp) počet opakování motivu v jednom lokusu řádově jednotky až stovky nejčastější jsou dinukleotidové (CA)n po celém genomu, ve valné většině mimo geny, ale jsou výjimky onemocnění z expanze trinukleotidových repetic Huntingtonova chorea huntingtin - repetitivní sekvence (CAG)n v exonu kóduje úsek bílkoviny tvořený zbytky glutaminu doména pro interakce s jinými proteiny normálně do 20 Glu, nad 30 Glu začíná problém myotonická dystrofie DMPK - repetitivní sekvence (CTG)n v nepřekládané 3´části genu při expanzi je mRNA patogenní – sekvestrace (odlučování) transkripčních faktorů
 dlouhá řádově jednotky bazí (do 10 bp) počet opakování motivu v jednom lokusu řádově jednotky až stovky. nejčastější jsou dinukleotidové (CA)n. po celém genomu, ve valné většině mimo geny, ale jsou výjimky. onemocnění z expanze trinukleotidových repetic. Huntingtonova chorea. huntingtin - repetitivní sekvence (CAG)n v exonu kóduje úsek bílkoviny tvořený zbytky glutaminu. doména pro interakce s jinými proteiny. normálně do 20 Glu, nad 30 Glu začíná problém. myotonická dystrofie. DMPK - repetitivní sekvence (CTG)n v nepřekládané 3´části genu. při expanzi je mRNA patogenní – sekvestrace (odlučování) transkripčních faktorů.")
27
mají STR nějakou funkci?
možná ano…! mnoho indicií, žádné nezvratné důkazy… některé dinukleotidy asi spojeny s regulací genové exprese (jsou před promotorem) některé dinukleotidy asi fungují jako rekombinační hot-spoty některé ale asi opravdu k ničemu
 některé dinukleotidy asi fungují jako rekombinační hot-spoty. některé ale asi opravdu k ničemu.")
28
klasifikace STR dle délky motivu: mono- -AAAAAA- di- -TATATA-
tri- -TACTAC- tetra- -GAGCGAGC- … dle stavby motivu: perfect - CACACACACACACACACACA – imperfect - CACACACACACTCACACACA – interrupted - CACACACAGTTCCACACACA – composite - CACACACACACTCTCTCTCT –

29
názvosloví STR lokusy triviální FGA (located in the third intron of the human alpha fibrinogen gene) vWA (von Willebrand Factor, 40th intron) TH01 (intron 1 of human tyrosine hydroxylase gene) TPOX (human thyroid peroxidase gene), CSF1PO (human c-fms proto-oncogene for CSF-1 receptor gene) SE33 (β-actin related pseudogene) Penta D (21q22.3) Penta E (15q26.2) LPL (intron 6 of the lipoprotein lipase gene) polotriviální Y-GATA-H4 systematické D21S DYS390
 vWA (von Willebrand Factor, 40th intron) TH01 (intron 1 of human tyrosine hydroxylase gene) TPOX (human thyroid peroxidase gene), CSF1PO (human c-fms proto-oncogene for CSF-1 receptor gene) SE33 (β-actin related pseudogene) Penta D (21q22.3) Penta E (15q26.2) LPL (intron 6 of the lipoprotein lipase gene) polotriviální Y-GATA-H4. systematické D21S11 DYS390.")
30
názvosloví STR alela 7 v lokusu TH01: [AATG]7
alely označují se číslem, které vyjadřuje počet opakování základního motivu alela 7 v lokusu TH01: [AATG]7 alela 9 v lokusu TH01: [AATG]9 alela 9.3 v lokusu TH01: [AATG]6ATG[AATG]3 tzv. MIKROVARIANTA jedno označení může zahrnovat více sekvencí alela 7 [AATG]6 [AAAG] [AATG]4 [AAAG] [AATG]2
![názvosloví STR alela 7 v lokusu TH01: [AATG]7](http://slideplayer.cz/slide/2315784/8/images/30/n%C3%A1zvoslov%C3%AD+STR+alela+7+v+lokusu+TH01%3A+%5BAATG%5D7.jpg "alely. označují se číslem, které vyjadřuje počet opakování základního motivu. alela 7 v lokusu TH01: [AATG]7. alela 9 v lokusu TH01: [AATG]9. alela 9.3 v lokusu TH01: [AATG]6ATG[AATG]3. tzv. MIKROVARIANTA. jedno označení může zahrnovat více sekvencí. alela 7 [AATG]6 [AAAG] [AATG]4 [AAAG] [AATG]2.")
31
STR – jak vlastně vznikají nové alely?
vysoká mutační rychlost: 10-2 to 10-6 nt / lokus / generace asi dva základní mechanismy – nerovnoměrný crossing over a chyba při replikaci tímto mechanismem vznikají i alely s „tečkou“ = neúplné (9.3)
")
32
+n -n

33
7 7 8 7 8 9 7 8 9 9.3 7 8 9 9.3 10.3 6.2 7 8 9 10 9.3 10.3
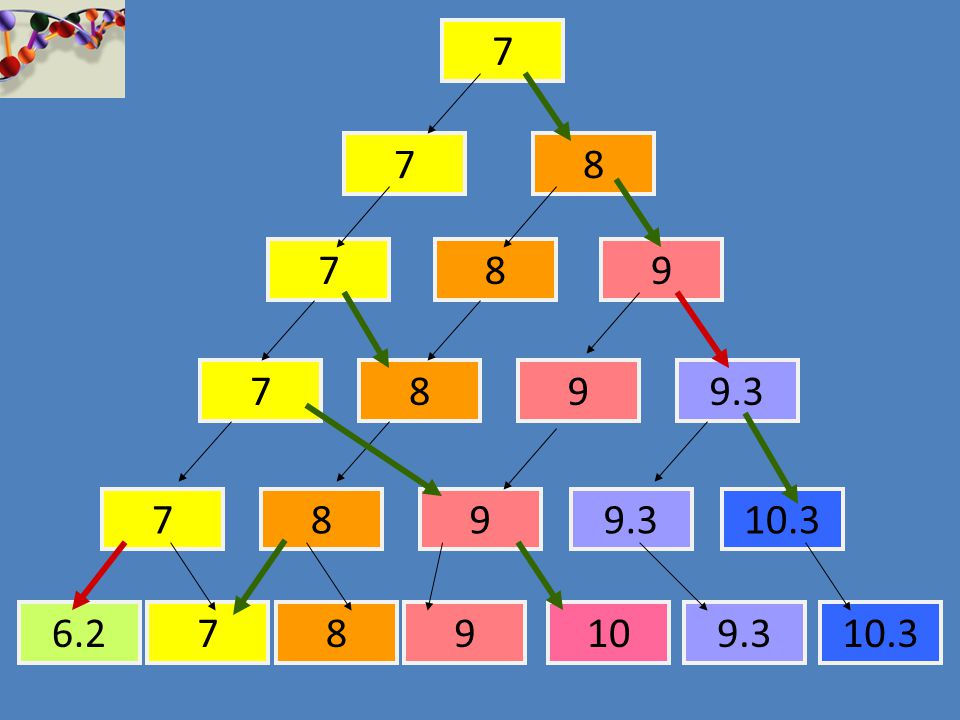
34
kde najdeme v lidském genomu STR ?

35
Dědičnost STR – autozomální STR
klasická mendelovská dědičnost homozygozita a heterozygozita STR lokus, např. TH01 9 / 9 6 / 9.3

36
Dědičnost STR – autozomální STR
6 8 9 10 6 / 9 8 / 9 6 / 10 8 / 10

37
22 / 22 22 21 / 24 Dědičnost STR – X-STR nonmendelovská dědičnost
homozygozita a heterozygozita u žen, hemizygozita u mužů STR lokus STR lokus 22 / 22 22 21 / 24

38
Dědičnost STR – X-STR 22 Y 21 24 22 / 21 Y / 21 22 / 24 Y / 24 XX XY

39
22 Dědičnost STR – Y-STR nonmendelovská dědičnost
jedna kopie lokusu u mužů STR lokus není STR lokus 22

40
Dědičnost STR – Y-STR X 22 X X / X 22 / X XX XY

41
Analýza STR SNADNO A RYCHLE

42
Analýza STR je založena na PCR
POMOCÍ SEKVENČNĚ SPECIFICKÉHO PÁRU PRIMERŮ AMPLIFIKUJI FRAGMENT OBSAHUJÍCÍ DANOU REPETICI

43
Analýza STR je založena na PCR
konstantní sekvence REPETICE konstantní sekvence 160 – 204 bp Fragment má délku podle počtu opakování motivu v repetici (např. 160 – 204 bp) S celkovým rozpětím délek můžu šoupat podle toho kam umístím primery 240 – 284 bp
 S celkovým rozpětím délek můžu šoupat podle toho kam umístím primery. 240 – 284 bp.")
44
Při PCR nepoužijeme obyčejné primery, ale jeden v páru je vždy fluorescenčně značený
Cca polovina vzniklých fragmentů bude mít tudíž začleněnou fluorescenční barvičku

45
Barvičky mohou emitovat v různých oblastech spektra
chci od nich, aby: byly chemicky stabilní velmi dobře emitovaly byly fotostabilní (emitovaly bez problémů opakovaně)
")
46
Provedu elektroforézu a detekci fluorescenční barvičky
gelová elfo kapilární elfo Hitachi FMBIO II Applied Biosystems 310, 3100

47
Sample Detection (Post-Electrophoresis)
DNA samples are loaded onto a polyacrylamide gel STR alleles separate during electrophoresis through the gel Sample Separation Sample Detection (Post-Electrophoresis) 505 nm scan to detect fluorescein-labels 585 nm scan to detect TMR-labels
 505 nm scan to detect fluorescein-labels. 585 nm scan to detect TMR-labels.")
48
Sample Interpretation
Mixture of dye-labeled PCR products from multiplex PCR reaction Sample Separation Sample Detection CCD Panel (with virtual filters) Argon ion LASER (488 nm) Color Separation Fluorescence ABI Prism spectrograph Capillary Sample Injection Size Processing with GeneScan/Genotyper software Sample Interpretation
 Argon ion LASER (488 nm) Color. Separation. Fluorescence. ABI Prism spectrograph. Capillary. Sample Injection. Size. Processing with GeneScan/Genotyper software. Sample Interpretation.")
49
Kapilární elfo

50
Kapilární elfo

51
Kapilární elfo

52
Kapilární elfo

54
ISS = vnitřní standard = „vnitřní žebříček“
35 50 75 100 139 160 200 250 300 340 350 400 450 490 500 150 100bp 150bp 160bp 200bp 250bp 139bp X bp Y bp A B

55
různé ISS GS500 ROX (Applied Biosystems) ILS600 CXR (Promega)
LTI ROX (Life Technologies)
")
57
allelic ladder = vnější standard = „vnější žebříček“
160 bp 200 bp 7 = bp 8 = bp 9 = bp 10 = bp 11 = bp 12 = bp 13 = bp 7 8 9 10 11 12 13 160 bp 200 bp A = bp = 8 B = bp = 11 A B

58
alelický ladder konkrétního lokusu interní ladder celé elektroforézy

59
off-ladder alely ? ? 13 10 11 10.3

60
Výsledek analýzy jednoho lokusu
heterozygot 16/17 homozygot 16/16

61
analýza více lokusů najednou = multiplex PCR
amplifikuji několik STR více páry primerů najednou (jak prosté, že?) ale ve skutečnosti je to peklo: primery se nesmí lepit = nesmí být komplementární primery musí mít stejnou anelační teplotu primery musí mít stejné pracovní prostředí amplifikace všech lokusů musí být stejně účinná jak ale pak při elektroforéze poznám, který fragment patří do kterého lokusu???
 ale ve skutečnosti je to peklo: primery se nesmí lepit = nesmí být komplementární. primery musí mít stejnou anelační teplotu. primery musí mít stejné pracovní prostředí. amplifikace všech lokusů musí být stejně účinná. jak ale pak při elektroforéze poznám, který fragment patří do kterého lokusu")
62
rozlišení fragmentů I. = pomocí dye

63
rozlišení fragmentů II. = pomocí délkových rozsahů
160 – 204 bp 240 – 284 bp 160 – 204 bp 240 – 284 bp

64
rozlišení fragmentů III. = pomocí modifikátorů mobility
Lokus A 160 – 204 bp Lokus B 190 – 254 bp 215 – 279 bp Výhoda – nemusím složitě vylaďovat multiplexy s novými primery

65
Komerční kity - Identifiler
D8S1179 D7S820 CSF1PO D21S11 D3S1358 TH01 D13S317 D16S539 D2S1338 D19S433 VWA TPOX D18S51 FGA AMEL D5S818

66
Komerční kity - PowerPlex® 16
Penta E D18S51 D3S1358 TH01 D21S11 Penta D D16S539 CSF1PO D5S818 D13S317 D7S820 FGA AMEL VWA D8S1179 TPOX

67
Některé nemilé jevy I. stuttering
D8S1179 D18S51 D21S11 Allele Stutter Product 6.2% 5.4% 6.3%

68
Některé nemilé jevy I. stuttering
GATA CTAT 3’ 5’ 1 2 3 5 6 Sklouznutí polymerázy 4 C T A Lokus je tím náchylnější, čím kratší je motiv Dinukleotidy mají stuttery a stuttery stutterů Tetranukleotidy mají stuttery do 15% Pentanukleotidy prakticky nestutterují

69
imbalance heterozygota až alelický drop-out
Některé nemilé jevy II. imbalance heterozygota až alelický drop-out

70
Některé nemilé jevy III. Splitting = „upadání adenosinu“ = deadenylace
5’ 3’ Polymerase extension Reverse Primer Forward A (-A form) (+A form) Shoulder peak -A +A +A -A Split peak +A -A
 (+A form) Shoulder peak. -A. +A. +A. -A. Split peak. +A. -A.")
71
Interlokusová imbalance
Některé nemilé jevy IV. Interlokusová imbalance AMEL D19 D3 TH01 D8 VWA D21 FGA D16 D18 D2 D3 AMEL D19 D21 D8 VWA TH01 D16 D18 D2 FGA

72
Některé nemilé jevy V. mizerná kapilára

73
Některé nemilé jevy VI. mutace v místě pro primer
* 8 6 alela 6 dropoutuje nevyvážené heterozygotní alely vyvážené heterozygotní alely bez mutace mutace ve středu vazebného místa primeru mutace na 3’-konci vazebného místa primeru (dropout)
")
74
tři píky D21S11 nejčastěji TPOX a D21S11

Podobné prezentace













>")

>")



